基于海量图数据的模型计算方法及装置与流程
1.本发明涉及数据处理技术领域,具体而言,涉及一种基于海量图数据的模型计算方法及装置。
背景技术:
2.在一般的知识图谱项目中,图模型是图分析挖掘的重要组成部分,图模型能够利用图数据做机器学习、数据挖掘等深层次分析,能够更好地发现图数据隐含的知识。但是在实际应用中,由于图数据之间关联较多,在做图模型计算时很难将其拆分开,在图数据量较小时可以将数据全部加载到内存中,然后再进行计算,因此影响不是很大。而在海量数据的情况下,不可能将数据全部加载到内存,同时单机运行所耗费的时间也不能接受,因此需要一种在海量图数据的情况下,能够耗费较小的资源,同时能够将计算并行起来的方法。
技术实现要素:
3.为了改善上述问题,本发明提供了一种基于海量图数据的模型计算方法及装置。
4.本发明实施例提供了一种基于海量图数据的模型计算方法,应用于计算机设备,所述方法包括以下步骤:
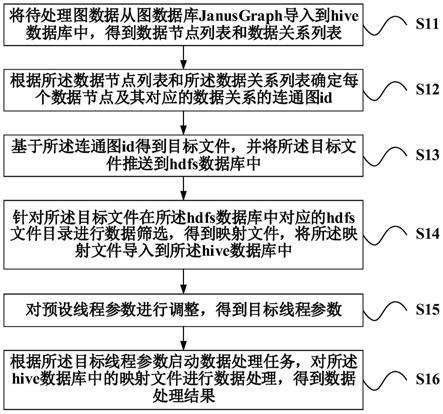
5.将待处理图数据从图数据库janusgraph导入到hive数据库中,得到数据节点列表和数据关系列表;
6.根据所述数据节点列表和所述数据关系列表确定每个数据节点及其对应的数据关系的连通图id;
7.基于所述连通图id得到目标文件,并将所述目标文件推送到hdfs数据库中;
8.针对所述目标文件在所述hdfs数据库中对应的hdfs文件目录进行数据筛选,得到映射文件,将所述映射文件导入到所述hive数据库中;
9.对预设线程参数进行调整,得到目标线程参数;
10.根据所述目标线程参数启动数据处理任务,对所述hive数据库中的映射文件进行数据处理,得到数据处理结果。
11.可选地,根据所述数据节点列表和所述数据关系列表确定每个数据节点及其对应的数据关系的连通图id,包括:
12.通过获取到的spark代码,读取所述数据节点列表和所述数据关系列表;
13.基于spark的graphx框架,计算每个数据节点及其对应的数据关系的连通图id。
14.可选地,基于所述连通图id得到目标文件,并将所述目标文件推送到hdfs数据库中,包括:
15.对所述连通图id进行分组;
16.将每个组的数据节点以及数据关系依次写入初始文件,得到目标文件;
17.将所述目标文件推送到hdfs数据库中。
18.可选地,针对所述目标文件在所述hdfs数据库中对应的hdfs文件目录进行数据筛
选,得到映射文件,将所述映射文件导入到所述hive数据库中,包括:
19.定义数据过滤文件;
20.根据所述数据过滤文件读取所述hdfs文件目录;
21.将所述hdfs文件目录下的每一个待处理文件转换为sqlite文件以及para与sqlite的映射文件;
22.将所述sqlite文件以及所述映射文件推送到所述hive数据库的指定目录下。
23.可选地,对预设线程参数进行调整,得到目标线程参数,包括:
24.将预设的单机代码修改为分布式代码。
25.可选地,根据所述目标线程参数启动数据处理任务,包括:
26.基于所述分布式代码启动计算任务,使用spark的submit命令将任务进行提交。
27.可选地,所述方法还包括:
28.对所述数据处理结果进行验证。
29.本发明实施例提供了一种基于海量图数据的模型计算装置,应用于计算机设备,所述装置包括以下功能模块:
30.数据导入模块,用于将待处理图数据从图数据库janusgraph导入到hive数据库中,得到数据节点列表和数据关系列表;
31.连通图确定模块,用于根据所述数据节点列表和所述数据关系列表确定每个数据节点及其对应的数据关系的连通图id;
32.文件推送模块,用于基于所述连通图id得到目标文件,并将所述目标文件推送到hdfs数据库中;
