一种基于NLP技术的集中性事件挖掘方法与流程
本申请属于文本处理技术领域,具体来说涉及一种基于nlp技术的集中性事件挖掘方法,主要针对政府服务热线的工单进行集中性事件挖掘。
背景技术:
随着网络技术的发展和社会服务意识的进步,目前群众经常通过登录政府服务热线反映遇到的各种亟待解决的社会问题。因此,如何从海量反馈信息中进行数据挖掘并找出群众反映的集中性事件进行优先处理,是本领域技术人员需要研究的方向。
技术实现要素:
:
本发明的目的在于提供一种基于nlp技术的集中性事件挖掘方法,能够从海量的反馈信息中找出集中性事件,并进行优先处理。
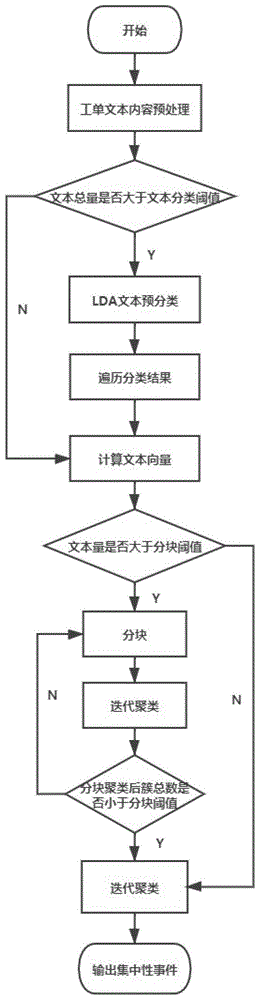
一种基于nlp技术的集中性事件挖掘方法,其包括如下步骤:
步骤1:对文本进行数据清洗处理;
步骤2:将文本总量与文本分类阈值进行比对,若文本总量大于文本分类阈值、则基于lda主题分类模型将文本进行预分类并取得k个分类结果;若文本总量小于文本分类阈值、则视为所有文本归于一个分类结果中、即k=1;
步骤3:对步骤2所得k个分类结果进行排序、并依据该排序将k个分类结果作为当前分类结果分别执行步骤4至13;
步骤4:在当前分类结果下计算每条文本的文本向量、并将当前分类结果下的各个文本分别构成一个单独的簇并进行编号;
步骤5:设定对应于簇文本长度的文本相似度阈值,所述簇文本长度为该簇中所包含文本的平均文本长度;
步骤6:将当前分类结果下簇的数量与文本分块阈值进行比对;
若当前分类结果下簇的数量小于文本分块阈值则跳转至步骤7;
若当前分类结果下簇的数量大于文本分块阈值则跳转至步骤9;
步骤7:初始化聚类空间、使聚类空间中包含0个簇;
步骤8:将当前分类结果下的所有簇乱序排布、并逐一投放至聚类空间中;
若聚类空间中包含0个簇,则将当前簇作为一个新的簇添加到聚类空间中;
若聚类空间中已包含其他簇,则令当前簇与聚类空间中的其他各簇逐一比对、分别求得当前簇与其他簇的文本相似度,并将文本相似度大于其相似度阈值的簇视为当前簇的候选聚类簇;
若聚类空间中包含当前簇的候选聚类簇、使当前簇与文本相似度最高的候选聚类簇聚成一类,并更新聚类空间中各个簇的簇的文本向量、簇平均文本长度和簇包含的文本id;此处所述簇的文本向量是指簇中包含的所有文本向量的平均值;
若聚类空间中未包含当前簇的候选聚类簇,则将当前簇作为一个新的簇添加到聚类空间中,并更新聚类空间中各个簇的簇的文本向量、簇平均文本长度和簇包含的文本id;
跳转至步骤13;
步骤9:将当前分类结果进行分块处理、生成多个文本分块且令各个文本分块中包含的簇的数量等于预设的块尺寸,将所产生的文本分块进行排序、并依据该排序将各个文本分块作为当前文本分块分别执行步骤10至11;
步骤10:初始化聚类空间、使聚类空间中包含0个簇;
步骤11:将当前文本分块下的所有簇乱序排布、并逐一投放至聚类空间中;
若聚类空间中包含0个簇,则将当前簇作为一个新的簇添加到聚类空间中;
若聚类空间中已包含其他簇,则令当前簇与聚类空间中的其他各簇逐一比对、分别求得当前簇与其他簇的文本相似度,并将文本相似度大于其相似度阈值的簇视为当前簇的候选聚类簇;
若聚类空间中包含当前簇的候选聚类簇、使当前簇与文本相似度最高的候选聚类簇聚成一类,并更新聚类空间中各个簇的簇的文本向量、簇平均文本长度和簇包含的文本id;
若聚类空间中未包含当前簇的候选聚类簇,则将当前簇作为一个新的簇添加到聚类空间中,并更新聚类空间中各个簇的簇的文本向量、簇平均文本长度和簇包含的文本id;
