数据处理方法、装置、存储介质及计算机设备与流程
1.本发明涉及图像领域,具体而言,涉及一种数据处理方法、装置、存储介质及计算机设备。
背景技术:
2.增强现实(augmented reality,简称为ar)试鞋是一种立足于计算机视觉与图形学的技术,可以为鞋类行业提供新零售的解决方案。ar试鞋的技术中,检测2d图像中的脚部关键点通常采用监督学习方法,但是该监督学习方法需要丰富的训练数据以增强检测算法的准确性以及鲁棒性。训练数据包含试鞋图像及图像中2d脚部关键点的像素位置,相关技术中,获取训练数据采用逐帧标注的全人工方法、标注关键帧的半自动方法或者全自动的虚拟渲染方法。但是上述获取训练数据的方法存在多种问题,例如,人工标注的方法存在成本不稳定、数据质量不可控的问题,而全自动的虚拟渲染方法存在生成数据缺乏真实性、样本易趋向同一性导致训练价值不高的问题。
3.针对上述的问题,目前尚未提出有效的解决方案。
技术实现要素:
4.本发明实施例提供了一种数据处理方法、装置、存储介质及计算机设备,以至少解决获取训练数据存在成本高,训练数据质量不高的技术问题。
5.根据本发明实施例的一个方面,提供了一种数据处理方法,包括:采集物理目标对象的色彩图像及深度图像;根据所述深度图像,确定所述物理目标对象的三维重建模型;根据所述三维重建模型,确定虚拟目标对象在预定坐标系下的第一位姿,以及确定虚拟物件在所述预定坐标系下的第二位姿;根据所述第一位姿,将所述虚拟目标对象的3d关键点投影到图像平面得到2d关键点,以及根据所述第二位姿以及所述色彩图像绘制所述虚拟物件在所述图像平面中与所述物理目标对象的交互图像。
6.可选地,在所述深度图像为多个的情况下,根据所述多个深度图像,确定所述物理目标对象的三维重建模型,包括:将所述多个深度图像转换为多片三维点云;根据所述多片三维点云建立点云位姿图,其中,所述多片三维点云中的每片点云为所述点云位姿图中的节点;对所述点云位姿图进行配准,得到所述物理目标对象的三维重建模型。
7.可选地,对所述点云位姿图进行配准,得到所述物理目标对象的三维重建模型,包括:采用迭代最近点icp方法,对所述点云位姿图进行序列化配准,得到所述点云位姿图的序列化配准结果图;对所述序列化配准结果图进行全局配准,得到所述物理目标对象的三维重建模型,其中,所述三维重建模型中的每片点云的位姿为在全局坐标系下的位姿。
8.可选地,根据所述三维重建模型,确定虚拟目标对象在预定坐标系下的第一位姿,包括:获取所述三维重建模型在所述预定坐标系下的第三位姿;确定所述虚拟目标对象变换到所述三维重建模型的变换矩阵;根据所述第三位姿和所述变换矩阵,确定所述虚拟目标对象在所述预定坐标系下的所述第一位姿。
9.可选地,确定所述虚拟目标对象变换到所述三维重建模型的变换矩阵,包括:基于快速点特征直方图fpfh的点云粗配准方法和点面icp的点云细配准方法,将所述虚拟目标对象与所述三维重建模型进行对齐,得到对齐参数;根据所述对齐参数,确定所述虚拟目标对象变换到所述三维重建模型的变换矩阵。
10.可选地,确定虚拟物件在所述预定坐标系下的第二位姿,包括:获取所述虚拟物件与所述虚拟目标对象的对齐关系;根据所述第一位姿和所述对齐关系,确定所述虚拟物件在所述预定坐标系下的所述第二位姿。
11.可选地,根据所述第一位姿,将所述虚拟目标对象的3d关键点投影到图像平面得到2d关键点,以及根据所述第二位姿以及所述色彩图像绘制所述虚拟物件在所述图像平面中与所述物理目标对象的交互图像,包括:根据所述第一位姿,以及预定成像方法,将所述虚拟目标对象的3d关键点投影到图像平面得到2d关键点;根据所述第二位姿以及所述色彩图像,调用预定渲染引擎对所述虚拟物件在所述图像平面中与所述物理目标对象交互后的结果进行绘制,得到所述虚拟物件在所述图像平面中与所述物理目标对象的交互图像。
12.可选地,根据所述第二位姿以及所述色彩图像,调用预定渲染引擎对所述虚拟物件在所述图像平面中与所述物理目标对象交互后的结果进行绘制,得到所述虚拟物件在所述图像平面中与所述物理目标对象的交互图像,包括:在根据所述第二位姿以及所述色彩图像,调用预定渲染引擎对所述虚拟物件在所述图像平面中与所述物理目标对象的交互结果进行绘制时,通过替换背景和/或调整光源的方法,得到所述虚拟物件在所述图像平面的中与所述物理目标对象的多张交互图像。
13.可选地,在采集的所述色彩图像及深度图像为所述物理目标对象不同状态下和/或不同角度下的多个色彩图像及多个深度图像的情况下,分别得到所述物理目标对象不同状态下和/或不同角度下的2d关键点和与所述虚拟物件的交互图像。
14.可选地,根据所述2d关键点和所述交互图像,生成训练数据;获取与多种物理目标对象对应的不同的所述训练数据;采用与多种物理目标对象对应的不同的所述训练数据进行机器训练,得到关键点检测模型。
15.根据本发明实施例的另一方面,还提供了一种数据处理方法,包括:接收输入图像,其中,所述输入图像中包括物理目标对象;采用关键点检测模型,检测出所述输入图像中所述物理目标对象的2d关键点,其中,所述关键点检测模型采用多组训练数据通过机器训练得到,所述多组训练数据中的数据包括:所述物理目标对象与物件的交互图像和该交互图像中的2d关键点,所述2d关键点根据虚拟目标对象在预定坐标系下的第一位姿,将所述虚拟目标对象的3d关键点投影到图像平面得到,所述交互图像根据虚拟目标对象在所述预定坐标系下的第二位姿和采集的物理目标对象的色彩图像,绘制所述虚拟物件在所述图像平面得到,所述第一位姿,所述第二位姿根据三维重建模型确定的,所述三维重建模型根据采集的物理目标对象的多个深度图像融合得到。
16.根据本发明实施例的又一方面,还提供了一种数据处理方法,包括:获取多组训练数据,其中,所述多组训练数据中的数据包括:物理目标对象与虚拟物件的交互图像和该交互图像中的2d关键点,所述2d关键点根据虚拟目标对象在预定坐标系下的第一位姿,将所述虚拟目标对象的3d关键点投影到图像平面得到,所述交互图像根据虚拟物件在所述预定坐标系下的第二位姿和采集的物理目标对象的色彩图像,绘制所述虚拟物件在所述图像平
面得到,所述第一位姿,所述第二位姿根据三维重建模型确定的,所述三维重建模型根据采集的物理目标对象的多个深度图像融合得到;采用所述多组训练数据进行机器训练,得到关键点检测模型。
17.根据本发明实施例的再一方面,还提供了一种数据处理装置,包括:采集模块,用于采集物理目标对象的色彩图像及深度图像;第一处理模块,用于根据所述多个深度图像,融合得到所述物理目标对象的三维重建模型;确定模块,用于根据所述三维重建模型,确定虚拟目标对象在预定坐标系下的第一位姿,以及确定虚拟物件在所述预定坐标系下的第二位姿;第二处理模块,用于根据所述第一位姿,将所述虚拟目标对象的3d关键点投影到图像平面得到2d关键点,以及根据所述第二位姿以及所述色彩图像绘制所述虚拟物件在所述图像平面中与所述物理目标对象的交互图像。
