一种基于对比学习和度量学习的接地网不开挖腐蚀预测模型的制作方法
本发明涉及电力系统技术领域,特别涉及一种基于对比学习和度量学习的接地网不开挖腐蚀预测模型。
背景技术:
随着我国电力系统向更高压和更大容量发展,对系统运行的安全性和可靠性提出了越来越高的要求。接地网是电网为了保障人身和设备安全而必须设置的装置,目前我国普遍采用镀锌钢和碳钢作为接地网导体。随着我国生态环境的恶化和线路电压等级的提升,接地网材料表面的腐蚀程度不断加剧甚至发生断裂,严重影响着电网的安全运行。
由于接地网常年埋在地下,因此会因为地下复杂的土壤环境常对其产生腐蚀,导致其接地性能劣化,进而影响整个电网的正常运行。由此,探究接地网的腐蚀规律非常重要。
专利号为201510170082.9,名称为“一种接地网腐蚀状态诊断及预防方法”的专利,提出了对接地网水质信息、相对湿度信息和接地网材质并进行数据处理,但未提出明确的数据处理方法。
专利号为201610053843.7,名称为“变电站q235镀锌钢接地网的腐蚀率预测方法”,采用神经网络对接地网的腐蚀率进行预测,但是由于腐蚀是一个长期和渐变的过程,对实际电站接地网进行动态监测时通常样本数量很少,而在样本情况过少的情况下,直接采用神经网络或拟合的方法,极易产生过拟合的问题。
技术实现要素:
本发明所要解决的技术问题在于提供一种基于对比学习和度量学习的接地网不开挖腐蚀预测模型,显著减小了拟合函数的压力与复杂性,提高预测精度。为实现上述目的,本发明的技术方案包括以下步骤:
其包括以下步骤,
(1)选择用于预测模型的数据采样区域及其数据采样点,建立采样点样本库;
(2)通过将对比学习和度量学习相结合建立神经网络,形成预测模型;
(3)对步骤(2)形成的预测模型进行验证。
进一步地,步骤(1)中数据采样区域为选择接地网中2-4个腐蚀支路,将该腐蚀支路所在区域作为数据采样区域;所述数据采样点为在所述数据采样区域内的接地网腐蚀样本点。
进一步地,步骤(2)包括以下步骤,
(2-1)确定输入数据和输出数据:
输入数据为步骤(1)中数据采样区域对应土壤理化性质;
输出数据为数据采样区域对应的接地导体的腐蚀速率;
(2-2)通过度量学习和对比学习对步骤(2-1)的输入输出数据进行拟合。
进一步地,步骤(2-1)中,接地导体的腐蚀速率为将数据采样区域的接地网腐蚀样本点处截取腐蚀支路对应的部分接地导体作为样本,利用失重法计算出对应接地导体的腐蚀速率。
进一步地,步骤(2-1)中,土壤理化性质包括土壤电阻率、含水率、孔隙率、so42-和cl-的含量;
所述土壤电阻率的获得方法为:在数据采样区域内,垂直等距埋入地下4支金属探针,互相之间相隔为a,金属探针的埋入深度不超过a的5%;
土壤电阻率计算公式为:
ρ=2πar(1);
式中ρ为土壤电阻率,a为两个相邻金属探针之间的距离,r为接地电阻测量仪读数。
进一步地,步骤(2-2)包括以下步骤,
(2-2-1)通过度量学习确定虚拟度量指标α;
(2-2-2)对虚拟度量指标α进行训练,通过对比学习对虚拟度量指标α的拟合误差进行自监督对比学习,根据对比学习算法对虚拟度量指标α进行优化;
如果步骤(2-2-2)结果不收敛,则返回步骤(2-2-1)中,重新确定虚拟度量指标α值,直至结果收敛。
进一步地,步骤(2-2-1)中,确定虚拟度量指标α的方法为:
定义神经网络的损失函数如下:
其中,i表示训练集;它的k个查询为r={ik,jk,rk},k=1,...k;其中ik为第k个查询中一个样本的虚拟度量指标,jk为另一个样本产生的度量指标,而rk∈{+1,-1,0}是ik和jk两个点之间的真实腐蚀速率大小比较,小、大和相等分别用+1,-1和0表示,ψk(i,ik,jk,r,z)是第k次查询的损失值,表示为:
z是预测值,zik和zjk是在点ik和jk时的预测值;得到的z为α。
进一步地,步骤(2-2-2)中,对虚拟度量指标α进行训练的过程为:通过多层神经网络对样本集进行训练,在此基础上通过损失函数确定出虚拟度量指标a。
