一种基于优化AnimeGAN的图像风格迁移的制作方法
一种基于优化animegan的图像风格迁移
技术领域
1.本发明属于图像处理技术领域,具体涉及一种基于优化animegan的图像风格迁移。
背景技术:
2.图像处理是一种具有巨大的社会和经济效益的实用技术,被广泛应用于各行各业以及人们的日常生活中。图像处理中常见的一个技术就是图像的风格迁移,图像风格迁移的目的是对图像的纹理、色彩、内容等进行定向的改变,使得图像从一种风格变化为另一种风格,例如,将照片进行风格迁移,得到宫崎骏动漫风格的图像,将光线较昏暗的条件下拍摄得到的风景照片进行风格迁移,得到光线较为明亮条件下的图像等。
3.现有的风格迁移技术通常存在着一些问题,比如生成的图像没有明显的目标风格纹理、生成的图像丢失了原有图像的边缘和内容、网络参数的存储容量要求太大等。生成对抗网络(generative adversarial networks,gan)被认为能够有效解决上述问题。
4.生成对抗网络是由ian j.goodfellow等人在2014年提出的,是一种非监督式的学习方法,通过两个神经网络相互博弈的方式进行学习。生成对抗网络由一个生成网络和一个判别网络组成的,其中生成网络从潜在空间中随机取样作为输入,输出的结果需要尽量模仿训练集中的样本,判别网络的输入为真实样本或者生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来,而生成网络则尽可能欺骗判别网络。两个网络通过互相对抗、不断调整参数,最终的目的是使判别网络无法判断生成网络的输出结果是否真实。
5.animegan(图像卡通风格迁移算法)是生成对抗网络的一个变体,animegan使用未配对的训练数据进行端到端训练,实现图片的风格迁移。
技术实现要素:
6.为了解决风格迁移时生成的图像目标风格纹理不明显、内容迁移效果不佳、图像边缘不清晰等问题,本发明提出了一种基于优化animegan的图像风格迁移,将优化后的animegan(图像卡通风格迁移算法)应用于非成对图像之间的风格迁移。
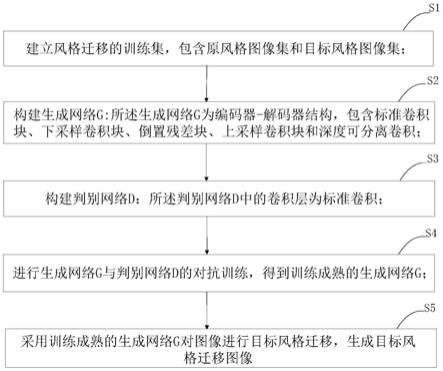
7.本发明提出的一种基于优化animegan的图像风格迁移,包含以下步骤:
8.s1、建立风格迁移的训练集,包含原风格图像集和目标风格图像集;
9.s2、构建生成网络g:所述生成网络g为编码器
‑
解码器结构,包含标准卷积块、下采样卷积块、倒置残差块、上采样卷积块和深度可分离卷积;
10.s3、构建判别网络d:所述判别网络d中的卷积层为标准卷积;
11.s4、进行生成网络g与判别网络d的对抗训练,得到训练成熟的生成网络g;
12.s5、采用训练成熟的生成网络g对图像进行目标风格迁移,生成目标风格迁移图像。
13.优选地,原风格图像集包含若干第一类图像,第一类图像为原风格图像,用来进行
目标风格迁移;
14.对第一类图像进行转化,生成第一类图像的yuv格式三通道图像。
15.优选地,目标风格图像集包含若干第二类图像和若干第三类图像,第二类图像为第一类图像对应的目标风格图像,第三类图像为第二类图像平滑处理后的图像;
16.对第三类图像进行转化,生成第三类图像的灰度图和第三类图像的yuv格式三通道图像。
17.优选地,所述生成网络g的编码器通过一层标准卷积块输入,将该标准卷积块与一层标准卷积块、一个下采样卷积块、一个标准卷积块、一个深度可分离卷积、一个下采样卷积块、一个标准卷积块以及8块倒置残差块依次连接,形成所述编码器;
18.所述生成网络g的解码器通过一个卷积层输出,依次连接一层标准卷积块、一个上采样卷积块、一个深度可分离卷积、一个标准卷积块、一个上采样卷积块、两个标准卷积块和该卷积层,形成所述解码器。