18.根据本发明实施例的再一方面,还提供了一种数据处理装置,包括:接收模块,用于接收输入图像,其中,所述输入图像中包括物理目标对象;检测模块,用于采用关键点检测模型,检测出所述输入图像中所述物理目标对象的2d关键点,其中,所述关键点检测模型采用多组训练数据通过机器训练得到,所述多组训练数据中的数据包括:所述物理目标对象与物件的交互图像和该交互图像中的2d关键点,所述2d关键点根据虚拟目标对象在预定坐标系下的第一位姿,将所述虚拟目标对象的3d关键点投影到图像平面得到,所述交互图像根据虚拟目标对象在所述预定坐标系下的第二位姿和采集的物理目标对象的色彩图像,绘制所述虚拟目标对象在所述图像平面得到,所述第一位姿,所述第二位姿根据三维重建模型确定的,所述三维重建模型根据采集的物理目标对象的多个深度图像融合得到。
19.根据本发明实施例的再一方面,还提供了一种数据处理装置,包括:获取模块,用于获取多组训练数据,其中,所述多组训练数据中的数据包括:物理目标对象与虚拟物件的交互图像和该交互图像中的2d关键点,所述2d关键点根据虚拟目标对象在预定坐标系下的第一位姿,将所述虚拟目标对象的3d关键点投影到图像平面得到,所述交互图像根据虚拟物件在所述预定坐标系下的第二位姿和采集的物理目标对象的色彩图像,绘制所述虚拟物件在所述图像平面得到,所述第一位姿,所述第二位姿根据三维重建模型确定的,所述三维重建模型根据采集的物理目标对象的多个深度图像融合得到;训练模块,用于采用所述多组训练数据进行机器训练,得到关键点检测模型。
20.根据本发明实施例的再一方面,还提供了一种存储介质,所述存储介质包括存储的程序,其中,在所述程序运行时控制所述存储介质所在设备执行上述任意一项所述的数据处理方法。
21.根据本发明实施例的再一方面,还提供了一种计算机设备,包括:存储器和处理器,所述存储器存储有计算机程序;所述处理器,用于执行所述存储器中存储的计算机程序,所述计算机程序运行时使得所述处理器执行上述任意一项所述的数据处理方法。
22.根据本发明实施例的再一方面,还提供了一种数据处理方法,包括:采集脚部的色彩图像及深度图像;根据所述深度图像,确定所述脚部的三维重建脚模型;根据所述三维重建脚模型,确定虚拟脚在预定坐标系下的第一位姿,以及确定虚拟鞋在所述预定坐标系下的第二位姿;根据所述第一位姿,将所述虚拟脚的3d脚部关键点投影到图像平面得到2d脚部关键点,以及根据所述第二位姿以及所述色彩图像绘制所述虚拟鞋在所述图像平面的试穿图像。
23.在本发明实施例中,采用采集物理目标对象的色彩图像及深度图像的方式,通过融合多个深度图像得到物理目标对象的三维重建模型,根据三维重建模型,确定虚拟目标对象在预定坐标系下的第一位姿,以及确定虚拟物件在预定坐标系下的第二位姿,并根据第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到2d关键点,以及根据第二位姿以及色彩图像绘制虚拟物件在图像平面中与物理目标对象的交互图像,达到了根据物理目标对象的图像生成标注了2d关键点的交互图像的目的,从而实现了降低获取训练数据的成本,提高训练数据质量的技术效果,进而解决了获取训练数据存在成本高,训练数据质量不高的技术问题。
附图说明
24.此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
25.图1是根据本发明实施例的一种用于实现数据处理方法的计算机终端硬件结构框图;
26.图2是根据本发明实施例1的数据处理方法一的流程图;
27.图3是根据本发明实施例1的数据处理方法二的流程图;
28.图4是根据本发明实施例1的数据处理方法三的流程图;
29.图5是根据本发明实施例1的数据处理方法四的流程图;
30.图6是根据本发明可选实施方式的训练数据获取流程示意图;
31.图7是根据本发明可选实施方式的获取三维重建模型示意图;
32.图8是根据本发明可选实施方式对齐虚拟鞋、虚拟脚与重建脚的示意图;
33.图9是根据本发明实施例2的数据处理装置一的结构框图;
34.图10是根据本发明实施例3的数据处理装置二的结构框图;
35.图11是根据本发明实施例4的数据处理装置三的结构框图;
36.图12是根据本发明实施例5的数据处理装置四的结构框图;
37.图13是根据本发明实施例的一种计算机终端的结构框图。
具体实施方式
38.为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
39.需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品
或设备固有的其它步骤或单元。
40.首先,在对本技术实施例进行描述的过程中出现的部分名词或术语适用于如下解释:
41.深度学习(deep learning):深度学习,或称为模型训练,是指多层神经网络上运用各种机器学习算法解决图像,文本等各种问题的算法集合。深度学习从大类上可以归入神经网络,但在具体实现上有许多变化。深度学习的核心是特征学习,旨在通过分层网络获取分层次的特征信息,从而解决以往需要人工设计特征的重要难题。
42.6dof:6自由度位姿,指物体在空间中沿x、y、z轴的平移和绕轴的转动。
43.pnp:perspective-n-point,n点透视(已知2d-3d的点对,求解6dof位姿)。
44.icp:iterative closest point,迭代最近点配准算法,针对成对点云配准。
45.pose graph optimization:位姿图优化,针对全局点云配准。
46.3d关键点:虚拟目标对象三维模型上的多个关键点。
47.2d关键点:3d关键点在成像平面上的2d投影点。
48.虚拟目标对象:美工制作的目标对象的3d模型。
49.虚拟物件:美工制作的物件的3d模型,与虚拟目标对象已完成参数化对齐。
50.实施例1
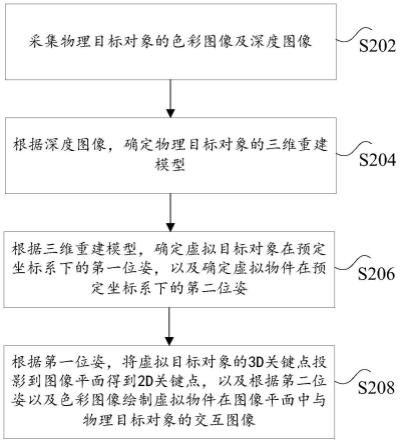
51.根据本发明实施例,还提供了一种数据处理方法实施例,需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
52.本技术实施例1所提供的方法实施例可以在移动终端、计算机终端或者类似的运算装置中执行。图1示出了一种用于实现数据处理方法的计算机终端(或移动设备)的硬件结构框图。如图1所示,计算机终端10(或移动设备)可以包括一个或多个(图中采用102a、102b,
……
,102n来示出)处理器102(处理器102可以包括但不限于微处理器mcu或可编程逻辑器件fpga等的处理装置)、用于存储数据的存储器104、以及用于通信功能的传输装置。除此以外,还可以包括:显示器、输入/输出接口(i/o接口)、通用串行总线(usb)端口(可以作为bus总线的端口中的一个端口被包括)、网络接口、电源和/或相机。本领域普通技术人员可以理解,图1所示的结构仅为示意,其并不对上述电子装置的结构造成限定。例如,计算机终端10还可包括比图1中所示更多或者更少的组件,或者具有与图1所示不同的配置。
53.应当注意到的是上述一个或多个处理器102和/或其他数据处理电路在本文中通常可以被称为“数据处理电路”。该数据处理电路可以全部或部分的体现为软件、硬件、固件或其他任意组合。此外,数据处理电路可为单个独立的处理模块,或全部或部分的结合到计算机终端10(或移动设备)中的其他元件中的任意一个内。如本技术实施例中所涉及到的,该数据处理电路作为一种处理器控制(例如与接口连接的可变电阻终端路径的选择)。
