一种特权账号异常行为分析方法与流程
1.本发明涉及网络安全技术领域,尤其涉及一种特权账号异常行为分析方法。
背景技术:
2.随着工业互联网的发展,我国工业互联网发展越来越向智能化生产、网络化协同、个性化定制和服务化延伸方向发展,而工厂的永远在线,也意味着网络威胁隐患时刻存在。在工业互联网领域,高价值(如可以读取业务敏感数据的应用账号)、高风险(如可以启停设备的管理员账号)的工控特权账号繁多且复杂,工控终端安全管理薄弱,安全问题严峻。一旦特权账号被窃取或者拥有特权账号的相关内部人员利用特权账号对企业造成破坏或者发生其他特权威胁异常行为,将对企业造成极大的特权威胁安全隐患。传统系统针对特权威胁异常行为绝大多数是通过人工方式实现,凭借人工个人经验提供固化的简单逻辑条件进行检测,这种方法仅适用于特权账号较少的应用场景;在特权账号多且复杂工控互联网,这种方法并不适用,不仅需要投入大量的人力成本,还容易产生大量误报或者漏报情况,对企业正常经营生产极为不利。
3.中国专利申请文献cn110519241a中,公开了一种基于机器学习的主动发现特权威胁异常行为的方法及装置,该方法应用于特权账号威胁分析系统,包括如下步骤:a)通过通用的接口接入特权账号会话日志数据,通过通用的接口接入特权账号终端操作审计日志数据;b)对所述特权账号会话日志数据和特权账号终端操作审计日志数据进行处理;c)根据需要,选择让机器学习算法学习的历史日志数据或历史日志数据中某个维度数据;d)创建机器学习工作流模型,确认机器学习执行分析任务所需的配置信息和元数据;e)通过机器对选择的历史日志数据或历史日志数据中某个维度数据的学习,自动确认正常行为基线并开始实时检测;f)判断是否检测到特权威胁异常行为,如是,执行步骤g);否则,返回步骤e);g)实时报告特权威胁异常行为。所述步骤b)中对所述特权账号会话日志数据和特权账号终端操作审计日志数据进行处理包括过滤、提取和序列化。当特权行为偏离所述正常行为基线时,则认为该特权行为为特权威胁异常行为。所述特权账号威胁分析系统包括相互连接的智能威胁审计单元、实时威胁监测单元和统筹配置管理单元;所述智能威胁审计单元用于将关于账号威胁事件详细信息进行分析,以及对账号威胁事件数据进行汇总,并通过图表结合控制面板进行展示;所述实时威胁监测单元用于展现监测到的账号威胁活动,设置账号威胁规则条件,以及在账号威胁规则条件触发后自动响应与发出预警记录;所述统筹配置管理单元用于实现所述特权账号威胁分析系统中重要系统配置的管理。但是该方法使用的是监督式的机器学习算法,使用的机器学习模型要求特权账号行为数据具有很强的线性关系,现实中特权账号的很多行为数据之间并不存在线性关系,所以该模型一旦面对大规模复杂且无线性规律的训练样本将难以实施,得出的数据也不准确,存在很高的误报率。
4.现有技术至少存在以下不足:
5.1.传统系统针对特权威胁异常行为绝大多数是通过人工方式实现,凭借人工个人
经验提供固化的简单逻辑条件进行检测,这种方法仅适用于特权账号较少的应用场景,在特权账号多且复杂工控互联网,这种方法并不适用,不仅需要投入大量的人力成本,还容易产生大量误报或者漏报情况,对企业正常经营生产极为不利。
6.2.现有的发现特权账号威胁行为的方法要求特权账号行为数据特征需要存在强线性关系,但现实中特权账号的很多行为数据特征之间几乎不存在线性关系,故使用该种方法得出的数据是不准确的,误报率很高。
7.3.现有的方法不能很好的处理大量多类特征或变量多的复杂情况下的特权账号威胁行为问题。
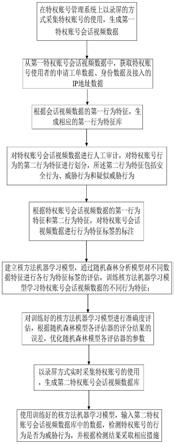
技术实现要素:
8.为解决现有技术中存在的技术问题,本发明提供了一种特权账号异常行为分析方法,采集特权账号的会话视频数据并进行预处理;将预处理后的会话视频数据进行标注划分,对标注后的会话视频进行审计处理;针对不同特征可形成不同的特征行为预测分类树;将每棵分类树根据训练数据集中的引导样本独立增长到最大大小并形成分类树;将形成的各个分类树进行集成,并用测试集进行模型测试;根据分类树的投票多少判定分类结果;将会话视频导入异常行为预测随机森林模型,通过分类树投票得到行为预测结果。通过对特权行为的会话视频等数据的人工神经与分析系统检测相结合,通过对特权行为的会话视频等数据进行机器学习,使得检测结果更准确。
9.本发明提供了一种特权账号异常行为分析方法,包括如下步骤:
10.s100:在特权账号管理系统上以录屏的方式采集特权账号的使用,生成第一特权账号会话视频数据;
11.s200:从第一特权账号会话视频数据中,获取特权账号使用者的申请工单数据、身份数据及接入的ip地址数据;
12.s300:根据会话视频数据的第一行为特征,生成相应的第一行为特征库;
