一种基于改进YOLOv3的菜品识别方法与流程
一种基于改进yolo v3的菜品识别方法
技术领域
1.本发明属于数据处理技术领域,具体涉及一种基于改进yolo v3的菜品识别方法。
背景技术:
2.目前国内众多快餐店、学校、工厂等单位的餐厅和食堂中打菜工作枯燥、人工需求大、劳动力成本高。利用机器人代替人工完成打菜操作成为一种解决方案之一。使用面向餐厅服务的智能机器人系统要完成打菜的操作,要求机器人能够完全代替人眼完成对菜品的识别,即需要识别输入图像中各个菜品的类别及其所属区域。
3.由于中餐菜品不仅种类繁多,不同菜品之间可能看起来很相似,且同一菜品每次烹制完成的色、形都存在差异,这些情况都增加了菜品识别的难度,导致菜品的识别率低,速度慢。现有技术对菜品的识别工作,是对已经盛放在如碗等的用餐工具中的菜品,并非直接对盛放在食堂盛菜盆等器皿中的菜品进行识别,这种识别方法还是需要工作人员提前将菜品盛入碗中,打菜过程依然需要人工参与。如果将该方法直接用于对盛菜盆中的菜品识别,由于每次盛菜后菜品的数量发生变化导致图像也发生变化,会降低识别的准确率。
4.近年来,随着神经网络与深度学习的快速发展,众多优秀的目标检测网络被提出,目标检测的两个关键任务是目标分类与目标定位。其中yolo v3算法实现了在目标检测任务中速度与性能的较好平衡。由于yolo v3的特征提取部分对于不同通道间特征的关注度是一样的,但是某些通道中的特征对于网络具有更大的价值,需要网络更多的关注这些通道的特征信息。同时,特征提取部分的标准卷积在输入特征图上只能进行固定几何形状的采样,而这样的卷积神经网络在几何形变的建模上将受到限制,不能很好的适应未知的形变。
技术实现要素:
5.针对现有技术的不足,本发明提出了一种基于改进yolo v3的菜品识别方法,对yolo v3算法进行优化改进,将se模块嵌入darknet53的残差模块中,并引入可变形卷积dc,在无需人工参与的条件下完成对食堂盛菜盆中菜品的识别。
6.一种基于改进yolo v3的菜品识别方法,具体包括以下步骤:
7.步骤一、数据采集
8.利用相机对餐厅打菜窗口盛有不同菜品的盛菜盆进行图像拍摄;
9.步骤二、图像预处理
10.对步骤一中采集到的图像进行分析处理以及数据增强;
11.作为优选,所述数据增强的方法为对图像随机加入少量的高斯噪声提升网络的推理与泛化能力。
12.步骤三、数据集划分
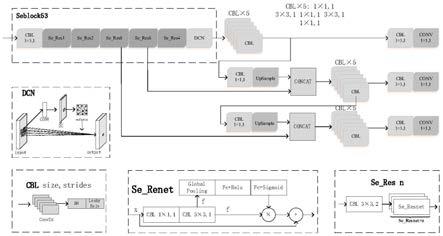
13.使用步骤二中增强处理后的图像制作数据集,对图像中的菜品类别以及边界框进行标注,将标注的菜品类别与边界框称为真实类别与真实框,再将标注后的数据集划分为
训练集、验证集与测试集;
14.步骤四、数据集分析处理
15.对标注后的数据集进行可视化分析,分别统计训练集、验证集与测试集中各个类别的真实框数量,对真实框数量少于所有类别真实框平均值一半的菜品图像进行数据扩充。所述数据扩充的方法为对真实框数量较少的菜品图像随机进行真实框图像扣出或整张图像选择,然后使用pix2pix图像风格迁移对扣出或选择的图像进行转化,将转化后的结果加入到数据集中完成数据扩充。
16.步骤五、构建特征提取与分类模型
17.yolo v3网络包括特征提取部分和预测部分,对其特征提取部分进行优化、改进,构建用于特征提取与分类的神经网络结构。yolo v3网络的特征提取部分为darknet53,包含5个残差块,每个残差块由一个2倍下采样卷积层cbl和一组重复的残差单元组成,其中cbl由2d
‑
convolution、batch normalization和leaky relu构成。本方法将se模块嵌入到残差单元中,构成新的残差单元。新的残差单元的结构为:输入特征图x,经过(1
×
1,1)与(3
×
3,1)的两个cbl后输出特征图f,该输出特征图f经过由global pooling、fc+relu与fc+sigmoid构成的se模块后得到的残差输出再与输出特征图f进行加权相乘,加权结果再与输入特征图x进行叠加,5个残差块中残差单元的重复次数依次为1、2、8、8、4;将最后一个残差块的输出与一层可变形卷积dc相连,组成网络的特征提取部分。
18.可变形卷积dc在标准卷积的操作基础上加入一个可学习的偏移参数
△
p
n
,偏移参数
△
p
n
通过对输入特征层做卷积得到,根据公式(1)计算当前点p0对应的输出y(p0):
[0019][0020]
