利用随机哈密顿量的相位估计的制作方法
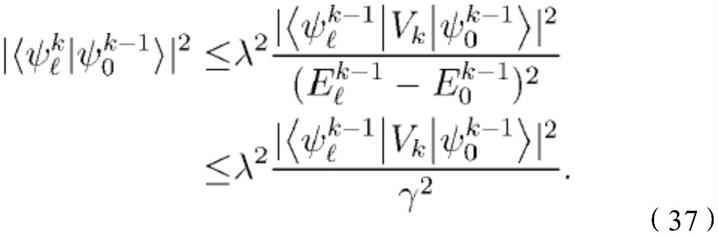
利用随机哈密顿量的相位估计
1.相关申请的交叉引用
2.本技术要求于2019年6月3日提交的、名称为“phase estimation with randomized hamiltonians”的美国非临时申请第16/430,205号的优先权,该非临时申请要求于2019年3月15日提交的、名称为“phase estimation with randomized hamiltonians”的美国临时申请第62/819,301号的权益,这两者通过引用整体并入本文。
技术领域
3.本技术总体上涉及量子计算。更详细地,公开了示例方法,其中哈密顿项被随机化并且随机绘制近似的精度随着相位估计中所需要的精度的增加而被适配。
技术实现要素:
4.现有的物理系统动力学模拟方法使用确定性或随机选择的哈密顿量项。在本公开中,公开了示例方法,其中哈密顿项被随机化并且随机绘制近似的精度随着相位估计中所需要的精度的增加而被适配。这减少了所需要的量子门的数目,并且在某些情况中减少了在模拟中使用的量子位的数目。
5.实施例包括通过在每次模拟时将哈密顿量替换为随机生成的哈密顿量来随机化相位估计。另外的实施例涉及在迭代相位估计算法内使用随机化来选择用于包括在近似中的哈密顿项以及它们的排序。某些实施例涉及使用基于基态的项的重要性的重要性函数来确定它是否被包括在随机采样的哈密顿量中。另外的实施例涉及使用基于对基态(诸如但不限于cisd状态)的变分近似的重要性采样。某些实施例涉及使用自适应贝叶斯方法与该过程相结合来量化在给定算法正在估计的特征值中的当前不确定性时所需要的哈密顿量的精度。
6.在该应用中,用于执行量子模拟的示例方法使用自适应哈密顿随机化。所描述的特定实施例不应当被解释为限制性的,因为所公开的方法动作可以单独地、以不同顺序或至少部分彼此同时地执行。此外,任何公开的方法或方法动作可以与本文中公开的任何其他方法或方法动作一起执行。在特定实施例中,输入要由量子计算机设备计算的哈密顿量;在相位估计算法内使用随机化来减少哈密顿量中的哈密顿项的数目;并且输出针对哈密顿项的数目减少的哈密顿量的量子电路描述。
7.在某些实施例中,减少包括基于重要性函数来选择一个或多个随机哈密顿项;基于所选择的哈密顿随机项中的每个哈密顿随机项的重要性来重新加权所选择的随机哈密顿项;并且使用重新加权的随机项生成量子电路描述。一些实施例还包括在量子计算设备中实现由量子电路描述所描述的量子电路;并且测量量子电路的量子态。另外的实施例包括基于来自测量的结果(例如,使用迭代过程)重新执行该方法。在一些实施例中,迭代过程包括计算针对哈密顿量的期望精度值;基于实现和测量的结果来计算针对哈密顿量的标准偏差;并且将期望精度值与标准偏差比较。一些实施例还包括基于减少来改变哈密顿项的阶数。某些实施例还包括将重要性函数应用于基态的哈密顿量的项;并且至少部分地基于
重要性函数来选择一个或多个随机哈密顿项。一些实施例包括使用基于对基态的变分近似的重要性采样。某些实施例还包括给定特征值中的当前不确定性的估计,使用自适应贝叶斯方法量化针对哈密顿量所需要的精度。
8.其他实施例包括一种或多种存储计算机可执行指令的计算机可读介质,该计算机可执行指令在由计算机执行时,使得计算机执行一种方法,该方法包括输入要由量子计算机设备计算的哈密顿量;在相位估计算法内使用随机化来减少哈密顿量中的哈密顿项的数目;并且输出针对哈密顿项的数目减少的哈密顿量的量子电路描述。
9.从以下参考附图进行的详细描述中,所公开的技术的前述和其他目的、特征和优点将变得更加明显。
附图说明
10.图1示出了用于执行迭代相位估计的量子电路。
11.图2至图9包含的图表示出了平均基态能变化(与未采样哈密顿量相比)、采样哈密顿量上的基态能方差、平均量子位要求、以及li2的采样哈密顿量中的平均项数(作为用于生成哈密顿量的样本数和参数ρ的值的函数)。
12.图10是示出根据所公开的技术的实施例的用于实现重要性采样模拟方法的示例方法的流程图。
13.图11是示出用于使用自适应哈密顿随机化执行量子模拟的示例方法的流程图。
14.图12示出了可以在其中实现所描述的实施例的各方面的合适的经典计算环境的一般化示例。
15.图13示出了用于实现根据所公开的技术的系统的可能的网络拓扑(例如,客户端服务器网络)的示例。
16.图14示出了用于实现根据所公开的技术的系统的可能的网络拓扑结构(例如,分布式计算环境)的另一示例。
17.图15示出了用于实现所公开的技术的示例性系统。
18.图16是示出用于使用自适应哈密顿随机化执行量子模拟的示例方法的流程图。
具体实施方式
19.i.引言
20.并非所有哈密顿项在量子模拟中被平等创建。从化学、材料和其他应用中自然产生的哈密顿量通常由小到可以忽略不计的项组成。这些项通常在哈密顿量到达模拟器之前从哈密顿量中被剔除。正式出现在哈密顿量中的其他项被去除,不是因为它们的范数,而是因为预计它们不会影响感兴趣量。例如,在量子化学中,人们通常选择活跃的轨道空间,而忽略活跃空间之外的任何轨道。这导致哈密顿量中省略了很多大项。
21.这个过程(通常被称为抽取)通常涉及从哈密顿量中系统地去除项并且模拟动力学。这种方案背后的想法是去除哈密顿量中的项,直到特征值中允许的最大变化与所需要的精度水平相当。针对化学,化学精度为这样的模拟设置自然精度阈值,但通常无需将该精度要求视为常数。
22.本公开的示例创新之一是,在迭代相位估计中,哈密顿量中采用的项数在理想情
况中不应当保持恒定。原因是,当人们试图学习例如本征相的二进制扩展的给定位时,高阶位大多是无关的。与学习高阶位时相比,可以容忍精度低得多的模拟。然后,随着迭代相位估计进行通过相位估计的位,适配哈密顿量中的项数是有意义的。所公开的技术的示例实施例提供了一种用于去除项的系统方法并且提供了这样的过程不需要显著影响相位估计的结果或其成功概率的形式证明。