13.所述第一行为特征包括使用原因、使用者身份、使用者的ip地址、特权账号的操作日期和时间、特权账号类型、操作的数据对象、数据修改前后的值;
14.所述第一行为特征库,包括:使用原因数据库a、身份数据库b和使用者的ip地址数据库c、特权账号的操作日期和时间数据库d、特权账号类型数据库e、操作的数据对象数据库f和修改前后数据值数据库g;
15.s400:对特权账号会话视频数据进行人工审计,对特权账号行为的第二行为特征进行划分,所述第二行为特征包括安全行为、威胁行为和疑似威胁行为;
16.s500:根据特权账号会话视频数据的第一行为特征和第二行为特征,对特权账号会话视频数据进行行为特征标签的标注;
17.s600:建立核方法机器学习模型,通过随机森林分析模型对不同数据特征进行各行为特征标签的评估,训练核方法机器学习模型学习特权账号会话视频数据的不同行为特征;
18.s700:对训练好的核方法机器学习模型进行准确度评估,根据随机森林模型各评估器的评分结果的误差,优化随机森林模型各评估器的参数;
19.s800:以录屏方式实时采集特权账号的使用,生成第二特权账号会话视频数据库;
20.s900:使用训练好的核方法机器学习模型,输入第二特权账号会话视频数据库中的数据,检测特权账号的行为是否为威胁行为。
21.优选地,步骤s600中对核方法机器学习模型的训练包括如下步骤:
22.s601:导入第一行为特征库和随机森林分类模型模块;
23.s602:对第一行为特征库进行数据预处理,进行格式转换及缺失值处理;
24.s603:对第一行为特征库的各特征数据库中的数据进行划分,将一部分数据作为训练样本集,用于对核方法机器学习模型的训练;将另一部分数据作为测试样本集,用于对特权账号的行为进行测试;
25.s604:使用scikit
‑
learn工具包将各特征数据库中的训练样本集数据导入随机森林分类模型中对应于各行为特征的评估器类,分别对随机森林分类模型各评估器的核方法机器学习模型进行训练,直到各评估器对各自特征的检测结果与第一行为特征库中该特征的真实特征一致。
26.s605:分别获取各特征数据库的行为特征相关性特征矩阵和目标数组,确定各评估器的权重;
27.s606:根据确定的各评估器的权重及各评估器的评估结果,得到第一行为特征库的检测结果,并重复步骤s604到步骤s606,直到特征检测结果与第一行为特征库的真实特征一致,得到训练好的核方法机器学习模型。
28.优选地,随机森林模型的特征评估结果通过如下方法获得:
29.使用sort voting算法获取各评估器对特征行为预测的准确率;
30.通过各第一行为特征对特权行为的重要性分配各评估器的权重weights;
31.根据各评估器的权重参数weights及各评估器的预测概率得到整个随机森林的预测结果。
32.优选地,随机森林模型初始化参数为默认超参数,使用第一行为特征所包含的特征数个决策树,最多允许5层判别进行训练。
33.优选地,步骤s602中的预处理包括如下步骤:
34.s6021:剔除特殊的异常数据,统一数据格式,对于缺失值统一使用0补充;
35.s6022:使用one
‑
hot encoding的方式对第一行为特征库中的各特征数据库中的数据进行处理,将其全部转化为数字形式。
36.优选地,步骤s700中对训练好的机器学习模型中随机森林模型的优化包括如下步骤:
37.s701:将测试集数据导入到训练好的核方法机器学习模型中随机森林模型的各评估器,分别计算各评估器的绝对误差和平均绝对误差(mae),获取绝对百分比误差(mape);
[0038][0039]
其中:
[0040]
f
i
为预测值;
[0041]
y
i
为真实值;
[0042]
mape=mae*100%
ꢀꢀ
(2)
[0043]
s702:根据平均绝对误差mae调整随机森林模型各评估器的参数,直到预测值与实
际值的平均绝对误差mae在预设范围内。
[0044]
优选地,步骤s702中,调整随机森林模型各评估器的参数,具体包括如下步骤:
[0045]
s7021:根据各行为特征的真实值和预测值绘制特征矩阵图像,调整参数n_estimators和子树值,使该评估器的泛化误差达到预设最低点;
[0046]
s7022:调整max_depth的参数,使该评估器的泛化误差达到预设最低点;
[0047]
s7023:在得两个参数n_estimators,max_depth的最优解情况下,对参数max_features进行调整,当当前得分比初始得分提升的比例小于预设阈值时,随机森林模型的该评估器优化结束。
[0048]
优选地,步骤s900包括:
[0049]
s901:将特权账号会话视频数据库中的数据生成第一行为特征库,并进行特征标签的标注;
[0050]
s902:导入训练好的核方法机器学习模型和随机森林模型各评估器,检测该特权账号的行为;
