具身智能体中的记忆的制作方法
1.本文所述实施方案涉及人工智能领域以及用于实现和使用[title]的系统和方法。更具体地,但非排他性地,本文所述实施方案涉及无监督学习。
背景技术:
[0002]
人工智能(ai)的目标是构建具有与人类相似能力的计算机系统,包括类似人类的学习和记忆。大多数当代机器学习技术依赖于“离线”学习,其中ai系统设置有经准备和清理的数据来进行学习,这些数据限于特定域。现有技术所面临的一项挑战在于创建以类似人类的方式体验世界上的对象和事件并从具身交互中学习的ai系统。此类ai智能体凭借其具身化和与环境的感觉运动反馈回路,可以影响和指导自身的学习。此类智能体将理解来自世界的多模态数据流,并以有意义且有用的方式保留信息。所面临的另一项挑战在于创建灵活的ai具身智能体,该智能体不仅能够从其自身体验中学习,而且能够由外部来源(诸如人类用户)编写或改变其记忆。分层时间记忆(htm)是一种复制人类记忆的方法,其基于具有多个寄存器的计算结构,这些寄存器类似于皮质层。htm被配置为复制大脑皮层的补丁。然而,htm无法提供让具身智能体得以从感觉运动体验中实时学习和发展的[title]。
附图说明
[0003]
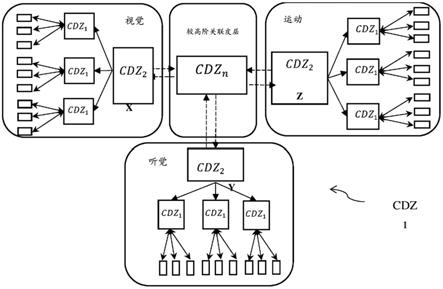
图1:cdz架构示意图。
[0004]
图2:asom。
[0005]
图3:不同模态的资格信号。
[0006]
图4:资格迹如何创建资格窗口。
[0007]
图5:学习事件的阶段。
[0008]
图6:用于设置不同模态的资格的用户界面。
[0009]
图7:asom训练显示画面。
[0010]
图8:查询查看器输入字段。
[0011]
图9:用于指定查询模式的用户界面。
[0012]
图10:ltm和stm显示画面。
[0013]
图11:工作记忆系统(wm系统)。
具体实施方式
[0014]
计算结构为具身智能体提供记忆,该记忆可以从经验中实时填充,和/或编写。具身智能体(可以是虚拟对象、数字实体或机器人)设置有一个或多个影响或引导具身智能体行为的经验记忆存储器。经验记忆存储器可以包括会聚发散区(cdz),该区域模拟人类记忆以在回忆过程中可以重新体验的心理意象或模拟形式表示外部现实的能力。记忆数据库以简单、可编写的方式生成,使经验能够在具身智能体的实时操作中被学习或被编写。基于资格的学习确定来自多模态信息流的哪些方面存储在经验记忆存储器中。
[0015]
经验记忆存储器
[0016]
在一个实施方案中,由智能体体验的经验存储在一个或多个经验记忆存储器中。“经验(experience)”应广义地解释为具身智能体能够感测或感知的任何事物,诸如对象、事件、情绪、观察、动作,或它们的任何组合。经验记忆存储器可以将经验的降维表示存储在神经网络权重中。
[0017]
会聚发散区(cdz)
[0018]
在一个实施方案中,经验记忆存储器被实现为会聚发散区(cdz)。cdz是指从要记录其活性度的位点接收会聚投影并且将发散投影返回到相同位点的网络。cdz保持“配置”的模式:完成部分呈现的感知模式,或响应于此类模式而起作用。分层上游关联记忆关联较低阶感觉和/或运动映射的活性度组合,以形成允许在下游重建分量特性的内隐记忆(例如对象的聚合性质)。例如,存储可用于对象分类的对象经验的经验记忆存储器能够使用如下cdz来实现:每个单模态对象分类路径是一种cdz层级结构,其中对象的显式映射在感知过程中被构建并且在回忆过程中重建。如果已经学习,则激活任何单一较低层级模态中的一种模式都能够触发较高层级多模态cdz中的一种模式。然后,该活性度能够触发活性度“自上而下”流入其他cdz,以激活经验记忆存储器所学到的与初始模式相关联的模式。
[0019]
图1示出了cdz 1的图示。多模态cdz位于每个高层级单模态cdz上方。两种模态x和y之间的相关性保持在单独区域(“会聚区”)z中,该区域独立地连接至x和y两者,而不是通过从x到y的直接连接。表示会聚在来自多个区域的区域z上。该会聚区中的陈述性表示存储较低层级区域中的刺激之间的关联。各种模式被显式激活以显示出关联。当会聚区表示被激活时,它显示出一组较低层级区域中相关联模式的活性度,因此作为“发散区”,其将活性度从单个区域扩散到一系列区域。
[0020]
可以使用能够从若干模态接收输入的映射来实现会聚发散区,然后该会聚发散区可以由这些模态中的任一个模态激活。映射可以是关联自组织映射(asom),其通过从低层级映射中获取激活映射并关联并发激活来关联不同输入。asom接收输入向量,该输入向量的输入字段大小和数量与神经元权重向量相对应,其中每个输入字段表示一种不同模态或输入类型。一旦对多个输入进行了训练,映射就会学习相似输入的拓扑分组。asom可以“自下而上”的构建方式和“自上而下”的重建方式工作。asom能够生成预测,此类预测能够与输入信息进行比较。最低层级(非关联)感觉、运动或其他活性度位点可以实现为映射,诸如自组织映射,或者以任何其他合适的方式实现。
[0021]
图3示出了低层级som和较高层级asom之间的映射,其中asom是聚合区(cdz)的结构构建输入字段。该低层级som包括与视觉、听觉、触觉、神经化学(nc)和位置模态相对应的感觉运动输入。在一组分层结构化cdz中,较低阶cdz som向较高层级cdz som提供输入。作为会聚发散区的较高层级asom包括视觉-听觉-触觉(vat)、视觉-运动(vm)、视觉-神经化学(vnc)。视觉-听觉-触觉(vat)asom会聚发散区与较高层级vat-活性度-位置asom中的位置模态相关联。
[0022]
cdz使实时学习系统能够存储多模态情绪记忆。这就是例如当具身智能体“想象”狗或听到“狗”这个词时,表示狗的高层级asom中的一个或多个神经元被激活的方式。较高层级asom具有指向较低层级视觉(显示狗的图像)、听觉(听到狗吠)甚至情绪状态映射的感觉映射,这些映射再现具身智能体第一次体验狗时感受到的情绪。
[0023]
模态
[0024]“模态”应广义地解释为所存在的某物的方面,包括其表示、表达或经验。对象和/或事件可以不同模态来体验,包括但不限于视觉、听觉、触觉、运动和神经化学。在一个实施方案中,每个模态输入由各个som表示和/或学习。可以使用包括与每个模态相关联的映射的架构,使得当同时体验两个或更多个模态时,该组合被存储在较高层级(关联式)映射中,作为指向其原始较低阶映射中的两种感觉中的每一者的指针。关联映射可以由对应于其关联的任何模态的输入激活。如果仅接收到来自其中一种模态的输入,则可以预测来自其他模态的相应表示。
[0025]
视觉输入可以任何合适的方式被流式传输到具身智能体。在一个实施方案中,经由捕获真实世界环境的相机向具身智能体提供视觉。视觉可以通过用户界面的录屏或以其他方式从计算机系统来传递。因此,具身智能体的视觉能够被引导至真实世界,其可以包括经由相机或“虚拟世界”或计算表示(诸如屏幕表示或vr/ar系统表示)或这两者的任何组合来查看人类用户。“真实世界”和“界面”视野两者都可以表示给具身智能体,使得该具身智能体具有两个单独的视野。每个视野可以具有控制注意力的关联显著性映射。在一个实施方案中,只有一个跨越这两个映射的单一显著区域被选择为引起注意:所以当涉及到注意力例程时,这两个视野可以被视为具有两个部分的单一视野。相机输入的子区域可以自动映射到虚拟“中央凹”:即对应于具身智能体的眼睛被引导至的位置的视频输入的较小区域。中央凹图像子区域可以分模块进一步处理,例如影响分类器和/或对象分类器。这使具身智能体只注意相机输入的一小部分,从而降维。在一个实施方案中,提供28x28rgb中央凹图像。也可以处理外周图像,但分辨率要低得多。
[0026]
音频输入可以经由麦克风传递,从而捕获在听觉系统中处理的波形。在一个实施方案中,用fft和其它技术分析声学特征,以创建声谱图,该声谱图用作听觉som的输入(例如,20
×
14(f
×
