基于句子级索引的数据实时去重方法及系统与流程
本发明涉及数据处理领域,具体地,涉及一种基于句子级索引的数据实时去重方法及系统。
背景技术:
在新闻报道方面,随着互联网、智能终端广泛普及,新媒体新技术新应用迭代升级,各类信息爆炸式增长、裂变式传播。每日新闻量都在以数以万计的速度不断增长,而媒体间的相互转载,或进行小修改后重新发布,导致新闻的重复率较高,极大降低了数据的有效性。因此,如何过滤重复新闻,提高数据的价值,是一项值得研究的技术课题。
通过采集系统可以采集大量新闻文本数据,但是文本中存在很多重复数据影响对于结果的分析。分析前需要对这些数据去除重复,将采集到的文本数据向量化,用向量之间的距离来表示文章的相似度,常用方法有欧氏距离,海明距离,余弦距离等。专利cn107315809a公开了一种基于spark平台的集团新闻数据预处理方法,采集集团新闻数据,将采集回来的集团新闻数据进行去噪处理,去噪算子基于spark平台完成,对去噪处理后的数据进行去重处理;最后设定海明距离阈值,在去重处理中将海明距离小于设定的阈值的文本判定为近似文本。然而,目前需要去重的新闻中包含的新闻长短不一,且对实时性要求很高,且难以区分发布时间。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种基于句子级索引的数据实时去重方法及系统。
根据本发明提供的一种基于句子级索引的数据实时去重方法,包括:
索引构建步骤:对数据构建句子级索引;
数据存储步骤:将构建的句子级索引放入es集群和redis集群的索引进行存储,所述redis集群存储预定时间内的数据,所述es集群存储所有数据;
实时去重步骤:对待去重的数据进行历史相似性数据检索,根据待去重的数据的文本长度选择相应的相似度计算方法计算与历史相似性数据检索结果的相似度,根据相似度进行去重,以及形成新的句子级索引并添加到es集群和redis集群的索引中。
优选地,所述索引构建步骤包括:对数据进行数据正向索引构建以及句子倒排索引构建;
对数据进行数据正向索引构建包括:
对数据进行文本格式化处理,并进行分词;
根据分词结果进行权重均方根计算;
对分词结果通过哈希算法得到数据的哈希码;
按分隔符对数据进行分句,通过哈希算法构建每个句子的向量;
计算数据的文本长度,从而判断是长文本、短文本;
对数据进行句子倒排索引构建包括:
将数据正向索引构建中的句子的向量作为关键字值,将向量相同的数据对应的新闻编码作为值,通过新闻编码提取数据。
优选地,所述实时去重步骤包括:
输入子步骤:对待去重数据进行文本格式化处理,计算数据文本长度,在数据文本长度小于预值kmin的情况下不进行去重,否则进入相似数据检索子步骤;
相似数据检索子步骤:
根据分隔符将数据拆分为句子集,按顺序选取前n句词语个数大于m的句子,n、m为自然数;
将选取的前n句句子分别进行分词并通过simhash算法得到n个句子的向量集合φ:{sencode0,sencode1,sencode2,...,sencoden};
根据向量集合φ的句子的向量在句子倒排索引中进行检索,在redis集群和es集群中进行同步查询,若待去重数据的文本长度大于阈值k,则选取对应的长文本数据的新闻编码,若待去重数据的文本长度小于等于阈值k且大于等于预值kmin,则选取对应的短文本数据的新闻编码,得到n句句子在redis集群中查询得到结果集合φr,以及在es集群中查询得到结果集合φe;
若结果集合φr不为空,则对结果集合φr中的新闻编码进行数据正向索引提取,并与待去重的数据进行相似度计算;若结果集合φr为空,则对结果集合φe中的新闻编码进行数据正向索引提取,并与待去重的数据进行相似度计算;
根据相似度计算结果进行去重,并将新获取的数据正向索引和句子倒排索引添加到redis集群和es集群的索引中。
优选地,所述相似度计算包括:
步骤1:对待去重数据进行分词处理,若待去重数据为长文本,则通过simhash算法计算待去重数据的哈希码,循环φr中的哈希码,与待去重数据的哈希码进行海明距离计算,若不存在海明距离小于预定值的数据,则表明未找到相似数据,进入步骤2;若存在海明距离小于定值的数据,则表明待去重数据存在相似数据;
