贴图延迟渲染的数据驱动方法及装置与流程
本发明涉及显示驱动领域,具体而言,涉及一种贴图延迟渲染的数据驱动方法及装置。
背景技术:
相关技术中的移动gpu驱动(gpudrivenonmobile)包括tbdr(tilebaseddeferredrendering,贴图延迟渲染)模式和sparsetexture(稀疏贴图)模式,tbdr(tilebaseddeferredrendering,贴图延迟渲染)算是tbr(tilebasedrendering,贴图渲染)的延伸,跟tbr(贴图渲染)原理相似;但是通过hsr(hiddensurfaceremoval,隐藏面消除)操作,在执行pixelshader(像素着色)之前进一步减少了不需要渲染的fragment(片段),降低了带宽需求。
在执行pixelshader(像素着色)之前,对raster(光栅)生成的每个像素都做depthtest(深度测试)的比较,剔除被遮挡的像素,这就是hsr(隐藏面消除)的原理,理论上经过hsr(隐藏面消除)剔除以后,tbdr(贴图延迟渲染)每帧需要渲染的像素上限就是屏幕像素的数量(没有考虑alphablend(alpha混合)的情况下)。而传统的tbr(贴图渲染)在执行复杂一点的游戏时可能需要渲染6倍于屏幕的像素。对比sparsetexture(稀疏贴图)分支与tbdr(贴图延迟渲染)分支的优缺点。st分支的优点在于:sparsetexture(稀疏贴图)+indirectdraw(非直接的渲染指令)可以在同一shader(渲染器)中最大化合批;geometry(几何)信息可通过visibilitybuffer(可见缓冲区)重建,无需gbufferpass(g缓冲区通道);缺点在于:在合并texture(贴图)的三种方案中,bindlesstexture(无粘结贴图)的支持率非常低,达不到实用阶段;而软实现的vt性能不如sparsetexture(稀疏贴图),sparsetexture(稀疏贴图)在ios设备中a11+的gpu都具备该特性,所以在ios设备中,会走sparsetexture(稀疏贴图)的分支,android设备中该特性也支持率非常低。tbdr(贴图延迟渲染)分支的优点在于:当前移动端设备gpu结构已几乎全部为tilebased(基于贴图)架构,tbdr(贴图延迟渲染)分支流程在可控的tilebuffer(贴图缓冲区)上将获得在带宽传输方面巨大的性能提升,不需要specialhardwarefeature(特殊硬件功能)支持;缺点在于:性能不如基于sparsetexture(稀疏贴图)的分支流程。
相关技术的gpudriven(gpu驱动)渲染流程中gpudriventbdr(贴图延迟渲染gpu驱动)所有buffer(缓存区)都位于systemmemory(系统存储器)中,导致systemmemory(系统存储器)占用大量的宽带开销,而移动设备受限于设备和内部主板的面积,不能向pc端一样设置高宽带,进而导致移动设备的gpu渲染能力有限。
针对相关技术中存在的上述问题,目前尚未发现有效的解决方案。
技术实现要素:
本发明实施例提供了一种贴图延迟渲染的数据驱动方法及装置。
根据本发明的一个实施例,提供了一种贴图延迟渲染的数据驱动方法,包括:在移动设备构建渲染对象的层次z缓冲数据;将所述层次z缓冲数据传输至所述移动设备的贴图存储区的层次z缓冲区中;将所述层次z缓冲数据从所述贴图存储区传输至所述移动设备的图像处理器gpu;在所述gpu中基于所述层次z缓冲数据对所述渲染对象进行视锥体剔除和/或遮挡剔除,得到贴图数据;将所述贴图数据从所述gpu传输至所述贴图存储区的可见缓冲区中。
可选的,在将所述贴图数据从所述gpu传输至所述贴图存储区的可见缓冲区中之后,所述方法还包括:将所述贴图数据从所述可见缓冲区上传至cpu的gpu场景缓冲区,并经过所述gpu场景缓冲区传输至所述gpu进行渲染。