跳转至步骤12;
步骤12:将各文本分块下的各个簇进行混合作为新的输入并跳转至步骤6;
步骤13:筛选出聚类结果中文本数量达到集中性事件阈值的簇,分别记为集中性事件,并分别生成各集中性事件的代表性得分和名称。
通过采用上述技术方案:将实际描述有所差异但反映同一件事件的文本聚成一类,由此从海量文本中找到各个集中性事件。需要说明的是:现有的聚类算法一般需要指定具体的类别数进行分类,这就导致如果两个不同的集中性事件在描述上存在一定的相似度可能被聚类在一起。而本申请的方案通过对不同文本长度的簇设定不同的相似度阈值,使各种长度的簇在聚类时,只有达到对应阈值才能聚成一类。不仅可以在描述性长度较长的文本中挖掘出各个集中性事件,也可以将长度较短的文本进行有效聚类,避免了两个不同的集中性事件被聚类在同一个簇中的问题。同时,针对由此产生的聚类运算时应文本量过大导致的耗时过长问题,对待聚类文本进行分块操作、大幅减少了对单个分块中文本进行迭代聚类的运算量、保证了本聚类方案在运算速度不低于现有的聚类算法。本方案在应用于政府服务热线时,有利于帮助发现群体性事件和苗头性事件。指导政府对集中性事件优先予以解决、对苗头性事件实现尽早控制。
优选的是,上述一种基于nlp技术的集中性事件挖掘方法中,步骤13包括:
步骤131:将各个簇的文本数量与预存的集中性文本阈值进行比对,筛选出文本数量达到集中性文本阈值的簇,分别将筛选出的簇记为集中性事件;
步骤132:分别计算步骤131所筛选出的簇中各文本与簇的文本向量的余弦相似度、该余弦相似度即为该集中性事件下各文本的代表性得分;
步骤133:基于tf-idf算法分别计算步骤131所筛选出的簇中的热频词或特有信息词、该热频词或特有信息词即为作为各集中性事件的名称。
通过采用这种技术方案:将热频词作为集中性事件名称。比如使用tf-idf计算每个集中性事件的前3个热频词,作为每个集中性事件的名称。也可以结合业务场景给出集中性事件名称。比如对于政府服务热线工单,可以使用集中性事件代表性得分最高的工单对应的工单标题进行命名。作为通用方法,本设计使用第一种方式给出每个集中性事件的名称。
优选的是,上述一种基于nlp技术的集中性事件挖掘方法中,步骤1包括:
步骤101:利用正则表达式匹配文本中出现的特定词,将其替换为空格;
步骤102:对文本进行分词处理、取得各文本的分词,并仅保留不存在于停用词库中的分词。
通过采用这种技术方案:实现对文本中的数据清洗。具体包括去除停用词和去除无效工单。停用词包含网上开源的停用词库和工单的特定话术两部分。工单的特定话术的存在会干扰计算文本相似度,应当将其进行剔除。无效工单,主要是不想参与计算集中性事件的工单。比如工单内容为“测试工单”,工单内容为空字符等。网上开源的停用词库主要是在对文章进行分词时进行停用词的过滤。特定的话术词会在文章分词前进行过滤。
优选的是,上述一种基于nlp技术的集中性事件挖掘方法中,步骤4中所述计算每条文本的文本向量包括:
步骤401:对所有文本进行分词、通过最小词频和最大词数参数对词进行过滤,得到所有文本的词集合、将该词集合按照某个顺序进行排序,得到一个有序的预存词汇表。
步骤402:对于某条文本,将词汇表中的每个词在该文本的分词结果中进行查找,如果词汇表中的某个词出现在文本分词结果中,则该条文本的文本向量相应位置记为1、否则文本向量相应位置记为0;
步骤403:基于tf-idf计算模型分别求得各个文本中每个词的tf-idf得分;
