基于改进Ranger的深度学习方法与流程
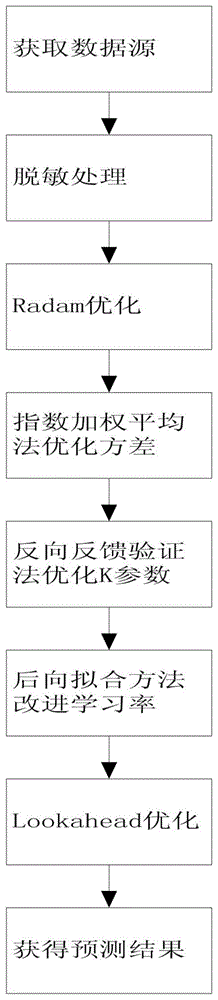
本发明涉及深度学习领域,特别涉及基于改进ranger的深度学习方法。
背景技术:
:销售预测系统运用模型进行数据预测,从而为业务提供技术支持,模型分为机器学习、深度学习、时间序列等。其中深度学习算法是预测算法中的重中之重,随着人工智能的发展,深度学习算法被广泛应用于各个场景。深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像、声音和文本,深度学习是无监督学习的一种。深度学习的概念源于人工神经网络的研究,含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示,基于深信度网(dbn)提出非监督贪心逐层训练算法,为解决深层结构相关的优化难题带来希望,随后提出多层自动编码器深层结构。ranger便是深度学习算法中的一种,它结合了radam算法和lookahead算法。radam的先进之处在于,能根据方差分散度,动态地打开或关闭自适应学习率,提供了一种不需要可调参数学习率预热的方法,它兼具adam和sgd两者的优点,既能保证收敛速度快,也不容易掉入局部最优解。lookahead受到深度神经网络损失表面方面进展的启发,能够稳定深度学习训练和收敛速度。lookahead减少了需要调整的超参数的数量,能以最小的计算开销实现不同深度学习任务的更快收敛。radam算法和lookahead算法从不同的角度着手,各自在深度学习优化上实现了新的突破,具有高度协同性,但是ranger仍存在以下缺点:1、radam算法计算方差的时候容易出现过拟合现象,导致运行结果精度低;2、lookahead算法训练k参数和学习率的时候,计算负担大,内存消耗多。技术实现要素:本发明所解决的技术问题:提供基于改进ranger的深度学习方法解决深度学习在算法训练时精度低、运行时间长和消耗资源多的问题。本发明解决上述技术问题采用的技术方案:基于改进ranger的深度学习方法包括以下步骤:s01、获取数据源;s02、将数据进行预处理;s03、将数据进行radam算法优化,计算梯度,利用指数加权平均方法优化方差,获得方差;s04、用反向反馈验证法改进k参数;利用后向拟合的方法改进学习率;将数据进行lookahead算法优化;s05、输出预测结果。进一步的,步骤s01中,数据源是销售数据。进一步的,步骤s02中,预处理包括脱敏处理、缺失值填充处理、字段类型转换处理、归一化处理和标准化处理中的一种或多种,所述缺失值填充采取就近原则进行填充;所述字段类型转换是将部分字段字符串类型转为浮点类型。进一步的,步骤s03中,优化方差的公式是其中s表示方差,β2是指数加权平均的超参,t表示步数,gi表示第i歩的梯度。进一步的,步骤s04中,反向反馈验证法包括以下步骤:s601、设置学习率a;s602、针对数据按照s601设置的学习率进行迭代运算,获得权重,并备份;s603、从现有权重出发,运行lookahead算法得到k参数,并根据φt+1=a+(1-a)φt+k得到新权重;s604、更新模型权重;s605、查看模型收敛性;s606、获得模型达到最佳收敛时的k。进一步的,步骤s601中,设置初始学习率为一个或多个,步骤s602中,迭代处理是任意单次或多次。进一步的,步骤s04中,后向拟合的方法,包括以下步骤:s901、针对数据进行迭代处理;s902、设置初始学习率a=0.5和k,k的值是反向反馈验证法计算出的k值;s903、运行lookahead算法,查看模型损失函数以及模型拟合情况,拟合优度其中sse表示误差平方和,sst表示回归平方和;s904、改变步骤s902中的初始学习率,找到模型最佳拟合情况,即r2=1或则无限接近1;s905、输出模型最佳拟合情况学习率设置值。进一步的,步骤s901中,迭代处理是任意单次或多次。进一步的,步骤s05中,输出预测结果是一个数据或多个数据。本发明的有益效果:本发明基于改进ranger的深度学习方法通过指数加权平均方法优化radam算法获得方差、反向反馈验证法改进lookahead算法的k参数和后项拟合的方法改进学习率解决了深度学习在算法训练时精度低、运行时间长和消耗资源多的问题,提高深度学习算法的学习速度和效果。附图说明图1是本发明基于改进ranger的深度学习方法的计算过程流程图。具体实施方式本发明提供基于改进ranger的深度学习方法解决了深度学习在算法训练时精度低、运行时间长和消耗资源多的问题,提高深度学习算法的学习速度和效果,包括以下步骤:s01、获取数据源;s02、将数据进行预处理;s03、将数据进行radam算法优化,计算梯度,利用指数加权平均方法优化方差,获得方差;s04、用反向反馈验证法改进k参数;利用后向拟合的方法改进学习率;将数据进行lookahead算法优化;s05、输出预测结果。进一步的,步骤s01中,数据源是销售数据。进一步的,步骤s02中,预处理包括脱敏处理、缺失值填充处理、字段类型转换处理、归一化处理和标准化处理中的一种或多种,所述缺失值填充采取就近原则进行填充;所述字段类型转换是将部分字段字符串类型转为浮点类型。进一步的,步骤s03中,优化方差的公式是其中s表示方差,β2是指数加权平均的超参,t表示步数,gi表示第i歩的梯度。