可选的,经过所述gpu场景缓冲区传输至所述gpu进行渲染包括:将所述贴图数据从所述gpu场景缓冲区传输至所述gpu的复制存储区,从所述复制存储区传输至系统存储区的gpu场景缓冲区,从所述系统存储区的gpu场景缓冲区传输至所述cpu,在所述cpu中对所述贴图数据执行批渲染,得到几何数据;通过回调指令将所述几何数据通过所述gpu的g缓冲区通道传输至所述贴图存储区的g缓冲区中;从所述g缓冲区将所述几何数据传输至所述gpu进行渲染。
可选的,所述方法还包括:从所述gpu中获取光栅剔除数据;将所述光栅剔除数据从所述gpu传输至所述贴图存储区的光源列表中;从所述光源列表将所述光栅剔除数据传输至所述gpu进行渲染。
可选的,在移动设备构建渲染对象的层次z缓冲数据包括:从所述移动设备的系统存储器的深度缓冲区读取所述渲染对象上一帧的深度数据;将所述深度数据从所述深度缓冲区传输至所述移动设备的gpu,并在所述gpu中基于所述深度数据构建所述渲染对象的层次z缓冲数据。
根据本发明的另一个实施例,提供了一种贴图延迟渲染的数据驱动装置,包括:构建模块,用于在移动设备构建渲染对象的层次z缓冲数据;第一传输模块,用于将所述层次z缓冲数据传输至所述移动设备的贴图存储区贴图存储区的层次z缓冲区中;第二传输模块,用于将所述层次z缓冲数据从所述贴图存储区传输至所述移动设备的图像处理器gpu;处理模块,用于在所述gpu中基于所述层次z缓冲数据对所述渲染对象进行视锥体剔除和/或遮挡剔除,得到贴图数据;第三传输模块,用于将所述贴图数据从所述gpu传输至所述贴图存储区的可见缓冲区中。
可选的,所述装置还包括:第四传输模块,用于在所述第三传输模块将所述贴图数据从所述gpu传输至所述贴图存储区的可见缓冲区中之后,将所述贴图数据从所述可见缓冲区上传至cpu的gpu场景缓冲区,并经过所述gpu场景缓冲区传输至所述gpu进行渲染。
可选的,所述第四传输模块包括:第一传输单元,用于将所述贴图数据从所述gpu场景缓冲区传输至所述gpu的复制存储区,从所述复制存储区传输至系统存储区的gpu场景缓冲区,从所述系统存储区的gpu场景缓冲区传输至所述cpu,在所述cpu中对所述贴图数据执行批渲染,得到几何数据;第二传输单元,用于通过回调指令将所述几何数据通过所述gpu的g缓冲区通道传输至所述贴图存储区的g缓冲区中;第三传输单元,用于从所述g缓冲区将所述几何数据传输至所述gpu进行渲染。
可选的,所述装置还包括:获取模块,用于从所述gpu中获取光栅剔除数据;第五传输单元,用于将所述光栅剔除数据从所述gpu传输至所述贴图存储区的光源列表中;渲染单元,用于从所述光源列表将所述光栅剔除数据传输至所述gpu进行渲染。
可选的,所述构建模块包括:读取单元,用于从所述移动设备的系统存储器的深度缓冲区读取所述渲染对象上一帧的深度数据;传输单元,用于将所述深度数据从所述深度缓冲区传输至所述移动设备的gpu,并在所述gpu中基于所述深度数据构建所述渲染对象的层次z缓冲数据。
根据本发明的又一个实施例,还提供了一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述任一项方法实施例中的步骤。
根据本发明的又一个实施例,还提供了一种电子设备,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一项方法实施例中的步骤。
通过本发明,在移动设备构建渲染对象的层次z缓冲数据,然后将所述层次z缓冲数据传输至所述移动设备的贴图存储区的层次z缓冲区中,将所述层次z缓冲数据从所述贴图存储区传输至所述移动设备的图像处理器gpu,通过将层次z缓冲数据传输和存储至贴图存储区,在所述gpu中基于所述层次z缓冲数据对所述渲染对象进行视锥体剔除和/或遮挡剔除,得到贴图数据,将所述贴图数据从所述gpu传输至所述贴图存储区的可见缓冲区中,通过将系统存储器的数据分流至贴图存储区,可以减少系统存储器的存储压力和传输带宽,解决了相关技术在贴图延迟渲染时系统内存占用和带宽开销过大的技术问题,均衡了gpu驱动通道中的内存分布,提高了整个gpu驱动的数据传输速度和画面渲染速度。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是本发明实施例的一种贴图延迟渲染的数据驱动手机的硬件结构框图;
