一种基于历史新闻报道的事件趋势预测方法
本发明涉及网络技术领域,尤其涉及一种基于历史新闻报道的事件趋势预测方法。
背景技术:
随着互联网的发展,大量新闻采用网络文本的方式进行报道,对于网络新闻进行有效率的挖掘是经济和社会发展的重要需求,其中对于某个新闻事件的未来走向进行预测是一个重要而又有很大难度的问题,具有巨大的经济和社会价值。现有的方法通常是由领域专家根据自己的经验进行推断,预测后续事件的发展,但由于每个人背景的不同和观点的不一致,预测结果经常会有较大差异,准确率也不能得到保证。
人类对于事件发展的预测通常是基于个人知识积累和历史事件的记录,采用算法模型进行预测通常也采用类似的思路,基于历史上类似事件的后续发展来预测当前事件的走向。
现有的趋势预测方法还是以领域专家的主观判断为主,缺少系统性的算法和模型支持,其不足是领域专家不唯一,且根据各自的背景、立场和倾向很可能做出不同的判断,无法给出较可靠的一致意见。对于事件的后续预测征询领域专家的意见,以专家的判断为准,缺少系统性的算法和模型支持。
但这里存在几个关键性的问题。一是没有两个事件是完全相同的,判断哪些历史事件是相似的,本身就存在较大的模糊性,而差异较大的事件又未必对于当前事件有参考价值;二是一个事件的走向具有一定的不确定性,多种可能的后续随着外部影响因素的变化又会导致不同结果,缺乏系统性的预测模型。
有研究从历史事件中寻找与当前事件的所处领域、时间地点、内容和当前发展几乎一致的场景,用该事件的后续走向来判断当前事件的未来发展。但很难找到和当前事件各方面因素都很一致的历史事件,导致无法使用历史信息进行判断。
因此,在大量历史事件积累的前提下,如何降低事件趋势预测的主观性,达到较高的准确率,在舆情分析领域显得尤为重要。
技术实现要素:
针对现有技术之不足,本发明提出一种基于历史新闻报道的事件趋势预测方法,所述方法包括:
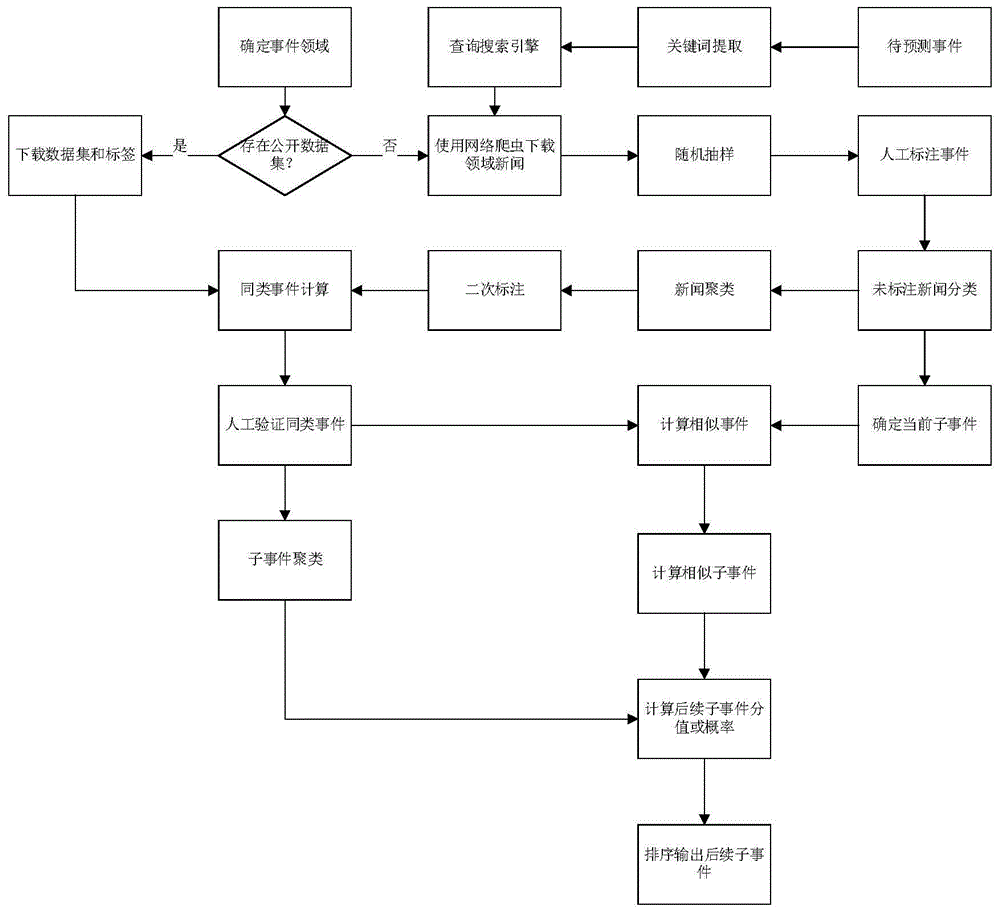
步骤1:首先确定待预测事件领域,在指定领域中,下载现有的公开新闻文本数据集和标签信息,若无公开数据集,则使用网络爬虫下载特定新闻网站的领域新闻。
步骤2:,当网络爬虫下载的数据集无标注信息时,需要通过人工标注加新闻分类/聚类的方法完成主要事件的标注;
步骤3:同类事件计算,在已完成主要事件标注的新闻中,使用设定的相似度阈值,在排除关键性3w信息后进行相似度计算,找到相似性事件,通过人工验证后将其标注为同类事件;
步骤4:子事件聚类,在每个同类事件内部,以关键性3w信息为主计算每两条新闻之间的相似度,将描述同一具体事件的新闻聚类为一个子事件;
步骤5:对步骤4得到的子事件之间,采用半人工标注的方式,根据事件内容的关联性和时间先后顺序,建立子事件之间的上下文联系,用有向边表示,从归因事件指向后续事件,获得每个子事件后续事件分布信息;
步骤6:对于待预测的新事件,获取核心的描述新闻,或者从公开信息源采集与所述待预测新事件相关的新闻报道,并对没有标注信息的新闻报道进行标注。具体方法为从待预测新事件中提取关键词,再根据提取的关键词在公开信息源中爬取搜索结果;
步骤7:确定所述待预测新事件的当前子事件,对于所述待预测新事件进行步骤4操作,建立子事件,并找到当前子事件;