54.存储器104可用于存储应用软件的软件程序以及模块,如本发明实施例中的数据处理方法对应的程序指令/数据存储装置,处理器102通过运行存储在存储器104内的软件程序以及模块,从而执行各种功能应用以及数据处理,即实现上述的应用程序的漏洞检测方法。存储器104可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器104可进一步包括相
对于处理器102远程设置的存储器,这些远程存储器可以通过网络连接至计算机终端10。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
55.传输装置用于经由一个网络接收或者发送数据。上述的网络具体实例可包括计算机终端10的通信供应商提供的无线网络。在一个实例中,传输装置包括一个网络适配器(network interface controller,nic),其可通过基站与其他网络设备相连从而可与互联网进行通讯。在一个实例中,传输装置可以为射频(radio frequency,rf)模块,其用于通过无线方式与互联网进行通讯。
56.显示器可以例如触摸屏式的液晶显示器(lcd),该液晶显示器可使得用户能够与计算机终端10(或移动设备)的用户界面进行交互。
57.在上述运行环境下,本技术提供了如图2所示的数据处理方法。图2是根据本发明实施例1的数据处理方法一的流程图。如图2所示,该方法包括如下步骤:
58.步骤s202,采集物理目标对象的色彩图像及深度图像;
59.步骤s204,根据多个深度图像,融合得到物理目标对象的三维重建模型;
60.步骤s206,根据三维重建模型,确定虚拟目标对象在预定坐标系下的第一位姿,以及确定虚拟物件在预定坐标系下的第二位姿;
61.步骤s208,根据第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到2d关键点,以及根据第二位姿以及色彩图像绘制虚拟物件在图像平面中与物理目标对象的交互图像。
62.通过上述步骤,达到了根据物理目标对象的图像建立三维重建模型,并依据建立的三维重建模型生成标注了2d关键点的与物理目标对象与虚拟物件的交互图像的目的,从而实现了降低获取训练数据的成本,提高训练数据质量的技术效果,进而解决了获取训练数据存在成本高,训练数据质量不高的技术问题。
63.作为一种可选地实施例,在采集物理目标对象的图像的情况下,物理目标对象图像的获取可以通过相机拍摄、矢量图等获得,采用上述方法可以准确生成包括2d关键点的虚拟物件在图像平面与物理目标对象的交互图像,并使用上述图像作为训练数据对关键点检测模型进行训练。根据本实施例得到的虚拟物件在物理目标对象上的交互图像自带2d关键点的标注,避免了人工标注2d关键点时的低效以及错误率难以把控的问题。同时,由于在生成虚拟物件与物理目标对象的交互图像的过程中使用的是物理目标对象的真实数据,因而生成的虚拟物件与物理目标对象的交互图像更加逼真,作为训练数据能够起到更好的训练效果。
64.作为一种可选的实施例,采集物理目标对象的色彩图像及深度图像时,只要能够从多角度获取物理目标对象的信息即可。因此,采集的色彩图像的数量可以为一张也可以为多张,深度图像也可以为一张或多张。例如,采用物理目标对象的色彩图像时,如果采用全景相机对物理目标对象进行拍摄时,可以得到物理目标对象多个视角的信息;又如果采用非全景相机对物理目标对象进行拍摄时,可以通过对物理目标对象从多个角度进行多次拍摄,得到物理目标对象多个视角的信息。采用深度图像时,也可以采用上述采集色彩图像相同的处理方式。例如,采集色彩图像和采集深度图像可以同时进行。
65.作为一种可选的实施例,在采集的色彩图像及深度图像为物理目标对象不同状态下和/或不同角度下的多个色彩图像及多个深度图像的情况下,分别得到物理目标对象不
同状态下和/或不同角度下的2d关键点和与物理目标对象的交互图像。采用多种物理目标对象的图像数据并通过三维重建模型的对应关系获取准确的2d关键点,以及在绘制虚拟物件与物理目标对象的交互图像时得到不同状态(例如物理目标对象为脚时,脚的不同状态包括光脚或者穿着袜子的状态)、不同类型、不同姿态、不同视角下的物理目标对象与虚拟物件的交互图像,可为后续的关键点监测模型的训练过程提供准确且多样的训练数据,弥补作为训练数据的虚拟物件在图像平面中与物理目标对象的交互图像经常缺少某些特殊视角的问题。例如,脚尖视角、脚后跟视角、侧平视角的穿鞋图像在现有的图像训练集中非常少,本实施例可以有效弥补此类训练数据的缺失,提供更加丰富的训练素材。
66.点云数据能够以较小的存储成本获得物体的准确的拓扑结构和几何结构,同时,在拍摄物理目标对象的过程中,单次扫描可能不太容易得到物理目标对象的完整几何信息,需要从不同角度对物理目标对象进行多次拍照,因此可以采用配准与多张物理目标对象图像对应的多组点云的方式建立物理目标对象对应的三维重建模型。作为一种可选的实施例,在深度图像为多个的情况下,根据多个深度图像融合得到物理目标对象的三维重建模型可以通过如下可选方式实现:将多个深度图像转换为多片三维点云,根据多片三维点云建立点云位姿图,其中,多片三维点云中的每片点云为点云位姿图中的节点,然后对点云位姿图进行配准,得到物理目标对象的三维重建模型。
67.作为一种可选的实施例,上述预定坐标系的类型可以多种,例如,上述深度图像是采用相同拍摄得到的,涉及相机的坐标系有多种,比如,包括像素平面坐标系(u,v)、图像平面坐标系、图像物理坐标系(x,y)、相机坐标系(xc,yc,zc)和世界坐标系。此处采用相机坐标系。相机坐标系:是以相机的聚焦中心为原点,以光轴为z轴建立的三维直角坐标系。相机坐标系的原点为相机的光心,x轴与y轴与图像的x、y轴平行,z轴为相机光轴,它与图形平面垂直。光轴与图像平面的交点,即为图像坐标系的原点,图像坐标系为二维直角坐标系。
68.作为一种可选的实施例,可以通过如下方式对点云位姿图进行配准,得到物理目标对象的三维重建模型:采用迭代最近点icp方法,对点云位姿图进行序列化配准,得到点云位姿图的序列化配准结果图;对序列化配准结果图进行全局配准,得到物理目标对象的三维重建模型,其中,三维重建模型中的每片点云的位姿为在全局坐标系下的位姿。由于拍摄物理目标对象得到的图像的视角以及遮挡关系不同,各图像对应的点云并不在同一坐标系中,对点云位姿图进行序列化配准和全局配准,可以将物理目标对象在不同拍摄角度下拍摄得到的位姿数据变换到同一预定坐标系中,实现物理目标对象的三维重建模型的构建。
69.作为一种可选的实施例,在通过多张深度图像得到物理目标对象的三维重建模型时,由于多张深度图像都有分别对应自身的相机坐标系,而为了建立准确的三维重建模型,可以为该多张深度图像选定一个统一的坐标系,用于对多张深度图像进行全局配准。选定该统一坐标系的方式可以多种,例如,可以选择拍摄的第一张深度图像时的相机坐标系为该统一坐标系,也可以选择其他时间点拍摄深度图像时对应的相机坐标系为该统一坐标系,可以根据需要灵活选择。