图2是根据本发明实施例的一种贴图延迟渲染的数据驱动方法的流程图;
图3是本发明实施例的贴图延迟渲染的时序图;
图4是根据本发明实施例的一种贴图延迟渲染的数据驱动装置的结构框图;
图5是本发明实施例的一种电子设备的结构图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
实施例1
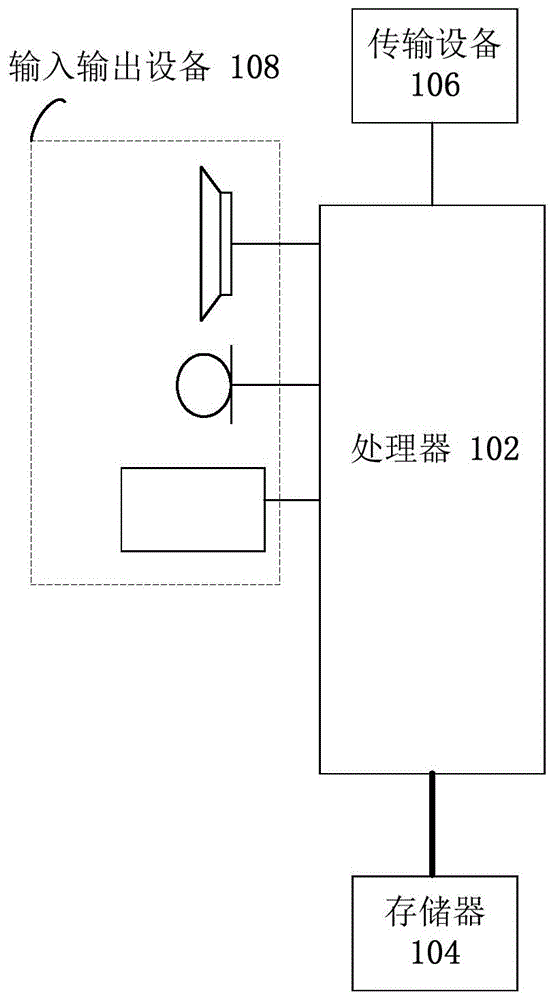
本申请实施例一所提供的方法实施例可以在手机、平板或者类似的移动终端中执行。以运行在手机上为例,图1是本发明实施例的一种贴图延迟渲染的数据驱动手机的硬件结构框图。如图1所示,手机可以包括一个或多个(图1中仅示出一个)处理器102(处理器102可以包括但不限于微处理器mcu或可编程逻辑器件fpga等的处理装置)和用于存储数据的存储器104,可选地,上述手机还可以包括用于通信功能的传输设备106以及输入输出设备108。本领域普通技术人员可以理解,图1所示的结构仅为示意,其并不对上述手机的结构造成限定。例如,手机还可包括比图1中所示更多或者更少的组件,或者具有与图1所示不同的配置。
存储器104可用于存储手机程序,例如,应用软件的软件程序以及模块,如本发明实施例中的一种贴图延迟渲染的数据驱动方法对应的手机程序,处理器102通过运行存储在存储器104内的手机程序,从而执行各种功能应用以及数据处理,即实现上述的方法。存储器104可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器104可进一步包括相对于处理器102远程设置的存储器,这些远程存储器可以通过网络连接至手机。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
传输设备106用于经由一个网络接收或者发送数据。上述的网络具体实例可包括手机的通信供应商提供的无线网络。在一个实例中,传输设备106包括一个网络适配器(networkinterfacecontroller,简称为nic),其可通过基站与其他网络设备相连从而可与互联网进行通讯。在一个实例中,传输设备106可以为射频(radiofrequency,简称为rf)模块,其用于通过无线方式与互联网进行通讯。
在本实施例中提供了一种贴图延迟渲染的数据驱动方法,图2是根据本发明实施例的一种贴图延迟渲染的数据驱动方法的流程图,如图2所示,该流程包括:
步骤s202,在移动设备构建渲染对象的hierarchical-zbuffer(层次z缓冲,简称为hzb)数据;
本实施例的移动设备可以是安卓设备,或者是采用类似arm构架的电子设备,渲染对象是待使用gpu进行渲染和展示的图像数据。
步骤s204,将所述层次z缓冲数据传输至所述移动设备的贴图存储区的层次z缓冲区中;
本实施例的贴图存储区是移动设备上独立于cpu、gpu、systemmemory(系统存储器)的存储区域,贴图存储区与移动设备的系统存储器连接,cpu、gpu、系统存储器一起组成移动设备的gpudrivenpipeline(gpu驱动管线)。
步骤s206,将所述层次z缓冲数据从所述贴图存储区传输至所述移动设备的gpu(图像处理器);
步骤s208,在所述gpu中基于所述hzb(层次z缓冲)数据对所述渲染对象进行视锥体剔除和/或遮挡剔除,得到贴图数据;
在本实施例中,occlusionculling(遮挡剔除)是当一个物体被其他物体遮挡住而不在摄像机的可视范围内时不对其进行渲染。遮挡剔除在3d图形计算中并不是自动进行的。因为在绝大多数情况下离相机最远的物体首先被渲染,靠近摄像机的物体后渲染并覆盖先前渲染的物体,遮挡剔除不同于视锥体剔除,视锥体剔除只是不渲染摄像机视角范围外的物体而对于被其他物体遮挡但依然在视角范围内的物体,则不会被剔除,当使用遮挡剔除时依然受益于frustumculling(视锥体剔除)。通过剔除视锥体和遮挡物,可以减少渲染数据,在不改变输出图像的前提下提高渲染速度。
步骤s210,将所述贴图数据从所述gpu传输至所述贴图存储区的可见缓冲区中。
