基于聚类的智能集成学习分类方法
1.本发明属于机器学习(machinelearning)与数据挖掘(data mining)技术领域,涉及一种用于解决二元分类(binaryclassification)及多类分类(multiclassclassification)问题的智能集成学习方法,具体为:针对机器学习领域中的分类问题(classificationproblem),提出了一种两阶段的集成学习方法,首先基于聚类算法(clustering algorithm)对数据集进行分割,从而形成一个个簇结构;之后,在聚类的基础上,针对每一个簇结构建立基分类器(base classifier);最后,提出一种动态赋权概率组合策略进行各个基分类器输出的集成,从而得到最终的预测结果。同时,这一方法还涉及到了多参数的组合优化 (combinatorial optimization)问题,针对模型中存在的多个敏感参数,提出了一种基于改进粒子群优化算法(improvedparticleswarmoptimizationalgorithm)的多参数优化策略。
背景技术:
2.作为一个新兴领域,机器学习受到了许多研究人员的关注。许多研究已经证明了机器学习方法在社会实践中的重要作用,比如在医疗健康领域、电子商务领域、应急管理领域以及金融市场领域等等。通常来说,机器学习主要可以划分为有监督学习(supervisedlearning)与无监督学习(unsupervisedlearning)这两大类。相比于无监督学习来说,更多的研究关注的是有监督学习,这也是和现实世界中分类问题的普遍存在是有关系的。从预测目标的角度来讲,有监督学习又可以划分为分类(classification)与回归 (regression)这两种。如果预测目标的取值是连续(continuous)的,那么这属于回归问题;如果预测目标的取值是离散(discrete)的,那么这就是分类问题。可以看出,分类问题本质上是回归问题的一种特例。分类问题是普遍存在于社会实践生活中的,比如在医疗健康领域,可以把人群划分为健康群体与患病群体,患病群体又可以具体分为患癌症群体与未患癌症群体。在解决分类问题时,早期的研究人员们大多使用基于专家系统(expertsystem)的方法。近年来,随着人工智能(artificialintelligence)技术的发展,研究人员们提出了多种机器学习算法来解决实际中的分类问题,比如决策树(decisiontree)、神经网络 (neuralnetwork)、支持向量机(supportvectormachine)及最近邻(k-nearest neighbors)等。
3.就无监督学习而言,被讨论和研究最多的就是聚类。在一些任务上,数据集中的样本并没有与之对应的标签,聚类的目的就是发现数据集中隐藏的簇结构,将数据集中的样本划分为若干子群落,从而为后续的进一步分析奠定基础。例如,在分析犯罪的相关记录时,qazi与wong(an interactive human centereddata science approach towards crime pattern analysis[j].information processingandmanagement, 2019)使用聚类算法将所有案例划分成了若干类别,通过对聚类结果进行分析,可以发现犯罪之间可能的关联,并识别潜在的犯罪模式。
[0004]
在过去的十几年间,学者们仅聚焦于有监督学习或者无监督学习,没有将二者进
行综合考虑。近些年,一些研究人员提出了半监督学习(semi-supervisedlearning)方法,目的是将无标签样本中的信息抽取出来从而用来提升有监督学习方法的性能(semi-supervised ensemble clustering based on selectedconstraint projection[j].ieee transactions on knowledgeand data engineering,2018)。除了半监督学习之外,还有另一种比较常见的监督学习与无监督学习组合方式,这一类研究首先将无标签数据聚类成一个个簇,并且将每个簇中的样本作为一个类别。之后,再使用监督学习模型对这些以簇为类别标签的样本进行学习(electricity clustering framework for automatic classification of customerloads[j].expert systems with applications,2017)。从这两类研究可以看出聚类方法在挖掘数据潜在模式方面具有不可比拟的优势。与这两类研究所不同的是,本发明聚焦于有标签样本的隐式簇结构发现,通过对数据集进行样本子空间的划分来确定基分类器的训练样本。
