交流支持系统、交流支持方法、交流支持程序以及图像控制程序与流程
1.本公开的一个方面涉及交流支持系统、交流支持方法、交流支持程序以及图像控制程序。
2.本技术主张基于2019年4月1日提出申请的日本技术2019-070095号、2019年6月14日提出申请的日本技术2019-110923号以及2019年9月30日提出申请的日本技术第2019-179883号的优先权,并援引记载于所述日本技术的全部记载内容。
背景技术:
3.已知有一种支持与第一终端对应的第一用户和与第二终端对应的第二用户之间的交流的交流支持系统。例如,在专利文献1中记载了一种使进行远程对话的成员彼此的视线一致的视线一致图像生成装置。在专利文献2中记载了一种用于视频电话或视频会议等的对话装置用的图像处理装置。专利文献3记载了一种视频会议系统中的视线一致脸部图像合成方法。
4.现有技术文献
5.专利文献
6.专利文献1:日本特开2015-191537号公报
7.专利文献2:日本特开2016-085579号公报
8.专利文献3:日本特开2017-130046号公报
技术实现要素:
9.本公开的一个方面的交流支持系统支持与第一终端对应的第一用户和与第二终端对应的第二用户之间的交流。交流支持系统具备至少一个处理器。至少一个处理器从第一终端接收呈现出第一用户的影像数据,对影像数据进行解析并从化身的动作模式组之中选择与第一用户的非语言行为对应的动作模式,将表示选择出的动作模式的控制数据发送至第二终端,以便使在第二终端上显示的虚拟空间内的、与第一用户对应的化身基于该选择出的动作模式进行动作。
附图说明
10.图1是表示实施方式的交流支持系统的概要的一个例子的图。
11.图2是表示视线的偏离的例子的图。
12.图3是表示虚拟空间和化身的例子的图。
13.图4是表示虚拟空间和化身的例子的另一图,更具体而言,是对共同注意进行说明的图。
14.图5是表示虚拟空间和化身的例子的又一图,更具体而言,是对化身的动作模式的几个例子进行说明的图。
15.图6是表示与实施方式的交流支持系统关联的硬件构成的一个例子的图。
16.图7是表示实施方式的终端的功能构成的一个例子的图。
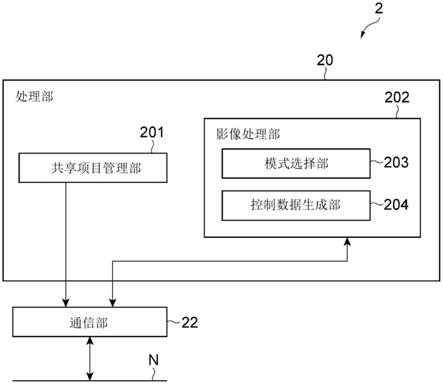
17.图8是表示实施方式的服务器的功能构成的一个例子的图。
18.图9是将实施方式的交流支持系统的动作的一个例子作为处理流程s1示出的时序图。
19.图10是将实施方式的交流支持系统的动作的一个例子作为处理流程s2示出的另一时序图。
20.图11是将实施方式的交流支持系统的动作的一个例子作为处理流程s3示出的又一时序图。
具体实施方式
21.[本公开所要解决的问题]
[0022]
在使用了图像的交流支持中,期望实现自然的交流。
[0023]
[本公开的效果]
[0024]
根据本公开的一个方面,能实现使用了图像的自然的交流。
[0025]
[本公开的实施方式的说明]
[0026]
列举本公开的实施方案来进行说明。也可以将以下记载的实施方式的至少一部分任意地组合。
[0027]
本公开的一个方面的交流支持系统支持与第一终端对应的第一用户和与第二终端对应的第二用户之间的交流。交流支持系统具备至少一个处理器。至少一个处理器从第一终端接收呈现出第一用户的影像数据,对影像数据进行解析并从化身的动作模式组之中选择与第一用户的非语言行为对应的动作模式,将表示选择出的动作模式的控制数据发送至第二终端,以便使在第二终端显示的虚拟空间内的、与第一用户对应的化身基于该选择出的动作模式进行动作。
[0028]
本公开的一个方面的交流支持方法由交流支持系统来执行,该交流支持系统支持与第一终端对应的第一用户和与第二终端对应的第二用户之间的交流并且具备至少一个处理器。交流支持方法包括如下步骤:从第一终端接收呈现出第一用户的影像数据;对影像数据进行解析并从化身的动作模式组之中选择与第一用户的非语言行为对应的动作模式;以及将表示选择出的动作模式的控制数据发送至第二终端,以便使在第二终端显示的虚拟空间内的、与第一用户对应的化身基于该选择出的动作模式进行动作。
[0029]
本公开的一个方面的交流支持程序使计算机作为交流支持系统发挥功能,该交流支持系统支持与第一终端对应的第一用户和与第二终端对应的第二用户之间的交流。交流支持程序使计算机执行如下步骤:从第一终端接收呈现出第一用户的影像数据;对影像数据进行解析并从化身的动作模式组之中选择与第一用户的非语言行为对应的动作模式;以及将表示选择出的动作模式的控制数据发送至第二终端,以便使在第二终端显示的虚拟空间内的、与第一用户对应的化身基于该选择出的动作模式进行动作。
[0030]
本公开的一个方面的图像控制程序使计算机作为能经由通信网络与第一终端连接的第二终端发挥功能。图像控制程序使计算机执行如下步骤:接收表示与第一用户的非语言行为对应的动作模式的控制数据,该第一用户与第一终端对应;以及使在第二终端显