在本实施例的tbdr(贴图延迟渲染)分支流程中,可见缓冲区保存可见的primitiveid(图元id)作为贴图数据,由于visibilitybuffe(可见缓冲区)位于tilememory(贴图存储区),可以减少系统存储器的带宽。
通过上述步骤,在移动设备构建渲染对象的层次z缓冲数据,然后将所述层次z缓冲数据传输至所述移动设备的贴图存储区的层次z缓冲区中,将所述层次z缓冲数据从所述贴图存储区传输至所述移动设备的图像处理器gpu,通过将层次z缓冲数据传输和存储至贴图存储区,在所述gpu中基于所述层次z缓冲数据对所述渲染对象进行视锥体剔除和/或遮挡剔除,得到贴图数据,将所述贴图数据从所述gpu传输至所述贴图存储区的可见缓冲区中,通过将系统存储器的数据分流至贴图存储区,可以减少系统存储器的存储压力和传输带宽,解决了相关技术在贴图延迟渲染时系统内存占用和带宽开销过大的技术问题,均衡了gpu驱动通道中的内存分布,提高了整个gpu驱动的数据传输速度和画面渲染速度。
可选的,在将所述贴图数据从所述gpu传输至所述贴图存储区的visibilitybuffe(可见缓冲区)中之后,还包括:将所述贴图数据从所述visibilitybuffe(可见缓冲区)上传至cpu的gpuscenebuffer(gpu场景缓冲区),并经过所述gpu场景缓冲区(贴图存储区)传输至所述gpu进行渲染。
在本实施例的一个实施方式中,经过所述gpu场景缓冲区(贴图存储区)传输至所述gpu进行渲染包括:将所述贴图数据从所述gpu场景缓冲区传输至所述gpu的copymemory(复制存储区),从所述memory(复制存储区)传输至系统存储区的gpu场景缓冲区,从所述系统存储区的gpu场景缓冲区传输至所述cpu,在所述cpu中对所述贴图数据执行批渲染,得到几何数据;通过drawcall(回调指令)通过所述gpu的gbuffer(g缓冲区)通道传输至所述tilememory(贴图存储区)的gbuffer(g缓冲区)中;从所述gbuffer(g缓冲区)将所述几何数据传输至所述gpu进行渲染。
通过构建gbuffer(g缓冲区)来输出几何数据(geometryinfo),参与到最终shading(渲染)。
在gpu渲染过程中,除了几何数据之外,还包括lightgridculling(光栅剔除数据),通过将缓存光栅剔除数据存储buff(缓冲区)放置在tilememory(贴图存储区)中,可以进一步节省系统存储器的带宽,提高渲染速度。
在渲染光栅剔除数据时,本实施例的方案执行以下流程:从所述gpu中获取光栅剔除数据;将所述光栅剔除数据从所述gpu传输至所述tilememory(贴图存储区)的光源列表lightlist(光源列表)中;从所述lightlist(光源列表)将所述光栅剔除数据传输至所述gpu进行渲染。
在本实施例的一个实施方式中,使用系统存储器中的深度数据构建渲染对象的hzb(层次z缓冲)数据,在移动设备构建渲染对象的hzb(层次z缓冲)数据包括:从所述移动设备的系统存储器的depthbuffer(深度缓冲区)读取所述渲染对象上一帧的深度数据;将所述深度数据从所述深度缓冲区传输至所述移动设备的gpu,并在所述gpu中基于所述深度数据构建所述渲染对象的hzb(层次z缓冲)数据。
图3是本发明实施例的贴图延迟渲染的时序图,在设置了tilememoryfeature(贴图存储区特征)之后,尽可能的将buffer(缓存区)都置于tilememory(贴图存储区)中,以节省带宽开销,本实施例的tbdr流程在时序上执行了如下优化:hi-zbuffer(层次z缓冲区)、lightlist(光源列表)、visibilitybuffer(可见缓冲区)和gbuffer(g缓冲区)都可从systemmemory(系统存储器)中移到tilememory(贴图存储区)中;而depthbuffer(深度缓冲区)由于要在每帧最开始用上一帧的内容参与构建hi-zbuffer(层次z缓冲区),这样就垮了多个renderpass(渲染通道)无法在tilememory(贴图存储区)中传递,以及其它需要cpu流程参与的数据传输,考虑到数据的传输效率,没有放在tilememory(贴图存储区)中,可以节省数据的传输时间。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到根据上述实施例的方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