[0005]
另一方面,就有监督学习而言,在机器学习领域研究的早期,研究者们主要聚焦于决策树、支持向量机及神经网络这一类的单一方法,直到集成学习(ensemblelearning)方法的出现。相较于单一机器学习方法,集成学习具有更好的性能。集成学习涵盖了模型融合的策略与方法,现在主流的集成学习框架有两大类:bagging和boosting。集成学习的核心思想是综合多个模型的长处从而生成最终的预测结果。通过前述的相关内容可知,聚类可以将原始数据集划分为若干个样本子空间,从而可以在各样本子空间建立基分类器,这与集成学习方法的研究内容十分契合,因此可以在集成学习理论的基础上融入聚类算法进行分类模型的构建。
[0006]
在机器学习方法使用时,参数的选择往往会对模型的预测性能产生很大的影响(an improved supportvector machine-based diabetic readmission prediction[j].computer methods and programs inbiomedicine,2018)。目前,大部分研究采用的参数优化方法主要是网格搜索法、贝叶斯优化方法等,这些方法在面对单一参数优化问题时,还能够取得不错的效果。但是,在面对多参数的优化问题时,这些方法却难以起到效果。
[0007]
从以上分析可知,目前在机器学习领域中分类问题的研究上虽然取得了较丰富的成果,但对于聚类与分类的融合方法等问题上还有待进一步地进行系统和深入的研究。虽然目前已有半监督学习等融合聚类进行分类问题解决的相关研究,但是如何从集成学习的角度出发,利用聚类算法进行数据本身隐式结构的发现,并将其用于分类模型的构建仍是大多数研究人员们十分关注的研究问题。同时,如何处理模型中涉及的多参数组合优化问题也是亟需解决的另一个重要问题。
技术实现要素:
[0008]
本发明提供了一种可广泛用于二元分类及多类分类问题的分类方法,该方法融合了聚类算法、分类算法以及智能优化算法等多种算法,解决了已有研究中类重叠下的分类模型构建问题,集成学习中基分类器输出的组合问题,以及模型涉及多参数时如何寻优的问题,从而提高了分类问题的预测精度。
[0009]
本发明的技术方案:
[0010]
一种基于聚类的智能集成学习分类方法,步骤如下:
[0011]
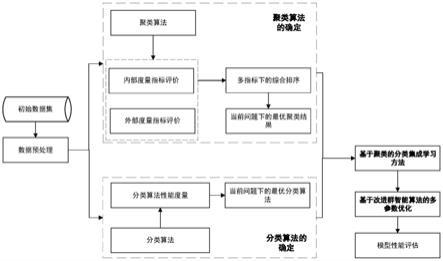
(一)最优聚类算法的确定
[0012]
首先,获取数据集d={(x1,y1),(x2,y2),
…
,(xi,yi)},其中i的取值范围为(1,2,
…
,n),n为样本数目的大小,xi为特征向量,yi为样本的类别标签;按照式(1.1)对数据进行预处理:
[0013][0014]
其中,xi′
(d)表示样本i的第d个特征处理后的取值,d的取值范围为(1,2,
…
,dim),xi(d)为样本i的第d个特征的原始取值,minixi(d)表示所有样本第d个特征取值中的最小值,max
i xi(d)表示所有样本第d个特征取值中的最大值;通过式(1.1)将所有样本每个特征的取值范围限制在[0,1]区间之内;
[0015]
之后,将预处理后的数据集输入至候选聚类算法中,通过运行聚类算法,将数据划分成一个个互不重叠的数据子集,即d=d1∪d2∪
…
∪dk,k表示预先设定的簇数目,即要聚成多少个数据子集;由此,得到当前候选聚类算法对于数据d的簇划分;在进行聚类算法性能评价时,使用的指标有外部度量指标和内部度量指标两大类,二者的区别在于外部度量指标需要使用样本的类别标签yi,内部度量不需要;在分类问题的背景下,将使用外部度量指标adjusted rand index(ari)、normalized mutual information(nmi)、 v-measure和fowlkes-mallows scores(fms)来综合评价候选聚类算法的性能;因为每一个指标都代表着对聚类算法不同方面性能的考量,将对所有候选聚类算法在此指标下的表现按照从优到劣进行排序,从而得到候选聚类算法在四个指标下的排序结果,之后按照式(1.2)计算综合排名情况:
[0016][0017]
计算出各个候选聚类算法的综合排名后,选择出适合当前问题的最优聚类算法;
[0018]
(二)最优分类算法的确定
[0019]
在进行最优分类算法的确定时,需要先按照式(1.1)将数据集d={(x1,y1),(x2,y2),
…
,(xi,yi)}进行数据的预处理,之后再按照8:2或9:1比例进行划分,其中包含样本多的部分为训练集d
train
,另一部分则为测试集d
test
;在进行样本的抽取时,是按照随机不放回采样的方法进行的;
[0020]
随后,将训练集数据输入进候选分类算法中进行分类模型的构建;在评估分类模型的性能时,将之前划分好的测试集作为输入,得到分类模型对每个测试集样本的预测结果;在分类算法的性能度量时,将采用受试者曲线下面积(areaunderroccurve,auc)这一指标进行性能度量;在确定最优分类算法时,需要将所有候选分类算法的auc取值进行排序,并选择auc取值最大的分类算法作为最优分类算法;
[0021]
(三)基于聚类的分类模型构建
[0022]
在确定最优聚类算法和最优分类算法后,在此基础上构建基于聚类的分类模型,具体过程为:
[0023]
首先,将获取到的数据集进行划分,得到训练集与测试集;之后,将训练集输入到最优聚类算法中进行数据子集的划分,依照既定的簇数目k,得到k个无交集的数据子集;针对每一个形成的数据子集,将其作为输入至最优分类算法中进行训练,从而获得对应的k个
训练好的分类模型,将其称之为基分类器;k个基分类器均是采用最优分类算法进行学习的,但由于输入数据的不同,从而使得这k个基分类器彼此间并不相同,这就提升了整个分类模型中基分类器的多样性,从而增加了整个分类模型的泛化能力 (generalization ability),泛化能力指的是对不同样本的预测都能保持一定的准确性,不会因为样本之间的差异导致预测准确性大幅度变化。同时,由于最优分类算法的产生是通过大量的实验对比确定的,这也就确保了整个分类模型的预测准确性。
[0024]
经过上述步骤,得到k个训练好的基分类器,在进行新样本的预测时,为了充分利用各个基分类器中所包含的信息,提出将待预测样本放入到k个基分类器中都进行预测,而每个基分类器都会给出对待预测样本的预测结果,因此获得k个预测结果然而,预测模型最后需要给出的是当前样本的一个预测结果,使用组合方法将k个预测结果进行集成,形成最终的预测结果;这一部分的过程如图2所示。
[0025]
(四)基于动态赋权概率组合策略的基分类器集成
[0026]
针对步骤(三)中所提出的基分类器输出组合问题,提出一种基于动态赋权概率组合策略的基分类器集成方法,该方法考虑到每个基分类器所具有的预测能力是不一致的,有的基分类器具有比其它基分类器更强的预测能力,因此应该占有更高的权重。同时,针对不同问题,基分类器的权重应该随着问题的变化而变化,因此应具有动态性。该方法的具体细节为:
[0027]
首先,我们得到了各个基分类器对待预测样本的预测结果需要的是一组权重 {w1,w2,
…
,wk},通过式(4.1)的计算来得到最终的预测结果。这里需要说明的是,基分类器的输出有两种形式,一种为硬输出,即输出的为具体类别标签;另一种为软输出,即输出的是属于各个类别的概率值。在计算时,软输出可以转换为硬输出,但是硬输出却不能转换为软输出,因为软输出包含有更多的预测信息。因此,本发明将使用软输出,即概率输出作为各个基分类器的输出形式。
[0028][0029]
其中,wb代表第b个基分类器的权重,
·
p
b,j
(x)代表第b个基分类器认为当前样本x属于类别j的概率,p
final,j
即为当前样本最终属于类别j的概率大小。并且各个基分类器的权重需要满足条件:且 0≤wb≤1,这是因为p
b,j
(x)的取值区间为[0,1]。如果要确保p
final,j
的取值区间在[0,1]之内,就需要满足权重wb的约束。
[0030]
(五)基于改进粒子群优化算法的多参数优化
[0031]
通过步骤(一)至(四),将整个分类模型构建完毕,但是需要注意到这一分类模型中涉及了许多要调整的参数,这些要调整的参数包括:聚类算法中的簇数目k、各个基分类器中所蕴含的超参数param