19.优选地,所述生成网络g通过所述标准卷积块提取图像的特征,通过所述下采样块避免池化带来的图像特征信息的丢失,通过所述倒置残差块降低训练时所需参数、提升训练速度,通过所述上采样块提高特征图的分辨率,通过所述深度可分离卷积减少计算量、加快图像的生成速度。
20.优选地,所述判别网络d包含七个卷积层:第一卷积层~第七卷积层;七个卷积层均为标准卷积层,第一卷积层至第七卷积层依次连接形成所述判别网络d。
21.优选地,所述判别网络d通过第一卷积层输入,并对第一卷积层、第二卷积层和第四卷积层分别进行lrelu激活函数操作,对第三卷积层、第五卷积层和第六卷积层分别进行实例正则化函数和lrelu激活函数操作,所述判别网络d通过第七卷积层输出。
22.优选地,所述生成网络g与判别网络d的对抗训练包含以下过程:
23.s41、所述生成网络d的预训练:
24.将第一类图像和第一类图像的yuv格式三通道图像,以及第三类图像和第三类图像的yuv格式三通道图像,输入所述生成网络d;
25.采用vgg19网络模型对所述生成网络d进行预训练,预训练过程采用l1稀疏正则化方法计算图像内容损失函数l
con
(g,d)和灰度损失函数l
gra
(g,d),计算公式如下:
[0026][0027][0028]
其中,公式(1)中g表示所述生成网络,d表示所述判别网络,p
i
表示第i张第一类图像,g(p
i
)表示第一类图像p
i
输入所述生成网络g生成的图像,表示第一类图像p
i
的yuv格式三通道图像的数学期望,vgg
l
(p
i
)表示输入第一类图像p
i
的vgg19网络模型、第l层的特征映射,vgg
l
(g(p
i
))表示输入g(p
i
)的vgg19网络模型、第l层的特征映射;
[0029]
公式(2)中表示输入所述生成网络g的、第三类图像的灰度图像x
i
的数学期望,gram表示特征图的gram矩阵;
[0030]
s42、训练所述判别网络d:
[0031]
将与第一类图像p
i
对应的第二类图像、所述生成网络g生成的图像g(p
i
)输入所述
判别网络d,对该第二类图像进行区分识别;识别过程中采用的损失函数计算公式如下:
[0032][0033]
其中,公式(3)中ω
adv
表示权重;表示第三类图像的yuv格式三通道图像a
i
的数学期望,该第三类图像与第一类图像p
i
对应;表示第一类图像p
i
的yuv格式三通道图像的数学期望;表示第三类图像的灰度图x
i
的数学期望,该第三类图像与第一类图像p
i
对应;表示图像g(p
i
)的灰度图像y
i
的数学期望;d(a
i
)、d(x
i
)、d(y
i
)分别表示判别网络判别输入的第三类图像的yuv格式三通道图像、第三类图像的灰度图、第一类图像的yuv格式三通道图像是否是真实;
[0034]
s43、训练生成网络g:
[0035]
将第一类图像的yuv格式三通道图像输入生成网络g,生成目标风格的图像并输出;
[0036]
所述生成网络g将rgb格式的图像颜色转换为yuv格式来构建颜色重构损失l
col
(g,d),计算公式如下:
[0037][0038]
其中,y(g(p
i
))、u(g(p
i
))、v(g(p
i
))分别表示所述生成网络g生成的图像g(p
i
)在yuv格式下的三个通道,h表示huber损失,p
i
表示第i张第一类图像;
[0039]
s44、重复步骤s41~s43,对第i+1张第一类图像进行生成网络g与判别网络d的对抗训练;
[0040]
以原风格图像集中每张第一类图像完成生成网络g与判别网络d的对抗训练,作为一个epoch。
[0041]
优选地,epoch为超参数,epoch值为原风格图像集中第一类图像的个数。
[0042]