实施例2
在本实施例中还提供了一种贴图延迟渲染的数据驱动装置,用于实现上述实施例及优选实施方式,已经进行过说明的不再赘述。如以下所使用的,术语“模块”可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的装置较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。
图4是根据本发明实施例的一种贴图延迟渲染的数据驱动装置的结构框图,如图4所示,该装置包括:构建模块40,第一传输模块42,第二传输模块44,处理模块46,第三传输模块48,其中,
构建模块40,用于在移动设备构建渲染对象的层次z缓冲数据;
第一传输模块42,用于将所述层次z缓冲数据传输至所述移动设备的贴图存储区贴图存储区的层次z缓冲区中;
第二传输模块44,用于将所述层次z缓冲数据从所述贴图存储区传输至所述移动设备的图像处理器gpu;
处理模块46,用于在所述gpu中基于所述层次z缓冲数据对所述渲染对象进行视锥体剔除和/或遮挡剔除,得到贴图数据;
第三传输模块48,用于将所述贴图数据从所述gpu传输至所述贴图存储区的可见缓冲区中。
可选的,所述装置还包括:第四传输模块,用于在所述第三传输模块将所述贴图数据从所述gpu传输至所述贴图存储区的可见缓冲区中之后,将所述贴图数据从所述可见缓冲区上传至cpu的gpu场景缓冲区,并经过所述gpu场景缓冲区传输至所述gpu进行渲染。
可选的,所述第四传输模块包括:第一传输单元,用于将所述贴图数据从所述gpu场景缓冲区传输至所述gpu的复制存储区,从所述复制存储区传输至系统存储区的gpu场景缓冲区,从所述系统存储区的gpu场景缓冲区传输至所述cpu,在所述cpu中对所述贴图数据执行批渲染,得到几何数据;第二传输单元,用于通过回调指令将所述几何数据通过所述gpu的g缓冲区通道传输至所述贴图存储区的g缓冲区中;第三传输单元,用于从所述g缓冲区将所述几何数据传输至所述gpu进行渲染。
可选的,所述装置还包括:获取模块,用于从所述gpu中获取光栅剔除数据;第五传输单元,用于将所述光栅剔除数据从所述gpu传输至所述贴图存储区的光源列表中;渲染单元,用于从所述光源列表将所述光栅剔除数据传输至所述gpu进行渲染。
可选的,所述构建模块包括:读取单元,用于从所述移动设备的系统存储器的深度缓冲区读取所述渲染对象上一帧的深度数据;传输单元,用于将所述深度数据从所述深度缓冲区传输至所述移动设备的gpu,并在所述gpu中基于所述深度数据构建所述渲染对象的层次z缓冲数据。
需要说明的是,上述各个模块是可以通过软件或硬件来实现的,对于后者,可以通过以下方式实现,但不限于此:上述模块均位于同一处理器中;或者,上述各个模块以任意组合的形式分别位于不同的处理器中。
实施例3
本申请实施例还提供了一种电子设备,图5是本发明实施例的一种电子设备的结构图,如图5所示,包括处理器51、通信接口52、存储器53和通信总线54,其中,处理器51,通信接口52,存储器53通过通信总线54完成相互间的通信,存储器53,用于存放计算机程序;处理器51,用于执行存储器53上所存放的程序时,实现如下步骤:在移动设备构建渲染对象的层次z缓冲数据;将所述层次z缓冲数据传输至所述移动设备的贴图存储区的层次z缓冲区中;将所述层次z缓冲数据从所述贴图存储区传输至所述移动设备的图像处理器gpu;在所述gpu中基于所述层次z缓冲数据对所述渲染对象进行视锥体剔除和/或遮挡剔除,得到贴图数据;将所述贴图数据从所述gpu传输至所述贴图存储区的可见缓冲区中。
可选的,在将所述贴图数据从所述gpu传输至所述贴图存储区的可见缓冲区中之后,所述方法还包括:将所述贴图数据从所述可见缓冲区上传至cpu的gpu场景缓冲区,并经过所述gpu场景缓冲区传输至所述gpu进行渲染。
