从影像学习铰接形状重建的制作方法
1.本公开总体上涉及三维(“3d”)重建。更具体地,本公开涉及从影像(例如,rgb输入图像)重建对象(例如,非刚性对象)的模型的系统和方法。
背景技术:
2.对3d实体进行建模是开发三维的对象(例如,对象的表面)的数学表示的过程。对3d实体的动态进行建模可以涉及使用描述对象的数据来构建可以被变形为各种姿态的对象的3d网格形状。
3.一些标准的3d建模方法依赖于3d监督,诸如合成渲染和深度扫描。然而,由于当前的传感器设计,深度数据通常难以获取,并且甚至更难以放大。其他标准3d建模方法依赖于从多个静态图像的点轨迹推断3d形状。这些标准模型能够在具有丰富训练标签的基准上实现高精度,然而,它们不能在低数据制度内推广。此外,当图像观察贫乏时,这种方法经常产生不准确的3d结构的幻觉。
4.虽然通过利用多视图数据记录在不依赖于强形状先验知识的情况下在该领域中已经取得了进展,但是这种结果受限于静态场景。
技术实现要素:
5.本公开的实施例的方面和优点将在以下描述中部分地阐述,或者可以从描述中获知,或者可以通过实施例的实践获知。
6.本公开的一个示例方面涉及一种用于从影像确定3d对象形状的计算机实现的方法。该方法包括计算系统获得一个或多个计算设备、描绘对象的输入图像和对象的当前网格模型。该方法包括计算系统利用相机模型处理输入图像,以获得输入图像的相机参数和对象变形数据。相机参数描述输入图像的相机姿态。对象变形数据描述当前网格模型相对于输入图像中示出的对象的形状的一个或多个变形。该方法包括计算系统基于相机参数、对象变形数据和当前网格模型来可微分地渲染对象的渲染图像。该方法包括计算系统评估损失函数,该损失函数将对象的输入图像的一个或多个特性与对象的渲染图像的一个或多个特性进行比较。该方法包括计算系统基于损失函数的梯度来修改相机模型和当前网格模型中的一个或两者的一个或多个值。
7.本公开的其他方面涉及各种系统、装置、非暂时性计算机可读介质、用户界面和电子设备。
8.参考以下描述和所附权利要求,将更好地理解本公开的各种实施例的这些和其他特征、方面和优点。并入本说明书中并构成其一部分的附图示出了本公开的示例实施例,并与描述一起用于解释相关原理。
附图说明
9.面向本领域普通技术人员的实施例的详细论述在参考附图的说明书中阐述,在附
图中:
10.图1a描绘了根据本公开的示例实施例的执行学习铰接形状重建(lasr)的示例计算系统的框图。
11.图1b描绘了根据本公开的示例实施例的执行铰接形状重建的示例计算设备的框图。
12.图1c描绘了根据本公开的示例实施例的执行铰接形状重建的示例计算设备的框图。
13.图2描绘了根据本公开的示例实施例的示例3d重建技术的框图。
14.图3描绘了学习铰接形状重建方法的方法概述的流程图。
15.图4示出了从粗到细的重建的示例。
16.图5示出了使用各种网格重建方法的网格重建的人类和动物的视觉比较的示例。
17.图6示出了使用各种网格重建方法的网格重建的人类和动物的视觉比较的另一个示例。
18.图7示出了使用各种关键点转移方法的关键点转移的示例。
19.图8示出了使用各种形状和铰接重建方法在不同时间戳处的形状和铰接重建结果的示例。
20.图9示出了colmap和lasr方法之间的近刚性视频序列的重建的视觉比较。
21.图10示出了使用各种方法的相机和刚性形状优化以及使用各种方法的铰接形状优化的消融研究结果的示例。
22.图11描绘了根据本公开的示例实施例的执行lasr的示例方法的流程图。
23.跨多个附图重复的附图标记旨在在各种实施方式中识别相同的特征。
具体实施方式
24.概述
25.总的来说,本公开涉及一种计算系统和方法,其可以用于从对象的图像,诸如例如对象的单目视频,重建对象的3d形状。具体地,本公开提供了用于从一个或多个图像学习铰接形状重建(其可以被称为lasr)的通用流水线。该流水线可以重建刚性或非刚性3d形状的模型。具体地,本文描述的示例流水线可以将非刚性地变形的形状自动分解成刚性骨骼附近的刚性运动。该流水线合并合成分析策略,并正向渲染轮廓、光流和彩色图像,该轮廓、光流和彩色图像可以与视频观察进行比较以调整模型的内部参数。通过反转渲染流水线并合并诸如光流的图像分析技术,流水线可以从由用户输入的一个或多个图像恢复3d模型的网格。
26.更具体地,示例3d建模流水线可以执行合成分析任务,其中可以通过最小化损失函数来与机器学习的相机模型一起联合学习对象的机器学习的网格模型,该损失函数评估对象的一个或多个输入图像和对象的一个或多个渲染图像之间的差异。此外,可以从对象的一个或多个图像的单个集合构建形状模型库。流水线可以解决恢复3d对象形状(例如,时空变形)和相机轨迹(例如,本征)的逆图形问题,以便拟合视频或图像帧观察,诸如轮廓、原始像素和光流。作为另一个示例,可以通过对描绘多个对象的多个图像执行流水线来构建形状模型库。
27.用于从一个或多个图像进行3d形状学习的无模型方法的示例方法可以包括获得描绘对象的输入图像和对象的当前网格模型。具体地,真实值(ground truth)可以被包括在一个或多个图像的集合中。例如,真实值可以是一个或多个单目序列,诸如由单目相机捕获的视频。作为另一个示例,单目序列可以具有前景对象的分割。
28.可以用机器学习的相机模型来处理输入图像。机器学习的相机模型可以预测关于真实值数据的信息。具体地,该信息可以包括相机参数和/或对象变形数据。相机参数可以描述输入图像(例如,相对于参考位置和/或姿态)的相机姿态。对象变形数据可以描述当前网格模型的一个或多个变形。例如,当前网格模型的变形可以是当前网格模型和图像中示出的对象的形状之间的相对变化。
29.对象的渲染图像可以被可微分地渲染(例如,使用可微分渲染技术)。渲染的图像可以是基于相机参数、对象变形数据和当前网格模型。渲染的图像可以描绘根据对象变形数据和从由相机参数描述的相机姿态而变形的当前网格模型。
30.可以评估损失函数,该损失函数将对象的输入图像的一个或多个特性与对象的渲染图像的一个或多个特性进行比较。可以基于损失函数来修改机器学习的相机模型和当前网格模型中的一个或两者的一个或多个值。例如,修改机器学习的相机模型和当前网格模型中的一个或两者可以是至少部分基于梯度信号,其中,梯度信号描述损失函数相对于模型的参数的梯度。