33.数据筛选模块,用于针对所述目标文件在所述hdfs数据库中对应的hdfs文件目录进行数据筛选,得到映射文件,将所述映射文件导入到所述hive数据库中;
34.参数调整模块,用于对预设线程参数进行调整,得到目标线程参数;
35.数据处理模块,用于根据所述目标线程参数启动数据处理任务,对所述hive数据库中的映射文件进行数据处理,得到数据处理结果。
36.可选地,连通图确定模块,用于:
37.通过获取到的spark代码,读取所述数据节点列表和所述数据关系列表;
38.基于spark的graphx框架,计算每个数据节点及其对应的数据关系的连通图id。
39.可选地,文件推送模块,用于:
40.对所述连通图id进行分组;
41.将每个组的数据节点以及数据关系依次写入初始文件,得到目标文件;
42.将所述目标文件推送到hdfs数据库中。
43.本发明所提供的基于海量图数据的模型计算方法及装置,将待处理图数据从图数据库janusgraph导入到hive数据库中得到数据节点列表和数据关系列表并确定每个数据节点及其对应的数据关系的连通图id,基于连通图id,聚合同一连通图的数据并推送到hdfs存储中,同时在聚合过程中保留好运行参数与聚合文件的映射并导入hive数据库中,对预设线程参数进行调整得到目标线程参数以根据目标线程参数启动数据处理任务对hive数据库中的映射文件进行数据处理得到数据处理结果。如此设计,提前采用连通图进行了数据拆分,为任务能够并行做好了准备,提前进行了数据筛选和数据转换,减少了计算
时的数据量,以及数据转换使得数据安装加载到内存,将单机的模型python代码简单的修改转换为spark代码,不仅能够并行计算,同时能够根据计算资源以及任务的需求动态调整并行度。
附图说明
44.为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
45.图1为本发明实施例所提供的一种基于海量图数据的模型计算方法的流程图。
46.图2为本发明实施例所提供的一种基于海量图数据的模型计算装置的模块框图。
具体实施方式
47.为了更好的理解上述技术方案,下面通过附图以及具体实施例对本发明技术方案做详细的说明,应当理解本发明实施例以及实施例中的具体特征是对本发明技术方案的详细的说明,而不是对本发明技术方案的限定,在不冲突的情况下,本发明实施例以及实施例中的技术特征可以相互组合。
48.发明人发现,常见的基于单机的内存图模型计算方案如下:a.将小量的数据加载到内存中,b.编写相应的分析代码,处理内存中的数据,c.启动单个或者多个线程运行分析代码,d.输出结果。
49.但是,现有技术存在以下缺点:现有的技术只能处理小量的数据,将数据全部加载到内存中,资源的耗用比较高,虽然能多线程并行运行,但是只能在单机上运行。当数据量较大时,无法利用大数据相关的计算引擎线性扩展计算资源。
50.为改善上述问题。发明人创新性地提出了基于海量图数据的模型计算方法及装置。首先请参阅图1,示出了基于海量图数据的模型计算方法,所述方法可以应用于计算机设备,进一步通过以下步骤s11
‑
步骤s16所描述的内容实现。
51.步骤s11,将待处理图数据从图数据库janusgraph导入到hive数据库中,得到数据节点列表和数据关系列表。
52.数据导出这一步是指将数据从图数据库janusgraph(一种分布式图数据库,常用于小批量的oltp查询)中导出到hive(一种大数据分布式数据仓库)中,导出的目的是为了后续的全量分析(olap)与前面的数据是一致的。导出的结果有两个hive表:数据节点列表(nodes表)以及数据关系列表(relations表)。
53.nodes表
[0054][0055]
relations表
[0056][0057][0058]
步骤s12,根据所述数据节点列表和所述数据关系列表确定每个数据节点及其对应的数据关系的连通图id。
