推论装置、推论方法及推论程序与流程
1.本发明涉及推论装置、推论方法及推论程序。
背景技术:
2.近年来,为了观测某些对象,照相机(拍摄装置)、麦克风、温度传感器、照度传感器等传感器被用于各种场景。例如,在制造生产线等的产品的场景中,利用了通过拍摄装置对制造的产品进行拍摄,并基于得到的图像数据来检查产品的好坏的技术。
3.如果观测对象的场所不同,则传感器的最佳观测方法可能不同。例如,在明亮的场所检查产品的状态的情况下,拍摄装置的快门速度越快越好,在黑暗的场所检查产品的状态的情况下,拍摄装置的快门速度越慢越好。另外,即使是同一场所,根据时间段,传感器的最佳观测方法也可能不同。例如,根据时间段,对象场所的明亮度可能不同。另外,例如,在不同的季节,即使在同一时间段,对象场所的明亮度也可能不同。即,如果观测的环境不同,则传感器的最佳观测方法可能不同。
4.为了适当地观察对象,即使在不同的环境下,也希望系统地实施传感器的观测。作为系统地实施传感器的观测的方法的一例,考虑通过人工将传感器的观测方法标准化。但是,在观测的环境多样的情况下,难以将观测方法千篇一律地标准化。另外,在安装传感器时,介入了人的主观,有可能无法实现标准化的观测方法。也就是说,有可能由于人为的因素而无法在各环境中实现标准化的观测方法。
5.因此,希望不依赖于人工标准化地在各环境中系统地使传感器的观测方法优化。例如,在专利文献1中,提出了一种使形成在基板上的对位用的标记的检测条件优化的方法。具体而言,在多个照明条件及成像条件下使用标记检测系统检测形成在基板上的多个标记。接着,通过规定的信号处理算法分析来自标记检测系统的检测信号,并计算与检测信号的波形形状相关的判定量。然后,基于所得到的判定量评价多个标记的检测结果的再现性,并基于评价结果使多个照明条件及成像条件优化。根据专利文献1的方法,在各环境中,能够使照明条件及成像条件优化,以适合于利用规定的信号处理算法进行的标记的检测。
6.另外,近年来也提出了一种使用机器学习来使传感器的观测方法优化的方法。例如,在专利文献2中,提出了一种边重复物体的观测行动的同时边基于通过观测行动得到的观测数据将物体分类为类的分类系统,该分类系统基于根据由对象物体的分类概率导出的熵的减少量设定的报酬来执行观测行动的强化学习。根据专利文献2的方法,分类系统能够在各环境中通过强化学习掌握适合于物体的类识别的观测行动。另外,例如,在非专利文献1中,提出了一种使用强化学习使超声波阵列传感器的指向性优化的方法。
7.在先技术文献
8.专利文献
9.专利文献1:日本特开2012-038794号公报
10.专利文献2:日本特开2012-216158号公报
11.专利文献3:日本特开2011-059924号公报
12.专利文献4:日本特开2017-173874号公报
13.专利文献5:日本特开2018-051664号公报
14.专利文献6:日本特开2019-067238号公报
15.专利文献7:日本特开2019-087096号公报
16.非专利文献
17.非专利文献1:小谷直树,谷口研二,“使用强化学习的超声波阵列传感器的指向性的最佳设计方法”,系统控制信息学会期刊,2010年,23卷,12号,p.291-293
技术实现要素:
18.发明要解决的技术问题
19.本技术的发明人们发现,在上述那样的现有的优化方法中,存在如下问题。
20.即,在现有的方法中,在各个环境中使传感器的观测方法优化。特别是在通过有监督学习、无监督学习及强化学习等机器学习使传感器的观测方法优化的情况下,在各环境中收集学习数据,通过利用所收集的学习数据的机器学习来构建学习完毕的机器学习模型。学习完毕的机器学习模型在与收集到学习数据的环境相同的环境中运用的情况下,能够适当地执行规定的推论(在这种情况下,推断传感器的最佳观测方法)。
21.但是,在与收集到学习数据的环境不同的环境中运用的情况下,学习完毕的机器学习模型不一定能够适当地执行该规定的推论。因此,基本上,在新的环境中使传感器的观测方法优化的情况下,在对象的新的环境中收集学习数据,利用所收集的学习数据,实施用于构建新的学习完毕的机器学习模型的机器学习。因此,在现有的方法中,存在在新的环境中使传感器的观测方法优化花费成本的问题。
22.需要说明的是,该问题不是使传感器的观测方法优化的场景所特有的。在通过学习完毕的机器学习模型执行规定的推论的所有场景中都会产生同样的问题。通过学习完毕的机器学习模型执行规定的推论的场景除了上述推断传感器的最佳观测方法的场景之外,例如是指预测移动体的移动路径的场景、推断适合于用户的会话策略的场景、推断适合于任务的机器人装置的动作指令的场景等。
23.作为具体例,在引用文献3中,提出了使隐马尔可夫模型掌握预测用户的移动路径的能力。在引用文献4中,提出了通过深度强化学习使学习器掌握确定使后续的发言接近会议目的的答复的能力。在引用文献5中,提出了通过强化学习使学习模型掌握确定作为机器人装置的具备机械手的工业用机器人的与物品的位置姿势、循环时间、转矩及振动相关的运转条件的能力。在引用文献6中,提出了通过强化学习使学习模型掌握确定作为机器人装置的控制对象设备的控制内容的能力。在引用文献7中,提出了通过强化学习使学习模型掌握确定作为机器人装置的自动驾驶车辆的行动的能力。
24.在这些场景中,在与收集到学习数据的环境不同的环境中运用的情况下,学习完毕的机器学习模型也不一定能够适当地执行规定的推论。因此,可能产生构建在新的环境中能够适当地执行规定的推论的学习完毕的机器学习模型花费成本的问题。
25.进而,上述问题并不是通过机器学习构建学习完毕的机器学习模型的场景所特有的。例如,在通过基于人工的规则化等机器学习以外的方法从学习数据导出构成为执行规定的推论的推论模型的所有场景中都可能产生。例如,设想通过基于人工的规则化来生成
推论模型的场景。即使在这种场景中,在与收集到学习数据的环境不同的环境中运用推论模型的情况下,也有可能提供在生成时没有考虑到的输入,推论模型不一定能够适当地执行规定的推论。因此,可能产生构建在新的环境中能够适当地执行规定的推论的推论模型花费成本的问题。
26.本发明的一方面鉴于这样的实际情况而提出,其目的在于提供用于降低构建在新的环境中能够适当地执行规定的推论的推论模型所花费的成本的技术。
27.用于解决技术问题的技术方案
28.本发明为了解决上述技术问题,采用以下构成。
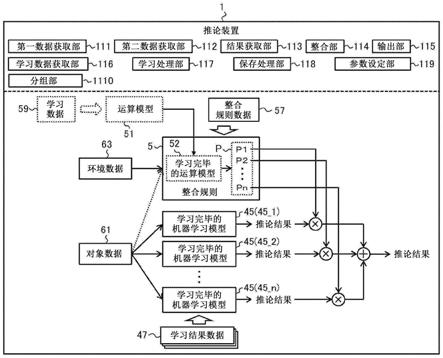
29.即,本发明的一方面所涉及的推论装置,具备:第一数据获取部,获取成为规定的推论的对象的规定的对象数据;第二数据获取部,获取与执行所述规定的推论的对象环境相关的环境数据;结果获取部,通过对根据在不同的环境下得到的局部学习数据而被导出以执行所述规定的推论的多个推论模型分别提供所述对象数据,并使该各推论模型对所述对象数据执行所述规定的推论,来获取该各推论模型对所获取的所述对象数据的推论结果;整合部,通过按照整合规则整合所述各推论模型的推论结果,来生成在所述对象环境下对所述对象数据的推论结果,所述整合规则由在所述对象环境下分别规定重视所述各推论模型的推论结果的程度的多个整合参数构成,按照所述整合规则整合所述各推论模型的推论结果具备:根据所获取的所述环境数据确定所述各整合参数的值、使用所确定的所述各整合参数的值对所述各推论模型的所述推论结果进行加权、以及整合所述各推论模型的加权后的所述推论结果;以及输出部,输出与所生成的所述推论结果相关的信息。
30.该构成所涉及的推论装置利用根据在不同的环境下得到的局部学习数据导出的多个推论模型,在对象环境下执行规定的推论。具体而言,该构成所涉及的推论装置通过将成为规定的推论的对象的对象数据提供给各推论模型,使各推论模型执行对对象数据的规定的推论,从而获取各推论模型对对象数据的推论结果。然后,该构成所涉及的推论装置通过按照整合规则整合各推论模型的推论结果,来生成在对象环境下对对象数据的推论结果。如此,该构成所涉及的推论装置为了在对象环境下执行规定的推论,不是构建新的推论模型,而是灵活应用已经构建的多个推论模型。
31.整合规则由在对象环境下分别规定重视各推论模型的推论结果的程度的多个整合参数构成。一般而言,设想越是根据在类似于对象环境的学习环境中得到的局部学习数据导出的推论模型,对在对象环境下得到的对象数据的推论精度越高。另一方面,设想越是根据在不类似于对象环境的学习环境中得到的局部学习数据导出的推论模型,对在对象环境下得到的对象数据的推论精度越低。另外,在多个推论模型中有时会包括推荐在对象环境下优先利用的推论模型。
32.因此,该构成所涉及的推论装置根据与执行规定的推论的对象环境相关的环境数据,来确定整合规则的各整合参数的值。例如,可以确定各整合参数的值,以重视类似于对象环境的学习环境的推论模型及优先级高的推论模型中的至少任一者的推论结果。然后,该构成所涉及的推论装置使用所确定的各整合参数的值,对各推论模型的推论结果进行加权,并整合加权后的各推论模型的推论结果。在该构成中,通过像这样地根据对象环境调整重视各推论模型的推论的程度,能够将在各种环境中得到的见解(推论模型)定制为适合于新的环境。其结果,能够在对象环境下适当地执行规定的推论。
33.因此,根据该构成,利用根据在不同的环境下得到的局部学习数据导出的多个推论模型,能够在对象环境下适当地执行规定的推论。即,通过灵活应用已经构建的多个推论模型,能够构建在对象环境下能够适当地执行规定的推论的推论模型。因此,能够省略在对象环境下收集新的学习数据并根据所收集的新的学习数据导出新的推论模型的作业的麻烦。因此,根据该构成,能够降低构建在新的环境中能够适当地执行规定的推论的推论模型所花费的成本。
34.需要说明的是,执行“规定的推论”是指,基于未知的对象数据执行某推断处理。推论的内容也可以不特别限定,可以根据实施方式适当确定。推论也可以是回归或识别。规定的推论例如可以是推断传感器的最佳观测方法、预测移动体的移动路径、推断适合于用户的会话策略、推断适合于任务的机器人装置的动作指令、等等。推论结果的表现可以根据推论的内容适当确定。推论结果例如可以通过基于回归的连续值、属于类的概率等来表现。另外,推论结果例如也可以通过一个以上的数值或一个以上的类来表现。
[0035]“对象数据”只要是在规定的推论时使用的数据即可,其种类也可以不特别限定,可以根据推论的内容适当选择。对象数据例如可以是图像数据、声音数据、数值数据、文本数据、其他由传感器得到的观测数据等。对象数据也可以改称为“输入数据”。
[0036]“环境数据”只要是与执行规定的推论的对象的环境相关的数据即可,其种类也可以不特别限定,可以根据实施方式适当选择。执行规定的推论的环境例如是得到对象数据的环境。与得到对象数据的环境相关的属性可以包括与规定的推论直接或间接地关联的对象物或用户的属性等可能与推论关联的所有现象。环境数据与对象数据同样地,例如可以是图像数据、声音数据、数值数据、文本数据、其他由传感器得到的观测数据等。
[0037]
获取对象数据及环境数据各自的方法也可以不特别限定,可以根据实施方式适当选择。在对象数据及环境数据来源于由传感器得到的观测数据的情况下,对象数据及环境数据可以来源于由同一传感器得到的同一观测数据,也可以来源于由不同的传感器得到的不同的观测数据。对象数据及环境数据也可以包括至少部分地共同的数据。
[0038]
各推论模型只要能够执行规定的推论即可,其构成也可以不特别限定,可以根据实施方式适当确定。各推论模型例如可以由数据表、函数式、规则等构成。推论中利用的各推论模型的输出(推论结果)的形式及内容未必完全一致。各推论模型的输出的形式及内容中的至少一方在能够整合各推论模型的推论结果的范围内也可以不同。例如,推断关节数量不同的机器人装置的动作指令的多个推论模型可以用于推断对象环境下的机器人装置的动作指令。整合各推论模型的推论结果的方法也可以不特别限定,可以根据实施方式适当确定。例如,整合各推论模型的推论结果可以通过平均化或多数表决构成。
[0039]
得到局部学习数据的环境不同是指,例如时间、场所、对象物、用户等可能对规定的推论产生影响的现象至少部分地不同。作为一例,在不同的场所获取到的局部学习数据可以作为在不同的环境下得到的局部学习数据来对待。另外,作为其他例,在同一场所不同的时刻获取到的局部学习数据可以作为在不同的环境下得到的局部学习数据来对待。在各推论模型的导出中利用的局部学习数据中,也可以包括至少部分地相同的数据。
[0040]
导出各推论模型的方法也可以不特别限定,可以根据实施方式适当选择。各推论模型的导出可以由人工进行,或者也可以通过机器学习进行。机器学习的方法例如可以使用有监督学习、无监督学习、强化学习等。局部学习数据的形式及种类也可以不特别限定,
例如可以根据导出各推论模型的方法、规定的推论的内容等适当确定。
[0041]
在上述一方面所涉及的推论装置中,所述各推论模型可以由通过利用所述局部学习数据的机器学习而获得了执行所述规定的推论的能力的学习完毕的机器学习模型构成。根据该构成,能够降低构建在新的环境中能够适当地执行规定的推论的学习完毕的机器学习模型所花费的成本。
[0042]
上述一方面所涉及的推论装置也可以还具备学习处理部,所述学习处理部执行用于根据所述环境数据计算所述各整合参数的值的运算模型的机器学习,所述机器学习通过训练所述运算模型以使计算出的所述各整合参数的值适合于所述对象环境下的所述规定的推论而构成。与此相应地,所述整合规则可以还具备通过所述机器学习而构建的学习完毕的运算模型。另外,所述根据所述环境数据确定所述各整合参数的值可以通过对所述学习完毕的运算模型提供所述环境数据并执行所述学习完毕的运算模型的运算处理来获取作为所述学习完毕的运算模型的输出的所述各整合参数的值而构成。根据该构成,通过包括通过机器学习而构建的学习完毕的运算模型的整合规则,能够在对象环境中更适当地执行规定的推论。
[0043]
推论模型的参数数量依赖于对象数据的维数及推论结果的表现形式。与此相对,运算模型的参数数量依赖于环境数据的维数及在对象环境下的规定的推论中利用的推论模型的数量。因此,对象数据及推论内容中的至少一方越复杂,推论模型的参数数量越增加,与此相对,能够抑制运算模型的参数数量的增加。
[0044]
例如,设想考虑明亮度作为对象环境,根据由该照相机得到的图像数据对照相机的最佳观测方法进行推断的场景。在这种情况下,推论模型的参数数量依赖于图像数据的像素数量及照相机可采取的状态数量,可能是过千的量级。另一方面,运算模型的参数数量依赖于明亮度的维数及推论模型的数量,但即使最佳观测方法的推断中利用几十个推论模型,也最多是几十~几百程度的量级。
[0045]
因此,一般而言,运算模型的参数数量比推论模型的参数数量少就可以了。由于机器学习的成本依赖于参数数量,因此通过机器学习构建学习完毕的运算模型的成本能够抑制得比构建学习完毕的机器学习模型作为新的推论模型的成本低。因此,在该构成中,也能够降低构建在新的环境中能够适当地执行规定的推论的学习完毕的机器学习模型所花费的成本。
[0046]
需要说明的是,运算模型的机器学习可以由推论装置以外的信息处理装置(计算机)执行。运算模型包括用于计算各整合参数的值的多个运算参数。运算模型的机器学习可以是调整运算参数的值以得到适合于对象环境的希望的输出。即,训练运算模型以使计算出的各整合参数的值适合于对象环境下的规定的推论可以是,调整运算模型的运算参数的值,以使根据环境数据计算出使得使用计算出的各整合参数的值整合各推论模型的推论结果的结果适合作为对象环境下的推论结果那样的各整合参数的值。
[0047]
在上述一方面所涉及的推论装置中,所述运算模型的所述机器学习可以通过根据通过所述整合生成的推论结果的适当度而设定有报酬的强化学习所构成,训练所述运算模型可以包括:反复进行构成所述运算模型的运算参数的值的修正以得到越多的所述报酬。运算参数的值的修正可以反复进行,例如直到满足修正运算参数的值的量为阈值以下等规定的条件为止。根据该构成,通过包括通过强化学习而构建的学习完毕的运算模型的整合
规则,能够在对象环境中更适当地执行规定的推论。
[0048]
需要说明的是,适当度表示通过整合生成的推论结果适当的程度。例如,在推断传感器的最佳观测方法的场景中,按照通过整合得到的观测方法变更传感器的观测状态,结果越能够由传感器获取适合于规定的条件的观测数据(例如,适合于产品的外观检查的图像数据),该观测方法的推断结果可以评价为越适当。另外,例如在预测移动体的移动路径的场景中,通过整合得到的预测路径越准确,该路径的预测结果可以评价为越适当。另外,例如在推断适合于用户的会话策略的场景中,通过整合得到的会话策略越适合于用户,该会话策略的推断结果可以评价为越适当。另外,例如在推断适合于任务的机器人装置的动作指令的场景中,通过整合得到的动作指令越适合于任务,该动作指令的推断结果可以评价为越适当。适当度可以基于规定的指标由计算机自动计算,或者也可以通过操作者的输入指定。即,适当度的评价可以由计算机进行,或者也可以由操作者进行。
[0049]
在上述一方面所涉及的推论装置中,根据所述环境数据确定所述各整合参数的值可以通过获取与得到所述各推论模型的导出中利用的所述局部学习数据的环境相关的学习环境数据、计算所获取的学习环境数据和所述环境数据的适合度、以及根据计算出的适合度确定针对所述各推论模型的所述各整合参数的值而构成。根据该构成,能够基于环境数据和学习环境数据的比较结果(即适合度)来确定各整合参数的值,使得学习环境越类似于对象环境,越重视该推论模型的推论结果。因此,根据该构成,能够通过简单的方法,降低构建在新的环境中能够适当地执行规定的推论的推论模型所花费的成本。
[0050]
上述一方面所涉及的推论装置也可以还具备参数设定部,所述参数设定部接收所述多个整合参数中的至少一个整合参数的值的指定、且将所述至少一个整合参数的值设定为指定的值。与此相应地,对所述各推论模型的所述推论结果进行加权也可以包括使用所设定的所述值对与所述至少一个整合参数对应的推论模型的推论结果进行加权。根据该构成,能够通过操作者的指定来确定应用于各推论模型的推论结果的各整合参数的值中的至少一部分。由此,能够在对象环境下的规定的推论中反映操作者的意图(例如,重视特定的推论模型的推论结果)。
[0051]
上述各方面所涉及的推论装置可以应用于通过推论模型执行某推论的所有场景。执行某推论的场景例如是指,推断传感器的最佳观测方法的场景、预测移动体的移动路径的场景、推断适合于用户的会话策略的场景、推断适合于任务的机器人装置的动作指令的场景等。或者,执行某推论的场景例如也可以是推断由照相机得到的图像数据中拍摄的被拍摄物的属性的场景等推断由传感器得到的观测数据中表现出的特征的场景。或者,执行某推论的场景也可以是根据由传感器得到的观测数据推断与传感器的观测条件相关的特征的场景。与观测条件相关的特征可以包括可能与观测条件关联的所有现象,例如可以包括传感器与观测对象之间的距离、观测对象周围的明亮度等。
[0052]
例如,在上述一方面所涉及的推论装置中,所述规定的推论可以是根据该观测数据推断由传感器得到的观测数据中表现出的特征。所述对象数据可以是由所述传感器得到的观测数据。所述环境数据可以是与获取所述观测数据的环境相关的数据。推断由传感器得到的观测数据中表现出的特征可以是推断由照相机得到的图像数据中拍摄的被拍摄物的属性。根据该构成,在推断由传感器得到的观测数据中表现出的特征的场景中,能够降低构建在新的环境中能够适当地执行规定的推论的推论模型所花费的成本。推论装置例如可
以适当改称为检查装置、预测装置、会话装置、控制装置等,以适合于推论内容。
[0053]
例如,在上述一方面所涉及的推论装置中,所述规定的推论可以是推断从由传感器观测对象物的属性的当前的观测状态变更为用于由传感器得到适合于规定条件的观测数据的适当的观测状态的变更方法。所述对象数据可以是与对象传感器的当前的观测状态相关的数据。所述环境数据可以是与所述对象传感器观测所述对象物的属性的对象观测环境相关的数据。根据该构成,在由传感器观测对象物的属性的场景中,能够降低构建在新的环境中能够适当地推断传感器的最佳观测方法的推论模型所花费的成本。
[0054]
需要说明的是,得到适合于规定条件的观测数据对应于传感器的观测状态适当。“规定条件”可以根据传感器的观测目的适当规定。例如,在为了产品的缺陷检测而得到观测数据的情况下,规定条件可以根据基于由传感器得到的观测数据能否进行缺陷检测、缺陷检测的精度是否满足基准等对于由传感器得到的观测数据的其他推论的性能来规定。产品的缺陷检测可以替换为被拍摄物的品质评价(例如,农作物的生长状态的评价)。推断“变更为适当的观测状态的变更方法”可以包括直接推断该变更方法、以及通过推断适当的观测状态并计算所推断的适当的观测状态与当前的观测状态的差分来间接地推断用于引导至适当的观测状态的变更方法。
[0055]
在上述一方面所涉及的推论装置中,所述环境数据可以由与所述对象传感器不同的观测所述对象观测环境的其他传感器得到。根据该构成,由于能够简单地获取环境数据,因此能够实现整合各推论模型的推论结果的一系列处理的简化。另外,根据该构成,由于能够适当地获取观测数据,因此能够实现通过整合生成的推论结果的精度的提高。
[0056]
上述一方面所涉及的推论装置可以与介入装置连接,所述介入装置通过介入所述对象传感器的观测状态来变更该观测状态。与所述推论结果相关的信息也可以包括用于使所述介入装置执行按照所推断的所述变更方法来变更所述对象传感器的观测状态的动作的指令信息。所述输出部也可以通过向所述介入装置发送所述指令信息而使所述介入装置执行用于按照所推断的所述变更方法来变更所述对象传感器的观测状态的所述动作。根据该构成,能够自动地优化传感器的观测状态。
[0057]
需要说明的是,介入装置只要能够介入传感器的观测状态即可,其种类也可以不特别限定,可以根据实施方式适当选择。作为具体例,介入装置例如可以是云台、照明装置等。云台可以用于变更传感器的位置及朝向中的至少任一者。照明装置可以用于变更传感器的观测对象周围的明亮度。介入装置可以具备控制该介入装置的动作的控制装置。在这种情况下,推论装置也可以通过向控制装置发送指令信息而使该控制装置执行用于变更对象传感器的观测状态的动作的控制。
[0058]
在上述一方面所涉及的推论装置中,与所述推论结果相关的信息也可以包括用于指示用户按照所述变更方法变更所述对象传感器的观测状态的指示信息。所述输出部也可以将所述指示信息输出到输出装置。根据该构成,能够向用户提示用于使传感器的观测状态优化的变更方法。由此,即使是不具有专业知识的用户,也能够根据对象环境使传感器的观测状态优化。
[0059]
在上述一方面所涉及的推论装置中,所述传感器可以是照相机。所述观测数据可以是图像数据。所述规定条件可以是与将所述对象物拍摄到所述图像数据中以适于检查所述对象物的属性相关的条件。根据该构成,在基于由照相机得到的图像数据检查对象物的
属性的场景中,能够降低构建在新的环境中能够适当地推断照相机的最佳观测方法的推论模型所花费的成本。
[0060]
另外,例如在上述一方面所涉及的推论装置中,所述规定的推论可以是根据移动体的状态预测移动体的移动路径。所述对象数据可以是与由传感器观测的对象移动体的状态相关的数据。所述环境数据可以是与所述传感器观测所述对象移动体的移动的对象观测环境相关的数据。根据该构成,在监视移动体的移动的场景中,能够降低构建在新的环境中能够适当地预测移动体的移动路径的推论模型所花费的成本。需要说明的是,移动体例如可以是生物(人等)、机械(车辆等)等。
[0061]
另外,例如在上述一方面所涉及的推论装置中,所述规定的推论可以是根据用户的会话行动推断适合于用户的会话策略。所述对象数据可以是与对象用户的会话行动相关的数据。所述环境数据可以是与所述对象用户进行会话行动的对象会话环境相关的数据。根据该构成,在生成针对用户的会话的场景中,能够降低构建在新的环境中能够适当地推断适合于用户的会话策略的推论模型所花费的成本。需要说明的是,会话策略只要与针对用户的会话行动的确定相关即可,其规定内容也可以不特别限定,可以根据实施方式适当选择。会话策略例如也可以规定会话的内容、说话时机、会话的频率、语调等。
[0062]
另外,例如在上述一方面所涉及的推论装置中,所述规定的推论可以是根据机器人装置的状态推断适合于任务的机器人装置的动作指令。所述对象数据可以是与对象机器人装置的状态相关的数据。所述环境数据可以是与所述对象机器人装置完成所述任务的对象任务环境相关的数据。根据该构成,在控制机器人装置的动作的场景中,能够降低构建在新的环境中能够适当地推断适合于任务的机器人装置的动作指令的推论模型所花费的成本。
[0063]
需要说明的是,机器人装置及任务也可以分别不特别限定,可以根据实施方式适当选择。机器人装置例如可以是工业用机器人、设备装置、可自动驾驶的车辆等。设备装置例如可以是空调设备(空调装置)、照明装置等。在机器人装置是工业用机器人的情况下,任务例如可以是将工件配置在目标位置、等等。在机器人装置是空调设备等设备装置的情况下,任务例如是保持在规定的温度等,可以根据设备装置的种类来确定。在机器人装置是可自动驾驶的车辆的情况下,任务例如可以是通过自动驾驶从当前位置移动到目标位置、等等。
[0064]
另外,本发明的一方面所涉及的运算模型生成装置具备:数据获取部,获取在运算模型的机器学习中利用的学习数据,运算模型用于根据环境数据计算在对象环境下分别规定重视各推论模型的推论结果的程度的多个整合参数各自的值,各推论模型是根据在不同的环境下得到的局部学习数据而被导出以执行规定的推论的模型;学习处理部,利用所获取的学习数据来执行上述运算模型的机器学习,机器学习通过训练运算模型以使计算出的各整合参数的值适合于对象环境下的规定的推论而构成;以及保存处理部,将运算模型的机器学习的结果保存在规定的存储区域中。运算模型生成装置可以改称为模型生成装置、学习装置等。各模型(例如,机器学习模型)的学习方法相当于学习完毕的模型(例如,学习完毕的机器学习模型)的生成方法。
[0065]
作为上述各方式所涉及的推论装置的其他方面,本发明的一方面可以是实现以上推论装置或模型生成装置的各构成的信息处理方法,也可以是程序,还可以是存储有这样
的程序的计算机等可读取的存储介质。计算机等可读取的存储介质是指,通过电、磁、光学、机械或化学作用来蓄积程序等信息的介质。另外,本发明的一方面所涉及的推论系统可以由上述任一方式所涉及的推论装置及根据局部学习数据导出推论模型的一个以上的推论模型生成装置构成。推论模型生成装置可以改称为模型生成装置、局部学习装置等。推论系统可以还具备上述运算模型生成装置。
[0066]
例如,本发明的一方面所涉及的推论方法是由计算机执行以下步骤的信息处理方法:获取成为规定的推论的对象的规定的对象数据;获取与执行所述规定的推论的对象环境相关的环境数据;通过对根据在不同的环境下得到的局部学习数据而被导出以执行所述规定的推论的多个推论模型分别提供所述对象数据,并使该各推论模型对所述对象数据执行所述规定的推论,来获取该各推论模型对所获取的所述对象数据的推论结果;通过按照整合规则整合所述各推论模型的推论结果,来生成在所述对象环境下对所述对象数据的推论结果,所述整合规则由在所述对象环境下分别规定重视所述各推论模型的推论结果的程度的多个整合参数构成,按照所述整合规则整合所述各推论模型的推论结果具备:根据所获取的所述环境数据确定所述各整合参数的值、使用所确定的所述各整合参数的值对所述各推论模型的所述推论结果进行加权、以及整合所述各推论模型的加权后的所述推论结果;以及输出与所生成的所述推论结果相关的信息。
[0067]
另外,例如本发明的一方面所涉及的推论程序是用于使计算机执行以下步骤的程序:获取成为规定的推论的对象的规定的对象数据;获取与执行所述规定的推论的对象环境相关的环境数据;通过对根据在不同的环境下得到的局部学习数据而被导出以执行所述规定的推论的多个推论模型分别提供所述对象数据,并使该各推论模型对所述对象数据执行所述规定的推论,来获取该各推论模型对所获取的所述对象数据的推论结果;通过按照整合规则整合所述各推论模型的推论结果,来生成在所述对象环境下对所述对象数据的推论结果,所述整合规则由在所述对象环境下分别规定重视所述各推论模型的推论结果的程度的多个整合参数构成,按照所述整合规则整合所述各推论模型的推论结果具备:根据所获取的所述环境数据确定所述各整合参数的值、使用所确定的所述各整合参数的值对所述各推论模型的所述推论结果进行加权、以及整合所述各推论模型的加权后的所述推论结果;以及输出与所生成的所述推论结果相关的信息。
[0068]
发明效果
[0069]
根据本发明,能够降低构建在新的环境中能够适当地执行规定的推论的学习完毕的机器学习模型所花费的成本。
附图说明
[0070]
图1a示意性地举例示出应用本发明的场景的一例。
[0071]
图1b示意性地举例示出应用本发明的场景的一例。
[0072]
图2示意性地举例示出实施方式所涉及的推论装置的硬件构成的一例。
[0073]
图3示意性地举例示出实施方式所涉及的局部学习装置的硬件构成的一例。
[0074]
图4示意性地举例示出实施方式所涉及的推论装置的软件构成的一例。
[0075]
图5a示意性地举例示出与实施方式所涉及的局部学习装置的机器学习相关的软件构成的一例。
[0076]
图5b示意性地举例示出与实施方式所涉及的局部学习装置的推论装置相关的软件构成的一例。
[0077]
图6举例示出与实施方式所涉及的局部学习装置的学习完毕的机器学习模型生成相关的处理过程的一例。
[0078]
图7a举例示出实施方式所涉及的机器学习模型及机器学习方法的一例。
[0079]
图7b举例示出实施方式所涉及的机器学习模型及机器学习方法的一例。
[0080]
图7c举例示出实施方式所涉及的机器学习模型及机器学习方法的一例。
[0081]
图8举例示出实施方式所涉及的局部学习装置的推论处理的处理过程的一例。
[0082]
图9a举例示出与实施方式所涉及的推论装置的推论处理相关的处理过程的一例。
[0083]
图9b举例示出与实施方式所涉及的推论装置的整合处理相关的子例程的处理过程的一例。
[0084]
图10a举例示出确定实施方式所涉及的整合参数的值的方法的一例。
[0085]
图10b举例示出实施方式所涉及的整合参数的值的确定中利用的运算模型的机器学习的处理过程的一例。
[0086]
图10c举例示出实施方式所涉及的运算模型及机器学习方法的一例。
[0087]
图10d举例示出实施方式所涉及的运算模型及机器学习方法的一例。
[0088]
图11a举例示出确定实施方式所涉及的整合参数的值的方法的一例。
[0089]
图11b举例示出通过图11a的方法确定整合参数的值的处理过程的一例。
[0090]
图12a举例示出确定实施方式所涉及的整合参数的值的方法的一例。
[0091]
图12b举例示出通过图12a的方法确定整合参数的值的处理过程的一例。
[0092]
图13a示意性地举例示出实施方式所涉及的学习完毕的机器学习模型的分组处理。
[0093]
图13b举例示出实施方式所涉及的推论装置进行的分组的处理过程的一例。
[0094]
图13c举例示出实施方式所涉及的推论装置进行的分组的处理过程的一例。
[0095]
图14示意性地举例示出应用本发明的其他场景的一例。
[0096]
图15示意性地举例示出其他方式所涉及的检查装置的硬件构成的一例。
[0097]
图16a示意性地举例示出其他方式所涉及的检查装置的软件构成的一例。
[0098]
图16b示意性地举例示出其他方式所涉及的检查装置的软件构成的一例。
[0099]
图17示意性地举例示出应用本发明的其他场景的一例。
[0100]
图18示意性地举例示出其他方式所涉及的预测装置的硬件构成的一例。
[0101]
图19a示意性地举例示出其他方式所涉及的预测装置的软件构成的一例。
[0102]
图19b示意性地举例示出其他方式所涉及的预测装置的软件构成的一例。
[0103]
图20示意性地举例示出应用本发明的其他场景的一例。
[0104]
图21示意性地举例示出其他方式所涉及的会话装置的硬件构成的一例。
[0105]
图22a示意性地举例示出其他方式所涉及的会话装置的软件构成的一例。
[0106]
图22b示意性地举例示出其他方式所涉及的会话装置的软件构成的一例。
[0107]
图23示意性地举例示出应用本发明的其他场景的一例。
[0108]
图24示意性地举例示出其他方式所涉及的控制装置的硬件构成的一例。
[0109]
图25a示意性地举例示出其他方式所涉及的控制装置的软件构成的一例。
[0110]
图25b示意性地举例示出其他方式所涉及的控制装置的软件构成的一例。
[0111]
图26a示意性地举例示出其他方式所涉及的模型生成装置的硬件构成的一例。
[0112]
图26b示意性地举例示出其他方式所涉及的模型生成装置的软件构成的一例。
[0113]
图27示意性地举例示出其他方式所涉及的局部学习装置的构成的一例。
[0114]
图28示意性地举例示出应用本发明的其他场景的一例。
[0115]
图29示意性地示出实施例及比较例的模拟中利用的机器人装置的概要。
[0116]
图30a示出在实施例及比较例中通过强化学习训练具有内插条件的动态的机器人装置的运动的结果。
[0117]
图30b示出在实施例及比较例中通过强化学习训练具有外插条件的动态的机器人装置的运动的结果。
具体实施方式
[0118]