示的虚拟空间内的、与第一用户对应的化身基于由接收到的控制数据表示的动作模式进行动作。该动作模式是对由第一终端拍摄到的第一用户的影像数据进行解析并从化身的动作模式组之中被选择为与该非语言行为对应的动作模式的动作模式。
[0031]
在这样的方面中,第一用户的非语言行为被反映至化身的动作,因此第二用户能借由该化身与第一用户取得自然的交流。
[0032]
在其他方面的交流支持系统中,也可以是,至少一个处理器使用学习模型来选择与第一用户的非语言行为和第一用户的声音信息对应的动作模式,学习模型是以当被输入用户的影像数据或被输入用户的影像数据和基于该影像数据的数据时,输出表示与该用户的非语言行为和该用户的声音信息对应的动作模式的信息的方式,使用训练数据生成的已学习模型。这样利用学习模型,不仅能使第一用户的非语言行为反映至化身的动作,而且也能使第一用户的声音信息反映至化身的动作。
[0033]
在其他方面的交流支持系统中,也可以是,第一用户的声音信息包括第一用户的声音和语言,用户的影像数据或基于该影像数据的数据包括用户的图像数据和声音信息。由此,能使第一用户的声音和语言反映至化身的动作。
[0034]
在其他方面的交流支持系统中,也可以是,至少一个处理器以化身的视线朝向第二用户的方式选择动作模式。由此,能使化身的视线与第二用户的视线一致。
[0035]
在其他方面的交流支持系统中,也可以是,至少一个处理器通过以文本表现选择出的动作模式来生成控制数据。通过以文本(即字符串)表现用于使化身进行动作的动作模式,发送至第二终端的数据大小被大幅抑制。因此,能减少施加于通信网络和终端的处理的负荷,并且能使化身按照第一用户的行为来实时地进行动作。
[0036]
在其他方面的交流支持系统中,也可以是,至少一个处理器通过以json形式记述选择出的动作模式来生成控制数据。通过采用json形式,表示动作模式的数据大小进一步被抑制。因此,能减少施加于通信网络和终端的处理的负荷,并且能使化身按照第一用户的行为来实时地进行动作。
[0037]
在其他方面的交流支持系统中,也可以是,非语言行为至少包括第一用户的视线,动作模式组中包括的各个动作模式至少表示化身的视线。也可以是,至少一个处理器选择表示与第一用户的视线对应的化身的视线的动作模式。通过使一般在交流中起到重要的作用的视线反映至化身的动作,能实现使用了图像的自然的交流。其结果是,能实现用户间的创造性的对话。
[0038]
在其他方面的交流支持系统中,也可以是,非语言行为还包括第一用户的姿势、活动以及表情中的至少一个,动作模式组中包括的各个动作模式还表示化身的姿势、活动以及表情的中的至少一个。也可以是,至少一个处理器选择表示与第一用户的姿势、活动以及表情中的至少一个对应的化身的姿势、活动以及表情中的至少一个的动作模式。通过使姿势、活动以及表情中的至少一个反映至化身的动作,能实现使用了图像的自然的交流。
[0039]
在其他方面的交流支持系统中,也可以是,动作模式组包括表示根据化身的视线的变化进行的、化身的上半身的旋转、化身的头的旋转以及化身的黑眼珠的移动中的至少一个的动作模式。通过根据化身的视线的变化来表现这样的非语言行为,能实现用户间的顺畅的交流或创造性的对话。
[0040]
在其他方面的交流支持系统中,也可以是,影像数据包括图像数据和声音数据。也
可以是,至少一个处理器将影像数据分离为图像数据和声音数据,对图像数据进行解析并选择与第一用户的非语言行为对应的动作模式,将表示选择出的动作模式的非语言行为数据与声音数据的组合作为控制数据发送至第二终端。第一用户的非语言行为被反映至化身的动作,并且该第一用户的声音被提供给第二终端。第二用户能通过识别化身的动作和该声音来与第一用户取得自然的交流。
[0041]
在其他方面的交流支持系统中,也可以是,至少一个处理器通过将表示共享项目的共享项目数据发送至第一终端和第二终端的每一个来使包含该共享项目的虚拟空间显示于第一终端和第二终端的每一个。通过共享项目被提供给各用户,第二用户能一边与第一用户共享该项目一边与该第一用户取得自然的交流。
[0042]
[本公开的实施方式的详情]
[0043]
以下,参照附图对本公开中的实施方式进行详细说明。需要说明的是,在附图的说明中对相同或等同的要素标注相同的附图标记,并省略重复的说明。
[0044]
(系统的构成)
[0045]
图1是表示实施方式的交流支持系统100的概要的一个例子的图。交流支持系统100是支持用户间的交流的计算机系统。交流支持系统100的使用目的不被限定。例如,交流支持系统100可以用于视频会议、聊天、诊察、咨询(counselling)、面试(人物评价)、远程办公等各种各样的目的。
[0046]
交流支持系统100包括建立多个终端1间的通话会话(session)的服务器2。多个终端1能通过经由通信网络n与服务器2通信连接来与其他终端1建立通话会话。在使用服务器2构成交流支持系统100的情况下,交流支持是云服务的一种。在图1中示出两台终端1,但连接于交流支持系统100的终端1的个数(换言之,参加一个通话会话的终端1的个数)不被限定。
