一种基于DR-Unet104的医疗图像分割方法与流程
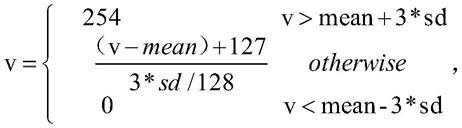
一种基于dr
‑
unet104的医疗图像分割方法
技术领域
1.本发明属于图像分割技术领域,具体涉及一种基于dr
‑
unet104的医疗图像分割方法。
背景技术:
2.病变的分割是推进放射学领域所必需的一个重要研究领域,利用影像学推断生物标志物,以帮助预测和治疗患者的预后,但由于各种医疗图像中病变部位的大小、形状、位置变化较大,且强度和对比度不一致,导致医疗图像的分割需要熟练且专业的医疗人员进行手工分割,耗时巨大。
3.存在问题或缺陷的原因:目前基于深度学习的分割方法被广泛应用于医学图像分割任务中,但由于相关的医学图像具有边缘模糊,目标区域小等特点,导致一些基于深度学习的分割方法存在特征利用率低等问题,最终导致模型的分割准确率难以提高,病灶部位难以精确分割。
技术实现要素:
4.针对上述基于深度学习的分割方法存在特征利用率低的技术问题,本发明提供了一种分割性能强、准确率高、效率高的基于双深度学习模型的隧道裂缝检测及测量方法。
5.为了解决上述技术问题,本发明采用的技术方案为:
6.一种基于dr
‑
unet104的医疗图像分割方法,包括下列步骤:
7.s100、数据采集:通过采集相关医疗图像,构建原始数据集;
8.s200、数据扩充:对原始数据集进行数据增强,实现数据集扩充;
9.s300、数据处理:包括数据集的划分、标准化及统一数据尺度大小;
10.s400、模型构建:通过使用dr
‑
unet104模型,进行模型训练。
11.所述s100中的数据采集中将对图像病灶部位进行手动标注。
12.所述s200数据扩充对原始数据集中的所有图像分别进行90度旋转、270度旋转、水平翻转和垂直翻转,将训练集扩充至原来的5倍。
13.所述s300数据处理中,数据划分将数据集按照8:1:1的比例分别将其划分为训练集、验证集和测试集;数据标准化过程方程如下:所述v为图像像素点,所述mean为均值,所述sd为标准差;统一尺度过程将数据集划分后得到的所有数据进行缩放,按照大小比例全部调整为224*224。
14.所述s400模型构建在dr
‑
unet104模型的编码器和解码器组件中各自部署五个具有卷积层和识别映射的重叠残差块层,在解码器路径中,残差块由两个3x3的二维卷积叠加而成,同时将激活函数用于所有剩余块,提高模型的特征提取能力,通过引入正则化方法
dropout对模型的特征进行筛选;
15.残差块层:残差块使用1x1卷积来减少图像特征的数量,之后通过3x3卷积进行特征提取,最后通过使用1x1卷积来增加特征的数量,残差块通过一个跳跃连接实现多个网络层的剩余连接,以帮助反向传播,并允许更深的网络被建立,f(x)=h(x)
‑
x,其中h(x)为残差网络的输出,f(x)为经过卷积操作的输出;
16.激活函数:加快模型的训练过程,
17.正则化方法:通过dropout减少模型特征数量,提高模型对特征的利用率,进一步加强模型的分割性能,所述w为权重参数,所述(l)表示层数,所述p为dropout的参数设置;
18.损失函数:使用的损失函数为稀疏分类交叉熵,所述n为图像数量,所述c为不同类别,所述ytrue为真实标签,所述ypred为预测标签。
19.本发明与现有技术相比,具有的有益效果是:
20.本发明通过标准化和数据扩充等预处理方法,提高模型泛化能力,其模型通过将基础的unet模型与残差连接模块的优势结合起来,提高模型分割性能,而dropout的使用更是提高了模型的整体性能,为医生的医疗诊断提供了极大的辅助作用。
附图说明
21.图1为本发明的主要步骤流程图。
具体实施方式
22.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
23.一种基于dr
‑
unet104的医疗图像分割方法,如图1所示,包括下列步骤:
24.s100、数据采集:通过采集相关医疗图像,构建原始数据集;
25.s200、数据扩充:对原始数据集进行数据增强,实现数据集扩充;
26.s300、数据处理:包括数据集的划分、标准化及统一数据尺度大小;
27.s400、模型构建:通过使用dr
‑
unet104模型,进行模型训练。
28.进一步,步骤s100数据采集中将对图像病灶部位进行手动标注。
29.进一步,步骤s200数据扩充对原始数据集中的所有图像分别进行90度旋转、270度旋转、水平翻转和垂直翻转,将训练集扩充至原来的5倍。
30.进一步,步骤s300数据处理中,数据划分将数据集按照8:1:1的比例分别将其划分为训练集、验证集和测试集;数据标准化过程方程如下:
31.其中v为图像像素点,mean为均值,sd为标准差;统一尺度过程将数据集划分后得到的所有数据进行缩放,按照大小比例全部调整为224*224。
32.进一步,步骤s400模型构建在dr
‑
unet104模型的编码器和解码器组件中各自部署五个具有卷积层和识别映射的重叠残差块层,在解码器路径中,残差块由两个3x3的二维卷积叠加而成,同时将激活函数用于所有剩余块,提高模型的特征提取能力,通过引入正则化方法dropout对模型的特征进行筛选,其中
33.残差块层:残差块使用1x1卷积来减少图像特征的数量,之后通过3x3卷积进行特征提取,最后通过使用1x1卷积来增加特征的数量,残差块通过一个跳跃连接实现多个网络层的剩余连接,以帮助反向传播,并允许更深的网络被建立,f(x)=h(x)
‑
x,其中h(x)为残差网络的输出,f(x)为经过卷积操作的输出;
34.激活函数:加快模型的训练过程,
35.正则化方法:通过dropout减少模型特征数量,提高模型对特征的利用率,进一步加强模型的分割性能,其中w为权重参数,(l)表示层数,p为dropout的参数设置;
36.损失函数:使用的损失函数为稀疏分类交叉熵;其中n为图像数量,c为不同类别,ytrue为真实标签,ypred为预测标签。
37.上面仅对本发明的较佳实施例作了详细说明,但是本发明并不限于上述实施例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化,各种变化均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1