23.示例高级抽取程序背后的概念之一是使用一种重要性采样形式先验地估计哈密顿量中的哪些项是重要的。然后在模拟电路内使用这些随机化哈密顿量来准备近似基态。因此表明,使用让人想起芝诺效应或量子绝热定理的分析,在每一轮相位估计中准备的本征态误差不需要对真实哈密顿量而估计的本征相的后验均值产生实质性影响。这表明,在对特征值差距进行适当假定的情况中,该过程可以用于降低模拟的时间复杂度,甚至在某些情况中,通过标识模拟所要求的精度级别不需要的量子位,可以降低空间复杂度。
24.本公开首先回顾迭代相位估计和贝叶斯推理,它们用于量化相位推理中的最大误差。本公开然后继续检查在简单情况中使用随机哈密顿量对由相位估计产生的本征相位的影响,其中在迭代相位估计的每个步骤使用固定但随机的哈密顿量。然后检查更复杂的情况,其中迭代相位估计电路中e
‑
iht
的每次重复使用不同随机哈密顿量而被实现。理论分析的结论是,如果原始哈密顿量的特征值差距足够大,则成功概率不会显著降低。此外,还示出了该采样过程的数值示例,并且从中可以得出结论:哈密顿量的示例采样过程会对哈密顿量中的项数产生重大影响,并且甚至在某些情况中,对在模拟中使用的量子位数也有重大影响。
25.ii.迭代相位估计
26.迭代相位估计背后的想法基于构建量子电路作为干涉仪的目标,其中希望探测的幺正一被应用于干涉仪的两个分支中的一个分支,但不被应用于另一分支。当量子态在协议结束时被允许干扰自身时,干扰模式揭示了本征相。这个过程允许在标准量子极限内估计u的特征值(即,在误差∈内估计相位所需要的u的应用次数为θ(1/∈2)。如果允许量子态重复通过干涉仪电路(或使用纠缠输入),则这种缩放可以减少到θ(1/∈),这被称为海森堡极限。这种电路在图1的示意框图100中示出。特别地,图1示出了用于执行迭代相位估计的量子电路。m是酉u的重复次数(不一定是整数),θ是辅助|0>和|1>状态之间的相位变化。
27.在u|ψ>=e
iφ
|ψ>的情况中,相位估计电路很容易分析。如果u重复m次,θ是相位变化,则使用这些参数的图1中电路的给定测量结果o∈{0,1}的似然是
[0028][0029]
在设计迭代相位估计实验时可以使用很多自由参数。特别地,用于为每个实验生成m和θ的规则随着用于处理这些实验返回的数据的方法而发生根本变化。诸如kitaev相位估计算法、稳健相位估计、信息论相位估计、或任何数目的近似贝叶斯方法等方法为选择这些参数提供了良好的启发式方法。在本公开中,假定人们不希望指定用于选择实验的这些方法中的任何一种,也不希望关注所使用的具体数据处理方法。尽管如此,还是依赖贝叶斯方法来讨论随机化哈密顿量对本征相估计的影响。
[0030]
贝叶斯定理可以解释为在给定一组实验证据和先验信念的情况中提供用于更新关于某些事实的信念的正确方法。实验者的初始信念由先验分布pr(φ)编码。很多情况中合适的是,将pr(φ)设置为[0,2π)上的均匀分布以表示关于本征相的最大无知状态。然而,在量子模拟中,如果相位估计中的每一步都使用并且针对不同t
j
服从则可以选择更广泛的先验,因为这样的实验可以学习e0,而不是使用固定t的实验,它会产生φ=e0t mod 2π。
[0031]
因此,贝叶斯定理给出后验分布pr(φ|o;φ,m)应当为
[0032][0033]
给定完整数据集而不是单一数据,可以得到
[0034][0035]
这个概率分布对实验者的整个知识状态进行编码,前提是数据被最佳地处理。
[0036]
不习惯将后验分布(或其近似)作为相位估计协议的输出而返回。相反,给出φ的点估计。最常用的估计是最大后验(map)估计,它只是概率最大的φ。尽管该量具有很好的操作解释,但出于本公开的目的,它存在很多缺陷。这里的主要缺点是,map估计不稳健,因为如果φ的两个不同值具有可比较的似然,则似然中的小误差会导致map估计的根本变化。为此目的,后验均值是用于这个目的的更好估计,其形式上是后验均值可以被看作是减少φ的任何无偏估计中的均方误差的估计,并且因此它的动机很好。它还具有对似然性中的小扰动具有鲁棒性的特性,这是下面用于估计对相位估计实验结果的影响的特征。
[0037]
iii.似然函数的误差
[0038]
a.酉的线性组合
[0039]
用于量子模拟的酉方法的线性组合已经迅速成为模拟量子系统中哈密顿动力学的一种受欢迎的方法。与trotter分解不同,这些方法中的很多方法不一定会产生模拟量子动力学的酉近似。这表示不可能直接使用斯通定理来论证酉方法的线性组合代替e
‑
iht
来实现反过来,由于对迭代相位估中从trotter分解到估计阶段的误差传播的标准分析失败,因为人们无法直接推理的特征值。
[0040]
在这里,为了部分解决这个问题,讨论了这样的误差可能对迭代相位估计的似然函数产生的影响。
[0041]
引理1.令v是一个可能的非酉运算,它可以由量子计算机以受控方式非确定性地执行,从而存在||u
‑
v||<δ<1的酉u。如果定义在v上后选的似然函数为
则
[0042]
证明。假定o=0。然后,针对输入状态|ψ>,由迭代相位估计输出的似然函数的误差为
[0043][0044]
因为p(0|et;m,θ)+p(1|et;m,θ)=1,它遵循相同的界限必须也适用于o=1。因此,结果适用于所声称的任何o。
[0045]
这个结果虽然直截了当但很重要,因为它允许后验分布平均值的最大误差传播通过迭代相位估计协议。传播这些误差的能力最终将使我们能够证明,迭代相位估计可以用于从酉方法的线性组合中估计特征值。
[0046]
b.欠采样哈密顿量
[0047]
现在考虑从哈密顿量均匀采样各项的情况。令哈密顿量是l个可模拟哈密顿量h
l
的总和始终,考虑h的本征态|ψ>及其对应本征能e。根据原始量,通过从原始哈密顿量对项均匀地采样,可以构造新的哈密顿量
[0048][0049]
当对哈密顿量进行随机欠采样时,自然会引入误差。主要问题不在于这样的误差有多大,而在于它们如何影响迭代相位估计协议。以下引理说明对似然函数的影响可以任意小。
[0050]
引理2.令l
i
是独立于更换由来自{1,...,l}的均匀采样元素形成的序列映射{1,...,m}
→
{1,...,l}的索引族,并且令{h
l
:l=1,...,l}是的对应的哈密顿族。针对|ψ>,h的本征态使得h|ψ>=e|ψ>并且对应本征态h
samp