[0047]
终端1是由交流支持系统100的用户使用的计算机。终端1的种类不被限定。例如,终端1可以是便携式电话机、高性能便携式电话机(智能手机)、平板终端、台式个人计算机、膝上型个人计算机或者可穿戴终端。如图1所示,终端1具备摄像部13、显示部14、操作部15以及声音输入输出部16。
[0048]
用户对操作部15进行操作并通过摄像部13对自身进行拍摄,一边确认在显示部14显示的各种信息(对方的化身、文件等),一边经由声音输入输出部16与对方进行会话。终端1通过对由摄像部13拍摄到的图像和由声音输入输出部16得到的声音的数据进行编码和复用来生成影像数据,并经由通话会话来发送该影像数据。终端1接收从另外的终端1发送的影像数据,并从显示部14和声音输入输出部16输出基于该影像数据的图像和声音。
[0049]
如图1所示,摄像部13的设置部位各种各样。但是,将摄像部13设于显示部14内(即,在供对方的图像显示的部位设置摄像部13)是困难的。在使拍摄到的人物像保持原样地显示于对方的终端1的显示部14的情况下,人物图像的视线并不朝向对方而是稍微偏离。图2是表示该视线的偏离的例子的图。如图2所示,视线的偏离是由于视差角φ而产生的,该视差角φ是看显示部14的用户的视线与拍摄用户的摄像部13的光轴之差。若该视差角φ大,则在用户间使视线一致变得困难,因此用户会对交流感到受挫(frustration)。
[0050]
为了消除或缓和这样的状况来支持自然的交流,交流支持系统100使与第一用户对应的化身显示于第二用户的终端1(第二终端)。然后,交流支持系统100基于来自第一用
户的终端1(第一终端)的影像数据,以该第一用户的非语言行为在第二终端被自然地表现的方式使该化身进行动作。即,交流支持系统100以与第一用户对应且在第二终端显示的化身进行与该第一用户的非语言行为对应的动作的方式,使该化身进行动作。例如,交流支持系统100执行使化身的视线朝向对方(正在经由显示部14看化身的人)或者使化身的身体的朝向朝自然的方向等控制。在现实中存在图2所示那样的视差角φ。但是,交流支持系统100并不是使由第一终端摄像得到的第一用户保持原样地显示于第二终端,而是使化身代替第一用户显示于第二终端,并控制该化身的非语言行为。通过该处理,该视差角φ最终被校正或消除,因此各用户能体验自然的对话。
[0051]
化身是指在由计算机表现的虚拟空间内表现的用户的分身。化身并不是由摄像部13拍摄到的用户本身(即,并不是由影像数据表示的用户本身),而是通过独立于影像数据的图像素材来显示。化身的表现方法不被限定,例如,化身既可以表示动画的角色,也可以由基于用户的照片预先制成的、更接近本人的用户图像来表示。化身可以通过二维或三维的计算机图形(cg:computer graphic)来描绘。化身可以由用户自由地选择。
[0052]
虚拟空间是指在终端1的显示部14表现的空间。化身被表现为存在于该虚拟空间内的对象。虚拟空间的表现方法不被限定,例如,虚拟空间既可以通过二维或三维的cg来描绘,也可以由呈现出现实世界的图像(运动图像或静止图像)来表现,还可以通过该图像和cg这双方来表现。与化身同样地,虚拟空间(背景画面)也可以由用户自由地选择。可以是化身能由用户配置于虚拟空间内的任意的位置。交流支持系统100表现能使多个用户认识共同的场景的虚拟空间。在此,需要注意的是,共同的场景只要是能使多个用户拥有共同的认识的场景即可。例如,共同的场景并不要求达到虚拟空间内的对象间的位置关系(例如化身彼此的位置关系)在多个终端1间相同。
[0053]
非语言行为是指人的行为中的不使用语言的行为。非语言行为包括视线、姿势、活动(包括手势)以及表情中的至少一个,还可以包括其他要素。在本公开中,将视线、姿势、活动、表情等构成非语言行为的要素也称为“非语言行为要素”。由化身表现的用户的非语言行为不受任何限定。例如,作为脸部的姿势或动作的例子,可列举出点头、摇头、歪头等。作为上半身的姿势或动作的例子,可列举出躯体的朝向、肩的扭转、肘的折弯、手的举放等。作为手指的活动的例子,可列举出伸展、弯曲、外展、内收等。作为表情的例子,可列举出中立、喜悦、轻蔑、厌恶、恐惧、惊讶、悲伤、愤怒等。
[0054]
图3~图5是表示由交流支持系统100提供的虚拟空间和化身的例子的图。在这些例子中,设为在三台终端1之间建立了通话会话,将三台终端1区分为用户ua的终端ta、用户ub的终端tb以及用户uc的终端tc。将与用户ua、ub、uc对应的化身分别设为化身va、vb、vc。设为提供给三位用户的虚拟空间300是模拟了在会议室中的谈话的虚拟空间。在各终端的显示部14显示的虚拟空间包含对方的化身。即,终端ta中的虚拟空间300包含化身vb、vc,终端tb中的虚拟空间300包含化身va、vc,终端tc中的虚拟空间300包含化身va、vb。