其中r={(
‑
1,
‑
1),(0,
‑
1),(1,
‑
1),(
‑
1.0),(0,0),(1,0),(
‑
1,1),(0,1),(1,1)},w(p
n
)为卷积参数,x(p0+p
n
)为特征图输入,p0+p
n
对应从输入特征上采样的以p0为中心、向四周扩散的9宫格网络上的9个位置,p0+p
n
+
△
p
n
对应偏移后的9个位置。将输入的特征图上的每个点依次作为当前点p0计算其输出y(p0),即完成特征提取。
[0021]
预测部分借鉴了fpn的思想,将特征提取网络中第3、4个残差块与最后一层dc的输出进行特征融合,产生52
×
52、26
×
26、13
×
13三个不同尺度的特征图,分别在这三个特征图上预测输出目标包围框中心点坐标(x,y)的调整参数、先验框宽度和高度(w,h)的调整参数以及类别置信度和预测概率。其中,13
×
13的特征图用于大目标的预测,26
×
26的特征图用于中等目标的预测,52
×
52的特征图用于小目标的预测。
[0022]
步骤六、分类模型训练与优化
[0023]
使用在大型数据集上充分训练过的模型进行预训练迁移,输入训练集对模型进行训练,在每次迭代结束后使用验证集对模型进行交叉验证,计算训练损失。采用学习率调整策略,使标签更平滑,再逐层精调网络;
[0024]
学习率调整策略为在模型优化初期使用warmup策略,当训练损失下降变得平缓后使用余弦衰减策略,让学习率更加平滑,提供周期性变化的学习率使网络跳出局部最优;其中,损失包括中心点坐标(x,y)的损失、anchor的(w,h)损失、置信度损失和类别预测损失。
[0025]
对网络进行逐层精调是指将整个网络分为特征提取网络以及三个yolo预测分支层,冻结特征提取网络后再分别冻结三个yolo预测层中的两个,对剩下的那个yolo预测层
进行微调。
[0026]
当达到设置的迭代次数时,完成模型的训练优化,保存模型参数。
[0027]
作为优选,迭代次数设置为小于500。
[0028]
步骤七、模型测试与结果分析
[0029]
将测试集输入步骤六优化后的分类模型中,针对输出结果中出现分类置信度低、候选框冗余重复等问题,使用改进的nms方法进行分析。
[0030]
改进后nms方法包括4个参数:置信度阈值score_threshold、通过非极大抑制选择的框的最大数量max_output_size、iou阈值iou_threshold1和niou阈值iou_threshold2。其中置信度阈值score_threshold、iou阈值iou_threshold1和niou阈值iou_threshold2的取值范围为0.3~0.5,通过非极大抑制选择的框的最大数量max_output_size根据步骤四的分析统计的每张图像真实框的数量进行设置。
[0031]
首先剔除置信度低于score_threshold的检测框;然后按nms的方法对检测框进行第一次筛选,剔除iou值大于iou_threshold1的检测框,当保留的检测框数量达到设定的max_output_size的值时,将剩余的检测框全部剔除,进入下一阶段的筛选,iou值的计算方法如下:
[0032][0033]
其中,a表示剩余的检测框,b表示已经被保留的检测框。
[0034]
对经过上述步骤筛选后的检测框再次进行筛选,以置信度最高的检测框作为第一个保留的检测框,依次计算剩余的检测框与已经被保留的检测框的niou值,niou值的计算公式为:
[0035][0036]
当剩余的检测框的niou值大于iou_threshold2时剔除该检测框,否则保留该检测框。
[0037]
最后输出保留的检测框的坐标与置信度。
[0038]
作为优选,置信度阈值score_threshold的值为0.35。
[0039]
作为优选,iou阈值iou_threshold1和niou阈值iou_threshold2的值分别为0.45、0.35。
[0040]
步骤八、菜品分类
[0041]
使用相机对餐厅打菜窗口的图像进行实时录像,将视频输入到保存的模型中进行分类、检测,并保存模型输出结果中菜品的类别与位置信息,辅助打菜机器人完成打菜。
[0042]
本发明具有以下有益效果:
[0043]
改进后的特征提取网络能够自适应学习特征图不同通道间的相互关系,并给予不同程度的关注,同时将每个特征图的全局特征信息向下传递减少信息的丢失;能够更好的适应打菜过程中菜品不断发生的几何形变,提高网络的识别准确度;改进的nms处理能够更好地抑制冗余预测框。