与现有技术相比,本发明基于优化后的animegan进行图像风格迁移,著降低了图像训练时间;将优化后的animegan应用于非成对图像之间的风格迁移,使得生成的图像具有明显的目标风格纹理、内容迁移的效果更好,且图像边缘清晰。
附图说明
[0043]
图1为本发明所述基于优化animegan的图像风格迁移流程图;
[0044]
图2为本发明中优化后的animegan的生成网络结构示意图;
[0045]
图3为本发明中优化后的animegan的判别网络结构示意图;
[0046]
图4为风格迁移前后的图像对比图。
具体实施方式
[0047]
以下结合附图,通过详细说明较佳的具体实施例,对本发明进行详细介绍。
[0048]
图1为本发明所述基于优化animegan的图像风格迁移流程图。如图1所示,本发明
提出的一种基于优化animegan的图像风格迁移,包含以下步骤:
[0049]
s1、建立风格迁移的训练集,包含原风格图像集和目标风格图像集。
[0050]
所述原风格图像集包含若干第一类图像,第一类图像为原风格图像,用来进行目标风格迁移。所述目标风格图像集包含若干第二类图像和若干第三类图像,第二类图像为第一类图像对应的目标风格图像,第三类图像为第二类图像平滑处理后的图像。第一类图像的数量与第二类图像或第三类图像的数量相等。本发明实施例中以现实生活风格图像为原风格图像,即第一类图像;以宫崎骏动漫风格图像为目标风格图像,即第二类图像;第三类图像即为宫崎骏动漫风格图像平滑处理后的图像。
[0051]
对第一类图像进行转化,生成第一类图像的yuv格式三通道图像;对第三类图像进行转化,生成第三类图像的灰度图和第三类图像的yuv格式三通道图像。
[0052]
s2、构建生成网络g:所述生成网络g为编码器
‑
解码器结构,包含标准卷积块(conv
‑
block)、下采样卷积块(down
‑
conv)、倒置残差块(inverted residual blocks,irbs)、上采样卷积块(up
‑
conv)和深度可分离卷积(dsc
‑
conv)。
[0053]
图2为本发明中优化后的animegan的生成网络结构示意图。如图2所示,所述生成网络g结构具体结构如下:
[0054]
所述生成网络g的编码器通过一层标准卷积块输入,将该标准卷积块还与一层标准卷积块、一个下采样卷积块(步长为2)、一个标准卷积块、一个深度可分离卷积、一个下采样卷积块(步长为2)、一个标准卷积块以及8块倒置残差块依次连接,形成所述编码器;所述生成网络g的解码器与上述编码器连接;所述生成网络g的解码器通过一个卷积层输出,通过依次连接一层标准卷积块、一个上采样卷积块、一个深度可分离卷积、一个标准卷积块(卷积核为3
×
3)、一个上采样卷积块、两个标准卷积块和该卷积层,形成所述解码器。
[0055]
所述卷积层(卷积核为1
×
1))没有使用归一化层,激化函数采用的是tanh,公式为:其中,x是自变量,y为因变量,e为常数。
[0056]
所述生成网络g中,所述标准卷积块用于提取图像的特征,所述下采样块用来避免池化带来的图像特征信息的丢失,所述倒置残差块用来降低训练时所需参数、提升训练速度,所述上采样块用来提高特征图的分辨率,所述深度可分离卷积用来减少计算量、加快图像的生成速度。
[0057]
s3、构建判别网络d:所述判别网络d中的卷积层为标准卷积。
[0058]
图3为本发明中优化后的animegan的判别网络结构示意图。如图3所示,所述判别网络d包含七个卷积层:第一卷积层~第七卷积层;七个卷积层均为标准卷积层(conv);每个卷积层的权值采用谱归一化使网络训练更加稳定;第一卷积层至第七卷积层依次连接形成所述判别网络d,具体结构如下:
[0059]