[0055]
图3的例子与以下状况对应:用户ua正在通过终端ta看化身vc,用户ub正在通过终端tb看化身vc,用户uc正在通过终端tc看化身vb。若将该状况置换为现实世界(用户ua、ub、uc存在于现实中的世界),则成为用户ua正在看用户uc,用户ub正在看用户uc,用户uc正在看用户ub。因此,用户ub、uc正在看彼此。通过交流支持系统100在各终端中如以下这样显示虚拟空间300。即,在终端ta中,显示化身vb与化身vc面对面的场景。在终端tb中,显示化身
on a chip:系统级芯片)。处理部10通过基于存储于存储部11的终端程序1p(图像控制程序)进行动作来使通用计算机作为终端1发挥功能。
[0064]
存储部11可以使用闪存、硬盘、ssd(solid state disk:固态硬盘)等非易失性存储介质来构成。存储部11存储终端程序1p和供处理部10参照的信息。为了判定(认证)终端1的用户的正当性,存储部11也可以存储用户图像或从用户图像得到的特征量(被矢量化后的特征量组)。存储部11还可以存储一个或多个化身图像或者一个或多个化身图像各自的特征量。
[0065]
通信部12使用网卡或无线通信设备来构成,实现向通信网络n的通信连接。
[0066]
摄像部13输出使用摄像机模块得到的影像信号。摄像部13具备内部存储器,以规定的帧率从由摄像机模块输出的影像信号捕捉帧图像并将该帧图像存储于该内部存储器。处理部10能从摄像部13的内部存储器依次获取帧图像。
[0067]
显示部14使用液晶面板、有机el显示器等显示装置来构成。显示部14对由处理部10生成的图像数据进行处理并输出图像。
[0068]
操作部15是受理用户的操作的接口,使用物理按钮、触摸面板、声音输入输出部16的麦克风16b等来构成。操作部15可以经由物理按钮或在触摸面板上显示的接口来受理操作。或者,操作部15既可以通过利用麦克风16b对输入声音进行处理来识别操作内容,也可以以使用了从扬声器16a输出的声音的对话形式来受理操作。
[0069]
声音输入输出部16使用扬声器16a和麦克风16b来构成。声音输入输出部16将基于影像数据的声音从扬声器16a输出,并将使用麦克风16b得到的声音向声音数据进行数字转换。
[0070]
服务器2使用一个或多个服务器计算机来构成。服务器2可以由在一台服务器计算机中进行动作的逻辑上为多个的虚拟机来实现。在使用物理上为多个的服务器计算机的情况下,通过这些服务器计算机经由通信网络相互连接来构成服务器2。服务器2具备处理部20、存储部21以及通信部22。
[0071]
处理部20使用cpu、gpu等处理器来构成。处理部20通过基于存储于存储部21的服务器程序2p(交流支持程序)进行动作来使通用计算机作为服务器2发挥功能。
[0072]
存储部21使用硬盘、闪存等非易失性存储介质来构成。或者,也可以是作为外部存储装置的数据库作为存储部21发挥功能。存储部21存储服务器程序2p和供处理部20参照的信息。
[0073]
通信部22使用网卡或无线通信设备来构成,实现向通信网络n的通信连接。服务器2通过通信部22来实现经由通信网络n的通信连接,由此在两个以上的任意个数的终端1间建立通话会话。用于通话会话的数据通信可以通过加密处理等更安全地被执行。
[0074]
通信网络n的构成不被限定。例如,通信网络n可以使用因特网(公共网)、通信载波网络、实现交流支持系统100的运营商的运营商网络、基站bs、接入点ap等来构建。服务器2也可以从运营商网络向通信网络n连接。
[0075]
图7是表示终端1的处理部10的功能构成的一个例子的图。处理部10具备影像发送部101和画面控制部102来作为功能要素。这些功能要素通过处理部10按照终端程序1p进行动作来实现。
[0076]
影像发送部101是将呈现出终端1的用户的影像数据发送至服务器2的功能要素。
影像发送部101通过对从摄像部13输入的表示一系列的帧图像的图像数据(以下,称为“帧图像数据”)和从麦克风16b输入的声音数据进行复用来生成影像数据。影像发送部101基于时间戳来取得帧图像数据与声音数据之间的同步。然后,影像发送部101对影像数据进行编码,并控制通信部12来将该编码后的影像数据发送至服务器2。用于影像数据的编码的技术不被限定。例如,影像发送部101既可以使用h.265等运动图像压缩技术,也可以使用aac(advanced audio coding:高级音频编码)等声音编码。
[0077]
画面控制部102是对与通话会话对应的画面进行控制的功能要素。画面控制部102响应于通话会话的开始而将该画面显示于显示部14。该画面表示至少包含与对方对应的化身的虚拟空间。虚拟空间的构成不被限定,可以按照任意的方针来设计。例如,虚拟空间可以模拟会议的场景或会议室。虚拟空间可以包含由服务器2提供的、在终端1间共享的项目(在各个终端1中显示的项目)。在本公开中,将该项目称为“共享项目”。共享项目的种类不被限定。例如,共享项目既可以表示桌子、白板等日常用具,也可以表示各用户能阅览的共享资料。