附图说明
[0044]
图1为实施例中采集的菜品图像;
[0045]
图2为实施例数据集中的真实框分布;
[0046]
图3为实施例菜品各类别的真实框分布。
[0047]
图4为实施例中使用pix2pix方法进行转化的前后对比图;
[0048]
图5为实施例中构建的特征提取与分类模型;
[0049]
图6(a)为标准卷积采样图,图6(b)为可变形卷积采样图示例;
[0050]
图7为实施例中训练优化的loss曲线图;
[0051]
图8为实施例中得到的分类结果。
具体实施方式
[0052]
以下结合附图对本发明作进一步的解释说明;
[0053]
步骤一、数据采集
[0054]
如图1所示,采集高校餐厅菜品图像6219张。
[0055]
步骤二、图像预处理
[0056]
对步骤一采集到的图像数据进行分析后,剔除其中出现次数过少的菜品种类后,保留其中37类满足条件的菜品作为检测目标类别。向保留的菜品图像加入少量的高斯噪声,以提升网络的推理与泛化能力,作为分类的数据集。
[0057]
步骤三、数据集划分
[0058]
使用步骤二中增强处理后的图像制作pascal voc格式的数据集,对图像中的菜品类别以及边界框进行标注,将标注的菜品类别与边界框称为真实类别与真实框,再将标注后的数据集按照45:5:6的比例随机划分为训练集、验证集与测试集;其中训练集包含4975张图像,验证集中包含552张图像,测试集中包含692张图像。
[0059]
步骤四、数据集分析处理
[0060]
对标注后的数据集进行可视化分析,分别统计训练集、验证集与测试集中各个类别的真实框数量,如图2所示,训练集包含23055个真实框,验证集包含3017个真实框,每张图片中的真实框最多为8个,最少为1个,平均个数为4
‑
5;部分菜品类别的真实框数量如图3所示,对千张包、毛豆冬瓜条、蛋蒸肉、炒小南瓜、盐水虾的图像进行数据扩充:对前述菜品图像随机进行真实框图像扣出或整张图像选择,然后使用pix2pix图像风格迁移对随机选择出的图像进行转化,如图4所示,将转化后的结果加入到数据集中完成数据扩充。
[0061]
同时对真实框的大小比例进行分析,真实框相当于原图的面积大概在12%
‑
30%左右,根据在相对尺寸上的定义,目标真实框的长度和宽度小于原始图像长度和宽度的10%时,即目标真实框的面积小于原始图像的1%,称其为小目标。分析结果表明,中等比例的数量占绝大部分,较大比例的其次,即检测任务以中、大型目标为主。
[0062]
步骤五、构建特征提取与分类模型
[0063]
对yolo v3网络中的特征提取部分进行优化、改进,构建用于特征提取与分类的神经网络结构,如图5所示。将se模块嵌入yolo v3网络中darknet53的5个残差模块中,se模块主要包括squeeze和excitation两个操作,可以对特征通道间的相关性进行建模,强化重要的特征。squeeze操作采用global average pooling实现将一个通道上整个空间特征编码
为一个全局特征;excitation操作采用sigmoid形式的门机制抓取通道之间的关系,使用了两个全连接层,第一个全连接层降维,然后通过relu激活,再通过第二个全连接层恢复维度,接着采用sigmoid激活,最后将学习到的各个通道的激活值乘上原始特征。整个se操作可以看作学习特征各个通道的权重系数。yolo v3网络的特征提取部分为darknet53,包含5个残差块,每个残差块由一个2倍下采样卷积层cbl和一组重复的残差单元组成,其中cbl由2d
‑
convolution、batch normalization和leaky relu构成。本方法将se模块嵌入到残差单元中,构成新的残差单元。新的残差单元的结构为:输入特征图x,经过(1
×
1,1)与(3
×
3,1)的两个cbl后输出特征图f,该输出特征图f经过由global pooling、fc+relu与fc+sigmoid构成的se模块后得到的残差输出再与输出特征图f进行加权相乘,加权结果再与输入特征图x进行叠加,5个残差块中残差单元的重复次数依次为1、2、8、8、4;将最后一个残差块的输出与一层可变形卷积dc相连,组成网络的特征提取部分。
[0064]
对于3
×
3的标准卷积,计算每个点的输出都要从输入特征中采样9个位置,这9个位置分布在以当前点p0为中心向四周扩散得到的9宫格形状的网格上,如图6(a)所示,则当前点p0对应的输出y(p0)为:
[0065][0066]
其中r={(
‑
1,
‑
1),(0,
‑
1),(1,
‑
1),(
‑
1.0),(0,0),(1,0),(
‑
1,1),(0,1),(1,1)},p0+p
n
对应以p0为中心在输入特征中采样的9个位置,w(p
n
)为卷积参数,x(p0+p
n
)为特征图输入。
[0067]
可变形卷积dcn在标准卷积的操作基础上加入一个可学习的偏移参数
△
p
n
,偏移参数
△
p
n
通过对输入特征做卷积得到,输入特征层尺寸为w
×
h
×
c,其中w、h表示宽度和高度,c为通道数,则对输入特征层做3
×
3,卷积核为2c的卷积获得偏移参数
△
p
n
,输出偏移参数的尺寸为w
×
h
×
2c,前c个通道为x方向上的偏移量,后c通道个为y方向上的偏移量。
[0068]
根据公式(5)计算当前点p0对应的输出y(p0):
[0069][0070]
其中p0+p
n
+
△
p
n
对应偏移后的9个位置,如图6(b)所示,加上偏移参数后的9个点成非矩形形状。将输入的特征图上的每个点依次作为当前点p0计算其输出y(p0),即完成特征提取。
[0071]
预测部分借鉴了fpn的思想,将特征提取网络中第3、4个残差块与最后一层dc的输出进行特征融合,分别预测输出目标包围框中心点坐标(x,y)的调整参数、先验框的(w,h)调整参数以及类别置信度和预测概率,产生52
×
52、26
×
26、13
×
13三个不同尺度的特征图。其中,13
×
13的特征图用于大目标的预测,26
×
26的特征图用于中等目标的预测,52
×
52的特征图用于小目标的预测。
[0072]
步骤六、分类模型训练与优化
[0073]
首先使用在coco数据集上充分训练过的预训练模型进行迁移训练,输入训练集对模型进行训练,在每次迭代结束后使用验证集对模型进行交叉验证,计算训练损失。在初期使用warmup策略,使训练稳定;当训练损失下降变得平缓后改用余弦衰减策略,让学习率更加平滑,提供周期性变化的学习率使网络跳出局部最优,其中,损失包括中心点坐标(x,y)
的损失、anchor的(w,h)损失、置信度损失和类别预测损失;由于在菜品数据集制作过程中也可能存在漏标错标的情况,标签平滑作为一种正则化策略,可以降低网络对标签置信度的信赖,对漏标、错标数据具有很好的适应性,降低标签错误对分类准确度的影响;
[0074]
将整个网络分为特征提取网络以及三个yolo预测分支层,冻结特征提取网络后再分别冻结三个yolo预测层中的两个,对剩下的那个yolo预测层进行微调。训练过程的loss曲线如图7所示。
[0075]
迭代训练490次时,完成模型的训练优化,保存模型参数。
[0076]
步骤七、模型测试与结果分析
[0077]
将测试集输入步骤六优化后的分类模型中,针对输出结果中出现分类置信度低、候选框冗余重复等问题,使用改进的nms方法进行分析。设置置信度阈值score_threshold=0.35、通过非极大抑制选择的框的最大数量max_output_size=12、iou阈值iou_threshold1=0.45、niou阈值iou_threshold2=0.35。
[0078]
首先剔除置信度低于score_threshold的检测框;然后按nms的方法对检测框进行第一次筛选,剔除iou值大于iou_threshold1的检测框,当保留的检测框数量达到12个时,将剩余的检测框全部剔除,进入后续的筛选,iou值的计算方法如下:
[0079][0080]
其中,a表示剩余的检测框,b表示已经被保留的检测框。
[0081]
对经过上述步骤筛选后的检测框再次进行筛选,以置信度最高的检测框作为第一个保留的检测框,依次计算剩余的检测框与已经被保留的检测框的niou值,niou值的计算公式为:
[0082][0083]
当剩余的检测框的niou值大于iou_threshold2时剔除该检测框,否则保留该检测框。
[0084]
输出最后的识别结果,如图8所示。
[0085]
根据voc标准的mean average precision计算方法计算测试集图像的识别准确率,本实施例的识别准确率为91.16%。
[0086]
上述具体实施方式用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1