|ψ
i
>=e
i
|ψ
i
>,则相位估计的似然函数中的误差在大的m极限内在h
samp
上以高概率消失:
[0051][0052]
证明。因为项是均匀采样的,所以每组项{l
i
}可能相等,并且通过期望的线性知道
[0053]
二阶矩很容易从分布的独立性来计算。
[0054][0055]
由于不同序列l
i
是随机均匀选择的,因此结果来自观察
[0056]
根据三阶微扰理论,任何特征值的前导阶变化在误差范围内为o(<ψ|(h
‑
h
samp
)|ψ>)。因此,根据等式(6),这种变化的方差是
[0057][0058]
这进一步表示,扰动的本征态|ψ
i
>具有本征值
[0059][0060]
根据马尔可夫不等式,其在i上的概率很高。因此,根据泰勒定理和等式(1),
[0061][0062]
其在i上的概率很高。
[0063]
这一结果表明,如果对要被包括在欠采样哈密顿量中的哈密顿量的系数进行均匀采样,则可以使哈密顿量的估计的误差任意小。在这种情况中,取m
→
∞不会导致模拟成本发散(就像很多采样问题一样)。这是因为,一旦每个可能的项都被包括在哈密顿量中,则欠采样就没有意义了,并且还可以将h
samp
取为h,以消除对哈密顿量进行欠采样所产生的似然函数的方差。一般来说,为了保证似然函数中的误差至多是一个常数,需要取因此,这表明,随着任何迭代相位估计算法的进行,(除非由于扰动而意外激发状态的问题)通过将m与m平方成反比来获取对本征相位的良好估计。
[0064]
iv.使用随机哈密顿量的贝叶斯相位估计
[0065]
定理3.令e是一个事件,令θ∈[
‑
π,π)的p(e|θ)和p
′
(e|θ)是两个似然函数,从而使得max
θ
(|p(e|θ)
‑
p
′
(e|θ)|)≤δ,并且进一步假定针对先验p(θ),min(p(e),p
′
(e))≥2δ。得到
[0066][0067]
并且如果其中1
‑
|p
′
(e
j
|θ)/p(e
j
|θ)|≤γ,则
[0068]
|∫θ(p(θ|e)
‑
p
′
(θ|e))dθ|≤5π((1+γ)n
‑
1)。
[0069]
证明。根据三角不等式,得到
[0070]
|p(e)
‑
p
′
(e)|=|∫p(θ)(p(e|θ)
‑
p
′
(e|θ))dθ|≤δ
[0071]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0072]
因此,从假定p
′
(e)>2δ得出
[0073][0074]
因此,得到
[0075][0076]
现在,如果假定似然函数可以分解为n个实验,则可以得到
[0077][0078]
根据三角不等式
[0079][0080]
求解这个递推关系得到
[0081][0082]
因此,结果如下。
[0083]
v.使用随机哈密顿量的后验均值的变化
[0084]
在本节中,假定所有实验的联合似然发生随机变化δ(φ),分析估计相位的后验均值的变化,
[0085][0086]
这里,是在给定真实相位φ以及原始哈密顿量的实验参数和时的一系列n个结果的联合似然。是在每个实验中使用新的随机哈密顿量的联合似然。通过如等向量,重复是针对该系列中执行的每个实验;m
i
是第i实验中的重复次数。
[0087]
首先,可以从联合似然变化一定量δ(φ)的假定向后工作,以确定真实和随机哈密顿量之间的基态能量的可接受差异的上限。可以通过从所有实验的联合似然的变化,到个体实验的似然的变化,再到基态能量之间的对应可容忍差异进行向后工作来做到这一点。其次,可以使用这一结果来确定后验均值在能量差异方面的变化、以及它在随机生成的哈密顿量集合上的标准偏差。
[0088]
a.联合似然的变化
[0089]
每个实验的随机哈密顿量导致一系列结果的联合似然的随机变化
[0090][0091]
假定人们想确定这种变化似然下的后验均值的最大可能变化。可以在假定先验上的似然的均值变化至多为的情况中工作。后验是
[0092][0093]
可以通过首先根据个体实验的似然的变化来限制联合似然的变化,从而在限制后验的变化方面取得进展,如下所示。
[0094]
引理4.令p(o
j
|φ;m
j
,θ
j
)是哈密顿量h的第j实验的结果o
j
的似然,并且p
′
(o
j
|φ;m
j
,θ
j
)=p(o
j
|φ;m
j
,θ
j
)+∈
j
(φ)是随机生成的哈密顿量h
j
的似然。假定针对所有实验j,n max
j
(|∈
j
(φ)|/p(o
j
|φ,m
j
,θ
j
))<1并且|∈
j
(φ)|≤p(o
j
|φ,m
j
,θ
j
)/2。因此,所有n个实验中的联合似然的平均变化,
[0095][0096]
至多是
[0097]
证明。可以根据与序列中的n个实验中的每个的似然p
′
(o
j
|φ;m
j
,θ
j
)=p(o
j
|φ;m
j
,θ
j
)+∈
j
(φ)的变化∈
j
(φ)来写出联合似然。联合似然为所以
[0098][0099]
这给出了变化与未变化联合似然的比率,
[0100][0101]
例如,可以使用对数和指数的不等式来线性化和简化这一点。通过求解这两个函数的上限或下限的不等式,可以根据未变化似然和p(o
j
|φ;m
j
,θ
j
)、以及单实验似然的变化∈
j
(φ)来确定|δ(φ)|的上限。
[0102]
可以用来夹住比率的不等式是
[0103]
针对x≤0,1
‑
|x|≤exp(x)
[0104]
针对x<1,exp(x)≤1+2|x|
[0105]
针对|x|≤1/2,
‑
2|x|≤log(1+x)
[0106]
针对log(1+x)≤|x|
[0107]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(21)
[0108]
为了使所有四个不等式成立,必须有,n max
j
(|∈
j
(φ)|/p(o
j
|φ,m
j
,θ
j
))<1(针
对指数不等式),并且针对所有j(针对对数不等式),|∈
j
(φ)|≤p(o
j
|φ,m
j
,θ
j
)/2。使用它们来确定变化与未变化似然的比率的上限,
[0109][0110]