70.作为一种可选的实施例,根据三维重建模型确定虚拟目标对象在预定坐标系下的第一位姿可以通过如下方式实现:获取三维重建模型在预定坐标系下的第三位姿;确定虚拟目标对象变换到三维重建模型的变换矩阵;根据第三位姿和变换矩阵,确定虚拟目标对
象在预定坐标系下的第一位姿。具体的,在虚拟目标对象与三维重建模型已经对齐的情况下,可以得到虚拟目标对象与三维重建模型的变换矩阵。三维重建模型在预定坐标系下的第三位姿可以在全局配准三维重建模型的过程中求解得到,因此可以以三维重建模型为基准,通过变换矩阵变换虚拟目标对象,得到虚拟目标对象在预定坐标系下的位姿。
71.快速点特征直方图(fast point feature histograms,简称fpfh)是点特征直方图(point feature histograms,简称pfh)计算方式的简化形式,通过分别计算查询点的k邻域中每一个点的简化点特征直方图,然后通过公式将所有的spfh加权成最后的快速点特征直方图。fpfh可以用于三维点云之间的配准。迭代最近点算法(iterative closest point,简称icp)可以分别在带匹配的目标点云和源点云中,按照一定的约束条件找到最邻近点,然后计算出较优匹配参数,使得误差函数最小。fpfh方法和icp方法均可以实现三维点云之间的配准。
72.作为一种可选的实施例,可以基于快速点特征直方图fpfh的点云粗配准方法和点面icp的点云细配准方法,将虚拟目标对象与三维重建模型进行对齐,得到对齐参数,然后根据对齐参数,确定虚拟目标对象变换到三维重建模型的变换矩阵。通过变换矩阵可以对虚拟目标对象进行变换,得到虚拟目标对象在预定坐标系下的位姿。
73.作为一种可选的实施例,在确定了三维重建模型的位姿,并将虚拟目标对象与三维重建模型进行对齐后,依据虚拟物件与虚拟目标对象对齐关系,实现虚拟物件、虚拟目标对象和三维重建模型的三者对齐。其中,虚拟目标对象与虚拟物件的对齐关系可以预先定义好。当虚拟目标对象与三维重建模型实现对齐之后,根据预先定义好的对齐关系调整虚拟物件的数据,实现虚拟物件与三维重建模型的对齐,得到虚拟物件在预定坐标系下的位姿。
74.作为一种可选的实施例,可以通过如下方式确定虚拟物件在预定坐标系下的第二位姿:获取虚拟物件与虚拟目标对象的对齐关系;根据第一位姿和对齐关系,确定虚拟物件在预定坐标系下的第二位姿。
75.关键点监测模型的训练数据包括2d关键点和虚拟物件的交互图像。作为一种可选的实施例,可以通过下方式获取到上述训练数据:根据第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到2d关键点;还可以根据第二位姿以及色彩图像绘制虚拟物件在图像平面中与物理目标对象的交互图像。具体的,可以采用如下方式得到2d图像上的关键点:根据第一位姿,以及相机成像方法,将虚拟目标对象的3d关键点投影到图像平面得到2d关键点。还可以采用如下方式得到虚拟物件在图像平面中与物理目标对象的交互图像:根据第二位姿以及色彩图像,调用预定渲染引擎对虚拟物件在图像平面中与物理目标对象的交互结果进行绘制,得到虚拟物件在图像平面中与物理目标对象的交互图像。
76.作为一种可选的实施方式,可以基于透视原理的将虚拟目标对象的3d关键点投影到图像平面得到2d关键点,得到的图像即自带关键点的标注,不需要人工再进行标注,标注效果准确且大大地节省人力。
77.举例而言,可以调用预定渲染引擎,例如blender,根据虚拟物件在预定坐标系中的第二位姿绘制虚拟物件在图像平面中与物理目标对象的交互结果。由于虚拟物件已经与根据物理目标对象生成的三维重建模型对齐,因而根据虚拟物件绘制得到的与物理目标对象的交互图像会十分逼真,提高了生成的虚拟物件在图像平面与物理目标对象交互效果图
像的真实性。此外,在使用渲染引擎绘制虚拟物件在图像平面与物理目标对象交互的效果图像时,还可以通过替换背景和/或调整光源的方法,得到虚拟物件在图像平面的多张与物理目标对象交互的图像。通过替换背景和/或调整光源,可以大大丰富能够得到的虚拟物件与物理目标对象交互的图像素材,一方面可以避免大量测量物理目标对象并生成与物理目标对象交互的虚拟物件图像的工作量,另一方面还可以得到多种包括不同类型与物理目标对象交互环境的图像素材,丰富了训练数据库,可以使得对关键点检测模型的训练取得更好的训练效果。
78.作为一种可选的实施例,根据2d关键点和交互图像,生成训练数据;获取与多种物理目标对象对应的不同的训练数据;采用与多种物理目标对象对应的不同的训练数据进行机器训练,得到关键点检测模型。通过本实施例,可以实现使用丰富的包括2d关键点和交互图像的训练数据训练关键点检测模型的目的,使用的训练数据中的2d关键点不依赖人工标注的主观判断,以关键点检测模型的sota检测结果作为标准,本实施例提供的方法的2d关键点标注精度可达90%以上。此外还可以通过丰富训练数据库帮助关键点检测模型取得更好的训练效果。
79.作为一种可选的实施例,物理目标对象和虚拟物件可以包括以下任意之一的组合:脚和虚拟鞋;头和虚拟帽子;手腕和虚拟手环;人体和虚拟服饰;面部和虚拟面部饰物。不同的目标对象与虚拟物件在不同场景下可以采用不同的方式进行交互,例如,生成脚试穿虚拟鞋的图像,或者头部试戴虚拟帽子的图像。
80.图3是根据本发明实施例1的数据处理方法二的流程图,如图3所示,该方法包括如下步骤:
81.步骤s302,接收输入图像,其中,输入图像中包括物理目标对象;
82.步骤s304,采用关键点检测模型,检测出输入图像中物理目标对象的2d关键点,其中,关键点检测模型采用多组训练数据通过机器训练得到,多组训练数据中的数据包括:物理目标对象与虚拟物件的交互图像和该交互图像中的2d关键点,2d关键点根据虚拟目标对象在预定坐标系下的第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到,交互图像根据虚拟物件在预定坐标系下的第二位姿和采集的物理目标对象的色彩图像,绘制虚拟物件在图像平面得到,第一位姿,第二位姿根据三维重建模型确定的,三维重建模型根据采集的物理目标对象的深度图像融合得到。
83.通过上述步骤,由于采用的关键点检测模型通过使用大量训练数据进行机器训练得到,而训练数据进行了准确的2d关键点标注,同时训练数据中的交互图像十分逼真且类型多样,因而实现了采用关键点检测模型准确检测接收到的包括物理目标对象的输入图像中物理目标对象的2d关键点的技术效果,解决了检测输入图像中的物理目标对象的2d关键点不准确的技术问题。
84.图4是根据本发明实施例1的数据处理方法三的流程图,如图4所示,该方法包括如下步骤:
85.步骤s402,获取多组训练数据,其中,多组训练数据中的数据包括:物理目标对象与虚拟物件的交互图像和该交互图像中的2d关键点,2d关键点根据虚拟目标对象在预定坐标系下的第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到,交互图像根据虚拟物件在预定坐标系下的第二位姿和采集的物理目标对象的色彩图像,绘制虚拟物件在图像
