一种面向咨询服务系统的用户画像构建方法
本发明涉及一种面向咨询服务系统的用户画像构建方法,属于大数据、数据挖掘、机器学习领域。
背景技术:
在大数据和社交媒体的背景下,咨询服务系统通过分析用户信息和行为中潜在的用户偏好,并将系统资源信息进行个性化推广。用户画像,即用户信息标签化,是基于一系列真实数据的目标用户模型。用户画像可以用“贴标签”的方式标注用户的社会属性、生活习惯和消费行为等。用户画像作为推荐系统的一个主要部分,通过挖掘用户个性特征、用户之间的个体差异、平台用户群体特征,广泛地被使用在电商商品推荐、广告商广告投放等商业领域。在用户画像勾勒的作用下,平台得以对用户进行个性化推荐,用户得到更好的体验,平台也可以吸引更多的流量。
面向咨询服务系统的用户画像,目标是收集服务领域的知识和技术并向不同的用户提供个性化的学习资源。由于不同学历、职位的人在学习能力和专业基础上有不同之处,在不同水平的用户进行咨询时就应该结合用户的真实需求进行资源的推送。而在智能推送学习资源过程中,针对人数众多繁杂的用户的画像分类是不可或缺的步骤。
现有技术构建用户画像时,往往通过调研问卷、电话访谈等手段获得用户的定性特征。例如,技术人员首先确定好待建立用户画像的目标人群以及列出能勾画目标人群用户画像的相关问题,如用户的年龄、性别、爱好等,然后通过问卷调查、走访交谈等方式收集记录目标人群对这些问题的回答。最终,在目标人群的答案的基础上,剔除无效冗余信息,提取高度精炼的特征,实现对用户的“标签化”,建立目标人群的用户画像。
在大数据时代,数据规模不断扩大,数据结构日益复杂。现有的技术方案中,存在以下几点问题:
(1)通过调研问卷、电话访谈等方式,耗费大量人力物力,成本高且效率低;
(2)受问卷问题与目标人群选择的影响,用户画像准确性不可知;
(3)缺乏用户画像评价分析与更新;
(4)提取高度精炼的特征不够完善,缺少行为信息,生成的用户画像质量低。
技术实现要素:
针对现有技术中存在的缺陷,本发明的目的在于提供一种面向咨询服务系统的用户画像构建方法,对用户画像在咨询服务方面的构建方法提出创新,根据采集到的咨询服务系统用户基本信息、行为信息等数据,将it技术与业务需求相结合,通过用户原始数据和用户目标属性的对应关系构建含多层标签的用户画像标签体系,用不同的方法对用户基本信息、行为信息等数据进行分析从而生成标签,然后勾勒出能够体现用户需求特征的完整的用户画像,并通过用户评价反馈数据,及时更新服务需求,最终将用户画像应用到个性化咨询服务系统中,提高用户的满意度。
所述方法具有下述优点:
(1)降低构建用户画像过程中的成本,提高生成效率;
(2)提高用户画像的准确性;
(3)保证用户画像的动态更新;
(4)将用户行为信息考虑在内,提高用户画像的质量。
为达到以上目的,本发明采取的技术方案是:
一种咨询服务系统用户画像的构建方法,包括以下步骤:
步骤s1、数据采集,得到用户的多维数据;数据采集包括静态数据采集和动态数据采集;
静态数据采集:对相关咨询服务系统数据库中的用户静态数据进行采集,静态数据包含用户的基本信息,用户的基本信息包括:用户id、用户工龄、用户学历、用户年龄、用户职位和用户专业;
动态数据采集:对相关咨询服务系统数据库中的用户动态数据进行采集,动态数据包含用户的行为信息,用户的行为信息包括:查询时间、查询专业、查询方向和评价反馈;
步骤s2、根据采集到的用户的多维数据,构建用户的两层标签体系;