进一步地,步骤(2-2-2)中,根据对比学习算法对虚拟度量指标α进行优化的过程为:
在对比学习中,数据本身为学习算法提供监督,对于虚拟度量指标α,对比方法的目的是学习编码器f,文中列项说明格式如下:
score(f(α),f(α+))>>score(f(α),f(α-))(4);
其中,α+是与α相似或相等的数据点,称为正样本;α-是与α不同的数据点,称为负样本;score函数用来度量两个特征之间相似性,其表达式为:
score(f(a),f(a+))=f(a)tf(a+)(5);
作为样本输入的α称为锚定点,构造一个softmax分类器来正确地分类正样本对和负样本对,这个分类器鼓励f让正样本对相似,负样本对差异化:
进一步地,如果步骤(2-2-2)结果不收敛,则返回步骤(2-2-1)中,重新确定虚拟度量指标α值;
确定虚拟度量指标α值后,预测出未知样本的腐蚀速率y;
y=a1×fushi1+a2×fushi2+…an×fushin(8);
式中y是组合输出结果,a1、a2、…、an是需要拟合的系数,而fushi1、fushi2、…、fushin是接地导体的腐蚀速率。n是数据采样点的总个数。
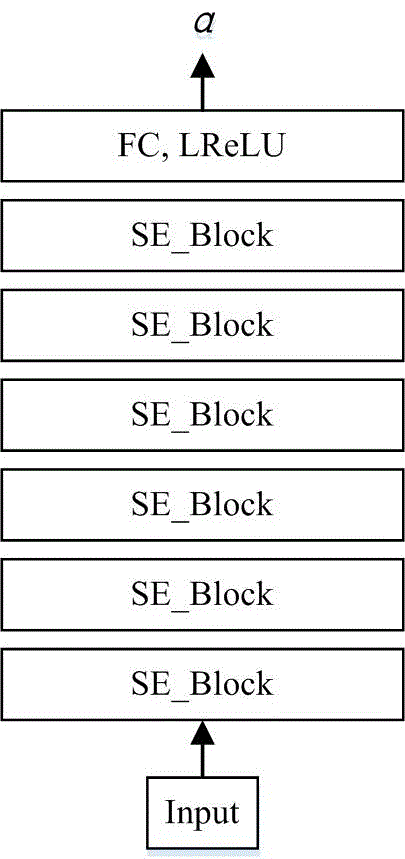
a1、a2、…、an拟合过程中,在多层神经网络的基础上,输入初始解阶段同样使用了se_block,并且底层三个层块共用了同样的参数,然后经过全局的压缩-膨胀模块dul_block,为临近样本提出的特征统筹判断重要性,最后经过全连接层输出临近样本的系数,以预测出未知样本的腐蚀速率。
进一步地,步骤(3)中,采用了广义回归神经网络(grnn)和bp神经网络对数据采样点进行了训练、拟合和预测,得到的结果与步骤(2)预测模型的结果进行比对。
本发明积极效果如下:
1、本发明将对比学习(cl-ml)和度量学习相结合,该方法把已经采样的数据采样点作为锚点,通过充分挖掘了数据采样点的内在相关性,显著减小了拟合函数的压力与复杂性。
2.本发明模型的预测精度远高于广义回归神经网络(grnn)和bp神经网络的预测精度。
附图说明
图1为对虚拟度量指标α进行训练时的神经网络图;
图2是本发明预测出未知样本的腐蚀速率y时使用的神经网络图。
具体实施方式
下面将结合附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本申请及其应用或使用的任何限制。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
本发明提供了一种基于对比学习和度量学习的接地网不开挖腐蚀预测模型,其包括以下步骤,
(1)选择用于预测模型的数据采样区域及其数据采样点,建立采样点样本库;
(2)通过将对比学习和度量学习相结合建立神经网络,形成预测模型;
(3)对步骤(2)形成的预测模型进行验证。
接地网在接入土壤后,随着使用时间的延长会发生腐蚀的现象,步骤(1)中数据采样区域为选择接地网中2-4个腐蚀支路,将该腐蚀支路所在区域作为数据采样区域;选择腐蚀支路时,优选的为选择严重腐蚀的支路。
所述数据采样点为在所述数据采样区域内的接地网腐蚀样本点。
步骤(2)包括以下步骤,
(2-1)确定输入数据和输出数据:
输入数据为步骤(1)中数据采样区域对应土壤理化性质;
输出数据为数据采样区域对应的接地导体的腐蚀速率;
(2-2)通过度量学习和对比学习对步骤(2-1)的输入输出数据进行拟合。
步骤(2-1)中,接地导体的腐蚀速率为将数据采样区域的接地网腐蚀样本点处截取腐蚀支路对应的部分接地导体作为样本,利用常规失重法计算出对应接地导体的腐蚀速率。
步骤(2-1)中,土壤理化性质包括土壤电阻率、含水率、孔隙率、so42-和cl-的含量;
所述土壤电阻率的获得方法为:在数据采样区域内,垂直等距埋入地下4支金属探针,互相之间相隔为a,金属探针的埋入深度不超过a的5%;
土壤电阻率计算公式为:
ρ=2πar(1);
式中ρ为土壤电阻率,a为两个相邻金属探针之间的距离,r为接地电阻测量仪读数。