t)声谱图)。听觉som学习音频输入的音质映射。替代地或另外地,可以将数字音频输入诸如来自音频文件的数字音频输入或来自计算机系统的流传输传递至具身智能体。声学信号可以经由深度神经网络进行分析,该深度神经网络提供与输入字词相对应的值的向量。这些被馈送到学习字词映射的第二独立听觉som。音质映射和字词映射可以通过作为音频模态的最终表示的较高层级听觉asom进一步整合。
[0027]
可以基于其与虚拟环境的交互向具身智能体提供触觉。例如,每当具身智能体的身体的一部分与具身智能体环境中的另一对象“相交”时,与该对象的交点可能触发具身智能体的触觉。此类触觉可以与具身智能体的身体的本体感觉映射、具身智能体环境的映射和/或任何其他模态相关联。如果具身智能体在虚拟世界中触摸到特定“可接触”对象,则具身智能体的效应器(例如手指)上的机械性刺激感受器检测到碰撞,并且触发活性度。可以通过计算机输入设备诸如鼠标、键盘或触摸屏向具身智能体提供触觉。例如,“触摸”屏幕将投射到具身智能体的身体“接触”手指(在触摸屏上)的部位上,或触摸鼠标光标将投射到机械性刺激感受器映射上。符号输入(例如键盘输入)能够被映射到任意触觉,例如对象纹理。例如,触觉对象类型som可以映射不同的对象纹理。对象的形状也能够通过触觉系统记录,该触觉系统包括触摸和运动动作。
[0028]“位置”模态可以表示中央凹位置,该中央凹位置包括具身智能体的中央凹的x和y坐标。坐标可以通过位置-活性度som直接转换为10
×
10激活映射。
[0029]
内感受性感觉是指具身智能体对其身体的内部状态的感知性感觉。通过从表示身体瞬时状态诸如饥饿、口渴、疲劳、心率、疼痛和厌恶的信号中获取输入,形成内感受性状态空间映射。神经化学参数表示生理内部状态变量,是情感系统的一部分。内感受性映射表示具身智能体的状态空间。可以建模的神经调节因子的例子包括用于运动功能的乙酰胆碱、作为压力指标的皮质醇和用于社会连结的催产素。原发情绪的基本表示可以映射到高维神经化学空间,该神经化学空间调节行为响应并且提供从连续本能感知状态到离散心理类别的映射。内感受性感觉可有助于具身智能体决策,因为事件与身体的情绪神经化学状态相关联,使得所想象事件的回忆情绪成为决策因素。
[0030]
本体感觉系统通过本体感受器向具身智能体提供关于具身智能体的身体结构的感知认识,包括具身智能体的效应器的位置(例如,四肢、头部和智能体躯干结构)。本体感觉映射可以包括关于从具身智能体身体的骨骼模型传递的每个关节的角度的信息。在具身智能体肌肉系统的更详细生物力学模型中,本体感觉映射也可以包括关于肌肉拉伸和张力的信息。运动模态可用于映射动作类型。
[0031]
各个字词可以经由书面字词、听觉音位表示和/或其他符号与对象、动作、事件或概念的表示相关联。与概念的表示相关联的一个或多个符号可以被存储为与表示该概念的感觉模态相关联的模态。
[0032]
可以实现任何其他合适的模态(或类似虚拟表示),诸如味觉、嗅觉。模态的特定方面可以被建模成其自身的模态。例如,视觉模态可以分为若干模态,包括光模态、颜色模态和形式模态。可以对内部感觉进行建模,诸如温度、疼痛、饥饿或平衡。
[0033]
直接编写经验记忆存储器
[0034]
可以将经过训练的神经网络(诸如som)及其后训练权重存储在尚未直接体验该权重的具身智能体中。如此,“空白”具身智能体可以设置有嵌入其经验记忆存储器的神经网络权重中的知识(例如,关于对象的知识)。
[0035]
记忆数据库(记忆文件)
[0036]
在一个实施方案中,除了经验记忆存储器之外,经验的表示还可以存储在记忆数据库中。记忆数据库可以通过具身智能体的经验来自动填充,和/或编写。用户或自动化系统能够检索存储在记忆数据库中的记忆,在记忆数据库中编写新记忆,以及/或者删除记忆。对应于每个所体验的模态的表示的原始数据可以存储在记忆数据库中并与对应的经验相关联。例如,与视觉模态相关的记忆的分量可以链接到图像文件(例如,jpeg、png等),与听觉模态有关的分量可以链接到音频文件(例如,mp3)。
[0037]
记忆数据库可以任何合适的方式实施,例如,作为存储文件集的数据库和/或文件夹。在一个实施方案中,记忆数据库是存储经验的csv文件。csv条目可以包含或指向与对应于该条目的经验相关联的原始数据的表示。将记忆存储为关联图像或对应于原始输入的其他原始数据允许智能体重现/处理经验。具身智能体可以学习那些输入,就如同具身智能体正在体验它们一样。
[0038]
在一个实施方案中,在具身智能体的实时操作期间,具身智能体将经验记忆同时存储在经验记忆存储器和记忆数据库两者中。例如,狗吠经验可以作为多模态记忆存储在经验记忆存储器中,也可以作为对应于经验的条目的属性存储在记忆数据库中,包括图像、声音、情绪效价和其他相关多模态数据,包括文本/语音话语。
[0039]
将经验存储在文件中还可以包括存储元数据,或关于经验的额外数据,例如事件发生的时间(时间戳)、事件的gps位置或与经验相关的任何其他上下文信息。
[0040]
通过经验填充记忆
[0041]
在一个实施方案中,存储在记忆数据库中的记忆由具身智能体在该具身智能体的实时操作过程中的实时经验填充。智能体与来自真实世界和/或虚拟世界的感觉流交互,如标题为“machine interaction”(机器交互)的新西兰临时专利申请nz744410中所述的,该临时专利申请也转让给本发明的受让人,并且以引用方式并入本文。
[0042]
如本文所述,具身智能体能够选择性地通过体验学习新经验、情绪经验或用户指示的经验。在具身智能体中,其经验记忆存储器被实施为cdz,记忆存储在该cdz中。每当在该cdz中存储新的经验记忆时,来自较低层级som的表示作为属性和/或文件被保存在记忆数据库的新条目中。
[0043]
经由记忆数据库训练经验记忆存储器
[0044]
记忆数据库可用于训练经验记忆存储器。记忆数据库中的条目被设置作为巩固期间经验记忆存储器的训练输入。编码在经验记忆存储器中的记忆使智能体能够识别对象、概念、事件并作出预测。例如,用户能够生成用于特定学习域的输入文件集。例如,通过设置有记忆数据库,智能体能够成为“狗专家”,而无需在实时操作期间体验狗,该记忆数据库包含不同狗品种的图像以及关联模态,此类符号包括狗的名字、狗吠声谱图以及狗会唤起的情绪反应。
[0045]
在cdz的具体实施中,记忆数据库中的条目用于重新训练cdz,从而改变底层会聚/发散区(例如som/asom)的权重。在训练过程中,对应于条目的原始文件/数据由经验记忆存储库重新读取,每次读取一个经验。以对象学习事件为例,加载对应于视觉、听觉和触觉模态的原始数据,并触发学习事件。在记忆巩固过程中发生的长期记忆学习事件可能比实时学习发生的时间要快得多,如“记忆巩固”部分中所述。在一个实施方案中,可以显示用于“训练”智能体的原始文件,以模拟智能体“幻想”,如同智能体“重温”或“重新想象”过去的经验。
[0046]
重建记忆
[0047]
能够重新读取记忆数据库中的条目以重建记忆:例如,它们可以在记忆巩固期间训练短期记忆经验记忆存储器、创建“虚拟事件”或训练长期记忆经验记忆存储器。可以重建从经验记忆存储器触发学习事件的原始感觉输入(诸如图像),因为该原始感觉输入存储在低层级映射的神经元的权重中。然而,由于可能有若干不同的输入向量能够修改单个神经元的权重,因此神经网络中的所得权重可以是若干输入实例的混合。因为记忆数据库将各个输入向量及其组分输入字段显式存储为具有关联属性的单独条目,所以记忆数据库提供了准确重建各项经验的方式。
[0048]
修改或删除记忆
[0049]
用户能够选择性地修改记忆,例如,通过修改记忆数据库中的条目(显式修改,诸如改变对象的效价),或删除整个条目。通过删除所有条目,可以删除具身智能体的整个记忆,从而变成空白状态。在一个实施方案中,在每次巩固时,经验记忆存储器被清除,并且通过使用更新的记忆数据库(可以包括编辑或删除的条目)进行训练来完全重新填充。在作为som的经验记忆存储器中,可以通过随机化所有神经元权重来完成经验记忆存储器的清除。
[0050]