[0051]
s903:使用transform方法对检测结果进行二维图像转换,通过图像的相关性特征判断特权账号行为是否存在异常;
[0052]
s904:若检测结果为特权账号行为存在异常或疑似异常,且概率大于90%,则自动报警,并终止特权账号的会话操作;否则,若检测结果为无异常,则将该数据作为训练样本对机器学习模型进行进一步优化。
[0053]
优选地,在步骤s602和步骤s603中间,还包括步骤s6030,对第一行为特征库中的各特征数据库中的数据进行第二次分类。
[0054]
优选地,步骤s6030的第二次分类包括:
[0055]
按ipv6的地址格式对ip地址进行分类,包括:单播地址,任播地址,组播地址;
[0056]
s6034:对操作时间数据库d的训练样本集进行第二次分类,按年份划分包括:2018年、2019年、2020年和202x年;
[0057]
s6035:对特权账号类型数据库e的训练样本集第二次分类,包括:主机、数据库、服务器、网络设备和web应用;
[0058]
s6036:对操作的数据对象数据库f的训练样本集第二次分类,包括:企业用户、应用程序和脚本工具;
[0059]
s6037:对数据修改前后的值数据库g的训练样本集进行第二次分类,包括:历史记录和会话日志。
[0060]
与现有技术相对比,本发明的有益效果如下:
[0061]
1.本发明是基于特权账号管理平台采集特权账号的行为数据,获取的训练集样本更具有真实性,通过对特权行为会话视频等数据进行机器学习,使得检测结果更准确。
[0062]
2.本发明对特权账号的会话视频等数据进行7个行为数据进行特征提取,再进一步的进行随机森林的机器学习模型,该种方法是从高维度对大量数据进行分类,并投票得出最终结果;该种方法允许特征数据之间不存在线性关系,符合现实中工控互联网的特权账号行为数据量大,且行为数据复杂非线性关系较多的特点,进一步提升检测结果的准确性,同时会提升检测的效率。
[0063]
3.本发明提供的特权账号异常行为分析方法,可根据实际需求增加特权账号的行
为特征,使用的特权账号行为特征越多,训练的模型越真实,得出的结果越准确。
附图说明
[0064]
图1是本发明特权威胁异常行为分析方法总体流程图;
[0065]
图2是本发明中对核方法机器学习模型的训练流程图;
[0066]
图3是本发明中调整随机森林模型各评估器的参数的流程图;
[0067]
图4是本发明中获取随机森林模型的特征评估结果的流程图;
[0068]
图5a
‑
1是本发明一个实施例中核方法的机器学习模型训练过程中获取的与使用原因相关的特征矩阵,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数据中与使用原因特征相关的实际数据;
[0069]
图5a
‑
2是本发明一个实施例中核方法的机器学习模型训练过程中获取的目标数组展示的与使用原因特征相关性的关系示意图,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数据中与使用原因特征相关的实际数据;
[0070]
图5b
‑
1是本发明一个实施例中核方法的机器学习模型训练过程中获取的与使用者身份相关的特征矩阵,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数据中与使用者身份特征相关的实际数据;
[0071]
图5b
‑
2是本发明一个实施例中核方法的机器学习模型训练过程中获取的目标数组展示的与使用者身份相关性的关系示意图,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数据中与使用者身份特征相关的实际数据;
[0072]
图5c
‑
1是本发明一个实施例中核方法的机器学习模型训练过程中获取的与使用者的ip地址相关的特征矩阵,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数据中与使用者的ip地址特征相关的实际数据;
[0073]
图5c
‑
2是本发明一个实施例中核方法的机器学习模型训练过程中获取的目标数组展示的与使用者的ip地址相关性的关系示意图,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数据中与使用者的ip地址特征相关的实际数据;
[0074]
图5d
‑
1是本发明一个实施例中核方法的机器学习模型训练过程中获取的与特权账号的操作日期和时间相关的特征矩阵,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数据中与特权账号的操作日期和时间特征相关的实际数据;
[0075]
图5d
‑