含水率、孔隙率、so42-和cl-的含量均可以通过现有技术的常规测量方法获取其数值。
由于接地网材料在土壤中的腐蚀受到多种参数的影响,本发明选择了土壤电阻率、含水率、孔隙率、so42-和cl-的含量这些土壤理化性质。但是上述参数的物理量纲差异巨大,直接由其拟合出腐蚀速率还是欠佳的。特别地,腐蚀是一个长期的、复杂的、包含时间积分的、非线性的电化学过程,所列出的参数显然也是探索研究中发现的,因此有必要对上述物理参数进行合适的无量纲化度量。这就要通过步骤(2-2)通过度量学习和对比学习对步骤(2-1)的输入输出数据进行拟合而实现。
步骤(2-2)包括以下步骤,
(2-2-1)通过度量学习确定虚拟度量指标α;
(2-2-2)对虚拟度量指标α进行训练,通过对比学习对虚拟度量指标α的拟合误差进行自监督对比学习,根据对比学习算法对虚拟度量指标α进行优化;
如果步骤(2-2-2)结果不收敛,则返回步骤(2-2-1)中,重新确定虚拟度量指标α值,直至结果收敛。
在数学中,一个度量(或距离函数)是一个定义集合中元素之间距离的函数。而度量学习是学习一个度量相似度的距离函数:相似的目标离得近,不相似的离得远。度量学习(ml)的基本步骤为:a计算浅入度距离度量;b.将每个样本都当作一个锚点;c.根据距离挑一部分同类做正样本,一部分其他类做负样本组成子集;d.对每个要么是一个大的子集里基本包含整个mini-batch(小批量,n个样本)只是权重不同,要么是n个更小的数据对。本发明基于度量学习,将每个数据采样点作为一个锚点,学习虚拟度量指标α并训练;训练方法为样本点库中包括m个数据采样点即训练样本,从m个训练样本中抽取n个,形成
步骤(2-2-1)中,确定虚拟度量指标α的方法为:
定义神经网络的损失函数如下:
其中,i表示训练集;它的k个查询为r={ik,jk,rk},k=1,...k;其中ik为第k个查询中一个样本的虚拟度量指标,jk为另一个样本产生的度量指标,而rk∈{+1,-1,0}是ik和jk两个点之间的真实腐蚀速率大小比较,小、大和相等分别用+1,-1和0表示,ψk(i,ik,jk,r,z)是第k次查询的损失值,表示为:
z是预测值,zik和zjk是在点ik和jk时的预测值;得到的z为α。
其表示,只有同时预测出虚拟度量指标α时才能获得相应的奖励分数。经此训练,每当遇到类似的新样本时,通过于m组锚点的对比,就可以判断出那两个锚点之间差距。
步骤(2-2-2)中,对虚拟度量指标α进行训练的过程为:附图1显示了训练过程所用的神经网络,通过附图1的的多层神经网络对样本集进行训练,在此基础上通过损失函数确定出虚拟度量指标a。
进而通过对比学习,实现锚点之间差距的自监督优化。在对比学习中,数据本身将为学习算法提供监督。由此,步骤(2-2-2)中,根据对比学习算法对虚拟度量指标α进行优化,该的过程为:
在对比学习中,数据本身为学习算法提供监督,对于虚拟度量指标α,对比方法的目的是学习编码器f,文中列项说明格式如下:
score(f(α),f(α+))>>score(f(α),f(α-))(4);
其中,α+是与α相似或相等的数据点,称为正样本;α-是与α不同的数据点,称为负样本;score函数用来度量两个特征之间相似性,其表达式为:
score(f(a),f(a+))=f(a)tf(a+)(5);
作为样本输入的α称为锚定点,构造一个softmax分类器来正确地分类正样本对和负样本对,这个分类器鼓励f让正样本对相似,负样本对差异化:
上述的score函数其实是n-waysoftmax分类器常见的交叉熵损失,在现有技术文献中通常称为infonce损失。infonce也与互信息有关系,最小化infonce损失可使f(α)和f(α+)之间互信息的下界最大化。作为样本输入的α也可以被称为锚定点。为了优化这一特性,本发明构造一个softmax分类器来正确地分类正样本对和负样本对。这个分类器鼓励f让正样本对相似,负样本对差异化。
如果步骤(2-2-2)结果不收敛,则返回步骤(2-2-1)中,重新确定虚拟度量指标α值;