以下,基于附图对本发明的一方面涉及的实施方式(以下,也表述为“本实施方式”)进行说明。但是,以下说明的本实施方式在所有方面都仅为本发明的例示。当然,能够在不脱离本发明的范围的情况下进行各种改良和变形。也就是说,在实施本发明时,也可以适当地采用符合实施方式的具体构成。需要说明的是,本实施方式中利用自然语言来说明出现的数据,但是,更为具体而言,利用计算机可识别的模拟语言、命令、参数、机器语言等来指定。
[0119]
§
1应用例
[0120]
首先,使用图1a及图1b对应用本发明的场景的一例进行说明。图1a及图1b示意性地举例示出应用本发明的场景的一例。如图1a及图1b所示,本实施方式所涉及的推论系统100具备推论装置1及多个局部学习装置2。推论装置1及各局部学习装置2可以经由网络相互连接。网络的种类例如可以从因特网、无线通信网、移动通信网、电话网、专用网等中适当选择。
[0121]
本实施方式所涉及的各局部学习装置2是构成为利用局部学习数据30执行机器学习模型40的机器学习的计算机。如图1a所示,各局部学习装置2在不同的环境下收集局部学习数据30,并利用所得到的局部学习数据30执行机器学习模型40的机器学习。通过该机器学习,各局部学习装置2构建获得了执行规定的推论的能力的学习完毕的机器学习模型45。
[0122]
所构建的各学习完毕的机器学习模型45是本发明的“根据在不同的环境下得到的局部学习数据而被导出以执行规定的推论的各推论模型”的一例。即,在本实施方式中,各推论模型由学习完毕的机器学习模型45构成。在以下的说明中,学习完毕的机器学习模型45可以改称为“推论模型”。
[0123]
机器学习的方法例如可以使用有监督学习、无监督学习及强化学习等。局部学习数据30的形式及种类也可以不特别限定,例如可以根据机器学习的方法、规定的推论内容等适当确定。各局部学习装置2可以改称为推论模型生成装置、模型生成装置等。
[0124]
执行规定的推论是基于未知的对象数据执行某推断处理。推论内容也可以不特别限定,可以根据实施方式适当确定。推论也可以是回归或识别。规定的推论例如可以是推断传感器的最佳观测方法、预测移动体的移动路径、推断适合于用户的会话策略、推断适合于任务的机器人装置的动作指令,等等。或者,规定的推论例如可以是推断由照相机(拍摄装
置)得到的图像数据中拍摄的被拍摄物的属性等推断由传感器得到的观测数据中表现出的特征。或者,规定的推论也可以是根据由传感器得到的观测数据推断与传感器的观测条件相关的特征。与观测条件相关的特征可以包括可能与观测条件关联的所有现象,例如可以包括传感器与观测对象之间的距离、观测对象周围的明亮度等。推论结果的表现可以根据推论内容适当确定。推论结果例如可以通过基于回归的连续值、属于类的概率等来表现。另外,推论结果例如也可以通过一个以上的数值或一个以上的类来表现。
[0125]
得到局部学习数据30的环境不同例如是时间、场所、对象物、用户等可能对规定的推论产生影响的现象至少部分地不同。作为一例,在不同的场所得到的局部学习数据30可以作为在不同的环境下得到的局部学习数据来对待。另外,作为其他例,在同一场所而不同的时刻得到的局部学习数据30可以作为在不同的环境下得到的局部学习数据来对待。在各学习完毕的机器学习模型45的构建中利用的局部学习数据30可以包括至少部分地相同的数据。
[0126]
得到局部学习数据30的环境及推论装置1执行规定的推论的对象环境可以分别通过一个以上的类或一个以上的数值来表现。在各环境通过数值来表现的情况下,各环境也可以用数值范围来表现。此时,第一环境与第二环境不同除了包括表现第一环境的第一数值范围与表现第二环境的第二数值范围不重复之外,也可以包括第一数值范围与第二数值范围部分地重复。
[0127]
需要说明的是,在图1a及图1b的例子中,推论系统100具备n个局部学习装置2_1~2_n。以下,为了便于说明,在区分每一个的情况下,附加_1、_2、_n等进一步的符号,否则,如“局部学习装置2”等那样省略这些符号。各局部学习装置2_1~2_n收集各局部学习数据30_1~30_n,并利用所收集的各局部学习数据30_1~30_n执行各机器学习模型40_1~40_n的机器学习。由此,各局部学习装置2_1~2_n构建各学习完毕的机器学习模型45_1~45_n。即,生成n个学习完毕的机器学习模型45_1~45_n。不过,局部学习装置2及生成的学习完毕的机器学习模型45各自的数量(n)也可以不特别限定,可以根据实施方式适当确定。另外,由各局部学习装置2生成的学习完毕的机器学习模型45的数量也可以不限于一个,也可以是两个以上。
[0128]
另一方面,本实施方式所涉及的推论装置1是构成为利用根据在不同的环境下得到的局部学习数据30导出的各学习完毕的机器学习模型45在对象环境下执行规定的推论的计算机。如图1b所示,本实施方式所涉及的推论装置1获取成为规定的推论的对象的规定的对象数据61。另外,本实施方式所涉及的推论装置1获取与执行规定的推论的对象环境相关的环境数据63。
[0129]
对象数据61只要是规定的推论时使用的数据即可,其种类也可以不特别限定,可以根据推论内容适当选择。对象数据61例如可以是图像数据、声音数据、数值数据、文本数据、其他由传感器得到的观测数据等。另外,对象数据61可以是未加工的数据或加工完毕的数据(例如,根据未加工的数据计算出的特征量)。对象数据61可以改称为“输入数据”。
[0130]
环境数据63只要是与执行规定的推论的对象环境相关的数据即可,其种类也可以不特别限定,可以根据实施方式适当选择。执行规定的推论的环境例如是得到对象数据61的环境。与得到对象数据61的环境相关的属性可以包括与规定的推论直接或间接地关联的对象物或用户的属性等可能与推论关联的所有现象。环境数据63与对象数据61同样地,例
如可以是图像数据、声音数据、数值数据、文本数据、其他由传感器得到的观测数据等。另外,环境数据63也可以是未加工的数据或加工完毕的数据。
[0131]
分别获取对象数据61及环境数据63的方法也可以不特别限定,可以根据实施方式适当选择。在对象数据61及环境数据63的获取中利用传感器的情况下,对象数据61及环境数据63可以来源于由同一传感器得到的同一观测数据,或者也可以来源于由不同的传感器得到的不同的观测数据。另外,对象数据61及环境数据63也可以包括至少部分地通用的数据。
[0132]
本实施方式所涉及的推论装置1将所获取的对象数据61提供给各学习完毕的机器学习模型45(45_1~45_n),使各学习完毕的机器学习模型45(45_1~45_n)对对象数据61执行规定的推论。由此,本实施方式所涉及的推论装置1获取各学习完毕的机器学习模型45(45_1~45_n)对所获取的对象数据61的推论结果。然后,本实施方式所涉及的推论装置1通过按照整合规则5整合各学习完毕的机器学习模型45(45_1~45_n)的推论结果,来生成在对象环境下对对象数据61的推论结果。
[0133]
具体而言,整合规则5由在对象环境下分别规定重视各学习完毕的机器学习模型45(45_1~45_n)的推论结果的程度的多个整合参数p(p1~pn)构成。整合参数的数量可以根据推论模型(学习完毕的机器学习模型45)的数量适当确定。在各学习完毕的机器学习模型45中可以设定一个以上的整合参数。
[0134]
本实施方式所涉及的推论装置1根据所获取的环境数据63确定各整合参数p(p1~pn)的值。需要说明的是,在各整合参数p(p1~pn)的值的确定中,除了环境数据63之外,可以进一步考虑对象数据61。即,本实施方式所涉及的推论装置1也可以根据对象数据61及环境数据63确定各整合参数p(p1~pn)的值。
[0135]
接着,本实施方式所涉及的推论装置1使用所确定的各整合参数p(p1~pn)的值,对对应的各学习完毕的机器学习模型45(45_1~45_n)的推论结果进行加权。然后,本实施方式所涉及的推论装置1整合各学习完毕的机器学习模型45(45_1~45_n)的加权后的推论结果。由此,本实施方式所涉及的推论装置1按照整合规则5整合各学习完毕的机器学习模型45(45_1~45_n)的推论结果。
[0136]
推论结果的整合方法也可以不特别限定,可以根据实施方式适当确定。例如,整合各学习完毕的机器学习模型45的推论结果可以由平均化或多数表决定构成。在规定的推论是回归的情况下,推论结果的整合可以主要通过平均化来进行。另外,在规定的推论是识别的情况下,推论结果的整合可以主要通过多数表决定来进行。通过该整合处理,生成在对象环境下对对象数据61的推论结果。本实施方式所涉及的推论装置1输出与所生成的推论结果相关的信息。
[0137]
如上所述,本实施方式所涉及的推论装置1为了在对象环境下执行规定的推论,不是构建新的推论模型,而是灵活应用已经构建的多个推论模型(学习完毕的机器学习模型45_1~45_n)。一般而言,设想为越是根据在类似于对象环境的学习环境中得到的局部学习数据导出的推论模型,对在对象环境下得到的对象数据的推论精度越高。另一方面,设想为越是根据在不类似于对象环境的学习环境中得到的局部学习数据导出的推论模型,对在对象环境下得到的对象数据的推论精度越低。另外,在多个推论模型中有时会包括推荐在对象环境下优先利用的推论模型。
[0138]
因此,在上述整合处理中,本实施方式所涉及的推论装置1根据与执行规定的推论的对象环境相关的环境数据63,来确定整合规则5的各整合参数p(p1~pn)的值。例如,也可以确定各整合参数p(p1~pn)的值,以重视类似于对象环境的学习环境的学习完毕的机器学习模型45及优先级高的学习完毕的机器学习模型45中的至少任一者的推论结果。在本实施方式中,通过像这样地根据对象环境调整重视各学习完毕的机器学习模型45的推论的程度,能够将在各种环境中得到的见解(学习完毕的机器学习模型45)定制为适合于新的环境。其结果,基于所定制的见解,换言之,基于各学习完毕的机器学习模型45的加权后的推论结果的整合结果,能够在对象环境下适当地执行规定的推论。
[0139]
因此,根据本实施方式,利用根据在不同的环境下得到的局部学习数据30导出的多个学习完毕的机器学习模型45,能够在对象环境下适当地执行规定的推论。即,通过灵活应用已经构建的多个学习完毕的机器学习模型45,能够构建在对象环境下能够适当地执行规定的推论的新的推论模型。因此,能够省略在对象环境下收集新的学习数据并根据所收集的新的学习数据导出新的推论模型(在本实施方式中是学习完毕的机器学习模型)的作业的麻烦。因此,根据该构成,能够降低构建在新的环境中能够适当地执行规定的推论的推论模型花费的成本。
[0140]
§
2构成例
[0141]
[硬件构成]
[0142]
《推论装置》
[0143]
接着,使用图2对本实施方式所涉及的推论装置1的硬件构成的一例进行说明。图2示意性地举例示出本实施方式所涉及的推论装置1的硬件构成的一例。
[0144]
如图2所示,本实施方式所涉及的推论装置1是与控制部11、存储部12、通信接口13、外部接口14、输入装置15、输出装置16及驱动器17电连接的计算机。需要说明的是,在图2中,将通信接口及外部接口记载为“通信i/f”及“外部i/f”。
[0145]
控制部11包括作为硬件处理器的cpu(central processing unit:中央处理单元)、ram(random access memory:随机存取存储器)、rom(read only memory:只读存储器)等,并构成为基于程序及各种数据执行信息处理。存储部12是存储器的一例,例如由硬盘驱动器、固态驱动器等构成。在本实施方式中,存储部12存储推论程序81、整合规则数据57、学习结果数据47、学习数据59、学习环境数据35等各种信息。
[0146]
推论程序81是用于使推论装置1在对象环境下执行与规定的推论相关的后述的信息处理(图9a及图9b)的程序。推论程序81包括该信息处理的一系列命令。整合规则数据57表示与整合规则5相关的信息。各份学习结果数据47表示与通过机器学习而构建的各学习完毕的机器学习模型45相关的信息。如后所述,运算模型可以用于根据环境数据63计算各整合参数p(p1~pn)的值。整合规则5可以进一步具备通过机器学习而构建的学习完毕的运算模型。学习数据59用于通过机器学习构建学习完毕的运算模型。各份学习环境数据35表示与得到在各推论模型的导出(在本实施方式中是各学习完毕的机器学习模型45的机器学习)中利用的局部学习数据30的环境相关的信息。详细情况将在后面叙述。
[0147]
通信接口13例如是有线lan(local area network:局域网)模块、无线lan模块等,是用于经由网络进行有线或无线通信的接口。推论装置1通过利用该通信接口13,能够与其他信息处理装置(例如,局部学习装置2)进行经由网络的数据通信。
[0148]
外部接口14例如是usb(universal serial bus:通用串行总线)端口、专用端口等,是用于与外部装置连接的接口。外部接口14的种类及数量可以根据所连接的外部装置的种类及数量适当选择。推论装置1可以经由外部接口14与用于获取对象数据61、环境数据63及可能与它们关联的数据中的至少任一者的传感器连接。另外,推论装置1可以经由外部接口14与基于推论结果进行控制的对象的装置(例如,后述的介入装置、机器人装置等)连接。
[0149]
输入装置15例如是鼠标、键盘等用于进行输入的装置。另外,输出装置16例如是显示器、扬声器等用于进行输出的装置。操作者通过利用输入装置15及输出装置16,能够操作推论装置1。
[0150]
驱动器17例如是cd驱动器、dvd驱动器等,是用于读入存储在存储介质91中的程序的驱动装置。驱动器17的种类可以根据存储介质91的种类适当选择。上述推论程序81、整合规则数据57、学习结果数据47、学习数据59及学习环境数据35中的至少任一者也可以存储在该存储介质91中。
[0151]
存储介质91是以使计算机及其他装置、机械等可读取所记录的程序等信息的方式来通过电、磁、光学、机械或化学作用蓄积该程序等信息的介质。推论装置1也可以从该存储介质91中获取上述推论程序81、整合规则数据57、学习结果数据47、学习数据59及学习环境数据35中的至少任一者。
[0152]
这里,在图2中,作为存储介质91的一例,举例示出cd、dvd等盘式的存储介质。但是,存储介质91的种类并不限于盘式,也可以是盘式以外的类型。作为盘式以外的存储介质,例如可列举闪存等半导体存储器。
[0153]
需要说明的是,关于推论装置1的具体的硬件构成,可根据实施方式适当地进行构成要素的省略、替换及追加。例如,控制部11也可以包括多个硬件处理器。硬件处理器可以由微处理器、fpga(field-programmable gate array:现场可编程门阵列)、dsp(digital signal processor:数字信号处理器)等构成。存储部12也可以由控制部11中包括的ram及rom构成。通信接口13、外部接口14、输入装置15、输出装置16及驱动器17中的至少任一者也可以省略。推论装置1也可以由多台计算机构成。在这种情况下,各计算机的硬件构成可以一致,也可以不一致。另外,推论装置1除了是设计为所提供的服务专用的信息处理装置之外,也可以是通用的服务器装置、pc(personal computer:个人计算机)等。
[0154]
《局部学习装置》
[0155]
接着,使用图3对本实施方式所涉及的各局部学习装置2的硬件构成的一例进行说明。图3示意性地举例示出本实施方式所涉及的各局部学习装置2的硬件构成的一例。
[0156]
如图3所示,本实施方式所涉及的各局部学习装置2是与控制部21、存储部22、通信接口23、外部接口24、输入装置25、输出装置26及驱动器27电连接的计算机。需要说明的是,在图3中,与图2同样地,将通信接口及外部接口记载为“通信i/f”及“外部i/f”。
[0157]
各局部学习装置2的控制部21~驱动器27可以分别与上述推论装置1的控制部11~驱动器17各自同样地构成。即,控制部21包括作为硬件处理器的cpu、ram、rom等,并构成为基于程序及数据执行各种信息处理。存储部22例如由硬盘驱动器、固态驱动器等构成。存储部22存储学习程序821、推论程序822、局部学习数据30、学习结果数据47、学习环境数据35等各种信息。
[0158]
学习程序821是用于使局部学习装置2执行与机器学习模型40的机器学习相关的后述的信息处理(图6)的程序。学习程序821包括该信息处理的一系列命令。推论程序822是用于使局部学习装置2执行与利用学习完毕的机器学习模型45的规定的推论相关的后述的信息处理(图8)的程序。推论程序822包括该信息处理的一系列命令。局部学习数据30在各个环境中收集,并在用于使机器学习模型40获得执行规定的推论的能力的机器学习中被利用。详细情况将在后面叙述。
[0159]
通信接口23例如是有线lan模块、无线lan模块等,是用于经由网络进行有线或无线通信的接口。各局部学习装置2通过利用该通信接口23,能够与其他信息处理装置(例如,推论装置1)进行经由网络的数据通信。
[0160]
外部接口24例如是usb端口、专用端口等,是用于与外部装置连接的接口。外部接口24的种类及数量可以根据所连接的外部装置的种类及数量适当选择。各局部学习装置2可以经由外部接口24与用于获取局部学习数据30、学习环境数据35、后述的对象数据及可能与它们关联的数据中的至少任一者的传感器连接。另外,各局部学习装置2可以经由外部接口24与基于推论结果进行控制的对象的装置(例如,后述的介入装置、机器人装置等)连接。
[0161]
输入装置25例如是鼠标、键盘等用于进行输入的装置。另外,输出装置26例如是显示器、扬声器等用于进行输出的装置。操作者通过利用输入装置25及输出装置26,能够操作各局部学习装置2。
[0162]
驱动器27例如是cd驱动器、dvd驱动器等,是用于读入存储在存储介质92中的程序的驱动装置。上述学习程序821、推论程序822及局部学习数据30中的至少任一者也可以存储在存储介质92中。另外,各局部学习装置2也可以从存储介质92中获取上述学习程序821、推论程序822及局部学习数据30中的至少任一者。
[0163]
需要说明的是,关于各局部学习装置2的具体的硬件构成,能够根据实施方式适当地进行构成要素的省略、替换及追加。例如,控制部21也可以包括多个硬件处理器。硬件处理器可以由微处理器、fpga、dsp等构成。存储部22也可以由控制部21中包括的ram及rom构成。通信接口23、外部接口24、输入装置25、输出装置26及驱动器27中的至少任一者也可以省略。各局部学习装置2也可以由多台计算机构成。在这种情况下,各计算机的硬件构成可以一致,也可以不一致。在本实施方式中,各局部学习装置2的硬件构成是通用的。但是,各局部学习装置2的硬件构成的关系也可以不限于这样的例子。在一个局部学习装置2与其他局部学习装置2之间,硬件构成也可以不同。另外,各局部学习装置2除了是设计为所提供的服务专用的信息处理装置之外,也可以是通用的服务器装置、通用的pc等。
[0164]
[软件构成]
[0165]
《推论装置》
[0166]
接着,使用图4对本实施方式所涉及的推论装置1的软件构成的一例进行说明。图4示意性地举例示出本实施方式所涉及的推论装置1的软件构成的一例。
[0167]
推论装置1的控制部11将存储在存储部12中的推论程序81在ram中展开。然后,控制部11通过cpu解释及执行在ram中展开的推论程序81所包括的命令,控制各构成要素。由此,如图4所示,本实施方式所涉及的推论装置1作为具备第一数据获取部111、第二数据获取部112、结果获取部113、整合部114、输出部115、学习数据获取部116、学习处理部117、保
存处理部118、参数设定部119及分组部1110作为软件模块的计算机进行动作。即,在本实施方式中,推论装置1的各软件模块通过控制部11(cpu)实现。
[0168]
第一数据获取部111获取成为规定的推论的对象的规定的对象数据61。第二数据获取部112获取与执行规定的推论的对象环境相关的环境数据63。结果获取部113通过对根据在不同的环境下得到的局部学习数据30而被导出以执行规定的推论的多个推论模型分别提供对象数据61,并使各推论模型执行对对象数据61的规定的推论,来获取各推论模型对所获取的对象数据61的推论结果。
[0169]
在本实施方式中,各推论模型由通过利用在不同的环境下得到的局部学习数据30的机器学习而获得了执行规定的推论的能力的学习完毕的机器学习模型45构成。进而,在本实施方式中,结果获取部113通过保持各份学习结果数据47,从而具备各学习完毕的机器学习模型45。结果获取部113参照各份学习结果数据47,进行各学习完毕的机器学习模型45的设定。然后,结果获取部113对各学习完毕的机器学习模型45提供对象数据61,通过使各学习完毕的机器学习模型45对对象数据61执行规定的推论,来获取各学习完毕的机器学习模型45对所获取的对象数据61的推论结果。
[0170]
整合部114按照整合规则5整合各推论模型的推论结果。整合规则5由在对象环境下分别规定重视各推论模型的推论结果的程度的多个整合参数p构成。在本实施方式中,各整合参数p(p1~pn)规定重视各学习完毕的机器学习模型45(45_1~45_n)的推论结果的程度。整合部114通过保持整合规则数据57,从而具有与整合规则5相关的信息。整合部114参照整合规则数据57进行整合规则5的设定。整合部114按照整合规则5整合各学习完毕的机器学习模型45(45_1~45_n)的推论结果。
[0171]
具体而言,整合部114根据所获取的环境数据63确定各整合参数p(p1~pn)的值。需要说明的是,在各整合参数p(p1~pn)的值的确定中,除了环境数据63之外,可以进一步考虑对象数据61。接着,整合部114使用所确定的各整合参数p的值,对对应的各推论模型的推论结果进行加权。然后,整合部114整合各推论模型的加权后的推论结果。
[0172]
在本实施方式中,整合部114使用所确定的各整合参数p(p1~pn)的值,对对应的各学习完毕的机器学习模型45(45_1~45_n)的推论结果进行加权。然后,整合部114整合各学习完毕的机器学习模型45(45_1~45_n)的加权后的推论结果。由此,整合部114按照整合规则5整合各学习完毕的机器学习模型45(45_1~45_n)的推论结果。
[0173]
通过以上整合处理,整合部114生成在对象环境下对对象数据61的推论结果。输出部115输出与所生成的推论结果相关的信息。
[0174]
在本实施方式中,运算模型可以用于根据环境数据63确定各整合参数p(p1~pn)的值。学习数据获取部116、学习处理部117及保存处理部118执行与学习完毕的运算模型的生成相关的信息处理。具体而言,学习数据获取部116获取用于根据环境数据63计算各整合参数p(p1~pn)的值的运算模型51的机器学习中利用的学习数据59。学习处理部117利用所获取的学习数据59执行运算模型51的机器学习。机器学习通过训练运算模型51以使计算的各整合参数p(p1~pn)的值适合于对象环境下的规定的推论而构成。由此,生成学习完毕的运算模型52。保存处理部118生成与运算模型51的机器学习的结果(即、学习完毕的运算模型52)相关的信息,并将所生成的信息保存在规定的存储区域中。所生成的与学习完毕的运算模型52相关的信息可以包括在整合规则数据57中。
[0175]
在这种情况下,整合部114也可以对学习完毕的运算模型52提供环境数据63(及对象数据61),通过执行学习完毕的运算模型52的运算处理,来获取各整合参数p(p1~pn)的值作为学习完毕的运算模型52的输出。由此,整合部114也可以根据环境数据63(及对象数据61)确定各整合参数p(p1~pn)的值。
[0176]
另外,在本实施方式中,多个整合参数p(p1~pn)中的至少一部分的值可以由用户等操作者指定。参数设定部119执行与整合参数的值的指定相关的信息处理。具体而言,参数设定部119接收多个整合参数p(p1~pn)中的至少一个整合参数的值的指定。然后,参数设定部119将至少一个整合参数的值设定为指定的值。与指定的设定内容相关的信息可以包括在整合规则数据57中。在这种情况下,对上述各推论模型(学习完毕的机器学习模型45)的推论结果进行加权可以包括对与至少一个整合参数对应的推论模型(学习完毕的机器学习模型45)的推论结果进行加权。
[0177]
另外,在本实施方式中,各推论模型(学习完毕的机器学习模型45)也可以分组。组可以根据推论的种类、目的、对象环境等适当设定。分组部1110执行与推论模型(学习完毕的机器学习模型45)的分组相关的信息处理。具体而言,分组部1110将各推论模型(学习完毕的机器学习模型45)分配给多个组中的至少任一者。与此相应地,结果获取部113也可以在所设定的多个组中确定对象环境中利用的组,针对属于所确定的组的推论模型(学习完毕的机器学习模型45),执行获取上述推论结果的处理。同样地,整合部114也可以针对属于所确定的组的推论模型(学习完毕的机器学习模型45)的推论结果,执行上述整合处理。与对各推论模型(学习完毕的机器学习模型45)的组的分配结果相关的信息可以适当地保存在规定的存储区域中。
[0178]
《局部学习装置》
[0179]
(a)学习处理
[0180]
接着,使用图5a对与本实施方式所涉及的各局部学习装置2的学习处理相关的软件构成的一例进行说明。图5a示意性地举例示出与本实施方式所涉及的各局部学习装置2的学习处理相关的软件构成的一例。
[0181]
各局部学习装置2的控制部21将存储在存储部22中的学习程序821在ram中展开。然后,控制部21通过cpu解释及执行在ram中展开的学习程序821所包括的命令,控制各构成要素。由此,如图5a所示,本实施方式所涉及的各局部学习装置2作为具备学习数据获取部21、环境数据获取部212、学习处理部213及保存处理部214作为软件模块的计算机进行动作。即,在本实施方式中,与学习处理相关的各局部学习装置2的各软件模块通过控制部21(cpu)实现。
[0182]
学习数据获取部211获取推论模型的导出中利用的局部学习数据30。在本实施方式中,学习数据获取部211获取机器学习模型40的机器学习中利用的局部学习数据30。环境数据获取部212获取与得到局部学习数据30的环境(以下,也记载为“学习环境”)相关的学习环境数据35。学习环境数据35是与环境数据63同种的数据。
[0183]
学习处理部213利用所获取的局部学习数据30执行机器学习模型40的机器学习。通过该机器学习,构建(生成)获得了执行规定的推论的能力的学习完毕的机器学习模型45。保持处理部214生成与所构建的学习完毕的机器学习模型45相关的信息作为学习结果数据47,并将所生成的学习结果数据47保存在规定的存储区域中。
[0184]
在本实施方式中,在各局部学习装置2之间,局部学习数据30的收集可能在不同的环境下执行。然后,根据所得到的局部学习数据30生成学习完毕的机器学习模型45。其结果,能够得到根据在不同的环境下得到的局部学习数据30而被导出以执行规定的推论的多个学习完毕的机器学习模型45。
[0185]
(b)推论处理
[0186]
接着,使用图5b对与本实施方式所涉及的各局部学习装置2的推论处理相关的软件构成的一例进行说明。图5b示意性地举例示出与本实施方式所涉及的各局部学习装置2的推论处理相关的软件构成的一例。
[0187]
各局部学习装置2的控制部21将存储在存储部22中的推论程序822在ram中展开。然后,控制部21通过cpu解释及执行在ram中展开的推论程序822所包括的命令,控制各构成要素。由此,如图5b所示,本实施方式所涉及的各局部学习装置2作为具备对象数据获取部216、推论部217及输出部218作为软件模块的计算机进行动作。即,在本实施方式中,与推论处理相关的各局部学习装置2的各软件模块也通过控制部21(cpu)实现。
[0188]
对象数据获取部216获取成为规定的推论的对象的对象数据225。对象数据225是与由推论装置1得到的对象数据61同种的数据。推论部217包括根据局部学习数据30导出的推论模型。推论部217利用推论模型对对象数据225执行规定的推论。在本实施方式中,推论部217通过保持学习结果数据47,从而包括学习完毕的机器学习模型45。推论部217参照学习结果数据47进行学习完毕的机器学习模型45的设定。接着,推论部217对学习完毕的机器学习模型45提供对象数据225,执行学习完毕的机器学习模型45的运算处理。由此,推论部217获取对对象数据225执行规定的推论的结果作为学习完毕的机器学习模型45的输出。输出部218输出与对对象数据225的推论结果相关的信息。
[0189]
《其他》
[0190]
关于推论装置1及各局部学习装置2的各软件模块,将在后述的动作例中详细说明。需要说明的是,在本实施方式中,对推论装置1及各局部学习装置2的各软件模块均通过通用的cpu实现的例子进行了说明。但是,以上软件模块的一部分或者全部也可以通过一个或多个专用的处理器实现。另外,关于推论装置1及各局部学习装置2各自的软件构成,也可以根据实施方式适当地进行软件模块的省略、替换及追加。
[0191]
§
3动作例
[0192]
[局部学习装置]
[0193]
(a)学习处理
[0194]
接着,使用图6对与推论模型的生成相关的各局部学习装置2的动作例进行说明。图6是示出与各局部学习装置2的学习完毕的机器学习模型45的生成相关的处理过程的一例的流程图。不过,以下说明的各处理过程只不过是一例而已,各步骤可以尽可能地变更。进而,对于以下说明的各处理过程,可以根据实施方式适当地进行步骤的省略、替换及追加。
[0195]
(步骤s101及步骤s102)
[0196]
在步骤s101中,控制部21作为学习数据获取部211进行动作,获取推论模型的导出中利用的局部学习数据30。在本实施方式中,控制部21获取机器学习模型40的机器学习中利用的局部学习数据30。
[0197]
在步骤s102中,控制部21作为学习处理部213进行动作,利用所获取的局部学习数据30执行机器学习模型40的机器学习。通过该机器学习,控制部21能够生成获得了执行规定的推论的能力的学习完毕的机器学习模型45。
[0198]
机器学习模型40的构成及机器学习的方法的构成也可以分别不特别限定,可以根据实施方式适当确定。机器学习的方法例如可以使用有监督学习、无监督学习、强化学习等。机器学习模型40例如可以通过数据表、函数式等来表现。在机器学习模型40通过函数式表现的情况下,机器学习模型40例如可以由神经网络、线性函数、决策树等构成。神经网络的种类也可以不特别限定,可以根据实施方式适当确定。构成机器学习模型40的神经网络例如可以使用全连接型神经网络、卷积神经网络、递归型神经网络、它们的组合等。以下,对机器学习模型40的构成及机器学习的方法各自的三个例子进行说明。
[0199]
1.第一例
[0200]
图7a示意性地示出了机器学习模型40的构成及机器学习的方法的第一例。在第一例中,机器学习模型40采用神经网络,机器学习方法采用有监督学习。需要说明的是,在图7a中,为了便于说明,将局部学习数据30、机器学习模型40及学习完毕的机器学习模型45各自的一例表述为局部学习数据301、机器学习模型401及学习完毕的机器学习模型451。
[0201]
1-1.机器学习模型的构成例
[0202]
在第一例中,机器学习模型401由四层结构的全连接型神经网络构成。具体而言,机器学习模型401从输入侧开始依次具备输入层4011、中间(隐藏)层(4012、4013)及输出层4014。不过,机器学习模型401的结构也可以不限于这样的例子,可以根据实施方式适当确定。例如,机器学习模型401具备的中间层的数量也可以不限于两个,可以是一个以下,也可以是三个以上。中间层也可以省略。另外,机器学习模型401也可以具备卷积层、池化层、递归层等其他种类的层。递归层例如可以使用长短期记忆(long short-term memory)等。
[0203]
各层4011~4014中包括的神经元(节点)的数量也可以不特别限定,可以根据实施方式适当选择。相邻的层的神经元之间适当连接,对各连接设定权重(连接权)。在图7a的例子中,各层4011~4014中包括的神经元与相邻的层的所有神经元连接。然而,神经元的连接关系也可以不限于这样的例子,可以根据实施方式适当确定。各神经元设定有阈值,基本上根据各输入与各权重之积的和是否超过阈值来确定各神经元的输出。各层4011~4014中包括的各神经元间的连接的权重及各神经元的阈值是通过机器学习成为调整的对象的运算参数的一例。
[0204]
1-2.局部学习数据的构成例
[0205]
该机器学习模型401的有监督学习中利用的局部学习数据301由分别包括训练数据311(输入数据)及正解数据312(监督信号)的组合的多个学习数据集310构成。训练数据311是成为执行规定的推论的对象的数据,是与对象数据(61、225)同种的数据。正解数据312是表示对训练数据311执行规定的推论的结果(正解)的数据。正解数据312也可以称为标签。
[0206]
训练数据311及正解数据312的内容可以根据使机器学习模型401掌握的推论的内容适当选择。例如,在使机器学习模型401掌握推断传感器的最佳观测方法的能力的情形下,训练数据311可以由与传感器的当前的观测状态相关的数据构成,正解数据312可以由表示从该当前的观测状态向适当的观测状态的变更方法的数据构成。另外,例如在使机器
