一种基于神经网络的长文本指代消解方法和装置与流程
本发明涉及自然语言处理学习领域,尤其涉及一种基于神经网络的长文本指代消解方法和装置。
背景技术:
自然语言理解是指人类使用计算机对文本、语音等形式表现的自然语言的形态、读音、语义等信息进行加工。
指代和省略是自然语言中广泛存在的语言现象,具备简化表述、连贯上下文等积极作用,但会造成语句的歧义问题,给自然语言理解带来了极大的困难,因此需要对代词指代的内容或缺省的部分进行恢复和补充。
指代消解,广义上说,就是在篇章中确定代词指向哪个名词短语的问题。按照指向,可以分为回指和预指。回指就是代词的先行语在代词前面,预指就是代词的先行语在代词后面。按照指代的类型可以分为三类:人称代词、指示代词、有定描述、省略、部分-整体指代、普通名词短语。
指代消解具有较长的研究历史,从早期的手工规则等理论方法研究到后来大规模语料中计算机自动处理技术的衍生,再到目前多种机器学习方法的引入,指代消解系统的性能在不断的提高。但由于对自然语言中语义的理解和表示方法仍然不够成熟,深层次的语言知识和语义特征的使用还较为简单,因此没有对词、句、篇章多层级的不同特点进行足够深入的挖掘,也没有对上下文信息进行有效的利用。指代消解是自然语言处理中的重点难点,对自然语言处理领域的信息抽取具有重要意义。
技术实现要素:
有鉴于现有技术的上述缺陷,本发明的目的是提供一种基于神经网络的长文本指代消解方法和装置,将深度学习技术引入代词消解任务中对长文本文本的指代和缺省部分进行恢复和补充。
为实现上述目的,本发明提供了一种基于神经网络的长文本指代消解方法,将深度学习技术引入代词消解任务,以实现中文代词消解及省略恢复任务。具体的,本发明运用了注意力网络,注意力网络本质上是多层的前向神经网络,通过计算目标相对于来源之间的概率值作为注意力,用于增强或减弱网络对某些词的关注程度,并在误差反传中进行调整。注意力网络的时间复杂度比循环神经网络rnn网络等神经网络小很多,适用于本应用。
本发明提出了一种基于神经网络的长文本指代消解方法,包括以下步骤:
步骤s1:输入长文本;
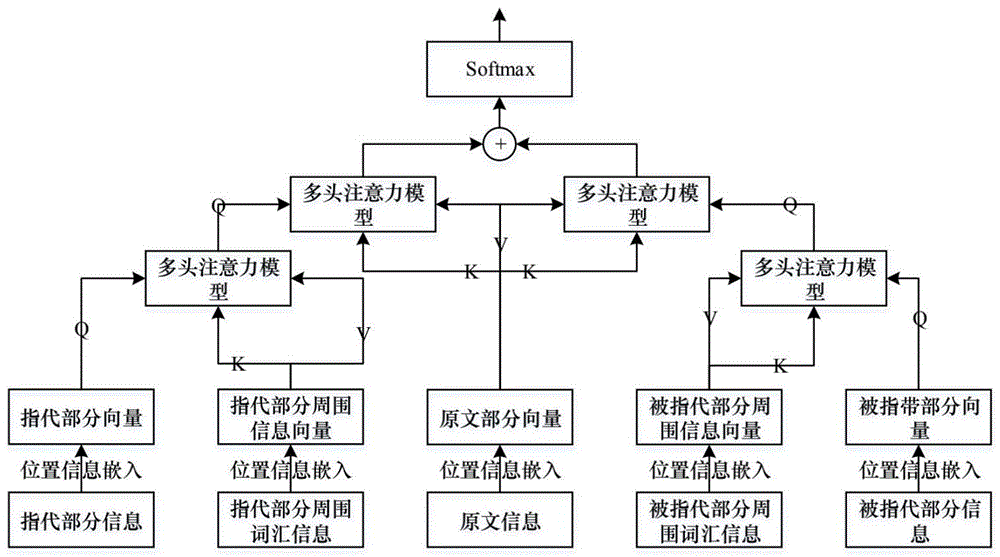
步骤s2:抽取长文本中的指代部分信息、指代部分周围词信息、原文信息、被指代部分信息、被指代部分周围词信息,进行向量化表示;并将向量化表示的指代部分信息、指代部分周围词信息、原文信息、被指代部分信息、被指代部分周围词信息分别嵌入位置信息,对应输出指代部分向量、指代部分周围信息向量、原文部分向量、被指代部分向量和被指代部分周围信息向量;
步骤s3:将指代部分向量与指代部分周围信息向量进行多头注意力机制计算,再使得到的结果继续与原文部分向量采用多头注意力机制计算,得到第一特征结果;
步骤s4:将被指代部分向量、被指代部分周围信息向量进行多头注意力机制计算,再使得到的结果继续和原文部分向量进行多头注意力机制计算,得到第二特征结果;
步骤s5:将步骤s3和步骤s4中获得的第一特征结果和第二特征结果连接组成一个综合结果,并利用softmax层将它映射在判别空间中,进行指代与否的判断。
进一步的,所述步骤s3具体包括:以指代部分向量为第一多头注意力模型的查询,以指代部分周围信息向量为键和值,第一多头注意力模型的输出作为第二多头注意力模型的查询,原文部分向量作为第二多头注意力模型的键和值,第二多头注意力模型输出第一特征结果。
进一步的,所述步骤s4具体包括:以被指代部分向量为第三多头注意力模型的查询,以被指代部分周围信息向量为键和值,第三多头注意力模型的输出作为第四多头注意力模型的查询,原文部分向量作为第四多头注意力模型的键和值,第四多头注意力模型输出第二特征结果。