在其他实施方案中,更新或修改的经验可以被置于经验记忆存储器中并且通过“不学习”特定数据点来选择性地从经验记忆存储器中删除,而不是清除整个经验记忆存储器。在“遗忘”模型中,经验被打上时间戳,或者以其他方式标记,以指示记忆的近因,并且通过从经验记忆存储器和/或记忆数据库中删除,可以“遗忘”旧事件。
[0051]
编写记忆
[0052]
对应于经验的记忆条目可以被直接“植入”智能体记忆中,而不必要求智能体经历新经验来创建新记忆。这创建了一种可引导的、可人工操纵的具身智能体。例如,该智能体可以被编程为对经验具有引导的自主响应(诸如对某些刺激的阴性反应)。因此,记忆数据库中的条目能够由外部工具“编写”,也可以直接在具身智能体的实时感觉运动经验中学习。
[0053]
使用文本语料库进行编写
[0054]
记忆的编写可以在上下文中使用文本语料库进行。用于编写事件记忆的标注文本语料库的示例如下:[timestamp]the red car(image,sound)drove(action)to the left(place).i《didn't》like it(emotion)
[0055]
实时感觉运动上下文能够反映字词选择(喜欢、不喜欢)以及具身智能体的指示和情绪状态。这可以通过提供原始输入(诸如图像/声音/感觉等)查找表来实现,这些原始输入与符号(诸如字词)相关联。这允许通过句子快速创建输入来用于学习事件。检索与查找表中的对应字词相匹配的数据,以训练经验记忆存储器和/或创建与记忆数据库中的原始数据相关联的详细条目。在具有关于对象、动作和情绪的现有知识的具身智能体中,能够通过使用语法结构关联事件的分量来编写事件。
[0056]
可以使得各项记忆易于定位、修改和/或删除的方式对记忆进行分类、标注或标记。可以提供用户界面来促进用户查看和编辑具身智能体的记忆。
[0057]
使用自组织映射(som)实施
[0058]
自组织映射
[0059]
可以使用自组织映射(som)来表示模态和会聚发散区两者,som是一种基于无监督学习的记忆结构,也称为kohonen映射。对som(可以是一维、二维或三维或n维)进行数据集训练,以提供此数据的离散化/量子化表示。然后,可以使用该离散化/量子化来分类原始数据集上下文中的新数据。
[0060]
加权距离函数
[0061]
在传统som中,在整个输入向量上使用简单距离函数(例如,欧几里得距离或余弦相似性)来计算输入向量与神经元的权重向量之间的相异性。然而,在一些应用中,可能期望比输入向量的其他部分更高地对输入向量的一些部分(对应于不同的输入字段)进行加权。
[0062]
在一个实施方案中,提供了用于多模态记忆的关联自组织映射(asom),其中对应于输入向量的子集的每个输入字段通过被称为asomα权重的项来有助于加权距离函数。asom计算输入字段集与神经元的权重向量之间的差异,不是作为单片欧几里得距离,而是通过首先将输入向量分为输入字段(其可对应于输入向量中记录的不同属性)。不同输入字段中的向量分量的差异有助于具有不同asomα权重的总距离。基于加权距离函数来计算asom的单个所得活性度,其中输入向量的不同部分可具有不同语义及其自身的asomα权重
值。因此,对asom的总体输入对要相关联的任何输入(诸如不同的模态、其他som的活性度或任何其他输入)进行子集求和。
[0063]
图2示出了合并来自若干模态的输入的asom的架构。对asom的输入由k个输入字段32组成。每个输入字段是dimk(i=1
…
k)个神经元的向量输入字段32可以是:感觉输入的直接独热编码;1d概率分布、较低层级自组织映射的2d活性度矩阵或任何其他合适的表示。
[0064]
图2的asom 3由n个神经元组成,每个神经元i=1
…
n具有对应于完整输入的权重向量被分成部分权重向量(对于k=1
…
k)的k个输入字段。当提供输入时,每个asom神经元首先计算输入和神经元的权重向量之间的输入字段方向距离:
[0065][0066]
其中αk为第k个输入字段的自下而上混合系数/增益(asomα权重)。distk是输入字段特定的距离函数。可使用任何合适的一个或多个距离函数,包括但不限于:欧几里得距离、kl散度、余弦距离。
[0067]
在一个实施方案中,加权距离函数基于欧几里得距离,如下:
[0068][0069]
其中k是输入字段的数量,αi是每个输入字段的对应asomα权重,di是第i个输入字段的维度,并且x
j(i)
或w
j(i)
分别是第i个输入字段的第j个分量或对应的神经元权重。
[0070]
在一些实施方案中,asomα权重可被归一化。例如,在使用欧几里得距离函数的情况下,通常使得活性度asomα权重总和为1。然而,在其他实施方案中,asomα权重未归一化。在某些应用中,诸如在具有从稀疏到密集动态变化的大量输入字段或高维asomα权重向量的asom中,不归一化可导致更稳定的距离函数(例如,欧几里得距离)。
[0071]
用于对记忆进行采样的方法:幻想和ior
[0072]
可能期望随机重建存储在som中的项目。例如,在长期记忆巩固过程中构建伪训练项目时,或者在蹒跚学步过程中随机生成运动动作时,就会发生这种情况。在这些情况下,som的训练记录驱动随机选择要重建的som神经元。采样可与返回抑制(ior)过程组合,从训练值全集中采样。
[0073]
训练记录
[0074]
当从som的完整活性度重建时,所有神经元都成比例地有助于其权重向量与输入向量的相似性,无论这些神经元是否经过训练来表示有意义的假设或包含初始随机噪声。
[0075]
为了提供更清洁的重建输出,可以给接受过更多训练的神经元更大的权重(忽略未训练的神经元)。每个神经元的适应量可以被记录为0到1之间的值,可在som参数“训练记录”中访问。
[0076]
训练记录是每个神经元的额外标量权重,初始化为0并且连接到固定输入1。因此,
每次训练该特定神经元时,由于它是获胜神经元,或者由于它在获胜神经元邻近,该神经元的训练记录就会与当前(可能由于匹配度而进行调整)学习速率成比例地增加。这意味着在训练过程中,训练记录向1上升。
[0077]
映射中所有神经元的训练记录值的平均值(“映射占用率”)指示映射学习新输入而不覆盖旧输入的空闲容量。“最大占用率”1指示“完全/拥挤映射”(无空闲容量),而“最大占用率”0则表示未经训练的映射。
[0078]
在计算som活性度时,训练记录可以用作激活掩码的值(项mi)。就贝叶斯定理而言,这并非使用统一的mi(所有假设都具有相同概率的平坦先验),而是相当于采用基于观察频率的先验:即,所得概率分布是以假设输入是训练som的先前所见输入之一为条件的。
[0079]
训练记录能够随时间而衰减,这表示探索避免了最近训练区域,但如果区域长时间未被重新激活,则能够循环用于新记忆。训练记录存储训练历史的方式能够通过参数“训练记录衰减”来调节。训练记录衰减值1表示无衰减。训练记录衰减值小于1表示训练记录将仅反映最近训练(通过介于0与1之间的值确定近因)。
[0080]
通过自上而下重建权重来检查内容
[0081]
在所连接的som层级结构中,低层级som的活性度向高层级som提供输入,在自上而下重建过程中,能够反转该激活流。来自较高层级som的重建输入向较低层级som提供自上而下信号:预期激活模式。该信号可以在较低层级som的自上而下偏置场中提供。它能够与较低层级som从其自身输入获得的激活模式组合。
[0082]
可以检索存储在神经元中的“记忆”的原始内容,其中记忆能够等同于各个事件,或者是若干事件的混合,这取决于训练环境和som参数(例如,小σ,即学习速率大=“尖锐”的各项记忆;大σ,即学习速率小,导致广义记忆和混合记忆)。
[0083]
配置用于快速学习的asom
[0084]
虽然基于反向传播的学习方法需要缓慢学习,但是通过小权重更新,som神经元表示的局部性质允许它们甚至在单次接触中也能非常快速地学习输入模式。在传统som中“快速”学习输入(只经过几次演示)时遇到的一个问题是覆盖之前编码的输入。不同训练项目(或至少出于某一用途而被视为不同的训练项目,例如不同类别的成员)应该通过在单独神经元或区域中编码来在som中保持独立。同时,彼此足够相似的项目应该被编码在相同神经元或区域中。与使用som进行关联而慢速学习的现有尝试不同,本文所述的asom可以“快速”学习。asom能够被设置为通过选择大学习常数/学习频率值来快速学习,使得给定输入能够在单次接触中由单个som神经元(或区域)编码。然而,要允许实际快速学习大量项目,改变学习常数是不够的。