平面得到,第一位姿,第二位姿根据三维重建模型确定的,三维重建模型根据采集的物理目标对象的深度图像融合得到;
86.步骤s404,采用多组训练数据进行机器训练,得到关键点检测模型。
87.通过上述步骤,实现了采用多组训练数据进行机器训练得到关键点检测模型的目的。由于训练数据进行了准确的2d关键点标注,同时训练数据中的交互图像十分逼真且类型多样,因而使用上述训练数据可以取得良好的训练效果,解决了2d关键点检测模型的训练素材较少且人工标注不准确导致关键点检测模型的训练结果不理想的技术问题。
88.图5是根据本发明实施例1的数据处理方法四的流程图。如图5所示,该方法包括如下步骤:
89.步骤s502,采集脚部的色彩图像及深度图像;
90.步骤s504,根据深度图像,确定脚部的三维重建脚模型;
91.步骤s506,根据三维重建脚模型,确定虚拟脚在预定坐标系下的第一位姿,以及确定虚拟鞋在预定坐标系下的第二位姿;
92.步骤s508,根据第一位姿,将虚拟脚的3d脚部关键点投影到图像平面得到2d脚部关键点,以及根据第二位姿以及色彩图像绘制虚拟鞋在图像平面的试穿图像。
93.通过上述步骤,达到了根据脚部的图像建立三维重建模型,并依据建立的三维重建模型生成标注了2d关键点与虚拟鞋在图像平面试穿图像的目的,从而实现了降低获取训练数据的成本,提高训练数据质量的技术效果,进而解决了获取训练数据存在成本高,训练数据质量不高的技术问题。
94.作为一种可选的实施方式,下面以脚部为例进行说明。
95.图6是根据本发明可选实施方式的训练数据获取流程示意图。如图6所示,可以通过如下步骤获得包括虚拟鞋试穿图像和2d脚部关键点的训练数据:
96.s1,基于rgbd相机采集到的真实脚的rgb色彩数据和深度数据,进行脚部建模,得到真实脚的3d脚模型;
97.s2,依据3d脚模型对齐虚拟脚模型;
98.s3,依据与3d脚模型对齐的虚拟脚模型,将虚拟鞋模型与虚拟脚模型进行对齐;
99.s4,根据虚拟脚模型在相机图像上进行投影的规律,确定虚拟脚模型上的3d脚部关键点投影在图像上得到的2d脚部关键点;
100.s5,根据虚拟鞋模型和真实脚的rgb图像,使用渲染引擎渲染得到虚拟鞋试穿图像,其中,虚拟鞋试穿图像中还包括2d脚部关键点的标注。
101.图7是根据本发明可选实施方式的真实脚三维配准的流程示意图。如图7所示,对真实脚进行三维配准可以通过如下步骤实现:
102.s1,采集真实脚的多视角图像数据,得到局部的彩色图像以及像素对应的深度信息。
103.s2,将多视角图像的深度信息转化为三维点云,此时每片三维点云位于对应图像的相机坐标系下,然后建立采集过程中的点云位姿图,每片点云构成位姿图中的节点。
104.s3,进行序列化配准,若点云之间存在足够多的重叠则为点云添加连接边,连接边分为相邻边和回环边,相邻边连接时序上相邻的两个节点pi和pi+1,回环边所连接的两个节点pi和pj并无相邻时序要求,当重叠区域满足一定阈值则进行添加;建立位姿图时,需要
求解所有连接边的权重值以及对应的变换矩阵,这一求解通过icp点云配准算法实现,亦为序列化配准过程;
105.s4,在位姿图的基础上进行全局配准,首先定义能量函数如公式:
[0106][0107]
其中,{pk}为待求解量——每片点云在全局坐标系下的位姿,{xk}为观测到的点云数据,ek(
·
)为定义在观测量和待求解量之间的代价函数。采用lm非线性优化方法对该能量函数进行求解,最终得到每片点云在全局坐标系下的位姿。作为一种可选的实施例,可以采用录制起始时刻t=0的点云p0所在坐标系为全局坐标系,经过全局配准求解后,获得每片点云在点云p0坐标系下的6dof位姿,根据位姿结果进行变换后,所有时刻的点云均对齐到点云p0坐标系,融合后得到重建脚模型。
[0108]
作为一种可选的实施方式,在对真实脚部进行3d重建时,全局配准过程还可以可仅采用时序上的序列化配准,即对于采集点云{x0,x1,x2,....,xi,xi+1,...,xn}进行相邻两帧的配准,之后每一片点云在全局坐标系(x0)的位姿通过变换关系传递得到。但上述方法中,由于传递过程中的误差累计,易产生较大的漂移误差,即x0和xn之间的配准误差明显。
[0109]
图8是根据本发明可选实施方式对齐虚拟鞋、虚拟脚与重建脚的示意图。如图8所示,实现虚拟鞋、虚拟脚与重建脚的三者对齐,可以按照如下方式进行:首先,预先定义对齐虚拟鞋与虚拟脚的关系;然后,进行虚拟脚与重建脚的对齐,对齐过程可以基于fpfh的点云粗配准和点面icp的点云细配准方法,得到变换矩阵,然后基于变换矩阵实现虚拟脚与重建脚对齐;最后,基于虚拟鞋与虚拟脚的对齐关系,调整虚拟鞋的位姿得到与虚拟脚对齐的虚拟鞋,由于虚拟脚已经于重建脚对齐了,因此此时得到的虚拟鞋也与重建脚实现了对齐。
[0110]
需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明并不受所描述的动作顺序的限制,因为依据本发明,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定是本发明所必须的。
[0111]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到根据上述实施例的数据处理方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本发明各个实施例的方法。
[0112]
实施例2
[0113]
根据本发明实施例,还提供了一种用于实施上述数据处理方法一的数据处理装置,图9是根据本发明实施例2的数据处理装置一的结构框图,如图9所示,该装置包括:第一采集模块92,第一处理模块94,第一确定模块96和第二处理模块98。下面对该数据处理装置一进行详细说明。
[0114]
第一采集模块92,用于采集物理目标对象的色彩图像及深度图像;
[0115]
第一处理模块94,连接于上述第一采集模块92,用于根据深度图像,融合得到物理
目标对象的三维重建模型;
[0116]
第一确定模块96,连接于上述第一处理模块94,用于根据三维重建模型,确定虚拟目标对象在预定坐标系下的第一位姿,以及确定虚拟物件在预定坐标系下的第二位姿;
[0117]
第二处理模块98,连接于上述第一确定模块96,用于根据第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到2d关键点,以及根据第二位姿以及色彩图像绘制虚拟物件在图像平面中与物理目标对象的交互图像。
[0118]
此处需要说明的是,上述第一采集模块92,第一处理模块94,第一确定模块96和第二处理模块98对应于实施例1中的步骤s202至步骤s208,多个模块与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例1所公开的内容。需要说明的是,上述模块作为装置的一部分可以运行在实施例1提供的计算机终端10中。
[0119]
实施例3
[0120]
根据本发明实施例,还提供了一种用于实施上述数据处理方法二的数据处理装置,图10是根据本发明实施例3的数据处理装置二的结构框图,如图10所示,该装置包括:接收模块1002和检测模块1004。下面对该数据处理装置二进行详细说明。