这里能够加速深度学习收敛速度,同时不会出现过拟合现象,能够使深度学习用最短的时间完成运算操作。进一步的,步骤s04中,反向反馈验证法包括以下步骤:s601、设置学习率a;s602、针对数据按照s601设置的学习率进行迭代运算,获得权重,并备份;s603、从现有权重出发,运行lookahead算法得到k参数,并根据φt+1=a+(1-a)φt+k得到新权重;s604、更新模型权重;s605、查看模型收敛性;s606、获得模型达到最佳收敛时的k。进一步的,步骤s601中,设置初始学习率为一个或多个,步骤s602中,迭代处理是任意单次或多次。进一步的,步骤s04中,后向拟合的方法,包括以下步骤:s901、针对数据进行迭代处理;s902、设置初始学习率a=0.5和k,k的值是反向反馈验证法计算出的k值;s903、运行lookahead算法,查看模型损失函数以及模型拟合情况,拟合优度其中sse表示误差平方和,sst表示回归平方和;s904、改变步骤s902中的初始学习率,找到模型最佳拟合情况,即r2=1或则无限接近1;s905、输出模型最佳拟合情况学习率设置值。进一步的,步骤s901中,迭代处理是任意单次或多次。进一步的,步骤s05中,输出预测结果是一个数据或多个数据。具体的,如附图1所示,选取一组销售数据作为原始数据,如下表1:表一:原始销售数据表下一步,将原始销售数据做脱敏处理,得到的数据如下表2所示:表2:脱敏数据表日期(月)脱敏数据2019年11月940812019年12月519542020年1月1763942020年2月1536972020年3月1774472020年4月1067862020年5月643162020年6月477442020年7月281532020年8月164832020年9月94081下一步,将数据进行radam算法优化,计算梯度,利用指数加权平均方法优化方差,获得方差,计算公式如下:gt=δθft(θt-1),t表示步数,gt表示t歩的梯度,ft(θt-1)表示权重,δθ表示参数更新量,mt是一阶矩,vt是二阶矩,η是学习率,ct是偏差修正项,ε防止除零错误及控制更新量的最大比例,vt表示二阶矩,β2表示二阶矩指数加权平均超参;mt=β1mt-1+(1-β1)gt,mt表示一阶矩,β1表示一阶矩指数加权平均超参;表示计算偏差校正移动平均数,表示第t次迭代过程中一阶矩指数加权平均超参;ρt表示计算第t次迭代过程中的近似指数加权平均长度,ρ∞表示计算近似值的最大长度,表示第t次迭代过程中一阶矩指数加权平均超参;radam算法在训练的初期方差vt会非常大。通过指数加权平均计算的梯度平方的方差大于使用简单平均计算的梯度平方的方差,推导过程如下:设计一个s(vt)作为radam算法的插值权重;s(vt)=rt,其中rt∈[0,1],选用的插值权重为rt描述了当前的vt的方差离最小的方差有多远,方差计算推到公式如下:其中gi服从正态分布其中s表示方差,其中0.8是固定值,这里采取人工调参的方式确认的。获得数据如下表3:表3:radam算法获得方差下一步,用反向反馈验证法改进k参数,利用后向拟合的方法改进学习率,进行lookahead算法优化,lookahead拥有两套权重,即fastweights和slowweights,lookahead首先使用内部循环中的sgd等标准优化器,更新k次fastweights,然后以最后一个fastweights的方向更新slowweights;第一套权重fastweights其更新规则:θt,i+1=θt,i+a(l,θt,i-1,d),其中a为优化器,l为目标函数,d为样本数据,θt,i+1表示内循环优化器更新规则,但这里会将该轮循环的k次权重,用序列都保存下来;第二套权重slowweights其计算公式:φt+1=φt+a(θt,k-φt)=a[θt,k+(1-a)θt-1,k+...+(1-a)t-1θ0,k]+(1-a)tφ0这里的a是slowweights的学习率。具体的,用反向反馈验证法改进k参数包括以下步骤:s601、设置学习率分别为0.1,0.01,0.5;s602、针对数据分别按照s601设置的学习率分别进行迭代5,10,15,20,25和30次运算,获得权重,并备份;s603、从现有权重出发,运行lookahead算法得到k参数,并根据φt+1=a+(1-a)φt+k得到新权重;s604、更新模型权重;s605、查看模型收敛性;s606、获得模型达到最佳收敛时的k,k=0.7;利用后向拟合的方法改进学习率包括以下步骤:s901、针对数据分别进行迭代5,10,15,20,25,30次;s902、设置初始学习率a=0.5和k,k的值是反向反馈验证法计算出的k值;s903、运行lookahead算法,查看模型损失函数以及模型拟合情况,拟合优度其中sse表示误差平方和,sst表示回归平方和;s904、改变步骤s902中的初始学习率,找到模型最佳拟合情况,即r2=1或则无限接近1;s905、输出模型最佳拟合情况学习率设置值a=0.8。下一步,输出预测结果,预测结果为2020年10月,销售数据为95926,本发明基于改进ranger的深度学习方法计算过程用时如下表4。表4:本发明基于改进ranger的深度学习方法用时当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1