31.在一些实施方式中,评估损失函数可以包括评估对象的一个或多个输入图像和对象的一个或多个渲染图像之间的差异。具体地,在特定帧处的相机姿态可以被包括在损失函数评估中。甚至更具体地,特定骨骼围绕其父关节的旋转可以被包括在损失函数评估中。甚至更具体地,静止形状的顶点3d坐标可以被包括在损失函数评估中。例如,在评估损失函数中使用的运动正则项可以包括时间平滑度项、最小运动项和尽可能刚性项。作为又一个示例,在评估损失函数中使用的形状正则项可以包括拉普拉斯平滑度项和规范化项,以消除多个解的歧义直到刚性变换。一个或多个渲染的图像可以包括基于机器学习的网格模型结合由机器学习的相机模型生成的相机参数渲染的图像。由机器学习的相机模型生成的数据可以源自一个或多个输入图像。流水线可以进一步指示系统接收附加的相机参数集合。流水线可以再次进一步指示系统至少部分地基于机器学习的网格模型和附加的相机参数集合来渲染对象的附加渲染图像。
32.在一些实施方式中,评估损失函数可以包括确定第一流(例如,使用一个或多个光流技术等)和第二流(例如,基于跨图像渲染的已知变化)。第一流可以用于输入图像,而第二流可以用于渲染图像。损失函数可以至少部分地基于第一流和第二流的比较来评估。
33.在一些实施方式中,评估损失函数可以包括确定第一轮廓(例如,使用一种或多种分割技术等)和第二轮廓(例如,基于渲染图像内的对象的已知位置)。第一轮廓可以用于输入图像,而第二轮廓可以用于渲染图像。可以至少部分基于第一轮廓和第二轮廓的比较来评估损失函数。
34.在一些实施方式中,评估损失函数可以包括确定第一纹理数据(例如,使用原始像素数据和/或各种特征提取技术)和第二纹理数据(例如,使用来自渲染图像的已知纹理数据)。第一纹理数据可以用于输入图像,而第二纹理数据可以用于渲染图像。可以至少部分基于第一纹理数据和第二纹理数据的比较来评估损失函数。
35.作为一个示例,评估损失函数可以包括生成梯度信号。通过将对象的输入图像的一个或多个特性与对象的渲染图像的一个或多个特性进行比较,可以为损失函数生成梯度信号。作为一个示例,通过将输入图像的第一流和渲染图像的第二流进行比较,可以为损失函数生成梯度信号。作为另一个示例,通过将输入图像的第一轮廓和渲染图像的第二轮廓进行比较,可以为损失函数生成梯度信号。作为又一个示例,通过将与输入图像相关联的第一纹理数据和与渲染图像相关联的第二纹理数据进行比较,可以为损失函数生成梯度信号。
36.在一些实施方式中,获得描绘该对象的输入图像可以包括选择规范图像。具体地,规范图像可以是来自视频的图像帧。可以自动或手动选择规范图像。作为用于选择规范输入图像的一个示例,可以选择一个或多个候选帧。可以评估候选帧中的每个候选帧的损失。具有最低最终损失的候选帧可以被选择为规范帧。
37.在一些实施方式中,网格模型可以包括构建网格模型的各种形状。例如,网格模型可以是多边形网格。多边形网格可以包括顶点集合、多个关节、多个关节相对于多个顶点的多个混合蒙皮权重、和/或定义多面体对象的形状的边和面。具体地,多边形网格的面可以由凹多边形、带孔多边形、简单凸多边形以及其他更特定的结构(例如,三角形、四边形等)组成。作为另一个示例,网格模型可以被初始化为投影到球体的细分的二十面体。在一些实施方式中,线性混合蒙皮算法可以用于使网格模型变形。在一些实施方式中,多个关节和多个混合蒙皮权重是可学习的。
38.在一些实施方式中,相机参数可以描述输入图像的对象到相机变换。作为一个示例,可以通过将刚性3d变换矩阵应用于以对象为中心的坐标的矩阵来创建3d对象的不同视图。通过应用对象到相机变换,以对象为中心的坐标的矩阵可以被变换到以相机为中心的坐标。甚至更具体地,对其计算变换的对象可以具有已知的几何模型。相机的校准可以通过捕捉现实世界对象的图像并在图像中定位一组标志点来开始。可以使用任何合适的技术找到图像中的标志点的位置(即姿态)。
39.在一些实施方式中,机器学习的相机模型可以包括卷积神经网络。例如,卷积神经网络可以估计相机姿态。具体地,卷积神经网络可以使用其位置向量和取向四元数来表示相机姿态。卷积神经网络可以通过被训练为最小化真实值数据和估计的姿态之间的损失而被训练为确定相机姿态。作为另一个示例,卷积神经网络可以预测相机外部因素(例如,相机在世界中的位置,相机指向什么方向,等等)。具体地,相机外部因素可以是至少部分基于相机校准。
40.在一些实施方式中,相机参数可以描述内在相机参数(例如,焦距、图像中心、纵横比等)。可以为输入图像描述内在相机参数。特别地,内在相机参数可以是至少部分基于相机校准。
41.在一些实施方式中,骨架的动态可以被共享。例如,如果一个骨架达到与存在更多数据或者存在更好的3d模型(例如,在库中)的另一个骨架的相似性的确定的阈值,则系统可以将来自一个3d模型的信息应用于另一个3d模型以改进第二3d模型(例如,如果没有足够的数据来以相同的精度创建第二3d模型)。
42.在一些实施方式中,可以合并关键点约束。此外,形状模板先验知识可以加快推断速度并提高准确性。
43.因此,本公开提供了用于从一个或多个图像(例如,单个视频)进行3d形状学习的无模板方法。示例实施方式采用合成分析策略,并正向渲染轮廓、光流和/或彩色图像,该轮廓、光流和/或彩色图像与视频观察进行比较以调整模型的相机、形状和/或运动参数。所提出的技术能够准确地重建刚性和非刚性3d形状(例如,人类、动物和野外的类别),而不依赖于类别或3d形状先验知识。
44.本公开的系统和方法提供了许多技术效果和益处。作为一个示例技术效果,所提出的技术能够从有限的图像数据(例如,单目视频)执行铰接形状重建,而不依赖于先前的模板或类别信息。具体地,示例实施方式利用两帧光流来克服非刚性结构的固有不完整性和运动估计问题。通过使得能够从有限的数据进行模型重建,并且不依赖于对象或类别特定的先验知识,本文描述的技术能够扩展能够生成准确3d模型的对象的范围。具体地,许多现有的非刚性形状重建方法依赖于先验形状模板,诸如用于人类的smpl、用于四足动物的smal以及其他类别特定的3d扫描。相反,所提出的系统和方法可以在不使用形状模板或类别信息的情况下从对象的单目视频联合恢复相机、形状和铰接。通过减少对先验知识的依赖,所提出的系统和方法可以被应用于更宽范围的非刚性形状,并且更好地拟合数据。
45.作为另一示例技术效果,一些示例实施方式在线性混合蒙皮下在刚性骨骼的约束下自动恢复非刚性形状。示例实施方式可以将从粗到细的重新网格化与软对称约束相结合,以恢复高质量网格。
46.本文进一步描述的并且在所提出的技术的示例实施方式上进行的示例实验证明了在badja动物视频数据集中的最先进的重建性能、对人类的基于模型的方法的强大性能、以及对两个动画动物的比使用形状模板的a-csm和smalify更高的准确性。