[0078]
画面控制部102包括对画面内的化身进行控制的化身控制部103。化身控制部103基于从服务器2发送并由通信部12接收的控制数据来使画面内的化身进行动作。该控制数据包括用于使作为对方的第一用户的非语言行为反映至化身的非语言行为数据和表示该用户的声音的声音数据。化身控制部103基于非语言行为数据来控制在显示部14显示的化身的动作。而且,化身控制部103以化身的动作与用户的声音同步的方式,对声音数据进行处理并从扬声器16a输出该声音。
[0079]
图8是表示服务器2的处理部20的功能构成的一个例子的图。处理部20具备共享项目管理部201和影像处理部202来作为功能要素。这些功能要素通过处理部20按照服务器程序2p进行动作来实现。
[0080]
共享项目管理部201是管理共享项目的功能要素。共享项目管理部201响应于通话会话的开始或者响应于来自任意的终端1的请求信号而将表示共享项目的共享项目数据发送至各终端1。共享项目管理部201通过该发送来使包含共享项目的虚拟空间显示于各终端1。共享项目数据既可以预先储存于存储部21,也可以包含于来自特定的终端1的请求信号。
[0081]
影像处理部202是基于从第一终端发送来的影像数据来生成控制数据并将该控制数据发送至第二终端的功能要素。影像处理部202将影像数据分离为帧图像数据和声音数据,并根据该帧图像数据来确定与第一用户的非语言行为对应的动作模式。动作模式是指通过对由影像数据表示的用户的非语言行为进行体系化或简化而表现的、化身的动作的类型或种类。人的具体的非语言行为可以基于视线、表情、躯体的朝向、手的活动或它们中的任意的两个以上的组合而无限地存在。影像处理部202将该无限的非语言行为体系化或简化为有限个的动作模式。然后,影像处理部202将表示选择出的动作模式的非语言行为数据与从影像数据分离出的声音数据的组合作为控制数据发送至第二终端。非语言行为数据用于使第一用户的非语言行为反映至化身。
[0082]
影像处理部202具备模式选择部203和控制数据生成部204。模式选择部203对从影像数据分离出的帧图像数据进行解析,并从化身的动作模式组之中选择与第一用户的非语言行为对应的动作模式。在交流支持系统100中,该无限的非语言行为被归纳成有限个的动作模式,表示各个动作模式的信息被预先存储于存储部21。通过将化身的动作模式化,用于
控制化身的数据量被抑制,因此能大幅减少通信量。模式选择部203参照存储部21来读出与第一用户的非语言行为对应的动作模式。控制数据生成部204将表示选择出的动作模式的非语言行为数据与从影像数据分离出的声音数据的组合作为控制数据发送至第二终端。
[0083]
(系统的动作)
[0084]
参照图9~图11,对交流支持系统100的动作进行说明,并且对本实施方式的交流支持方法进行说明。图9~图11均是表示交流支持系统100的动作的一个例子的时序图。图9~图11所示的处理均以三位用户登录交流支持系统100并在三台终端1之间建立了通话会话为前提。根据需要,将三台终端1区分为用户ua的终端ta、用户ub的终端tb以及用户uc的终端tc。将与用户ua、ub、uc对应的化身分别称为化身va、vb、vc。图9将基于来自拍摄了用户ua(第一用户)的终端ta(第一终端)的影像数据来使在终端tb、tc(第二终端)显示的化身va进行动作的处理作为处理流程s1示出。图10将基于来自拍摄了用户ub(第一用户)的终端tb(第一终端)的影像数据来使在终端ta、tc(第二终端)显示的化身vb进行动作的处理作为处理流程s2示出。图11将基于来自拍摄了用户uc(第一用户)的终端tc(第一终端)的影像数据来使在终端ta、tb(第二终端)显示的化身vc进行动作的处理作为处理流程s3示出。
[0085]
通话会话刚被建立之后的虚拟空间中的化身的状态(姿势)可以被任意地设计。例如,各终端1的化身控制部103可以以表示一个以上的化身的每一个相对于显示部14(画面)斜坐且俯视的状态的方式显示化身。各终端1的画面控制部102或化身控制部103可以将各化身的姓名显示于显示部14。
[0086]
参照图9,对处理流程s1进行说明。在步骤s101中,终端ta的影像发送部101将呈现出用户ua的影像数据发送至服务器2。在服务器2中,影像处理部202接收该影像数据。
[0087]
在步骤s102中,影像处理部202将影像数据分离为帧图像数据和声音数据。
[0088]