另一方面,使用它们来确定比率的下限,
[0111][0112]
上限和下限在符号之前是相同的。这允许人们直接将它们组合起来,得到
[0113][0114]
由此,通过三角不等式,可以找到后验上的均值变化的上限由此,通过三角不等式,可以找到后验上的均值变化的上限
[0115]
因此,根据个体实验的似然的变化,联合似然的变化是有界限的。这些结果允许根据个体实验的似然的变化∈
j
(φ)来界定后验均值的变化。
[0116]
b.后验均值的变化
[0117]
可以使用假定来界定后验均值的变化。
[0118]
引理5.假定除了引理4的假定之外,用理想似然函数看到的后验平均值与扰动似然函数之间的差异至多是
[0119][0120]
证明。可以通过使用原始哈密顿量对变化后验与后验之间的逐点差异确定边界来
解决后验均值之间的差异的边界问题,
[0121][0122]
作为第一步,可以对变化后验的分母设置上限:
[0123][0124]
其中在两个不等式中,使用假定使用这一点,再次使用后验点之间的逐点差异至多是
[0125][0126]
有了这个,可以界定后验均值的变化,
[0127][0128]
现在,引理4的界限允许根据个体实验的似然∈
j
(φ)的变化来界定后验均值的变化,
[0129][0130]
其中在最后一步中,可以乘以和除以这是
[0131][0132]
c.相位的可接受变化
[0133]
另一问题是后验均值的变化的界限在相位变化方面是什么。
[0134]
定理6.如果针对所有j和定理6.如果针对所有j和针对n个实验中的每个,假定引理5,在pe中使用的本征相{φ
′
j
:j=1,...n}和真正的哈密顿量的本征相φ服从|φ
‑
φ
′
j
|≤δφ和p(o
j
|φ,m
j
,θ
j
)∈θ(1),则由于介入哈密顿量的本征值不准确而引起的本征相的后验均值的变化服从
[0135]
[0136]
此外,如果针对所有j,∑
j
m
j
∈o(1/∈
φ
)并且p(o
j
|φ;m
j
,θ
j
)∈θ(1),则
[0137][0138]
证明。可以根据被应用于基态的相位的变化δφ通过根据它来界定∈
j
(φ)来表示后验均值的变化。回想一下,随机哈密顿量的似然为
[0139]
p
′
(o
j
|φ;m
j
,θ
j
)=p(o
j
|φ;m
j
,θ
j
)+∈
j
(φ),
ꢀꢀ
(32)
[0140]
其中第j实验的未变化似然为因此,使用导数sin(x)≤|x|的上限,
[0141][0142]
总之,后验均值的误差至多为
[0143][0144]
结果是,如果选择分支[
‑
π,π),则后验均值的绝对值至多为π。
[0145]
vi.在每次重复中使用新的随机哈密顿量的本征相的变化
[0146]
可以通过在每次重复中生成不同哈密顿量来减少所应用的相的方差。然而,这并非没有代价:它可以被视为导致演化中的失败概率或更一般地导致附加相移。
[0147]
这减少方差的原因在数学上形式化有些复杂,这在计算|δφ|的方差时会出现。不是只有单个哈密顿量的指数,方差是在m
j
个哈密顿量的指数上。因此,它只是扩展为而不是像通常那样扩展为(φ
est
存在潜在的方差)。代价是,通过以这种方式减少相位的方差,会导致相位的附加变化。如果不跨多个步骤这样做,则将一直与相同的误差哈密顿量绝热。相反,这表示,一个只是近似绝热,代价是方差降低一个因子m
j
。由于附加变化也是线性的,这可以带来改进。通常要求差距较小,并且要求λ
j
∝
||h
j
‑
h
j
‑1||较小。
[0148]
然后,标准偏差之间存在的竞争为或并且这个新变化在m
j
中是线性的。所以根据差距,可能很难得到一个严格的界限来证明这更好,而且不应当只坚持来自单个哈密顿量的更高方差。
[0149]
a.算法的失败概率
[0150]
针对相位估计,可以通过在每个实验的重复中随机化来减少相位估计的方差。针
对有m
j
次重复的第j实验(回想一下,m
j
不一定是整数),一个分为个重复。
[0151]
在每次重复中,可以随机生成新的哈密顿量h
k
。每个哈密顿量h
k
的基态和能量都与其他哈密顿量略有不同。
[0152]
减少估计相位方差的原因是,重复之间的相位不相关:而针对单哈密顿量情况,相位exp(
‑
imφ
est
)的方差为当在每次重复中模拟不同随机哈密顿量(并且估计相位的总和)时,方差为
[0153]
通过在每次重复中在哈密顿量的不同随机实例化下演化,相位的方差二次减少;唯一的代价是,该算法现在有一个失败概率(从重复到重复离开基态,例如在从h
k
‑1的基态到h
k
的基态的转变)或与基态能量的真实总和相比的附加相移。第一种情况更容易分析:如引理7所示,只要差距足够小,故障概率可以任意小。可以通过将算法的成功概率视为在整个个随机哈密顿量的序列中保持基态的概率来实现这一点。在第二种情况中,如果状态在演化过程中仅在很短的时间间隔内离开地面空间,则可以在引理8中证明特征值之间的差异的界限。
[0154]
引理7.考虑哈密顿量的序列,m>1。令γ为任何哈密顿量的地面能量与第一激发能量之间的最小差距,类似地,令λ=max
k
||h
k
‑
h
k
‑1||为序列中的任何两个哈密顿量之间的最大差异。当从h1到h2到h
m
依次转移时离开基态的概率至多为0<∈<1,条件为
[0155][0156]
证明。令是哈密顿量h
k
的第i本征态,令是对应能量。鉴于算法开始于的基态,在所有m个步骤中保持在基态的概率为
[0157][0158]
这是算法在每个段中保持基态的概率。可以通过为建立界限来简化这个表达式。令λ
k
v
k
=h
k
‑
h
k
‑1,其中可以选择λ
k
使得||v
k
||=1以简化证明。将λ
k
v
k
视为h
k
‑1上的扰动,h
k
‑1的基态的变化的组成部分由导数
[0159]
[0160]
乘以λ=max|λ
k
|界定,其中最大化在k以及给定k时的扰动上。使用这个,
[0161][0162]
这得到其中令其中可以再次选择κ
k
使得|φ
k
>被归一化,
[0163][0164]
可以根据求解因为由于针对x∈[0,1],所以
[0165][0166]
因为最后,回到因为κ