47.示例设备和系统
48.图1a描绘了根据本公开的示例实施例执行铰接形状重建的示例计算系统100的框图。系统100包括通过网络180通信耦合的用户计算设备102、服务器计算系统130和训练计算系统150。
49.用户计算设备102可以是任何类型的计算设备,诸如例如个人计算设备(例如,膝上型或台式)、移动计算设备(例如,智能手机或平板电脑)、游戏控制台或控制器、可穿戴计算设备、嵌入式计算设备或任何其他类型的计算设备。
50.用户计算设备102包括一个或多个处理器112和存储器114。一个或多个处理器112可以是任何合适的处理设备(例如,处理器内核、微处理器、asic、fpga、控制器、微控制器等)并且可以是可操作地连接的一个处理器或多个处理器。存储器114可以包括一个或多个非暂时性计算机可读存储介质,诸如ram、rom、eeprom、eprom、闪存设备、磁盘等以及其组合。存储器114可以存储数据116和由处理器112执行以使用户计算设备102执行操作的指令118。
51.在一些实施方式中,用户计算设备102可以存储或包括一个或多个3d重建模型120。例如,3d重建模型120可以是或者可以另外包括各种机器学习的模型,诸如神经网络(例如,深度神经网络)或者其他类型的机器学习的模型,包括非线性模型和/或线性模型。神经网络可以包括前馈神经网络、递归神经网络(例如,长短期记忆递归神经网络)、卷积神经网络或其他形式的神经网络。参考图2讨论示例3d重建模型120。
52.在一些实施方式中,一个或多个机器学习的模型120可以通过网络180从服务器计
算系统130被接收,被存储在用户计算设备存储器114中,并且然后由一个或多个处理器112使用或以其他方式实现。在一些实施方式中,用户计算设备102可以实现单个3d重建模型120的多个并行实例(例如,跨输入图像的多个实例执行并行3d重建)。
53.更具体地,3d重建模型可以在不使用形状模板或类别信息的情况下从对象的一系列图像联合恢复相机、形状和铰接。
54.附加地或替代地,一个或多个机器学习的模型140可以被包括在根据客户端-服务器关系与用户计算设备102通信的服务器计算系统130中,或者由服务器计算系统130存储和实现。例如,机器学习的模型140可以由服务器计算系统140实现为网络服务(例如,流传输服务)的一部分。因此,一个或多个模型120可以在用户计算设备102处存储和实现,和/或一个或多个模型140可以在服务器计算系统130处存储和实现。
55.用户计算设备102还可以包括接收用户输入的一个或多个用户输入组件122。例如,用户输入组件122可以是对用户输入对象(例如,手指或触笔)的触摸敏感的触敏组件(例如,触敏显示屏或触摸板)。触敏组件可以用来实现虚拟键盘。其他示例用户输入组件包括麦克风、传统键盘或用户可以用来提供用户输入的其他装置。
56.服务器计算系统130包括一个或多个处理器132和存储器134。一个或多个处理器132可以是任何合适的处理设备(例如,处理器内核、微处理器、asic、fpga、控制器、微控制器等)并且可以是可操作地连接的一个处理器或多个处理器。存储器134可以包括一个或多个非暂时性计算机可读存储介质,诸如ram、rom、eeprom、eprom、闪存设备、磁盘等以及其组合。存储器134可以存储数据136和由处理器132执行以使服务器计算系统130执行操作的指令138。
57.在一些实施方式中,服务器计算系统130包括一个或多个服务器计算设备或者由一个或多个服务器计算设备来实现。在服务器计算系统130包括多个服务器计算设备的情况下,这样的服务器计算设备可以根据顺序计算架构、并行计算架构或其某种组合来操作。
58.如上所述,服务器计算系统130可以存储或以其他方式包括一个或多个3d重建模型140。例如,模型140可以是或者可以包括各种机器学习的模型。示例机器学习的模型包括神经网络或其他多层非线性模型。示例神经网络包括前馈神经网络、深度神经网络、递归神经网络和卷积神经网络。参考图2讨论示例模型140。
59.用户计算设备102和/或服务器计算系统130可以经由与通过网络180通信耦合的训练计算系统150的交互来训练模型120和/或140。训练计算系统150可以与服务器计算系统130分离,或者可以是服务器计算系统130的一部分。
60.训练计算系统150包括一个或多个处理器152和存储器154。一个或多个处理器152可以是任何合适的处理设备(例如,处理器内核、微处理器、asic、fpga、控制器、微控制器等)并且可以是可操作地连接的一个处理器或多个处理器。存储器154可以包括一个或多个非暂时性计算机可读存储介质,诸如ram、rom、eeprom、eprom、闪存设备、磁盘等以及其组合。存储器154可以存储数据156和由处理器152执行以使训练计算系统150执行操作的指令158。在一些实施方式中,训练计算系统150包括一个或多个服务器计算设备或者由一个或多个服务器计算设备实现。
61.训练计算系统150可以包括模型训练器160,其使用各种训练或学习技术,诸如例如误差的反向传播,来训练存储在用户计算设备102和/或服务器计算系统130处的机器学
习的模型120和/或140。例如,损失函数可以通过模型反向传播,以更新模型的一个或多个参数(例如,基于损失函数的梯度)。可以使用各种损失函数,诸如均方误差、似然损失、交叉熵损失、铰链损失和/或各种其他损失函数。梯度下降技术可以用于在多次训练迭代中迭代地更新参数。
62.在一些实施方式中,执行误差的反向传播可以包括随时间执行截短的反向传播。模型训练器160可以执行多种泛化技术(例如,权重衰减、退出等)来提高被训练的模型的泛化能力。
63.具体地,模型训练器160可以基于训练数据162的集合来训练3d重建模型120和/或140。训练数据162可以包括例如一个或多个图像的集合。在一些实施方式中,一个或多个图像可以指向感兴趣对象。在一些实施方式中,一个或多个图像可以串在一起成为视频。在一些实施方式中,视频可以是单目视频。
64.在一些实施方式中,如果用户已经提供了同意,则训练示例可以由用户计算设备102提供。因此,在这样的实施方式中,提供给用户计算设备102的模型120可以由训练计算系统150在从用户计算设备102接收到的用户特定数据上训练。在某些情况下,这个过程可以被称为使模型个性化。