2是本发明一个实施例中核方法的机器学习模型训练过程中获取的目标数组展示的与特权账号的操作日期和时间相关性的关系示意图,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数据中与特权账号的操作日期和时间特征相关的实际数据;
[0076]
图5e
‑
1是本发明一个实施例中核方法的机器学习模型训练过程中获取的与特权账号类型相关的特征矩阵,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数据中与特权账号类型特征相关的实际数据;
[0077]
图5e
‑
2是本发明一个实施例中核方法的机器学习模型训练过程中获取的目标数组展示的与特权账号类型相关性的关系示意图,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数据中与特权账号类型特征相关的实际数据;
[0078]
图5f
‑
1是本发明一个实施例中核方法的机器学习模型训练过程中获取的与操作的数据对象相关的特征矩阵,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数
据中与操作的数据对象特征相关的实际数据;
[0079]
图5f
‑
2是本发明一个实施例中核方法的机器学习模型训练过程中获取的目标数组展示的与操作的数据对象相关性的关系示意图,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数据中与操作的数据对象特征相关的实际数据;
[0080]
图5g
‑
1是本发明一个实施例中核方法的机器学习模型训练过程中获取的与修改前后数据值相关的特征矩阵,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数据中与修改前后数据值特征相关的实际数据;
[0081]
图5g
‑
2是本发明一个实施例中核方法的机器学习模型训练过程中获取的目标数组展示的与修改前后数据值相关性的关系示意图,x轴是特权账号的各次行为数据,y轴是各次特权账号行为数据中与修改前后数据值特征相关的实际数据。
具体实施方式
[0082]
本发明提供了一种特权账号异常行为分析方法,包括如下步骤:
[0083]
s100:在特权账号管理系统上以录屏的方式采集特权账号的使用,生成第一特权账号会话视频数据;
[0084]
s200:从第一特权账号会话视频数据中,获取特权账号使用者的申请工单数据、身份数据及接入的ip地址数据;
[0085]
s300:根据会话视频数据的第一行为特征,生成相应的第一行为特征库;
[0086]
所述第一行为特征包括使用原因、使用者身份、使用者的ip地址、特权账号的操作日期和时间、特权账号类型、操作的数据对象、数据修改前后的值;
[0087]
所述第一行为特征库,包括:使用原因数据库a、身份数据库b和使用者的ip地址数据库c、特权账号的操作日期和时间数据库d、特权账号类型数据库e、操作的数据对象数据库f和修改前后数据值数据库g;
[0088]
s400:对特权账号会话视频数据进行人工审计,对特权账号行为的第二行为特征进行划分,所述第二行为特征包括安全行为、威胁行为和疑似威胁行为;
[0089]
s500:根据特权账号会话视频数据的第一行为特征和第二行为特征,对特权账号会话视频数据进行行为特征标签的标注;
[0090]
s600:建立核方法机器学习模型,通过随机森林分析模型对不同数据特征进行各行为特征标签的评估,训练核方法机器学习模型学习特权账号会话视频数据的不同行为特征,并对训练好的核方法机器学习模型进行准确度评估,根据随机森林模型各评估器的评分结果的误差,优化随机森林模型各评估器的参数;
[0091]
s700:以录屏方式实时采集特权账号的使用,生成第二特权账号会话视频数据库;
[0092]
s900:使用训练好的核方法机器学习模型,输入第二特权账号会话视频数据库中的数据,检测特权账号的行为是否为威胁行为。
[0093]
作为优选实施方式,步骤s600中对核方法机器学习模型的训练包括如下步骤:
[0094]
s601:导入第一行为特征库和随机森林分类模型模块;
[0095]
s602:对第一行为特征库进行数据预处理,进行格式转换及缺失值处理;
[0096]
s603:对第一行为特征库的各特征数据库中的数据进行划分,将90%的数据作为训练样本集,用于对核方法机器学习模型的训练;将10%的数据作为测试样本集,用于对特
权账号的行为进行测试;
[0097]
s604:使用scikit
‑
learn工具包将各特征数据库中的训练样本集数据导入随机森林分类模型中对应于各行为特征的评估器类,分别对随机森林分类模型各评估器的核方法机器学习模型进行训练,直到各评估器对各自特征的检测结果与第一行为特征库中该特征的真实特征一致。