[0121]
接收模块1002,用于接收输入图像,其中,输入图像中包括物理目标对象;
[0122]
检测模块1004,连接于上述接收模块1002,用于采用关键点检测模型,检测出输入图像中物理目标对象的2d关键点,其中,关键点检测模型采用多组训练数据通过机器训练得到,多组训练数据中的数据包括:物理目标对象与虚拟物件的交互图像和该交互图像中的2d关键点,2d关键点根据虚拟目标对象在预定坐标系下的第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到,交互图像根据虚拟目标对象在预定坐标系下的第二位姿和采集的物理目标对象的色彩图像,绘制虚拟物件在图像平面得到,第一位姿,第二位姿根据三维重建模型确定的,三维重建模型根据采集的物理目标对象的深度图像融合得到。
[0123]
此处需要说明的是,上述接收模块1002和检测模块1004对应于实施例1中的步骤s302至步骤s304,多个模块与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例1所公开的内容。需要说明的是,上述模块作为装置的一部分可以运行在实施例1提供的计算机终端10中。
[0124]
实施例4
[0125]
根据本发明实施例,还提供了一种用于实施上述数据处理方法三的数据处理装置,图11是根据本发明实施例4的数据处理装置三的结构框图,如图11所示,该装置包括:获取模块1102和训练模块1104。下面对该数据处理装置三进行详细说明。
[0126]
获取模块1102,用于获取多组训练数据,其中,多组训练数据中的数据包括:物理目标对象与虚拟物件的交互图像和该交互图像中的2d关键点,2d关键点根据虚拟目标对象在预定坐标系下的第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到,交互图像根据虚拟物件在预定坐标系下的第二位姿和采集的物理目标对象的色彩图像,绘制虚拟物件在图像平面得到,第一位姿,第二位姿根据三维重建模型确定的,三维重建模型根据采集的物理目标对象的深度图像融合得到;
[0127]
训练模块1104,连接于上述获取模块1102,用于采用多组训练数据进行机器训练,得到关键点检测模型。
[0128]
此处需要说明的是,上述获取模块1102和训练模块1104对应于实施例1中的步骤
s402至步骤s404,多个模块与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例1所公开的内容。需要说明的是,上述模块作为装置的一部分可以运行在实施例1提供的计算机终端10中。
[0129]
实施例5
[0130]
根据本发明实施例,还提供了一种用于实施上述数据处理方法四的数据处理装置,图12是根据本发明实施例5的数据处理装置四的结构框图,如图12所示,该装置包括:第二采集模块1202,第三处理模块1204,第二确定模块1206和第四处理模块1208。下面对该数据处理装置四进行详细说明。
[0131]
第二采集模块1202,用于采集脚部的色彩图像及深度图像;
[0132]
第三处理模块1204,连接于上述第二采集模块1202,用于根据深度图像,确定脚部的三维重建脚模型;
[0133]
第二确定模块1206,连接于上述第三处理模块1204,用于根据三维重建脚模型,确定虚拟脚在预定坐标系下的第一位姿,以及确定虚拟鞋在预定坐标系下的第二位姿;
[0134]
第四处理模块1208,连接于上述第二确定模块1206,用于根据第一位姿,将虚拟脚的3d脚部关键点投影到图像平面得到2d脚部关键点,以及根据第二位姿以及色彩图像绘制虚拟鞋在图像平面的试穿图像。
[0135]
此处需要说明的是,上述第二采集模块1202,第三处理模块1204,第二确定模块1206和第四处理模块1208对应于实施例1中的步骤s502至步骤s508,多个模块与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例1所公开的内容。需要说明的是,上述模块作为装置的一部分可以运行在实施例1提供的计算机终端10中。
[0136]
实施例6
[0137]
本发明的实施例可以提供一种计算机终端,该计算机终端可以是计算机终端群中的任意一个计算机终端设备。可选地,在本实施例中,上述计算机终端也可以替换为移动终端等终端设备。
[0138]
可选地,在本实施例中,上述计算机终端可以位于计算机网络的多个网络设备中的至少一个网络设备。
[0139]
在本实施例中,上述计算机终端可以执行应用程序的数据处理方法中以下步骤的程序代码:采集物理目标对象的色彩图像及深度图像;根据多个深度图像,融合得到物理目标对象的三维重建模型;根据三维重建模型,确定虚拟目标对象在预定坐标系下的第一位姿,以及确定虚拟物件在预定坐标系下的第二位姿;根据第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到2d关键点,以及根据第二位姿以及色彩图像绘制虚拟物件在图像平面的交互图像。
[0140]
可选地,图13是根据本发明实施例的一种计算机终端的结构框图。如图13所示,该计算机终端可以包括:一个或多个(图中仅示出一个)处理器1302、存储器1304等。
[0141]
其中,存储器1304可用于存储软件程序以及模块,如本发明实施例中的数据处理方法和装置对应的程序指令/模块,处理器1302通过运行存储在存储器内的软件程序以及模块,从而执行各种功能应用以及数据处理,即实现上述的数据处理方法。存储器1304可包括高速随机存储器,还可以包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器1304可进一步包括相对于处理器远程
设置的存储器,这些远程存储器可以通过网络连接至计算机终端。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
[0142]
处理器可以通过传输装置调用存储器存储的信息及应用程序,以执行下述步骤:采集物理目标对象的色彩图像及深度图像;根据多个深度图像,融合得到物理目标对象的三维重建模型;根据三维重建模型,确定虚拟目标对象在预定坐标系下的第一位姿,以及确定虚拟物件在预定坐标系下的第二位姿;根据第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到2d关键点,以及根据第二位姿以及色彩图像绘制虚拟物件在图像平面的交互图像。
[0143]
可选的,上述处理器还可以执行如下步骤的程序代码:在深度图像为多个的情况下,根据多个深度图像,融合得到物理目标对象的三维重建模型,包括:将多个深度图像转换为多片三维点云;根据多片三维点云建立点云位姿图,其中,多片三维点云中的每片点云为点云位姿图中的节点;对点云位姿图进行配准,得到物理目标对象的三维重建模型。
[0144]