65.模型训练器160包括用于提供所需功能的计算机逻辑。模型训练器160可以用控制通用处理器的硬件、固件和/或软件来实现。例如,在一些实施方式中,模型训练器160包括存储在存储设备上、加载到存储器中并由一个或多个处理器执行的程序文件。在其他实施方式中,模型训练器160包括一个或多个计算机可执行指令集合,这些指令被存储在诸如ram、硬盘或光学或磁性介质的有形计算机可读存储介质中。
66.网络180可以是任何类型的通信网络,诸如局域网(例如,内联网)、广域网(例如,互联网)或其某种组合,并且可以包括任何数量的有线或无线链路。一般而言,通过网络180的通信可以使用各种通信协议(例如,tcp/ip、http、smtp、ftp)、编码或格式(例如,html、xml)和/或保护方案(例如,vpn、安全http、ssl)经由任何类型的有线和/或无线连接来承载。
67.图1a示出了可以用于实现本公开的一个示例计算系统。也可以使用其他计算系统。例如,在一些实施方式中,用户计算设备102可以包括模型训练器160和训练数据集162。在这样的实施方式中,模型120可以在用户计算设备102处本地训练和使用。在一些这样的实施方式中,用户计算设备102可以实现模型训练器160以基于用户特定的数据来使模型120个性化。
68.图1b描绘了根据本公开的示例实施例执行的示例计算设备10的框图。计算设备10可以是用户计算设备或服务器计算设备。
69.计算设备10包括多个应用(例如,应用1至n)。每个应用都包含它自己的机器学习库和机器学习的模型。例如,每个应用可以包括机器学习的模型。示例应用包括文本消息应用、电子邮件应用、听写应用、虚拟键盘应用、浏览器应用等。
70.如图1b所示,每个应用可以与计算设备的多个其他组件通信,这些组件诸如例如为一个或多个传感器、场境管理器、设备状态组件和/或附加组件。在一些实施方式中,每个应用可以使用api(例如,公共api)与每个设备组件通信。在一些实施方式中,由每个应用使用的api是特定于该应用的。
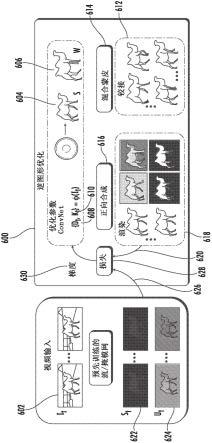
71.图1c描绘了根据本公开的示例实施例执行的示例计算设备50的框图。计算设备50可以是用户计算设备或服务器计算设备。
72.计算设备50包括多个应用(例如,应用1至n)。每个应用都与中央智能层通信。示例应用包括文本消息应用、电子邮件应用、听写应用、虚拟键盘应用、浏览器应用等。在一些实施方式中,每个应用可以使用api(例如,跨所有应用的公共api)与中央智能层(以及存储在其中的模型)通信。
73.中央智能层包括许多机器学习的模型。例如,如图1c所示,可以为每个应用提供相应的机器学习的模型,并且相应的机器学习的模型由中央智能层管理。在其他实施方式中,两个或更多个应用可以共享单个机器学习的模型。例如,在一些实施方式中,中央智能层可以为所有应用提供单个模型。在一些实施方式中,中央智能层被包括在计算设备50的操作系统中,或者由计算设备50的操作系统来实现。
74.中央智能层可以与中央设备数据层通信。中央设备数据层可以是计算设备50的集中式数据储存库。如图1c所示,中央设备数据层可以与计算设备的多个其他组件通信,这些组件诸如例如为一个或多个传感器、场境管理器、设备状态组件和/或附加组件。在一些实施方式中,中央设备数据层可以使用api(例如,私有api)与每个设备组件通信。
75.示例模型设置
76.图2描绘了根据本公开的示例实施例的示例3d重建流水线200的框图。在一些实施方式中,可以执行3d重建流水线200来接收描绘感兴趣对象的一个或多个图像204的集合(例如,指向感兴趣对象的单目视频),并且作为接收到图像204的结果,提供感兴趣对象的重建的3d模型206。在一些实施方式中,3d重建流水线200可以包括执行逆图形优化202,该逆图形优化包括求解逆图形优化问题,该逆图形优化问题可以通过基于视频的优化来联合恢复对象的静止形状、蒙皮权重、铰接和/或相机参数。
77.示例方法
78.如图3所示,在给定一个或多个图像(诸如单目视频{i
t
})的输入的情况下,本公开的一些示例实施方式利用求解非刚性3d形状和运动估计问题作为合成分析任务的某些方法。下面描述的方法可以通过给出适当的视频测量来在一定尺度上求解“低级”形状和运动,尽管该问题具有约束不足的性质。图3示出了计算系统600的基本步骤的示例实施例,其中首先可以将感兴趣对象(例如,用户希望创建其3d模型的对象)602的一个或多个图像,更具体地是单目视频{i
t
},输入到计算系统中。感兴趣对象可以由分割掩模{s
t
}622指示。
79.计算系统可以求解逆图形问题,以通过优化方法(例如,基于视频的优化)联合恢复对象的静止形状s 604、蒙皮权重w 606、时变铰接以及对象-相机变换d
t 608和/或相机参数,另外称为相机内在因素k
t 610。该方法可以迭代地重复,并且在每次迭代中,可以对多个连续的图像帧进行采样。例如,可以随机地采样c=8对连续帧。将理解,可以替代地使用其他数量的连续帧。在一些实施方式中,采样帧可以不是连续的。视频中的一些帧可以被跳过,例如可以采用每隔一帧或者每隔两帧。
80.随机采样的帧可以被馈送到卷积神经网络。卷积神经网络可以预测时变相机和运动参数。静止形状s 604,也称为平均形状,可以经历线性混合蒙皮过程614。线性混合结皮过程614可以根据下面讨论的进一步细节而进行。给定某些参数(例如,预测的铰接参数d
t 608、蒙皮权重w 606等),线性混合蒙皮过程614可以输出铰接静止形状612。
81.接下来,计算系统可以利用可微分渲染器616正向渲染纹理、光流和轮廓图像。根据下面讨论的进一步细节,可以利用可微分渲染器进行正向渲染。正向渲染可以输出渲染618,渲染618可以被输入620到损失函数628中。真实值像素、真实值光流624、真实值分割{s
t
}622也被输入626到损失函数628中。
82.损失函数628可以被评估以生成一个或多个梯度630。一个或多个梯度630可以用于更新相机k
t 610、形状s 604和铰接参数d
t 608。一个或多个梯度630可以用于使用梯度下降来更新k
t 610、形状s 604和铰接参数d
t 608,以最小化渲染的输出y=f(x)和在测试时的真实值视频测量y
*
之间的差异。为了处理对象形状s 604、变形和相机运动中的基本模糊性,以下公开可以利用变形的“低级”但富有表现力的参数化、由光流和原始像素提供的丰富约束以及对象形状变形和相机运动的适当正则化。
83.示例正向合成模型