b,l
以及组合策略中各个基分类器的权重wb。这些参数的选择会对整个分类模型的性能产生非常重要的影响,因此需要通过一定的方式进行确定。传统的参数调整方法主要是人工调参法,网格搜索法以及贝叶斯优化方法,这些方法一方面无法处理多参数的优化问题,另一方面是耗时长、计算开销大。鉴于此,本发明提出了一种基于改进粒子群优化算法的多参数优化方法用来解决多参数组合优化问题。该方法的流程图如图3 所示。
[0032]
步骤1:需要对粒子群优化算法的参数进行初始化。具体参数包括有:种群规模n
p
、最大迭代次数t、均衡全局搜索与局部搜索的初始权重因子ω以及粒子的位置取值区间[l
min
,l
max
]和速度取值区间 [v
min
,v
max
],每个粒子代表着一种候选解。
[0033]
步骤2:初始化每个粒子的速度和位置。本发明中粒子的位置编码包含有三个重要的部分,即聚类算法中的簇数目k、各个基分类器中所包含的超参数param
b,l
以及组合策略中各个基分类器的权重wb。
[0034]
步骤3:计算每个粒子的适应度。将每个粒子生成的候选解输入到基于聚类的分类集成学习方法中,计算其十折交叉验证的auc平均值,将这一auc平均值作为适应度函数值返回。
[0035]
步骤4:寻找个体最优位置和全局最优位置。根据第t次迭代中每个粒子的位置及其适应度值fitm,确定个体极大值及群体极大值,并将其分别与个体历史最优位置和全局最优位置g
t
进行比较,从而可以确定新的个体最优位置和全局最优位置。
[0036]
步骤5:更新粒子的速度和位置。分别根据式(5.1)和式(5.2)更新粒子的速度和位置
[0037][0038][0039]
其中,m=1,2,
…
,n
p
,t=1,2,
…
,n
iter
,代表第m个粒子在第t次迭代中的速度,代表第m个粒子在第t次迭代中的位置,表示第t次迭代中第m个粒子的历史最优位置,g
t
则是在第t次迭代中所有粒子中的全局最优位置,n
p
是种群规模,ω代表均衡全局搜索与局部搜索的初始权重因子,c1和c2则为加速因子, rand()是区间[0,1]内的随机数。
[0040]
步骤6:随机初始化粒子的速度和位置。在粒子每次更新后以概率prob重新初始化其速度和位置
[0041]
步骤7:判断是否停止。设置达到最大迭代次数t作为算法的停止准则。若满足停止准则,则寻优过程终止,输出种群中具有全局最优解的候选解,从而就确定了参数的具体取值。否则,返回步骤3重复执行步骤3至步骤6。
[0042]
综上,本发明提出了一种“分而治之”的建模概念,并且为如何集成多种机器学习技术(如聚类算法、分类算法)与群智能优化算法进行建模提供了思路。在所提出的发明中,首先通过数值实验来确定当前任务下的最优聚类算法与最优分类算法,并建立基于聚类的分类模型。之后,提出了一种基于动态赋权概率组合策略用于集成基分类器的输出结果。最后,针对多参数的组合优化问题,提出了一种改进的粒子群优化算法进行问题的求解。
[0043]
本发明的有益效果:在传统的分类问题研究中,较少研究人员考虑到聚类算法与分类算法的结合问题。如果分类任务比较简单,传统模型可以较好地胜任。可是一旦数据分布较为复杂,出现了类重叠情况时,直接进行建模势必会影响分类模型的准确性。因此,采用本发明提出的聚类-分类集成建模方法,可以将数据空间进行有效地切分,从而提升模型整体的预测性能。同时,采取本发明提出的组合策略及参数优化方法能够进一步提升模型的预测性能。本发明的应用范围广泛,只要是涉及分类问题的领域,均可以采用本发明设计的方法进行预测模型的构建。
expectedsquaredistanceratio[j].informationsciences,2016)。因此,要求解的目标函数可表示为:
[0052][0053][0054]
其中,εi是松弛变量,c表示惩罚系数,ω是正则向量,b是超平面的偏差。当基分类器训练完成后,每个基分类器fj可以给出其预测结果因此可以得到相应的基分类器输出向量通过使用结合策略e可以将向量p转化为最终的预测结果
[0055]
在聚类与分类的组合过程中,除了聚类与分类的算法选择外,还有以下两点需要考虑:(i)聚类簇数目的选择。为了解决这一问题,聚类簇数目将作为一个重要的参数嵌入群智能算法的个体编码中;(ii)组合策略的选择。本发明针对这一问题提出了一种动态赋权概率组合策略。各个基分类器的权重由群智能算法优化确定。表1阐述了ciel方法的计算流程。