步骤404:基于步骤403得到的tf-idf得分,作为步骤402中文本向量中词的权重,得到每条文本最终的文本向量。
与现有技术相比,本申请的技术方案能够从海量的工单信息中更高效的寻找出群众集中反映的一般性事件,对苗头性事件尽早控制和解决。
附图说明
下面结合附图与具体实施方式对本申请作进一步详细的说明:
图1为本发明中工作流程图;
图2为图1中迭代聚类步骤的流程图。
具体实施方式
为了更清楚地说明本申请的技术方案,下面将结合各个实施例作进一步描述。
如图1-2所示:
一种基于nlp技术的集中性事件挖掘方法,其包括如下步骤:
步骤1:对文本进行数据清洗处理;
步骤1具体包括:
步骤101:利用正则表达式匹配文本中出现的特定词,将其替换为空格;
步骤102:对文本进行分词处理、取得各文本的分词,并保留其中不存在于停用词库中的分词。
举例如下:设某条文本内容为“关于反映噪音扰民的问题。xx区xx路,此处工地夜间施工,噪音扰民”。上述文本中包含的特定词是“关于”、“反映”、“问题”等。通过正则,匹配替换后,生成的文本为:“噪音扰民的。xx区xx路,此处工地夜间施工,噪音扰民”。对处理后的文本进行分词并过滤停用词,得到“噪音扰民xx区xx路此处工地夜间施工噪音扰民”。
由此,在本步骤中,实现了对原始文本中去除停用词和无效工单。
步骤2:将文本总量与文本分类阈值进行比对,若文本总量大于文本分类阈值、则基于lda主题分类模型将文本进行预分类并取得k个分类结果;若文本总量小于文本分类阈值、则视为所有文本归于一个分类结果中、即k=1;
步骤3:对步骤2所得k个分类结果进行排序、并依据该排序将k个分类结果作为当前分类结果分别执行步骤4至13;
上述步骤2-3中:基于lda模型对文本进行预分类操作,这一步骤的作用在于:根据主题数对所有文本进行分类,保证了一个集中性事件只会被分到一个分类中,降低了单轮聚类处理所要处理的文本数量。设文本总数为n、文本尺寸为m,则k=n/m后取整的值。例如,对25000条文本进行lda预分类:设定lda主题分类的阈值为20000,lda分类文本尺寸m为3000,则由输入的25000条文本大于设定的lda主题分类阈值20000,故使用lda先对文本进行初步分类,且分类个数k为25000除以3000,向上取整后,得到k=9。即利用lda模型对输入的25000条文本分成9个类。
步骤4:在当前分类结果下计算每条文本的文本向量、并将当前分类结果下的各个文本分别构成一个单独的簇并进行编号;
具体的:所述计算每条文本的文本向量包括:
步骤401:对所有文本进行分词、通过最小词频和最大词数参数对词进行过滤,得到所有文本的词集合、将该词集合按照某个顺序进行排序,得到一个有序的预存词汇表。
步骤402:对于某条文本,将词汇表中的每个词在该文本的分词结果中进行查找,如果词汇表中的某个词出现在文本分词结果中,则该条文本的文本向量相应位置记为1、否则文本向量相应位置记为0;
步骤403:基于tf-idf计算模型分别求得各个文本中每个词的tf-idf得分;
步骤404:基于步骤403得到的tf-idf得分,作为步骤402中文本向量中词的权重,得到每条文本最终的文本向量。
步骤5:设定对应于簇文本长度的文本相似度阈值,所述簇文本长度为该簇中所包含文本的平均文本长度;
步骤6:将当前分类结果下簇的数量与文本分块阈值进行比对;
若当前分类结果下簇的数量小于文本分块阈值则跳转至步骤7;
若当前分类结果下簇的数量大于文本分块阈值则跳转至步骤9;