84.继续以上计算系统的示例步骤,在一些实施方式中,计算系统可以利用可微分渲染器616正向渲染纹理、光流和轮廓图像。给定帧索引t和模型参数x,可以合成对应帧对{t,t+1}的测量,包括彩色图像渲染对象轮廓渲染和正向-后向光流渲染
85.在一些实施方式中,对象形状可以被表示为具有n个彩色顶点和m个面的固定拓扑的网格。该网格可以是三角形网格。时变铰接d
t
可以通过来建模,其中
△vt
可以是应用于静止顶点的每顶点运动场,并且g
0,t
=(r0|t0)
t
可以是对象-相机变换矩阵(索引0可以用于区分在由计算系统利用的变形建模中从1索引的骨骼变换)。最后,可以在光栅化之前应用透视投影k
t
,其中,可以假设主点(p
x
,py)是恒定的,并且焦距f
t
随时间变化以处理缩放。
86.在一些实施方式中,可以利用可微分渲染器来渲染对象轮廓和彩色图像。给定每顶点外观c和恒定的环境光,可以渲染彩色图像。可以通过获取对应于帧t中的每个像素的表面位置v
t
、计算它们在下一帧中的位置v
t+1
、然后获取它们的投影的差来完成合成正向流例如:
[0087][0088]
其中,p(i)可以表示投影矩阵p的第i行。
[0089]
示例变形建模
[0090]
如上所述,在一些实施方式中,计算系统可以构建感兴趣对象的变形建模。变形建模可以利用多个计算过程。利用于变形建模的计算过程可以包括线性混合蒙皮(继续上述计算系统的示例步骤)和参数化蒙皮。可以分析求解逆问题的未知数和约束的数量。给定视频的t个帧,
[0091][0092]
其可以随着顶点的数量而线性增长。因此,可以生成形状和运动的富有表现力但
低级的表示。
[0093]
继续以上计算系统的示例步骤,在一些实施方式中,计算系统可以利用线性混合蒙皮。建模变形的一些实施方式可以将建模变形用作每顶点运动
△vt
。在其他实施方式中,线性混合蒙皮模型可以通过混合b个刚性“骨骼”变换{g1,
…
,gb}来约束顶点运动,这可以减少参数的数量并使优化更容易。除了骨骼变换,lbs模型还可以定义蒙皮权重矩阵该矩阵将静止形状顶点的顶点附加到骨骼集合。可以通过在对象坐标系中线性组合加权骨骼变换来变换每个顶点,然后将顶点变换到相机坐标系,例如:
[0094]vi,t
=g
0,t
(∑jw
j,igj,t
)vi[0095]
其中i可以是顶点索引,并且j可以是骨骼索引。在一些实施方式中,蒙皮权重和时变骨骼变换可以被联合学习。
[0096]
在一些实施方式中,计算系统可以利用参数化蒙皮。蒙皮权重可以被建模为高斯混合,例如:
[0097][0098]
其中可以是第j个骨骼的位置,qj可以是确定高斯的取向和半径的对应精度矩阵,并且c可以是可以确保将顶点分配给不同骨骼的概率总和为一的归一化因子。特别地,w
→
{q,j}可以被优化。值得注意的是,在一些实施方式中,高斯模型的混合将蒙皮权重的参数的数量从nb减少到9b。在进一步的实施方式中,高斯模型的混合也可以保证平滑度。形状和运动参数的数量现在可以表示为:
[0099][0100]
其可以相对于帧和骨骼的数量而线性增长。
[0101]
从视频的示例自我监督学习
[0102]
在一些实施方式中,可以利用来自密集光流和原始像素的丰富监督信号。此外,在一些实施方式中,可以利用形状和运动正则化器来进一步约束该问题。
[0103]
在一些实施方式中,可以利用逆图形损失。例如,对合成分析流水线的监督可以包括轮廓损失、纹理损失和光流损失。轮廓损失将渲染的纹理与测量的轮廓进行比较,例如使用l2损失。纹理损失将渲染的纹理与测量的纹理进行比较,例如使用l1损失和/或感知距离。光流损失将渲染的光流与测量的光流进行比较,例如使用l2损失。例如,给定一对渲染的输出和测量(s
t
,i
t
,u
t
),逆图形损失可以被计算为,
[0104][0105]
其中,{β1,
…
,β4}可以是根据经验选择的权重,σ
t
可以是用于流测量的归一化置信图,并且pdist(
·
,
·
)可以是感知距离。在一些实施方式中,将l1损失应用于光流可能比l2损失更好。例如,由于l1流损失对离群值(例如,非刚性运动)更宽容。
[0106]
在一些实施方式中,可以利用形状和运动正则化。例如,可以利用一般的形状和时间正则化来进一步约束该问题。拉普拉斯平滑度操作可以用于增强表面平滑度,例如:
[0107]
[0108]
运动正则化可以包括最小运动项、arap(尽可能刚性)变形项和时间平滑项中的一个或多个。最小运动项可以促进铰接形状保持接近静止形状,并且可以是基于对象的网格顶点和对象的静止顶点之间的差异,例如:
[0109][0110]
这可以有效地解决形状变形模糊性,即,修改形状可以被表达为将骨骼变换应用于原始形状。arap项可以用于促进自然变形,其可以是基于连续帧中的顶点间距离之间的差异,例如:
[0111][0112]
在一些实施方式中,一阶时间平滑可以被应用于相机旋转(j=0)和骨骼旋转(j=1,
…
,b),诸如:
[0113][0114]
其中可以使用测地线距离来比较旋转。
[0115]
在一些实施方式中,可以利用软对称约束。例如,可以利用在普通对象类别中展示的反射对称结构。例如,对于静止形状和蒙皮权重两者,可以在对象帧中沿y-z平面(即(n0,d0)=(1,0,0,0,0))设定软对称约束。
[0116]
在某些情况下,静止形状和反射的静止形状可以相似。
[0117][0118]
其中可以是householder反射矩阵,并且可以将倒角距离(chamfer distance)计算为双向像素到面距离。类似地,对于静止骨骼j,可以通过下式计算
[0119][0120]
最后,可以应用规范化项,
[0121][0122]
其中t
*
可以是规范帧,并且n
*
可以是该帧中的对称平面。例如,规范相机姿态可以被偏置以与对称平面对齐。对称平面可以用近似值初始化并优化。总损失可以是所有损失的加权和,权重根据经验选择,并在所有实验中保持不变。
[0123]
示例实现细节
[0124]
在一些实施方式中,可以利用相机和姿态获得实现细节。在一些实施方式中,可以直接优化时变参数{d
t
,k
t
}。在一些实施方式中,在给定输入图像i
t
的情况下,可以将时变参数{d
t
,k
t
}参数化为来自卷积网络的预测,
[0125]
ψw(i
t
)=(k,g0,g1,g2,
…
,gb)
t
,
[0126]
在可以为焦距预测一个参数的情况下,可以为由四元数(quaterion)参数化的每个骨骼旋转预测多个参数(例如,四个),并且可以为每个平移预测多个参数(例如,三个)。这些数量可以被加到每一帧的总共1+7(b+1)个数量中。预测的相机和姿态预测可以用于合成视频,这些视频与生成梯度以更新权重w的原始测量y