本发明还公开了一种基于神经网络的长文本指代消解装置,包括长文本抽取模块、连接层、softmax层和四个多头注意力模型;
所述长文本抽取模块用于从长文本中抽取指代部分信息、指代部分周围词信息、原文信息、被指代部分信息、被指代部分周围词信息,进行向量化表示;并将向量化表示的指代部分信息、指代部分周围词信息、原文信息、被指代部分信息、被指代部分周围词信息分别嵌入位置信息,并输出指代部分向量、指代部分周围信息向量、原文部分向量、被指代部分向量、被指代部分周围信息向量;
所述四个多头注意力模型的输入、输出的连接关系为:
第一多头注意力模型的查询的输入为指代部分向量,其键和值的输入为指代部分周围信息向量;第一多头注意力模型的输出为第二多头注意力模型的查询的输入;第二多头注意力模型的键和值的输入为原文部分向量;第二多头注意力模型输出第一特征结果;
第三多头注意力模型的查询的输入为被指代部分向量,其键和值的输入为被指代部分周围信息向量,第三多头注意力模型的输出为第四多头注意力模型的查询的输入,第四多头注意力模型的键和值的输入为原文部分向量,第四多头注意力模型输出第二特征结果;
所述连接层用于将所述第一特征结果和所述第二特征结果连接组成一个综合结果;
所述softmax层用于将综合结果映射在判别空间中,进行指代与否的判断。
技术效果:
本发明的长文本指代消解方法通过构建多层注意力模型实现了自然语言中不同层次信息的处理。根据注意力机制计算指代部分和被指代部分在其周围信息和原文条件下的向量表示,进而计算出是否存在指代关系。这种方法有助于指代部分和被指代部分在当前语境下直接进行指代关系判别,对于显性指代和零指代两种情况都有较好的效果。
附图说明
图1为本发明指代消解方法的算法结构示意图;
图2是多头注意力机制模型结构图;
图3是本发明指代消解装置的结构示意图。
具体实施方式
为进一步说明各实施例,本发明提供有附图。这些附图为本发明揭露内容的一部分,其主要用以说明实施例,并可配合说明书的相关描述来解释实施例的运作原理。配合参考这些内容,本领域普通技术人员应能理解其他可能的实施方式以及本发明的优点。图中的组件并未按比例绘制,而类似的组件符号通常用来表示类似的组件。
现结合附图和具体实施方式对本发明进一步说明。
实施例1
如图1和图2所示,本发明提供了一种基于神经网络的长文本指代消解方法,将深度学习技术引入代词消解任务中,从而优化中文代词消解及省略恢复任务的完成。
本发明涉及多个指代消解的专业词汇,说明如下:
(1)回指(anaphora)又译为上指、前指或照应,是指用一个词项指代前文中提到过的单位或意义(crystal,1985)(转引自胡壮麟,1994∶48)。其中,前文中被指代的词项叫先行项(antecedent),指代的词项叫回指项或者指代项(anaphor)。一般来说,当话语中提到某个事物后,需要再次论及时,会使用回指(anaphoric)形式,使上下文之间相互照应(陈平,1987)。
多数情况下,回指中的先行项与回指项所指同一,二者为共指(coreferential)关系。称之为显性回指(directanaphora),并进一步指出其主要检验手段是语篇还原,即,看是否可以将先行词照抄下来放到被回指项替代的位置上而不改变意思,若并不影响原句语义的表达,则可断定其为显性回指。
在显性回指中,先行项在篇章出现时有明显的示踪性(tacking),且回指项可以被先行项替代,并不改变句子意义。而隐性回指却是对隐性(implicit)先行词的指代。隐性回指项的所指不必是语篇中具体的某一个词或某一句法成分,但它必定是交际双方根据话语所建立的心理表征中突出的实体。这时,回指项只认同与先行词相关的语义(identityofsense),两者所指并不相同。因此,在隐性回指中,如若用先行项替换回指项,必然会造成意义的改变。