步骤s3、根据用户的多维数据与标签体系中标签的对应关系,按照标签层级由下往上的方式对用户的一层标签、二层标签的每一个标签进行预测,构建咨询领域用户画像;
步骤s4、用户画像评价分析。
在上述方案的基础上,步骤s2的具体步骤为:
步骤s21、构建一层标签:使用多维数据中的用户职位、用户学历、用户工龄和用户专业,采用机器学习算法对用户属性中的用户专业基础进行预测,使用多维数据中的查询专业和查询方向,采用统计学对用户属性中的用户查询偏好进行预测,使用多维数据中的查询时间,采用统计学对用户属性中的用户查询时间特征进行预测,形成一层标签,一层标签包括:用户专业基础标签、用户查询偏好标签和用户查询时间特征标签;
步骤s22、构建二层标签:使用一级标签中的用户专业基础、用户查询时间特征,采用机器学习算法对用户知识需求中的用户知识难度需求进行预测,使用一级标签中的用户专业基础、用户查询偏好,采用机器学习算法对用户知识需求中的用户知识专业需求进行预测,使用一级标签中的用户专业基础、用户查询偏好、用户查询时间特征,采用机器学习算法对用户知识需求中的用户知识范围需求进行预测,形成二层标签,二层标签包括:用户知识难度需求标签、用户知识专业需求标签和用户知识范围需求标签。
在上述方案的基础上,步骤s3的具体步骤为:
步骤s31、用户专业基础标签计算步骤:
多维数据中的用户职位分为工人、技术员和工程师三个等级,用户学历分为初中及以下、高中、大专、本科、硕士及以上五个等级,用户工龄按照0-5、5-10、10-20、20-30分为1、2、3、4四个等级,用户专业按照咨询服务系统中所包含的专业进行分类,用户专业基础分为不同的专业基础,不同的专业基础由弱到强分别划分为1,2,3,4,5五个等级,首先对一部分用户手动标注用户专业基础,再将分类后的用户职位、用户学历、用户工龄和用户专业作为输入特征输入随机森林分类模型,预测用户专业基础;
步骤s32、用户查询偏好标签计算步骤:
统计用户近一个月的专业查询次数和专业方向查询次数,用于计算专业偏好系数与专业方向偏好系数,用户查询偏好标签包含专业偏好系数和专业方向偏好系数的统计型标签;
其中专业偏好系数的计算公式为:
其中p(i)表示专业i的偏好系数,c(i)表示专业i的查询次数,i=1,2,…,n,n表示所有专业个数;
专业方向偏好系数的计算公式为:
其中d(j)表示专业方向偏好系数,d(j)表示专业方向j的查询次数,j=1,2,…,m,m表示所有方向个数;
步骤s33、用户查询时间特征标签计算步骤:
对用户的查询时间进行统计分析,所述用户查询时间特征标签包含的特征有两次查询时间间隔的平均值与标准差、周末查询次数、工作日查询次数、工作日上班时间查询次数、工作日下班时间查询次数,用户查询时间特征间接反映用户的学习热情;
步骤s34、用户知识难度需求标签计算步骤:
将用户知识难度需求分为简单、一般、困难,分别标为类别1、2、3,首先对一部分用户按照权重规则手动标注用户知识难度需求类别,再将步骤s31得到的用户专业基础标签与步骤s33得到的用户查询时间特征标签作为输入特征输入随机森林分类模型,预测用户知识难度需求;
步骤s35、用户知识专业需求标签计算步骤:
首先将用户知识专业需求按照咨询专业进行分类,对用户查询偏好标签中的专业按照专业偏好系数由高到低进行排序,选择排名靠前的专业,并结合用户专业基础标签手动标注用户知识专业需求,再将步骤s31得到的用户专业基础标签与步骤s32得到的用户查询偏好标签作为输入特征输入随机森林分类模型,预测用户知识专业需求;