*
进行比较。该网络可以学习相机和姿态的联合基础,该联合基础比原始参数更容易优化。
[0127]
在一些实施方式中,可以利用轮廓和流测量获得实现细节。可以假设提供了前景
对象的可靠分割。可以使用实例分割和跟踪方法来手动注释或估计分割。可以利用合理的光流估计,其可以由在数据集的混合上训练的最先进的流估计器来提供。值得注意的是,学习铰接形状重建可以从一些不良流初始化恢复,并且获得更好的长期对应。
[0128]
在一些实施方式中,可以利用从粗到细的重建获得实现细节,如图4所示。可以利用从粗到细的策略来重建高质量的网格。对于s0,702,可以假设刚性对象,并且可以针对l个时期优化静止形状和相机{s,g
0,t
,k
t
}。对于s1-s3,704、706和708,可以联合优化所有参数{s,d
t
,k
t
},并且可以在每l个时期之后执行重新网格化,这可以重复多次。(例如,它可以被重复三次,第一重新网格化704、第二重新网格化706和第三重新网格化708)。在每次重新网格化之后,顶点的数量和骨骼的数量两者都会增加,如图4所示。
[0129]
在一些实施方式中,可以利用初始化获得实现细节。静止形状可被初始化为在s0 702处投影到球体上的细分的二十面体。可以通过在s1-s3 704、706和708处在顶点的坐标上运行k均值(k-means)来初始化静止骨骼。视频的第一帧可以被选择为规范帧,并且规范对称平面n
*
可以(通过提供y-z平面或x-y平面中的一个)手动给出,或者从八个假设中选择,这八个假设的方位角和仰角可以在半球上均匀间隔开,这是通过对每个假设并行运行s0 702并选取具有最低最终损失的假设来实现的。
[0130]
动物视频上的示例2d关键点转移
[0131]
例如,用户可以对动物视频数据集使用该计算系统,该数据集可以提供具有2d关键点和掩模注释的多个真实动物视频(例如,九个真实动物视频)。这些数据可以从视频分割数据集或在线库存影片中获得。它可以包括许多动物的许多视频,这些动物诸如狗(例如,狗的三个视频)、跳马(例如,跳马的两个视频)和骆驼、牛、熊以及黑斑羚(例如,骆驼、牛、熊和黑斑羚各一个)。
[0132]
为了近似3d形状和铰接恢复的精度,可以使用正确关键点转移百分比(pck-t)。给定具有2d关键点注释的参考和目标图像对,参考关键点可以被转移到目标图像,并且如果转移的关键点在距目标关键点的某个阈值距离内,则被标记为“正确的”,其中|s|可以是真实值轮廓的面积。给定铰接形状和相机姿态估计,可以通过从参考帧到目标帧的重新投影对转移点进行转移。如果反投影的关键点位于重建的网格之外,则其与网格相交的最近相邻点可以被重新投影。可以在所有t(t-1)对帧上对精度求平均。
[0133]
可以用作用于比较目的的基线的替代动物重建方法的分类如下表1所示。(1)指基于模型的形状优化。(2)指基于模型的回归。(3)指类别特定的重建。(4)指无模板方法。s指单个视图。v指视频或多视图数据。i指图像。j2指2d关节。j3指3d关节。m指2d掩模。v3指3d网格。c指相机矩阵。o指光流。quad指四足动物。仅指列出的代表性类别。*指不可用的实施方式。smalst是为斑马训练的基于模型的回归器。它将图像作为输入,并为smal模型预测形状、姿态和纹理。umr是针对几个类别训练的类别特定的形状估计器,这几个类别包括鸟类、马和其他具有大量带注释图像的集合的类别。由于其他动物类别的模型不可用,因此报告了马模型的性能。a-csm从图像集合中学习类别特定的规范表面映射和铰接。在测试时,它将一幅图像作为输入,并预测装配模板网格的铰接参数。它提供了27个动物类别的3d模板和马的铰接模型,该模型在整个实验中使用。smalify是一种基于模型的优化方法,其将smal模型的五个类别(包括猫、狗、马、牛和河马)中的一个匹配到视频或单个图像。所有视频帧都被提供有真实值关键点和掩模注释。最后,包括基于检测的方法,oja,其训练沙漏网
络来检测动物关键点(由检测器指示),并用提出的最优分配算法对联合成本图进行后处理。
[0134][0135]
表1:非刚性形状重建的相关工作。
[0136]
在图5中示出了3d形状重建的示例定性结果。图5示出了使用参考图像802基于来自lasr以及竞争者的骆驼和人类数据的示例3d形状重建结果。在804处,参考一系列图像(例如,视频)的不同时间示出了来自lasr的形状重建结果。在806处,示出了在0
°
旋转和60
°
旋转处来自lasr的进一步形状重建结果。在808处,示出了在0
°
旋转和60
°
旋转处来自umr-马的进一步形状重建结果。在810处,示出了在0
°
旋转和60
°
旋转处来自a-csm(骆驼模板)的进一步形状重建结果。在812处,示出了在0
°
旋转和60
°
旋转处来自smalify马的进一步形状重建结果。在814处,示出了在0
°
旋转和60
°
旋转处来自lasr的进一步形状重建结果,具体示出了类人形。在816处,示出了在0
°
旋转和60
°
旋转处来自pifuhd的进一步形状重建结果。在818处,示出了在0
°
旋转和60
°
旋转处来自smplify-x的进一步形状重建结果。在820处,示出了在0
°
旋转和60
°
旋转处来自vibe的进一步形状重建结果。lasr可以在不使用形状模板或类别信息的情况下从对象的一个或多个图像(例如,单目视频)联合恢复相机、形状和铰接。通过依靠较少的先验知识,lasr可以应用于更广泛的非刚性形状,并且更好地拟合数据。来自lasr 806的结果恢复了从其他方法808、810和812的结果丢失的两个驼峰。此外,可以通过来自lasr 814和pifuhd 816的结果来重建舞者的布料丝带822,但是将smplify-x 818和
vibe 820混淆成舞者的右臂。
[0137]
在图6中示出3d形状重建的定性结果的另一个示例,其中我们在熊和狗数据902(例如,熊和狗视频)上与umr、a-csm和smalify进行比较。视频的第一帧的重建从两个视角示出。与同样不使用形状模板的umr相比,lasr重建了更细粒度的几何形状。与使用形状模板的a-csm和smalify相比,lasr恢复了实例特定的细节,诸如狗毛茸茸的尾巴和更自然的姿态。在0
°
旋转904和60
°
旋转914处示出了来自lasr的示例形状重建结果。在0
°
旋转906和60
°
旋转914处示出了来自umr马的示例形状重建结果。在0
°
旋转908和60
°