学习模型401掌握预测移动体的移动路径的能力的情形下,训练数据311可以由与移动体的状态相关的数据构成,正解数据312可以由表示该状态的移动体实际或虚拟地移动的路径的数据构成。另外,例如在使机器学习模型401掌握推断适合于用户的会话策略的能力的情形下,训练数据311可以由与用户的会话行动相关的数据构成,正解数据312可以由表示适合于该用户的会话策略的数据构成。另外,例如在使机器学习模型401掌握推断适合于任务的机器人装置的动作指令的能力的情形下,训练数据311可以由与机器人装置的状态相关的数据构成,正解数据312可以由表示适合于该任务的完成的动作指令的数据构成。另外,例如在使机器学习模型401掌握推断由传感器得到的观测数据中表现的特征的能力的情形下,训练数据311可以由传感器得到的观测数据构成,正解数据312可以由表示该观测数据中表现的特征的数据构成。
[0207]
1-3.关于步骤s101
[0208]
在上述步骤s101中,控制部21获取由多个学习数据集310构成的局部学习数据301。生成各学习数据集310的方法也可以不特别限定,可以根据实施方式适当选择。例如,也可以通过实际或虚拟地创建执行规定的推论的各种状况,从而在所创建的各种状况中获取与对象数据(61、225)同种的数据作为训练数据311。作为具体例,在对象数据(61、225)的获取中利用传感器的情况下,准备与所利用的传感器同种的传感器,通过所准备的传感器观测执行规定的推论的各种状况,从而能够获取训练数据311。接着,对所获取的训练数据311执行规定的推论。在这种场景中,规定的推论可以由操作者等手动进行。然后,将对训练数据311执行规定的推论的结果(正解)与该训练数据311建立关联。由此,能够生成各学习数据集310。
[0209]
各学习数据集310可以通过计算机的动作自动生成,也可以通过操作者的操作手动生成。另外,各学习数据集310的生成可以由各局部学习装置2进行,也可以由各局部学习装置2以外的其他计算机进行。在由各局部学习装置2生成各学习数据集310的情况下,控制部21自动地或通过经由输入装置25的操作者的操作手动地执行上述一系列的生成处理,从而获取由多个学习数据集310构成的局部学习数据301。另一方面,在由其他计算机生成各学习数据集310的情况下,控制部21例如经由网络、存储介质92等获取由其他计算机生成的多个学习数据集310构成的局部学习数据301。也可以由各局部学习装置2生成一部分学习数据集310,由一个或多个其他计算机生成其他的学习数据集310。所获取的学习数据集310的份数也可以不特别限定,可以根据实施方式适当选择。
[0210]
1-4.关于步骤s102
[0211]
在上述步骤s102中,控制部21利用所获取的局部学习数据301执行机器学习模型401的机器学习(有监督学习)。在第一例中,控制部21通过机器学习训练机器学习模型401,使得对于各学习数据集310,当将训练数据311输入到输入层4011时,从输出层4014输出适合于正解数据312的输出值。由此,控制部21生成获得了执行规定的推论的能力的学习完毕的机器学习模型451。
[0212]
作为有监督学习的具体的处理过程的一例,控制部21首先准备成为机器学习的处理对象的机器学习模型401。所准备的机器学习模型401的结构(例如,层的数量、各层中包括的神经元的数量、相邻的层的神经元之间的连接关系等)及各运算参数的初始值(例如,各神经元间的连接的权重的初始值、各神经元的阈值的初始值等)可以通过模板提供,也可
以通过操作者的输入提供。另外,在进行重新学习的情况下,控制部21也可以基于通过过去的有监督学习得到的学习结果数据来准备机器学习模型401。
[0213]
接着,控制部21利用各学习数据集310中包括的训练数据311作为输入数据,利用正解数据312作为监督信号,执行构成机器学习模型401的神经网络的学习处理。该学习处理可以使用批量梯度下降法、随机梯度下降法、小批量梯度下降法等。
[0214]
例如,在第一步骤中,控制部21对于各学习数据集310,将训练数据311输入到机器学习模型401,执行机器学习模型401的运算处理。即,控制部21向输入层4011输入训练数据311,从输入侧开始依次进行各层4011~4014中包括的各神经元的点火判定。通过该运算处理,控制部21从输出层4014获取与训练中的机器学习模型401对训练数据311执行规定的推论的结果对应的输出值。
[0215]
在第二步骤中,控制部21基于损失函数计算从输出层4014获取到的输出值与正解数据312的误差。损失函数是评价机器学习模型401的输出与正解的差分的函数,从输出层4014获取到的输出值与正解数据312的差分值越大,通过损失函数计算的误差的值越大。该误差的计算中利用的损失函数的种类也可以不特别限定,可以根据实施方式适当选择。
[0216]
在第三步骤中,控制部21通过误差反向传播(back propagation)法,使用计算出的输出值的误差的梯度,计算各神经元间的连接的权重、各神经元的阈值等机器学习模型401的各运算参数的值的误差。在第四步骤中,控制部21基于计算出的各误差,进行机器学习模型401的各运算参数的值的更新。更新运算参数的值的程度可以通过学习率来调节。
[0217]
控制部21通过重复上述第一~第四步骤来调整机器学习模型401的各运算参数的值,使得对于各学习数据集310,当将训练数据311输入到输入层4011时,从输出层4014输出适合于对应的正解数据312的输出值。例如,控制部21也可以重复上述第一~第四步骤,直到对于各学习数据集310,从输出层4014得到的输出值与正解数据312的误差之和变为阈值以下为止。正解数据312的值与输出层4014的输出值适合也可以包括在正解数据312的值与输出层4014的输出值之间产生基于这样的阈值的误差。阈值可以根据实施方式适当设定。或者,控制部21也可以重复进行规定次数的上述第一~第四步骤。重复调整的次数例如可以通过学习程序821内的设定值指定,也可以通过操作者的输入指定。
[0218]
由此,控制部21能够生成被训练为对于训练数据311的输入、输出适合于对应的正解数据312的输出值的学习完毕的机器学习模型451。例如,在推断上述传感器的最佳观测方法的情形下,能够生成获得了推断从传感器的当前的观测状态变更为适当的观测状态的变更方法的能力的学习完毕的机器学习模型451。
[0219]
1-5.其他
[0220]
需要说明的是,在机器学习的方法采用有监督学习的情况下,机器学习模型40的构成也可以不限于神经网络,也可以采用神经网络以外的模型作为机器学习模型40。机器学习模型40例如可以由回归模型、支持向量机、决策树等构成。有监督学习的方法也可以不限于上述那样的例子,可以根据机器学习模型40的构成适当选择。
[0221]
2.第二例
[0222]
图7b示意性地示出机器学习模型40的构成及机器学习的方法的第二例。在第二例中,机器学习模型40采用生成模型,机器学习方法采用无监督学习。需要说明的是,在图7b中,为了便于说明,将局部学习数据30、机器学习模型40及学习完毕的机器学习模型45各自
的一例表述为局部学习数据302、机器学习模型402及学习完毕的机器学习模型452。
[0223]
2-1.机器学习模型的构成例
[0224]
在第二例中,机器学习模型402构成为根据噪声323生成伪数据325。机器学习模型402被用作生成模型。机器学习模型402的机器学习与其他机器学习模型412一起执行。其他机器学习模型412构成为识别所提供的输入数据的来源,即识别所提供的输入数据是局部学习数据302中包括的训练数据321还是由机器学习模型402生成的伪数据325。其他机器学习模型412被用作识别模型。
[0225]
在第二例中,在机器学习模型402与其他机器学习模型412之间实施对抗学习。机器学习模型402及其他机器学习模型412分别与机器学习模型401同样地具备运算参数。只要能够执行各个信息处理,机器学习模型402及其他机器学习模型412各自的构成就也可以不特别限定,可以根据实施方式适当确定。机器学习模型402及其他机器学习模型412可以分别由神经网络构成。另外,机器学习模型402及其他机器学习模型412可以分别构成为进一步接收表示条件的数据(可以称为标签)的输入。由此,能够限定条件来进行数据的生成及识别。
[0226]
2-2.局部学习数据的构成例
[0227]
对抗学习中利用的局部学习数据302由多份训练数据321构成。通过对抗学习,机器学习模型402获得生成适合(例如,类似)于局部学习数据302中包括的训练数据321的伪数据325的能力。因此,训练数据321由想要通过以对抗学习掌握的能力使机器学习模型402生成的数据构成。
[0228]
例如,在使机器学习模型402掌握预测移动体的移动路径(即,生成移动体的预测的移动路径)的能力的情形下,训练数据321可以由表示移动体实际或虚拟地移动的路径的数据构成。另外,例如在使机器学习模型402掌握推断适合于用户的会话策略的能力的情形下,训练数据321可以由表示在任意的用户间实际或虚拟地采用的会话策略的数据构成。在机器学习模型402及其他机器学习模型412分别构成为进一步接收表示条件的数据的输入的情况下,训练数据321也可以与表示条件的数据建立关联。
[0229]
2-3.关于步骤s101
[0230]
在上述步骤101中,控制部21获取由多份训练数据321构成的局部学习数据302。生成训练数据321的方法也可以不特别限定,可以根据实施方式适当选择。例如,与上述第一例同样地,通过实际或虚拟地创建想要生成数据的各种状况,能够获取表现出所创建的各种状况的数据作为训练数据321。所获取的训练数据321也可以与表示用于识别该状况的条件(例如,类别)的数据建立关联。
[0231]
训练数据321可以通过计算机的动作自动生成,也可以通过操作者的操作手动生成。另外,训练数据321的生成可以由各局部学习装置2进行,也可以由各局部学习装置2以外的其他计算机进行。在由各局部学习装置2生成训练数据321的情况下,控制部21自动地或通过经由输入装置25的操作者的操作手动地执行上述一系列的生成处理,从而获取由多份训练数据321构成的局部学习数据302。另一方面,在由其他计算机生成训练数据321的情况下,控制部21例如经由网络、存储介质92等获取由其他计算机生成的多份训练数据321构成的局部学习数据302。也可以由各局部学习装置2生成一部分训练数据321,由一个或多个其他计算机生成其他的训练数据321。所获取的训练数据321的份数也可以不特别限定,可
以根据实施方式适当选择。
[0232]
2-4.关于步骤s102
[0233]
在上述步骤s102中,控制部21利用所获取的局部学习数据302执行机器学习模型402及其他机器学习模型412的对抗学习。以下,对对抗学习的处理过程的一例进行说明。在以下处理过程中,为了便于说明,设想机器学习模型402及其他机器学习模型412分别由神经网络构成。不过,机器学习模型402及其他机器学习模型412的构成也可以不限于这样的例子。机器学习模型402及其他机器学习模型412中的至少一方可以由神经网络以外的模型构成。
[0234]
·
预处理
[0235]
作为预处理,控制部21准备成为处理对象的机器学习模型402及其他机器学习模型412。所准备的机器学习模型402及其他机器学习模型412各自的结构及各运算参数的初始值可以通过模板提供,也可以通过操作者的输入提供。另外,在进行重新学习的情况下,控制部21也可以基于通过过去的有监督学习得到的学习结果数据来准备机器学习模型402及其他机器学习模型412。
[0236]
·
识别模型的机器学习
[0237]
首先,控制部21在固定了机器学习模型402的运算参数的基础上,执行其他机器学习模型412的机器学习。即,控制部21从规定的概率分布(例如,高斯分布)中提取多个噪声323。接着,控制部21将所提取的各噪声323提供给机器学习模型402,执行机器学习模型402的运算处理。换言之,控制部21向机器学习模型402的输入层输入各噪声,从输入侧开始依次进行各层中包括的各神经元的点火判定。由此,控制部21获取根据噪声323生成的伪数据325作为来自机器学习模型402的输出层的输出。所生成的伪数据325的份数也可以不特别限定,可以根据实施方式适当选择。
[0238]
然后,控制部21利用局部学习数据302中包括的多份训练数据321及所生成的多份伪数据325,执行其他机器学习模型412的学习处理。在该学习处理中,训练其他机器学习模型412,以获得识别所提供的输入数据的来源,换言之,识别所提供的输入数据是训练数据321还是伪数据325的能力。该学习处理例如可以使用随机梯度下降法、小批量梯度下降法等。
[0239]
具体而言,控制部21将由机器学习模型402生成的伪数据325输入到其他机器学习模型412,执行其他机器学习模型412的运算处理。即,控制部21向其他机器学习模型412的输入层输入伪数据325,从输入侧开始依次进行各层中包括的各神经元的点火判定。由此,控制部21获取与其他机器学习模型412识别所提供的伪数据325的来源的结果对应的输出值,作为来自其他机器学习模型412的输出层的输出。
[0240]
在这种场景中,由于输入数据是伪数据325,因此其他机器学习模型412识别为“伪”是正解。控制部21对于由机器学习模型402生成的各份伪数据325,计算从输出层得到的输出值与该正解的误差。与上述第一例同样地,误差的计算可以使用损失函数。
[0241]
另外,控制部21将局部学习数据302中包括的训练数据321输入到其他机器学习模型412,执行其他机器学习模型412的运算处理。即,控制部21向其他机器学习模型412的输入层输入训练数据321,从输入侧开始依次进行各层中包括的各神经元的点火判定。由此,控制部21获取与其他机器学习模型412识别所提供的训练数据321的来源的结果对应的输
出值,作为来自其他机器学习模型412的输出层的输出。
[0242]
在这种场景中,由于输入数据是训练数据321,因此其他机器学习模型412识别为“真”是正解。控制部21对于局部学习数据302中包括的各份训练数据321,计算从输出层得到的输出值与该正解的误差。与上述同样地,误差的计算可以使用损失函数。
[0243]
控制部21与上述第一例同样地,通过误差反向传播法,使用计算出的输出值的误差的梯度,计算其他机器学习模型412的运算参数的值的误差。控制部21基于计算出的误差,进行其他机器学习模型412的运算参数的值的更新。更新运算参数的值的程度可以通过学习率来调节。
[0244]
控制部21分别从局部学习数据302中包括的多份训练数据321及由机器学习模型402生成的多份伪数据325中提取样本,并使用所提取的样本执行上述一系列的学习处理。由此,控制部21调整其他机器学习模型412的运算参数的值。重复该调整的次数可以适当设定。
[0245]
例如,控制部21与上述第一例同样地,也可以反复执行一系列的学习处理,直到计算出的输出值的误差之和变为阈值以下为止。或者,控制部21也可以将基于上述一系列的学习处理的运算参数的值的调整重复规定次数。在这种情况下,重复调整的次数例如可以通过学习程序821内的设定值指定,也可以通过操作者的输入指定。
[0246]
由此,控制部21能够针对局部学习数据302中包括的多份训练数据321及由机器学习模型402生成的多份伪数据325,构建获得了识别所提供的输入数据的来源的能力的其他机器学习模型412。
[0247]
·
生成模型的机器学习
[0248]
接着,控制部21在固定了其他机器学习模型412的运算参数的值的基础上,执行机器学习模型402的机器学习。即,控制部21利用上述训练完毕的其他机器学习模型412执行机器学习模型402的学习处理。在该学习处理中,控制部21训练机器学习模型402,以生成使其他机器学习模型412的识别性能降低那样的数据(伪数据325)。也就是说,控制部21训练机器学习模型402,以生成使其他机器学习模型412误识别为“真”(即、来源于局部学习数据302)那样的数据。
[0249]
具体而言,首先,与上述同样地,控制部21从规定的概率分布中提取多个噪声323。接着,控制部21将所提取的各噪声323提供给机器学习模型402,执行机器学习模型402的运算处理。换言之,控制部21向机器学习模型402的输入层输入各噪声,从输入侧开始依次进行各层中包括的各神经元的点火判定。由此,控制部21获取根据噪声323生成的伪数据325,作为来自机器学习模型402的输出层的输出。所生成的伪数据325的份数也可以不特别限定,可以根据实施方式适当选择。需要说明的是,在机器学习模型402的学习处理中,同样可以利用其他机器学习模型412的机器学习时生成的伪数据325。在这种情况下,在机器学习模型402的学习处理中,可以省略生成伪数据325的一系列处理。
[0250]
接着,控制部21将所生成的各伪数据325提供给其他机器学习模型412,执行其他机器学习模型412的运算处理。换言之,控制部21向其他机器学习模型412的输入层输入各伪数据325,从输入侧开始依次进行各层中包括的各神经元的点火判定。由此,控制部21获取与其他机器学习模型412识别所提供的伪数据325的来源的结果对应的输出值,作为来自其他机器学习模型412的输出层的输出。
[0251]
在这种场景中,其他机器学习模型412将输入数据误识别为“真”是正解。控制部21对于由机器学习模型402生成的各份伪数据325,计算从其他机器学习模型412的输出层得到的输出值与该正解的误差。由此,控制部21计算该输出值的误差,以使其他机器学习模型412的识别性能降低。与上述同样地,误差的计算可以使用损失函数。
[0252]
控制部21通过误差反向传播法,将计算出的输出值的误差的梯度经由其他机器学习模型412反向传播给机器学习模型402的运算参数,计算机器学习模型402的运算参数的值的误差。控制部21基于计算出的误差,进行机器学习模型402的运算参数的值的更新。与上述同样地,更新运算参数的值的程度可以通过学习率来调节。
[0253]
控制部21通过反复执行上述一系列的学习处理,来调整机器学习模型402的运算参数的值。重复该调整的次数可以适当设定。与上述同样地,控制部21可以重复执行上述一系列的学习处理,直到计算出的输出值的误差之和变为阈值以下为止,或者也可以将基于上述一系列的学习处理的运算参数的值的调整重复规定次数。由此,控制部21能够训练机器学习模型402,以生成使上述训练完毕的其他机器学习模型412的识别性能降低那样的数据。
[0254]
·
各学习处理的反复执行
[0255]
控制部21交替地反复执行上述其他机器学习模型412的学习处理及机器学习模型402的学习处理。交替地反复执行的次数可以适当设定。交替地反复执行的次数例如可以通过学习程序821内的设定值指定,也可以通过操作者的输入指定。需要说明的是,在表示条件的数据与训练数据321建立关联的情况下,在上述各学习处理中,可以分别进一步向机器学习模型402及其他机器学习模型412输入表示条件的数据。
[0256]
由此,能够交替地提高其他机器学习模型412及机器学习模型402的精度。其结果,机器学习模型402获得生成适合于局部学习数据302中包括的训练数据321的伪数据325的能力。换言之,控制部21能够生成获得了生成适合于局部学习数据302中包括的训练数据321的伪数据325的能力的学习完毕的机器学习模型452。例如,在预测移动体的移动路径的情形下,能够生成获得了生成表示移动体的预测的移动路径的数据的能力的学习完毕的机器学习模型452。
[0257]
2-5.其他
[0258]
需要说明的是,在机器学习的方法采用无监督学习的情况下,机器学习模型40的构成也可以不限于上述生成模型,也可以采用生成模型以外的模型作为机器学习模型40。机器学习的方法可以采用聚类等。另外,机器学习模型40可以由单类支持向量机、自组织映射、其他识别模型等构成。
[0259]
3.第三例
[0260]
图7c示意性地示出机器学习模型40的构成及机器学习的方法的第三例。在第三例中,机器学习方法采用强化学习。需要说明的是,在图7c中,为了便于说明,将局部学习数据30、机器学习模型40及学习完毕的机器学习模型45各自的一例表述为局部学习数据303、机器学习模型403及学习完毕的机器学习模型453。
[0261]
3-1.机器学习模型的构成例
[0262]
在第三例中,机器学习模型403可以采用基于价值、基于策略或这两者。在采用基于价值的情况下,机器学习模型403例如可以由状态价值函数、行动价值函数(q函数)等价
值函数构成。状态价值函数构成为输出所提供的状态的价值。行动价值函数构成为对所提供的状态输出各行动的价值。在采用基于策略的情况下,机器学习模型403例如可以由策略函数构成。策略函数构成为对所提供的状态输出选择各行动的概率。在采用两者的情况下,机器学习模型403例如可以由价值函数(critic)及策略函数(actor)构成。各函数例如可以通过数据表、函数式等来表现。在由函数式表现的情况下,各函数可以由神经网络、线性函数、决策树等构成。
[0263]
3-2.局部学习数据的构成例
[0264]
在强化学习中,基本上,假定通过按照策略进行行动而与学习的环境相互作用的智能体(agent)。智能体的实体例如是cpu。机器学习模型403通过上述构成作为确定行动的策略进行动作。智能体在所提供的学习的环境内观测与强化的行动相关的状态。
[0265]
成为观测对象的状态及执行的行动可以根据使机器学习模型403掌握的推论的内容适当设定。例如,在推断传感器的最佳观测方法的情形下,成为观测对象的状态可以是传感器的观测状态,执行的行动可以是传感器的观测状态的变更。另外,例如在预测移动体的移动路径的情形下,成为观测对象的状态可以是与移动体的移动路径相关的状态,执行的行动可以是移动体的移动。另外,例如在推断适合于用户的会话策略的情形下,成为观测对象的状态可以是与用户的会话行动相关的状态,执行的行动可以是与用户的会话。另外,例如在推断适合于任务的机器人装置的动作指令的情形下,成为观测对象的状态可以是与机器人装置的内部及外部中的至少一方的状况相关的状态,执行的行动可以是基于动作指令的动作。学习的环境可以手动或自动地适当创建。
[0266]
智能体通过机器学习模型403对观测的当前的状态(输入数据)执行规定的推论,并基于所得到的推论的结果确定采用的行动。或者,采用的行动也可以随机确定。当执行所确定的行动时,观测的状态迁移到下一状态。根据情况,智能体能够根据学习的环境得到立即报酬。
[0267]
一边反复进行该行动的确定及执行的试行错误,智能体一边更新机器学习模型403,以使立即报酬的总和(即,价值)最大化。由此,最佳行动、即可期待获取高价值的行动被强化,能够得到使这样的行动的选择成为可能的策略(学习完毕的机器学习模型453)。
[0268]
因此,在强化学习中,局部学习数据303由状态迁移数据构成,该状态迁移数据是通过该试行错误而得到的状态迁移数据,表示通过所执行的行动从当前的状态向下一状态迁移,并根据情况得到立即报酬的状态迁移。一份状态迁移数据可以由表示一个回合全部的状态迁移的轨迹的数据构成,或者也可以由表示规定次数(一次以上)的状态迁移的数据构成。
[0269]
另外,根据状态迁移计算立即报酬可以使用报酬函数。报酬函数可以通过数据表、函数式或规则来表现。在通过函数式来表现的情况下,报酬函数可以由神经网络、线性函数、决策树等构成。报酬函数也可以根据使机器学习模型403掌握的推论的内容,由操作者等手动设定。
[0270]
或者,报酬函数可以设定为根据机器学习模型403的推论结果(即,所确定的行动)的适当度来提供立即报酬。推论结果的适当度也可以像五级、十级等这样由规定数量的等级来表现。或者,推论结果的适当度也可以通过连续值来表现。另外,推论结果的适当度也可以由操作者等手动提供。或者,推论结果的适当度可以使用判定器48按照规定的基准进
行评价。规定的基准可以根据推论的内容适当设定。判定器48可以适当构成为按照规定的基准评价推论结果的适当度。
[0271]
作为具体例,在实施产品的图像检查的情形下,设想通过强化学习使机器学习模型403掌握推断最适合于产品的缺陷检测的照相机的观测方法的能力的场景。推断该照相机的最佳观测方法的场景是推断传感器的最佳观测方法的场景的一例。作为强化学习的环境,可以准备分别包括不同的缺陷的多个产品,创建由照相机拍摄所准备的各产品的环境。
[0272]
在这种情况下,规定的基准可以是关于能否根据由照相机得到的图像数据检测产品的缺陷的基准。与此相应地,判定器48可以由构成为根据图像数据检测产品的缺陷的检测器构成。检测器可以构成为通过边缘检测等图像处理来检测缺陷,也可以由神经网络等学习完毕的机器学习模型构成。
[0273]
此时,报酬函数可以设定为根据检测器对缺陷的检测精度来计算立即报酬。作为一例,也可以多次试行检测器对由照相机得到的图像数据的缺陷检测。报酬函数可以设定为基于该多次缺陷检测的试行结果,如果缺陷检测的成功概率为阈值以上,则提供正的立即报酬,如果不能检测出缺陷,则提供负的立即报酬(惩罚)。需要说明的是,试行次数及成为提供正的立即报酬的基准的阈值可以分别通过程序内的设定值提供,也可以由操作者等手动提供。
[0274]
在其他情形下也同样地,可以根据推论结果的适当度来设定报酬。例如,在预测移动体的移动路径的情形下,也可以多次试行移动体的移动路径的预测。报酬函数可以设定为基于该多次预测的试行结果,如果预测的精度为阈值以上,则提供正的立即报酬,如果预测精度为容许值以下,则提供负的立即报酬(惩罚)。同样地,在推断适合于用户的会话策略的情形下,可以多次试行适合于用户的会话策略的推断。报酬函数也可以设定为基于该多次推断的试行结果,如果推断的精度为阈值以上,则提供正的立即报酬,如果推断精度为容许值以下,则提供负的立即报酬(惩罚)。在推断适合于任务的机器人装置的动作指令的情形下,也可以同样地设定报酬函数。需要说明的是,评价适当度的方法也可以不限于基于上述推论结果的精度的方法。例如,在推断传感器的最佳观测方法的场景中,设想为观测同一对象而传感器的测量所花费的时间越短越好。与此相应地,报酬函数也可以设定为传感器的测量所花费的时间越长,越提供负的立即报酬,传感器的测量所花费的时间越短,越提供正的立即报酬。如此,报酬函数可以设定为越能够得到所希望的结果,提供越高的立即报酬,否则提供越低的立即报酬或者负的立即报酬。
[0275]
或者,报酬函数可以根据由专家得到的事例数据通过逆强化学习来推断。事例数据由表示专家的演示(的轨迹)的数据构成。在推断传感器的最佳观测方法的场景中,事例数据例如可以由表示通过熟练者的操作而得到的传感器的变更方法的数据构成。在预测移动体的移动路径的场景中,事例数据例如可以由表示移动体实际移动的路径的数据构成。在推断适合于用户的会话策略的场景中,事例数据例如可以由表示通过熟练者所指定的会话策略的数据构成。在推断适合于任务的机器人装置的动作指令的场景中,可以由表示熟练者对机器人装置的操作轨迹的数据构成。生成事例数据的方法也可以不特别限定,可以根据实施方式适当选择。事例数据例如可以通过由传感器等记录专家的演示轨迹来生成。
[0276]
逆强化学习的方法可以不特别限定,可以根据实施方式适当选择。逆强化学习例如可以使用基于最大熵原理的方法、基于相对熵的最小化的方法、利用对抗生成网络的方
法(例如,justin fu,et al.,“learning robust rewards with adversarial inverse reinforcement learning”,arxiv:1710.11248,2018)等。在通过逆强化学习得到报酬函数的情况下,局部学习数据303可以进一步具备逆强化学习中利用的事例数据。
[0277]
3-3.关于步骤s101及步骤s102
[0278]
在上述步骤s101中,控制部21也可以利用训练中的学习完毕的机器学习模型403,通过执行上述试行错误来获取上述状态迁移数据。或者,状态迁移数据也可以由其他计算机生成。在这种情况下,在上述步骤s101中,控制部21也可以经由网络、存储介质92等获取由其他计算机生成的状态迁移数据。
[0279]
在上述步骤s102中,控制部21基于所得到的状态迁移数据更新机器学习模型403的运算参数的值,以使价值最大化。调整机器学习模型403的运算参数的值的方法可以根据机器学习模型403的构成适当选择。例如,在机器学习模型403由神经网络构成的情况下,机器学习模型403的运算参数的值可以通过误差反向传播法等以与上述第一例及第二例同样的方法来调整。
[0280]
控制部21重复步骤s101及步骤s102的处理,调整机器学习模型403的运算参数的值,以使得到的价值(的期望值)最大化(例如,直到更新量变为阈值以下为止)。即,训练机器学习模型403包括反复进行构成机器学习模型403的运算参数的值的修正,以得到多的报酬,直到满足规定的条件为止。由此,控制部21能够生成获得了执行规定的推论(在第三例中,确定能够期待获取高价值的行动)的能力的学习完毕的机器学习模型453。例如,在推断上述传感器的最佳观测方法的情形下,能够生成获得了推断从传感器的当前的观测状态变更为适当的观测状态的变更方法的能力的学习完毕的机器学习模型453。
[0281]
在机器学习模型403由基于价值构成的情况下,上述强化学习的方法可以使用td(temporal difference:时序差分)法、td(λ)法、蒙特卡洛法、动态规划法等。试行错误中的行动的确定可以是同策略,也可以是异策略。作为具体例,强化学习的方法可以使用q学习、sarsa等。在试行错误时,也可以以概率ε采用随机的行动(ε-贪婪法)。
[0282]
另外,在机器学习模型403由基于策略构成的情况下,上述强化学习的方法可以使用策略梯度法等。在这种情况下,控制部21在所得到的价值增加的方向上计算策略函数的运算参数的梯度,并基于计算出的梯度来更新策略函数的运算参数的值。策略函数的梯度的计算例如可以使用reinforce算法等。
[0283]
另外,在机器学习模型403由两者构成的情况下,上述强化学习的方法可以使用actor critic法等。
[0284]
进而,在实施逆强化学习的情况下,在执行上述强化学习的处理之前,控制部21在上述步骤s101中进一步获取事例数据。事例数据可以由各局部学习装置2生成,也可以由其他计算机生成。在由其他计算机生成的情况下,控制部21也可以经由网络、存储介质92等获取由其他计算机生成的事例数据。接着,控制部21利用所获取的事例数据,通过执行逆强化学习来设定报酬函数。然后,控制部21利用通过逆强化学习设定的报酬函数,执行上述强化学习的处理。由此,控制部21利用通过逆强化学习设定的报酬函数,能够生成获得了执行规定的推论的能力的学习完毕的机器学习模型453。
[0285]
4.总结
[0286]
在本实施方式中,机器学习模型40的构成可以采用上述三个构成中的至少任一
者。控制部21通过采用上述三个机器学习的方法中的至少任一者,能够生成获得了执行规定的推论的能力(训练为能够执行规定的推论)的学习完毕的机器学习模型45。当生成了学习完毕的机器学习模型45时,控制部21使处理进入下一步骤s103。
[0287]
(步骤s103)
[0288]
在步骤s103中,控制部21作为环境数据获取部212进行动作,获取与得到局部学习数据30的环境相关的学习环境数据35。与得到局部学习数据30的环境相关的属性可以包括与规定的推论直接或间接地关联的对象物或用户的属性等可能与推论关联的所有现象。学习环境数据35是与由推论装置1得到的环境数据63同种的数据。
[0289]
学习环境数据35的内容也可以不特别限定,可以根据在推论装置1的整合处理中考虑的环境的内容适当选择。例如,在推断传感器的最佳观测方法的情形下,学习环境数据35中可以包括与对传感器的观测产生影响的环境属性(例如,明亮度、温度等)相关的信息。另外,例如在推断适合于用户的会话策略的情形下,学习环境数据35中可以包括与用户的属性(例如,年龄、性别、职业、出生地、性格类型等)相关的信息。
[0290]
另外,获取学习环境数据35的方法也可以不特别限定,可以根据实施方式适当选择。例如,也可以经由输入装置25,通过用户等操作者的输入获取学习环境数据35。另外,例如学习环境数据35的获取中也可以利用传感器。
[0291]
在学习环境数据35的获取中利用传感器的情况下,学习环境数据35可以是由传感器得到的观测数据本身,也可以是通过对观测数据执行某信息处理(例如,特征提取)而得到的数据。作为对观测数据执行信息处理的场景的一例,在推断适合于用户的会话策略的情形下,设想获取与用户的性别相关的信息作为学习环境数据35的场景。在这种情况下,控制部21也可以利用照相机作为用于获取学习环境数据35的传感器,来获取拍到用户的脸的图像数据。然后,控制部21也可以对所得到的图像数据执行根据脸来推断性别的图像处理。控制部21也可以基于该推断处理的结果,获取与用户的性别相关的信息。
[0292]
另外,获取学习环境数据35的路径也可以不特别限定,可以根据实施方式适当选择。控制部21也可以经由外部接口24、输入装置25等直接获取学习环境数据35。或者,控制部21也可以经由网络、存储介质92等间接获取学习环境数据35。
[0293]
当获取到学习环境数据35时,控制部21使处理进入下一步骤s104。需要说明的是,执行步骤s103的处理的时机也可以不限于这样的例子。步骤s103的处理可以在执行下一步骤s104的处理之前的任意的时机执行。
[0294]
(步骤s104)
[0295]
控制部21作为保存处理部214进行动作,生成与所生成的学习完毕的机器学习模型45相关的信息作为学习结果数据47。在图7a~图7c的例子中,控制部21生成与所生成的学习完毕的机器学习模型451~453相关的信息作为学习结果数据47。与学习完毕的机器学习模型45相关的信息例如可以包括表示学习完毕的机器学习模型45的结构的信息、以及表示通过机器学习调整后的运算参数的值的信息。然后,控制部21将所生成的学习结果数据47与学习环境数据35建立关联地保存在规定的存储区域中。