[0098]
s605:分别获取各特征数据库的行为特征相关性特征矩阵和目标数组,确定各评估器的权重;
[0099]
特征矩阵是通过二维图表将特征相关性清晰地表达出来,目标数组则是通过一维图表表示;特征矩阵通常被简记为变量x,目标数组的特征是从数据中预测的量化结果,即y是统计学中的因变量。
[0100]
将数据导入到评估器类中,则可针对不同的特征生成类似图5a
‑
1到图5g
‑
2的图表,更加便于观测xy之间的关系;抽取特殊矩阵和目标数组(能形成明显关系的数据组),整理获得其x,y的值,将数据x整理成[n_samples,n_features]的形式;
[0101]
s606:根据确定的各评估器的权重及各评估器的评估结果,得到第一行为特征库的检测结果,并重复步骤s604到步骤s606,直到特征检测结果与第一行为特征库的真实特征一致,得到训练好的核方法机器学习模型。
[0102]
作为优选实施方式,随机森林模型的特征评估结果通过如下方法获得:
[0103]
使用sort voting算法获取各评估器对特征行为预测的准确率;
[0104]
通过各第一行为特征对特权行为的重要性分配各评估器的权重weights;
[0105]
根据各评估器的权重参数weights及各评估器的预测概率得到整个随机森林的预测结果。
[0106]
作为优选实施方式,随机森林模型初始化参数为默认超参数,使用第一行为特征所包含的特征数个决策树,最多允许5层判别进行训练。
[0107]
作为优选实施方式,步骤s602中的预处理包括如下步骤:
[0108]
s6021:剔除特殊的异常数据,统一数据格式,对于缺失值统一使用0补充;
[0109]
s6022:使用one
‑
hot encoding的方式对第一行为特征库中的各特征数据库中的数据进行处理,将其全部转化为数字形式。
[0110]
作为优选实施方式,步骤s600中对训练好的机器学习模型中随机森林模型的优化包括如下步骤:
[0111]
s701:将测试集数据导入到训练好的核方法机器学习模型中随机森林模型的各评估器,分别计算各评估器的绝对误差和平均绝对误差(mae),获取绝对百分比误差(mape);
[0112][0113]
其中:
[0114]
f
i
为预测值;
[0115]
y
i
为真实值;
[0116]
mape=mae*100%
ꢀꢀ
(2)
[0117]
s702:根据平均绝对误差mae调整随机森林模型各评估器的参数,直到预测值与实际值的平均绝对误差mae在预设范围内。
[0118]
作为优选实施方式,步骤s702中,调整随机森林模型各评估器的参数,具体包括如下步骤:
[0119]
s7021:根据各行为特征的真实值和预测值绘制特征矩阵图像,调整参数n_estimators和子树值,使该评估器的泛化误差达到预设最低点;
[0120]
根据特征值和预测值;在机器学习中,用来衡量模型在未知数据上的准确率的指标,叫做泛化误差;图像是建模情况的一个直观反映,泛化误差受到模型的复杂度影响。当模型太复杂,模型就会过拟合,泛化能力就不够,所以泛化误差大。当模型太简单,模型就会欠拟合,拟合能力就不够,所以误差也会大。只有当模型的复杂度刚刚好(能形成明确的函数关系,如一次函数等)的才能够达到泛化误差最小的目标。
[0121]
泛化误差=偏差+方差+噪声;
[0122]
偏差:度量了模型的期望预测和真实结果的偏离程度;
[0123]
方差:度量了同样大小的训练集的变动所导致的学习性能的变化;
[0124]
噪声:表达了当前任务上任何模型所能达到的期望值下界;
[0125]
欠拟合:原因偏差过高,训练不足,偏差主导泛化误差;
[0126]
解决方法:加深迭代次数;加多特征;降低正则化;
[0127]
过拟合:原因方差过高,训练过多,方差主导泛化误差;
[0128]
解决方案:降低模型复杂度,加训练集,减特征,提高正则化;
[0129]
s7022:调整max_depth的参数,使该评估器的泛化误差达到预设最低点;
[0130]
s7023:在得两个参数n_estimators,max_depth的最优解情况下,对参数max_features进行调整,当当前得分比初始得分提升的比例小于预设阈值时,随机森林模型的该评估器优化结束。
[0131]
作为优选实施方式,步骤s900包括:
[0132]
s901:将特权账号会话视频数据库中的数据生成第一行为特征库,并进行特征标签的标注;
[0133]
s902:导入训练好的核方法机器学习模型和随机森林模型各评估器,检测该特权账号的行为;
[0134]
s903:使用transform方法对检测结果进行二维图像转换,通过图像的相关性特征判断特权账号行为是否存在异常;
[0135]