步骤8:计算相似事件,在排除关键性3w信息后,计算所述待预测新事件与所有同类事件的相似度,取相似度超过设定的第二阈值的同类事件作为备选的相似事件,组成备选相似事件库;
步骤9:计算相似子事件,计算所述当前子事件和相似事件中的子事件的相似度,对于低于第三阈值的予以舍弃。
步骤10:综合步骤8得到的所述待预测新事件与相似事件的相似度、步骤9得到的当前子事件与相似事件中的子事件相似度,以及相似事件中的所述子事件后续事件分布,计算当前子事件的后续事件分值;
步骤11:对于可能的后续事件按照概率从大到小排序,并列举前5个可能后续事件作为对于当前子事件的后续发展趋势预测。
根据一种优选的实施方式,进行人工标注的方法包括:
步骤21:从下载新闻中随机抽取较小数量(如1000条),由专门的标注人员对其进行阅读,标明其涉及的主要事件;
步骤22:如该条新闻的事件在前序新闻中已提到,将其并入同一事件中,否则新建一个独立的种子事件;
步骤23:使用已标注事件中的新闻作为基准,将未标注新闻与其计算相似度,对于相似度达到第一阈值的新闻归入同一事件,有多个事件都足够相似时,取相似度最高的事件;一般相似度的第一阈值设置为0.75。
步骤24:对于尚未划分到其他事件中的新闻,采用聚类方法对其进行聚类;
步骤25:在聚类结果中人工手动选择较大的类别进行人工二次标注,选择适当的事件加入现有集合;
步骤26:当剩余新闻数量少于设定比例或新闻条数少于设定条数,停止聚类和人工二次标注,否则重复步骤24至步骤26,并调整聚类参数。
根据一种优选的实施方式,步骤6具体还包括:
步骤61:从事件描述中提取关键的描述词;
步骤62:使用关键词查询主流搜索引擎,获得相关报道的url;
步骤63:使用爬虫获取报道内容;
步骤64:重复步骤2的步骤对数据进行清洗,不过仅处理和当前事件相关的内容,忽略其他搜索引擎返回的噪声数据。
本发明的有益效果在于:
1、基于历史新闻报道,使用一定具有明确判断标准的人工标注信息,作为后续事件预测的依据,一方面避免了领域专家主观判断的倾向性和随意性,另一方面能够充分利用相似场景中的不同发展走向,给出更全面的趋势预测。
2、结合自动的算法,从多个历史事件中提取类似的场景信息,较为完整地找到可能的后续演化可能,并定量地计算各种可能的相应得分或概率,辅助利益相关方对未来发展进行不确定性分析。
附图说明
图1是本发明事件预测方法的流程图;
图2是本发明同类事件和待预测新事件的示意图;和
图3是本发明子事件之间上下文联系图的一个示例。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
基于网络新闻进行有效数据挖掘,用历史信息预测未来事件的发展趋势是有很大现实应用价值的一项工作,现有方法一般是由领域专家基于其经验进行人工预测,具有主观性强、不容易得到一致意见、可靠性不确定等缺点。本发明基于历史新闻报道,使用一定具有明确判断标准的人工标注信息,结合自动的算法,从多个历史事件中提取类似的场景信息,较为完整地找到可能的后续演化可能,并定量地计算各种可能的相应得分或概率。相比人工分析的方式,这种方法能够更好地覆盖各种事件发展趋势,并获得更高的预测精确度,以更好地应对可能发生的各种后续事件。