[0296]
规定的存储区域例如可以是控制部21内的ram、存储部22、外部存储装置、存储媒体或它们的组合。存储媒体例如可以是cd、dvd等,控制部21也可以经由驱动器27在存储媒体中保存学习结果数据47。外部存储装置例如可以是nas(network attached storage:网
络附加存储)等数据服务器。在这种情况下,控制部21也可以利用通信接口23,经由网络将学习结果数据47保存在数据服务器中。另外,外部存储装置例如也可以是与各局部学习装置2连接的外置的存储装置。
[0297]
由此,当学习结果数据47的保存完成时,控制部21结束与学习完毕的机器学习模型45的生成相关的一系列信息处理。
[0298]
需要说明的是,学习结果数据47及学习环境数据35可以在任意的时机提供给推论装置1。例如,控制部21也可以作为步骤s104的处理或者与步骤s104的处理分开地另行将学习结果数据47及学习环境数据35转发给推论装置1。推论装置1的控制部11也可以通过接收该转发来获取学习结果数据47及学习环境数据35。另外,例如控制部11也可以利用通信接口13而经由网络访问各局部学习装置2或数据服务器,来获取学习结果数据47及学习环境数据35。另外,例如控制部11也可以经由存储介质91来获取学习结果数据47及学习环境数据35。另外,例如学习结果数据47及学习环境数据35也可以预先嵌入在推论装置1中。
[0299]
进而,控制部21也可以通过定期地重复上述步骤s101~步骤s104的处理,来定期地更新或新生成学习结果数据47及学习环境数据35。在该重复时,可以适当执行局部学习数据30中包括的数据的变更、修正、追加、删除等。然后,控制部21也可以通过在每次执行学习处理时对推论装置1提供更新的或新生成的学习结果数据47及学习环境数据35,来定期地更新推论装置1保持的学习结果数据47及学习环境数据35。
[0300]
(b)推论处理
[0301]
接着,使用图8对与各局部学习装置2的规定的推论相关的动作例进行说明。图8是示出与各局部学习装置2的规定的推论相关的处理过程的一例的流程图。不过,以下说明的各处理过程只不过是一例而已,各步骤可以尽可能地变更。进而,对于以下说明的各处理过程,可以根据实施方式适当地进行步骤的省略、替换及追加。
[0302]
(步骤s111)
[0303]
在步骤s111中,控制部21作为对象数据获取部216进行动作,获取成为规定的推论的对象的对象数据225。对象数据225是与由推论装置1得到的对象数据61同种的数据。
[0304]
对象数据225的内容也可以不特别限定,可以根据规定的推论的内容适当选择。例如,在推断传感器的最佳观测方法的情形下,对象数据225可以包括表示与传感器的设置状况相关的属性(例如,传感器的设置角度、传感器与观测对象之间的距离等)的信息,作为与传感器的当前的观测状态相关的信息。另外,例如在推断适合于用户的会话策略的情形下,对象数据225可以包括与通过输入设备(例如,键盘、触摸面板)、照相机、麦克风等得到的用户的会话行动相关的数据。在学习完毕的机器学习模型45由生成模型构成的情况下,对象数据225可以包括从规定的概率分布中提取出的噪声。
[0305]
另外,获取对象数据225的方法也可以不特别限定,可以根据实施方式适当选择。例如,也可以经由输入装置25,通过用户等操作者的输入获取对象数据225。另外,例如在对象数据225的获取中也可以利用传感器。
[0306]
在对象数据225的获取中利用传感器的情况下,对象数据225与学习环境数据35同样地,可以是由传感器得到的观测数据本身,也可以是通过对观测数据执行某信息处理而得到的数据。作为对观测数据执行信息处理的场景的一例,在推断适合于用户的会话策略的情形下,设想获取用户的说话内容的字符串作为对象数据225的场景。在这种情况下,控
制部21也可以利用麦克风作为用于获取对象数据225的传感器,来获取包括用户的说话语音的声音数据。然后,控制部21也可以对所得到的声音数据执行语音分析。控制部21也可以基于该语音分析处理的结果,来获取用户的说话内容的字符串。
[0307]
进而,在学习环境数据35及对象数据225各自的获取中利用传感器的情况下,学习环境数据35及对象数据225可以来源于由同一传感器得到的同一观测数据,也可以来源于由不同的传感器得到的不同的观测数据。作为来源于同一观测数据的场景的一例,在上述推断适合于用户的会话策略的情形下,设想利用摄像机的场景。在这种情况下,控制部21也可以通过根据由摄像机得到的图像数据推断用户的性别,来获取与所推断的用户的性别相关的信息作为学习环境数据35。另外,控制部21也可以通过根据由摄像机得到的声音数据分析用户的说话内容的字符串,来获取所得到的用户的说话内容的字符串作为对象数据225。
[0308]
另外,获取对象数据225的路径也可以不特别限定,可以根据实施方式适当选择。控制部21也可以经由外部接口24、输入装置25等直接获取对象数据225。或者,控制部21也可以经由网络、存储介质92等间接获取对象数据225。
[0309]
当获取到对象数据225时,控制部21使处理进入下一步骤s112。
[0310]
(步骤s112)
[0311]
在步骤s112中,控制部21作为推论部217进行动作,利用根据局部学习数据30导出的推论模型,对所获取的对象数据225执行规定的推论。在本实施方式中,控制部21通过保持学习结果数据47,从而具备学习完毕的机器学习模型45作为推论模型。控制部21参照学习结果数据47进行学习完毕的机器学习模型45的设定。接着,控制部21对学习完毕的机器学习模型45提供对象数据225,执行学习完毕的机器学习模型45的运算处理。
[0312]
运算处理可以根据学习完毕的机器学习模型45的构成适当执行。在学习完毕的机器学习模型45由函数式构成的情况下,控制部21将对象数据225代入函数式,执行该函数式的运算处理。在学习完毕的机器学习模型45由神经网络构成的情况下,控制部21将对象数据225输入到输入层,从输入侧开始依次进行各层中包括的各神经元的点火判定。在学习完毕的机器学习模型45由数据表构成的情况下,控制部21将对象数据225与数据表进行对照。
[0313]
由此,控制部21获取对对象数据225执行规定的推论的结果,作为学习完毕的机器学习模型45的输出(即,运算处理的执行结果)。所得到的推论结果依赖于使学习完毕的机器学习模型45掌握的能力。例如,在使学习完毕的机器学习模型45掌握推断传感器的最佳观测方法的能力的情形下,控制部21能够获取根据传感器的当前的观测状态推断的变更为传感器的适当的观测状态的变更方法相关的信息作为推断处理的结果。当获取到推论结果时,控制部21使处理进入下一步骤s113。
[0314]
(步骤s113)
[0315]
在步骤s113中,控制部21作为输出部218进行动作,输出与对对象数据225的推论结果相关的信息。
[0316]
输出目的地及输出的信息的内容可以分别根据实施方式适当确定。例如,控制部21也可以将通过步骤s112对对象数据225执行规定的推论的结果直接输出到输出装置26。另外,例如控制部21也可以基于执行规定的推论的结果来执行某信息处理。然后,控制部21也可以将执行该信息处理的结果作为与推论结果相关的信息输出。执行该信息处理的结果
的输出可以包括根据推论结果输出特定的消息、根据推论结果控制控制对象装置的动作、等等。输出目的地例如可以是输出装置26、其他计算机的输出装置、控制对象装置等。
[0317]
当与推论结果相关的信息的输出完成时,控制部21结束与规定的推论相关的一系列的信息处理。需要说明的是,在规定的期间内,控制部21也可以继续重复执行步骤s111~步骤s113的一系列信息处理。重复的时机可以是任意的。由此,各局部学习装置2也可以继续实施规定的推论。
[0318]
[推论装置]
[0319]
接着,使用图9a对与推论装置1的规定的推论相关的动作例进行说明。图9a是示出与推论装置1的规定的推论相关的处理过程的一例的流程图。以下说明的处理过程是本发明的“推论方法”的一例。不过,以下说明的各处理过程只不过是一例而已,各步骤可以尽可能地变更。进而,关于以下说明的各处理过程,可以根据实施方式适当地进行步骤的省略、替换及追加。
[0320]
(步骤s201及步骤s202)
[0321]
在步骤s201中,控制部11作为第一数据获取部111进行动作,获取成为规定的推论的对象的规定的对象数据61。除了处理环境不同这一点之外,步骤s201的获取对象数据61的处理可以与上述步骤s111的获取对象数据225的处理是同样的。
[0322]
即,对象数据61的内容可以根据规定的推论的内容适当选择。获取对象数据61的方法及路径可以分别根据实施方式适当选择。对象数据61也可以通过经由输入装置15的操作者的输入来获取。对象数据61的获取中也可以利用与对象数据225的获取中利用的传感器同种的传感器。在对象数据61的获取中利用传感器的情况下,对象数据61可以是由传感器得到的观测数据本身,也可以是通过对观测数据执行某信息处理而得到的数据。控制部11可以经由外部接口14、输入装置15等直接获取对象数据61,或者也可以经由网络、存储介质91等间接获取对象数据61。
[0323]
在步骤s202中,控制部11作为第二数据获取部112进行动作,获取与执行规定的推论的对象环境相关的环境数据63。除了处理环境不同这一点之外,步骤s202的获取环境数据63的处理可以与上述步骤s103的获取学习环境数据35的处理是同样的。
[0324]
即,环境数据63的内容可以根据整合处理中考虑的环境的内容适当选择。获取环境数据63的方法及路径可以分别根据实施方式适当选择。环境数据63也可以通过经由输入装置15的操作者的输入来获取。环境数据63的获取中也可以利用与学习环境数据35的获取中利用的传感器同种的传感器。在环境数据63的获取中利用传感器的情况下,环境数据63可以是由传感器得到的观测数据本身,也可以是通过对观测数据执行某信息处理而得到的数据。在对象数据61及环境数据63的获取中利用传感器的情况下,对象数据61及环境数据63可以来源于由同一传感器得到的同一观测数据,也可以来源于由不同的传感器得到的不同的观测数据。控制部11可以经由外部接口14、输入装置15等直接获取环境数据63,或者也可以经由网络、存储介质91等间接获取环境数据63。
[0325]
需要说明的是,环境数据63是关于获取对象数据61的对象环境而获取的,与此相对,学习环境数据35是关于得到局部学习数据30的环境而获取的。在局部学习数据30中蓄积有与对象数据61同种的数据(例如,上述训练数据311)。因此,学习环境数据35与环境数据63相比,例如关于时间、场所、对象物、用户等环境的属性,也可以具有扩展。与此相应地,
环境数据63的数据形式和学习环境数据35的数据形式在能够比较各自的环境的方式下也可以不同。
[0326]
由此,控制部11获取对象数据61及环境数据63。需要说明的是,步骤s201及步骤s202的处理顺序可以是任意的。可以先执行步骤s201及步骤s202中的任一者,也可以并行地执行步骤s201及步骤s202的处理。当获取到对象数据61及环境数据63时,控制部11使处理进入下一步骤s203。
[0327]
(步骤s203)
[0328]
在步骤s203中,控制部11作为结果获取部113进行动作,对根据在不同环境下得到的局部学习数据30而被导出以执行规定的推论的多个推论模型分别提供对象数据61,使各推论模型执行对对象数据61的规定的推论。由此,控制部11获取各推论模型对所获取的对象数据61的推论结果。
[0329]
在本实施方式中,各推论模型由通过上述各局部学习装置2生成的各学习完毕的机器学习模型45构成。另外,在本实施方式中,推论装置1通过保持由各局部学习装置2生成的各份学习结果数据47,从而具备各学习完毕的机器学习模型45。因此,控制部11通过参照各份学习结果数据47来进行各学习完毕的机器学习模型45的设定。接着,控制部11对各学习完毕的机器学习模型45提供对象数据61,执行各学习完毕的机器学习模型45的运算处理。各学习完毕的机器学习模型45的运算处理可以与上述步骤s112中的学习完毕的机器学习模型45的运算处理是同样的。由此,控制部11能够获取各学习完毕的机器学习模型45对对象数据61的推论结果,作为各学习完毕的机器学习模型45的输出。需要说明的是,推论处理中使用的学习完毕的机器学习模型45可以通过操作者的指定等适当选择。当获取到各学习完毕的机器学习模型45对对象数据61的推论结果时,控制部11使处理进入下一步骤s204。
[0330]
(步骤s204)
[0331]
在步骤s204中,控制部11作为整合部114进行动作,按照整合规则5整合在步骤s203中得到的各推论模型的推论结果。在本实施方式中,控制部11按照整合规则5整合各学习完毕的机器学习模型45的推论结果。由此,控制部11生成在对象环境下对对象数据61的推论结果。
[0332]
在本实施方式中,控制部11通过保持整合规则数据57,从而具有与整合规则5相关的信息。整合规则5具备在对象环境下分别规定重视各学习完毕的机器学习模型45的推论结果的程度的多个整合参数p。控制部11通过参照整合规则数据57来进行整合规则5的设定。然后,控制部11通过以下处理,按照整合规则5整合各学习完毕的机器学习模型45的推论结果。
[0333]
图9b是示出与步骤s204的整合处理相关的子例程的处理过程的一例的流程图。本实施方式所涉及的步骤s204的处理包括以下步骤s211~步骤s213的处理。不过,以下说明的处理过程只不过是一例而已,各处理可以尽可能地变更。另外,对于以下说明的处理过程,可以根据实施方式适当地进行步骤的省略、替换及追加。
[0334]
在步骤s211中,控制部11根据所获取的环境数据63确定各整合参数p的值。确定各整合参数p的值的方法的详细情况将在后面叙述。需要说明的是,在各整合参数p的值的确定中,除了考虑环境数据63之外,可以进一步考虑对象数据61。即,控制部11也可以根据对
象数据61及环境数据63来确定各整合参数p的值。
[0335]
在步骤s212中,控制部11使用所确定的各整合参数p的值,对对应的各推论模型的推论结果进行加权。在步骤s213中,控制部11整合各推论模型的加权后的推论结果。在本实施方式中,控制部11使用所确定的各整合参数p的值,对对应的各学习完毕的机器学习模型45的推论结果进行加权。然后,控制部11整合各学习完毕的机器学习模型45的加权后的推论结果。
[0336]
加权及整合的方法只要是根据加权而使推论结果优先的方式即可,也可以不特别限定,可以根据实施方式适当设定。例如,整合各学习完毕的机器学习模型45的推论结果的加权后的推论结果可以是计算表示各学习完毕的机器学习模型45的推论结果的值的加权平均。另外,例如整合各学习完毕的机器学习模型45的推论结果的加权后的推论结果可以是在加权的基础上进行多数表决来选择各学习完毕的机器学习模型45的推论结果中的任一者。在规定的推论是回归的情况下,推论结果的整合可以主要通过上述加权平均来进行。另外,在规定的推论是识别的情况下,推论结果的整合可以主要通过上述加权多数表决来进行。
[0337]
当步骤s213的整合完成时,控制部11结束与步骤s204的整合处理相关的子例程的处理。由此,控制部11能够生成在对象环境下对对象数据61的推论结果。当通过该整合处理生成了推论结果时,控制部11使处理进入下一步骤s205。
[0338]
(步骤s205)
[0339]
返回到图9a,在步骤s205中,控制部11作为输出部115进行动作,输出与所生成的推论结果相关的信息。除了处理环境不同这一点之外,步骤s205的输出处理可以与上述步骤s113的输出处理是同样的。
[0340]
即,输出目的地及输出的信息的内容可以分别根据实施方式适当确定。例如,控制部11也可以将通过步骤s204生成的推论结果直接输出到输出装置16。另外,例如控制部11也可以基于所生成的推论结果执行某信息处理。然后,控制部11也可以将执行该信息处理的结果作为与推论结果相关的信息输出。执行该信息处理的结果的输出可以包括根据推论结果输出特定的消息、根据推论结果控制控制对象装置的动作、等等。输出目的地例如可以是输出装置16、其他计算机的输出装置、控制对象装置等。
[0341]
当与推论结果相关的信息的输出完成时,控制部11结束与规定的推论相关的一系列的信息处理。需要说明的是,在规定的期间内,控制部11也可以继续重复执行步骤s201~步骤s205的一系列信息处理。重复的时机可以是任意的。由此,推论装置1也可以继续实施规定的推论。
[0342]
《整合参数的值的确定方法》
[0343]
接着,对上述步骤s211中确定各整合参数p的值的方法的具体例进行说明。在本实施方式中,控制部11能够通过以下三种方法中的至少任一种方法来确定各整合参数p的值。
[0344]
(1)第一方法
[0345]
图10a示意性地举例示出通过第一方法确定各整合参数p的值的场景的一例。在第一方法中,控制部11利用用于根据环境数据63(及对象数据61)计算各整合参数p的值的运算模型。
[0346]
(1-1)确定整合参数的值的处理
[0347]
在本实施方式中,控制部11利用学习数据59执行运算模型51的机器学习。运算模型51与上述机器学习模型40同样地,例如可以通过数据表、函数式等来表现。通过机器学习,控制部11构建(生成)被训练为使得计算出的各整合参数p的值适合于对象环境下的规定的推论的学习完毕的运算模型52。在第一方法中,整合规则5进一步具备通过该机器学习构建的学习完毕的运算模型52。与所构建的学习完毕的运算模型52相关的信息可以作为整合规则数据57的至少一部分保存,也可以与整合规则数据57分开保存。
[0348]
在上述步骤s211中,控制部11通过适当参照该信息来进行学习完毕的运算模型52的设定。然后,控制部11对学习完毕的运算模型52提供环境数据63,执行学习完毕的运算模型52的运算处理。在进一步考虑对象数据61的情况下,控制部11对学习完毕的运算模型52进一步提供对象数据61,执行学习完毕的运算模型52的运算处理。学习完毕的运算模型52的运算处理可以与上述学习完毕的机器学习模型45的运算处理是同样的。由此,控制部11能够获取针对各推论模型的各整合参数p的值,作为学习完毕的运算模型52的输出。在本实施方式中,在获取各整合参数p的值之后,控制部11通过执行步骤s212及其之后的处理,来整合各学习完毕的机器学习模型45的推论结果。
[0349]
(1-2)运算模型的机器学习
[0350]
接着,进一步使用图10b对与学习完毕的运算模型52的生成相关的推论装置1的动作例进行说明。图10b是示出与推论装置1生成学习完毕的运算模型52相关的处理过程的一例的流程图。不过,以下说明的各处理过程只不过是一例而已,各步骤可以尽可能地变更。进而,对于以下说明的各处理过程,可以根据实施方式适当地进行步骤的省略、替换及追加。
[0351]
(步骤s301及步骤s302)
[0352]
在步骤s301中,控制部11作为学习数据获取部116进行动作,获取运算模型51的机器学习中利用的学习数据59。在步骤s302中,控制部11作为学习处理部117进行动作,利用所获取的学习数据59执行运算模型51的机器学习。
[0353]
步骤s302中的机器学习通过训练运算模型51以使计算出的各整合参数p的值适合于对象环境下的规定的推论而构成。该运算模型51的机器学习可以是调整运算模型51的运算参数的值,以得到适合于对象环境的希望的输出。即,训练运算模型51以使计算出的各整合参数p的值适合于对象环境下的规定的推论可以是,调整运算模型51的运算参数的值,使得根据环境数据(及对象数据)计算通过上述步骤s212及步骤s213的处理而使用计算出的各整合参数p的值对各推论模型(各机器学习模型45)的推论结果进行整合的结果适合于对象环境下的推论结果那样的各整合参数p的值。通过该机器学习,控制部11能够生成获得了根据环境数据(及对象数据)推断适合于对象环境下的规定的推论的各整合参数p的值的能力的学习完毕的运算模型52。
[0354]
运算模型51的构成及机器学习的方法也可以分别不特别限定,可以根据实施方式适当确定。学习完毕的运算模型52用于计算各整合参数p的值。计算出的各整合参数p的值用于在上述整合处理时对各推论模型的推论结果进行加权。在推论装置1中,通过上述整合处理生成推论结果。另一方面,学习完毕的机器学习模型45直接导出对对象数据的推论结果。因此,运算模型51(学习完毕的运算模型52)在处理的数据及得到推论结果的过程这一点上与上述机器学习模型40(学习完毕的机器学习模型45)不同。不过,关于这些以外的点,
运算模型51的构成及机器学习的方法可以与上述机器学习模型40是同样的。
[0355]
运算模型51例如可以通过数据表、函数式等来表现。在运算模型51通过函数式来表现的情况下,运算模型51例如可以由神经网络、线性函数、决策树等构成。神经网络的种类也可以不特别限定,可以根据实施方式适当确定。构成运算模型51的神经网络例如可以使用全连接型神经网络、卷积神经网络、递归型神经网络、它们的组合等。以下,对运算模型51的构成及机器学习的方法各自的两个例子进行说明。
[0356]
i.第一例
[0357]
图10c示意性地示出运算模型51的构成及机器学习的方法的第一例。在第一例中,与上述机器学习模型40的第一例同样地,运算模型51采用神经网络,机器学习方法采用有监督学习。需要说明的是,在图10c中,为了便于说明,将学习数据59、运算模型51及学习完毕的运算模型52各自的一例表述为学习数据591、运算模型511及学习完毕的运算模型521。
[0358]
i-1.运算模型的构成例
[0359]
在第一例中,运算模型511由三层结构的全连接型神经网络构成。具体而言,运算模型511从输入侧开始依次具备输入层5111、中间(隐藏)层5112及输出层5113。不过,运算模型511的构成与上述机器学习模型401同样地,也可以不限于这样的例子,可以根据实施方式适当确定。例如,运算模型511所具备的中间层的数量也可以是两个以上。或者,中间层5112也可以省略。另外,运算模型511也可以具备卷积层、池化层、递归层等其他种类的层。关于其他方面,运算模型511可以与上述机器学习模型401是同样的。运算模型511具备各层5111~5113中包括的各神经元间的连接的权重、各神经元的阈值等运算参数。
[0360]
i-2.学习数据的构成例
[0361]
该运算模型511的有监督学习中利用的学习数据591由分别包括训练用环境数据5911、训练用对象数据5912及正解数据5913(监督信号)的组合的多个学习数据集5910构成。训练用环境数据5911是与环境数据63同种的数据,被用作训练数据(输入数据)。训练用对象数据5912是与对象数据61同种的数据。在进一步考虑对象数据61的情况下,训练用对象数据5912可以与训练用环境数据5911一起被用作训练数据(输入数据)。正解数据5913是表示在对象环境下对训练用对象数据5912执行规定的推论的结果(正解)的数据。正解数据5913也可以称为标签。
[0362]
训练用环境数据5911的内容可以根据整合处理中考虑的环境的内容适当选择。除了获取用于训练这一点之外,训练用环境数据5911可以与上述环境数据63是同样的。训练用对象数据5912及正解数据5913的内容可以根据使各推论模型(学习完毕的机器学习模型45)掌握的推论的内容适当选择。除了获取用于训练这一点之外,训练用对象数据5912可以与上述对象数据61是同样的。另外,除了考虑推论装置1执行规定的推论的对象环境而获取这一点之外,训练用对象数据5912及正解数据5913可以与上述训练数据311及正解数据312是同样的。
[0363]
i-3.关于步骤s301
[0364]
在上述步骤s301中,控制部11获取由多个学习数据集5910构成的学习数据591。生成各学习数据集5910的方法也可以不特别限定,可以根据实施方式适当选择。例如,也可以通过实际或虚拟地创建在对象环境下执行规定的推论的各种状况,从而在所创建的各种状况中获取与环境数据63同种的数据作为训练用环境数据5911。另外,也可以与训练用环境
数据5911一起获取与对象数据61同种的数据作为训练用对象数据5912。然后,在对象环境下对所获取的训练用对象数据5912执行规定的推论。在这种场景中,规定的推论可以由操作者等手动进行。然后,将对训练用对象数据5912执行规定的推论的结果(正解)与训练用环境数据5911及训练用对象数据5912建立关联。由此,能够生成各学习数据集5910。
[0365]
i-4.关于步骤s302
[0366]
在上述步骤s302中,控制部11利用所获取的学习数据591执行运算模型511的机器学习(有监督学习)。在第一例中,控制部11通过机器学习训练运算模型511,使得对于各学习数据591,通过将训练用环境数据5911(及训练用对象数据5912)输入到输入层5111,从而从输出层5113输出使得使用所输出的各整合参数p的值整合各推论模型(学习完毕的机器学习模型45)对训练用对象数据5912的推论结果的结果适合于正解数据5913那样的各整合参数p的值。由此,控制部11生成获得了根据环境数据(及对象数据)推断适合于对象环境下的规定的推论的各整合参数p的值的能力的学习完毕的运算模型521。
[0367]
有监督学习的具体的处理过程可以与上述机器学习模型401是同样的。控制部11首先准备成为机器学习的处理对象的运算模型511。所准备的运算模型511的结构及各运算参数的初始值可以通过模板提供,也可以通过操作者的输入提供。另外,在进行重新学习的情况下,控制部11也可以基于通过过去的有监督学习得到的学习结果数据来准备运算模型511。
[0368]
接着,控制部11将各学习数据集5910中包括的训练用环境数据5911用作输入数据,将正解数据5913用作监督信号,执行构成运算模型511的神经网络的学习处理。在该学习处理中,可以进一步将训练用对象数据5912用作输入数据。基本上,运算模型511的学习处理可以与上述机器学习模型401是同样的。
[0369]
在第一步骤中,控制部11对于各学习数据集5910,将训练用环境数据5911输入到运算模型511的输入层5111。在进一步考虑对象数据61的情况下,控制部11也可以进一步将训练用对象数据5912输入到运算模型511的输入层5111。接着,控制部11从输入侧开始依次进行各层5111~5113中包括的各神经元的点火判定。通过该运算处理,控制部11从输出层5113获取与训练中的运算模型511根据训练用环境数据5911(及训练用对象数据5912)计算各整合参数p的值的结果对应的输出值。
[0370]
在第二步骤中,控制部11对对应的训练用对象数据5912执行上述步骤s203的处理。即,控制部11对各推论模型提供对应的训练用对象数据5912,使各推论模型对训练用对象数据5912执行规定的推论。由此,控制部11获取各推论模型对训练用对象数据5912的推论结果。在本实施方式中,控制部11获取各学习完毕的机器学习模型45对训练用对象数据5912的推论结果。
[0371]
接着,控制部11利用通过第一步骤得到的各整合参数p的值,对所得到的各学习完毕的机器学习模型45的推论结果执行上述步骤s204的处理。即,控制部11使用通过第一步骤得到的各整合参数p的值,对各学习完毕的机器学习模型45的推论结果进行加权。然后,控制部11整合各学习完毕的机器学习模型45的加权后的推论结果。由此,控制部11生成对象环境下的推论结果。然后,控制部11计算所生成的推论结果与正解数据5913的误差。误差的计算可以适当使用损失函数。
[0372]
在第三步骤中,控制部11通过误差反向传播法,使运算模型511反向传播所计算出
的误差的梯度,来计算各神经元间的连接的权重、各神经元的阈值等运算模型511的各运算参数的值的误差。在第四步骤中,控制部11基于计算出的各误差,进行运算模型511的各运算参数的值的更新。更新运算参数的值的程度可以通过学习率来调节。
[0373]
控制部11通过重复上述第一~第四步骤来调整运算模型511的各运算参数的值,使得对于各学习数据集5910,通过将训练用环境数据5911(及训练用对象数据5912)输入到输入层5111,从而从输出层5113输出使得使用所输出的各整合参数p的值整合各推论模型(学习完毕的机器学习模型45)对训练用对象数据5912的推论结果的结果适合于正解数据5913那样的各整合参数p的值。例如,控制部11也可以重复上述第一~第四步骤,直到对于各学习数据集5910,所生成的推论结果的误差之和变为阈值以下为止。或者,控制部11也可以重复执行规定次数的上述第一~第四步骤。由此,控制部11能够生成获得了根据环境数据(及对象数据)推断适合于对象环境下的规定的推论的各整合参数p的值的能力的学习完毕的运算模型521。
[0374]
i-5.其他
[0375]
需要说明的是,在机器学习的方法采用有监督学习的情况下,运算模型511的构成也可以不限于神经网络,也可以采用神经网络以外的模型作为运算模型511。运算模型511例如可以由回归模型、支持向量机、决策树等构成。有监督学习的方法也可以不限于上述那样的例子,可以根据运算模型511的构成适当选择。
[0376]
ii.第二例
[0377]
图10d示意性地示出运算模型51的构成及机器学习的方法的第三例。在第二例中,与上述机器学习模型40的第三例同样地,机器学习方法采用强化学习。需要说明的是,在图10d中,为了便于说明,将学习数据59、运算模型51及学习完毕的运算模型52各自的一例表述为学习数据592、运算模型512及学习完毕的运算模型522。
[0378]
ii-1.运算模型的构成例
[0379]
运算模型512可以与上述机器学习模型403同样地构成。即,运算模型512可以采用基于价值、基于策略或这两者。各函数例如可以通过数据表、函数式等来表现。在通过函数式来表现的情况下,各函数可以由神经网络、线性函数及决策树等构成。
[0380]
ii-2.学习数据的构成例
[0381]
除了所处理的数据及导出对象的环境下的推论结果的过程不同这一点之外,运算模型512的强化学习的方法可以与上述机器学习模型403是同样的。学习的环境可以手动或自动地适当创建。在运算模型512的强化学习中,智能体观测的状态与环境数据63及对象数据61对应。
[0382]
智能体利用运算模型512,根据观测到的当前的状态(输入数据)计算各整合参数p的值。另外,与上述步骤s203同样地,智能体将所观测到的当前的状态中包括的对象数据提供给各推论模型,使各推论模型执行对对象数据的规定的推论。由此,智能体获取各推论模型对对象数据的推论结果。在本实施方式中,智能体获取各学习完毕的机器学习模型45对对象数据的推论结果。接着,智能体使用由运算模型512得到的各整合参数p的值,对各学习完毕的机器学习模型45的推论结果进行加权。然后,智能体整合各学习完毕的机器学习模型45的加权后的推论结果。由此,智能体生成对象环境下的推论结果。
[0383]
智能体基于所生成的推论结果确定采用的行动。或者,采用的行动也可以随机确
定。当执行所确定的行动时,观测的状态迁移到下一状态。根据情况,智能体能够根据学习的环境得到立即报酬。一边反复进行该行动的确定及执行的试行错误,智能体一边更新运算模型512,以使立即报酬的总和最大化。由此,最佳行动被强化,能够得到计算使这样的行动的选择成为可能的各整合参数p的值的策略(学习完毕的运算模型522)。
[0384]
因此,在第二例中,学习数据592由状态迁移数据构成,该状态迁移数据是通过该试行错误得到的状态迁移数据,表示通过所执行的行动从当前的状态向下一状态迁移,并根据情况得到立即报酬的状态迁移。与上述局部学习数据303同样地,一份状态迁移数据可以由表示一个回合全部的状态迁移的轨迹的数据构成,或者也可以由表示规定次数(一次以上)的状态迁移的数据构成。
[0385]
需要说明的是,与上述机器学习模型403的强化学习同样地,在运算模型512的强化学习中,可以使用用于计算立即报酬的报酬函数。报酬函数可以通过数据表、函数式或规则来表现。在通过函数式来表现的情况下,报酬函数可以由神经网络、线性函数、决策树等构成。报酬函数也可以根据通过上述一系列的处理执行的规定的推论的内容,由操作者等手动设定。
[0386]
或者,报酬函数也可以设定为根据通过上述一系列的处理生成的推论结果的适当度来提供立即报酬。推论结果的适当度也可以像五级、十级等这样由规定数量的等级来表现。或者,推论结果的适当度也可以通过连续值来表现。另外,推论结果的适当度也可以由操作者等手动提供。或者,推论结果的适当度可以使用判定器49按照规定的基准进行评价。规定的基准可以与上述机器学习模型403是同样的。另外,判定器49可以与上述机器学习模型403的强化学习中的判定器48是同样的。
[0387]
或者,报酬函数可以根据由专家得到的事例数据通过逆强化学习来推断。事例数据的内容、生成事例数据的方法及逆强化学习的方法也可以分别不特别限定,可以与在上述机器学习模型403的强化学习中的报酬函数的设定中利用的事例数据是同样的。在通过逆强化学习得到报酬函数的情况下,学习数据592可以进一步具备在逆强化学习中利用的事例数据。
[0388]
ii-3.步骤s301及步骤s302