s904:若检测结果为特权账号行为存在异常或疑似异常,且概率大于90%,则自动报警,并终止特权账号的会话操作;否则,若检测结果为无异常,则将该数据作为训练样本对机器学习模型进行进一步优化。
[0136]
作为优选实施方式,在步骤s602和步骤s603中间,还包括步骤s6030,对第一行为特征库中的各特征数据库中的数据进行第二次分类。
[0137]
作为优选实施方式,步骤s6030的第二次分类包括:
[0138]
按ipv6的地址格式对ip地址进行分类,包括:单播地址,任播地址,组播地址;
[0139]
单播地址:一个单播地址对应一个接口,发往单播地址的数据包会被对应的接口接收;
[0140]
任播地址:一个任播地址对应一组接口,发往任播地址的数据包会被这组接口的其中一个接收,被哪个接口接收由具体的路由协议确定;
[0141]
组播地址:一个组播地址对应一组接口,发往组播地址的数据包会被这组的所有接口接收;
[0142]
s6034:对操作时间数据库d的训练样本集进行第二次分类,按年份划分包括:2018年、2019年、2020年和202x年;
[0143]
s6035:对特权账号类型数据库e的训练样本集第二次分类,包括:主机、数据库、服务器、网络设备和web应用;
[0144]
s6036:对操作的数据对象数据库f的训练样本集第二次分类,包括:企业用户、应用程序和脚本工具;
[0145]
s6037:对数据修改前后的值数据库g的训练样本集进行第二次分类,包括:历史记录和会话日志
[0146]
实施例1
[0147]
参照附图1
‑
5,根据本发明的一个具体实施方案,对本发明提供的特权威胁异常行为分析方法进行详细说明。
[0148]
本发明提供了一种特权威胁异常行为分析方法,包括以下步骤:
[0149]
实例背景:针对某公司2018
‑
2020年间财务部门的特权账号采用上述方法进行训练,并对最新的特权账号行为进行自动检测,判断特权账号是否存在异常。
[0150]
最新的特权账号行为公司的财会人员于1月1日要登录公司的采购系统对一笔采购工业材料账款进行核对,并支付该笔账款。
[0151]
s100:在特权账号管理系统上以录屏的方式采集2018
‑
2020年财务部门的特权账号的使用,生成第一特权账号会话视频数据;
[0152]
s200:从第一特权账号会话视频数据中,获取特权账号使用者的申请工单数据、身份数据及接入的ip地址数据;
[0153]
s300:根据会话视频数据的第一行为特征,生成相应的第一行为特征库;
[0154]
所述第一行为特征包括使用原因、使用者身份、使用者的ip地址、特权账号的操作日期和时间、特权账号类型、操作的数据对象、数据修改前后的值;
[0155]
所述第一行为特征库,包括:使用原因数据库a、身份数据库b和使用者的ip地址数据库c、特权账号的操作日期和时间数据库d、特权账号类型数据库e、操作的数据对象数据库f和修改前后数据值数据库g;
[0156]
s400:对财务部的特权账号会话视频数据进行人工审计,对特权账号行为的第二行为特征进行划分,所述第二行为特征包括安全行为、威胁行为和疑似威胁行为;
[0157]
s500:根据特权账号会话视频数据的第一行为特征和第二行为特征,对财务部的特权账号会话视频数据进行行为特征标签的标注;
[0158]
s600:建立核方法机器学习模型,通过随机森林分析模型对不同数据特征进行各行为特征标签的评估;
[0159]
s601:导入第一行为特征库和随机森林分类模型模块;
[0160]
s602:对第一行为特征库进行数据预处理,剔除特殊的异常数据,统一数据格式,对于缺失值统一使用0补充,使用one
‑
hot encoding的方式对第一行为特征库中的各特征数据库中的数据进行处理,将其全部转化为数字形式。
[0161]
s6031:将身份数据库a的训练样本集进行第二次分类,包括:财务总监,财务主管,
审计主管,会计专员,审计专员,出纳专员;
[0162]
s6032:对使用原因数据库b的训练样本集进行第二次分类,包括:查询财务数据,审计财务报表,修改财务报表,完成付款;
[0163]
s6033:对ip地址数据库c的训练样本集进行第二次分类,包括:单播地址,任播地址,组播地址;
[0164]
s6034:对操作时间数据库d的训练样本集进行第二次分类,包括:2018年,2019年,2020年;
[0165]
s6035:对特权账号类型数据库e的训练样本集第二次分类,包括:oa系统,金蝶财务系统,erp进销存系统,支付系统;
[0166]
s6036:对操作的数据对象数据库f的训练样本集第二次分类,包括:公司内员工,应用程序,脚本工具;
[0167]
s6037:对数据修改前后的值数据库g的训练样本集进行第二次分类,包括:历史记录,会话日志
[0168]