在步骤s103中,模式选择部203对帧图像数据进行解析,并从化身的动作模式组之中选择与用户ua的非语言行为对应的动作模式。可能被选择的各个动作模式与至少一个非语言行为要素对应。例如,与视线对应的动作模式表示化身的视线。与姿势对应的动作模式表示化身的朝向(例如,脸部和躯体中的至少一个的朝向)和活动中的至少一方。与活动对应的动作模式例如表示挥手、摇头、歪头、点头等。与表情对应的模式表示化身的表情(笑脸、为难的表情、愤怒的表情等)。动作模式组中包括的各个动作模式可以表示由一个以上的非语言行为要素的组合表示的非语言行为。例如,各动作模式既可以表示由视线和姿势的组合表示的非语言行为,也可以表示由视线、姿势、活动以及表情的组合表示的非语言行为。或者,也可以针对各个非语言行为要素准备有限个的给定的动作模式。例如,可以准备关于视线的动作模式组和关于姿势的动作模式组。在针对各个非语言行为要素准备多个动作模式的情况下,模式选择部203针对一个以上的非语言行为要素选择一个动作模式。动作模式组中包括的动作模式的个数不被限定。例如,为了用化身稍微夸张地表现用户的非语言行为,也可以针对各个非语言行为要素预先准备十个等级左右的动作模式。
[0089]
在选择与视线对应的动作模式的情况下,模式选择部203以虚拟空间内的化身va的视线与由帧图像数据表示的用户ua的视线对应的方式,选择表示化身va的视线的动作模式。在用户ua正在经由终端ta的显示部14看虚拟空间内的化身vb的情况下,模式选择部203选择化身va的视线朝向化身vb(用户ub)的动作模式。在该情况下,在终端tb中,成为化身va被显示为透过显示部14朝向用户ub,在终端tc中,成为化身va被显示为朝向虚拟空间内的
化身vb。
[0090]
动作模式组可以包括表示根据化身的视线的变化进行的非语言行为的动作模式。例如,动作模式组可以包括表示根据化身的视线的变化进行的、化身的上半身的旋转、化身的头的旋转以及化身的黑眼珠的移动中的至少一个的动作模式。
[0091]
与帧图像数据的解析和动作模式的选择相关的技术不被限定。例如,模式选择部203可以使用人工智能(ai:artificial intelligence)来选择动作模式,例如可以使用作为ai的一种的机器学习来选择动作模式。机器学习是指通过基于被给予的信息反复地进行学习来自主地找出规律或规则的方法。作为机器学习的例子,可列举出深度学习。深度学习是指使用了多层结构的神经网络(深度神经网络(dnn:deep neural networks))的机器学习。神经网络是指模拟了人类的脑神经系统的机制的信息处理的模型。但是,机器学习的种类不限定于深度学习,模式选择部203可以使用任意的学习方法。
[0092]
在机器学习中使用学习模型。该学习模型是将表示图像数据的矢量数据作为输入矢量进行处理,并将表示非语言行为的矢量数据作为输出矢量输出的算法。该学习模型是被推定为预测精度最高的最佳的计算模型,因此可以称为“最佳的学习模型”。但是,需要注意的是,该最佳的学习模型未必是“现实中最佳的”。最佳的学习模型是通过由给定的计算机对包括呈现出人物的一系列的图像与非语言行为的动作模式的许多组合的训练数据进行处理来生成的。由训练数据表示的非语言行为的动作模式的集合与动作模式组对应。给定的计算机通过将表示人物图像的输入矢量输入至学习模型来计算出表示非语言行为的输出矢量,并求出该输出矢量与由训练数据表示的非语言行为的误差(即,推定结果与正确结果之差)。然后,计算机基于该误差来更新学习模型内的给定的动作参数。计算机通过重复这样的学习来生成最佳的学习模型,该学习模型被储存于存储部21。生成最佳的学习模型的计算机不被限定,例如既可以是服务器2,也可以是服务器2以外的计算机系统。生成最佳的学习模型的处理可以称为学习阶段。
[0093]
模式选择部203使用存储于存储部21的最佳的学习模型来选择动作模式。相对于学习阶段,由模式选择部203进行的学习模型的利用可以称为运用阶段。模式选择部203通过将帧图像数据作为输入矢量输入至该学习模型来得到表示与用户ua的非语言行为对应的模式的输出矢量。模式选择部203也可以通过从帧图像数据提取用户ua的区域并将该被提取区域作为输入矢量输入至学习模型来得到输出矢量。总之,输出矢量表示从有限个的给定的模式之中选择出的模式。
[0094]
或者,模式选择部203也可以不使用机器学习来选择动作模式。具体而言,模式选择部203从一系列的帧图像的每一个提取用户ua的区域,并从该被提取区域确定包括脸部的上半身的活动。例如,模式选择部203可以基于一系列的被提取区域中的特征量的变化来确定用户ua的至少一个非语言行为要素。模式选择部203从动作模式组之中选择与至少一个非语言行为要素对应的动作模式。
[0095]
模式选择部203在无法基于帧图像数据来选择动作模式的情况下,可以选择给定的特定的动作模式(例如,表示化身va的初始状态的动作模式)。
[0096]
在步骤s104中,控制数据生成部204生成表示选择出的动作模式的非语言行为数据与声音数据的组合来作为控制数据。控制数据生成部204生成不使用图像而是以文本(即字符串)表现了选择出的动作模式的非语言行为数据。例如,控制数据生成部204可以通过