若待去重数据为短文本,则对待去重数据分词结果进行权重均方根计算,得到rootofsquare1,循环φr中的rootofsquare,与待去重数据的rootofsquare1进行余弦相似度计算,若不存在相似度大于预定值的新闻,则表明未找到相似数据,进入步骤2;若存在相似度大于定值的数据,则表明待去重数据存在相似新数据;
步骤2:对待去重数据进行分词处理,若待去重数据为长文本,则通过simhash算法计算待去重数据的hashcode,循环φe中的哈希码,与待去重数据的hashcode进行海明距离计算,若不存在海明距离小于预定值的数据,则表明未找到相似数据;若存在海明距离小于预定值的数据,则表明待去重数据存在相似数据;
若待去重数据为短文本,则对待去重数据分词结果进行权重均方根计算,得到rootofsquare,循环φe中的rootofsquare,与待去重数据的rootofsquare进行余弦相似度计算,若不存在相似度大于预定值的数据,则表明未找到相似数据;若存在相似度大于定值的数据,则表明待去重数据存在相似数据。
优选地,所述实时去重步骤将大于一定时间的索引同步更新至es集群。
根据本发明提供的一种基于句子级索引的数据实时去重系统,包括:
索引构建模块:对数据构建句子级索引;
数据存储模块:将构建的句子级索引放入es集群和redis集群的索引进行存储,所述redis集群存储预定时间内的数据,所述es集群存储所有数据;
实时去重模块:对待去重的数据进行历史相似性数据检索,根据待去重的数据的文本长度选择相应的相似度计算方法计算与历史相似性数据检索结果的相似度,根据相似度进行去重,以及形成新的句子级索引并添加到es集群和redis集群的索引中。
优选地,所述索引构建模块包括:对数据进行数据正向索引构建以及句子倒排索引构建;
对数据进行数据正向索引构建包括:
对数据进行文本格式化处理,并进行分词;
根据分词结果进行权重均方根计算;
对分词结果通过哈希算法得到数据的哈希码;
按分隔符对数据进行分句,通过哈希算法构建每个句子的向量;
计算数据的文本长度,从而判断是长文本、短文本等不同的情况;
对数据进行句子倒排索引构建包括:
将数据正向索引构建中的句子的向量作为关键字值,将向量相同的数据对应的闻编码作为值,通过新闻编码提取数据。
优选地,所述实时去重模块包括:
输入子模块:对待去重数据进行文本格式化处理,计算数据文本长度,在数据文本长度小于预值kmin的情况下不进行去重,否则进入相似数据检索子模块;
相似数据检索子模块:
根据分隔符将数据拆分为句子集,按顺序选取前n句词语个数大于m的句子,n、m为自然数;
将选取的前n句句子分别进行分词并通过simhash算法得到n个句子的向量集合φ:{sencode0,sencode1,sencode2,...,sencoden};
根据向量集合φ的句子向量在句子倒排索引中进行检索,在redis集群和es集群中进行同步查询,若待去重数据的文本长度大于阈值k,则选取对应的长文本数据的新闻编码,若待去重数据的文本长度小于等于阈值k且大于等于预值kmin,则选取对应的短文本数据的新闻编码,得到n句句子在redis集群中查询得到结果集合φr,以及在es集群中查询得到结果集合φe;
若结果集合φr不为空,则对结果集合φr中的新闻编码进行数据正向索引提取,并与待去重的数据进行相似度计算;若结果集合φr为空,则对结果集合φe中的新闻编码进行数据正向索引提取,并与待去重的数据进行相似度计算;
根据相似度计算结果进行去重,并将新获取的数据正向索引和句子倒排索引添加到redis集群和es集群的索引中。
优选地,所述相似度计算包括:
模块m1:对待去重数据进行分词处理,若待去重数据为长文本,则通过simhash算法计算待去重数据的哈希码,循环φr中的哈希码,与待去重数据的哈希码进行海明距离计算,若不存在海明距离小于预定值的数据,则表明未找到相似数据,执行模块m2;若存在海明距离小于定值的数据,则表明待去重数据存在相似数据;
若待去重数据为短文本,则对待去重数据分词结果进行权重均方根计算,得到rootofsquare1,循环φr中的rootofsquare,与待去重数据的rootofsquare1进行余弦相似度计算,若不存在相似度大于预定值的新闻,则表明未找到相似数据,执行模块m2;若存在相似度大于定值的数据,则表明待去重数据存在相似新数据;
