基于多元线性回归和第三方信用的改进协同过滤方法
1.本发明属于智能推荐算法领域,具体是基于多元线性回归及第三方信用的改进协同过滤算法。
背景技术:
2.在高速发展的信息时代,如何从海量的数据中挖掘出数据的共性,找出其中潜在的规律,变得越来越重要。改进的协同过滤算法从数据中找出用户的潜在需求并结合互联网的快速发展趋势,可以推广到生活的各个方面。每天清晨想要找到一首喜欢的歌迎接一天的好心情时,协同过滤算法可以帮你;每餐想要找到自己爱吃的食物补充能量时,协同过滤算法可以帮你;吃多了想要运动减肥却又纠结运动装备如何选择时,协同过滤算法也可以帮你。总之,协同过滤算法已经渗透到生活里的方方面面,应用实例数不胜数。
3.但是传统的协同过滤算法存在着很多不足,如:稀疏性矩阵、冷启动问题、用户的信任问题、相似度计算公式的缺陷。如何有效的缓解或者解决传统协同过滤算法的缺陷一直是一大难题,针对这一问题,大量学者提出了一些解决方案。姚劲勃、余宜诚等人提出利用pca降维的方式,改善稀疏性矩阵的问题;于金明、孟军等人提出的相似性度量方法,有效的改善了系统存在的冷启动等问题;王博生、何先波等人提出的多重相似度融合,有效缓解了数据稀疏性和冷启动问题;但是在这些问题里,基于第三方的信任度等多种信息的融合考虑常常被人忽略。在这种情况下,系统基于虚假信息产生用户推荐,推荐误差变大,理所当然,并且对其他用户也会产生或多或少的影响。这必然是对系统推荐算法的一大挑战,将第三方个人信用的信任度加入到考虑因素可以有效地解决这些问题。基于多元线性回归及第三方信用改进协同过滤算法的优点是通过物品的属性特征、用户的信用值等信息,通过将上述字段量化后,建立了评分值与上述各种信息的多元线性回归方程,求出了用户的喜爱向量,有效的解决了稀疏性矩阵问题,再利用欧式距离去求出目标用户的邻居用户,最后利用推荐公式对用户推荐。
技术实现要素:
4.处于大数据时代,系统中处理用户的信息规模可以达到亿数量级,与此同时,大量的用户和项目必然会导致用户项目矩阵高度稀疏,这给推荐系统带来了巨大的挑战。针对系统中用户项目稀疏矩阵的问题,本发明的目的在于提供一种基于多元线性回归及第三方信用机构的改进的推荐算法。
5.本文所述的改进的推荐算法是一种融合了过去某个项目被用户产生行为的地点、第三方机构对用户的信用值及项目的属性特征等信息的推荐算法,该算法主要解决了用户项目稀疏矩阵、恶意用户评分等问题。所述方法包括如下步骤:
6.(1)构建基于第三方个人或信用机构的加权信用模型。
7.(2)根据系统中项目的特征及前面两步骤得到的信用构建与用户关联的项目特征向量:
8.nati=(nat
i1
,nat
i2
,...,nat
ij
,...,nat
in
)
9.(3)根据第二步骤得到的nati向量及系统中用户对项目的评分,对于每一个用户构建多元线性回归方程。
10.yi=b0+b1x1+b2x2+...+bnxn+μi11.(4)根据第三步骤的多元线性回归方程,求出每个用户综合多源信息的评分向量。
12.useri=(y
i1
,y
i2
,...,y
ij
,...,y
in
)
13.(5)用第四步骤求到的向量来表征用户的喜爱,根据这个向量利用欧式距离计算目标用户与其他用户的距离,再用如下公式计算目标用户与其他用户的相似度,基于knn的思想,选取与目标用户最相似的n个用户作为目标用户的邻居。
[0014][0015]
(6)根据第五步骤求到的用户相似度,利用推荐公式,对用户产生推荐。
[0016][0017]
步骤一所述的构建基于第三方机构的加权信用模型具体如下:
[0018]