[0085]
可以确定输入是否是“新的”,如果匹配不够紧密,则不覆盖“获胜神经元”,而是选择不同的神经元。可以定义“最佳匹配阈值”参数,该参数控制呈现给asom的项目是被认为是“新的”还是“旧的”。“最佳匹配阈值”是对输入项目反应最强烈的som神经元的(原始-未归一化)活性度值的阈值。如果该值低于“最佳匹配阈值”,则项目被视为“新的”,否则项目被视为“旧的”。新项目作为单独模式存储在som中;而旧项目则更新现有模式。
[0086]
当遇到新项目时,“探索方法”参数确定分配哪个神经元来编码新输入。可以使用任何合适的探索方法。示例包括:
[0087]
·
输入噪声探索:将随机噪声添加至当前输入,并根据应用于至该修改输入的距
离的高斯激活函数找到新获胜神经元。
[0088]
·
激活噪声探索:从复合激活映射中选择新获胜神经元,该复合激活映射是原始激活映射和充满随机噪声的辅助映射的混合物。辅助映射的混合系数称为compare_noise,它决定原始映射的失真程度。小compare_noise值将导致在原始获胜神经元附近局部探索。
[0089]
代替将活性度与噪声混合,辅助映射能够被设置为任何内容,对向着或远离som特定区域的偏置进行编码,例如反向反映每个神经元最近频率和活性度的值,以确保避免先前获胜神经元,并促进更均匀地填充som。一种特别有用的方法是跟踪每个神经元已接收的训练量(总共或最近),即所谓的训练记录,并排斥从已训练区域中选择获胜神经元(使之前未训练/死亡的神经元参与进来)。
[0090]
关于映射的每个神经元/区域、其已获得的训练程度和获胜神经元竞争的记录仍然取决于输入的相似性,但是偏离已获得多批训练的区域。网络被均匀填充,并且“死神经元”(因为初始权重不良而永远不会得到训练,)减少。使用反向训练记录作为激活噪声,这确保如果存在未使用的神经元,将首先分配这些神经元。
[0091]
为了保持som的拓扑组织并将新获胜神经元放置在原始获胜神经元附近,“比较噪声”可以被设置为小值。如果比较噪声较小,则原始激活仍然有强大影响,所以新获胜神经元很可能来自旧获胜神经元附近。然后用当前输入对其进行训练,原始获胜神经元将对其之前的输入进行编码,新输入不会覆盖它,而是由附近神经元表示。
[0092]
将模式设置为反向反映每个神经元最近频率和活性度的值的映射(这有助于通过使得之前未使用的神经元参与进来而更均匀地填充som,并确保不选择第一获胜神经元),可以使用以下伪代码对som同构向量进行计算:
[0093]
#during training,leaky-integrate the current activation_map with recency map(decay
[0094]
#is aconstant<1,e.g.0.999)
[0095]
recency=plastic>0?decay*recency+activation_map:recency
[0096]
#truncate values>1 to 1
[0097]
recency=recency>ones?ones:recency
[0098]
#compute inverse recency map as 1-recency
[0099]
inv_recency=ones-recency
[0100]
#set the noiseto inverse recency map
[0101]
asom/activation_noise=inv_recency
[0102]
如果某个项目被视为“旧的”,则该项目被存储在som中已发生学习的区域。在标准som中,如果重复呈现相同项目,则表示该神经元的区域将发展,并且能够潜在地扩大规模,最终主导整个som。这就是som的低效使用。为了控制这种效应,“最佳匹配学习乘数”参数根据获胜神经元的活性度调整som的学习频率。如果“最佳匹配学习乘数”被设置为零,则完全重复的项目将不会在som中诱导任何新学习。如果被设置为1,则原始som的学习频率没有调整。学习频率的乘数m可使用如下公式计算:m=1-原始获胜神经元活性度*(1-最佳匹配学习乘数):因为即使在完美匹配的情况下,一些训练也是好的,而且完美匹配邻近的更多神经元能够适应它的值,并且重建的“软”输出也将反映遇到不同值的频率,所以可能期望最佳匹配学习乘数为小的非零值,而非0。
[0103]
如前所述,快速学习som时遇到的一个问题是,大学习频率增加了覆盖神经元的风险。对于小学习频率,权重不会被完全覆盖,而是被平均化。根据其参数的值,som能够被配置用于缓慢学习或快速学习。缓慢学习(如标准kohonen som所述,类似于大脑中的皮质学习,其中各项记忆能够被广义化/混合)的特征在于:较小的学习频率;较大的邻近尺寸σ值;例如通过设置best_match_threshold=0禁用新颖性检测。快速学习的特征在于:最大学习频率;极小σ;高best_match_threshold设置;类似于大脑中的海马学习,并且可以像概率查找表一样作用(很大程度上能够单独/正交且准确地表示各项经验)。由于上述参数的范围是连续的,所以在som中能够实现快速学习和慢速学习的混合。当som拥挤时,可以自适应地降低学习频率(就其映射占用率而言,如“训练记录”部分中所述),然后som自动切换到标准慢速学习som(因为在完整映射中继续快速学习将意味着覆盖/遗忘旧知识。当降低学习频率时,新记忆将与最相似的旧记忆混合。在一个实施方案中,学习的“速度”取决于som容量。在具有足够容量的som中,该som可以被配置为快速学习(甚至是一次性学习),并且各项记忆的精度高。当som接近其全容量时,可能会发生向更渐进学习的过渡(不是用新记忆完全取代旧记忆,而是混合它们)。为了监控剩余容量(即,能够在不覆盖旧记忆的情况下训练的未使用神经元),可以定义映射占用率,作为每个神经元的训练记录的平均值,即sum_i(训练记录[i])/map_size。值0表示空的/未训练的映射,值1表示完整映射。为了从快速映射类型过渡到慢速映射类型,可以随着映射占用率的增加而逐渐调整参数学习频率、σ和最佳匹配阈值。或者,当映射占用率超过特定阈值(例如90%(0.9))时,可以发生离散切换。
[0104]
针对性遗忘
[0105]
通过用随机噪声替换所有神经元权重向量(与som初始化的方式相同),能够实现“遗忘”som学习的所有内容。然而,在有些情况下,“针对性遗忘”是有用的,例如:
[0106]
·“撤销”最近错误学习的经验
[0107]
·
遗忘特定类型的所有记忆,即与枪声相关联的所有图像
[0108]
·
遗忘非频繁出现的记忆(假设这些记忆是偶然发生的,并且质量没有反复遇到的经验那么好)。
[0109]
·
遗忘非常旧的记忆(假设开始时训练不稳定,并且自当时起的表示质量低)。
[0110]
针对性遗忘由掩码(类似于激活掩码)控制,称为“重置掩码”。该重置掩码与som同构(即,每个som神经元有一个掩码值)。在用噪声替代神经元权重向量时,仅对重置掩码=1的神经元进行重置,其余(重置掩码=0)神经元则予以保留。
[0111]
或者,重置掩码值可以在0和1之间,在这种情况下,原始权重向量将与随机噪声混合,混合系数由重置掩码值确定:
[0112]
new_weight[i]=(1-reset_mask[i])*original_weight[i]+reset_mask[i]*noise
[0113]
在重置期间,可以更新训练记录,使得重置的神经元训练记录被清除(即,在离散重置掩码的情况下,对于那些重置掩码=1的神经元,训练记录=0)。在连续混合的情况下(模糊记忆):
[0114]