k
≤1(这是真的,因为||v
k
||=1),两个哈密顿量的基态之差至多为
[0167][0168]
这表示,任何两个相邻哈密顿量的基态之间的重叠概率为跨m个段(m
‑
1个转变),成功概率至少为如果希望失败概率最大固定为0<∈<1,则需要
[0169][0170]
如果只能准备原始哈密顿量的基态|ψ0>,则成功概率有一个附加因素在这种情况中,可以应用引理7,||h
‑
h1||被包括在λ的最大化中。此外,由于||被包括在λ的最大化中。此外,由于其中e1‑
e0是h的基态和第一激发态之间的差距,则需要
[0171][0172]
如果发生这种情况,则在整个模拟过程中,每个哈密顿量都以概率1
‑
∈保持在基态。在这种情况中,总累积相位为
[0173][0174]
其中
[0175]
b.由于哈密顿量误差引起的相移
[0176]
可以通过确定期望(绝热)酉与真实酉之间的差异来概括对相位差异的分析。在m个随机哈密顿量下依次演化,被应用于每个新哈密顿量h
k
的酉为
[0177][0178]
而理想情况中应用的绝热酉为
[0179][0180]
这两者的区别在于,h
k
下的真实时间演化u
k
对h
k
的本征态应用相位,而绝热酉u
k,ad
应用本征相,然后将h
k
的每个本征态映射到h
k+1
的对应本征态。这表示,如果系统从h1的基态开始,则序列将被应用于它的相位与该序列中的每个哈密顿量的基态能量的总和成比例。相比之下,将包括来自不同哈密顿量h
k
的很多不同本征态的贡献。
[0181]
可以将酉u
k
与u
k,ad
之间的差异限定如下。
[0182]
引理8.令为到h
k
的基态上的投影仪,并且令引理7的假定成立。和的特征值之间的差异(其中δt是模拟时间)至多为
[0183][0184]
证明。首先,可以使用身份的解析来扩展真正的酉,下一哈密顿量h
k+1
的本征态为
[0185][0186]
令(p≠l)和(当p=l时)。在某种意义上,将新的本征状态写为与状态的轻微变化,这就是选择的原因。使用这个定义,可以继续简化u
k
:
[0187][0188]
[0189]
现在可以很好地确定界限注意,u
k,ad
恰好等于u
k
中的第一总和中的1,
[0190][0191]
界定||u
k
‑
u
k,ad
||的最后一步是界定类似于如何界定δ
pl
。针对p≠l,δ
pl
由下式给出
[0192][0193]
所以,与引理7中的|δ0|2和∑
l
>0|δ
l
|2的界限一样,的上限由下式给出
[0194][0195]
这就完成了证明。
[0196]
定理9.考虑哈密顿量的序列,m>1。令γ为任何哈密顿量的地面能量与第一激发能量之间的最小差距,类似地,令λ=max
k
||h
k
‑
h
k
‑1||为序列中的任何两个哈密顿量之间的最大差异。由这m个哈密顿量的乘积求得的酉本征相的估计误差最大为
[0197][0198]
失败的概率至多为∈,条件是
[0199][0200]
证明。引理8给出和的特征值之间的差异。跨整个序列,有
[0201][0202]
这是理想序列和实际序列的累积相位之间的最大可能差异,假定系统一次针对至多一次重复离开基态。
[0203]
由哈密顿量的相邻值处的测量引起的作为朗道齐纳过程的一部分的离开基态的概率是在引理7的假定下,在每个投影处发生的失效概率∈,如果
[0204][0205]
因此,从这两个结果中可以轻松得出结果。
[0206]
vii.重要性采样
[0207]
抽取哈密顿量的示例方法背后的基本思想是重要性采样。这种方法已经在合并中得到了很大的使用,但在这里可以稍微不同地使用它。重要性采样背后的思想是通过重新加权总和来减少量的均值的方差。特别地,可以将n个数字f(j)的均值写为
[0208][0209]
其中f(j)是给定项的重要性。这表明,可以将初始未加权平均值视为重新加权量x
j
/(f(j)n)的平均值。虽然这样做对x
j
的均值没有影响,它可以显著降低均值的样本方差,因此被广泛用于统计中以提供更准确的均值估计。在这些情况中采用的最佳重要性函数是f(j)
∝
|x
j
|。在这种情况中,可以直接看出,如果x
j
的符号是常数,则结果分布的方差实际上为零。在这种情况中,直接向前计算表明,这个最佳方差是
[0210][0211]
如果数字的符号是常数,则(54)中的最佳方差实际上为零。虽然这看起来令人惊讶,但当注意到为了计算最佳重要性函数而需要要估计的整体均值时,这就变得不那么神秘了。在大多数情况中,这将违背重要性采样的目的。因此,如果想要从哈密顿模拟的重要性采样中获取优势,则重要的是要表明即使使用不精确的重要性函数也可以使用它,例如,该不精确的重要性函数可以使用经典计算机有效计算。
[0212]
现在将在下面示出这种稳健性是如何保持的。
[0213]
引理10.令是可以
从中采样的未知概率分布,并且令为已知函数,从而使得针对所有j,其中|δ
j
|≤|f(j)|/2。如果重要性采样与重要性函数一起使用,则方差服从
[0214]
证明。证明是三角不等式中的一个直接练习,一旦使用|δ
j
|≤|f(j)|/2以及针对所有x∈[
‑
1/2,1/2]的1/(1
‑
|x|)≤1+2|x|:
[0215][0216]
这个界限是紧的,因为作为max
k
|δ
k
|
→
0,方差的上限收敛到作为最佳可达到方差的
[0217]
在诸如量子化学模拟等应用中,人们想要做的是最小化引理2中的方差。这个最小方差可以通过选择f(j)
∝
|<ψ|h
j
|ψ>|来获取。然而,计算这样一个函数的任务至少和求解想要解决的特征值估计问题一样困难。要采取的自然方法是从引理10中汲取灵感,而不是采用其中是有效可计算ansatz状态,诸如cisd状态。然而,在实践中,给定项的重要性可能无法完全由ansatz预测来预测。在这种情况中,可以使用对冲策略,其中针对一些ρ∈[0,1],f(j)
∝
(1
‑
ρ)<h
j
>+ρ||h
j
||。该策略允许在由哈密顿项的大小表示的重要性以及基态的代理的期望值之间平滑地插值。
[0218]
viii.数值结果
[0219]