s6038:对第一行为特征库的各特征数据库中的数据进行划分,将以上90%的数据作为训练样本集,用于对核方法机器学习模型的训练;剩下的10%的数据作为测试样本集,用于对特权账号的行为进行测试;
[0169]
s604:使用scikit
‑
learn工具包将上述特征数据库中的训练样本集数据导入随机森林分类模型中对应于各行为特征的评估器类,分别对随机森林分类模型各评估器的核方法机器学习模型进行训练
[0170]
s605:分别获取上述各特征数据库的行为特征相关性特征矩阵和目标数组,各特征矩阵和目标数组均并没有呈现出明显的相关性关系,故将各评估器的权重占比为1:1:1:1:1:1:1;
[0171]
s606:使用sort voting算法获取各评估器对对上述各特征行为预测的准确率;
[0172]
计算各个评估器准确率的平均值;根据评估器的权重比,将参数weights的值默认为0,收集各评估器的预测概率,乘以各评估器权重,然后取平均概率;取最高平均概率评估器对应的特征作为最终的特征评估结果。
[0173]
使用第一行为特征所包含的特征数个决策树,最多允许5层判别进行训练;重复步骤s604到步骤s606多次,得到的特征检测结果没有变化,且与第一行为特征库的真实特征一致,确定特征的权重比及参数weight的值为0,此时初步得到训练好的学习模型。
[0174]
s607:将剩下10%的作为测试集的数据导入到训练好的核方法机器学习模型中随机森林模型的各评估器,分别各评估器的绝对误差和平均绝对误差(mae),获取绝对百分比误差(mape);
[0175][0176]
其中:
[0177]
f
i
为预测值;
[0178]
y
i
为真实值;
[0179]
mape=mae*100%
ꢀꢀ
(2)
[0180]
s608:将测试集数据导入到训练好的核方法机器学习模型中随机森林模型的各评
估器,分别各评估器的绝对误差和平均绝对误差(mae),获取绝对百分比误差(mape);
[0181]
s609:参考往常的建模案例,将参数设置值如下:
[0182]
n_estimators=200,max_depth=8,random_state=37
[0183]
得到:准确率:89.19%、mae:0.8849、mape:88.49%
[0184]
根据平均绝对误差mae调整随机森林模型各评估器的参数,直到预测值与实际值的平均绝对误差mae在预设范围内。
[0185]
s610:绘制特征矩阵图像,调整参数n_estimators为100和50,其他参数不变时,发现准确率有明显上升,在50的时候达到一个峰值;将参数n_estimators设置为45,50,60,其他不变,结果发现在50的时候,准确率为最高为95.34%、mae:0.9512、mape:95.12%,,故确定参数n_estimators值为50;
[0186]
s611:在s610的基础上调整max_depth的参数,将max_depth设置为10,5,3,发现准确率在10,8,5这几个点处的结果几乎一样,故确定最优的max_depth参数的取值为5;
[0187]
s612:在s612的max_depth最优解的情况下,对参数max_features进行调整,将max_features的参数设为auto(默认该参数等于特征数=7),输出结果为准确率为95.95%、mae:0.9584、mape:95.84%,比初始得分提升的比例小于预设阈值1时,即继续调整参数值则输出的准确率上升不超过1%;此时,随机森林模型的该评估器优化结束。
[0188]
s613:导入训练好的核方法机器学习模型和随机森林模型各评估器,检测该特权账号的行为;
[0189]
s700:以录屏方式实时采集特权账号的使用,生成第二特权账号会话视频数据库;财会人员提交申请工单登录进入到特权账号系统,后台审核授权,此时将获取特权账号的身份者数据a,标记为财务部门人员a1,继续对其分类标记为财务部门经理a11;获取本次财会人员对特权账号的使用原因为查看数据标记为b1,细分原因为查看账款数据标记b11;获取本次财会人员接入的ip地址数据标记为c1,细分进行分类,细分为地址c11;后台审核申请工单无误,授权使用特权账号,后台获取本次特权账号的接入操作时间d1,对时间进行细分为d11;获取特权账号类型,对类型进行细分将财务处理系统标注为e11;获取操作的数据对象为erp管理系统的材料库存数据将其详细标注为f11;财会人员对该笔款项进行了支付,故修改前后的值数据库标注为g11;
[0190]
s800:使用transform方法对检测结果进行二维图像转换,通过图像可发现所有相关性特征均为连续,平稳的图像,没有出现明显的突出和断层,并不存在明显的异常关系;
[0191]