步骤s36、用户知识范围需求标签计算步骤:
将用户知识范围需求分为小、较小、中、较大、大,分别标为类别1、2、3、4、5,首先对一部分用户手动标注用户知识范围需求,再将步骤s31得到的用户专业基础标签、步骤s32得到的用户查询偏好标签与步骤s33得到用户查询时间特征标签作为输入特征输入随机森林分类模型,预测用户知识范围需求。
在上述方案的基础上,步骤s4的具体步骤为:
步骤s41、用户评价反馈信息采集:采集用户在咨询服务系统中对咨询结果的反馈信息,反馈信息包含难度反馈、专业匹配反馈和知识范围反馈;
步骤s42、用户画像更新:根据采集到的用户评价反馈信息对用户画像直接进行更新,具体更新规则:当难度反馈为困难时,降低用户知识难度需求等级,难度反馈为容易时,提高用户知识难度需求等级;当专业匹配反馈为偏离时,更改用户知识专业需求属性;当知识范围反馈为小时,增大用户知识范围需求等级,知识范围反馈为大时,降低用户知识范围需求等级;最终用户的反馈会不断趋向于合适,用户画像也会随之趋向于稳定。
本发明的有益效果:
本方法将实现咨询服务系统的用户画像构建,对用户画像在咨询服务方面的构建方法提出创新。
附图说明
本发明有如下附图:
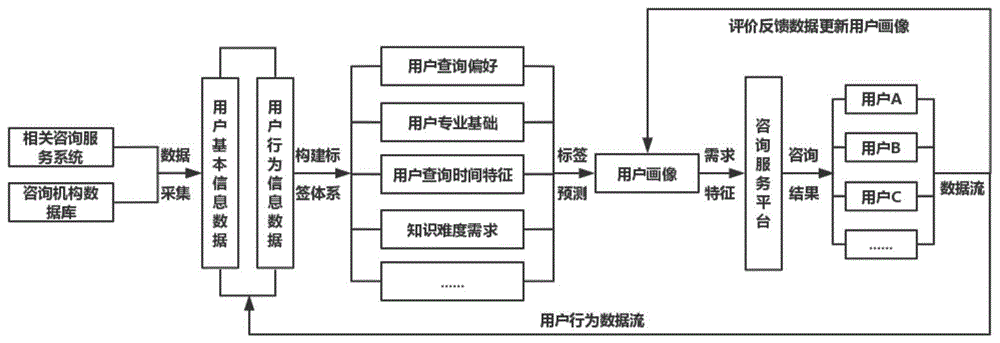
图1用户画像构建流程图。
图2用户画像标签体系示意图。
图3用户专业基础标签计算步骤示意图。
图4用户知识难度需求标签计算步骤示意图。
图5用户知识专业需求标签计算步骤示意图。
图6用户知识范围需求标签计算步骤示意图。
具体实施方式
以下结合附图1-6对本发明作进一步详细说明。
本方法从用户原始数据到最后生成用户画像,总共经历以下几个步骤(用户画像构建流程见图1,用户画像标签体系见图2):
(1)数据采集,得到用户的多维数据;数据采集包括静态数据采集和动态数据采集;
i.静态数据采集:对相关咨询服务系统数据库中的用户静态数据进行采集,静态数据包含用户的基本信息,用户的基本信息包括:用户id、用户工龄、用户学历、用户年龄、用户职位和用户专业;
ii.动态数据采集:对相关咨询服务系统数据库中的用户动态数据进行采集,动态数据包含用户的行为信息,用户的行为信息包括:查询时间、查询专业、查询方向和评价反馈;
(2)根据采集到的用户的多维数据,构建用户的两层标签体系
i.构建一层标签:使用多维数据中的用户职位、用户学历、用户工龄和用户专业,采用机器学习算法对用户属性中的用户专业基础进行预测,使用多维数据中的查询专业和查询方向,采用统计学对用户属性中的用户查询偏好进行预测,使用多维数据中的查询时间,采用统计学对用户属性中的用户查询时间特征进行预测,形成一层标签,一层标签包括:用户专业基础标签、用户查询偏好标签和用户查询时间特征标签;
ii.构建二层标签:使用一级标签中的用户专业基础、用户查询时间特征,采用机器学习算法对用户知识需求中的用户知识难度需求进行预测,使用一级标签中的用户专业基础、用户查询偏好,采用机器学习算法对用户知识需求中的用户知识专业需求进行预测,使用一级标签中的用户专业基础、用户查询偏好、用户查询时间特征,采用机器学习算法对用户知识需求中的用户知识范围需求进行预测,形成二层标签,二层标签包括:用户知识难度需求标签、用户知识专业需求标签和用户知识范围需求标签;