本公开已经表明,可以使用随机化哈密顿量来使用迭代相位估计。为了示出示例实施例的有效性,考虑双原子分子的两个示例:二锂和氯化氢。在这两种情况中,分子都是在最小的sto6g基础上制备的,并且使用cisd状态,cisd状态是通过在远离hartree fock状态的2个激发范围内在所有状态上变化地最小化基态能量而发现。然后可以随机采样哈密
顿项,然后检查几个感兴趣的量,包括平均基态能量、基态能量的方差和哈密顿量中的平均项数。有趣的是,还可以查看模型中存在的量子位数。这可能会有所不同,因为一些随机采样的哈密顿量实际上会选择哈密顿量中不与系统其余部分耦合的项。在这些情况中,表示状态所需要的量子位数实际上可能低于通常预期的总数。
[0220]
从图2至图5和图6至图9可以看出,基态能量的估计随着所使用的对冲程度而发生根本变化。发现,如果两种情况中ρ=1,则在所有情况中,基态能量的方差都非常大,正如预期的那样,因为重要性采样在这种情况中影响很小。相反,发现,当ρ=0时,可以最大限度地从cisd状态中优先考虑哈密顿项的重要性,这导致非常简洁的模型,但针对甚至107个随机选择的项(其中一些可能是重复的)基态能量的变化在1ha量级。如果改为使用适度对冲(p=2
×
10
‑5),则注意到,假定化学精度的10%或0.1mha的能量变化针对哈密顿量截断误差来说是可接受的,则基态能量的变化最小化。针对二锂,这表示哈密顿量的项数减少了30%;而针对hc1,这将哈密顿量中的项数减少了3倍。由于trotter
‑
suzuki化学模拟的成本与哈密顿量中的项数呈超线性比例,这构成了复杂性的显著降低。
[0221]
还可以注意到,针对二锂的情况,执行模拟所需要的量子位数目在不同的运行中有所不同。相比之下,氯没有表现出这种行为。这种差异源于二锂需要位于20个自旋轨道中的6个电子。氯化氢由18个电子组成,示例fock空间也由20个自旋轨道组成。因此,几乎每个自旋轨道都与这相关,这解释了为什么将二锂表达到一定精度所需要的自旋轨道数目会发生变化,而针对hc1则不会。这说明所公开的随机化过程的实施例可以用于帮助选择用于模拟的活动空间,因为哈密顿量所需要的精度在相位估计过程中增加。
[0222]
图2至图9包括图200、300、400、500、600、700、800和900,它们示出了平均基态能变化(与未采样哈密顿量相比)、采样的哈密顿量上的基态能方差、平均量子位要求、和li2的采样哈密顿量中的平均数项,作为用于生成哈密顿量的样本数目和参数ρ的值的函数。哈密顿量h
α
中的一项以概率p
α
∝
(1
‑
ρ)<h
α
>+ρ||h
α
||被采样,其中在cisd状态下取期望值。
[0223]
ix.示例实施例
[0224]
在本节中,公开了用于执行所公开的技术的示例方法。所描述的特定实施例不应当被解释为限制性的,因为所公开的方法动作可以单独地、以不同顺序或至少部分彼此同时地执行。此外,任何公开的方法或方法动作可以与本文中公开的任何其他方法或方法动作一起执行。
[0225]
图10是示出根据所公开的技术的实施例的用于实现重要性采样模拟方法的示例方法的流程图1000。
[0226]
图11是示出用于使用自适应哈密顿随机化执行量子模拟的示例方法的流程图1100。
[0227]
图16是示出用于使用自适应哈密顿随机化执行量子模拟的示例方法的流程图1600。
[0228]
在1610,输入要由量子计算机设备计算的哈密顿量。
[0229]
在1612,在相位估计算法内使用随机化来减少哈密顿量中的哈密顿项的数目。
[0230]
在1614,输出针对哈密顿项的数目减少的哈密顿量的量子电路描述。
[0231]
在某些实施例中,减少包括基于重要性函数来选择一个或多个随机哈密顿项;基于所选择的哈密顿随机项中的每个哈密顿随机项的重要性来重新加权所选择的随机哈密
顿项;并且使用重新加权的随机项生成量子电路描述。一些实施例还包括在量子计算设备中实现由量子电路描述所描述的量子电路;并且测量量子电路的量子态。另外的实施例包括基于来自测量的结果(例如,使用迭代过程)重新执行该方法。在一些实施例中,迭代过程包括计算针对哈密顿量的期望精度值;基于实现和测量的结果来计算针对哈密顿量的标准偏差;并且将期望精度值与标准偏差比较。一些实施例还包括基于减少来改变哈密顿项的阶数。某些实施例还包括将重要性函数应用于基态的哈密顿量的项;并且至少部分地基于重要性函数来选择一个或多个随机哈密顿项。一些实施例包括使用基于对基态的变分近似的重要性采样。某些实施例还包括给定特征值中的当前不确定性的估计,使用自适应贝叶斯方法量化针对哈密顿量所需要的精度。
[0232]
其他实施例包括一种或多种存储计算机可执行指令的计算机可读介质,该计算机可执行指令在由计算机执行时,使得计算机执行一种方法,该方法包括输入要由量子计算机设备计算的哈密顿量;在相位估计算法内使用随机化来减少哈密顿量中的哈密顿项的数目;并且输出针对哈密顿项的数目减少的哈密顿量的量子电路描述。
[0233]
该方法可以包括基于重要性函数来选择一个或多个随机哈密顿项;基于所选择的哈密顿随机项中的每个哈密顿随机项的重要性来重新加权所选择的随机哈密顿项;以及使用重新加权的随机项生成量子电路描述。该方法还可以包括在量子计算设备中实现由量子电路描述所描述的量子电路;以及测量量子电路的量子态。该方法还可以包括计算针对哈密顿量的期望精度值;基于实现和测量的结果来计算针对哈密顿量的标准偏差;将期望精度值与标准偏差比较;以及基于比较的结果来重新执行减少。
[0234]
另一实施例是一种系统,该系统包括量子计算系统;以及经典被配置为与量子计算系统通信和控制量子计算系统的计算系统。在这样的实施例中,经典计算系统还被配置为:输入要由量子计算机设备计算的哈密顿量;在迭代相位估计算法内使用随机化来减少哈密顿量中的哈密顿项的数目;并且输出针对哈密顿项的数目减少的哈密顿量的量子电路描述。经典计算系统还可以被配置为:基于重要性函数来选择一个或多个随机哈密顿项;基于所选择的哈密顿随机项中的每个哈密顿随机项的重要性来重新加权所选择的随机哈密顿项;并且使用重新加权的随机项生成量子电路描述。经典计算系统还可以被配置为引起由量子电路描述所描述的量子电路由量子计算设备实现;并且测量量子电路的量子态。更进一步,经典计算系统还可以被配置为计算针对哈密顿量的期望精度值;基于实现和测量的结果来计算针对哈密顿量的标准偏差;将期望精度值与标准偏差比较;并且基于比较的结果来重新执行减少。在另外的实施例中,配置经典计算系统还可以被配置为使得作为随机化的一部分,一个或多个不必要的量子位被省略。