[0389]
在上述步骤s301中,控制部11也可以利用训练中的运算模型512,通过执行上述试行错误,来获取上述状态迁移数据。或者,状态迁移数据也可以由其他计算机生成。在这种情况下,在上述步骤s301中,控制部11也可以经由网络、存储介质91等获取由其他计算机生成的状态迁移数据。
[0390]
在上述步骤s302中,控制部11基于所得到的状态迁移数据来更新运算模型512的运算参数的值,以使价值最大化。调整运算模型512的运算参数的值的方法可以根据运算模型512的构成适当选择。例如,在运算模型512由神经网络构成的情况下,运算模型512的运算参数的值可以通过误差反向传播法等以与上述第一例同样的方法进行调整。
[0391]
控制部11重复步骤s301及步骤s302的处理,调整运算模型512的运算参数的值,以使得到的价值(的期望值)最大化(例如,直到更新量变为阈值以下为止)。即,训练运算模型512包括反复进行构成运算模型512的运算参数的值的修正,以得到多的报酬,直到满足规定的条件为止。由此,控制部11能够生成获得了根据环境数据(及对象数据)推断适合于对象环境下的规定的推论的各整合参数p的值的能力的学习完毕的运算模型522。需要说明的
是,强化学习的方法可以与上述机器学习模型403是同样的。
[0392]
进而,在实施逆强化学习的情况下,在执行上述强化学习的处理之前,控制部11在上述步骤s301中进一步获取事例数据。事例数据可以由推论装置1生成,也可以由其他计算机生成。在由其他计算机生成的情况下,控制部11也可以经由网络、存储介质91等获取由其他计算机生成的事例数据。接着,控制部11利用所获取的事例数据,通过执行逆强化学习设定报酬函数。然后,控制部11利用通过逆强化学习设定的报酬函数,执行上述强化学习的处理。由此,控制部11利用通过逆强化学习设定的报酬函数,能够生成获得了根据环境数据(及对象数据)推断适合于对象环境下的规定的推论的各整合参数p的值的能力的学习完毕的运算模型522。
[0393]
iii.总结
[0394]
在本实施方式中,运算模型51的构成可以采用上述两个构成中的至少任一者。控制部11通过采用上述两个机器学习的方法中的至少任一者,能够生成学习完毕的运算模型52。当运算模型51的机器学习完成并生成学习完毕的运算模型52时,控制部11使处理进入下一步骤s303。
[0395]
(步骤s303)
[0396]
返回到图10b,在步骤s303中,控制部11作为保存处理部118进行动作,生成运算模型51的机器学习的结果、即与学习完毕的运算模型52相关的信息。在图10c及图10d的例子中,控制部11生成与学习完毕的运算模型(521、522)相关的信息。控制部11将所生成的与学习完毕的运算模型52相关的信息保存在规定的存储区域中。
[0397]
规定的存储区域例如可以是控制部11内的ram、存储部12、外部存储装置、存储媒体或它们的组合。存储媒体例如可以是cd、dvd等,控制部11也可以经由驱动器17在存储媒体中保存与学习完毕的运算模型52相关的信息。外部存储装置例如可以是nas等数据服务器。在这种情况下,控制部11也可以利用通信接口13,经由网络在数据服务器中保存与学习完毕的运算模型52相关的信息。另外,外部存储装置例如也可以是与推论装置1连接的外置的存储装置。
[0398]
所生成的与学习完毕的运算模型52相关的信息可以作为整合规则数据57的至少一部分保存,也可以与整合规则数据57分开保存。由此,当与学习完毕的运算模型52相关的信息的保存完成时,控制部11结束与学习完毕的运算模型52的生成相关的一系列信息处理。
[0399]
需要说明的是,控制部11也可以通过定期地重复上述步骤s301~步骤s303的处理,来定期地更新或新生成学习完毕的运算模型52。在该重复时,可以适当执行学习数据59中包括的数据的变更、修正、追加、删除等。然后,控制部11也可以将更新后的或新生成的学习完毕的运算模型52用于以后的推论处理。
[0400]
在第一方法中,通过机器学习,构建被训练为使得计算出的各整合参数p的值适合于对象环境下的规定的推论的学习完毕的运算模型52。因此,通过使用由所构建的学习完毕的运算模型52计算出的各整合参数p的值,能够以适合于对象环境的方式适当地整合各学习完毕的机器学习模型45的推论结果。因此,根据第一方法,能够在对象环境下更适当地执行规定的推论。
[0401]
需要说明的是,机器学习模型40(学习完毕的机器学习模型45)的参数数量依赖于
对象数据(61、225)的维数及推论结果的表现形式。因此,对象数据(61、225)及推论内容中的至少一方越复杂,机器学习模型40的参数数量越增加。与此相对,运算模型51(学习完毕的运算模型52)的参数数量依赖于环境数据63的维数及在对象环境下用于规定的推论的学习完毕的机器学习模型45的数量。由于运算模型51的信息处理只不过是确定各整合参数p的值而已,因此即使对象数据(61、225)及推论内容变得复杂,也能够抑制运算模型51的参数数量的增加。
[0402]
例如,设想考虑明亮度作为对象环境,并根据由该照相机得到的图像数据推断照相机的最佳观测方法的场景。在这种情况下,对象数据(61、225)是图像数据。机器学习模型40的参数数量依赖于图像数据的像素数量及照相机可采取的状态数量,可能是过千的量级。另一方面,运算模型51的参数数量依赖于明亮度的维数及学习完毕的机器学习模型45的数量,但即使最佳观测方法的推断中利用几十个学习完毕的机器学习模型45,也最多是几十~几百程度的量级。
[0403]
因此,一般而言,确定整合参数p的值的运算模型51的参数数量比直接执行规定的推论的机器学习模型40的参数数量少就可以了。例如,在运算模型51及机器学习模型40分别采用神经网络,并采用有监督学习作为机器学习的方法的情况下,运算模型51的神经网络的规模可以比机器学习模型40的神经网络小。另外,例如在采用强化学习作为机器学习的方法的情况下,与训练机器学习模型40的场景相比,训练运算模型51的场景中,规定学习的环境的参数的数量更少就可以了。由于机器学习的成本依赖于参数数量,因此通过机器学习构建学习完毕的运算模型52的成本能够抑制得比构建适合于对象环境的新的学习完毕的机器学习模型45的成本低。因此,根据第一方法,能够在抑制构建在新的环境中能够适当地执行规定的推论的推论模型所花费的成本的同时实现规定的推论的精度提高。
[0404]
(2)第二方法
[0405]
图11a示意性地举例示出通过第二方法确定各整合参数p的值的场景的一例。在第二方法中,控制部11基于执行规定的推论的对象环境与得到在各推论模型的导出中利用的局部学习数据30的学习环境的比较,来确定各整合参数p的值。具体而言,控制部11计算环境数据63与各份学习环境数据35的适合度,根据计算出的适合度来确定针对对应的各推论模型的整合参数p的值。
[0406]
图11b是示出通过第二方法确定各整合参数p的值的子例程的处理过程的一例的流程图。在采用第二方法的情况下,上述步骤s211包括以下步骤s311~步骤s313的处理。不过,以下说明的处理过程只不过是一例而已,各处理可以尽可能地变更。另外,对于以下说明的处理过程,可以根据实施方式适当地进行步骤的省略、替换及追加。
[0407]
在步骤s311中,控制部11获取与得到在各推论模型的导出中利用的局部学习数据30的环境相关的学习环境数据35。如上所述,在本实施方式中,各学习完毕的机器学习模型45的学习环境数据35可以在任意的时机从各局部学习装置2提供给推论装置1。控制部11可以适当地获取各份学习环境数据35。当获取到各份学习环境数据35时,控制部11使处理进入下一步骤s312。
[0408]
在步骤s312中,控制部11计算各份学习环境数据35和环境数据63的适合度。只要能够根据计算出的适合度评价对象环境与学习环境是否类似,则适合度的形式也可以不特别限定,可以根据实施方式适当确定。例如,控制部11也可以计算学习环境数据35和环境数
据63的一致度作为适合度。另外,例如控制部11也可以计算学习环境数据35与环境数据63之间的距离(范数),并根据计算出的距离计算适合度。在这种情况下,控制部11也可以计算出的距离越大,将适合度计算为越小的值,计算出的距离越小,将适合度计算为越大的值。距离与适合度之间的对应关系可以通过数据表、函数式或规则等来表现。该对应关系可以由操作者等手动设定,或者,例如也可以通过拟合等公知的方法自动导出。或者,控制部11也可以将计算出的距离的倒数作为适合度进行计算。适合度可以用规定数量的等级来表现,或者也可以通过连续值来表现。当计算出各适合度时,控制部11使处理进入下一步骤s313。
[0409]
在步骤s313中,控制部11根据计算出的各适合度,来确定针对对应的各推论模型的各整合参数p的值。设想根据从与对象环境类似的学习环境得到的局部学习数据30导出的推论模型的推论结果即使在该对象环境中可靠性也较高。相反,设想根据从与对象环境大不相同的学习环境得到的局部学习数据30导出的推论模型的推论结果在该对象环境中可靠性较低。因此,控制部11也可以适合度越大,将整合参数p的值计算为越大的值,适合度越小,将整合参数p的值计算为越小的值。适合度与整合参数p的值的对应关系可以通过数据表、函数式或规则等来表现。该对应关系可以由操作者等手动设定,或者,例如也可以通过拟合等公知的方法自动导出。或者,控制部11也可以将计算出的各适合度直接用作各整合参数p的值。
[0410]
由此,控制部11能够根据计算出的适合度来确定针对各推论模型的各整合参数p的值。控制部11可以将表示确定各整合参数p的值的结果的信息作为整合规则数据57的至少一部分保存,也可以与整合规则数据57分开保存。当确定了各整合参数p的值时,控制部11结束与步骤s211相关的子例程的处理。在本实施方式中,在确定各整合参数p的值之后,控制部11通过执行步骤s212及其之后的处理,来整合各学习完毕的机器学习模型45的推论结果。
[0411]
与第一方法不同,在第二方法中,能够省略生成学习完毕的运算模型52的麻烦。另外,能够通过对象环境与学习环境的比较这样的简单的处理来适当地确定各整合参数p的值。因此,根据第二方法,能够通过简单的方法降低构建在新的环境中能够适当地执行规定的推论的推论模型花费的成本。
[0412]
(3)第三方法
[0413]
图12a示意性地举例示出通过第三方法确定各整合参数p的值的场景的一例。在第三方法中,控制部11接收操作者经由输入装置15对整合参数p的值的指定,并将对象的整合参数p的值设定为指定的值。图12a示意性地举例示出用于接收该整合参数p的值的指定的接收画面的一例。
[0414]
图12b是示出通过第三方法设定整合参数p的值的子例程的处理过程的一例的流程图。控制部11作为参数设定部119进行动作,执行以下步骤s321~步骤s323的处理。不过,以下说明的处理过程只不过是一例而已,各处理可以尽可能地变更。另外,对于以下说明的处理过程,可以根据实施方式适当地进行步骤的省略、替换及追加。
[0415]
在步骤s321中,控制部11输出用于接收针对推论模型的整合参数p的值的输入的接收画面。在步骤s322中,控制部11经由接收画面接收多个整合参数p中的至少一个整合参数p的值的指定。
[0416]
在本实施方式中,控制部11将图12a中例示的接收画面输出到输出装置16。接收画面的输出目的地也可以不限于输出装置16。接收画面例如可以输出到其他计算机的输出装置。图12a中例示的接收画面具备显示栏161、选择栏162、输入栏163及确定按钮165。
[0417]
在显示栏161中显示各推论模型的信息。例如,也可以在显示栏161中显示学习环境数据35的内容。另外,例如在已计算出上述适合度的情况下,也可以在显示栏161中显示计算出的适合度。在选择栏162中接收是否在推论处理中使用的选择。在本实施方式中,控制部11根据选择栏162的选择,来确定推论处理中使用的学习完毕的机器学习模型45。
[0418]
在输入栏163中接收针对对象的推论模型的整合参数p的值的指定。操作者操作输入装置15,通过在对象的推论模型的输入栏163中输入希望的值,能够指定对应的整合参数p的值。整合参数p的值可以由规定数量的等级来指定,也可以通过连续值来指定。需要说明的是,通过在输入栏163中输入无效值(例如,0),可以指定不使用对象的推论模型。在这种情况下,选择栏162可以省略。
[0419]
确定按钮165用于结束整合参数p的值的指定。在整合参数p的值的指定完成之后,操作者操作输入装置15来操作确定按钮165。控制部11根据该确定按钮165的操作,结束步骤s322的处理,使处理进入下一步骤s323。
[0420]
在步骤s323中,控制部11将对象的整合参数p的值设定为指定的值。控制部11可以将与指定的设定内容相关的信息作为整合规则数据57的至少一部分保存,也可以与整合规则数据57分开保存。当对象的整合参数p的值的设定完成时,控制部11结束与整合参数p的值的设定相关的子例程的处理。在本实施方式中,在设定整合参数p的值之后,控制部11通过执行步骤s212及其之后的处理,来整合各学习完毕的机器学习模型45的推论结果。在上述步骤s212中,控制部11使用上述设定的值,对与对象的整合参数p对应的学习完毕的机器学习模型45的推论结果进行加权。
[0421]
根据第三方法,能够通过操作者的指定来确定应用于各学习完毕的机器学习模型45的推论结果的各整合参数p的值中的至少一部分。因此,能够在对象环境下执行的规定的推论中反映操作者的意图(例如,重视特定的学习完毕的机器学习模型45的推论结果)。
[0422]
(4)总结
[0423]
在本实施方式中,控制部11通过采用上述三种方法中的至少任一种,能够在步骤s211中确定各整合参数p的值。上述三种方法可以适当采用。例如,控制部11也可以在通过第一方法或第二方法确定各整合参数p的值之后,通过第三方法修正多个整合参数p中的至少任一者的值。
[0424]
《推论模型的分组》
[0425]
接着,使用图13a对各推论模型的分组进行说明。图13a示意性地举例示出对各推论模型进行分组的场景的一例。在本实施方式中,作为推论模型的一例的学习完毕的机器学习模型45由各个局部学习装置2生成。因此,多个学习完毕的机器学习模型45中的一个学习完毕的机器学习模型45与其他学习完毕的机器学习模型45有可能因完全不同的目的而被生成以实施不同的推论。在这种情况下,难以整合一个学习完毕的机器学习模型45的推论结果与其他学习完毕的机器学习模型45的推论结果。
[0426]
因此,在本实施方式中,控制部11也可以作为分组部1110进行动作,将各推论模型(在本实施方式中为各学习完毕的机器学习模型45)分配给多个组中的至少任一个组。各组
可以根据推论的种类、目的、对象环境等适当设定。图13a示意性地举例示出将各学习完毕的机器学习模型45分配给a组及b组这两个组的场景的一例。控制部11将针对该各学习完毕的机器学习模型45的组的分配结果保存在分配信息125中。分配信息125例如可以保存在规定的存储区域中。规定的存储区域可以是控制部11内的ram、存储部12、外部存储装置、存储媒体或它们的组合。
[0427]
与此相应地,对每个组准备整合规则5。在上述步骤s203中,控制部11也可以确定所设定的多个组中在对象环境中利用的组,对于属于所确定的组的学习完毕的机器学习模型45,执行获取上述推论结果的处理。然后,在上述步骤s204中,控制部11也可以按照对应的整合规则5,整合属于所确定的组的学习完毕的机器学习模型45的推论结果。由此,能够根据目的按每个组执行整合处理。
[0428]
需要说明的是,分组的方法也可以不特别限定,可以根据实施方式适当确定。在本实施方式中,控制部11能够通过以下两种方法中的任一种方法,将各推论模型分配给多个组中的至少任一个组。
[0429]
(1)第一分组方法
[0430]
首先,使用图13b对第一分组方法的一例进行说明。图13b是示出与通过第一分组方法对各推论模型进行组的分配相关的处理过程的一例的流程图。在第一分组方法中,控制部11通过从组的列表中选择希望的组,来将各推论模型分配给多个组中的至少任一个组。
[0431]
需要说明的是,在采用第一分组方法作为将各推论模型分配给组的方法的情况下,将各推论模型分配给多个组中的至少任一个组由以下步骤s411及步骤s412的处理构成。不过,以下说明的处理过程只不过是一例而已,各处理可以尽可能地变更。另外,对于以下说明的处理过程,可以根据实施方式适当地进行步骤的省略、替换及追加。
[0432]
在步骤s411中,控制部11从示出多个组的列表中接收对各推论模型分配的一个以上的组的选择。例如,控制部11也可以将示出多个组的列表输出到输出装置16。与此相应地,操作者也可以操作输入装置15,从列表中选择对各推论模型分配的一个以上的组。由此,能够从示出多个组的列表中接收对各推论模型分配的一个以上的组的选择。
[0433]
需要说明的是,组的选择也可以不通过推论装置1实施。例如,组的选择也可以通过各局部学习装置2实施。作为具体例,控制部11也可以将示出多个组的列表分发给各局部学习装置2。由此,控制部11可以使各局部学习装置2从列表所示的多个组中选择一个以上的组。
[0434]
另外,列表中包括的各组可以根据局部学习数据30、局部学习装置2、局部学习装置2的利用者等的属性来设定。例如,在推断传感器的最佳观测方法的情形下,设想为了监视工厂的生产线的状态而利用传感器的场景。在这种情况下,也可以根据生产线编号、工厂名、企业名等属性来设定组。可以根据操作者的操作或来自各局部学习装置2的请求,将新的组追加到列表中。
[0435]
在步骤s412中,控制部11基于步骤s411的回答,将各推论模型分配到所选择的一个以上的组。当一个以上的组的分配完成时,控制部11结束与通过第一分组方法进行组的分配相关的一系列处理。根据该第一分组方法,控制部11能够通过简单的方法对各推论模型进行分组。
[0436]
(2)第二分组方法
[0437]
接着,使用图13c对第二分组方法的一例进行说明。图13c是示出与通过第二分组方法对各推论模型进行组的分配相关的处理过程的一例的流程图。在第二分组方法中,控制部11根据局部学习数据30的属性,将各推论模型分配给适当的组。
[0438]
需要说明的是,在采用第二分组方法作为将各推论模型分配给组的方法的情况下,将各推论模型分配给多个组中的至少任一个组由以下步骤s421~步骤s423的处理构成。不过,以下说明的处理过程只不过是一例而已,各处理可以尽可能地变更。另外,对于以下说明的处理过程,可以根据实施方式适当地进行步骤的省略、替换及追加。
[0439]
(步骤s421)
[0440]
在步骤s421中,控制部11从各局部学习装置2中获取与局部学习数据30相关的属性数据。获取属性数据的方法可以与获取上述学习环境数据35的方法是同样的。控制部11可以从各局部学习装置2中适当获取属性数据。
[0441]
属性数据也可以包括与局部学习数据30相关的所有信息。属性数据例如也可以包括表示局部学习数据30中包括的数据的类别的信息、表示数据中表现出的特征的信息、表示数据的利用目的的信息等。另外,属性数据也可以包括学习环境数据35。属性数据可以在通过上述步骤s101获取局部学习数据30时以及通过步骤s103获取学习环境数据35时中的至少任一者时生成。当获取到属性数据时,控制部11使处理进入下一步骤s422。
[0442]
(步骤s422及步骤s423)
[0443]
在步骤s422中,控制部11对从各局部学习装置2中获取到的属性数据进行聚类。聚类的方法也可以不特别限定,可以根据实施方式适当选择。聚类可以采用k均值法(k-means聚类)等公知的方法。
[0444]
在步骤s423中,控制部11基于聚类的结果,将各推论模型分配给多个组中的至少任一个组。作为一例,控制部11将所获取的属性数据被分配到同一类的推论模型分配给同一组。在这种情况下,各组可以根据属性数据的类来设定。另外,控制部11也可以基于聚类的结果,将各推论模型分配给两个以上的组。
[0445]
当基于聚类的结果的组的分配完成时,控制部11结束与通过第二分组方法进行的组的分配相关的一系列处理。根据该第二分组方法,控制部11能够根据局部学习数据30的属性,将各推论模型分配给适当的组。
[0446]
通过采用以上两种方法中的至少任一种方法,控制部11能够对各推论模型适当地进行分组。不过,分组的方法也可以不限于这些例子,可以根据实施方式适当确定。
[0447]
[特征]
[0448]
如上所述,本实施方式所涉及的推论装置1为了在对象环境下执行规定的推论,不是构建新的推论模型,而是在上述步骤s203及步骤s204的处理中灵活应用已经构建的多个学习完毕的机器学习模型45。在上述步骤s211~步骤s213的整合处理中,本实施方式所涉及的推论装置1根据环境数据63所示的对象环境,来调整重视各学习完毕的机器学习模型45的推论的程度。由此,本实施方式所涉及的推论装置1能够将在各种环境下得到的与规定的推论相关的见解定制为适合于新的环境。其结果,能够基于定制后的见解,换言之,基于整合各学习完毕的机器学习模型45的加权后的推论结果的结果而在对象环境下适当地执行规定的推论。
[0449]
因此,根据本实施方式,通过灵活应用根据在不同的环境下得到的局部学习数据30而分别导出的多个学习完毕的机器学习模型45,能够构建在对象环境下能够适当地执行规定的推论的新的推论模型。因此,能够省略在对象环境下收集新的学习数据并根据所收集的新的学习数据导出新的推论模型、特别是生成新的学习完毕的机器学习模型的作业的麻烦。因此,根据本实施方式,能够降低构建在新的环境中能够适当地执行规定的推论的推论模型花费的成本。
[0450]
§
4变形例
[0451]
以上,对本发明的实施方式进行了详细说明,至此为止的说明在所有方面只不过是本发明的例示而已。当然可以在不脱离本发明的范围的情况下进行各种改良或变形。例如,可以进行如下的变更。需要说明的是,以下,关于与上述实施方式同样的构成要素使用相同的附图标记,至于与上述实施方式同样的方面则适当省略说明。以下变形例可以适当组合。
[0452]
《4.1》
[0453]
上述实施方式所涉及的推论装置1及各局部学习装置2可以应用于通过推论模型执行某推论的所有场景。执行某推论的场景是指,例如推断传感器的最佳观测方法的场景、预测移动体的移动路径的场景、推断适合于用户的会话策略的场景、推断适合于任务的机器人装置的动作指令的场景等。以下举例示出限定了应用场景的4个变形例。
[0454]
(a)推断传感器的最佳观测方法的场景
[0455]
图14示意性地举例示出第一变形例所涉及的检查系统100a的应用场景的一例。本变形例是将上述实施方式应用于推测传感器的最佳观测方法的场景的例子。如图14所示,本变形例所涉及的检查系统100a具备检查装置1a及多个局部学习装置2a。与上述实施方式同样地,检查装置1a及各局部学习装置2a可以经由网络相互连接。
[0456]
检查装置1a与上述推论装置1对应。各局部学习装置2a与上述各局部学习装置2对应。除了处理的数据及推论的内容被限定这一点之外,检查装置1a可以与上述推论装置1同样地构成,各局部学习装置2a可以与上述各局部学习装置2同样地构成。检查装置1a的硬件构成及软件构成可以与上述推论装置1是同样的。各局部学习装置2a的硬件构成及软件构成可以与上述各局部学习装置2是同样的。
[0457]
在本变形例中,传感器sa1与检查装置1a及各局部学习装置2a连接。本变形例所涉及的规定的推论是推断从由传感器sa1观测对象物ra的属性的当前的观测状态变更为用于通过传感器sa1得到适合于规定条件的观测数据的适当的观测状态的变更方法。传感器sa1例如可以是照相机、麦克风、生命传感器等。照相机例如可以是构成为获取rgb图像的普通的数码照相机、构成为获取深度图像的深度照相机、构成为将红外线量图像化的红外线照相机等。对象物ra例如可以是产品、植物、人物等。
[0458]
规定的条件可以根据传感器sa1的观测目的适当规定。例如,设想为了评价对象物ra的品质而由传感器sa1得到观测数据的情况。在这种情况下,规定的条件可以根据对由传感器sa1得到的观测数据的品质评价相关的推论的性能而规定。对象物ra的品质评价例如可以是产品的检查(例如,缺陷检测)、植物(例如,农作物)的生长状态的检查、人物的健康状态的检查等。作为具体例,在产品的检查的情况下,规定的条件可以根据基于由传感器sa1得到的观测数据能否进行缺陷检测、缺陷检测的精度是否满足基准等对于由传感器得
到的观测数据的目标检查的性能来规定。
[0459]
本变形例所涉及的各局部学习装置2a生成获得了推断传感器sa1变更为适当的观测状态的变更方法的能力的学习完毕的机器学习模型45a。与此相对,本变形例所涉及的检查装置1a利用根据由各局部学习装置2a在不同的环境下得到的局部学习数据30a导出的各学习完毕的机器学习模型45a,在对象环境下推断对象的传感器sa1的最佳观测方法。在本变形例中,推断最佳观测方法的对象的传感器sa1是与检查装置1a连接的传感器sa1。不过,对象的传感器sa1也可以不限于此,检查装置1a也可以推断与其他计算机连接的传感器sa1的最佳观测方法。
[0460]
本变形例所涉及的检查装置1a获取成为规定的推论的对象的对象数据61a及与执行规定的推论的对象环境相关的环境数据63a。本变形例所涉及的成为规定的推论的对象的对象数据61a是与对象的传感器sa1的当前的观测状态相关的数据。另一方面,本变形例所涉及的与执行规定的推论的对象环境相关的环境数据63a是与对象的传感器sa1观测对象物ra的属性的对象观测环境相关的数据。
[0461]
在本变形例中,检查装置1a进一步与其他传感器sa2连接。其他传感器sa2与推断最佳观测方法的对象的传感器sa1不同,用于观测对象观测环境。因此,检查装置1a能够从其他传感器sa2获取环境数据63a。作为对象观测环境,在考虑明亮度、温度、湿度等的情况下,其他传感器sa2例如可以是照相机、光度计、照度计、温度计、湿度计等。
[0462]
本变形例所涉及的检查装置1a将所获取的对象数据61a提供给各学习完毕的机器学习模型45a,使各学习完毕的机器学习模型45a推断传感器sa1变更为适当的观测状态的变更方法。由此,本变形例所涉及的检查装置1a获取各学习完毕的机器学习模型45a对传感器sa1变更为适当的观测状态的变更方法的推断结果。然后,本变形例所涉及的检查装置1a按照整合规则5a整合各学习完毕的机器学习模型45a的推断结果。
[0463]
与上述实施方式同样地,整合规则5a具备在对象环境下分别规定重视各学习完毕的机器学习模型45a的推断结果的程度的多个整合参数pa。本变形例所涉及的检查装置1a根据环境数据63a确定各整合参数pa的值。此时,除了环境数据63a之外,也可以进一步考虑对象数据61a。接着,本变形例所涉及的检查装置1a使用所确定的各整合参数pa的值,对对应的各学习完毕的机器学习模型45a的推断结果进行加权。然后,本变形例所涉及的检查装置1a整合各学习完毕的机器学习模型45a的加权后的推断结果。
[0464]
由此,本变形例所涉及的检查装置1a能够生成在对象环境下推断从对象的传感器sa1的当前的观测状态变更为适当的观测状态的变更方法的结果。推断变更为适当的观测状态的变更方法可以包括直接推断该变更方法、以及通过推断适当的观测状态并计算所推断的适当的观测状态与当前的观测状态的差分来间接地推断用于引导至适当的观测状态的变更方法。
[0465]
需要说明的是,图14的各符号示意性地举例示出产品的图像检查的场景。对象物ra可以是生产线上制造的产品,传感器sa1可以是照相机。由传感器sa1得到的观测数据可以是图像数据。在图像检查的场景中考虑明亮度的情况下,其他传感器sa2也可以是光度计或照度计。规定的条件可以是与以适合于检查对象物ra(产品)的属性(例如,有无缺陷、缺陷的种类)的方式将对象物ra拍到图像数据中相关的条件。
[0466]
另外,在本变形例中,检查装置1a进一步与云台装置in1及照明装置in2连接。传感
器s1安装在云台装置in1上。云台装置in1具备底座部in11、第一关节部in12及第二关节部in13。各关节部(in12、in13)可以具备伺服电机等驱动装置。第一关节部in12与底座部in11连接,使前端侧的部分绕底座的轴旋转。第二关节部in13与第一关节部in12连接,使前端侧的部分向前后方向旋转。云台装置in1构成为通过具备这些部件而能够在计算机控制下变更传感器s1的朝向及配置。另外,照明装置in2可以构成为通过在计算机控制下调节输出的光量而能够变更观测环境的明亮度。
[0467]
通过云台装置in1及照明装置in2,能够变更传感器sa1的观测状态中的传感器sa1的设置角度及对象物ra周围的明亮度。云台装置in1及照明装置in2分别是本发明的“介入装置”的一例。不过,介入装置只要构成为通过介入对象的传感器sa1的观测状态而能够变更观测状态即可,也可以不限于这样的例子。在介入温度、湿度的情况下,可以利用空调装置、加湿器、加热器等作为介入装置。另外,在介入对象物ra及传感器sa1中的至少一方的位置或姿势的情况下,可以利用输送机装置、机械臂等作为介入装置。
[0468]
《学习完毕的机器学习模型的生成》
[0469]
本变形例所涉及的各局部学习装置2a与上述各局部学习装置2同样地,通过执行步骤s101~步骤s104的处理,来生成学习完毕的机器学习模型45a。即,在步骤s101中,各局部学习装置2a获取局部学习数据30a。然后,在步骤s102中,各局部学习装置2a利用所获取的局部学习数据30a执行机器学习模型40a的机器学习。机器学习模型40a的构成及机器学习的方法可以与上述机器学习模型40是同样的。
[0470]
作为一例,机器学习的方法可以使用上述有监督学习(第一例)或强化学习(第三例)。在采用有监督学习的情况下,局部学习数据30a由分别包括训练数据及正解数据的组合的多个学习数据集构成。训练数据与上述对象数据61a同种,可以由与传感器sa1的当前的观测状态相关的数据构成。正解数据可以由表示对训练数据的推论的结果(正解)、即从当前的观测状态变更为适当的观测状态的变更方法的数据构成。各学习数据集可以通过与上述实施方式同样的方法生成。各局部学习装置2a利用所获取的局部学习数据30a执行机器学习模型40a的有监督学习。有监督学习的方法可以与上述实施方式是同样的。
[0471]
另外,在采用强化学习的情况下,机器学习模型40a可以采用基于价值、基于策略或这两者。成为观测对象的状态可以是传感器sa1的观测状态,由智能体执行的行动可以是传感器sa1的观测状态的变更。报酬函数也可以由操作者等手动设定。或者,报酬函数也可以设定为根据机器学习模型40a的推断结果的适当度来提供立即报酬。在这种情况下,与上述实施方式同样地,适当度也可以由操作者等手动提供。或者,适当度也可以使用判定器按照规定的基准进行评价。判定器可以构成为对由传感器sa1得到的观测数据执行目标推断处理。例如,在产品的图像检查的场景中,判定器可以构成为根据图像数据来检测产品的缺陷。与此相应地,报酬函数可以设定为基于多次推断处理的试行结果,如果推断处理的精度为阈值以上,则提供正的立即报酬,如果推断处理的精度为容许值以下(例如,无法检测出缺陷),则提供负的立即报酬。或者,报酬函数也可以根据表示专家的演示的事例数据通过逆强化学习来推断。在本变形例中,事例数据例如可以由表示通过熟练者的操作而得到的传感器sa1的变更方法的数据构成。各局部学习装置2a调整机器学习模型40a的运算参数的值,以使在适当设定的学习环境中,得到的价值(的期望值)最大化。强化学习的方法可以与上述实施方式是同样的。
[0472]
各局部学习装置2a能够通过上述任一种方法来执行机器学习模型40a的机器学习。由此,各局部学习装置2a能够生成获得了推断从由传感器sa1观测对象物ra的属性的当前的观测状态变更为用于通过传感器sa1得到适合于规定的条件的观测数据的适当的观测状态的变更方法的能力的学习完毕的机器学习模型45a。
[0473]
在步骤s103中,各局部学习装置2a获取与得到局部学习数据30a的环境相关的学习环境数据35a。学习环境数据35a是与通过检查装置1a得到的环境数据63a同种的数据。获取学习环境数据35a的方法可以与获取环境数据63a的方法是同样的。例如,各局部学习装置2a可以进一步与和其他传感器sa2同种的传感器连接,也可以从该传感器获取学习环境数据35a。在步骤s104中,各局部学习装置2a生成与所生成的学习完毕的机器学习模型45a相关的信息作为学习结果数据47a。然后,各局部学习装置2a将学习结果数据47a与学习环境数据35a建立关联地保存在规定的存储区域中。
[0474]
在本变形例中,在各局部学习装置2a之间,局部学习数据30a可以在不同的环境下获取。然后,可以根据所得到的局部学习数据30a生成学习完毕的机器学习模型45a。其结果,能够得到以可推断传感器sa1的最佳观测方法的方式根据在不同环境下得到的局部学习数据30a导出的多个学习完毕的机器学习模型45a。
[0475]
《检查装置的硬件构成》
[0476]
图15示意性地举例示出本变形例所涉及的检查装置1a的硬件构成的一例。如图15所示,本变形例所涉及的检查装置1a与上述推论装置1同样地,是与控制部11、存储部12、通信接口13、外部接口14、输入装置15、输出装置16及驱动器17电连接的计算机。检查装置1a经由外部接口14与传感器sa1、其他传感器sa2、云台装置in1及照明装置in2连接。不过,检查装置1a的硬件构成也可以不限于这样的例子。关于检查装置1a的具体的硬件构成,可以根据实施方式适当地进行构成要素的省略、替换及追加。检查装置1a除了是设计为所提供的服务专用的信息处理装置之外,也可以是通用的服务器装置、通用的pc、plc(programmable logic controller:可编程逻辑控制器)等。