模块m2:对待去重数据进行分词处理,若待去重数据为长文本,则通过simhash算法计算待去重数据的哈希码,循环φe中的哈希码,与待去重数据的哈希码进行海明距离计算,若不存在海明距离小于预定值的数据,则表明未找到相似数据;若存在海明距离小于预定值的数据,则表明待去重数据存在相似数据;
若待去重数据为短文本,则对待去重数据分词结果进行权重均方根计算,得到rootofsquare,循环φe中的rootofsquare,与待去重数据的rootofsquare进行余弦相似度计算,若不存在相似度大于预定值的数据,则表明未找到相似数据;若存在相似度大于定值的数据,则表明待去重数据存在相似数据。
优选地,所述实时去重模块将大于一定时间的索引同步更新至es集群。
与现有技术相比,本发明具有如下的有益效果:
本发明针对不同长度数据,采用不同算法,长文本之间采用海明去重,短文本采用余弦去重。同时,对海量历史数据采用句子集索引,充分结合es和redis的优点进行去重加快查询速度,实现数据实时去重。
本发明可以实现大数据量新闻快速去重,提高大数据量新闻查询效率以及实现对差异化新闻分类处理。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为正向索引构建示意图;
图2为句子倒排索引构建示意图;
图3为去重流程图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
本实施例提供一种应用于实时新闻去重的基于句子级索引的数据实时去重系统,包括:
新闻索引构建模块:用于构建句子级索引及新闻相关与计算信息。
数据存储模块:用于存储新闻相关索引及历史新闻。
新闻实时去重模块:用于实时新闻去重。
其中,实时新闻去重包括如下子模块:
输入子模块:用于输入待去重新闻,对新闻进行文本格式化处理。
相似新闻检索子模块:其用于对预处理后的文本进行历史相似新闻检索。
新闻相似度计算子模块:根据新闻长度,选择不同相似度计算方法。
输出子模块:输出新闻去重结果。
具体的来说:
1、新闻索引构建模块主要分为:新闻正向索引构建及句子倒排索引构建。
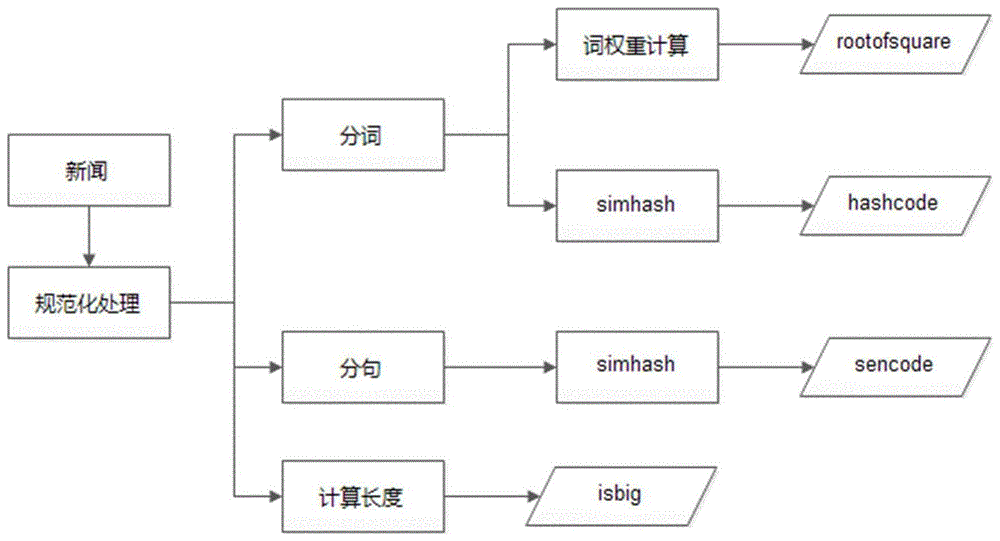
如图1所示,新闻正向索引构建包括:
步骤1:对新闻进行规范化处理,如剔除新闻中的图片等;
步骤2:对句子分隔符进行统一处理,转换成规范分隔符;
步骤3:对新闻进行分词,得到分词结果,分词结果由词语,词权重,词性三部分组成(word|w|ps);分词结果示意如下:
待分词句子:互联网赋能金融行业
分词结果:互联网|0.04981000|d_l,赋能|0.00068602|d_v,金融行业|0.00430044|d_n。
步骤4:对新闻分词结果进行权重均方根计算,得到rootofsquare,均方根公式如下:
x:为一种向量模式,本处采用tfidf,xn:指的是分词后的第n个词所表示的结果值。
步骤5:计算新闻的哈希码。对新闻分词结果通过simhash算法进行hash、加权、合并、降维,得到每条新闻的哈希码。
步骤6:按分隔符对新闻进行分句,按顺序选择新闻前n句词语个数大于m的句子,通过simhash算法,构建句子的向量;。
步骤7:计算新闻文本长度length,若大于k,则isbig=1,为长文本;否则isbig=0,为短文本;若字数小于kmin,如:新闻正文文本超短,则数据不参与去重,isbig=0;。
如图2所示,句子倒排索引构建包括:
将1.1新闻正向索引中句子向量作为关键字值,将向量相同的新闻对应的新闻编码作为值,通过新闻编码可提取到新闻正文。
2、数据存储模块
对于上述新闻正向索引和句子倒排索引放入es集群和redis集群存储;redis集群主要存储一定时间以内的新闻,es存储所有新闻。es由于是非实时搜素,所以redis保留一定时间的最新数据,用来解决es非实时问题。
3、新闻实时去重模块包括:
3.1、输入模块
本模块用于用于输入待去重新闻,对新闻进行文本格式化处理。
步骤1:剔除新闻中的图片等,对标点符号做统一转换;