指代部分信息,指代词。代词是指代替名词、动词、形容词、数量词、副词的词,包括:ɑ)人称代词,如“我、你、他、我们、咱们、自己、人家”,b)疑问代词,如“谁、什么、哪儿、多会儿、怎么、怎样、几、多少、多么”,c)指示代词,如“这、这里、这么、这样、这么些、那、那里、那么、那样、那么些”等。
(2)多头注意力机制(multi-headattention)
多头注意力是利用多个查询,来平行地计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分。
多头注意力模型的结构如图2所示,查询q,键k,值v首先进过一个线性变换(linear),然后输入到放缩点积attention(scaleddot-produactattention),这里要做h次,其实也就是所谓的多头,每一次算一个头。而且每次q,k,v进行线性变换的参数w是不一样的。然后将h次的放缩点积attention结果进行拼接(concat),再进行一次线性变换(linear)得到的值作为多头attention的结果。
本发明公开了一种基于神经网络的长文本指代消解方法,具体包括以下步骤:
(1)输入长文本,该长文本可以是一个句子或一段文字;
(2)抽取长文本的指代部分信息、指代部分周围词信息、原文信息、被指代部分信息、被指代部分周围词信息,进行向量化表示;并将向量化表示的指代部分信息、指代部分周围词信息、原文信息、被指代部分信息、被指代部分周围词信息分别嵌入位置信息,对应输出指代部分向量、指代部分周围信息向量、原文部分向量、被指代部分向量和被指代部分周围信息向量。
(3)将指代部分向量与指代部分周围信息向量进行多头注意力机制计算,再使得到的结果继续与原文部分向量采用多头注意力机制计算,得到表示指代部分的第一特征结果。该结果能够体现多层注意力机制条件下原文和指代部分周围词信息对指代部分的作用。更具体的,以指代部分向量为第一多头注意力模型的查询(query,简称q),以指代部分周围信息向量为键(key,简称k)和值(value,简称v),第一多头注意力模型的输出作为第二多头注意力模型的查询q,原文部分向量作为第二多头注意力模型的键k和值v,第二多头注意力模型输出第一特征结果。
(4)利用同样的方式将指代部分向量、指代部分周围信息向量和原文部分向量进行多头注意力机制计算,得到表示被指代部分的第二特征结果。更具体的,以被指代部分向量为第三多头注意力模型的查询q,以被指代部分周围信息向量为键k、值v,第三多头注意力模型的输出作为第四多头注意力模型的查询q,原文部分向量作为第四多头注意力模型的键k和值v,第四多头注意力模型输出第二特征结果。
(5)最后,将第一特征结果、第二特征结果连接组成一个综合结果,并利用softmax层将它映射在判别空间中,进行指代与否的判断。
实施例2
接下来举例说明以上各步骤的信息处理结果:
首先,在训练模型之前,训练数据的收集与数据预处理非常重要,因此举例说明训练数据的输入格式,如下:
示例1:崩龙珍夫妻康健和美;鞠琴十年前丧偶,两年前重结良缘,现在的老伴是一位以前未曾有过婚史的高级工程师;崩龙珍和鞠琴都尽量避免谈及自己的爱人,也尽量回避提及蒋盈波的亡夫屈晋勇——尽管她们对他都很熟悉;当然也绝不会愚蠢地提出蒋盈波今后是一个人过到底还是再找个老伴的问题来加以讨论,那无论如何还为时过早。“你是心里头不情愿,”崩龙珍对鞠琴说,“我当时对二哥是有意的,二哥真不错,惟一让我犹豫的只是他的岁数,比我大5岁,太大了点……后来是我自己出了事儿,”说到这儿崩龙珍脸上那潜存的惊恐表情浮凸出来,她闭上嘴唇,嘴角下撇,令人不忍目睹。鞠琴后来却表示她要感念蒋盈波一辈子,因为她觉得只有蒋盈波一人,似乎是给予了她不打折扣的无限的同情。