[0477]
本变形例所涉及的检查装置1a的存储部12存储检查程序81a、整合规则数据57a、学习结果数据47a、学习数据59a、学习环境数据35a等各种信息。检查程序81a、整合规则数据57a、学习结果数据47a、学习数据59a及学习环境数据35a与上述实施方式所涉及的推论程序81、整合规则数据57、学习结果数据47、学习数据59及学习环境数据35对应。检查程序81a、整合规则数据57a、学习结果数据47a、学习数据59a及学习环境数据35a中的至少任一者也可以存储在存储介质91中。另外,检查装置1a也可以从存储介质91中获取检查程序81a、整合规则数据57a、学习结果数据47a、学习数据59a及学习环境数据35a中的至少任一者。
[0478]
《检查装置的软件构成》
[0479]
图16a及图16b示意性地举例示出本变形例所涉及的检查装置1a的软件构成的一例。与上述实施方式同样地,检查装置1a的软件构成通过控制部11执行检查程序81a而实现。如图16a及图16b所示,除了处理的数据及推论的内容被限定这一点之外,检查装置1a的软件构成与上述推论装置1的软件构成是同样的。由此,检查装置1a与上述推论装置1同样地执行与上述推论相关的一系列处理。
[0480]
(步骤s201)
[0481]
即,如图16a所示,在步骤s201中,检查装置1a的控制部11获取对象数据61a。对象数据61a只要是与对象的传感器sa1的当前的观测状态相关的数据即可,其内容也可以不特别限定,可以根据实施方式适当选择。在对象数据61a中,例如可以包括表示与对象传感器sa1的设置状况相关的属性的数据、表示与对象传感器sa1的动作设定相关的属性的数据、由对象传感器sa1得到的观测数据等。在与对象传感器sa1的设置状况相关的属性中,例如可以包括传感器sa1的设置角度、传感器sa1与观测对象(对象物ra)之间的距离、对传感器sa1的观测产生影响的观测属性(例如,明亮度、温度、湿度等)等。在与对象传感器sa1的动作设定相关的属性中,例如可以包括传感器sa1的测量范围的设定值、测量范围的分辨率的设定值、采样频率的设定值等。作为具体例,在传感器sa1是照相机的情况下,与动作设定相关的属性中可以包括光圈值、快门速度、变焦倍率等。
[0482]
获取对象数据61a的方法也可以不特别限定,可以根据实施方式适当选择。例如,也可以从对象传感器sa1自身获取对象数据61a。另外,例如也可以从观测环境属性的其他传感器(例如,其他传感器sa2)获取对象数据61a。另外,在本变形例中,作为介入装置,云台装置in1及照明装置in2与检查装置1a连接。也可以从各介入装置自身及观测各介入装置的状态的传感器(未图示)中的至少任一者获取对象数据61a。另外,例如也可以通过操作者等的输入来获取对象数据61a。控制部11可以从各装置中直接获取对象数据61a,也可以经由其他计算机间接获取对象数据61a。
[0483]
(步骤s202)
[0484]
在步骤s202中,控制部11获取环境数据63a。环境数据63a只要是与对象的传感器sa1观测对象物ra的属性的对象观测环境相关的数据即可,其内容也可以不特别限定,可以根据实施方式适当选择。在环境数据63a中,例如可以包括表示与对象传感器sa1的规格(或性能)相关的属性的数据、表示观测对象(对象物ra)的属性的数据、对对象传感器sa1的观测产生影响的环境属性等。在与对象传感器sa1的规格(或性能)相关的属性中,例如可以包括传感器sa1的灵敏度极限、动态范围、空间分辨率的可设定范围、采样频率的可设定范围等。在观测对象(对象物ra)的属性中,例如可以包括观测对象的种类、观测目的等。观测对象的种类例如可以是产品/工件的种类、植物的种类等。观测目的例如是缺陷检测、品质检查等。
[0485]
获取环境数据63a的方法也可以不特别限定,可以根据实施方式适当选择。例如,也可以通过操作者等的输入来获取环境数据63a。另外,例如也可以从对象传感器sa1自身获取环境数据63a。另外,例如也可以从由对象传感器sa1得到的观测数据中获取环境数据63a。另外,例如也可以从观测环境属性的其他传感器(例如,其他传感器sa2)获取环境数据63a。控制部11可以从各装置中直接获取环境数据63a,也可以经由其他计算机间接获取环境数据63a。
[0486]
(步骤s203)
[0487]
在步骤s203中,控制部11通过参照各份学习结果数据47a来进行各学习完毕的机器学习模型45a的设定。接着,控制部11对各学习完毕的机器学习模型45a提供对象数据61a,执行各学习完毕的机器学习模型45a的运算处理。由此,控制部11获取各学习完毕的机器学习模型45a对于对象传感器sa1变更为适当的观测状态的变更方法的推断结果,作为各学习完毕的机器学习模型45a的输出。
[0488]
(步骤s204)
[0489]
在步骤s204中,控制部11参照整合规则数据57a进行整合规则5a的设定。然后,控制部11按照整合规则5a整合各学习完毕的机器学习模型45a的推断结果。具体而言,在步骤s211中,控制部11根据环境数据63a确定各整合参数pa的值。此时,除了环境数据63a之外,也可以进一步考虑对象数据61a。确定各整合参数pa的值的方法可以采用上述第一~第三方法中的任一者。
[0490]
(1)第一方法
[0491]
如图16b所示,在采用第一方法的情况下,控制部11获取学习数据59a。然后,控制部11利用学习数据59a执行运算模型51a的机器学习。运算模型51a的构成及机器学习的方法可以与上述运算模型51是同样的。运算模型51a的构成及机器学习的方法可以采用上述两个例子中的任一个例子。
[0492]
在采用第一例的情况下,学习数据59a与上述学习数据59同样地,可以由分别包括训练用环境数据、训练用对象数据及正解数据的组合的多个学习数据集构成。训练用环境数据是与环境数据63a同种的数据。训练用对象数据是与对象数据61a同种的数据。正解数据可以由表示对训练用对象数据的推论的结果(正解)、即在对象环境下从当前的观测状态变更为适当的观测状态的变更方法的数据构成。各学习数据集可以通过与上述实施方式同样的方法生成。控制部11利用所获取的学习数据59a执行运算模型51a的机器学习。机器学习的方法可以与上述第一例是同样的。
[0493]
在采用第二例的情况下,运算模型51a可以采用基于价值、基于策略或这两者。与上述实施方式同样地,成为观测对象的状态与环境数据63a及对象数据61a对应。由智能体执行的行动可以是传感器sa1的观测状态的变更。智能体通过上述一系列的处理获取各学习完毕的机器学习模型45a的推断结果,通过整合所获取的推断结果,能够生成对象环境下的推断结果。智能体也可以基于所生成的推断结果确定采用的行动。
[0494]
报酬函数也可以由操作者等手动设定。或者,报酬函数可以设定为根据通过上述一系列的处理生成的推断结果的适当度来提供立即报酬。适当度可以由操作者等手动提供。或者,适当度也可以使用判定器按照规定的基准进行评价。判定器可以与上述机器学习模型40a的强化学习中的判定器是同样的。或者,报酬函数也可以根据表示专家的演示的事例数据通过逆强化学习来推断。该事例数据可以与在上述机器学习模型40a的强化学习中的报酬函数的设定中利用的事例数据是同样的。控制部11调整运算模型51a的运算参数的值,以使在适当设定的学习的环境中,得到的价值(的期望值)最大化。强化学习的方法可以与上述实施方式是同样的。
[0495]
控制部11能够通过上述任一种方法来执行运算模型51a的机器学习。由此,控制部11能够生成获得了根据环境数据63a(及对象数据61a)推断适合于对象观测环境下的传感器sa1的最佳观测方法的推断的各整合参数pa的值的能力的学习完毕的运算模型52a。控制部11也可以将与所生成的学习完毕的运算模型52a相关的信息保存在规定的存储区域中。与学习完毕的运算模型52a相关的信息可以作为整合规则数据57a的至少一部分保存,也可以与整合规则数据57a分开保存。
[0496]
在第一方法中,控制部11利用上述生成的学习完毕的运算模型52a确定各整合参数pa的值。即,在步骤s211中,控制部11对学习完毕的运算模型52a提供环境数据63a。此时,
控制部11可以进一步对学习完毕的运算模型52a提供对象数据61a。然后,控制部11执行学习完毕的运算模型52a的运算处理。由此,控制部11能够获取针对各学习完毕的机器学习模型45a的各整合参数pa的值,作为学习完毕的运算模型52a的输出。
[0497]
(2)第二方法
[0498]
在第二方法中,控制部11基于对象环境与各学习环境的比较,来确定各整合参数pa的值。即,控制部11获取各学习完毕的机器学习模型45a的学习环境数据35a。接着,控制部11计算各份学习环境数据35a及环境数据63a的适合度。适当度的形式及表现可以与上述实施方式是同样的。在上述步骤s211中,控制部11也可以根据计算出的各适合度,来确定针对对应的各学习完毕的机器学习模型45a的各整合参数pa的值。根据适合度确定整合参数pa的值的方法可以与上述实施方式是同样的。
[0499]
(3)第三方法
[0500]
在第三方法中,控制部11接收操作者对整合参数pa的值的指定,并将对象的整合参数pa的值设定为指定的值。接收画面可以与上述实施方式是同样的(图12a)。
[0501]
返回到图16a,在步骤s211中,控制部11通过采用上述三种方法中的至少任一种方法,能够确定各整合参数pa的值。在步骤s212中,控制部11使用所确定的各整合参数pa的值,对对应的各学习完毕的机器学习模型45a的推断结果进行加权。在通过上述第三方法设定了多个整合参数pa中的至少任一个整合参数pa的值的情况下,在步骤s212中,控制部11使用上述设定的值,对与对象的整合参数pa对应的学习完毕的机器学习模型45a的推断结果进行加权。在步骤s213中,控制部11整合各学习完毕的机器学习模型45a的加权后的推断结果。推断结果的整合可以与上述实施方式同样地通过加权平均或加权多数表决来进行。由此,能够生成在对象环境下推断从对象传感器sa1的当前的观测状态变更为适当的观测状态的变更方法的结果。
[0502]
(步骤s205)
[0503]
在步骤s205中,控制部11输出与所生成的推断结果相关的信息。与上述实施方式同样地,输出目的地及输出的信息内容可以分别根据实施方式适当确定。控制部11可以将通过步骤s204生成的推断结果直接输出到输出装置16,也可以基于所生成的推断结果执行某信息处理。
[0504]
例如,控制部11也可以基于通过步骤s204生成的推断结果,生成用于指示用户按照所推断的变更为适当的观测状态的变更方法变更对象传感器sa1的观测状态的指示信息,作为与推断结果相关的信息。然后,控制部11也可以将所生成的指示信息输出到输出装置。输出目的地的输出装置可以是检查装置1a的输出装置16,也可以是其他计算机的输出装置。其他计算机可以是配置在用户附近的计算机,也可以是用户持有的终端装置。根据该输出方法,即使是不具有专业知识的用户,也能够根据对象环境使传感器sa1的观测状态优化。
[0505]
另外,设想检查装置1a与变更对象传感器sa1的观测状态的介入装置连接的情况。在这种情况下,控制部11也可以基于所生成的推断结果,生成用于使介入装置执行按照所推断的变更为适当的观测状态的变更方法变更对象传感器sa1的观测状态的动作的指令信息,作为与推断结果相关的信息。然后,控制部11也可以通过向介入装置发送指令信息,使介入装置执行用于按照所推断的变更方法变更对象传感器sa1的观测状态的动作。此时,控
制部11也可以直接控制介入装置的动作。或者,在介入装置具备控制装置的情况下,控制部11也可以向控制装置发送指令信息,通过使控制装置执行介入装置的动作的控制,来间接地控制介入装置的动作。根据该输出方法,能够自动地使传感器sa1的观测状态优化。
[0506]
在本变形例中,检查装置1a与作为介入装置的一例的云台装置in1及照明装置in2连接。控制部11也可以基于在步骤s204中生成的推断结果,控制云台装置in1及照明装置in2中的至少任一方的动作,来变更对象传感器sa1的观测状态。由此,能够使对象传感器sa1的设置角度及对象物ra周围的明亮度中的至少任一方优化。
[0507]
需要说明的是,与上述实施方式同样地,检查装置1a的控制部11可以将各学习完毕的机器学习模型45a分配给多个组中的至少任一个组。由此,控制部11也可以根据目的对每个组执行整合处理。分组的方法可以采用上述两种方法中的任一种方法。
[0508]
《局部学习装置的推论处理》
[0509]
另外,本变形例所涉及的各局部学习装置2a与上述各局部学习装置2同样地,通过执行步骤s111~步骤s113的处理,能够利用学习完毕的机器学习模型45a来推断传感器sa1的最佳观测方法。通过各局部学习装置2a推断最佳观测方法的对象的传感器sa1典型的是与各局部学习装置2a自身连接的传感器sa1。不过,对象的传感器sa1也可以不限于此,各局部学习装置2a也可以推断与其他计算机连接的传感器sa1的最佳观测方法。
[0510]
在步骤s111中,各局部学习装置2a获取在推断中利用的对象数据。对象数据的获取方法可以与上述检查装置1a的步骤s201是同样的。在步骤s112中,各局部学习装置2a对学习完毕的机器学习模型45a提供对象数据,执行学习完毕的机器学习模型45a的运算处理。由此,各局部学习装置2a能够获取推断从传感器sa1的当前的观测状态变更为适当的观测状态的变更方法的结果,作为学习完毕的机器学习模型45a的输出。
[0511]
在步骤s113中,各局部学习装置2a输出与推断结果相关的信息。输出目的地及输出的信息的内容可以分别根据实施方式适当确定。各局部学习装置2a可以将通过步骤s112得到的推断结果直接输出到输出装置,也可以基于所得到的推断结果来执行某信息处理。
[0512]
另外,步骤s113的处理可以与上述检查装置1a的步骤s205同样地执行。例如,各局部学习装置2a也可以生成用于指示用户按照所推断的变更为适当的观测状态的变更方法变更传感器sa1的观测状态的指示信息,并将所生成的指示信息输出到输出装置。另外,各局部学习装置2a例如也可以进一步与云台装置in1、照明装置in2等介入装置连接。在这种情况下,各局部学习装置2a也可以生成用于使介入装置执行按照所推断的变更为适当的观测状态的变更方法变更传感器sa1的观测状态的动作的指令信息。然后,各局部学习装置2a也可以通过向介入装置发送指令信息,使介入装置执行用于按照所推断的变更方法变更传感器sa1的观测状态的动作。
[0513]
《特征》
[0514]
根据本变形例,在由传感器sa1观测对象物ra的属性的场景中,能够降低构建在新的环境中能够适当地推断传感器sa1的最佳观测方法的推论模型花费的成本。另外,通过在传感器sa1的观测状态的观测中利用其他传感器sa2,能够获取充分反映了传感器sa1的观测状态的环境数据63a。由此,能够实现检查装置1a对对象传感器sa1的最佳观测方法的推断精度的提高。
[0515]
进而,通过检查装置1a的输出处理,能够自动地或由用户手动地使对象传感器sa1
的观测状态优化。由此,能够不依赖于人工标准化地在各环境中系统地使传感器sa1的观测状态优化。因此,根据本变形例,能够在各种环境中低成本地使为了进行产品的缺陷检测、植物的品质检查等而观察对象物ra的属性的方法适当化。因此,能够在各种环境中实施抑制了偏差的高品质的检查。
[0516]
需要说明的是,本变形例可以适当变更。例如,在从其他传感器sa2以外获取环境数据63a的情况下,其他传感器sa2可以省略。在不通过介入装置实施观测状态的变更的情况下,云台装置in1及照明装置in2可以省略。检查装置1a与各装置(传感器sa1、其他传感器sa2、云台装置in1及照明装置in2)可以经由通信接口连接。检查装置1a也可以构成为在上述步骤s205中能够输出指示信息及指令信息这两者。或者,指示信息及指令信息中的任一方也可以省略。
[0517]
(b)预测移动体的移动路径的场景
[0518]
图17示意性地举例示出第二变形例所涉及的预测系统100b的应用场景的一例。本变形例是将上述实施方式应用于预测移动体的移动路径的场景的例子。如图17所示,本变形例所涉及的预测系统100b具备预测装置1b及多个局部学习装置2b。与上述实施方式同样地,预测装置1b及各局部学习装置2b可以经由网络相互连接。
[0519]
预测装置1b与上述推论装置1对应。各局部学习装置2b与上述各局部学习装置2对应。除了处理的数据及推论的内容被限定这一点之外,预测装置1b可以与上述推论装置1同样地构成,各局部学习装置2b可以与上述各局部学习装置2同样地构成。预测装置1b的硬件构成及软件构成可以与上述推论装置1是同样的。各局部学习装置2b的硬件构成及软件构成可以与上述各局部学习装置2是同样的。
[0520]
本变形例所涉及的规定的推论是根据移动体rb的状态预测移动体rb的移动路径。移动体rb只要是移动的对象物即可,其种类也可以不特别限定,可以根据实施方式适当选择。移动体rb例如可以是生物(人等)、机械(车辆等)等。在本变形例中,传感器sb1与预测装置1b及各局部学习装置2b连接。移动体rb的状态由传感器sb1进行观测。传感器sb1例如可以是照相机、信标等。照相机例如可以是构成为获取rgb图像的普通的数码照相机、构成为获取深度图像的深度照相机、构成为将红外线量图像化的红外线照相机等。
[0521]
本变形例所涉及的各局部学习装置2b生成获得了根据移动体rb的状态预测移动体rb的移动路径的能力的学习完毕的机器学习模型45b。与此相对,本变形例所涉及的预测装置1b利用根据由各局部学习装置2b在不同的环境下得到的局部学习数据30b而被导出的各学习完毕的机器学习模型45b,在对象环境下预测移动体rb的移动路径。
[0522]
本变形例所涉及的预测装置1b获取成为规定的推论的对象的对象数据61b、以及与执行规定的推论的对象环境相关的环境数据63b。本变形例所涉及的成为规定的推论的对象的对象数据61b是与由传感器sb1观测的对象的移动体rb的状态相关的数据。另一方面,本变形例所涉及的与执行规定的推论的对象环境相关的环境数据63b是与传感器sb1观测对象的移动体rb的对象观测环境相关的数据。
[0523]
在本变形例中,预测装置1b进一步与其他传感器sb2连接。其他传感器sb2与观测移动体rb的状态的传感器sb1不同,用于观测传感器sb1观测对象的移动体rb的对象观测环境。因此,预测装置1b能够从其他传感器sb2获取环境数据63b。在考虑天气、气压等作为对象观测环境的情况下,其他传感器sb2例如可以是气象传感器、气压计等。
[0524]
本变形例所涉及的预测装置1b将所获取的对象数据61b提供给各学习完毕的机器学习模型45b,使各学习完毕的机器学习模型45b预测移动体rb的移动路径。由此,本变形例所涉及的预测装置1b获取各学习完毕的机器学习模型45b针对移动体rb的移动路径的预测结果。然后,本变形例所涉及的预测装置1b按照整合规则5b整合各学习完毕的机器学习模型45b的预测结果。
[0525]
与上述实施方式同样地,整合规则5b具备在对象环境下分别规定重视各学习完毕的机器学习模型45b的预测结果的程度的多个整合参数pb。本变形例所涉及的预测装置1b根据环境数据63b确定各整合参数pb的值。此时,除了环境数据63b之外,也可以进一步考虑对象数据61b。接着,本变形例所涉及的预测装置1b使用所确定的各整合参数pb的值,对对应的各学习完毕的机器学习模型45b的预测结果进行加权。然后,本变形例所涉及的预测装置1b整合各学习完毕的机器学习模型45b的加权后的预测结果。
[0526]
由此,本变形例所涉及的预测装置1b能够生成在对象环境下根据移动体rb的状态预测移动体rb的移动路径的结果。
[0527]
《学习完毕的机器学习模型的生成》
[0528]
本变形例所涉及的各局部学习装置2b与上述各局部学习装置2同样地,通过执行步骤s101~步骤s104的处理,生成学习完毕的机器学习模型45b。即,在步骤s101中,各局部学习装置2b获取局部学习数据30b。然后,在步骤s102中,各局部学习装置2b利用所获取的局部学习数据30b执行机器学习模型40b的机器学习。机器学习模型40b的构成及机器学习的方法可以与上述机器学习模型40是同样的。
[0529]
在本变形例中,机器学习的方法可以采用上述第一例~第三例中的任一者。在采用第一例的情况下,局部学习数据30b由分别包括训练数据及正解数据的组合的多个学习数据集构成。训练数据与上述对象数据61b同种,可以由与由传感器sb1观测的移动体rb的状态相关的数据构成。正解数据可以由表示对训练数据的推论的结果(正解)、即该状态的移动体rb实际或虚拟地移动的路径的数据构成。各学习数据集可以通过与上述实施方式同样的方法生成。各局部学习装置2b利用所获取的局部学习数据30b执行机器学习模型40b的有监督学习。有监督学习的方法可以与上述实施方式是同样的。
[0530]
在采用第二例的情况下,局部学习数据30b由多份训练数据构成。训练数据由想要使机器学习模型40b生成的数据构成。训练数据例如由表示移动体rb实际或虚拟地移动的路径的数据构成。各份训练数据可以通过与上述实施方式同样的方法生成。各局部学习装置2b利用所获取的局部学习数据30b执行机器学习模型40b及其他机器学习模型的对抗学习。对抗学习的方法可以与上述实施方式是同样的。
[0531]
在采用第三例的情况下,机器学习模型40b可以采用基于价值、基于策略或这两者。成为观测对象的状态可以是与移动体rb的移动路径相关的状态,由智能体执行的行动可以是移动体rb的移动。报酬函数也可以由操作者等手动设定。或者,报酬函数也可以设定为根据机器学习模型40b的预测结果的适当度来提供立即报酬。在这种情况下,与上述实施方式同样地,适当度也可以由操作者等手动提供。或者,适当度也可以使用判定器按照规定的基准进行评价。判定器可以构成为对预测移动体rb的移动路径的结果的精度进行评价。与此相应地,报酬函数可以设定为基于多次预测处理的试行结果,如果路径预测的精度为阈值以上,则提供正的立即报酬,如果路径预测的精度为容许值以下,则提供负的立即报
酬。或者,报酬函数也可以根据表示专家的演示的事例数据通过逆强化学习来推断。在本变形例中,事例数据例如可以由表示移动体rb实际移动的路径的数据构成。各局部学习装置2b调整机器学习模型40b的运算参数的值,以使在适当设定的学习环境中,得到的价值(的期望值)最大化。强化学习的方法可以与上述实施方式是同样的。
[0532]
各局部学习装置2b能够通过上述任一种方法来执行机器学习模型40b的机器学习。由此,各局部学习装置2b能够生成获得了根据移动体rb的状态预测移动体rb的移动路径的能力的学习完毕的机器学习模型45b。
[0533]
在步骤s103中,各局部学习装置2b获取与得到局部学习数据30b的环境相关的学习环境数据35b。学习环境数据35b是与通过预测装置1b得到的环境数据63b同种的数据。获取学习环境数据35b的方法可以与获取环境数据63b的方法是同样的。例如,各局部学习装置2b可以进一步与和其他传感器sb2同种的传感器连接,也可以从该传感器获取学习环境数据35b。在步骤s104中,各局部学习装置2b生成与所生成的学习完毕的机器学习模型45b相关的信息作为学习结果数据47b。然后,各局部学习装置2b将学习结果数据47b与学习环境数据35b建立关联地保存在规定的存储区域中。
[0534]
在本变形例中,在各局部学习装置2b之间,局部学习数据30b可以在不同的环境下获取。然后,可以根据所得到的局部学习数据30b生成学习完毕的机器学习模型45b。其结果,能够得到以能够预测移动体rb的移动路径的方式根据在不同环境下得到的局部学习数据30b而被导出的多个学习完毕的机器学习模型45b。
[0535]
《预测装置的硬件构成》
[0536]
图18示意性地举例示出本变形例所涉及的预测装置1b的硬件构成的一例。如图18所示,本变形例所涉及的预测装置1b与上述推论装置1同样地,是与控制部11、存储部12、通信接口13、外部接口14、输入装置15、输出装置16及驱动器17电连接的计算机。预测装置1b经由外部接口14与传感器sb1及其他传感器sb2连接。不过,预测装置1b的硬件构成也可以不限于这样的例子。关于预测装置1b的具体的硬件构成,可以根据实施方式适当地进行构成要素的省略、替换及追加。预测装置1b除了是设计为所提供的服务专用的信息处理装置之外,可以是通用的服务器装置、通用的pc等。
[0537]
本变形例所涉及的预测装置1b的存储部12存储预测程序81b、整合规则数据57b、学习结果数据47b、学习数据59b、学习环境数据35b等各种信息。预测程序81b、整合规则数据57b、学习结果数据47b、学习数据59b及学习环境数据35b与上述实施方式所涉及的推论程序81、整合规则数据57、学习结果数据47、学习数据59及学习环境数据35对应。预测程序81b、整合规则数据57b、学习结果数据47b、学习数据59b及学习环境数据35b中的至少任一者也可以存储在存储介质91中。另外,预测装置1b也可以从存储介质91中获取预测程序81b、整合规则数据57b、学习结果数据47b、学习数据59b及学习环境数据35b中的至少任一者。
[0538]
《预测装置的软件构成》
[0539]
图19a及图19b示意性地举例示出本变形例所涉及的预测装置1b的软件构成的一例。与上述实施方式同样地,预测装置1b的软件构成通过控制部11执行预测程序81b而实现。如图19a及图19b所示,除了处理的数据及推论的内容被限定这一点之外,预测装置1b的软件构成与上述推论装置1的软件构成是同样的。由此,预测装置1b与上述推论装置1同样
地执行与上述推论相关的一系列处理。
[0540]
(步骤s201)
[0541]
即,如图19a所示,在步骤s201中,预测装置1b的控制部11获取对象数据61b。对象数据61b只要是与由传感器sb1观测的对象的移动体rb的状态相关的数据即可,其内容也可以不特别限定,可以根据实施方式适当选择。对象数据61b例如可以包括由观测移动体rb的状态的传感器sb1得到的观测数据、表示根据该观测数据分析的移动范围的状态(例如,拥挤情况等)的数据、表示移动体rb的当前位置的数据、表示移动体rb到当前为止的移动路径的数据等。
[0542]
获取对象数据61b的方法也可以不特别限定,可以根据实施方式适当选择。例如,也可以获取传感器sb1的观测数据作为对象数据61b。另外,例如也可以通过对由传感器sb1得到的观测数据执行某分析处理来获取对象数据61b。另外,例如也可以通过操作者等的输入来获取对象数据61b。控制部11可以从各装置直接获取对象数据61b,也可以经由其他计算机间接获取对象数据61b。
[0543]
(步骤s202)
[0544]
在步骤s202中,控制部11获取环境数据63b。环境数据63b只要是与传感器sb1观测对象的移动体rb的对象观测环境相关的数据即可,其内容也可以不特别限定,可以根据实施方式适当选择。在环境数据63b中,例如可以包括表示移动体rb的属性的数据、表示移动范围的属性的数据、表示对移动产生影响的环境属性的数据、表示与传感器sb1的规格(或性能)相关的属性的数据、表示与传感器sb1的观测条件相关的属性的数据等。在移动体rb的属性中,例如可以包括移动体rb的种类(人物或车辆的区别、车型等)、与移动体rb的移动能力相关的信息。在移动体rb是人物的情况下,移动能力也可以根据人物的性别、年龄、身高、体重等进行评价。另外,在移动体rb是车辆的情况下,移动能力可以根据车辆的性能进行评价。在移动范围的属性中,例如可以包括移动的场所、移动的通道(道路)的种类等。在移动的通道(道路)的种类中,例如可以包括步行者专用、高速路、普通道路等。在对移动产生影响的环境属性中,例如可以包括天气、拥挤情况、星期几、假日/平日的种类等。在与传感器sb1的规格相关的属性中,例如可以包括传感器sb1的灵敏度极限、动态范围、空间分辨率的可设定范围、采样频率的可设定范围等。在与传感器sb1的观测条件相关的属性中,例如可以包括传感器sb1的设置角度、传感器sb1的动作设定相关的属性等。在与传感器sb1的动作设定相关的属性中,例如可以包括传感器sb1的测量范围的设定值、测量范围的分辨率的设定值、采样频率的设定值等。作为具体例,在传感器sb1是照相机的情况下,与动作设定相关的属性可以包括光圈值、快门速度、变焦倍率等。
[0545]
获取环境数据63b的方法也可以不特别限定,可以根据实施方式适当选择。例如,可以通过操作者等的输入来获取环境数据63b。另外,例如环境数据63b也可以通过对由传感器sb1得到的观测数据执行某分析处理来获取。另外,例如也可以从观测对象观测环境的其他传感器(例如,其他传感器sb2)获取环境数据63b。另外,例如也可以从发布气象数据等信息的其他信息处理装置(服务器)获取环境数据63b。控制部11可以从各装置直接获取环境数据63b,也可以经由其他计算机间接获取环境数据63b。
[0546]
(步骤s203)
[0547]
在步骤s203中,控制部11通过参照各份学习结果数据47b来进行各学习完毕的机
器学习模型45b的设定。接着,控制部11对各学习完毕的机器学习模型45b提供对象数据61b,执行各学习完毕的机器学习模型45b的运算处理。由此,控制部11获取各学习完毕的机器学习模型45b针对移动体rb的移动路径的预测结果,作为各学习完毕的机器学习模型45b的输出。
[0548]
(步骤s204)
[0549]
在步骤s204中,控制部11参照整合规则数据57b进行整合规则5b的设定。然后,控制部11按照整合规则5b整合各学习完毕的机器学习模型45b的预测结果。具体而言,在步骤s211中,控制部11根据环境数据63b确定各整合参数pb的值。此时,除了环境数据63b之外,也可以进一步考虑对象数据61b。确定各整合参数pb的值的方法可以采用上述第一~第三方法中的任一种方法。
[0550]
(1)第一方法
[0551]
如图19b所示,在采用第一方法的情况下,控制部11获取学习数据59b。然后,控制部11利用学习数据59b执行运算模型51b的机器学习。运算模型51b的构成及机器学习的方法可以与上述运算模型51是同样的。运算模型51b的构成及机器学习的方法可以采用上述两个例子中的任一个例子。
[0552]
在采用第一例的情况下,学习数据59b与上述学习数据59同样地,可以由分别包括训练用环境数据、训练用对象数据及正解数据的组合的多个学习数据集构成。训练用环境数据是与环境数据63b同种的数据。训练用对象数据是与对象数据61b同种的数据。正解数据可以由表示对训练用对象数据的推论的结果(正解)、即在对象环境下任意状态的移动体rb实际或虚拟地移动的路径的数据构成。各学习数据集可以通过与上述实施方式同样的方法生成。控制部11利用所获取的学习数据59b执行运算模型51b的机器学习。机器学习的方法可以与上述第一例是同样的。
[0553]
在采用第二例的情况下,运算模型51b可以采用基于价值、基于策略或这两者。与上述实施方式同样地,成为观测对象的状态与环境数据63b及对象数据61b对应。由智能体执行的行动可以是移动体rb的移动。智能体通过上述一系列处理获取各学习完毕的机器学习模型45b的预测结果,通过整合所获取的预测结果,能够生成对象环境下的移动体rb的移动路径的预测结果。智能体也可以基于所生成的预测结果确定采用的行动。
[0554]
报酬函数也可以由操作者等手动设定。或者,报酬函数也可以设定为根据通过上述一系列处理生成的预测结果的适当度来提供立即报酬。适当度也可以由操作者等手动提供。或者,适当度也可以使用判定器按照规定的基准进行评价。判定器可以与上述机器学习模型40b的强化学习中的判定器是同样的。或者,报酬函数也可以根据表示专家的演示的事例数据通过逆强化学习来推断。该事例数据可以与在上述机器学习模型40b的强化学习中的报酬函数的设定中利用的事例数据是同样的。控制部11调整运算模型51b的运算参数的值,以使在适当设定的学习环境中,得到的价值(的期望值)最大化。强化学习的方法可以与上述实施方式是同样的。
[0555]
控制部11能够通过上述任一种方法来执行运算模型51b的机器学习。由此,控制部11能够生成获得了根据环境数据63b(及对象数据61b)推断适合于对象观测环境下的移动体rb的移动路径的预测的各整合参数pb的值的能力的学习完毕的运算模型52b。控制部11也可以将与所生成的学习完毕的运算模型52b相关的信息保存在规定的存储区域中。与学
习完毕的运算模型52b相关的信息可以作为整合规则数据57b的至少一部分保存,也可以与整合规则数据57b分开保存。
[0556]
在第一方法中,控制部11利用上述生成的学习完毕的运算模型52b确定各整合参数pb的值。即,在步骤s211中,控制部11对学习完毕的运算模型52b提供环境数据63b。此时,控制部11可以进一步对学习完毕的运算模型52b提供对象数据61b。然后,控制部11执行学习完毕的运算模型52b的运算处理。由此,控制部11能够获取针对各学习完毕的机器学习模型45b的各整合参数pb的值,作为学习完毕的运算模型52b的输出。
[0557]
(2)第二方法
[0558]