可选的,上述处理器还可以执行如下步骤的程序代码:对点云位姿图进行配准,得到物理目标对象的三维重建模型,包括:采用迭代最近点icp方法,对点云位姿图进行序列化配准,得到点云位姿图的序列化配准结果图;对序列化配准结果图进行全局配准,得到物理目标对象的三维重建模型,其中,三维重建模型中的每片点云的位姿为在全局坐标系下的位姿。
[0145]
可选的,上述处理器还可以执行如下步骤的程序代码:根据三维重建模型,确定虚拟目标对象在预定坐标系下的第一位姿,包括:获取三维重建模型在预定坐标系下的第三位姿;确定虚拟目标对象变换到三维重建模型的变换矩阵;根据第三位姿和变换矩阵,确定虚拟目标对象在预定坐标系下的第一位姿。
[0146]
可选的,上述处理器还可以执行如下步骤的程序代码:确定虚拟目标对象变换到三维重建模型的变换矩阵,包括:基于快速点特征直方图fpfh的点云粗配准方法和点面icp的点云细配准方法,将虚拟目标对象与三维重建模型进行对齐,得到对齐参数;根据对齐参数,确定虚拟目标对象变换到三维重建模型的变换矩阵。
[0147]
可选的,上述处理器还可以执行如下步骤的程序代码:确定虚拟物件在预定坐标系下的第二位姿,包括:获取虚拟物件与虚拟目标对象的对齐关系;根据第一位姿和对齐关系,确定虚拟物件在预定坐标系下的第二位姿。
[0148]
可选的,上述处理器还可以执行如下步骤的程序代码:根据第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到2d关键点,以及根据第二位姿以及色彩图像绘制虚拟物件在图像平面的与物理目标对象的交互图像,包括:根据第一位姿,以及相机成像方法,将虚拟目标对象的3d关键点投影到图像平面得到2d关键点;根据第二位姿以及色彩图像,调用预定渲染引擎对虚拟物件在图像平面中与物理目标对象的交互结果进行绘制,得到虚拟物件在图像平面中与物理目标对象的交互图像。
[0149]
可选的,上述处理器还可以执行如下步骤的程序代码:根据第二位姿以及色彩图像,调用预定渲染引擎对虚拟物件在图像平面的交互效果进行绘制,得到虚拟物件在图像平面的交互图像,包括:在根据第二位姿以及色彩图像,调用预定渲染引擎对虚拟物件在图像平面中与物理目标对象的交互结果进行绘制时,通过替换背景和/或调整光源的方法,得到虚拟物件在图像平面的多张与物理目标对象的交互图像。
[0150]
可选的,上述处理器还可以执行如下步骤的程序代码:在采集的色彩图像及深度图像为物理目标对象不同状态下和/或不同角度下的多个色彩图像及多个深度图像的情况下,分别得到物理目标对象不同状态下和/或不同角度下的2d关键点和与虚拟物件的交互图像。
[0151]
可选的,上述处理器还可以执行如下步骤的程序代码:根据2d关键点和交互图像,生成训练数据;获取与多种物理目标对象对应的不同的训练数据;采用与多种物理目标对象对应的不同的训练数据进行机器训练,得到关键点检测模型。
[0152]
可选的,上述处理器还可以执行如下步骤的程序代码:物理目标对象和虚拟物件包括以下任意之一的组合:脚和虚拟鞋;头和虚拟帽子;手腕和虚拟手环;人体和虚拟服饰;面部和虚拟面部饰物。
[0153]
可选的,上述处理器还可以执行如下步骤的程序代码:接收输入图像,其中,输入图像中包括物理目标对象;采用关键点检测模型,检测出输入图像中物理目标对象的2d关键点,其中,关键点检测模型采用多组训练数据通过机器训练得到,多组训练数据中的数据包括:物理目标对象与虚拟物件的交互图像和该交互图像中的2d关键点,2d关键点根据虚拟目标对象在预定坐标系下的第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到,交互图像根据虚拟物件在预定坐标系下的第二位姿和采集的物理目标对象的色彩图像,绘制虚拟物件在图像平面得到,第一位姿,第二位姿根据三维重建模型确定的,三维重建模型根据采集的物理目标对象的深度图像融合得到。
[0154]
可选的,上述处理器还可以执行如下步骤的程序代码:获取多组训练数据,其中,多组训练数据中的数据包括:物理目标对象与虚拟物件的交互图像和该交互图像中的2d关键点,2d关键点根据虚拟目标对象在预定坐标系下的第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到,交互图像根据虚拟物件在预定坐标系下的第二位姿和采集的物理目标对象的色彩图像,绘制虚拟物件在图像平面得到,第一位姿,第二位姿根据三维重建模型确定的,三维重建模型根据采集的物理目标对象的深度图像融合得到;采用多组训练数据进行机器训练,得到关键点检测模型。
[0155]
可选的,上述处理器还可以执行如下步骤的程序代码:采集脚部的色彩图像及深度图像;根据深度图像,确定脚部的三维重建脚模型;根据三维重建脚模型,确定虚拟脚在预定坐标系下的第一位姿,以及确定虚拟鞋在预定坐标系下的第二位姿;根据第一位姿,将虚拟脚的3d脚部关键点投影到图像平面得到2d脚部关键点,以及根据第二位姿以及色彩图像绘制虚拟鞋在图像平面的试穿图像。
[0156]
本领域普通技术人员可以理解,图13所示的结构仅为示意,计算机终端也可以是智能手机(如android手机、ios手机等)、平板电脑、掌声电脑以及移动互联网设备(mobile internet devices,mid)、pad等终端设备。图13其并不对上述电子装置的结构造成限定。例如,计算机终端还可包括比图13中所示更多或者更少的组件(如网络接口、显示装置等),或者具有与图13所示不同的配置。
[0157]
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令终端设备相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:闪存盘、只读存储器(read-only memory,rom)、随机存取器(random access memory,ram)、磁盘或光盘等。
[0158]
实施例7
[0159]
本发明的实施例还提供了一种存储介质。可选地,在本实施例中,上述存储介质可以用于保存上述实施例1所提供的数据处理方法所执行的程序代码。
[0160]
可选地,在本实施例中,上述存储介质可以位于计算机网络中计算机终端群中的任意一个计算机终端中,或者位于移动终端群中的任意一个移动终端中。
[0161]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:采集物理目标对象的色彩图像及深度图像;根据深度图像,融合得到物理目标对象的三维重建模型;根据三维重建模型,确定虚拟目标对象在预定坐标系下的第一位姿,以及确定虚拟物件在预定坐标系下的第二位姿;根据第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到2d关键点,以及根据第二位姿以及色彩图像绘制虚拟物件在图像平面中与物理目标对象的交互图像。
[0162]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:在深度图像为多个的情况下,根据多个深度图像,融合得到物理目标对象的三维重建模型,包括:将多个深度图像转换为多片三维点云;根据多片三维点云建立点云位姿图,其中,多片三维点云中的每片点云为点云位姿图中的节点;对点云位姿图进行配准,得到物理目标对象的三维重建模型。