new_training_record[i]=(1-reset_mask[i])*original_training_record[i]
[0115]
可以根据以下要求设置适当的重置掩码:
[0116]
重置掩码被设置为som的最新激活映射(整个som在接受有关想要撤消的经验训练
后的活性度)。这会导致部分遗忘——与活性度大小成比例模糊。或者,可以创建离散重置掩码,例如,对于概率性som,将激活大于重置阈值的所有神经元的重置掩码设置为1,其余神经元的重置掩码设置为0。或者,在非概率性som中,将获胜神经元的掩码值设置为1,将所有其他神经元的掩码值设置为0。
[0117]
输入要遗忘其关联记忆的刺激。在上述示例中,在音频输入字段提供枪声,视频的asomα权重被设置为0(以检索与枪声相关联的所有视频)。所得激活映射能够被直接用作重置掩码。或者,可以创建离散重置掩码,例如,将激活大于重置阈值的所有神经元的重置掩码设置为1,其余神经元的重置掩码设置为0。或者,将获胜神经元的重置掩码设置为1,将所有其他神经元的重置掩码设置为0。重置掩码设置为1-训练记录或其离散化版本(如果训练记录[i]《阈值,则重置掩码[i]=1,否则为0)。在训练期间,训练记录衰减被设置为《1的值。随着时间推移,对于那些没有通过新训练“刷新”的神经元,这将导致训练记录减少到零。然后重置掩码被设置为1-训练记录或其离散化版本(如果训练记录[i]《重置阈值,则重置掩码[i]=1,否则为0)。
[0118]
asom可视化
[0119]
som可用作使多维数据可视化的工具。图7示出了asom训练显示画面,该asom关联五个输入字段(数字位图、偶数、小于5、3的倍数、颜色)。可视化显示了训练期间asom权重的组织,以及如何查询asom以显示满足查询的数据在查询中的表示位置。指定训练数据,其中每个数据包括后接(二进制)标记的数字,该标记指定该数字是否为偶数、小于5和3的倍数(按此顺序)以及(任意)颜色。asom以任何合适的方式进行数据训练。邻近尺寸和学习速率可以逐渐退火。
[0120]
图7示出了输入模式(数字本身由20
×
20位图表示)、重建的输出模式、显示网络何时是可塑/经过训练的标记以及权重的静态视图。因为asom关联了五个输入字段(数字位图、偶数、小于5、3的倍数、颜色),所以权重矩阵被分解为输入字段权重矩阵。在表示二进制信息时,白色表示零/假,黑色表示一/真。在表示位图和颜色映射时,颜色表示其自然含义。
[0121]
一旦asom得到训练,就可以制定查询并动态地查看映射上最满足查询的区域。查询视图显示在动态查询查看器输入字段的列中,如图8所示。每个查询都独立于其他查询,并且能够使用相应选项卡上的滑块进行操纵,如图9的屏幕截图所示。查询并排显示,以便用户能够可视地比较对应于不同查询的区域。
[0122]
要创建查询,用户或自动化系统可以指定一个或多个查询模式(例如,如图9所示)。还可以指定每个所定义模式的影响强度(作为每个输入字段的α/输入字段权重)。强度可以是二进制的(0或1),也可以支持连续/模糊混合查询。
[0123]
相应视图的映射可以显示与查询最对应的asom的区域,并且输出显示与查询最近似的重建数据。通过组合模式,可以询问问题,诸如“在三的偶倍数中,哪些小于五?”或“哪些数字是表示蓝色阴影?”。
[0124]
可以增加或减少匹配的严格度,换言之,就是asom的激活灵敏度(如图9的匹配严格度变量所示)。在该示例中,如果映射完全为白色或输出位图完全为黑色,则可能期望减少匹配的严格度;如果映射太暗或位图太模糊,则可能期望增加严格度。
[0125]
每个视图都有两个主asom的副本,一个用于使其活性度可视化,另一个用于重建输出。asom将输出计算为活性度的加权组合,这需要将活性度归一化,使得和为1,而显示
asom的活性度映射应该显示未经归一化的原始活性度,以查看每个神经元的权重满足查询的实际程度。
[0126]
asom的示例包括:vat(视觉/听觉/触觉)、vm(视觉/运动)、vnc(视觉/nc)、vatactivityl(vat/位置)、hc或动作结果(v1/v2/m/l1/l2/nc)
[0127]
交叉模态对象表示som
[0128]
可以在关联对象的不同感觉模态的som中学习交叉模态对象表示。在一个实施方案中,关联视觉、听觉和触觉输入,并且用作学习对象类型的模态集成表示的交叉模态对象表示som。它从三个学习单模态对象类型表示的som中获取输入:视觉对象类型som、听觉对象类型som和触觉对象类型som。信号检测过程可以通过向cdz som的每个输入字段提供相关联的信号检测过程来实现,该信号检测过程在该字段中查找信号的起始点,并在起始点发生时触发该字段的资格迹。对于交叉模态对象表示som,这些信号可以来自三个单独模态的注意系统。在交叉模态对象表示som中和在其输入som中学习由三个单独模态的注意力系统检测的低层级事件驱动。例如,听觉刺激事件可能是比特定阈值大的声音。
[0129]
学习还需要这些不同信号之间存在一定的一致性,如使用资格迹来实施。当检测事件时,在每个模态中启动资格迹(由泄漏积分和发射神经元编码)。如果两个模态的迹线同时活跃,则学习在用于这些模态的som中进行,并且也在交叉模态对象表示som中进行。
[0130]
如果仅在一个模态中检测到事件,则触发不同的连接性模式。在记录事件的模态中激活的模式作为输入传递到交叉模态对象表示som,该som激活与模态无关的对象表示。然后,该表示被用于重建其他单模态类型som中的表示,使得自上而下推断缺失模态中的模式。
[0131]
在此模型中,交叉模态对象类型som由单个模态的刺激和多个模态的刺激两者激活(前提是它们是一致的)。
[0132]
情感对象关联som
[0133]
情绪状态能够与输入刺激相关联。例如,在呈现对象的同时配对响亮的、突然的和/或可怕的噪声能够在具身智能体中引起情绪调节。当下一次遇到该对象时,它将诱导恐惧反应。此类关联在称为情感对象关联asom的会聚区(cdz)asom中学习。在一个实施方案中,这通过将视觉模态与神经化学模态(vnc som)相关联的asom来实现。该asom从视觉对象类型som和保持智能体情绪状态的神经化学som获取输入。
[0134]
情感对象关联asom的每个输入字段具有相关联的信号检测过程,该信号检测过程在该字段中查找信号的起始点,并在起始点发生时触发该字段的资格迹。触发对象类型som资格的信号是在显著性映射中选择新显著区域,例如,可由视野中的显著移动触发。从与情绪状态向量相关联的
‘
相位’信号计算触发情绪状态介质资格的事件,该信号指示该向量的突然变化。
[0135]
根据起始点依赖性学习原理,如果这些字段的资格迹在其相应阈值以上同时活跃,则仅允许som在其输入字段中学习表示之间的关联。在这种情况下,该原理确保当感知到新显著对象暂时与给定情绪的突然起始点同时发生时,情绪关联被学习。在学习与给定o型对象的情绪关联后,将o作为新显著对象呈现会自动激活相关联的情绪。这通过缺失输入重建原理来实现。
[0136]
操作性学习
[0137]
操作性条件反射是智能体在给定上下文中产生的运动动作与在执行该动作后一段时间达到的奖励刺激变得相关联的过程。学习这些关联的回路可以在具身智能体中持续运行,表明在给定上下文中会导致奖励的动作。动作结果asom是在较早的会聚区分层构建的会聚区。动作结果asom学习在某个给定时间产生的感知上下文刺激(在位置l1处出现的视觉对象类型l1)、稍后执行的运动动作以及之后较长时间出现的奖励刺激之间的关联。该奖励刺激与另一t2型对象相关联,该对象出现在另一位置l2。动作结果som需要存储感知上下文刺激的表示,因为这在奖励刺激出现时就已经消失。对动作结果som的t1和l1输入保持要在对象类型som中唤起的先前对象类型和在显著映射中选择的先前位置的副本。t2和l2输入是当前选择的显著位置和当前活跃的对象类型。因此,动作结果som学习所记住的对象和当前感知的对象之间的关联。可以调整资格窗口,以适应在不同时间发生的相关联事件。
[0138]