旋转916处示出了来自a-csm(狼模板)的示例形状重建结果。在0
°
旋转910和60
°
旋转918处示出了来自smalify狗的示例形状重建结果。
[0138]
关键点转移的定量结果如下面的表2所示。假定所有3d重建基线都是类别特定的,并且可能不会为一些类别(诸如骆驼)提供精确的模型,因此为每个动物视频选择了最佳模型或模板。与3d重建基线相比,lasr对于所有类别都更好,甚至在为其训练基线的类别上也是如此(例如,在跳马高上,lasr:49.3vs umr:32.4)。利用对象分割器pointrend替换真实值分割掩模,lasr的性能下降,但仍优于所有重建基线。与基于检测的方法相比,我们在跳马视频上的准确性更高,在其他视频上接近基线。与初始光流相比,lasr也显示出很大的改进(对于骆驼,为81.9%vs 47.9%)。(2)指基于模型的回归。(3)指类别特定的重建。(4)指自由形式的重建。指不重建3d形状的方法。*指未被指定用于这种类别的方法。如果重建3d形状,则最佳结果会以下划线和粗体显示。
[0139][0140]
表2:2d关键点转移准确度
[0141]
与初始光流相比,lasr示出很大的改进,特别是在如图7所示的长程帧之间。图7示出了样本骆驼视频的帧2和帧70之间的示例关键点转移。转移的关键点和目标注释之间的距离由圆的半径表示。正确的转移用实心圆1014标记,并且错误的转移用虚线1016标记。示出了lasr流覆盖在顶部1002上的参考图像。使用lasr 1004示出了具有帧2和帧70之间的关键点转移的示例图像。使用vcn流1006示出了具有帧2和帧70之间的关键点转移的示例图像。使用a-csm(骆驼模板)1008示出了具有帧2和帧70之间的关键点转移的示例图像。使用smalst-斑马1010示出了具有帧2和帧70之间的关键点转移的示例图像。使用umr-马1012示出了具有帧2和帧70之间的关键点转移的示例图像。
[0142]
铰接对象上的示例网格重建
[0143]
对于铰接对象上的一个示例网格重建,为了评估网格重建的准确度,使用了具有真实值网格和铰接的五个铰接对象的视频数据集,包括一个舞者视频、一个德国牧羊犬视频、一个马视频、一个鹰视频和一个石巨人视频。还包括刚性对象,keenan的点,以评估s0阶
段的对刚性对象重建和消融的性能。
[0144]
大多数先前的网格重建工作假设给定的相机参数。然而,在lasr可以建模的某些情况下,相机和几何形状两者都是未知的,这导致评估中的模糊性,包括尺度模糊性(对于所有单目重建存在)以及深度模糊性(对于如在umr、a-csm、vibe等中使用的弱透视相机存在)。为了分解出未知的相机矩阵,两个网格通过迭代最近点求解的3d相似性变换来对齐。然后,采用双向倒角距离作为评估度量。从预测的网格和真实值网格的表面均匀地随机采样10k个点,并计算对应点云中的每个点的最近邻之间的平均距离。
[0145]
除了用于动物重建的a-csm、smalify和umr之外,smplify-x、vibe和pifuhd还与用于人类重建的lasr进行比较。smplify-x是一种用于人体表情捕捉的基于模型的优化方法。使用了舞者序列的女性smpl模型,并且提供了从openpose估计的关键点输入。vibe[19]是用于人体姿态和形状推断的最先进的基于模型的视频回归器。pifuhd是为穿着衣服的人类设计的最先进的自由形式3d形状估计器。它以单个图像作为输入,并且预测隐式形状表示,其通过移动立方体(marching cube)算法被转换为网格。为了与关于狗和马的smalify进行比较,每帧手动注释18个关键点,并利用对应的形状模板进行初始化。
[0146]
在图5以及图8中示出了关于人类和动物的视觉比较。图8示出了在我们的合成狗和马序列上在不同时间戳处的形状和铰接重建结果。使用gt 1102示出了在t=0、t=5和t=10处狗的示例形状和铰接重建。使用lasr 1104示出了在t=0、t=5和t=10处狗的示例形状和铰接重建。使用a-csm(狼模板)1106示出了在t=0、t=5和t=10处狗的示例形状和铰接重建。使用smalify-狗1108示出了在t=0、t=5和t=10处狗的示例形状和铰接重建。使用gt 1110示出了马在t=0、t=5和t=10处的示例形状和铰接重建。使用lasr 1112示出了在t=0、t=5和t=10处马的示例形状和铰接重建。使用umr 1114示出了在t=0、t=5和t=10处马的示例形状和铰接重建。使用a-csm-马1116示出了在t=0、t=5和t=10处马的示例形状和铰接重建。使用smalify-马1118示出了在t=0、t=5和t=10时马的示例形状和铰接重建。该参考图在每个重建1122的左上角处示出。使用的模板网格在右下方1120中示出。与基于模板的方法(umr 1114)相比,lasr 1112成功地重建了马的四条腿。与基于模板的方法(a-csm 1106和smalify 1108)相比,lasr 1104成功地重建了实例特定的细节(狗的耳朵和尾巴),并恢复了更自然的铰接。
[0147]
定量结果如下表3所示。在狗的视频上,lasr比所有基线都好(0.28vs a-csm:0.38)。lasr可能更好,因为a-csm和umr不是专门针对狗训练的(尽管a-csm使用狼模板),并且smalify不能从有限的关键点和轮廓注释重建自然的3d形状。对于马的视频,lasr比使用马形状模板的a-csm稍好,并且优于其余基线。对于舞者序列,lasr不如基线方法准确(0.35vs vibe:0.22),这是预期的,因为所有基线要么使用良好设计的人类模型,要么已经利用3d人类网格数据训练过,而lasr无法访问3d人类数据。对于石巨人视频,lasr是唯一一种重建了有意义的形状的方法。虽然石巨人与人类的形状相似,但openpose不能正确地检测关节,从而导致smalify-x、vibe和pifuhd的失败。最佳结果以粗体显示。
“‑”
是指不适用于特定序列的方法。
[0148][0149]
表3:动画对象数据集上的根据倒角距离的网格重建误差。
[0150]
为了检查在任意真实世界对象上的性能,五个视频,包括舞蹈旋转、滑板车、肥皂盒、汽车转弯、野鸭飞行和猫视频。视频被分段。与无模板sfm-mvs流水线colmap的比较如图9所示。左侧1202示出了代表性输入帧。图9示出了使用滑板车视频的colmap的结果1204。图9示出了使用滑板车视频的lasr的结果1206。图9示出了使用肥皂盒视频的colmap的结果1208。图9示出了使用肥皂盒视频的lasr的结果1210。图9示出了使用汽车转弯视频的colmap的结果1212。图9示出了使用汽车转弯视频的lasr的结果1214。这些比较是在接近刚性的序列之间进行的。colmap仅重建了可见的刚性部分,而lasr重建了刚性对象和接近刚性的人两者。