[0163]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:对点云位姿图进行配准,得到物理目标对象的三维重建模型,包括:采用迭代最近点icp方法,对点云位姿图进行序列化配准,得到点云位姿图的序列化配准结果图;对序列化配准结果图进行全局配准,得到物理目标对象的三维重建模型,其中,三维重建模型中的每片点云的位姿为在全局坐标系下的位姿。
[0164]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:根据三维重建模型,确定虚拟目标对象在预定坐标系下的第一位姿,包括:获取三维重建模型在预定坐标系下的第三位姿;确定虚拟目标对象变换到三维重建模型的变换矩阵;根据第三位姿和变换矩阵,确定虚拟目标对象在预定坐标系下的第一位姿。
[0165]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:确定虚拟目标对象变换到三维重建模型的变换矩阵,包括:基于快速点特征直方图fpfh的点云粗配准方法和点面icp的点云细配准方法,将虚拟目标对象与三维重建模型进行对齐,得到对齐参数;根据对齐参数,确定虚拟目标对象变换到三维重建模型的变换矩阵。
[0166]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:确定虚拟物件在预定坐标系下的第二位姿,包括:获取虚拟物件与虚拟目标对象的对齐关系;根据第一位姿和对齐关系,确定虚拟物件在预定坐标系下的第二位姿。
[0167]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:根据第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到2d关键点,以及根据第二位姿绘制虚拟物件在图像平面中与物理目标对象的交互图像,包括:根据第一位姿,以及相机成像方法,将虚拟目标对象的3d关键点投影到图像平面得到2d关键点;根据第二位姿以及色彩图像,调用预定渲染引擎对虚拟物件在图像平面中与物理目标对象的交互结果进行绘制,得到虚拟物件在图像平面中与物理目标对象的交互图像。
[0168]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:根
据第二位姿以及色彩图像,调用预定渲染引擎对虚拟物件在图像平面中与物理目标对象的交互结果进行绘制,得到虚拟物件在图像平面中与物理目标对象的交互图像,包括:在根据第二位姿以及色彩图像,调用预定渲染引擎对虚拟物件在图像平面中与物理目标对象的交互结果进行绘制时,通过替换背景和/或调整光源的方法,得到虚拟物件在图像平面的多张与物理目标对象的交互图像。
[0169]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:在采集的色彩图像及深度图像为物理目标对象不同状态下和/或不同角度下的色彩图像及多个深度图像的情况下,分别得到物理目标对象不同状态下和/或不同角度下的2d关键点和与虚拟物件的交互后的图像。
[0170]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:根据2d关键点和交互图像,生成训练数据;获取与多种物理目标对象对应的不同的训练数据;采用与多种物理目标对象对应的不同的训练数据进行机器训练,得到关键点检测模型。
[0171]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:物理目标对象和虚拟物件包括以下任意之一的组合:脚和虚拟鞋;头和虚拟帽子;手腕和虚拟手环;人体和虚拟服饰;面部和虚拟面部饰物。
[0172]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:接收输入图像,其中,输入图像中包括物理目标对象;采用关键点检测模型,检测出输入图像中物理目标对象的2d关键点,其中,关键点检测模型采用多组训练数据通过机器训练得到,多组训练数据中的数据包括:物理目标对象与物件的交互图像和该交互图像中的2d关键点,2d关键点根据虚拟目标对象在预定坐标系下的第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到,交互图像根据虚拟物件在预定坐标系下的第二位姿和采集的物理目标对象的色彩图像,绘制虚拟物件在图像平面得到,第一位姿,第二位姿根据三维重建模型确定的,三维重建模型根据采集的物理目标对象的深度图像融合得到。
[0173]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:获取多组训练数据,其中,多组训练数据中的数据包括:物理目标对象与虚拟物件的交互图像和该交互图像中的2d关键点,2d关键点根据虚拟目标对象在预定坐标系下的第一位姿,将虚拟目标对象的3d关键点投影到图像平面得到,交互图像根据虚拟物件在预定坐标系下的第二位姿和采集的物理目标对象的色彩图像,绘制虚拟物件在图像平面得到,第一位姿,第二位姿根据三维重建模型确定的,三维重建模型根据采集的物理目标对象的深度图像融合得到;采用多组训练数据进行机器训练,得到关键点检测模型。
[0174]
可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:采集脚部的色彩图像及深度图像;根据深度图像,确定脚部的三维重建脚模型;根据三维重建脚模型,确定虚拟脚在预定坐标系下的第一位姿,以及确定虚拟鞋在预定坐标系下的第二位姿;根据第一位姿,将虚拟脚的3d脚部关键点投影到图像平面得到2d脚部关键点,以及根据第二位姿以及色彩图像绘制虚拟鞋在图像平面的试穿图像。
[0175]
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
[0176]
在本发明的上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
[0177]
在本技术所提供的几个实施例中,应该理解到,所揭露的技术内容,可通过其它的
方式实现。其中,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,单元或模块的间接耦合或通信连接,可以是电性或其它的形式。
[0178]
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
[0179]
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0180]
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
[0181]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1