基于重建记忆的行为
[0139]
所有具身智能体行为都可以受到重建记忆的影响。在us10181213b2中公开了使用神经行为建模框架来创建和以动画方式显示具身智能体或化身,该专利也转让给本发明的受让人,并且以引用方式并入本文。在神经行为模型(诸如us10181213b2中所述)中,重建来自不同模态的输入可以改变具身智能体的内部状态,从而修改智能体的行为。
[0140]
编写情绪记忆允许自主触发具身智能体中的情绪表达。在客户服务化身中,经验记忆存储器可以用于有效地对化身中的反应进行编程。例如,品牌忠诚度客户服务化身可以被编程为对与该品牌相关联的所有商标有积极情绪反应,包括图形商标和文字商标。例如,听到品牌名称“灵魂机器”可以与“快乐”感受相关,从而相应改变智能体的神经化学状态。一听到这个词,快乐的神经化学状态就被预测出,促使化身微笑。
[0141]
在一个实施方案中,对经验或事件的直接响应可以经由可编写记忆“植入”到智能体中。例如,将品牌“灵魂机器”与专注/警觉、睁大眼睛的状态相关联的记忆。-即视觉模态持续合格的状态,而经由asom与视觉模态间接关联的其他模态则接收自上而下的输入以产生预测。
[0142]
在玩具应用程序中,具身智能体诸如化身或虚拟角色能够由用户编程为展现行为。例如,与虚拟朋友玩耍的孩子能够通过体验(将对象呈现在虚拟朋友面前并创建消极面部表情和/或话语)或通过界面在虚拟朋友中“植入”特定对象令人不快的记忆。
[0143]
具身智能体的个性或性格能够通过编写记忆来编写,包括具身智能体的好恶。通过编写与对象和/或事件相关联的情绪状态,易于开发具有特定个性的智能体:能够呈现若干对象并与情绪状态相关联。例如,通过编写若干与“快乐”情绪相关联的不同动物的基于文件的记忆,可以将化身编程为具有动物爱好者的个性。同样,能够将对象与愤怒、悲伤或中性情绪相关联。
[0144]
运动计划
[0145]
运动记忆系统可以被设置成离散地存储运动动作和/或运动计划,智能体能够激活该运动动作和/或运动计划,以执行相应的运动动作。运动动作的示例包括但不限于按压、拖曳和提拉。每个动作都有特定的时空模式,例如,对于表示动作,为本体感觉的关节位置序列;对于观察动作是偶,为视觉识别的关节位置序列。时间维度能够由递归投影隐式表示,其中asom将当前输入与其在前一计算时间步骤中的自身活性度相关联
[0146]
具身智能体可以具有运动控制系统,使其能够有目的地移动身体部位,诸如四肢
或其他效应器。有关每个关节角度的信息可以从智能体身体的骨骼模型传递。智能体可以具有能够在视觉空间中伸及指定点的手眼协调能力。自组织映射模型(asom)可以使智能体能够学习手眼协调,从而使得其能够以真实的眼动和伸及动作与周围变化的三维虚拟(或真实,在vr/ar的情况下)空间进行交互。一旦经过训练,asom就可用于反向运动,并在出现目标位置时返回关节角度。
[0147]
运动动作可以是单独运动动作(例如,伸及空间中的某个点以接触对象),也可以是连续运动。例如,对象导向运动行为诸如抓取、拍击和击打是连续运动,因为智能体的手(或其他效应器)沿着不同的轨迹和/或速度朝向目标对象。例如,拍击和击打运动动作的轨迹比伸及运动动作的轨迹更快;并且该轨迹也可以包括抽回手。也可以描述手指的轨迹。抓取包括张开手指,然后合上手指。击打和拍击包括在接触对象之前将手配置成特定形状。
[0148]
多个运动动作能够各自与目标相关联,并被排序以创建运动计划。标题为“system for sequencing and planning”(用于排序和计划的系统)的临时专利申请nz752901中描述了一种用于创建计划的系统,该临时专利申请也由本技术人所有,并通过引用并入本文。
[0149]
运动行为和/或运动计划可以与回合(作为wm动作)、对象(作为对象的示能表示)或任何其他体验或模态相关。运动动作和/或运动计划可以与在经验记忆存储器和/或记忆数据库和/或工作记忆中标识运动动作和/或运动计划的标签或其他符号相关联。运动计划的示例包括:在键盘上弹奏曲子、在触摸屏上绘制图像。开门。
[0150]
如标题为“machine interaction”(机器交互)的新西兰临时专利申请nz744410中所述(该临时专利申请通过引用并入本文),运动计划可以与用户界面事件相关联,并且可以触发智能体与之交互的应用程序或计算机系统上的事件。例如:触摸目标两次可以转换为用户界面上的“双击”(在这种情况下,触摸“按钮”两次的运动动作触发双击用户界面上的按钮)。
[0151]
感知和保留记忆
[0152]
事件驱动性认知与哪些事件被感知有关(并因此传达给具身智能体的其他子系统),而生物上现实的强化方案管理哪些事件被保留。
[0153]
记忆是由事件构建的;然而,人类对与预期不同的事物记忆更强烈。将这一原理应用于具身智能体允许具身智能体由事件驱动;而不是由感觉输入不断触发。这是一种时间压缩形式,可减少智能体对“事件”作出反应所需的计算。与事件相关的时间快照能够基于以下因素予以保留:重要性、超出阈值的容量、移动、新颖性、上下文信息或任何其他合适的度量。事件通过触发创建资格窗口的模态资格迹来有助于记忆存储,在该资格窗口中,模态有资格供学习。
[0154]
基于资格的学习可用于确定智能体保留哪些“事件”。事件的发生触发模态的资格迹19。每个输入通道具有其自身的资格迹。例如,如果有自下而上的事件(例如,足够大的声音),则“声音”的输入通道在资格窗口期间打开,并在一段时间后关闭。输入类型(模态)可以与独特资格神经元相关联。如果事件在其相应输入通道中发生,则神经元接收输入。当该神经元的电压超过阈值时,输入通道有资格持续一段时间。
[0155]
泄漏积分器(li)神经元可以实现资格迹,以促进基于资格的学习。li神经元的活性度在特定程度时启动,并随时间衰减。当给定li神经元的活性度超过特定阈值时,定义“资格窗口”:在此时间段,一些关联回路有资格供学习。图4示出了在泄漏积分器神经元的
事件触发与电压阈值之间创建资格窗口18的模态中的资格迹19。
[0156]
在诸如us10181213b2(该专利也转让给本发明的受让人)中所述的神经行为模型中,资格迹可以在整个网络上而不是个别突触上操作。可以在us10181213b2中所述的编程环境的“连接器”中执行为每个低层级输入创建资格迹和资格窗口的步骤。
[0157]
资格窗口可以在cdz中用于控制学习如何以及何时发生,并控制活性度如何通过会聚区系统传播。例如,在由som实现的具有两个输入字段的简单感知会聚区中,每个输入字段具有相关联的信号检测过程,该信号检测过程在该字段中查找信号的起始点,并在起始点发生时触发该字段的资格迹。现在,som中的学习和活性度由跨所有会聚区som操作的若干一般原理控制。
[0158]
能够基于上下文参数调整会聚区som的每个输入字段的资格窗口。例如,智能体情绪状态的某些参数能够导致特定窗口延长或缩短:因此,挫折可能使特定窗口变短,而放松可能使其变长。
[0159]
对于直接从感知或运动信号中获取输入的cdz som,与其输入字段相关联的信号检测过程捕获感觉或运动刺激的起始点。在cdz som从另一cdz som获取其输入的情况下,信号检测过程可以识别较低层级cdz som中清晰信号的起始点。这能够通过度量较低层级som的活性度模式的变化来读取,指示它表示新事物。该变化度量可以与较低层级som的熵度量相组合。如果som模式可以解释为概率分布,则其熵可以度量。该变化必须导致低熵状态,表明som自信地表示其输入模式。如果较低层级som被配置为缓慢学习,则在较低层级som对其自身输入的编码变得足够清晰之前,较高层级som不会学习。
[0160]
活性度可通过“自上而下激活”字段自上而下地从较高层级cdz som流向较低层级cdz som。当低层级som的资格较高时,其活性度会激活较高层级的关联som,然后这些关联som会向所连接的其他低层级som实时提供自上而下信号。这些能够作为计算这些输入的自下而上过程的实时自上而下指导。
[0161]