在第二方法中,控制部11基于对象环境与各学习环境的比较,来确定各整合参数pb的值。即,控制部11获取各学习完毕的机器学习模型45b的学习环境数据35b。接着,控制部11计算各份学习环境数据35b及环境数据63b的适合度。适合度的形式及表现可以与上述实施方式是同样的。在上述步骤s211中,控制部11也可以根据计算出的各适合度,来确定针对对应的各学习完毕的机器学习模型45b的各整合参数pb的值。根据适合度确定整合参数pb的值的方法可以与上述实施方式是同样的。
[0559]
(3)第三方法
[0560]
在第三方法中,控制部11接收操作者对整合参数pb的值的指定,并将对象的整合参数pb的值设定为指定的值。接收画面可以与上述实施方式是同样的(图12a)。
[0561]
返回到图19a,在步骤s211中,控制部11通过采用上述三种方法中的至少任一种方法,能够确定各整合参数pb的值。在步骤s212中,控制部11使用所确定的各整合参数pb的值,对对应的各学习完毕的机器学习模型45b的预测结果进行加权。在通过上述第三方法设定了多个整合参数pb中的至少任一个整合参数pb的值的情况下,在步骤s212中,控制部11使用上述设定的值,对与对象的整合参数pb对应的学习完毕的机器学习模型45b的预测结果进行加权。在步骤s213中,控制部11整合各学习完毕的机器学习模型45b的加权后的预测结果。预测结果的整合可以与上述实施方式同样地通过加权平均或加权多数表决来进行。由此,能够生成在对象环境下根据移动体rb的状态预测移动体rb的移动路径的结果。
[0562]
(步骤s205)
[0563]
在步骤s205中,控制部11输出与所生成的预测结果相关的信息。与上述实施方式同样地,输出目的地及输出的信息的内容可以分别根据实施方式适当确定。控制部11也可以将通过步骤s204生成的预测结果直接输出到输出装置16,也可以基于所生成的预测结果执行某信息处理。
[0564]
例如,控制部11也可以基于通过步骤s204生成的预测结果,例如生成表示不拥挤的路径等推荐的移动路径的信息作为与预测结果相关的信息。然后,控制部11也可以向其他移动体输出所生成的表示推荐路径的信息。
[0565]
需要说明的是,与上述实施方式同样地,预测装置1b的控制部11可以将各学习完毕的机器学习模型45b分配给多个组中的至少任一个组。由此,控制部11也可以根据目的按每个组执行整合处理。分组的方法可以采用上述两种方法中的任一种方法。
[0566]
《局部学习装置的推论处理》
[0567]
另外,本变形例所涉及的各局部学习装置2b与上述各局部学习装置2同样地,通过执行步骤s111~步骤s113的处理,能够利用学习完毕的机器学习模型45b预测移动体rb的
移动路径。
[0568]
在步骤s111中,各局部学习装置2b获取预测中利用的对象数据。对象数据的获取方法可以与上述预测装置1b的步骤s201是同样的。在步骤s112中,各局部学习装置2b对学习完毕的机器学习模型45b提供对象数据,执行学习完毕的机器学习模型45b的运算处理。由此,各局部学习装置2b获取预测移动体rb的移动路径的结果,作为学习完毕的机器学习模型45b的输出。
[0569]
在步骤s113中,各局部学习装置2b输出与预测结果相关的信息。输出目的地及输出的信息的内容可以分别根据实施方式适当确定。各局部学习装置2b可以将通过步骤s112得到的推断结果直接输出到输出装置,也可以基于所得到的推断结果执行某信息处理。另外,步骤s113的处理可以与上述预测装置1b的步骤s205同样地执行。
[0570]
《特征》
[0571]
根据本变形例,在由传感器sb1观测移动体rb的移动的场景中,能够降低构建在新的环境下能够适当地预测移动体rb的移动的推论模型花费的成本。另外,通过在传感器sb1的观测环境的观测中利用其他传感器sb2,能够获取充分反映了传感器sb2的观测环境的环境数据63b。由此,能够实现预测装置1b对移动体rb的移动路径的预测精度的提高。
[0572]
需要说明的是,本变形例可以适当变更。例如,在从其他传感器sb2以外获取环境数据63b的情况下,其他传感器sb2可以省略。预测装置1b与各传感器(传感器sa1、其他传感器sa2)可以经由通信接口连接。
[0573]
(c)推断适合于用户的会话策略的场景
[0574]
图20示意性地举例示出第三变形例所涉及的会话系统100c的应用场景的一例。本变形例是将上述实施方式应用于推断适合于用户的会话策略的场景的例子。如图20所示,本变形例所涉及的会话系统100c具备会话装置1c及多个局部学习装置2c。与上述实施方式同样地,会话装置1c及各局部学习装置2c可以经由网络相互连接。
[0575]
会话装置1c与上述推论装置1对应。各局部学习装置2c与上述各局部学习装置2对应。除了处理的数据及推论的内容被限定这一点之外,会话装置1c可以与上述推论装置1同样地构成,各局部学习装置2c可以与上述各局部学习装置2同样地构成。会话装置1c的硬件构成及软件构成可以与上述推论装置1是同样的。各局部学习装置2c的硬件构成及软件构成可以与上述各局部学习装置2是同样的。
[0576]
本变形例所涉及的规定的推论是根据用户rc的会话行动来推断适合于用户rc的会话策略。会话策略提供生成会话的规则。会话策略例如也可以规定说话的会话的内容、说话时机、会话的频率、语调等。用户的会话行动可以包括与用户的会话相关的所有行动。在用户的会话行动中,例如可以包括会话的内容、会话的频率等。会话的频率例如可以通过从上次会话起所经过的时间、到下一次会话为止的平均时间、一定时间内的会话次数等来表现。在本变形例中,麦克风sc1与会话装置1c及各局部学习装置2c连接。用户rc的会话行动由麦克风sc1进行观测。
[0577]
需要说明的是,麦克风sc1是观测用户rc的会话行动的传感器的一例。观测用户rc的会话行动的方法也可以不限于这样的例子,也可以采用麦克风以外的方法。例如,用户rc的会话行动也可以由摄像机进行观测。另外,例如用户rc的会话行动也可以经由键盘等输入装置来获取。
[0578]
本变形例所涉及的各局部学习装置2c生成获得了根据用户rc的会话行动来推断适合于用户rc的会话策略的能力的学习完毕的机器学习模型45c。与此相对,本变形例所涉及的会话装置1c利用根据由各局部学习装置2c在不同环境下得到的局部学习数据30c而被导出的各学习完毕的机器学习模型45c,在对象环境下推断适合于对象用户rc的会话策略。
[0579]
本变形例所涉及的会话装置1c获取成为规定的推论的对象的对象数据61c及与执行规定的推论的对象环境相关的环境数据63c。本变形例所涉及的成为规定的推论的对象的对象数据61c是与对象的用户rc的会话行动相关的数据。另一方面,本变形例所涉及的与执行规定的推论的对象环境相关的环境数据63c是与对象的用户rc进行会话行动的对象会话环境相关的数据。
[0580]
在本变形例中,作为与麦克风sc1不同的其他传感器,照相机sc2进一步与会话装置1c连接。照相机sc2用于观测对象的用户rc进行会话行动的对象会话环境。因此,本变形例所涉及的会话装置1c能够从照相机sc2获取环境数据63c。需要说明的是,观测对象会话环境的传感器也可以不限于照相机,可以根据实施方式适当选择。作为对象会话环境,在考虑气温、天气等的情况下,观测对象会话环境的传感器例如可以使用气温计、气象传感器等。
[0581]
本变形例所涉及的会话装置1c将所获取的对象数据61c提供给各学习完毕的机器学习模型45c,使各学习完毕的机器学习模型45c推断适合于用户rc的会话策略。由此,本变形例所涉及的会话装置1c获取各学习完毕的机器学习模型45c对适合于用户rc的会话策略的推断结果。然后,本变形例所涉及的会话装置1c按照整合规则5c整合各学习完毕的机器学习模型45c的推断结果。
[0582]
与上述实施方式同样地,整合规则5c具备在对象环境下分别规定重视各学习完毕的机器学习模型45c的推断结果的程度的多个整合参数pc。本变形例所涉及的会话装置1c根据环境数据63c确定各整合参数pc的值。此时,除了环境数据63c之外,也可以进一步考虑对象数据61c。接着,本变形例所涉及的会话装置1c使用所确定的各整合参数pc的值,对对应的各学习完毕的机器学习模型45c的推断结果进行加权。然后,本变形例所涉及的会话装置1c整合各学习完毕的机器学习模型45c的加权后的推断结果。
[0583]
由此,本变形例所涉及的会话装置1c能够生成在对象环境下根据对象的用户rc的会话行动推断适合于对象的用户rc的会话策略的结果。
[0584]
《学习完毕的机器学习模型的生成》
[0585]
本变形例所涉及的各局部学习装置2c与上述各局部学习装置2同样地,通过执行步骤s101~步骤s104的处理,来生成学习完毕的机器学习模型45c。即,在步骤s101中,各局部学习装置2c获取局部学习数据30c。然后,在步骤s102中,各局部学习装置2c利用所获取的局部学习数据30c执行机器学习模型40c的机器学习。机器学习模型40c的构成及机器学习的方法可以与上述机器学习模型40是同样的。
[0586]
在本变形例中,机器学习的方法可以采用上述第一例~第三例中的任一者。在采用第一例的情况下,局部学习数据30c由分别包括训练数据及正解数据的组合的多个学习数据集构成。训练数据与上述对象数据61c同种,可以由与用户rc(受试者)的会话行动相关的数据构成。正解数据可以由表示对训练数据的推论的结果(正解)、即适合于该用户rc(受试者)的会话策略的数据构成。各学习数据集可以通过与上述实施方式同样的方法生成。各
局部学习装置2c利用所获取的局部学习数据30c执行机器学习模型40c的有监督学习。有监督学习的方法可以与上述实施方式是同样的。
[0587]
在采用第二例的情况下,局部学习数据30c由多份训练数据构成。训练数据由想要使机器学习模型40c生成的数据构成。训练数据例如由表示适合于用户rc(受试者)的会话策略的数据构成。各份训练数据可以通过与上述实施方式相同的方法生成。各局部学习装置2c利用所获取的局部学习数据30c执行机器学习模型40c及其他机器学习模型的对抗学习。对抗学习的方法可以与上述实施方式是同样的。
[0588]
在采用第三例的情况下,机器学习模型40c可以采用基于价值、基于策略或这两者。成为观测对象的状态可以是与用户rc的会话行动相关的状态,由智能体执行的行动可以是与用户rc的会话。报酬函数也可以由操作者等手动设定。或者,报酬函数也可以设定为根据机器学习模型40c的推断结果的适当度来提供立即报酬。在这种情况下,与上述实施方式同样地,适当度也可以由操作者等手动提供。或者,适当度也可以使用判定器按照规定的基准进行评价。判定器可以构成为对推断适合于用户rc的会话策略的结果的精度进行评价。与此相应地,报酬函数可以设定为基于多次推断处理的试行结果,如果会话策略的推断精度为阈值以上,则提供正的立即报酬,如果会话策略的推断精度为容许值以下,则提供负的立即报酬。需要说明的是,会话策略的推断精度例如可以基于用户rc的会话频率提高等、智能体与用户rc的会话在公共方向上改善来进行评价。或者,报酬函数也可以根据表示专家的演示的事例数据通过逆强化学习来推断。在本变形例中,事例数据例如可以由表示通过熟练者所指定的会话策略的数据构成。各局部学习装置2c调整机器学习模型40c的运算参数的值,以使在适当设定的学习环境中,得到的价值(的期望值)最大化。强化学习的方法可以与上述实施方式是同样的。
[0589]
各局部学习装置2c能够通过上述任一种方法执行机器学习模型40c的机器学习。由此,各局部学习装置2c能够生成获得了根据用户rc的会话行动来推断适合于用户rc的会话策略的能力的学习完毕的机器学习模型45c。
[0590]
在步骤s103中,各局部学习装置2c获取与得到局部学习数据30c的环境相关的学习环境数据35c。学习环境数据35c是与通过会话装置1c得到的环境数据63c同种的数据。获取学习环境数据35c的方法可以与获取环境数据63c的方法是同样的。例如,各局部学习装置2c可以进一步与和照相机sc2同种的照相机连接,也可以从该照相机中获取学习环境数据35c。在步骤s104中,各局部学习装置2c生成与所生成的学习完毕的机器学习模型45c相关的信息作为学习结果数据47c。然后,各局部学习装置2c将学习结果数据47c与学习环境数据35c建立关联地保存在规定的存储区域中。
[0591]
在本变形例中,在各局部学习装置2c之间,局部学习数据30c可以在不同的环境下获取。然后,可以根据得到的局部学习数据30c生成学习完毕的机器学习模型45c。其结果,能够得到以能够推断适合于用户rc的会话策略的方式根据在不同环境下得到的局部学习数据30c而被导出的多个学习完毕的机器学习模型45c。
[0592]
《会话装置的硬件构成》
[0593]
图21示意性地举例示出本变形例所涉及的会话装置1c的硬件构成的一例。如图21所示,本变形例所涉及的会话装置1c与上述推论装置1同样地,是与控制部11、存储部12、通信接口13、外部接口14、输入装置15、输出装置16及驱动器17电连接的计算机。会话装置1c
经由外部接口14与麦克风sc1及照相机sc2连接。不过,会话装置1c的硬件构成也可以不限于这样的例子。关于会话装置1c的具体的硬件构成,可以根据实施方式适当地进行构成要素的省略、替换及追加。会话装置1c除了是设计为所提供的服务专用的信息处理装置之外,可以是通用的服务器装置、通用的pc、便携电话、智能手机、移动pc等。
[0594]
本变形例所涉及的会话装置1c的存储部12存储会话程序81c、整合规则数据57c、学习结果数据47c、学习数据59c、学习环境数据35c等各种信息。会话程序81c、整合规则数据57c、学习结果数据47c、学习数据59c及学习环境数据35c与上述实施方式所涉及的推论程序81、整合规则数据57、学习结果数据47、学习数据59及学习环境数据35对应。会话程序81c、整合规则数据57c、学习结果数据47c、学习数据59c及学习环境数据35c中的至少任一者也可以存储在存储介质91中。另外,会话装置1c也可以从存储介质91中获取会话程序81c、整合规则数据57c、学习结果数据47c、学习数据59c及学习环境数据35c中的至少任一者。
[0595]
《会话装置的软件构成》
[0596]
图22a及图22b示意性地举例示出本变形例所涉及的会话装置1c的软件构成的一例。与上述实施方式同样地,会话装置1c的软件构成通过控制部11执行会话程序81c而实现。如图22a及图22b所示,除了处理的数据及推论的内容被限定这一点之外,会话装置1c的软件构成与上述推论装置1的软件构成是同样的。由此,会话装置1c与上述推论装置1同样地执行与上述推论相关的一系列处理。
[0597]
(步骤s201)
[0598]
即,如图22a所示,在步骤s201中,会话装置1c的控制部11获取对象数据61c。对象数据61c只要是与对象的用户rc的会话行动相关的数据即可,其内容也可以不特别限定,可以根据实施方式适当选择。在对象数据61c中,例如可以包括由观测对象的用户rc的会话行动的传感器得到的观测数据、表示根据观测数据分析的会话信息的数据等。观测会话行动的传感器例如可以是麦克风、照相机、摄像机等。另外,根据观测数据分析的会话信息例如可以包括会话的内容、会话的频率、会话装置1c与用户rc之间的距离等。会话信息的分析可以采用公知的方法。另外,会话的内容、会话的频率等会话信息也可以根据经由输入装置15进行的用户rc的输入行动来确定。
[0599]
获取对象数据61c的方法也可以不特别限定,可以根据实施方式适当选择。例如,可以获取由观测会话行动的传感器得到的观测数据作为对象数据61c。在本变形例中,由于麦克风sc1与会话装置1c连接,因此控制部11能够获取由麦克风sc1得到的声音数据作为对象数据61c。另外,例如也可以通过对由传感器得到的观测数据执行某分析处理来获取对象数据61c。在本变形例中,也可以对由麦克风sc1得到的声音数据执行某分析处理(例如,语音分析),获取由此得到的分析结果(例如,会话的字符串)作为对象数据61c。另外,例如也可以基于用户rc经由输入装置15的输入行动来获取对象数据61c。控制部11可以从各装置直接获取对象数据61c,也可以经由其他计算机间接获取对象数据61c。
[0600]
(步骤s202)
[0601]
在步骤s202中,控制部11获取环境数据63c。环境数据63c只要是与对象的用户rc进行会话行动的对象会话环境相关的数据即可,其内容也可以不特别限定,可以根据实施方式适当选择。在环境数据63c中,例如可以包括表示用户rc的属性的数据、表示对会话行
动产生影响的环境属性的数据、表示与观测会话行动的传感器的规格(或性能)相关的属性的数据等。在用户rc的属性中,例如可以包括用户rc的年龄、性别、职业、出生地、性格类型等。在对会话行动产生异教的环境属性中,例如可以包括气温、天气、星期几、假日/平日的种类等。与传感器的规格相关的属性例如可以包括传感器的灵敏度极限、动态范围、空间分辨率的可设定范围、采样频率的可设定范围等。
[0602]
获取环境数据63c的方法也可以不特别限定,可以根据实施方式适当选择。例如,环境数据63c也可以通过用户等的输入来获取。另外,例如环境数据63c也可以从观测会话行动的传感器中获取。在本变形例中,也可以将从麦克风sc1得到的与规格相关的信息作为环境数据63c来获取。另外,例如环境数据63c也可以通过对由观测会话行动的传感器得到的观测数据执行某分析处理来获取。在本变形例中,也可以对由麦克风sc1得到的声音数据执行某分析处理(例如,语音分析),获取由此得到的分析结果(例如,识别用户的性别的结果)作为环境数据63c。另外,例如环境数据63c也可以从观测对象会话环境的其他传感器中获取。在本变形例中,作为其他传感器,照相机sc2与会话装置1c连接。因此,也可以获取由照相机sc2得到的图像数据作为环境数据63c。另外,例如环境数据63c也可以通过对由其他传感器得到的观测数据执行某分析处理来获取。在本变形例中,也可以对由照相机sc2得到的图像数据执行某分析处理(例如,识别用户的属性的图像分析),获取由此得到的分析结果(用户的属性的识别结果)作为环境数据63c。另外,例如也可以从发布气象数据等信息的其他信息处理装置(服务器)中获取环境数据63c。控制部11可以从各装置直接获取环境数据63c,也可以经由其他计算机间接获取环境数据63c。
[0603]
(步骤s203)
[0604]
在步骤s203中,控制部11通过参照各份学习结果数据47c来进行各学习完毕的机器学习模型45c的设定。接着,控制部11对各学习完毕的机器学习模型45c提供对象数据61c,执行各学习完毕的机器学习模型45c的运算处理。由此,控制部11获取各学习完毕的机器学习模型45c对适合于用户rc的会话策略的推断结果,作为各学习完毕的机器学习模型45c的输出。
[0605]
(步骤s204)
[0606]
在步骤s204中,控制部11参照整合规则数据57c进行整合规则5c的设定。然后,控制部11按照整合规则5c整合各学习完毕的机器学习模型45c的推断结果。具体而言,在步骤s211中,控制部11根据环境数据63c确定各整合参数pc的值。此时,除了环境数据63c之外,也可以进一步考虑对象数据61c。确定各整合参数pc的值的方法可以采用上述第一~第三方法中的任一种方法。
[0607]
(1)第一方法
[0608]
如图22b所示,在采用第一方法的情况下,控制部11获取学习数据59c。然后,控制部11利用学习数据59c执行运算模型51c的机器学习。运算模型51c的构成及机器学习的方法可以与上述运算模型51是同样的。运算模型51c的构成及机器学习的方法可以采用上述两个例子中的任一个例子。
[0609]
在采用第一例的情况下,学习数据59c与上述学习数据59同样地,可以由分别包括训练用环境数据、训练用对象数据及正解数据的组合的多个学习数据集构成。训练用环境数据是与环境数据63c同种的数据。训练用对象数据是与对象数据61c同种的数据。正解数
据可以由表示对训练用对象数据的推论的结果(正解)、即在对象环境下适合于用户rc的会话策略的数据构成。各学习数据集可以通过与上述实施方式同样的方法生成。控制部11利用所获取的学习数据59c执行运算模型51c的机器学习。机器学习的方法可以与上述第一例是同样的。
[0610]
在采用第二例的情况下,运算模型51c可以采用基于价值、基于策略或这两者。与上述实施方式同样地,成为观测对象的状态与环境数据63c及对象数据61c对应。由智能体执行的行动可以是与用户rc的会话。智能体通过上述一系列处理获取各学习完毕的机器学习模型45c的推断结果,通过整合所获取的推断结果,能够在对象环境下生成适合于用户rc的会话策略的推断结果。智能体也可以基于所生成的推断结果(即,所推断的最佳会话策略)确定采用的会话行动。
[0611]
报酬函数也可以由操作者等手动设定。或者,报酬函数也可以设定为根据通过上述一系列处理生成的推断结果的适当度来提供立即报酬。适当度也可以由操作者等手动提供。或者,适当度也可以使用判定器按照规定的基准进行评价。判定器可以与上述机器学习模型40c的强化学习中的判定器是同样的。或者,报酬函数也可以根据表示专家的演示的事例数据通过逆强化学习来推断。该事例数据可以与在上述机器学习模型40c的强化学习中的报酬函数的设定中利用的事例数据是同样的。控制部11调整运算模型51c的运算参数的值,以使在适当设定的学习环境中,得到的价值(的期望值)最大化。强化学习的方法可以与上述实施方式是同样的。
[0612]
控制部11能够通过上述任一种方法来执行运算模型51c的机器学习。由此,控制部11能够生成获得了根据环境数据63c(及对象数据61c)推断适合于会话策略的推断的各整合参数pc的值的能力的学习完毕的运算模型52c,其中,该会话策略适合于对象会话环境下的用户rc。控制部11也可以将与所生成的学习完毕的运算模型52c相关的信息保存在规定的存储区域中。与学习完毕的运算模型52c相关的信息可以作为整合规则数据57c的至少一部分保存,也可以与整合规则数据57c分开保存。
[0613]
在第一方法中,控制部11利用上述生成的学习完毕的运算模型52c确定各整合参数pc的值。即,在步骤s211中,控制部11对学习完毕的运算模型52c提供环境数据63c。此时,控制部11可以进一步对学习完毕的运算模型52c提供对象数据61c。然后,控制部11执行学习完毕的运算模型52c的运算处理。由此,控制部11能够获取针对各学习完毕的机器学习模型45c的各整合参数pc的值,作为学习完毕的运算模型52c的输出。
[0614]
(2)第二方法
[0615]
在第二方法中,控制部11基于对象环境与各学习环境的比较,来确定各整合参数pc的值。即,控制部11获取各学习完毕的机器学习模型45c的学习环境数据35c。接着,控制部11计算各份学习环境数据35c及环境数据63c的适合度。适合度的形式及表现可以与上述实施方式是同样的。在上述步骤s211中,控制部11也可以根据计算出的各适合度来确定针对对应的各学习完毕的机器学习模型45c的各整合参数pc的值。根据适合度确定整合参数pc的值的方法可以与上述实施方式是同样的。
[0616]
(3)第三方法
[0617]
在第三方法中,控制部11接收操作者对整合参数pc的值的指定,并将对象的整合参数pc的值设定为指定的值。接收画面可以与上述实施方式是同样的(图12a)。
[0618]
返回到图22a,在步骤s211中,控制部11通过采用上述三种方法中的至少任一种方法,能够确定各整合参数pc的值。在步骤s212中,控制部11使用所确定的各整合参数pc的值,对对应的各学习完毕的机器学习模型45c的推断结果进行加权。在通过上述第三方法设定了多个整合参数pc中的至少任一个整合参数pc的值的情况下,在步骤s212中,控制部11使用上述设定的值,对与对象的整合参数pc对应的学习完毕的机器学习模型45c的推断结果进行加权。在步骤s213中,控制部11整合各学习完毕的机器学习模型45c的加权后的推断结果。推断结果的整合也可以与上述实施方式同样地通过加权平均或加权多数表决来进行。由此,能够在对象环境下生成推断适合于对象的用户rc的会话策略的结果。
[0619]
(步骤s205)
[0620]
在步骤s205中,控制部11输出与所生成的推断结果相关的信息。与上述实施方式同样地,输出目的地及输出的信息的内容可以分别根据实施方式适当确定。控制部11可以将通过步骤s204生成的推断结果直接输出到输出装置16,也可以基于所生成的推断结果执行某信息处理。
[0621]
例如,控制部11也可以基于所生成的推断结果、即所推断的适合于用户rc的会话策略,与用户rc进行会话。控制部11也可以经由扬声器、显示器等输出装置16输出会话内容。会话的输出可以是语音输出,也可以是图像输出。另外,会话的输出目的地也可以不限于输出装置16。控制部11也可以经由其他计算机与用户rc进行会话。
[0622]
需要说明的是,与上述实施方式同样地,会话装置1c的控制部11可以将各学习完毕的机器学习模型45c分配给多个组中的至少任一个组。由此,控制部11也可以根据目的按每个组执行整合处理。分组的方法可以采用上述两种方法中的任一种方法。
[0623]
《局部学习装置的推论处理》
[0624]
另外,本变形例所涉及的各局部学习装置2c与上述各局部学习装置2同样地,通过执行步骤s111~步骤s113的处理,能够利用学习完毕的机器学习模型45c来推断适合于用户rc的会话策略。
[0625]
在步骤s111中,各局部学习装置2c获取在推断中利用的对象数据。对象数据的获取方法可以与上述会话装置1c的步骤s201是同样的。在步骤s112中,各局部学习装置2c对学习完毕的机器学习模型45c提供对象数据,执行学习完毕的机器学习模型45c的运算处理。由此,各局部学习装置2c获取推断适合于用户rc的会话策略的结果,作为学习完毕的机器学习模型45c的输出。
[0626]
在步骤s113中,各局部学习装置2c输出与推断结果相关的信息。输出目的地及输出的信息的内容可以分别根据实施方式适当确定。各局部学习装置2c可以将通过步骤s112得到的推断结果直接输出到输出装置,也可以基于所得到的推断结果执行某信息处理。另外,与上述会话装置1c的步骤s205同样地,作为输出处理,各局部学习装置2c也可以基于所推断的适合于用户rc的会话策略与用户rc进行会话。
[0627]
《特征》
[0628]
根据本变形例,在与用户rc之间进行会话的场景中,能够降低构建在新的环境中能够适当地推断适合于对象的用户rc的会话策略的推论模型花费的成本。另外,与此相应地,能够缩短构建这样的推论模型花费的时间。
[0629]
在构建能够适当地推断适合于用户rc的会话策略的推论模型花费时间的情况下,
在该构建期间,有可能会重复进行基于不适合于用户rc的会话策略的会话。由此,用户rc有可能会感到与会话装置的会话烦人,并停止利用会话装置。与此相对,根据本变形例,由于能够缩短构建能够适当地推断适合于用户rc的会话策略的推论模型花费的时间,因此能够提高会话装置1c的利用性。
[0630]
需要说明的是,本变形例可以适当变更。例如,在从麦克风sc1以外获取对象数据61c的情况下,麦克风sc1可以省略。在从照相机sc2以外获取环境数据63c的情况下,照相机sc2可以省略。会话装置1c与各传感器(麦克风sc1、照相机sc2)也可以经由通信接口连接。
[0631]
(d)推断适合于任务的动作指令的场景
[0632]
图23示意性地举例示出第四变形例所涉及的控制系统100d的应用场景的一例。本变形例是将上述实施方式应用于推断适合于任务的动作指令的场景的例子。如图23所示,本变形例所涉及的控制系统100d具备控制装置1d及多个局部学习装置2d。与上述实施方式同样地,控制装置1d及各局部学习装置2d可以经由网络相互连接。
[0633]
控制装置1d与上述推论装置1对应。各局部学习装置2d与上述各局部学习装置2对应。除了处理的数据及推论的内容被限定这一点之外,控制装置1d可以与上述推论装置1同样地构成,各局部学习装置2d可以与上述各局部学习装置2同样地构成。控制装置1d的硬件构成及软件构成可以与上述推论装置1是同样的。各局部学习装置2d的硬件构成及软件构成可以与上述各局部学习装置2是同样的。
[0634]
本变形例所涉及的规定的推论是根据机器人装置rd的状态推断适合于任务的机器人装置rd的动作指令。机器人装置rd及任务各自的种类也可以不特别限定,可以根据实施方式适当选择。机器人装置rd例如可以是工业用机器人、设备装置、可自动驾驶的车辆等。设备装置例如可以是空调设备、照明装置等。在机器人装置rd是工业用机器人的情况下,任务例如可以是将工件配置在目标位置、等等。在机器人装置rd是空调设备等设备装置的情况下,任务例如是保持在规定温度等,可以根据设备装置的种类适当确定。在机器人装置rd是可自动驾驶的车辆的情况下,任务例如可以是通过自动驾驶从当前位置移动到目标位置、等等。在本变形例中,机器人装置rd分别与控制装置1d及各局部学习装置2d连接。由此,控制装置1d及各局部学习装置2d能够分别基于所推断的动作指令来控制机器人装置rd的动作。
[0635]
本变形例所涉及的各局部学习装置2d生成获得了根据机器人装置rd的状态推断适合于任务的机器人装置rd的动作指令的能力的学习完毕的机器学习模型45d。与此相对,本变形例所涉及的控制装置1d利用根据由各局部学习装置2d在不同环境下得到的局部学习数据30d而被导出的各学习完毕的机器学习模型45d,推断在对象环境下适合于对象的机器人装置rd的任务的动作指令。
[0636]
本变形例所涉及的控制装置1d获取成为规定的推论的对象的对象数据61d及与执行规定的推论的对象环境相关的环境数据63d。本变形例所涉及的成为规定的推论的对象的对象数据61d是与对象的机器人装置rd的状态相关的数据。另一方面,本变形例所涉及的与执行规定的推论的对象环境相关的环境数据63d是与对象的机器人装置rd完成任务的对象任务环境相关的数据。
[0637]
在本变形例中,传感器sd进一步与控制装置1d连接。传感器sd例如是照相机等,用于观测对象的机器人装置rd的状态。因此,本变形例所涉及的控制装置1d能够从传感器sd
中获取对象数据61d。需要说明的是,可以由传感器sd或其他传感器观测对象任务环境。在这种情况下,本变形例所涉及的控制装置1d也可以从传感器sd或其他传感器中获取环境数据63d。
[0638]
本变形例所涉及的控制装置1d将所获取的对象数据61d提供给各学习完毕的机器学习模型45d,使各学习完毕的机器学习模型45d推断适合于任务的机器人装置rd的动作指令。由此,本变形例所涉及的控制装置1d获取各学习完毕的机器学习模型45d对适合于任务的机器人装置rd的动作指令的推断结果。然后,本变形例所涉及的控制装置1d按照整合规则5d整合各学习完毕的机器学习模型45d的推断结果。
[0639]
与上述实施方式同样地,整合规则5d具备在对象环境下分别规定重视各学习完毕的机器学习模型45d的推断结果的程度的多个整合参数pd。本变形例所涉及的控制装置1d根据环境数据63d确定各整合参数pd的值。此时,除了环境数据63d之外,也可以进一步考虑对象数据61d。接着,本变形例所涉及的控制装置1d使用所确定的各整合参数pd的值,对对应的各学习完毕的机器学习模型45d的推断结果进行加权。然后,本变形例所涉及的控制装置1d整合各学习完毕的机器学习模型45d的加权后的推断结果。
[0640]
由此,本变形例所涉及的控制装置1d能够推断在对象环境下适合于对象的机器人装置rd的任务的动作指令。
[0641]
《学习完毕的机器学习模型的生成》
[0642]
本变形例所涉及的各局部学习装置2d与上述各局部学习装置2同样地,通过执行步骤s101~步骤s104的处理,生成学习完毕的机器学习模型45d。即,在步骤s101中,各局部学习装置2d获取局部学习数据30d。然后,在步骤s102中,各局部学习装置2d利用所获取的局部学习数据30d执行机器学习模型40d的机器学习。机器学习模型40d的构成及机器学习的方法可以与上述机器学习模型40是同样的。
[0643]
在本变形例中,机器学习的方法可以采用上述第一例~第三例中的任一者。在采用第一例的情况下,局部学习数据30d由分别包括训练数据及正解数据的组合的多个学习数据集构成。训练数据与上述对象数据61d同种,可以由与机器人装置rd的状态相关的数据构成。正解数据可以由表示对训练数据的推论的结果(正解)、即适合于该任务的完成的机器人装置rd的动作指令的数据构成。各学习数据集可以通过与上述实施方式同样的方法生成。各局部学习装置2d利用所获取的局部学习数据30d,执行机器学习模型40d的有监督学习。有监督学习的方法可以与上述实施方式是同样的。
[0644]
在采用第二例的情况下,局部学习数据30d由多份训练数据构成。训练数据由想要使机器学习模型40d生成的数据构成。训练数据例如由表示适合于任务的完成的机器人装置rd的动作指令的数据构成。各局部学习装置2d利用所获取的局部学习数据30d,执行机器学习模型40d和其他机器学习模型的对抗学习。对抗学习的方法可以与上述实施方式是同样的。
[0645]
在采用第三例的情况下,机器学习模型40d可以采用基于价值、基于策略或这两者。成为观测对象的状态可以是与机器人装置rd的内部及外部中的至少一方的状况相关的状态。由智能体执行的行动可以是基于动作指令的动作。报酬函数也可以由操作者等手动设定。或者,报酬函数也可以设定为根据机器学习模型40d的推断结果的适当度来提供立即报酬。在这种情况下,与上述实施方式同样地,适当度也可以由操作者等手动提供。或者,适