以json(javascript object notation:javascript对象简谱)形式记述选择出的动作模式来生成非语言行为数据。或者,控制数据生成部204也可以通过以xml(extensible markup language:可扩展置标语言)等其他形式记述动作模式来生成非语言行为数据。控制数据生成部204既可以生成非语言行为数据和声音数据被一体化了的控制数据,也可以将分别存在的非语言行为数据和声音数据的组合作为控制数据来处理。因此,控制数据的物理结构不被限定。总之,控制数据生成部204基于时间戳来取得帧图像数据与声音数据之间的同步。
[0097]
在步骤s105中,控制数据生成部204将控制数据发送至终端tb、tc。与控制数据的物理结构不被限定相对应地,控制数据的发送方法也不被限定。例如,控制数据生成部204可以发送非语言行为数据和声音数据被一体化了的控制数据。或者,控制数据生成部204也可以通过发送物理上相互独立的非语言行为数据和声音数据的组合来将控制数据发送至终端tb、tc。在终端tb、tc的每一个中,画面控制部102接收该控制数据。
[0098]
在终端tb中执行步骤s106、s107的处理。在步骤s106中,终端tb的化身控制部103基于非语言行为数据来控制与用户ua对应的化身va的动作(显示)。化身控制部103按照由非语言行为数据表示的动作模式来使在终端tb的显示部14显示的化身va进行动作。例如,化身控制部103通过执行使化身va的视线、姿势、活动以及表情中的至少一个从当前的状态向由该动作模式表示的下一个状态变化的动画控制来使化身va进行动作。在一个例子中,化身va通过这样的控制一边采取上半身的旋转、头的旋转、黑眼珠的移动中的至少一个动作,一边使视线与用户ub一致。在化身va正在经由显示部14看用户ub的场景(即,使化身va的视线与用户ub一致的场景)中,化身控制部103可以与该视线一致关联地展现化身va的表情。例如,化身控制部103可以通过以一定时间(例如0.5秒~1秒)睁大眼睛或者挑起眉毛或者扬起嘴角等方法来展现化身va的表情,由此强调视线的一致(即,目光接触)。
[0099]
在步骤s107中,终端tb的化身控制部103以与化身va的动作(显示)同步的方式对声音数据进行处理并从扬声器16a输出声音。化身控制部103可以基于所输出的声音来使化身va进一步进行动作。例如,化身控制部103可以使化身va的嘴变化,或者与用户ua的表情或感情对应地使脸部变化,或者使胳膊或手活动。
[0100]
通过步骤s106、s107的处理,用户ub能听到用户ua的讲话,并且能借由化身va来识别用户ua的当前的非语言行为(例如,视线、姿势、活动以及表情中的至少一个)。
[0101]
除了步骤s106、s107的处理之外,终端tb的画面控制部102还可以将用户ub实际正在看的区域(注视区域)显示于显示部14。例如,画面控制部102可以通过对从摄像部13得到的帧图像数据进行解析来推定用户ub的视线,并基于该推定结果将图3所示的辅助表现310显示于显示部14。
[0102]
在终端tc中,执行与步骤s106、s107同样的步骤s108、s109的处理。通过这一系列的处理,用户uc能听到用户ua的讲话,并且能借由化身va来识别用户ua的当前的非语言行为(例如,视线、姿势、活动以及表情中的至少一个)。
[0103]
交流支持系统100与处理流程s1并行地执行处理流程s2、s3。图10所示的处理流程s2包括与步骤s101~s109对应的步骤s201~s209。图11所示的处理流程s3包括与步骤s101~s109对应的步骤s301~s309。处理流程s1~s3被并行地处理,由此在各终端1中各用户的讲话和非语言行为通过各化身被实时地表现。
[0104]
[变形例]
[0105]
以上,基于本公开的实施方式进行了详细说明。但是,本公开并不限定于上述实施方式。本公开在不脱离其主旨的范围内可以进行各种各样的变形。
[0106]
在上述实施方式中,交流支持系统100使用服务器2来构成,但交流支持系统也可以应用于不使用服务器2的终端彼此的点对点(peer to peer)方式的通话会话。在该情况下,服务器2的各功能要素可以安装于第一终端和第二终端中的任一方,也可以分开安装于第一终端和第二终端。因此,交流支持系统的至少一个处理器既可以位于服务器内也可以位于终端内。
[0107]
在本公开中,“至少一个处理器执行第一处理,执行第二处理,
……
执行第n处理。”这样的表达是包括从第一处理起至第n处理为止的n个处理的执行主体(即处理器)在中途改变的情况的概念。即,该表达是包括n个处理全部由相同的处理器执行的情况和在n个处理中处理器以任意的方针改变的情况这双方的概念。
[0108]
影像数据和控制数据也可以不包括声音数据。即,交流支持系统也可以用于支持不伴有声音的交流(例如手语)。
[0109]