[0151]
研究了不同设计选择对刚性牛和动画狗序列的影响。在t=15个帧中,使用环境光和围绕对象水平旋转的相机(对于牛是一整圈,并且对于狗是圈)渲染视频。除了彩色图像外,还渲染了作为监督的轮廓和光流。结果如图10所示。图10示出了在t=0和t=5处对于牛使用gt的作为监督的轮廓和光流的渲染1302。图10示出了在t=0和t=5处对于牛使用参考的作为监督的轮廓和光流的渲染1304。图10示出了在t=0和t=5处对于牛使用gt的作为监督的轮廓和光流的渲染1304。图10示出了具有作为监督信号的光流的在t=0和t=5处对于牛的无流的作为监督的轮廓和光流的渲染1306。图10示出了具有对称平面的规范化的在t=0和t=5处对于牛的无l_can的作为监督的轮廓和光流的渲染1308。图10示出了具有作为相机参数的隐式表示的卷积神经网络(cnn)的在t=0和t=5处对于牛的无cnn的作为监督的轮廓和光流的渲染1310。图10示出了在t=8并且α=0
°
和α=60
°
处对于狗使用gt的作为监督的轮廓和光流的渲染1312。图10示出了在t=8并且α=0
°
和α=60
°
处对于狗使用参考的作为监督的轮廓和光流的渲染1314。图10示出了具有线性混合蒙皮的在t=8并且α=0
°
和α=60
°
处对于狗的无lbs的作为监督的轮廓和光流的渲染1316。图10示出了具有从粗到细的重新网格化的在t=8并且α=0
°
和α=60
°
处对于狗的无c2f的作为监督的轮廓和光流的渲染1318。图10示出了具有参数化蒙皮模型的在t=8并且α=0
°
和α=60
°
处对于狗的无高斯混合模型(gmm)的作为监督的轮廓和光流的渲染1312。1302、1304、1306、1308和1310示出了对相机和刚性形状优化的消融研究。去除光流损失会在相机姿态估计中引入大的误差,并且因此不能恢复整体几何形状。去除规范化损失导致更差的相机姿态估计,并且因此对称形状约束没有被正确地强制实施。最后,如果不使用卷积网络而直接优化相机姿态,则它收敛得慢得多,并且在相同的迭代内不会产生理想的形状。1312、1314、1316、1318、1320示出了关于铰接形状优化的消融研究。具体地,示出了从两个视点在中间帧(t=8)处重建的铰接形状。在没有lbs模型的情况下,尽管从可见视图来看重建看起来似乎合理,但是由于冗余的变形参数和缺乏约束,重建不能恢复完整的几何形状。如果不进行从粗到细的重
新网格化,细粒度的细节将无法恢复。用nxb矩阵替换gmm蒙皮权重(9xb个参数)会导致重建时出现额外的肢体和尾巴。
[0152]
定量结果被报告在下表4中。在相机参数优化和刚性形状重建(s0)方面,
(1)
指作为监督信号的光流,
(2)
指对称平面的规范化,并且
(3)
指作为相机参数的隐式表示的cnn。对于铰接形状重建(s1-s3),
(1)
指线性混合蒙皮,
(2)
指从粗到细的重新网格化,并且
(3)
指参数化蒙皮模型。
[0153][0154]
表4:具有网格重建误差的消融研究。
[0155]
示例方法
[0156]
图11描绘了根据本公开的示例实施例执行的示例方法的流程图。尽管为了说明和讨论的目的,图11描绘了以特定顺序执行的步骤,但是本公开的方法不限于特别说明的顺序或布置。在不脱离本公开的范围的情况下,方法1400的各个步骤可以以各种方式被省略、重新排列、组合和/或调适。
[0157]
在1402处,计算系统可以获得描绘对象的输入图像和该对象的当前网格模型。输入图像可以是一个或多个图像。此外,输入图像可以是以视频形式附接在一起的多个图像。该视频可以是单目视频。输入图像中描绘的对象可以是感兴趣对象。此外,对象可以是任何感兴趣实体,诸如动物、人类或无生命的对象。
[0158]
在1404处,计算系统可以利用机器学习的相机模型处理输入图像,以获得输入图像的相机参数和对象变形数据。相机参数可以描述输入图像的相机姿态。对象变形数据描述了当前网格模型相对于图像中示出的对象的形状的一个或多个变形。可以进一步处理输入图像以获得静止形状、蒙皮权重和铰接。
[0159]
在1406处,计算系统至少部分基于相机参数来可微分地渲染对象的渲染图像。该计算系统还可以至少部分地基于对象变形数据来可微分地渲染对象的渲染图像。该计算系统还可以至少部分地基于当前网格模型来可微分地渲染对象的渲染图像。可微分地渲染对象的渲染图像可以包括在线性混合蒙皮下铰接静止形状。给定预测的铰接参数和蒙皮权重,计算系统可以在线性混合蒙皮下铰接静止形状。
[0160]
在1408处,计算系统可以评估损失函数,该损失函数将对象的输入图像的一个或多个特性与对象的渲染图像的一个或多个特性进行比较。可以与对象的输入图像的一个或多个特性相比较的对象的渲染图像的一个或多个特性可以包括像素、光流和分割。
[0161]
在1410,计算系统可以基于损失函数的梯度来修改机器学习的相机模型和当前网格模型中的一个或两者的一个或多个值。机器学习的相机模型和当前网格模型中的一个或两者的一个或多个值可以包括相机、形状或铰接参数。
[0162]
附加公开
[0163]
本文讨论的技术参考了服务器、数据库、软件应用和其他基于计算机的系统,以及所采取的动作和发送到这些系统和从这些系统发送的信息。基于计算机的系统的固有灵活性允许在组件之间和之中对任务和功能进行多种可能的配置、组合和划分。例如,本文讨论
的过程可以使用单个设备或组件或者组合工作的多个设备或组件来实现。数据库和应用可以在单个系统上实现,或者跨多个系统分布。分布式组件可以顺序地或并行地操作。
[0164]
虽然本主题已经关于其各种具体示例实施例进行了详细描述,但是每个示例都是以解释的方式提供的,而不是对本公开的限制。本领域的技术人员在获得了对前述内容的理解后,可以容易地对这样的实施例产生变更、变型和等效。因此,如对于本领域普通技术人员将是显而易见的,本公开不排除对本主题的这种修改、变型和/或添加。例如,作为一个实施例的一部分示出或描述的特征可以与另一个实施例一起使用,以产生又一个实施例。因此,本公开旨在涵盖这些变更、变型和等效。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1