确定虚拟度量指标α值后,预测出未知样本的腐蚀速率y;
利用紧邻的两个或多个锚点,本发明采用k-临近的方法进行拟合,使用如改进后的神经网络图,即附图2所示的神经网络,输出结果是参与拟合的锚点的腐蚀速率的系数,即
y=a1×fushi1+a2×fushi2+…an×fushin(8);
式中y是组合输出结果,a1、a2、…、an是需要拟合的系数,而fushi1、fushi2、…、fushin是接地导体的腐蚀速率。n是数据采样点的总个数。
a1、a2、…、an拟合过程中,利用了如附图2所示的神经网络即在多层神经网络的基础上,输入初始解阶段同样使用了se_block,并且底层三个层块共用了同样的参数,然后经过全局的压缩-膨胀模块dul_block,为临近样本提出的特征统筹判断重要性,最后经过全连接层输出临近样本的系数,以预测出未知样本的腐蚀速率。
以k=2的2-临近预测为例,输入初始解阶段同样使用了se_block,并且底层三个层块共用了同样的参数,然后经过全局的压缩-膨胀模块(dul_block),为临近样本提出的特征统筹判断重要性,最后经过全连接层输出临近样本的系数,以预测出未知样本的腐蚀速率,损失使用l2损失。
步骤(3)中,采用了广义回归神经网络(grnn)和bp神经网络对数据采样点进行了训练、拟合和预测,得到的结果与步骤(2)预测模型的结果进行比对。这个不同算法有不同收敛速度,一般认为基于样本点算法拟合时误差收敛稳定了就认为建模成功了(这个收敛误差是样本点的误差,不是预测点的误差)。但原算法拟合的是否好取决于预测能力是否好。
步骤(3)中,采用了广义回归神经网络(grnn)和bp神经网络对数据采样点进行了训练、拟合和预测,得到的结果与步骤(2)预测模型的结果进行比对。
本实施例选取来自石家庄、保定等地的25个变电站的观测数据作为样本。接地网在土壤中腐蚀受到多种因素的影响,本发明选取了其中5个代表性土壤理化性质作为影响要素,包括土壤电阻率、含水率、孔隙率、so42-和cl-的含量。
为了和本发明(cl-ml)方法进行对比,同时采用了广义回归神经网络(grnn)和bp神经网络对样品进行了训练、拟合和预测。应用了上述三种模型对测试样本进行了预测,相关测试结果如表1所示。
表1实际值和3种模型的预测值对比
根据表1可知,本模型的预测精度远高于广义回归神经网络(grnn)和bp神经网络的预测精度。
由于腐蚀是一个长期和渐变的过程,故对实际电站接地网进行动态监测时通常是选择月为时间间隔,这就导致了腐蚀数据的样本通常少于100个,属于典型的小样本情况。而在样本情况过少的情况下,直接采用神经网络或拟合的方法,极易产生过拟合的问题。甚至因为样本过少,对过拟合的分析都具有很大的不确定性。此外,腐蚀速率虽然与土壤中的各项指标有关,但直接根据这些物理量纲差异巨大的参数拟合出腐蚀速率还是欠佳的。特别地,腐蚀是一个长期的、复杂的、包含时间积分的、非线性的电化学过程,所列出的参数显然也是探索研究中发现的比较重要的参数,而根据这些参数对应的腐蚀速率的趋势具有自然的对比性和相关性,因此,样本显然也具有超越仅仅用于拟合的价值。
本发明将对比学习(cl-ml)和度量学习相结合,提出一种cl-ml方法。该方法把已经采样的珍贵样本作为锚点,通过充分挖掘了稀有样本的内在相关性,显著减小了拟合函数的压力与复杂性。
本发明针对接地网腐蚀小样本和非线性强的问题,提出结合比较学习和度量学习的不开挖接地网腐蚀预测方法。本发明基于对比学习(contrastivelearning)和度量学习(metriclearning)的思想,把已经采样的样本作为锚点,预测新数据的腐蚀速率与现有样本腐蚀速率的关系,显著减小了拟合函数的压力与复杂性,并充分挖掘了数据采样点的内在相关性。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其他实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!