当度也可以使用判定器按照规定的基准进行评价。判定器可以构成为对推断适合于任务的动作指令的结果的精度进行评价。与此相应地,报酬函数可以设定为基于多次推断处理的试行结果,如果动作指令的推断精度为阈值以上,则提供正的立即报酬,如果动作指令的推断精度为容许值以下,则提供负的立即报酬。需要说明的是,动作指令的推断精度例如可以基于是否适当完成了对象的任务等任务的完成状况进行评价。或者,报酬函数也可以根据表示专家的演示的事例数据通过逆强化学习来推断。在本变形例中,事例数据例如可以由表示熟练者对机器人装置rd的操作轨迹的数据构成。各局部学习装置2d调整机器学习模型40d的运算参数的值,以使在适当设定的学习环境中,得到的价值(的期望值)最大化。强化学习的方法可以与上述实施方式是同样的。
[0646]
各局部学习装置2d能够通过上述任一种方法来执行机器学习模型40d的机器学习。由此,各局部学习装置2d能够生成获得了根据机器人装置rd的状态推断适合于任务的机器人装置rd的动作指令的能力的学习完毕的机器学习模型45d。
[0647]
在步骤s103中,各局部学习装置2d获取与得到局部学习数据30d的环境相关的学习环境数据35d。学习环境数据35d是与通过控制装置1d得到的环境数据63d同种的数据。获取学习环境数据35d的方法可以与获取环境数据63d的方法是同样的。在步骤s104中,各局部学习装置2d生成与所生成的学习完毕的机器学习模型45d相关的信息作为学习结果数据47d。然后,各局部学习装置2d将学习结果数据47d与学习环境数据35d建立关联地保存在规定的存储区域中。
[0648]
在本变形例中,在各局部学习装置2d之间,局部学习数据30d可以在不同的环境下获取。然后,可以根据所得到的局部学习数据30d生成学习完毕的机器学习模型45d。其结果,能够得到以能够推断适合于任务的机器人装置rd的动作指令的方式根据在不同环境下得到的局部学习数据30d导出的多个学习完毕的机器学习模型45d。
[0649]
图24示意性地举例示出本变形例所涉及的控制装置1d的硬件构成的一例。如图24所示,本变形例所涉及的控制装置1d与上述推论装置1同样地,是与控制部11、存储部12、通信接口13、外部接口14、输入装置15、输出装置16及驱动器17电连接的计算机。控制装置1d经由外部接口14与机器人装置rd及传感器sd连接。不过,控制装置1d的硬件构成也可以不限于这样的例子。关于控制装置1d的具体的硬件构成,可以根据实施方式适当地进行构成要素的省略、替换及追加。控制装置1d除了是设计为所提供的服务专用的信息处理装置之外,可以是通用的服务器装置、通用的pc、plc等。
[0650]
本变形例所涉及的控制装置1d的存储部12存储控制程序81d、整合规则数据57d、学习结果数据47d、学习数据59d、学习环境数据35d等各种信息。控制程序81d、整合规则数据57d、学习结果数据47d、学习数据59d及学习环境数据35d与上述实施方式所涉及的推论程序81、整合规则数据57、学习结果数据47、学习数据59及学习环境数据35对应。控制程序81d、整合规则数据57d、学习结果数据47d、学习数据59d及学习环境数据35d中的至少任一者也可以存储在存储介质91中。另外,控制装置1d也可以从存储介质91中获取控制程序81d、整合规则数据57d、学习结果数据47d、学习数据59d及学习环境数据35d中的至少任一者。
[0651]
《控制装置的软件构成》
[0652]
图25a及图25b示意性地举例示出本变形例所涉及的控制装置1d的软件构成的一
例。与上述实施方式同样地,控制装置1d的软件构成通过控制部11执行控制程序81d而实现。如图25a及图25b所示,除了处理的数据及推论的内容被限定这一点之外,控制装置1d的软件构成与上述推论装置1的软件构成是同样的。由此,控制装置1d与上述推论装置1同样地执行与上述推论相关的一系列处理。
[0653]
(步骤s201)
[0654]
即,如图25a所示,在步骤s201中,控制装置1d的控制部11获取对象数据61d。对象数据61d只要是与对象的机器人装置rd的状态相关的数据即可,其内容也可以不特别限定,可以根据实施方式适当选择。在对象数据61d中,例如可以包括表示机器人装置rd的内部状况的数据、表示机器人装置rd的外部状况的数据等。
[0655]
在机器人装置rd是工业用机器人的情况下,机器人装置rd的内部状况例如可以包括由编码器测量的各关节的角度、由力传感器测量的作用于末端执行器的力等,机器人装置rd的外部状况例如可以包括工件的状态、作业范围的状态等。工件的状态及作业范围的状态例如可以由照相机等传感器进行观测。
[0656]
另外,在机器人装置rd是设备装置的情况下,机器人装置rd的内部状况例如可以包括设备装置的动作设定(例如,空调温度)等,机器人装置rd的外部状况例如可以包括设备装置的动作范围的状态等。在设备装置是空调装置的情况下,设备装置的动作范围的状态例如可以包括由温度传感器得到的室内温度。
[0657]
在机器人装置rd是可自动驾驶的车辆的情况下,机器人装置rd的内部状况例如可以包括方向盘的转向角、油门量、制动量、喇叭操作的有无等,机器人装置rd的外部状况例如可以包括障碍物的有无、行驶道路的状态等车辆外部的状况。车辆外部的状况例如可以由照相机、激光雷达传感器等进行观测。
[0658]
获取对象数据61d的方法也可以不特别限定,可以根据实施方式适当选择。例如,也可以从机器人装置rd自身获取表示内部状况的数据作为对象数据61d。另外,例如对象数据61d也可以从观测机器人装置rd的内部状况的传感器中获取。观测机器人装置rd的内部状况的传感器例如可以使用编码器、力传感器等。另外,例如对象数据61d也可以从观测机器人装置rd的外部状况的传感器中获取。观测机器人装置rd的外部状况的传感器例如可以使用照相机、激光雷达传感器、红外线传感器等。另外,例如也可以通过操作者等的输入来获取对象数据61d。控制部11可以从各装置直接获取对象数据61d,也可以经由其他计算机间接获取对象数据61d。在本变形例中,观测机器人装置rd的外部状况的传感器sd与控制装置1d连接。因此,控制部11能够从传感器sd获取对象数据61d。
[0659]
(步骤s202)
[0660]
在步骤s202中,控制部11获取环境数据63d。环境数据63d只要是与对象的机器人装置rd完成任务的对象任务环境相关的数据即可,其内容也可以不特别限定,可以根据实施方式适当选择。在环境数据63d中,例如也可以包括表示机器人装置rd的属性的数据、表示与观测机器人装置rd的状态的传感器的规格(或性能)相关的属性的数据、表示与传感器的观测条件相关的属性的数据等。
[0661]
在机器人装置rd的属性中,例如可以包括机器人装置rd的类别、机器人装置rd的性能等。在机器人装置rd是工业用机器人的情况下,机器人装置rd的性能例如可以通过驱动范围、承载重量等来表现。在机器人装置rd是空调装置的情况下,机器人装置rd的性能例
如可以通过温度控制范围等来表现。在机器人装置rd是可自动驾驶的车辆的情况下,机器人装置rd的性能例如可以通过极限行驶速度等来表现。
[0662]
与传感器的规格相关的属性例如可以包括传感器的灵敏度极限、动态范围、空间分辨率的可设定范围、采样频率的可设定范围等。与传感器的观测条件相关的属性例如可以包括传感器的设置角度、传感器的动作设定相关的属性等。与传感器的动作设定相关的属性例如可以包括传感器的测量范围的设定值、测量范围的分辨率的设定值、采样频率的设定值等。作为具体例,在传感器是照相机的情况下,与动作设定相关的属性可以包括光圈值、快门速度、变焦倍率等。
[0663]
获取环境数据d的方法也可以不特别限定,可以根据实施方式适当选择。例如,环境数据63d也可以通过操作者等的输入来获取。另外,例如环境数据63d也可以从机器人装置rd自身或提供机器人装置rd的信息的其他信息处理装置(服务器)中获取。另外,例如环境数据63d也可以从观测机器人装置rd的状态的传感器自身或提供传感器的信息的其他信息处理装置(服务器)中获取。控制部11可以从各装置直接获取环境数据63d,也可以经由其他计算机间接获取环境数据63d。
[0664]
(步骤s203)
[0665]
在步骤s203中,控制部11通过参照各份学习结果数据47d来进行各学习完毕的机器学习模型45d的设定。接着,控制部11对各学习完毕的机器学习模型45d提供对象数据61d,执行各学习完毕的机器学习模型45d的运算处理。由此,控制部11获取各学习完毕的机器学习模型45d对适合于任务的机器人装置rd的动作指令的推断结果,作为各学习完毕的机器学习模型45d的输出。
[0666]
(步骤s204)
[0667]
在步骤s204中,控制部11参照整合规则数据57d进行整合规则5d的设定。然后,控制部11按照整合规则5d整合各学习完毕的机器学习模型45d的推断结果。具体而言,在步骤s211中,控制部11根据环境数据63d确定各整合参数pd的值。此时,除了环境数据63d之外,也可以进一步考虑对象数据61d。确定各整合参数pd的值的方法可以采用上述第一~第三方法中的任一者。
[0668]
(1)第一方法
[0669]
如图25b所示,在采用第一方法的情况下,控制部11获取学习数据59d。然后,控制部11利用学习数据59d执行运算模型51d的机器学习。运算模型51d的构成及机器学习的方法可以与上述运算模型51是同样的。运算模型51d的构成及机器学习的方法可以采用上述两个例子中的任一个例子。
[0670]
在采用第一例的情况下,学习数据59d与上述学习数据59同样地,可以由分别包括训练用环境数据、训练用对象数据及正解数据的组合的多个学习数据集构成。训练用环境数据是与环境数据63d同种的数据。训练用对象数据是与对象数据61d同种的数据。正解数据可以由表示对训练用对象数据的推论的结果(正解)、即在对象环境下适合于任务的完成的机器人装置rd的动作指令的数据构成。各学习数据集可以通过与上述实施方式同样的方法生成。控制部11利用所获取的学习数据59d执行运算模型51d的机器学习。机器学习的方法可以与上述第一例是同样的。
[0671]
在采用第二例的情况下,运算模型51d可以采用基于价值、基于策略或这两者。与
上述实施方式同样地,成为观测对象的状态与环境数据63d及对象数据61d对应。由智能体执行的行动可以是基于动作指令的动作。智能体通过上述一系列处理获取各学习完毕的机器学习模型45d的推断结果,通过整合所获取的推断结果,能够在对象环境下生成适合于任务的机器人装置rd的动作指令的推断结果。智能体也可以基于所生成的推断结果(即,所推断的最佳动作指令)确定采用的动作。
[0672]
报酬函数也可以由操作者等手动设定。或者,报酬函数也可以设定为根据通过上述一系列处理生成的推断结果的适当度来提供立即报酬。适当度也可以由操作者等手动提供。或者,适当度也可以使用判定器按照规定的基准进行评价。判定器可以与上述机器学习模型40d的强化学习中的判定器是同样的。或者,报酬函数也可以根据表示专家的演示的事例数据通过逆强化学习来推断。该事例数据可以与在上述机器学习模型40d的强化学习中的报酬函数的设定中利用的事例数据是同样的。控制部11调整运算模型51d的运算参数的值,以使在适当设定的学习环境中,得到的价值(的期望值)最大化。强化学习的方法可以与上述实施方式是同样的。
[0673]
控制部11能够通过上述任一种方法来执行运算模型51d的机器学习。由此,控制部11能够生成获得了根据环境数据63d(及对象数据61d)推断适合于动作指令的推断的各整合参数pd的值的能力的学习完毕的运算模型52d,其中,该动作指令在对象任务环境下适合于对象的机器人装置rd的任务。控制部11也可以将与所生成的学习完毕的运算模型52d相关的信息保存在规定的存储区域中。与学习完毕的运算模型52d相关的信息可以作为整合规则数据57d的至少一部分保存,也可以与整合规则数据57d分开保存。
[0674]
在第一方法中,控制部11利用上述生成的学习完毕的运算模型52d确定各整合参数pd的值。即,在步骤s211中,控制部11对学习完毕的运算模型52d提供环境数据63d。此时,控制部11可以进一步对学习完毕的运算模型52d提供对象数据61d。然后,控制部11执行学习完毕的运算模型52d的运算处理。由此,控制部11能够获取针对各学习完毕的机器学习模型45d的各整合参数pd的值,作为学习完毕的运算模型52d的输出。
[0675]
(2)第二方法
[0676]
在第二方法中,控制部11基于对象环境与各学习环境的比较,来确定各整合参数pd的值。即,控制部11获取各学习完毕的机器学习模型45d的学习环境数据35d。接着,控制部11计算各份学习环境数据35d和环境数据63d的适合度。适合度的形式及表现可以与上述实施方式是同样的。在上述步骤s211中,控制部11也可以根据计算出的各适合度,来确定针对对应的各学习完毕的机器学习模型45d的各整合参数pd的值。根据适合度确定整合参数pd的值的方法可以与上述实施方式是同样的。
[0677]
(3)第三方法
[0678]
在第三方法中,控制部11接收操作者对整合参数pd的值的指定,并将对象的整合参数pd的值设定为指定的值。接收画面可以与上述实施方式是同样的(图12a)。
[0679]
返回到图25a,在步骤s211中,控制部11通过采用上述三种方法中的至少任一种方法,能够确定各整合参数pd的值。在步骤s212中,控制部11使用所确定的各整合参数pd的值,对对应的各学习完毕的机器学习模型45d的推断结果进行加权。在通过上述第三方法设定了多个整合参数pd中的至少任一个整合参数pd的值的情况下,在步骤s212中,控制部11使用上述设定的值,对与对象的整合参数pd对应的学习完毕的机器学习模型45d的推断结
果进行加权。在步骤s213中,控制部11整合各学习完毕的机器学习模型45d的加权后的推断结果。推断结果的整合可以与上述实施方式同样地通过加权平均或加权多数表决来进行。由此,能够在对象环境下生成推断适合于对象的机器人装置rd的任务的动作指令的结果。
[0680]
(步骤s205)
[0681]
在步骤s205中,控制部11输出与所生成的推断结果相关的信息。与上述实施方式同样地,输出目的地及输出的信息的内容可以分别根据实施方式适当确定。控制部11可以将通过步骤s204生成的推断结果直接输出到输出装置16,也可以基于所生成的推断结果执行某信息处理。
[0682]
例如,控制部11也可以通过将所生成的推断结果、即所推断的适合于任务的动作指令作为与推断结果相关的信息发送给机器人装置rd,来按照所推断的动作指令控制机器人装置rd的动作。此时,控制部11也可以直接控制机器人装置rd。或者,机器人装置rd也可以具备控制器。在这种情况下,控制部11也可以通过向控制器发送动作指令来间接地控制机器人装置rd。
[0683]
另外,例如控制部11也可以生成用于指示用户按照所推断的适合于任务的动作指令操作机器人装置rd的指示信息作为与推断结果相关的信息。然后,控制部11也可以将所生成的指示信息输出到输出装置。输出目的地的输出装置可以是检查装置1a的输出装置16,也可以是其他计算机的输出装置。其他计算机可以是配置在用户附近的计算机,也可以是用户持有的终端装置。
[0684]
需要说明的是,与上述实施方式同样地,控制装置1d的控制部11可以将各学习完毕的机器学习模型45d分配给多个组中的至少任一个组。由此,控制部11也可以根据目的按每个组执行整合处理。分组的方法可以采用上述两种方法中的任一种方法。
[0685]
《局部学习装置的推论处理》
[0686]
另外,本变形例所涉及的各局部学习装置2d与上述各局部学习装置2同样地,通过执行步骤s111~步骤s113的处理,能够利用学习完毕的机器学习模型45d来推断适合于任务的机器人装置rd的动作指令。
[0687]
在步骤s111中,各局部学习装置2d获取推断中利用的对象数据。对象数据的获取方法可以与上述控制装置1d的步骤s201是同样的。在步骤s112中,各局部学习装置2d对学习完毕的机器学习模型45d提供对象数据,执行学习完毕的机器学习模型45d的运算处理。由此,各局部学习装置2d获取推断适合于任务的机器人装置rd的动作指令的结果,作为学习完毕的机器学习模型45d的输出。
[0688]
在步骤s113中,各局部学习装置2d输出与推断结果相关的信息。输出目的地及输出的信息的内容可以分别根据实施方式适当确定。各局部学习装置2d可以将通过步骤s112得到的推断结果直接输出到输出装置,也可以基于所得到的推断结果执行某信息处理。例如,各局部学习装置2d也可以通过将所推断的适合于任务的动作指令发送给机器人装置rd,来按照所推断的动作指令控制机器人装置rd的动作。另外,例如各局部学习装置2d也可以生成用于指示用户按照所推断的适合于任务的动作指令操作机器人装置rd的指示信息,并将所生成的指示信息输出到输出装置。
[0689]
《特征》
[0690]
根据本变形例,在控制机器人装置rd的动作的场景中,能够降低构建在新的环境
中能够适当地推断适合于对象的机器人装置rd的任务的动作指令的推论模型花费的成本。由此,能够抑制生成用于适当地完成任务的动作序列花费的成本。
[0691]
需要说明的是,本变形例可以适当变更。例如,在从传感器sd以外获取对象数据61d的情况下,传感器sd可以省略。控制装置1d与各装置(机器人装置rd、传感器sd)也可以经由通信接口连接。
[0692]
《4.2》
[0693]
在上述实施方式中,推论装置1通过实施运算模型51的机器学习来生成学习完毕的运算模型52。但是,生成学习完毕的运算模型52的主体也可以不限于推论装置1。推论装置1以外的其他计算机也可以通过实施运算模型51的机器学习来生成学习完毕的运算模型52。
[0694]
图26a示意性地举例示出本变形例所涉及的模型生成装置7的硬件构成的一例。模型生成装置7是生成学习完毕的运算模型52的其他计算机的一例。如图26a所示,本变形例所涉及的模型生成装置7是与控制部71、存储部72、通信接口73、外部接口74、输入装置75、输出装置76及驱动器77电连接的计算机。模型生成装置7的控制部71~驱动器77可以与上述推论装置1的控制部11~驱动器77是同样的。不过,模型生成装置7的硬件构成也可以不限于这样的例子。关于模型生成装置7的具体的硬件构成,可以根据实施方式适当地进行构成要素的省略、替换及追加。模型生成装置7除了是设计为所提供的服务专用的信息处理装置之外,可以是通用的服务器装置、通用的pc等。
[0695]
本变形例所涉及的模型生成装置7的存储部72存储生成程序87、整合规则数据57、学习结果数据47、学习数据59等各种信息。生成程序87是用于使模型生成装置7执行与运算模型51的机器学习相关的信息处理的程序。生成程序87包括该信息处理的一系列命令。生成程序87、整合规则数据57、学习结果数据47及学习数据59中的至少任一者也可以存储在存储介质97中。存储介质97可以与上述存储介质91是同样的。另外,模型生成装置7也可以从存储介质97中获取生成程序87、整合规则数据57、学习结果数据47及学习数据59中的至少任一者。
[0696]
图26b示意性地举例示出本变形例所涉及的模型生成装置7的软件构成的一例。与上述实施方式同样地,模型生成装置7的控制部71执行存储在存储部72中的生成程序87。由此,模型生成装置7作为具备学习数据获取部116、学习处理部117及保存处理部118作为软件模块的计算机进行动作。需要说明的是,模型生成装置7的软件模块的一部分或全部也可以通过一个或多个专用的处理器实现。另外,关于模型生成装置7的软件构成,也可以根据实施方式适当地进行软件模块的省略、替换及追加。
[0697]
模型生成装置7通过具备学习数据获取部116、学习处理部117及保存处理部118作为软件模块,来执行上述步骤s301~步骤s303的处理。即,在步骤s301中,控制部71作为学习数据获取部116进行动作,获取学习数据59。在步骤s302中,控制部71作为学习处理部117进行动作,利用学习数据59执行运算模型51的机器学习。在步骤s303中,控制部71作为保存处理部118进行动作,将运算模型51的机器学习的结果、即与学习完毕的运算模型52相关的信息保存在规定的存储区域中。与学习完毕的运算模型52相关的信息可以作为整合规则数据57的至少一部分保存。由此,控制部71能够与上述实施方式同样地生成学习完毕的运算模型52。
[0698]
与所生成的学习完毕的运算模型52相关的信息可以在任意的时机提供给推论装置1。在推论装置1不生成学习完毕的运算模型52的情况下,学习数据获取部116、学习处理部117及保存处理部118也可以从推论装置1的软件构成中省略。另外,也可以从保持在推论装置1的存储部12等中的信息中省略学习数据59。
[0699]
需要说明的是,关于上述变形例所涉及的检查装置1a、预测装置1b、会话装置1c及控制装置1d也可以是同样的。在上述变形例所涉及的检查装置1a、预测装置1b、会话装置1c及控制装置1d中的至少任一者中,学习完毕的运算模型52a~52d可以由其他计算机生成。在这种情况下,学习数据获取部116、学习处理部117及保存处理部118可以从软件构成中省略。
[0700]
《4.3》
[0701]
在上述实施方式中,各局部学习装置2构成为执行学习完毕的机器学习模型45的生成处理、以及利用所生成的学习完毕的机器学习模型45的推论处理这两者。但是,各局部学习装置2的构成也可以不限于这样的例子。多个局部学习装置2中的至少任一者可以由多台计算机构成。在这种情况下,局部学习装置2可以构成为由分开的计算机执行生成处理及推论处理。
[0702]
图27示意性地举例示出本变形例所涉及的局部学习装置2f的构成的一例。在本变形例中,局部学习装置2f具备构成为执行上述生成处理的模型生成装置200、以及构成为执行上述推论处理的模型利用装置201。模型生成装置200及模型利用装置201各自的硬件构成可以与上述实施方式所涉及的各局部学习装置2的硬件构成是同样的。
[0703]
模型生成装置200通过执行学习程序821,从而作为具备学习数据获取部211、环境数据获取部212、学习处理部213及保存处理部214作为软件模块的计算机进行动作。由此,模型生成装置200执行机器学习模型40的机器学习,生成学习完毕的机器学习模型45。
[0704]
另一方面,模型利用装置201通过执行推论程序822,从而作为具备对象数据获取部216、推论部217及输出部218作为软件模块的计算机进行动作。由此,模型利用装置201利用学习完毕的机器学习模型45执行规定的推论。
[0705]
需要说明的是,上述变形例所涉及的各局部学习装置2a~2d中的至少任一者也可以与本变形例同样地构成为由分开的计算机执行生成处理及推论处理。
[0706]
《4.4》
[0707]
在上述实施方式中,各局部学习装置2生成的学习完毕的机器学习模型45的数量也可以不特别限定,可以根据实施方式适当选择。多个局部学习装置2中的至少任一者也可以收集多份不同的局部学习数据30,并使用所得到的各份局部学习数据30来生成多个学习完毕的机器学习模型45。另外,在由一个局部学习装置2生成多个学习完毕的机器学习模型45的情况下,推论装置1中利用的多个学习完毕的机器学习模型45也可以是由一个局部学习装置2生成的模型。
[0708]
另外,在上述实施方式中,各局部学习装置2执行机器学习模型40的机器学习,生成学习完毕的机器学习模型45。但是,机器学习模型40的机器学习(即,学习完毕的机器学习模型45的生成)也可以不一定由各局部学习装置2来执行。机器学习模型40的机器学习也可以由推论装置1、其他信息处理装置等的各局部学习装置2以外的其他计算机来执行。
[0709]
另外,在上述实施方式中,作为执行规定的推论的推论模型的一例,采用了学习完
毕的机器学习模型45。但是,推论模型只要能够执行规定的推论即可,其构成也可以不限于学习完毕的机器学习模型,可以根据实施方式适当选择。导出推论模型的方法也可以不限于机器学习。推论模型例如也可以由人工导出。即,也可以采用参考局部学习数据30、由人启发式地确定的模型作为推论模型。
[0710]
需要说明的是,推论中利用的各推论模型的输出(推论结果)的形式及内容并不一定完全一致。各推论模型的输出的形式及内容中的至少一方在能够整合各推论模型的推论结果的范围内也可以不同。例如,推断关节数量不同的机器人装置的动作指令的多个推论模型可以用于推断对象环境下的机器人装置的动作指令。
[0711]
图28示意性地举例示出本变形例所涉及的推论系统100g的应用场景的一例。除了将学习完毕的机器学习模型45替换为推论模型45g这一点之外,本变形例所涉及的推论系统100g可以与上述推论系统100同样地构成。推论模型45g例如可以通过数据表、函数式、规则等构成。
[0712]
根据局部学习数据30导出推论模型45g的方法也可以不特别限定,可以根据实施方式适当选择。推论模型45g可以由操作局部学习装置2的操作者导出。在推论模型45g由人工导出的情况下,可以从各局部学习装置2的软件构成中省略学习处理部117。保存处理部118也可以将与由人工导出的推论模型45g相关的信息保存在规定的存储区域中。根据该变形例,能够削减在新的环境下由人工创建推论模型的麻烦。
[0713]
需要说明的是,在上述变形例所涉及的检查系统100a、预测系统100b、会话系统100c及控制系统100d中也可以是同样的。在上述检查系统100a、预测系统100b、会话系统100c及控制系统100d中的至少任一者中,也可以利用通过机器学习以外的方法导出的推论模型。例如,各学习完毕的机器学习模型45a~45d也可以替换为参考局部学习数据30a~30d而由人启发式地确定的模型。
[0714]
《4.5》
[0715]
在上述实施方式中,推论装置1保持各推论模型(各学习完毕的机器学习模型45),在步骤s203中,控制部11通过执行各推论模型的运算处理,来获取各推论模型的推论结果。但是,获取各推论模型的推论结果的方法也可以不限于这样的例子。在规定的推论中利用的多个推论模型中的至少任一者也可以不保持在推论装置1中,也可以保持在局部学习装置2、局部学习装置2以外的信息处理装置等其他计算机中。
[0716]
在这种情况下,在上述步骤s203中,控制部11也可以将对象数据61发送给其他计算机,使其他计算机执行推论模型的运算处理。然后,控制部11也可以通过从其他计算机接收运算结果,来获取推论模型的推论结果。与此相应地,可以从保持在推论装置1的存储部12等中的信息中省略对应的学习结果数据47。在上述变形例所涉及的检查系统100a、预测系统100b、会话系统100c及控制系统100d中也可以是同样的。
[0717]
另外,在上述实施方式中,作为确定各整合参数p的值的方法,可以采用上述第一~第三方法。但是,可以省略上述第一~第三方法中的任一者。在省略基于适合度的第二方法的情况下,可以从保持在推论装置1的存储部12等中的信息中省略学习环境数据35。可以从各局部学习装置2的软件构成中省略环境数据获取部212。进而,可以从与学习完毕的机器学习模型45的生成相关的处理过程中省略步骤s103的处理,在步骤s104的处理中,可以省略将学习环境数据35建立关联的处理。另外,在省略基于操作者的指定的第三方法的情
况下,也可以从推论装置1的软件构成中省略参数设定部119。在上述变形例所涉及的检查系统100a、预测系统100b、会话系统100c及控制系统100d中也可以是同样的。
[0718]
另外,在上述实施方式中,各推论模型的分组处理也可以省略。在这种情况下,也可以从推论装置1的软件构成中省略分组部1110。在上述变形例所涉及的检查装置1a、预测装置1b、会话装置1c及控制装置1d中也可以是同样的。
[0719]
§
5实施例
[0720]
为了验证实施上述运算模型51的机器学习的方式的有效性,在openai提供的强化学习的模拟环境中,生成了以下实施例及比较例所涉及的学习完毕的模型。不过,本发明并不限于以下实施例。
[0721]
首先,使用图29对在实施例及比较例的模拟环境中利用的机器人装置(hopper)进行说明。图29示意性地示出在实施例及比较例的模拟环境中利用的机器人装置900的概要。机器人装置900具有通过关节连结多个连杆的构成。多个连杆中与地面接触的下端的连杆是脚(foot)901,与脚901连结的连杆是腿部(leg)902。与腿部902连结的连杆是大腿部(thigh)903,与大腿部903连结的连杆是躯干部(torso)904。机器人装置900进行移动各连杆而前进的运动。在实施例及比较例中,采用以下基本条件,将在一定时间内前进得更多作为报酬来进行强化学习。
[0722]
《基本条件》
[0723]
·
强化学习的方法:ppo(proximal policy optimization:近端策略优化)、基于策略
[0724]
·
环境的并行数:8
[0725]
·
回合(episode)的最大时间步数:2048
[0726]
·
学习率:0.00025
[0727]
·
策略函数的构成:四层全连接型神经网络、第二层及第三层为中间(隐藏)层
[0728]
·
策略函数的中间层:第二层及第三层均为64通道
[0729]
·
价值函数的构成:四层全连接型神经网络、第二层及第三层为中间(隐藏)层
[0730]
·
价值函数的中间层:第二层及第三层均为64通道
[0731]
·
激活函数:tanh函数
[0732]
·
折扣率:0.99
[0733]
·
gae(generated advantage estimation:广义优势估计)参数:0.95
[0734]
·
裁剪宽度:0.2
[0735]
·
批大小:128
[0736]
·
各采样(roll out)后的训练的轮(epoch)数:10
[0737]
·
熵系数:0
[0738]
·
优化算法:adam
[0739]
在实施例中,首先,准备分别具有上述基本条件的构成的四个智能体,对所准备的四个智能体分别进行训练,直到通过强化学习使具有以下表1所示的第一~第四条件各自的动力学的机器人装置900的运动得到最大报酬为止。由此,生成四个学习完毕的模型。
[0740]
[表1]
[0741] 腿部的长度脚的长度连杆的质量关节的衰减
第一条件0.470.36默认值
×
0.80.5第二条件0.440.33默认值
×
0.82.0第三条件0.50.39默认值
×
0.91.5第四条件0.530.42默认值
×
0.91.0
[0742]
接着,准备具有上述基本条件的构成、作为上述实施方式的整合规则5进行动作的智能体。由此,构成了通过整合四个学习完毕的模型的推论结果来确定机器人装置900的动作的实施例所涉及的模型。
[0743]
另一方面,准备具有上述基本条件的构成的智能体,由此,构成了确定机器人装置900的动作的比较例所涉及的模型。
[0744]
然后,分别准备具有以下表2所示的内插条件及外插条件的动力学的机器人装置900,对所准备的各机器人装置900的动作利用实施例及比较例各自的模型通过强化学习各训练三次。然后,计算各试行的平均值。内插条件相当于上述第一~第四条件的范围内的实验样本,外插条件相当于上述第一~第四条件的范围外的实验样本。
[0745]
[表2]
[0746] 腿部的长度脚的长度连杆的质量关节的衰减内插条件0.50.39默认值
×
0.82外插条件0.410.3默认值
×
0.752.5
[0747]
图30a示出在实施例及比较例中通过强化学习训练具有内插条件的动力学的机器人装置900的运动的结果。图30b示出在实施例及比较例中通过强化学习训练具有外插条件的动力学的机器人装置900的运动的结果。纵轴表示在各回合得到的报酬,纵轴表示回合数。
[0748]
如图30a及图30b所示,对于内插条件及外插条件,学习均收敛,以使实施例的模型与比较例相比可在极短时间内得到最大报酬。根据该结果可知,在上述实施方式中,即使在采用了实施运算模型51的机器学习的构成的情况下,与在新的环境下生成新的学习完毕的机器学习模型相比,也能够短时间且低成本地构建能够执行适当的推论的推论模型。
[0749]
附图标记说明
[0750]1…
推论装置、
[0751]
11
…
控制部、12
…
存储部、13
…
通信接口、
[0752]
14
…
外部接口、
[0753]
15
…
输入装置、16
…
输出装置、
[0754]
17
…
驱动器、91
…
存储介质、
[0755]
81
…
推论程序、
[0756]2…
局部学习装置、
[0757]
21
…
控制部、22
…
存储部、23
…
通信接口、
[0758]
24
…
外部接口、
[0759]
25
…
输入装置、26
…
输出装置、
[0760]
27
…
驱动器、92
…
存储介质、
[0761]
821
…
学习程序、822
…
推论程序、
[0762]
225
…
对象数据、
[0763]
30
…
局部学习数据、35
…
学习环境数据、
[0764]
40
…
机器学习模型、45
…
学习完毕的机器学习模型、
[0765]
47
…
学习结果数据、
[0766]5…
整合规则、p1~pn
…
整合参数、
[0767]
51
…
运算模型、52
…
学习完毕的运算模型、
[0768]
57
…
整合规则数据、59学习数据、
[0769]
61
…
对象数据、63
…
环境数据。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1