用户的信用是值得考虑的一部分。在网上往往会存在有些用户不愿意打真实评分或者恶意刷评分的现象,造成了很多数据存在着一定的虚假性。因此引入第三方信任机构的概念。假设有m个第三方信任机构ca,n个用户user以及每个机构对每个用户的信用值矩阵,具体表示为:
[0019]
ca={ca1,ca2,...,cai,...,cam}
[0020]
user=(user1,user2,...,useri,...,usern)
[0021][0022]
首先,针对第三方信任机构的可信度根据已知的官方数据给第三方信任机构 ca进行降序排列,排序好的第三方信任机构aca及每个排序好的机构对每个用户的信用值矩阵为:
[0023]
aca={aca1,aca2,...,acai,...,acam}
[0024][0025]
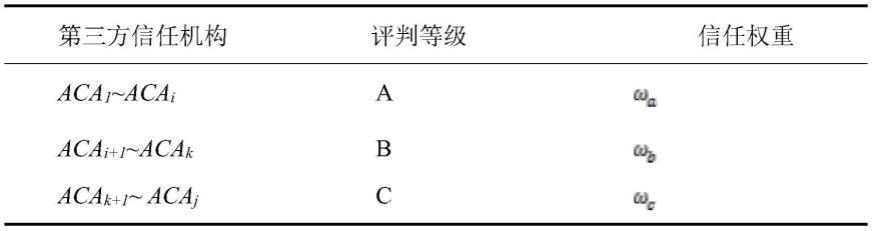
接着,根据排序好的第三方信任机构aca进行划分等级,具体划分情况如下表所示:
[0026][0027]
最后,为了得到用户的综合信用度ccre,可以根据等级来分情况讨论:对于同一等级的信任机构,利用求切尾均值/去尾平均数的方法得到处理后的综合信用度,具体公式如下:
[0028][0029]
其中c代表某一评判等级含有的第三方信任机构的数量,m代表行,q代表n个用户,max代表当前评判等级中最认可的第三方信任机构,min代表当前评判等级中认可度排名最后的第三方信任机构。
[0030]
经过上面的变换后,信用值矩阵可用下式来表示:
[0031][0032]
对于不同等级的信任机构,通过根据前面的信任权重来得到用户综合信用度,具体表示如下:
[0033][0034]
其中的credit
tac
(m,n)表示信用值矩阵的转置,通过上面公式就可以得到一个 n
×
1的基于第三方信任机构的用户综合信用度。
[0035]
步骤二所述的nat向量,它是由项目的本身的属性、第三方个人或机构的综合信用度组成的。每一个用户所评分的每一样物品都会有一个nat向量,那么如果该用户参与评分了m个物品,就会有m个对应的nat向量。假设nat向量规定共有n个字段,若某物品不具备某个字段,则通常令这个字段值为0;如果有某个项目本身的属性字段,就根据多元线性回归方程回归方程的系数来得到该字段的值,另外用户的综合信用值、地域及季节信息是每个向量都有的,其中地域取值用邮政编码代替,季节的取值如下面的表格所示:
[0036][0037]
根据这些向量和已知的评分值可以方便后面建立评分值与nat向量中每个字段的多元线性回归方程。
[0038]
步骤三所述的对于每一个用户构建多元线性回归方程,具体如下:
[0039]
基于步骤三所述的与用户关联的项目特征向量nat向量,根据用户对应的nat向量和评分值,为每一个用户建立评分值与nat向量中每个字段的多元线性回归方程。具体公式如下所示:
[0040]
yi=b0+b1nat
i1
+b2nat
i2
+...+bnnat
in
+μi[0041]
其中bn代表了第n个对评分值y产生影响的因素,b0代表了常数项,μi代表了随机误差,yi代表对于给定的nat向量通过回归方程得到的第i个用户的评分值。
[0042]
通过这个公式求得多元线性回归方程的系数之后,接着就可以求用户的喜爱向量,并使用用户的喜爱向量代替用户项目矩阵,来解决矩阵稀疏性问题。假设用户的喜爱向量为preference,它的具体表示如下所示:
[0043]
preferencei=(b
i0
+b
i1
+μ
i1
,b
i0
+b
i2
+μ
i2
,...,b