步骤7:初始化聚类空间、使聚类空间中包含0个簇;
步骤8:将当前分类结果下的所有簇乱序排布、并逐一投放至聚类空间中;
若聚类空间中包含0个簇,则将当前簇作为一个新的簇添加到聚类空间中;
若聚类空间中已包含其他簇,则令当前簇与聚类空间中的其他各簇逐一比对、分别求得当前簇与其他簇的文本相似度,并将文本相似度大于其相似度阈值的簇视为当前簇的候选聚类簇;
若聚类空间中包含当前簇的候选聚类簇、使当前簇与文本相似度最高的候选聚类簇聚成一类,并更新聚类空间中各个簇的簇的文本向量、簇平均文本长度和簇包含的文本id;
若聚类空间中未包含当前簇的候选聚类簇,则将当前簇作为一个新的簇添加到聚类空间中,并更新聚类空间中各个簇的簇的文本向量、簇平均文本长度和簇包含的文本id;
跳转至步骤13;
步骤9:将当前分类结果进行分块处理、生成多个文本分块且令各个文本分块中包含的簇的数量等于预设的块尺寸,将所产生的文本分块进行排序、并依据该排序将各个文本分块作为当前文本分块分别执行步骤10至11;
步骤10:初始化聚类空间、使聚类空间中包含0个簇;
步骤11:将当前文本分块下的所有簇乱序排布、并逐一投放至聚类空间中;
若聚类空间中包含0个簇,则将当前簇作为一个新的簇添加到聚类空间中;
若聚类空间中已包含其他簇,则令当前簇与聚类空间中的其他各簇逐一比对、分别求得当前簇与其他簇的文本相似度,并将文本相似度大于其相似度阈值的簇视为当前簇的候选聚类簇;
若聚类空间中包含当前簇的候选聚类簇、使当前簇与文本相似度最高的候选聚类簇聚成一类,并更新聚类空间中各个簇的簇的文本向量、簇平均文本长度和簇包含的文本id;
若聚类空间中未包含当前簇的候选聚类簇,则将当前簇作为一个新的簇添加到聚类空间中,并更新聚类空间中各个簇的簇的文本向量、簇平均文本长度和簇包含的文本id;
跳转至步骤12;
步骤12:将各文本分块下的各个簇进行混合作为新的输入并跳转至步骤6;
通过采用上述步骤:基于各个簇与簇之间的文本相似度、将各个集中性事件最终归并到一个簇里。同时通过根据对不同簇的簇文本长度分别设定其相似度阈值,使得在对不同长度的文本聚类时更加合理。
步骤13:筛选出聚类结果中文本数量达到集中性事件阈值的簇,分别记为集中性事件,并分别生成各集中性事件的代表性得分和名称。
具体的,步骤13包括:
步骤131:将各个簇的文本数量与预存的集中性文本阈值进行比对,筛选出文本数量达到集中性文本阈值的簇,分别将筛选出的簇记为集中性事件;
步骤132:分别计算步骤131所筛选出的簇中各文本与簇的文本向量的余弦相似度、该余弦相似度即为该集中性事件下各文本的代表性得分;
步骤133:基于tf-idf算法分别计算步骤131所筛选出的簇中的热频词或特有信息词、该热频词或特有信息词即为作为各集中性事件的名称。
举例如下:假设两条文本的文本向量分别为:
[1,0,1,0,1,0]和[1,1,1,1,0,0]
则,上述两个向量的点积为两个向量相应位置的元素相乘后再求和,即
1*1+0*1+1*1+0*1+1*0+0*0=2。
两个向量的模分别为:
以上所述,仅为本申请的具体实施例,但本申请的保护范围并不局限于此,任何熟悉本领域技术的技术人员在本申请公开的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。本申请的保护范围以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!