[0059]
步骤s13,基于所述连通图id得到目标文件,并将所述目标文件推送到hdfs数据库中。
[0060]
步骤s14,针对所述目标文件在所述hdfs数据库中对应的hdfs文件目录进行数据筛选,得到映射文件,将所述映射文件导入到所述hive数据库中。
[0061]
步骤s15,对预设线程参数进行调整,得到目标线程参数。
[0062]
步骤s16,根据所述目标线程参数启动数据处理任务,对所述hive数据库中的映射文件进行数据处理,得到数据处理结果。
[0063]
如此设计,将待处理图数据从图数据库janusgraph导入到hive数据库中得到数据节点列表和数据关系列表并确定每个数据节点及其对应的数据关系的连通图id,基于连通图id,聚合同一连通图的数据并推送到hdfs存储中,同时在聚合过程中保留好运行参数与聚合文件的映射并导入hive数据库中,对预设线程参数进行调整得到目标线程参数以根据目标线程参数启动数据处理任务对hive数据库中的映射文件进行数据处理得到数据处理结果。如此设计,提前采用连通图进行了数据拆分,为任务能够并行做好了准备,提前进行了数据筛选和数据转换,减少了计算时的数据量,以及数据转换使得数据安装加载到内存,
将单机的模型python代码简单的修改转换为spark代码,不仅能够并行计算,同时能够根据计算资源以及任务的需求动态调整并行度。
[0064]
进一步地,步骤s12所描述的根据所述数据节点列表和所述数据关系列表确定每个数据节点及其对应的数据关系的连通图id,包括:通过获取到的spark代码,读取所述数据节点列表和所述数据关系列表;基于spark的graphx框架,计算每个数据节点及其对应的数据关系的连通图id。可以理解,在传统的方法中,数据无法并行的原因就是图数据相互的管理而导致没有把数据拆分开来,本步骤的拆分是利用图数据连通图的属性,计算每一个节点的连通图id。
[0065]
进一步地,步骤s13所描述的基于所述连通图id得到目标文件,并将所述目标文件推送到hdfs数据库中,包括:对所述连通图id进行分组;将每个组的数据节点以及数据关系依次写入初始文件,得到目标文件;将所述目标文件推送到hdfs数据库中。
[0066]
可以理解,数据汇聚的目的是将同一个连通图的节点和关系写到同一个文件为后续计算做准备,同时为了防止有的连通图过小而导致产生大量的小文件,需要设置一个文件最小的记录数目。
[0067]
例如,编写spark代码,读取步骤的结果,根据连通图id进行分组,先将每个组的节点写入到文件并以node|开始,一行一个记录,再写关系,并以relations|开始,同时为了防止内存溢出,每写1w行,便flush缓存到磁盘。如果该文件写入的记录数没有到达阈值,便不切换新的文件写入,还在原来的文件写入。最终形成的文件如下:
[0068][0069]
当文件写完成后,将文件推送到hdfs(一种分布式文件存储系统)上去。
[0070]
对于一些可能的示例而言,步骤s14所描述的针对所述目标文件在所述hdfs数据库中对应的hdfs文件目录进行数据筛选,得到映射文件,将所述映射文件导入到所述hive数据库中,包括:定义数据过滤文件;根据所述数据过滤文件读取所述hdfs文件目录;将所述hdfs文件目录下的每一个待处理文件转换为sqlite文件以及para与sqlite的映射文件;将所述sqlite文件以及所述映射文件推送到所述hive数据库的指定目录下。本步骤的目的是筛选数据并且将步骤s13的文件转换为计算需要的数据。由于一般模型只用到了部分节点和关系的数据,提前将不用的数据筛选出去,有助于减少计算的数据量。
[0071]
例如,数据过滤文件如下。
[0072]
[0073][0074]