下面结合附图对本发明的技术方案进行详细描述。
图1是本发明事件预测方法的流程图;如图1所示,本发明提出的一种基于历史新闻报道的事件趋势预测方法,方法包括:
步骤1:首先确定待预测事件领域,在指定领域中,下载现有的公开新闻文本数据集和标签信息,若无公开数据集,则使用网络爬虫下载特定新闻网站的领域新闻。对于公开新闻文本集,一般具有是否属于同一事件的标注信息。待预测事件是指:要进行未来发展预测的一个包含所有相关新闻的较大规模事件。
步骤2:,当网络爬虫下载的数据集无标注信息时,需要通过人工标注加新闻分类/聚类的方法完成主要事件的标注。具体标注方法如下:
步骤21:从下载新闻中随机抽取较小数量新闻报道,由专门的标注人员对其进行阅读,标明其涉及的主要事件;一般选取1000条数据。
步骤22:如该条新闻的事件在前序新闻中已提到,将其并入同一事件中,否则新建一个独立的种子事件。
步骤23:使用已标注事件中的新闻作为基准,将未标注新闻与其计算相似度,对于相似度达到第一阈值的新闻归入同一事件,有多个事件都足够相似时,取相似度最高的事件;一般相似度的第一阈值设置为0.75。
步骤24:对于尚未划分到其他事件中的新闻,采用聚类方法对其进行聚类。
如k-means聚类和层次化集聚等方法对其进行聚类。
步骤25:在聚类结果中人工手动选择较大的类别进行人工二次标注,选择适当的事件加入现有集合;较大类别指大于100条数据的事件。
步骤26:当剩余新闻数量少于设定比例或新闻条数少于设定条数,停止聚类和人工二次标注,否则重复步骤24至步骤26,并调整聚类参数。
少于设定比例指不超过总量的10%,设定条数一般设定为10条。调整聚类参数是指通过降低k-means的参数k或者层次化集聚的相似度阈值,以获得更少的类别,或把更多的新闻合并进入现有类别。
图2是是本发明同类事件和待预测新事件的示意图。
步骤3:同类事件计算,在已完成主要事件标注的新闻中,使用设定的相似度阈值。一般可取0.8。在排除关键性3w信息后进行相似度计算,找到相似性事件,通过人工验证后将其标注为同类事件;同类事件是指的是包含若干新闻报道的一个较大的事件,内部还可能有包含若干具有不同3w信息的子事件。
相似度计算公式使用向量夹角的余弦,相似度取值范围0~1。
其中,d1、d2分别指待计算相似度的两个文档,
文本特征表达方式使用词嵌入表达,可使用的模型包括word2vec的skipgram和glove等,向量维度为200。
关键性3w信息包括:who人物、when时间、where地点。
步骤4:子事件聚类,在每个同类事件内部,以关键性3w信息为主计算每两条新闻之间的相似度,将描述同一具体事件的新闻聚类为一个子事件。为了趋势预测的准确度,同类事件的新闻条数不能太少,一般应不少于20条。
步骤5:对步骤4得到的子事件之间,采用半人工标注的方式,根据事件内容的关联性和时间先后顺序,建立子事件之间的上下文联系,用有向边表示,从归因事件指向后续事件,获得每个子事件后续事件分布信息;归因事件指发生时间较早的事件,后续时间指发生时间较晚的事件。步骤5的作用是:建立一个或者一类事件中的子事件网络,后续就是基于历史事件的这些信息,在新的事件中根据已出现子事件的信息去预测后续可能发生的其他子事件以及出现可能性。