步骤2:计算新闻文本长度length,若字数小于kmin,则为超短文本,不进行去重;否则则进入相似新闻检索模块。
3.2、相似新闻检索模块
本模块为去重核心模块,用于查找是否存在相似新闻。
步骤1:根据分隔符,将新闻拆分为句子集,按顺序选取符合条件的前n句。
步骤2;将句子集进行分词处理,分词后通过simhash算法,得到n个句子的哈希码集合φ{sencode0,sencode1,sencode2,...,sencoden}。
步骤3:根据集合φ中的句子的哈希码在句子倒排索引中进行检索,在redis和es索引中进行同步查询,若新闻长度length大于k,则为长文本,选取isbig=1的新闻编码,否则则为短文本,选取isbig=0的新闻编码;对redis和es中对应n个句子获取的新闻结果分别取并集,获得结果集合φr和φe。
步骤4:若集合φr不为空,则对集合φr中的新闻编码对应新闻正向索引进行提取,进入步骤5与待去重新闻进行相似度计算;若合φr为空,则对集合φe中的新闻编码对应新闻正向索引进行提取,进入新闻相似度计算模块与待去重新闻进行相似度计算。
3.3、新闻相似度计算模块
步骤1:对待去重新闻news1进行分词处理,若news1为长文本,则通过simhash算法计算news1的hashcode1,循环φr中的哈希码,与待去重新闻news1的hashcode1进行海明距离计算,若不存在海明距离小于定值的新闻,则表明未找到相似新闻,进入步骤2;若存在海明距离小于定值的新闻,则表明news1存在相似新闻,为重复新闻,进入输出模块。若news1为短文本,则对新闻分词结果进行权重均方根计算,得到rootofsquare1,循环φr中的rootofsquare,与待去重新闻news1的rootofsquare1进行余弦相似度计算,若不存在相似度大于定值的新闻,则表明未找到相似新闻,进入步骤2;若存在相似度大于定值的新闻,则表明news1存在相似新闻,为重复新闻,进入输出模块。
步骤2:与步骤1流程一致,只是对比集合为φe,具体步骤如下:对待去重新闻news1进行分词处理,若news1为长文本,则通过simhash算法计算news1的hashcode1,循环φe中的哈希码,与待去重新闻news1的hashcode1进行海明距离计算,若不存在海明距离小于定值的新闻,则表明未找到相似新闻;若存在海明距离小于定值的新闻,则表明news1存在相似新闻,为重复新闻。若news1为短文本,则对新闻分词结果进行权重均方根计算,得到rootofsquare1,循环φe中的rootofsquare,与待去重新闻news1的rootofsquare1进行余弦相似度计算,若不存在相似度大于定值的新闻,则表明未找到相似新闻;若存在相似度大于定值的新闻,则表明news1存在相似新闻,为重复新闻,进入输出模块。
3.4、输出模块
输出去重结果,并将实时去重模块计算得到的新闻正向索引和句子倒排索引添加到redis和es的索引中,同时将大于一定时间的新闻索引同步更新至es。
在本发明中,索引可以是字、词、句子,向量可以是tfidf、hash、word2vec、bert等。联合查询指的是多个机构、多个前缀一起查,按得分高低排序,大于一定阀值的才进行去重比较。如果循环查询每个机构、前缀,数量大,处理效果慢。es由于是非实时搜素,所以redis保留一定时间的最新数据,用来解决es非实时问题。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置、模块、单元以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置、模块、单元以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置、模块、单元可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置、模块、单元也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置、模块、单元视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!