[0235]
x.示例计算环境
[0236]
图12示出了可以在其中实现所描述的实施例的各方面的合适的经典计算环境1200的一般化示例。计算环境1200不打算对所公开的技术的使用范围或功能提出任何限制,因为本文中描述的技术和工具可以在具有计算硬件的各种通用或专用环境中实现。
[0237]
参考图12,计算环境1200包括至少一个处理设备1210和存储器1220。在图12中,这个最基本的配置1230被包括在虚线内。处理设备1210(例如,cpu或微处理器)执行计算机可执行指令。在多处理系统中,多个处理设备执行计算机可执行指令以增加处理能力。存储器1220可以是易失性存储器(例如,寄存器、高速缓存、ram、dram、sram)、非易失性存储器(例
如,rom、eeprom、闪存)、或这两者的某种组合。存储器1220存储实现工具的软件1280,该工具用于执行用于操作量子计算机以执行如本文所述的哈密顿随机化的任何公开技术。
[0238]
存储器1220还可以存储用于合成、生成或编译用于执行任何公开技术的量子电路的软件1280。
[0239]
计算环境可以具有附加特征。例如,计算环境1200包括存储装置1240、一个或多个输入设备1250、一个或多个输出设备1260和一个或多个通信连接1270。互连机制(未示出)(诸如总线、控制器、或网络)互连计算环境1200的组件。通常,操作系统软件(未示出)为在计算环境1200中执行的其他软件提供操作环境,并且协调计算环境1200的组件的活动。
[0240]
存储装置1240可以是可移除的或不可移除的,并且包括一个或多个磁盘(例如,硬盘驱动器)、固态驱动器(例如,闪存驱动器)、磁带或盒式磁带、cd
‑
rom、dvd、或者可以用于存储信息并且可以在计算环境1200内访问的任何其他有形的非易失性存储介质。存储装置1240还可以存储用于实现任何公开技术的软件1280的指令。存储装置1240还可以存储用于生成和/或合成任何所描述的技术、系统或量子电路的软件1280的指令。
[0241]
(多个)输入设备1250可以是触摸输入设备,诸如键盘、触摸屏、鼠标、笔、轨迹球、语音输入设备、扫描设备、或向计算环境1200提供输入的另一设备。(多个)输出设备1260可以是显示设备(例如,计算机显示器、膝上型显示器、智能手机显示器、平板显示器、上网本显示器或触摸屏)、打印机、扬声器、或提供来自计算环境1200的输出的另一设备。
[0242]
(多个)通信连接1270能够通过通信介质与另一计算实体通信。通信介质在调制数据信号中传送诸如计算机可执行指令或其他数据等信息。调制数据信号是这样一种信号,它的一个或多个特性被设置或改变,以便对信号中的信息进行编码。作为示例而非限制,通信介质包括利用电、光、rf、红外线、声学或其他载体实现的有线或无线技术。
[0243]
如上所述,用于执行哈密顿随机化、用于控制量子计算设备以执行如本文中公开的电路设计或编译/合成的各种方法和技术可以在被存储在一个或多个计算机可读介质上的计算机可读指令的一般上下文中描述。计算机可读介质是可以在计算环境内或由计算环境访问的任何可用介质(例如,存储器或存储设备)。计算机可读介质包括有形计算机可读存储器或存储设备,诸如存储器1220和/或存储装置1240,并且不包括传播载波或信号本身(有形计算机可读存储器或存储设备不包括传播载波或信号本身)。
[0244]
本文中公开的方法的各种实施例也可以在由处理器在计算环境中执行的计算机可执行指令(例如,包括在程序模块中的那些)的一般上下文中描述。通常,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、库、对象、类、组件、数据结构等。在各种实施例中,程序模块的功能可以根据需要在程序模块之间组合或拆分。程序模块的计算机可执行指令可以在本地或分布式计算环境中执行。
[0245]
图13中描绘了用于实现根据所公开的技术的系统的可能的网络拓扑1300(例如,客户端服务器网络)的示例。联网计算设备1320可以是例如运行浏览器或被连接到网络1312的其他软件的计算机。计算设备1320可以具有如图12所示和上面讨论的计算机架构。计算设备1320不限于传统的个人计算机,而是可以包括被配置为被连接到网络1312并且与之通信的其他计算硬件(例如,智能手机、膝上型计算机、平板计算机、或者其他移动计算设备、服务器、网络设备、专用设备等)。此外,计算设备1320可以包括fpga或其他可编程逻辑设备。在图示的实施例中,计算设备1320被配置为经由网络1312与计算设备1330(例如,远
程服务器,诸如云计算环境中的服务器)通信。在图示的实施例中,计算设备1320被配置为将输入数据传输到计算设备1330,并且计算设备1330被配置为实现用于控制量子计算设备执行任何公开实施例的技术和/或用于生成用于执行本文中公开的任何技术的量子电路的电路生成/编译/合成技术。计算设备1330可以向计算设备1320输出结果。从计算设备1330接收的任何数据都可以存储或显示在计算设备1320上(例如,显示为计算设备1320处的图形用户界面或网页上的数据)。在图示的实施例中,图示的网络1312可以被实现为使用有线联网(例如,以太网ieee标准802.3或其他适当标准)或无线联网(例如,ieee标准802.11a、802.11b、802.llg或802.11h或其他适当标准之一)的局域网(lan)。备选地,网络1312的至少一部分可以是互联网或类似的公共网络并且使用适当协议(例如,http协议)进行操作。
[0246]