在时间介导的基于资格的学习中,关联网络中的两个输入必须在特定时间内相互发生,以便在这些网络中学习关联。只有当其输入字段的资格迹同时活跃(高于各自阈值)时,才允许一些asom学习其输入字段中的表示之间的关联。这确保只有当新信号同时到达或具有某种程度的时间一致性时才会发生学习,并防止学习随机或嘈杂信号之间的关联。因此,学习需要同时资格窗口。例如,为了学习视觉刺激与触觉刺激之间的关联视觉表示和触觉表示的资格窗口必须是同时的。这些同时合格窗口模拟了不同低层级多模态“事件”的同时发生。图3示出了不同模态的资格信号。图5示出了学习事件的标记和阶段。学习事件由两个并发事件(0和1)触发。当事件发生时,智能体可以获得更多信息,例如通过扫视或等待音频序列结束。这种延迟可以使用泄漏积分器神经元来实现。可以改变泄漏神经元的输入频率常数和/或膜频率常数,以改变延迟的长度。所有显示的周期都是由单独的泄漏神经元控制的。在事件结束时,对于“主要”som,在2和3处存在可塑性;对于辅助som,在4处存在可塑性。此为一般学习事件序列,如果在层级结构中存在多层cdz,则学习阶段能够扩展以相应适应该层级结构。
[0162]
如果资格迹仅对一个输入字段活跃,则som处于仅由该字段驱动其活性度的模式。(即,其他输入字段的asomα权重被设置为零。)然后,其他输入字段中的活性度根据活跃的som模式重建,如在“通过自上而下重建权重来检查内容”中所述。在缺失的输入字段由较低
层级分类过程传递的情况下,重建的值提供有用的自上而下偏置。重建还提供简单的感知“填充”模型,由此可以想象缺失的关联信息。当第一字段的资格迹仍然活跃时,重建的(或预测的)输入可以自下而上到达。在这种情况下,som将进行更多学习,从而加强用于做出预测的关联。另一方面,如果非预测信号到达第二字段,而第一字段的资格迹仍然活跃,则将在som中学习新关联。
[0163]
在一个实施方案中,实施时间依赖性多巴胺可塑性模型,以确定具身智能体观察到的哪些事件(以及在多大程度上)被学习/保留。发生的学习量,即相关系统的“可塑性”受若干因素影响。相关资格信号的电平是一个因素。另一个重要因素是一致“奖励”信号的强度。奖励信号可以作为神经递质水平(特别是多巴胺水平)实施。诸如asom、概率性som及其混合物的映射可以与确定asom的权重何时被更新的可塑性变量相关联。为了防止过度训练,可塑性可以在不同时刻或时间间隔动态开启(例如,当新输入到达时),然后关闭。在更新权重之前,如果输入与获胜神经元之间存在良好匹配,则学习频率常数可能会降低,以防止神经元过度学习。
[0164]
记忆巩固
[0165]
经验记忆存储器可以包括两个独立且相互竞争的som:短期记忆(stm)和长期记忆(ltm)。stm可配置用于快速在线/快速学习,可以一次性学习方式进行训练,具有高lfc和不良地形数据排列。stm可作为缓冲系统,用于尚未巩固的学习。stm记忆可以在每次巩固后被擦除。ltm可被配置用于缓慢离线学习,具有低时间衰减学习频率常数,从而产生良好的地形分组。ltm在记忆巩固期间训练(可以在化身中表示为“睡眠”)。来自stm的训练数据可被模拟或重现至ltm som。在巩固过程中,stm可以随机性或系统性方式激活经过训练的单元,重新创建对象类型和图像,并将其作为ltm的训练数据。ltm针对重新创建的数据对或数据元组进行训练,并可将新数据的训练与自身的训练数据交错进行。或者,可以不使用stm som重新创建对象,而是提供来自记忆数据库中条目的原始数据文件来训练ltm。
[0166]
例如,ltm和stm对象分类器可以在视觉识别方面处于持续竞争之中。ltm和stm对象分类器两者都可以将视觉空间(例如,像素)中的表示映射到对象类型的公共独热编码上。如果在ltm中没有足够好的匹配,系统会假设在stm中存在匹配。若ltm匹配的熵低于阈值,并且获胜神经元的活性度高于阈值,则满足ltm匹配。因此,stm和stm分类器共同并选择性地表示对象类型(其中stm表示自上次巩固以来的对象类型,ltm表示在上次巩固之前学习的对象类型)。当遇到新对象时,可以首先检查ltm中是否存在该对象。如果不存在,则该对象在stm中学习。
[0167]
图10示出了ltm和stm显示画面。最左窗口显示了向视觉系统的当前中央凹输入。第二个窗口指示哪个系统(stm/ltm)经由紫色矩形对中央凹(自下而上)输入有足够好的匹配或更好的匹配。绿色指示哪个系统正在接收自上而下的影响。该窗口的上半部分和下半部分分别对应于stm和ltm。对于其余显示画面,上半部分属于stm,下半部分属于ltm。以正方形排列的4个窗口(以实线突出显示)显示了(顺时针方向)输入图像、输出图像、som权重和带som获胜神经元叠层的som训练记录。右边的两个窗口是视觉som的副本,显示预测的下一个序列图像。
[0168]
从记忆数据库进行训练
[0169]
记忆数据库中的经验可用于在睡眠期间训练ltm。可以设置多次迭代记忆数据库
(随机或系统地)。
[0170]
语言
[0171]
通过将本文所述的记忆系统连接到语言系统,可以在具身智能体能够进行交互的环境中对具身智能体建模,从而奠定具身智能体的意义。与提供符号性知识库相反,具身智能体从其接收的感觉输入和其产生的动作中自行建立意义。通过将本文所述的记忆系统与语言系统相连接,从特定语言中抽象出来的相关句法结构可以捕捉到跨语言泛化。
[0172]
回合记忆
[0173]
智能体能够体验世界上所发生事件的回合,这些回合可以用简单的句子来报告。回合是以句子语义单位表示的事件,围绕动作和其参与者。不同的对象在回合中扮演不同的“语义角色”/“主题角色”。例如,wm智能体是动作的原因或发起者,wm受动者是动作的目标或经历者。回合可能涉及智能体执行、感知其他智能体的动作、计划或想象事件或回忆过去的事件。与其他经验一样,回合可以被存储在经验记忆存储器和记忆数据库中。回合的表示可以在工作记忆系统中存储和处理,工作记忆系统将回合作为编码为离散动作的准备序列/规律进行处理。wm系统40将低层级对象/回合感知与记忆、(高级)行为控制和语言相连接。
[0174]
图11示出了工作记忆系统(wm系统)40,该系统被配置用于处理和存储回合。wm系统40包括wm回合42和wm个体41。wm个体41定义了以回合为特征的个体。wm回合42包括构成该回合的所有元素,包括wm个体和动作。在wm回合42的一个简单示例中,包括个体wm智能体和wm受动者:wm智能体、wm受动者和wm动作被相继处理以填充wm回合。
[0175]
个体存储器/介质46存储wm个体,并且可用于确定个体是新的还是被重新关注的个体。个体存储器/介质可被实现为som或asom,其中新个体存储在新募集的神经元的权重中,并且被重新关注的个体更新表示被重新关注的个体的神经元。在一个实施方案中,个体存储器/介质是cdz的会聚区,其存储个体的独特属性组合,诸如位置、数量和性质作为单独个体。asom期望具有高学习速率和几乎为零的邻近尺寸,能够立即学习个体(一次性学习)并且没有地形组织(使得不同个体的表示彼此不会影响)。不同个体的性质存储在不同神经元的权重中;为此,如果获胜神经元的活性度低于新颖性阈值,则募集新的未使用的神经元,否则更新获胜神经元的权重。
[0176]
位置、数量和性质相继从个体缓冲区48到达,一次一个。个体存储器/介质46系统始终使用非零字母查询已填写的分量,因此,如果最近在该位置看到个体,则能够,例如,根据位置预测数量和性质。然而,只有当位置-数量-性质序列成功完成时,系统中的可塑性才会开启。然后,个体存储器/介质46系统经历其学习周期,当完成时,会保持在原位一段时间,以允许将个体(连同其旧/新状态)复制到回合缓冲区的的相应智能体/受动者缓冲区中。
[0177]
回合存储器/介质47存储wm回合。回合存储器/介质可以实施为针对个体和动作组合进行训练的som或asom。在一个实施方案中,回合存储器/介质是cdz的会聚区,其存储独特的回合元素组合。回合存储器/介质47可以实施为具有三个输入字段的asom:智能体、受动者和动作,它们从各自的wm回合时隙获取输入。仅当输入字段的输入已成功处理时,输入字段的混合系数(α)才非零。这意味着,随着输入字段逐渐被填充,asom传递关于剩余输入字段的预测,例如,智能体通常参与哪些回合。
