学习装置、学习方法以及学习程序与流程
本发明涉及学习装置、学习方法以及学习程序。
背景技术:
1、随着iot时代的到来,多种设备在多种使用方式下与互联网连接。为了这些iot设备的安全对策,近来盛行研究面向iot设备的业务会话异常检测系统、侵入检测系统(ids)。
2、在这样的异常检测系统中,存在使用variational auto encoder(vae)等基于无教师学习的概率密度估计器的异常检测系统。使用概率密度估计器的异常检测系统根据实际的通信而生成被称为业务特征量的学习用的高维数据,使用该特征量学习正常的业务的特征,由此能够估计正常通信模式的发生概率。另外,在以后的说明中,有时将概率密度估计器简称为模型。
3、之后,异常检测系统使用已学习的模型来计算各通信的发生概率,将发生概率小的通信检测为异常。因此,根据使用概率密度估计器的异常检测系统,具有如下优点:即使不知道全部恶性状态也能够进行异常检测,并且还能够应对未知的网络攻击。另外,在异常检测系统中,有时在异常检测中使用异常得分,前述的发生概率越小则该异常得分越大。
4、在此,vae等概率密度估计器的学习大多在学习对象的正常数据间件数存在偏差的状况下无法顺利地进行。特别是,在业务会话数据中,经常发生件数存在偏差的状况。例如,由于经常使用http通信,因此数据在短时间内大量集中。另一方面,难以大量收集仅稀少地进行通信的ntp通信等的数据。若在这样的状况下进行基于vae等概率密度估计器的学习,则数据的件数少的ntp通信的学习不能顺利地进行,发生概率被估计得低,有时成为误检测的原因。
5、作为解决由于这样的数据件数的偏差而产生的问题的方法,已知有以2个阶段进行概率密度估计器的学习的方法(例如,参照专利文献1)。
6、现有技术文献
7、专利文献
8、专利文献1:日本特开2019-101982号公报
技术实现思路
1、发明所要解决的问题
2、然而,在现有技术中,存在处理时间有时会增大的问题。例如,在专利文献1所记载的方法中,概率密度估计器的学习以2个阶段进行,因此与1个阶段的情况相比,学习时间变长2倍左右。