可选的,经过所述gpu场景缓冲区传输至所述gpu进行渲染包括:将所述贴图数据从所述gpu场景缓冲区传输至所述gpu的复制存储区,从所述复制存储区传输至系统存储区的gpu场景缓冲区,从所述系统存储区的gpu场景缓冲区传输至所述cpu,在所述cpu中对所述贴图数据执行批渲染,得到几何数据;通过回调指令将所述几何数据通过所述gpu的g缓冲区通道传输至所述贴图存储区的g缓冲区中;从所述g缓冲区将所述几何数据传输至所述gpu进行渲染。
可选的,所述方法还包括:从所述gpu中获取光栅剔除数据;将所述光栅剔除数据从所述gpu传输至所述贴图存储区的光源列表中;从所述光源列表将所述光栅剔除数据传输至所述gpu进行渲染。
可选的,在移动设备构建渲染对象的层次z缓冲数据包括:从所述移动设备的系统存储器的深度缓冲区读取所述渲染对象上一帧的深度数据;将所述深度数据从所述深度缓冲区传输至所述移动设备的gpu,并在所述gpu中基于所述深度数据构建所述渲染对象的层次z缓冲数据。
上述终端提到的通信总线可以是外设部件互连标准(peripheralcomponentinterconnect,简称pci)总线或扩展工业标准结构(extendedindustrystandardarchitecture,简称eisa)总线等。该通信总线可以分为地址总线、数据总线、控制总线等。为便于表示,图中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
通信接口用于上述终端与其他设备之间的通信。
存储器可以包括随机存取存储器(randomaccessmemory,简称ram),也可以包括非易失性存储器(non-volatilememory),例如至少一个磁盘存储器。可选的,存储器还可以是至少一个位于远离前述处理器的存储装置。
上述的处理器可以是通用处理器,包括中央处理器(centralprocessingunit,简称cpu)、网络处理器(networkprocessor,简称np)等;还可以是数字信号处理器(digitalsignalprocessing,简称dsp)、专用集成电路(applicationspecificintegratedcircuit,简称asic)、现场可编程门阵列(field-programmablegatearray,简称fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
在本申请提供的又一实施例中,还提供了一种计算机可读存储介质,该计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行上述实施例中任一所述的贴图延迟渲染的数据驱动方法。
在本申请提供的又一实施例中,还提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述实施例中任一所述的贴图延迟渲染的数据驱动方法。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本申请实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(dsl))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质(例如固态硬盘solidstatedisk(ssd))等。
以上所述仅为本申请的较佳实施例而已,并非用于限定本申请的保护范围。凡在本申请的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本申请的保护范围内。
以上所述仅是本申请的具体实施方式,使本领域技术人员能够理解或实现本申请。对这些实施例的多种修改对本领域的技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所申请的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!