s900:将数据代入到s613中已训练好的机器学习模型中进行计算,a类的投票计算结果为财务部门经理的身份的准确率:95%、mae:0.95、mape:95%,合理;b类的投票计算结果为申请查看账款部门的数据准确率:96%、mae:0.96、mape:96%,合理;c类的投票计算结果为接入的ip地址数据准确率:95%、mae:0.95、mape:95%,合理;d类的投票计算结果为操作时间准确率:94%、mae:0.94、mape:94%,合理;e类的投票计算结果为接入特权账号类型准确率:98%、mae:0.98、mape:98%,特权账号类型与其身份匹配;f类的投票计算结果为准确率:99%、mae:0.99、mape:99%,操作对象合规;g类的投票计算结果为准确率:95%、mae:0.95、mape:95%,修改前后的值数据符合要求,支付的款项合理;最终计算结果为各特征权重比*各特征评估值的加和的平均值,得(95%*1+96%*1+95%*1+94%*1+98%*1+99%*1+95%)/7=96%。
[0192]
最终的特权账号行为合理的投票结果为96%,大于要求的值95%,则该特权行为无异常,则将该数据作为训练样本对机器学习模型进行进一步优化。
[0193]
实施例2
[0194]
本发明提供了一种特权威胁异常行为分析方法,包括以下步骤:
[0195]
实例背景:公司的财会人员于1月1日要登录公司的采购系统对一笔采购工业材料账款进行核对,并支付该笔账款。
[0196]
操作步骤s100
‑
s800同实施例1;
[0197]
s900:将数据代入到已训练好的机器学习模型中进行计算,a类的投票计算结果为财务部门经理的身份的准确率:95%、mae:0.95、mape:95%,合理;b类的投票计算结果为申请查看账款部门的数据准确率:96%、mae:0.96、mape:96%,合理;c类的投票计算结果为接入的ip地址数据准确率:95%、mae:0.95、mape:95%,合理;d类的投票计算结果为操作时间准确率:94%、mae:0.94、mape:94%,合理;e类的投票计算结果为接入特权账号类型准确率:98%、mae:0.98、mape:98%,特权账号类型与其身份匹配;f类的投票计算结果为准确率:99%、mae:0.99、mape:99%,操作对象合规;g类的投票计算结果为准确率:50%、mae:0.50、mape:50%,修改前后的值数据不符合要求,此次支付的款项不符合实际的材料购买款项,不合理;
[0198]
最终的特权账号行为合理的投票结果为各特征权重比*各特征评估值的加和的平均值,得(95%*1+96%*1+95%*1+94%*1+98%*1+99%*1+50%)/7=89.6%。
[0199]
最终的特权账号行为合理的投票结果为89.6%,小于要求的值95%,故本次该特权账号行为存在异常,发现特权威胁异常行为,立刻暂停该特权账号会话并自动报警;审计排查发现可能财会人员输入付款金额时误操作导致的。
[0200]
实施例3
[0201]
本发明提供了一种特权威胁异常行为分析方法,包括以下步骤:
[0202]
实例背景:公司的财会人员于1月1日要登录公司的采购系统对一笔采购工业材料账款进行核对,并支付该笔账款。
[0203]
操作步骤s100
‑
s800同实施例1;
[0204]
s900:将数据代入到已训练好的机器学习模型中进行计算,a类的投票计算结果为财务部门经理的身份的准确率:95%、mae:0.95、mape:95%,合理;b类的投票计算结果为申请查看账款部门的数据准确率:96%、mae:0.96、mape:96%,合理;c类的投票计算结果为接入的ip地址数据准确率:95%、mae:0.95、mape:95%,合理;d类的投票计算结果为操作时间准确率:55%、mae:0.55、mape:55%,操作时间发生在深夜的非办公时间,不合理;e类的投票计算结果为接入特权账号类型准确率:98%、mae:0.98、mape:98%,特权账号类型与其身份匹配;f类的投票计算结果为准确率:99%、mae:0.99、mape:99%,操作对象合规;g类的投票计算结果为准确率:50%、mae:0.50、mape:50%,修改前后的值数据不符合要求,此次支付的款项不符合实际的材料购买款项,不合理;
[0205]
最终的特权账号行为合理的投票结果为各特征权重比*各特征评估值的加和的平均值,得(95%*1+96%*1+95%*1+55%*1+98%*1+99%*1+50%)/7=84%,远小于要求的值95%,故本次该特权账号行为存在异常,发现特权威胁异常行为,立刻暂停该特权账号会话并自动报警;综合审计排查发现财会人员可能私收厂商回扣,蓄意支付错误金额时操作
导致的。
[0206]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1