3、用于解决问题的手段
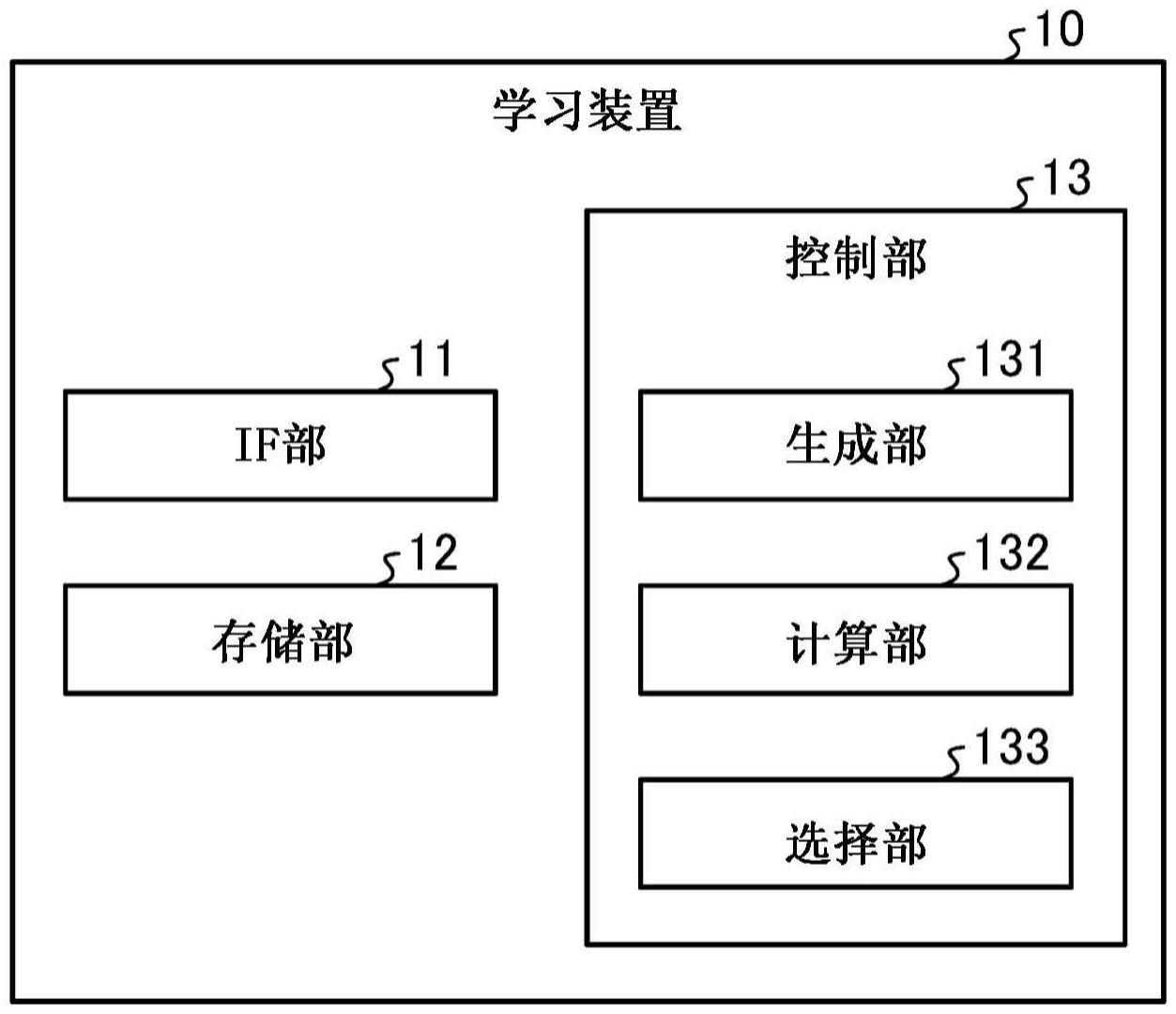
4、为了解决上述问题,实现目的,学习装置的特征在于,具有:生成部,其对学习用数据中的被选择为未学习数据的数据进行学习,生成计算异常得分的模型;以及选择部,其将所述学习用数据中的、利用由所述生成部生成的模型计算出的异常得分为阈值以上的数据的至少一部分选择为所述未学习数据。
5、发明效果
6、根据本发明,即使在正常数据间的件数存在偏差的情况下,也能够利用短时间高精度地进行学习。
技术特征:
1.一种学习装置,其特征在于,具有:
2.根据权利要求1所述的学习装置,其特征在于,每当通过所述选择部选择了数据作为所述未学习数据时,所述生成部就对该选择的数据进行学习,生成计算异常得分的模型,
3.根据权利要求1或2所述的学习装置,其特征在于,所述选择部选择所述学习用数据中的、利用由所述生成部生成的模型计算出的异常得分为基于在所述模型的生成时得到的各数据的损失值而计算出的阈值以上的数据的至少一部分作为所述未学习数据。
4.根据权利要求1至3中的任意一项所述的学习装置,其特征在于,所述选择部在所述学习用数据中的、利用由所述生成部生成的模型计算出的异常得分为阈值以上的数据的数量满足规定条件的情况下,选择该异常得分为阈值以上的数据的至少一部分作为所述未学习数据。
5.一种学习方法,该学习方法由学习装置执行,其特征在于,所述学习方法包括:
6.一种学习程序,用于使计算机作为权利要求1至4中的任意一项所述的学习装置发挥功能。
技术总结
生成部(131)对学习用数据中的被选择为未学习数据的数据进行学习,生成计算异常得分的模型。选择部(133)选择学习用数据中的、利用由生成部(131)生成的模型计算出的异常得分为阈值以上的数据的至少一部分作为未学习数据。
技术研发人员:山中友贵
受保护的技术使用者:日本电信电话株式会社
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!