交流支持系统100中的各装置具备被配置为包括微处理器、rom、ram等存储部的计算机。微处理器等处理部从该存储部读出包括上述的各步骤的一部分或全部的程序并执行。程序能从外部的服务器装置等安装于各计算机。各装置的程序既可以以储存于cd-rom、dvd-rom、半导体存储器等记录介质的状态来分发,也可以经由通信网络来分发。
[0110]
由至少一个处理器执行的方法的处理过程不限定于上述实施方式中的例子。例如,既可以省略上述的步骤(处理)的一部分,也可以按照另外的顺序来执行各步骤。既可以组合上述的步骤中的任意的两个以上的步骤,也可以修改或删除步骤的一部分。或者,除了上述的各步骤之外,还可以执行其他步骤。
[0111]
在上述实施方式中,对基于与用户的非语言行为对应地选择出的模式来使化身进行动作的例子进行了说明。不过,非语言行为以外的信息、例如用户的声音信息也可以用于模式选择。用户的声音信息的例子是用户的声音和用户的语言。在实施这样的模式选择的情况下,在交流支持系统100中,例如进行以下这样的处理。
[0112]
在服务器2中,影像处理部202的模式选择部203不仅如之前说明的那样对从影像数据分离出的帧图像数据进行解析,而且还对从影像数据分离出的声音数据、更具体而言对第一用户的声音和语言进行解析。第一用户的声音是第一用户所发出的声的信息,可以是声音数据本身。第一用户的语言是第一用户的声音的意思内容,例如通过对声音数据执行声音识别处理来得到。模式选择部203通过不仅对帧图像数据进行解析而且还对声音和语言进行解析来选择与第一用户的非语言行为和声音信息对应的动作模式。
[0113]
在上述的模式选择中,也可以如之前说明的那样使用人工智能(ai)。在该情况下,存储于存储部21的学习模型可以是以当被输入用户的影像数据或被输入用户的影像数据和基于该影像数据的数据时,输出表示与该用户的非语言行为和声音信息对应的模式的信息的方式,使用训练数据生成的已学习模型。影像数据是影像数据中包括的帧图像数据和声音数据。基于影像数据的数据是相当于上述的“语言”的数据,例如是影像数据中包括的声音数据的声音识别结果。在学习模型内执行声音识别处理的情况下,可以在学习模型中输入帧图像数据和声音数据。在学习模型外执行声音识别处理的情况下,可以在学习模型
中输入帧图像数据、声音数据以及该声音数据的声音识别处理结果。在后者的情况下,模式选择部203在使用学习模型之前执行得到声音数据的声音识别处理结果这样的前处理。在声音识别处理中,可以使用各种公知的方法(声音识别处理引擎等)。声音识别处理的功能既可以由模式选择部203或者学习模型来具备,也可以以能被模式选择部203或者学习模型利用的方式设于服务器2的其他部分或服务器2的外部(另外的服务器等)。
[0114]
上述的训练数据的例子例如可以是将用户的影像数据或者将用户的影像数据及基于该影像数据的数据和表示与该用户的非语言行为和声音信息对应的动作模式的信息建立对应地存储而得到的教学数据的组。训练数据中的输入数据(用户的影像数据等)可以通过使用摄像机、麦克风等对用户平时交流的情形进行监控来获取。训练数据中的输出数据(表示模式的信息)既可以由例如该用户、用户的相关人员、专家等选择,也可以使用公知的分类处理等自动地选择。
[0115]
作为程序的一个形态或遵照程序的模型,学习模型可以被存储于存储部21(图6)来作为服务器程序2p的一部分。存储于存储部21的学习模型可以被适时更新。
[0116]
模式选择部203也可以不使用学习模型来选择模式。如果是用户的声音,则例如音量、音调、速度等可以被反映至模式选择。如果是用户的语言,则例如单词的类别、上下文等可以被反映至模式选择。
[0117]
通过如以上那样不仅使第一用户的非语言行为反映至化身的动作,而且还使第一用户的声音信息反映至化身的动作,能更准确地再现第一用户的感情、活动等,能实现更顺畅的交流。该效果通过利用大数据分析来准备用于生成学习模型的训练数据而被进一步提高。如果按每个用户生成学习模型(如果进行定制),则能更适当地再现该用户的感情、活动。
[0118]
附图标记说明
[0119]
100
……
交流支持系统,1
……
终端,10
……
处理部,11
……
存储部,12
……
通信部,13
……
摄像部,14
……
显示部,15
……
操作部,16
……
声音输入输出部,16b
……
麦克风,16a
……
扬声器,101
……
影像发送部,102
……
画面控制部,103
……
化身控制部,2
……
服务器,20
……
处理部,21
……
存储部,22
……
通信部,201
……
共享项目管理部,202
……
影像处理部,203
……
模式选择部,204
……
控制数据生成部,ua、ub、uc
……
用户,ta、tb、tc
……
终端,va、vb、vc
……
化身,300
……
虚拟空间,301
……
演示资料,1p
……
终端程序,2p
……
服务器程序,bs
……
基站,ap
……
接入点,n
……
通信网络。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1