以上长文本中的提及到的实体名称有:“老伴”、“鞠琴”、“蒋盈波”、“屈晋勇”、“崩龙珍夫妻”、“崩龙珍和鞠琴”、“崩龙珍”、“二哥”等;指代词包括:“他”、“她”等;接下来展示该长文本输入的正确格式如下:
备注:长文本指代消解的难点在于如何在一段非常长的文本中快速定位到文中提到的各指代词对应哪一个实体。
第二步:将以上大量的训练数据传入实施例1中提及到的步骤(2)至步骤(5),由于训练数据传入模型内部操作以后全部都是数组形式传输,无法可视化解释每一层的输出结果,并且从长文本的处理到长文本训练模型或者模型推理,都经过了上述4个步骤(长文本的数据处理、向量化处理、神经网络层数组变换与计算等),因此步骤(2)至步骤(5)可按照模型的需要分为模型训练模块和模型推理模块两个部分。在模型训练模块会生成一个模型文件;模型推理模块会生成一个推理结果。
第三步:经过第一步的训练数据处理、第二步的模型训练并保存模型以后,进入数据的推理阶段。在此,采用一个新的示例进行说明,该示例输入数据的格式如下所示:
第四步:推理的输出结果,示例如下所示:
本领域技术人员应该了解,以上示例仅用于说明本发明的基于神经网络的长文本指代消解方法的步骤流程,其单个的推理结果并不能用于解释和评估模型的推理性能。
本发明的基于神经网络的长文本指代消解方法是一种回指消解方法,通过构建多层注意力模型实现了自然语言的不同层次信息的处理。根据注意力机制计算指代部分和被指代部分在其周围信息和原文条件下的向量表示,进而计算出是否存在指代关系。这种方法有助于指代部分和被指代部分在当前语境下直接进行指代关系判别,对于显性指代和零指代两种情况都有较好的效果。
如图3所示,本发明还公开了一种基于神经网络的长文本指代消解装置,包括长文本抽取模块、连接层、softmax层和四个多头注意力模型;
所述长文本抽取模块用于从长文本中抽取指代部分信息、指代部分周围词信息、原文信息、被指代部分信息、被指代部分周围词信息,进行向量化表示;并将向量化表示的指代部分信息、指代部分周围词信息、原文信息、被指代部分信息、被指代部分周围词信息分别嵌入位置信息,并输出指代部分向量、指代部分周围信息向量、原文部分向量、被指代部分向量、被指代部分周围信息向量;
所述四个多头注意力模型的输入、输出的连接关系为:
第一多头注意力模型的查询的输入为指代部分向量,其键和值的输入为指代部分周围信息向量;第一多头注意力模型的输出为第二多头注意力模型的查询的输入;第二多头注意力模型的键和值的输入为原文部分向量;第二多头注意力模型输出第一特征结果;
第三多头注意力模型的查询的输入为被指代部分向量,其键和值的输入为被指代部分周围信息向量,第三多头注意力模型的输出为第四多头注意力模型的查询的输入,第四多头注意力模型的键和值的输入为原文部分向量,第四多头注意力模型输出第二特征结果;
所述连接层用于将所述第一特征结果和所述第二特征结果连接组成一个综合结果;
所述softmax层用于将综合结果映射在判别空间中,进行指代与否的判断。
尽管结合优选实施方案具体展示和介绍了本发明,但所属领域的技术人员应该明白,在不脱离所附权利要求书所限定的本发明的精神和范围内,在形式上和细节上可以对本发明做出各种变化,均为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!