i0
+b
in
+μ
in
)
[0044]
其中的preferencei代表了第i个用户的喜爱向量,另外的变量前文已经提及,这里就不再赘述。
[0045]
步骤四所述的利用欧式距离法计算目标用户的邻居用户,它的具体步骤如下:
[0046]
欧式距离方法计算比较简单,而且结果也更加精准,它是一个常用的距离定义。它的思想是:在m维空间中,将当前用户与目标用户的喜爱向量相减,若最终值distance(m,n)越小,则说明当前用户与目标用户的物品偏好越相似。;反之,就说明这两个用户物品偏好越不相似。它的计算公式如下:
[0047][0048][0049]
其中x
mn
代表用户m的第n个属性,k代表了总共有k个用户,distance(m,n) 代表第m个用户与第n个用户的距离,sim(m,n)代表第m个用户对第n个用户的相似度。
[0050]
结合sim(m,n)的公式,计算出每个用户之间的偏爱相似度,从而构建出用户喜爱的相似度矩阵,具体公式如下所示:
[0051][0052]
计算得到相似矩阵之后,为了减少不必要的计算,基于knn的思想,可以取sim相似度矩阵的每一行前m个最大的值,代入到后面的推荐公式中,以便得到最后的结果。
[0053]
步骤五所述的对用户产生推荐,具体推荐方式如下:
[0054]
通过步骤五得到相似度矩阵之后我们就可以再根据推荐公式给出用户推荐结果,具体的推荐公式如下:
[0055][0056]
其中的r
ij
代表在评分-项目矩阵中用户i对物品j的打分,sim(m,i)是两个用户m,i之间喜好的相近程度,代表当前用户m对它历史参与的任何项目的平均打分,代表了当前用户i对它历史参与的任何项目的平均打分,k代表选取 k个与用户m较高喜爱相似度的用户,pre(m,j)代表用户m对项目j的预测得分。
附图说明
[0057]
图1为基于多元线性回归及第三方信用的改进协同过滤算法的流程图。
[0058]
图2为基于第三方个人的加权信用模型后得到的用户综合信用值。
[0059]
图3为20个用户中每个用户与其相似度最高的前3个用户的相似值。
[0060]
图4为每个用户根据基于多元线性回归及第三方信用的改进协同过滤算法得到的对没参加评分的项目的预测得分。
具体实施方式
[0061]
为了更清楚、直观地展示该发明工作的各个步骤,本文使用matlab工具,结合实际案例详细地阐述基于多元线性回归及第三方机构信用的改进协同过滤算法。
[0062]
案例背景是使用基于多元线性回归及第三方信用的改进协同过滤算法根据目标用户的喜好推荐衣服。假设现有3个第三方个人,基于官方的数据,他们的权重分配如下:
[0063]
第三方个人评判等级信任权重ca1a0.6ca2b0.3ca3c0.1
[0064]
第三方个人会给每个用户进行评分,再按照如下公式计算出用户的综合信用值。
[0065]
[0066]
图2的纵坐标是他们的综合综合信用值。得到用户的综合信用值之后,然后根据系统中项目的特征及前面两步骤得到的信用,构建与用户关联的项目特征向量,再根据这些特征向量为每一个用户构建多元线性回归方程,并用求出的系数根据上述公式得到用户的喜爱向量。之后用上述的欧式距离计算用户的相似度,接着构建sim相似度矩阵,再基于knn的思想,取sim相似度矩阵的每一行前m个最大的值,代入到后面的推荐公式中,其中图3表示了取sim相似度矩阵的每一行前3个最大的相似值。得到相似值后,对用户产生推荐,得到推荐的结果,如图4所示。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1