所述判别网络d通过第一卷积层输入,并对第一卷积层进行lrelu激活函数操作,对第二卷积层进行lrelu激活函数操作,对第三卷积层进行实例正则化函数(instance_norma)和lrelu激活函数操作,对第四卷积层进行lrelu激活函数操作,对第五卷积层进行实例正则化函数和lrelu激活函数操作,对第六卷积层进行实例正则化函数和lrelu激活函数操作,最后,所述判别网络d通过第七卷积层输出。lrelu激活函数公式为:
其中,x是自变量,y为因变量。实例正则化是一个批次中单个图片进行归一化处理。
[0060]
s4、进行生成网络g与判别网络d的对抗训练,得到训练成熟的生成网络g,具体过程如下:
[0061]
s41、所述生成网络d的预训练:
[0062]
将第一类图像和第一类图像的yuv格式三通道图像,以及第三类图像和第三类图像的yuv格式三通道图像,输入所述生成网络d。
[0063]
采用vgg19网络模型对所述生成网络d进行预训练,预训练过程采用l1稀疏正则化方法计算图像内容损失函数l
con
(g,d)和灰度损失函数l
gra
(g,d),计算公式如下:
[0064][0065][0066]
其中,公式(1)中g表示所述生成网络,d表示所述判别网络,p
i
表示第i张第一类图像,g(p
i
)表示第一类图像pi输入所述生成网络g生成的图像,表示第一类图像p
i
的yuv格式三通道图像的数学期望,vgg
l
(p
i
)表示输入第一类图像p
i
的vgg19网络模型、第l层的特征映射,vgg
l
(g(p
i
))表示输入g(p
i
)的vgg19网络模型、第l层的特征映射;
[0067]
公式(2)中表示输入所述生成网络g的、第三类图像的灰度图像x
i
的数学期望,gram表示特征图的gram矩阵;
[0068]
s42、训练所述判别网络d:
[0069]
将与第一类图像p
i
对应的第二类图像、所述生成网络g生成的图像g(p
i
)输入所述判别网络d,对该第二类图像进行区分识别;识别过程中采用的损失函数计算公式如下:
[0070][0071]
其中,公式(3)中ω
adv
表示权重;表示第三类图像的yuv格式三通道图像a
i
的数学期望,该第三类图像与第一类图像p
i
对应;表示第一类图像p
i
的yuv格式三通道图像的数学期望;表示第三类图像的灰度图x
i
的数学期望,该第三类图像与第一类图像p
i
对应;表示图像g(p
i
)的灰度图像y
i
的数学期望;d(a
i
)、d(x
i
)、d(y
i
)分别表示判别网络判别输入的第三类图像的yuv格式三通道图像、第三类图像的灰度图、第一类图像的yuv格式三通道图像是否是真实。
[0072]
s43、训练生成网络g:
[0073]
将第一类图像的yuv格式三通道图像输入生成网络g,生成目标风格的图像并输出;
[0074]
所述生成网络g将rgb格式的图像颜色转换为yuv格式来构建颜色重构损失l
col
(g,d),计算公式如下:
[0075][0076]
其中,y(g(p
i
))、u(g(p
i
))、v(g(p
i
))分别表示所述生成网络g生成的图像g(p
i
)在yuv格式下的三个通道,h表示huber损失,p
i
表示第i张第一类图像;
[0077]
s44、重复步骤s41~s43,对第i+1张第一类图像进行生成网络g与判别网络d的对抗训练;
[0078]
以原风格图像集中每张第一类图像完成生成网络g与判别网络d的对抗训练,作为一个epoch。epoch为超参数,epoch值为原风格图像集中第一类图像的个数。
[0079]
s5、采用训练成熟的生成网络g对图像进行目标风格迁移,生成目标风格迁移图像。图4为风格迁移前后的图像对比图。
[0080]
尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1