图14中描绘了用于实现根据所公开的技术的系统的可能的网络拓扑1400(例如,分布式计算环境)的另一示例。联网计算设备1420可以是例如运行浏览器或被连接到网络1112的其他软件的计算机。计算设备1420可以具有如图12所示和上面讨论的计算机架构。在所示实施例中,计算设备1420被配置为经由网络1412与多个计算设备1430、1431、1432(例如,远程服务器或其他分布式计算设备,诸如云计算环境中的一个或多个服务器)通信。在所示实施例中,计算环境1400中的计算设备1430、1431、1432中的每个用于执行哈密顿随机化技术的至少一部分和/或用于控制量子计算设备执行任何公开的实施例的技术的至少一部分和/或用于生成用于执行本文中公开的任何技术的量子电路的电路产生/编译/合成技术。换言之,计算设备1430、1431、1432形成分布式计算环境,其中用于执行本文中公开的任何技术和/或量子电路生成/编译/合成过程的技术的各方面跨多个计算设备被共享。计算设备1420被配置为将输入数据传输到计算设备1430、1431、1432,计算设备1430、1431、1432被配置为分布式地实现诸如过程,包括任何公开方法的执行或任何公开电路的创建,并且向计算设备1420提供结果。从计算设备1430、1431、1432接收的任何数据可以存储或显示在计算设备1420上(例如,显示为计算设备1420处的图形用户界面或网页上的数据)。图示的网络1412可以是上面关于图13讨论的任何网络。
[0247]
参考图15,用于实现所公开的技术的示例性系统包括计算环境1500。在计算环境1500中,编译的量子计算机电路描述(包括用于执行如本文中公开的任何公开技术的量子电路)可以用于编程(或配置)一个或多个量子处理单元,从而使得量子处理单元实现由量子计算机电路描述所描述的电路。
[0248]
环境1500包括一个或多个量子处理单元1502和一个或多个读出设备1508。量子处理单元执行由量子计算机电路描述预编译和描述的量子电路。量子处理单元可以是以下中的一个或多个,但不限于:(a)超导量子计算机;(b)离子阱量子计算机;(c)用于量子计算的容错架构;和/或(d)拓扑量子架构(例如,使用majorana零模式的拓扑量子计算设备)。预编译的量子电路(包括任何公开的电路)可以在量子处理器控制器1520的控制下经由控制线1506发送到(或以其他方式应用于)(多个)量子处理单元。量子处理器控制器(qp控制器)1520可以与经典处理器1510(例如,具有如上文关于图12所述的架构)一起操作以实现期望的量子计算过程。在所示示例中,qp控制器1520还经由一个或多个qp子控制器1504来实现期望的量子计算过程,该子控制器1504特别适用于控制(多个)量子处理器1502中的对应的一个。例如,在一个示例中,量子控制器1520通过以下方式促进编译的量子电路的实现:向一个或多个存储器(例如,低温存储器)发送指令,然后将指令传递到(多个)低温控制单元
(例如,(多个)qp子控制器1504),例如,低温控制单元将代表门的脉冲序列传输到(多个)量子处理单元1502以用于实现。在其他示例中,qp控制器1520和qp子控制器1504操作以向(多个)量子处理器提供适当的磁保持、编码操作或其他这样的控制信号,以实现编译的量子计算机电路描述的操作。(多个)量子控制器还可以与读出设备1508交互以帮助控制和实现期望的量子计算过程(例如,一旦可用,则通过从量子处理单元读取或测量出数据结果等)
[0249]
参考图15,编译是将量子算法的高级描述转换成量子计算机电路描述的过程,该电路描述包括一系列量子操作或门,其中可以包括本文中公开的电路(例如,电路被配置为执行如本文所公开的一种或多种过程)。编译可以由编译器1522使用环境1500的经典处理器1510(例如,如图12所示)来执行,该处理器1510从存储器或存储设备1512加载高级描述并且将所产生的量子计算机电路描述存储在存储器或存储设备1512中。
[0250]
在其他实施例中,编译和/或验证可以由远程计算机1560(例如,具有如上文关于图12所述的计算环境的计算机)远程执行,远程计算机1560将所得到的量子计算机电路描述存储在一个或多个存储器或存储设备1562中并且将量子计算机电路描述传输到计算环境1500以在(多个)量子处理单元1502中实现。此外,远程计算机1500可以将高级描述存储在存储器或存储设备中1562并且将高级描述传输到计算环境1500以用于(多个)量子处理器编译和与其一起使用。在这些场景中的任何一个中,由(多个)量子处理器执行的计算的结果可以在计算过程之后和/或过程中传送到远程计算机。更进一步,远程计算机可以与(多个)qp控制器1520通信,从而使得量子计算过程(包括任何编译、验证和qp控制过程)可以由远程计算机1560远程控制。一般而言,远程计算机1560经由通信连接1550与(多个)qp控制器1520、编译器/合成器1522和/或验证工具1523通信。
[0251]
在特定实施例中,环境1500可以是云计算环境,其通过合适的网络(可以包括互联网)向一个或多个远程计算机(诸如远程计算机1560)提供环境1500的量子处理资源。
[0252]
xi.结束语
[0253]
该应用表明,迭代相位估计比以前可能认为的更灵活,并且哈密顿量中的项数在迭代相位估计的每个步骤中都是随机的,而不会对本征相的无偏估计量的潜在方差产生实质性的影响。在数值上进一步表明,通过使用这种对哈密顿项进行二次采样的策略,可以使用比传统方法所需要的更少的哈密顿项来执行模拟。这些项数的减少直接影响基于trotter
‑
suzuki的模拟的复杂性,并且间接影响量子化和截断泰勒级数模拟方法,因为它们还减少了哈密顿项向量的1范数。
[0254]
已经参考图示的实施例描述和示出了所公开的技术的原理,应当认识到,图示的实施例可以在不脱离这些原理的情况中在布置和细节上进行修改。例如,在软件中示出的所示实施例的元素可以在硬件中实现,反之亦然。此外,来自任何示例的技术可以与在任何一个或多个其他示例中描述的技术组合。应当理解,诸如参考所示示例描述的那些过程和功能可以在单个硬件或软件模块中实现,或者可以提供单独的模块。提供上述特定布置是为了方便说明,也可以使用其他布置。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1