编写代码读取配置文件,使用spark读取步骤s13结果的hdfs文件目录,将改目录下每一个文件转为为一个sqlite文件,每个sqlite文件有两个表nodes,relations两个表的数据和索引符合上面文件的定义。sqlite的文件名在原来的文件名后面加一个后缀’.db’,在转换的过程中,同时也需要把para所在的文件写入到文件中。在转换过程中,每转换10000条数据,提交一下记录。每转换完成一个文件,将有两个文件生成。一个是转换完成的sqlite文件,一个是para与sqlite的映射文件,将这两个文件推送到hdfs指定的目录。将para与sqlite的映射文件导入到hive中,该hive表有两列:para,db。
[0075]
进一步地,步骤s15所描述的对预设线程参数进行调整,得到目标线程参数,包括:将预设的单机代码修改为分布式代码。这一步骤的目的是将分析师编写单机代码转换为分布式的代码。
[0076]
在一些实施例中,步骤s16所描述的根据所述目标线程参数启动数据处理任务,包括:基于所述分布式代码启动计算任务,使用spark的submit命令将任务进行提交。
[0077]
在上述内容的基础上,还可以包括以下步骤:对所述数据处理结果进行验证。例如,计算完成后,选择部分的数据与单机的进行比较验证。
[0078]
基于上述同样的发明构思,请结合参阅图2,示出了一种基于海量图数据的模型计算装置200,应用于计算机设备,所述装置包括以下模块:
[0079]
数据导入模块210,用于将待处理图数据从图数据库janusgraph导入到hive数据库中,得到数据节点列表和数据关系列表;
[0080]
连通图确定模块220,用于根据所述数据节点列表和所述数据关系列表确定每个数据节点及其对应的数据关系的连通图id;
[0081]
文件推送模块230,用于基于所述连通图id得到目标文件,并将所述目标文件推送到hdfs数据库中;
[0082]
数据筛选模块240,用于针对所述目标文件在所述hdfs数据库中对应的hdfs文件目录进行数据筛选,得到映射文件,将所述映射文件导入到所述hive数据库中;
[0083]
参数调整模块250,用于对预设线程参数进行调整,得到目标线程参数;
[0084]
数据处理模块260,用于根据所述目标线程参数启动数据处理任务,对所述hive数
据库中的映射文件进行数据处理,得到数据处理结果。
[0085]
可选地,连通图确定模块220,用于:通过获取到的spark代码,读取所述数据节点列表和所述数据关系列表;基于spark的graphx框架,计算每个数据节点及其对应的数据关系的连通图id。
[0086]
可选地,文件推送模块230,用于:对所述连通图id进行分组;将每个组的数据节点以及数据关系依次写入初始文件,得到目标文件;将所述目标文件推送到hdfs数据库中。
[0087]
综上,本发明的基于海量图数据的模型计算方法及装置,将待处理图数据从图数据库janusgraph导入到hive数据库中得到数据节点列表和数据关系列表并确定每个数据节点及对应的数据关系的连通图id,基于连通图id,聚合同一连通图的数据并推送到hdfs存储中,同时在聚合过程中保留好运行参数与聚合文件的映射并导入hive数据库中,对预设线程参数进行调整得到目标线程参数以进行数据处理得到数据处理结果。如此,提前采用连通图进行了数据拆分,为任务能够并行做好了准备,提前进行了数据筛选和数据转换,减少了计算时的数据量,以及数据转换使得数据安装加载到内存,将单机的模型python代码简单的修改转换为spark代码,不仅能够并行计算,同时能够根据计算资源以及任务的需求动态调整并行度。
[0088]
以上仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1