(3)根据用户的多维数据与标签体系中标签的对应关系,按照标签层级由下往上的方式对咨询用户的一层标签、二层标签的每一个标签进行预测,构建一个较为完善的咨询领域用户画像
i.用户专业基础标签计算步骤如图3所示:多维数据中的职位分为工人、技术员、工程师三个等级,用户学历分为初中及以下、高中、大专、本科、硕士及以上五个等级,工龄按照0-5、5-10、10-20、20-30分为1,2,3,4四个等级,用户专业按照咨询系统中所包含的专业进行分类。用户专业基础要分为不同的专业基础,而不同的专业基础由弱到强分别划分为1,2,3,4,5五个等级。首先对一部分用户手动标注用户专业基础,再将分类后的用户职位、用户学历、用户工龄和用户专业作为输入特征输入随机森林分类模型,预测用户专业基础;ii.用户查询偏好标签计算步骤:统计用户近一个月的专业查询次数和专业方向查询次数,用于计算专业偏好系数与专业方向偏好系数,用户查询偏好标签包含专业偏好系数和专业方向偏好系数的统计型标签。
其中专业偏好系数计算公式为:
其中p(i)表示专业i的偏好系数,c(i)表示专业i的查询次数,i=1,2,…,n,n表示所有专业个数。
方向偏好系数计算公式为:
其中d(j)表示专业方向偏好系数,d(j)表示专业方向j的查询次数,j=1,2,…,m,m表示所有方向个数;
iii.用户查询时间特征标签计算步骤:对用户的查询时间进行统计分析,该标签包含的特征有两次查询时间间隔的平均值与标准差、周末查询次数、工作日查询次数、工作日上班时间查询次数、工作日下班时间查询次数,用户查询时间特征可以间接反映用户的学习热情。
iv.用户知识难度需求标签计算步骤如图4所示:将用户知识难度需求分为简单,一般,困难,分别标为类别1,2,3。首先对一部分用户按照权重规则手动标注用户知识难度需求类别,再将分类后的用户专业基础标签与用户查询时间特征标签作为输入特征输入随机森林分类模型,预测用户知识难度需求。
v.用户知识专业需求标签计算步骤如图5所示:首先将用户知识专业需求按照咨询专业进行分类,对用户查询偏好标签中的专业按照专业偏好系数由高到低进行排序,选择排名靠前的专业,并结合用户专业基础标签手动标注用户知识专业需求,再将分类后的用户专业基础标签与用户查询偏好标签作为输入特征输入随机森林分类模型,预测用户知识专业需求。
vi.用户知识范围需求标签计算步骤如图6所示:将用户知识范围需求分为小,较小,中,较大,大,分别标为类别1,2,3,4,5。首先对一部分用户手动标注用户知识范围需求,接着将分类后的用户专业基础标签、用户查询偏好标签与用户查询时间特征标签作为输入特征输入随机森林分类模型,预测用户知识范围需求。
(4)用户画像评价分析
i.用户评价反馈信息采集:采集用户在咨询服务系统中对咨询结果的反馈信息,反馈信息包含难度反馈、专业匹配反馈和知识范围反馈;
ii.用户画像更新:根据采集到的用户评价反馈信息对用户画像直接进行更新,具体更新规则:当难度反馈为困难时,降低用户知识难度需求等级,难度反馈为容易时,提高用户知识难度需求等级;当专业匹配反馈为偏离时,更改用户知识专业需求属性;当知识范围反馈为小时,增大用户知识范围需求等级,知识范围反馈为大时,降低用户知识范围需求等级;最终用户的反馈会不断趋向于合适,而用户画像也会随之趋向于稳定。
本说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!