如图3所示为子事件之间上下文联系图的一个示例。
步骤6:对于待预测的新事件,获取核心的描述新闻,或者从公开信息源采集与待预测新事件相关的新闻报道,并对没有标注信息的新闻报道进行标注。具体方法为从待预测新事件中提取关键词,再根据提取的关键词在公开信息源中爬取搜索结果。核心的描述新闻是指:跟一个事件相关的新闻报道中,最早或者描述最重要子事件的相关报道。主要通过人工的方式获取。具体的,包括以下步骤:
步骤61:从事件描述中提取关键的描述词;
步骤62:使用关键词查询主流搜索引擎,获得相关报道的url;
步骤63:使用爬虫获取报道内容;
步骤64:重复步骤2的步骤对数据进行清洗,不过仅处理和当前事件相关的内容,忽略其他搜索引擎返回的噪声数据。这样可以提高数据清洗的效率,缩短标注时间。
步骤61至步骤64的作用在于:用跟历史事件相似的方法,取得待预测的事件当前已有的新闻报道并进行聚类,作为建立子事件的前序操作。
步骤7:确定待预测新事件的当前子事件,对于待预测新事件进行步骤4操作,建立子事件,并找到当前子事件。
当前子事件指发生时间最近的子事件。本步骤作用在于:确定该对当前哪个事件进行后续发展预测。
步骤8:计算相似事件,在排除关键性3w信息后,计算待预测新事件与所有同类事件的相似度,取相似度超过设定的第二阈值的同类事件作为备选的相似事件,组成备选相似事件库。设定的第二阈值一般取为0.5。
本发明就是基于这些同类事件的演化情况去预测当前和未来的类似事件。
步骤9:计算相似子事件,计算当前子事件和相似事件中的子事件的相似度,对于低于第三阈值的予以舍弃。
第三阈值一般设定为0.5。本步骤的作用是:降低步骤10需要处理的子事件数量。
步骤10:综合步骤8得到的待预测新事件与相似事件的相似度、步骤9得到的当前子事件与相似事件中的子事件相似度,以及相似事件中的子事件后续事件分布,计算当前子事件的后续事件分值,其数学表示如下:
其中,其中event为当前待分析的事件,包括所有子事件和相应新闻报道内容,current指当前事件中最新的当前子事件,事件i指与event足够相似的所有历史事件,事件j为事件i中与current最相似的若干子事件,subsequent是其中一个或几个子事件的后续子事件,sim指事件或子事件之间的相似度,out_degree指子事件j在该历史事件中的后续子事件数,参数α指该事件的加权系数,对于没有同类事件的历史事件为1,而如果有较多的同类事件时可以取更高的权重,出于简化可以取2。
步骤11:对于可能的后续事件按照概率从大到小排序,并列举前n个可能后续事件作为对于当前子事件的后续发展趋势预测。n可根据实际情况进行调整,本发明一个实施例中n=5。
如果需要输出后续子事件的发生概率而不是分值,可以使用softmax算子将各个可能得到后续子事件的分值转化为概率。
需要注意的是,上述具体实施例是示例性的,本领域技术人员可以在本发明公开内容的启发下想出各种解决方案,而这些解决方案也都属于本发明的公开范围并落入本发明的保护范围之内。本领域技术人员应该明白,本发明说明书及其附图均为说明性而并非构成对权利要求的限制。本发明的保护范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!