[0178]
个体缓冲区48相继获得个体的属性。当序列完成时(所有缓冲区的保留门关闭),回合存储器/介质47中的可塑性被开启,回合存储器/介质47能够将该特定的位置、数量和性质组合存储为新个体(或更新被重新关注的个体)。当回合存储器/介质47完成其处理时,整个循环再次开始。
[0179]
回合缓冲区相继获得回合的元素。回合存储器/介质系统中的可塑性仅在回合序列已成功完成时才开启。这确保如果注意机制猜测的回合参与者错误,就不会学习不正确的表示。
[0180]
强化学习分量
[0181]
如果感知回合为智能体带来特定奖励,则其能够作为附加输入字段与回合存储器/介质47中的回合相关联。在回合感知期间,asomα权重奖励为零的回合存储器/介质47将产生与当前感知回合相关联的预期奖励预测。在动作执行期间,奖励输入能够用于使介质准备好优先激活与特定奖励值相关联的回合。
[0182]
情绪
[0183]
如果感知回合与特定的感受情绪或情感值相连,则其能够作为附加输入字段与回合存储器/介质47中的回合相关联。在回合感知期间,情绪asomα权重为零的回合存储器/介质47将产生与预测回合相关联的情绪。在动作执行期间,情感值能够用于使介质准备好优先激活与类似情绪相关联的回合。
[0184]
具身智能体详情和变化
[0185]
自上而下和自下而上神经行为建模
[0186]
本发明的实施方案通过将能够突现行为的低层级建模与高层级抽象模型相结合来改善人工智能,虽然这些模型的生物学依据较少,但对给定任务来说更快且更有效。在us10181213b2中公开了具有能够突现行为的架构的具身智能体的实施例,该专利也转让给本发明的受让人,并且以引用方式并入本文。高度模块化的编程环境允许自上而下的认知架构,具有互连的高层级“黑匣子”(模块10)。理想情况下,每个“黑匣子”都包含一组互连的、生物学上合理的低层级模型,但也可以轻松包含:抽象规则或逻辑语句、访问知识库/数据库、会话引擎、使用传统机器学习神经网络或任何其他计算技术处理输入。每个模块12的输入和输出作为模块的“变量”公开,这些变量能够用于驱动行为(以及因此产生的动画参数)。连接器在模块12之间传送变量。在最简单的情况下,连接器在每个时间步骤将一个变量的值复制到另一个模块12。这些高层级符号过程与从低层级神经回路模型中突现的行为相结合。突现行为以自然方式与高层级过程相互作用。执行计算的回路连续并行运行,没有任何中心控制点。编程环境可以通过不允许任何单一控制脚本执行到模块12的指令序列来硬编码该原理。编程环境支持通过一组神经上更合理的分布式机制来控制认知和行为。
[0187]
泄漏积分器具有控制定时的三个主要参数:ifc、mfc和电压阈值。当修改参数以控制时间时,最简单的做法是调整mfc——增加以加快衰减,反之亦然。cdz中的典型电压阈值可以是0.1。
[0188]
情绪
[0189]
情绪被建模成协调的大脑-身体状态,其中有体验组分或感受成分和行为响应。对一种基于情感神经科学的方法进行建模,其中行为回路是由生理参数调节的。生理调节改变感觉、认知和运动状态的相互作用。虚拟神经递质是在对刺激的反应中产生的,能够映射
到情绪并指导行为反应。例如,“威胁性刺激”会触发虚拟去甲肾上腺素和皮质醇的释放,这两种物质为战斗或逃跑反应释放能量,并引发恐惧情绪。微笑的人脸或柔和的声音(根据某种函数评估)能够触发虚拟催产素和多巴胺,其映射到正效价状态和离散情绪诸如快乐,产生微笑的面部表情,并减少激动行为。
[0190]
优势
[0191]
因此,提供了一种实时学习网络架构——最突出的机器学习算法离线学习,并且需要大量数据。智能体能够自己学习(通过与环境交互),能够受教(由用户向其呈现特定刺激),或者能够完全由用户控制(通过植入记忆)。该架构是一种通用学习架构,能够学习不同类型的事物。
[0192]
此外,该实时学习网络架构并非黑匣子,因为能够了解突现行为的原因。可以追溯到导致行为的整个途径。som能够适应任何形式的输入,例如独热向量、rgb图像、来自深度神经网络的特征向量或任何其他输入。此外,该架构是可分层堆叠的——低层级输入被集成,并且进一步与其他关联区域集成。这允许不相交的模态间接相关,从而能够产生复杂行为。
[0193]
如本文所公开的映射允许智能体在实时操作过程中灵活地对事件进行编码并检索所存储的信息。在体验世界的过程中,表示记忆事件的映射会呈现要编码的新事件。但是,当具身智能体正在体验该事件时,相同映射被用在“查询模式”中,在其中呈现迄今为止体验的事件的部分,并要求预测剩余部分,因此这些预测能够用作感觉运动过程的自上而下引导。
[0194]
som提供了一种构建htm型系统的替代方式,但具有地形自组织优势,因此能够更好地聚集信息。与传统深度网络不同,som支持快速、一次性学习,而传统深度网络必须进行缓慢离线训练。som易于支持对其接收的输入模式进行泛化学习。som可以将其记忆存储在映射中的每个神经元的权重向量中。这允许双重表示:som的活性度表示多个选项上的概率分布,但每个选项的内容存储在每个神经元的权重中并且可自上而下重建。
[0195]
asom能够灵活地关联来自不同源/模态的输入,并且给予动态可变的注意力/重要性。激活流能够反向进行——asom支持自下而上(从输入到激活)和自上而下(从激活到重建输入)处理两者,以及它们的组合。som能够消除噪声输入或重建缺失部分,或者返回原型并突出显示输入和原型不同的部分。所有这一切都在som层级结构中的多个层级上发挥作用。
技术实现要素:
[0196]
在一个实施方案中:一种用于以动画方式显示具身智能体的方法,该方法包括以下步骤:接收与第一模态中的经验的第一表示相对应的感觉输入;查询经验记忆存储器,以检索第二模态中经验的第二表示;并且使用所述第二模态中的所述第二表示来以动画方式显示所述具身智能体。
[0197]
在另一个实施方案中:一种用于存储具身智能体的记忆的系统,该系统包括:经验记忆存储器,该经验记忆存储器由该具身智能体在操作过程中体验到的经验填充,其中每项经验与不同模态的该经验的多个表示相关联,并且该经验记忆存储器将该经验的表示存储在神经网络权重中;和记忆数据库,该记忆数据库用于存储在该经验记忆储器中存储的
该经验的副本,其中该记忆数据库存储有对应于不同模态的该经验的该表示的原始数据。
[0198]
在另一个实施方案中:一种选择性地存储由具身智能体在该具身智能体的实时操作过程中体验的经验的方法,该方法包括以下步骤:从用于接收多个模态的输入的多个输入流接收输入表示,其中每个输入流与至少一个条件相关联,该条件在该输入流中创建资格迹;检测两个或更多个输入流的同时资格迹(“合资格”输入流);以及存储和关联来自该合资格输入流的该输入表示。
[0199]
在另一个实施方案中:一种用于训练som的方法,该som包括多个神经元和训练记录,每个神经元与权重向量相关联;该方法包括以下步骤:接收输入向量;确定该输入向量是否为“新的”;如果该输入向量不是新的:选择第一获胜神经元,促进该输入向量与该获胜神经元之间更高的相似性,并且向着该输入向量修改该第一获胜神经元的该权重向量;
[0200]
如果该输入向量是新的:选择第二获胜神经元,促进具有较低训练记录的神经元,并且向着该输入向量修改该第二获胜神经元的该权重向量。
[0201]
在另一个实施方案中:一种选择性地存储由具身智能体在该具身智能体的操作过程中体验的经验的方法实施系统,该方法包括以下步骤:
[0202]
从用于接收多个模态的输入的多个输入流接收输入表示,其中每个输入流与至少一个条件相关联,该条件在该输入流中创建资格迹;检测两个或更多个输入流的同时资格迹(“合资格”输入流);以及存储和关联来自该合资格输入流的该输入表示。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1