[0056]
表1ciel方法的计算步骤
[0057][0058]
(二)基于动态赋权概率组合策略的基分类器集成
[0059]
在集成学习方法中,组合策略的选择是非常重要的一个部分。在处理分类问题时,分类器的输出形式有两种:一类是标签型,一类是概率型。以二元分类为例,假定分类器f对样本x的预测结果为如果为标签型输出,则其值为0或者1,如果是概率型输出,则其值处于[0,1]区间内。此外,概率型输出是可以转化为标签型输出的。例如,研究人员们常将0.5作为阈值,当大于0.5时,的值将被转换为1,否则,转换为0。因此,概率型输出也被称为软输出,而标签型输出则被称为硬输出。对比硬输出,软输出更有利于构建一个性能良好的分类系统,这是由于软输出还隐含着对当前预测结果的信度,预测结果越接近0或者1,表明预测结果越可信。因此,本发明使用软输出作为各个基分类器的输出类型。
[0060]
当使用概率作为预测输出类型时,在集成学习中常用的四种组合策略为:平均法、最大法、最小法及赋权法。假定各基分类器输出的结果为p
b,j
∈[0,1],b=1,
…
,b;j=1,
…
,
c,其中b为基分类器的数目,c为数据集中的类别数,p
b,j
即为基分类器b预测样本属于类别j的概率。因此,通过各个组合策略生成的最终预测结果可以定义为:
[0061]
·
平均法:将所有基分类器的输出概率值加和平均作为最终的概率输出,计算公式为:
[0062][0063]
·
最大法:将所有基分类器的输出概率值进行比较,并选择最大的输出概率值作为最终的输出概率,计算公式为:
[0064][0065]
·
最小法:将所有基分类器的输出概率值进行比较,并选择最小的输出概率值作为最终的输出概率,计算公式为:
[0066][0067]
·
赋权法:赋权法是在平均法的基础上发展而来的。许多著名的集成学习算法,如gbdt和xgboost 等都采用赋权法来组合各个基分类器的输出,其计算方式如下:
[0068][0069]
其中,且0≤wb≤1,这是因为p
b,j
(x)的取值区间为[0,1]。如果要确保p
final,j
的取值区间在[0,1]之内,就需要满足权重wb的约束。
[0070]
当选用赋权概率组合策略时,需要对基分类器的权重进行确定。传统的基分类器权重确定方式有两种,一种是手动调整权重值,然后观察预测准确率的变化来确定最优的权重值;另一种是通过基于先验知识或者基分类器的表现等机制来确定权重值。事实上,权重的确定方式可以转化为组合优化问题进行求解。因此,本发明提出了一种基于群智能算法的动态赋权概率组合策略。各个基分类器的权重将被嵌入到群智能算法的个体编码中。
[0071]
(三)基于改进群智能算法的多参数优化
[0072]
为了解决ciel方法中的参数优化问题,本发明提出使用群智能算法作为求解算法。在众多的群智能算法中,粒子群算法(particleswarmoptimization,pso)因为具有很高的搜索效率受到了许多研究人员的关注。与进化算法相似,pso算法也随机产生初始种群。然而,pso算法仿真的是社会行为而非自然选择和进化机制。在pso算法中,每个粒子的位置代表着一个候选解,每个粒子的表现由适应度函数决定。在算法的迭代过程中,粒子将根据自身与其它粒子的位置来更新自身的速度及位置,从而逐步靠近最优位置。在每次迭代中,第m个粒子将依据下式进行粒子速度和位置的更新:
[0073][0074][0075]
其中,m=1,2,
…
,n
p
,t=1,2,
…
,n
iter
,代表第m个粒子在第t次迭代中的速度,代表第m个粒子在第t次迭代中的位置,表示第t次迭代中第m个粒子的历史最优位置,g
t
则是在第t次迭代中所有粒子中的全局最优位置,n
p
是种群数目,ω代表均衡全局搜索与
局部搜索的初始权重因子,c1和c2则为加速因子, rand()是区间[0,1]内的随机数。为了解决pso算法在寻优过程中,粒子容易陷入到局部最优解的问题,本发明引入了变异策略,即以一定概率随机初始化粒子的位置。综上,本发明提出了一种改进的粒子群算法来解决参数优化的问题。
[0076]
在使用改进的pso算法优化ciel参数的过程中,首先需要解决的是粒子编码的设计问题。本发明中的粒子编码如图3所示,整个粒子编码包含三个部分:聚类簇的数目k,基分类器的关键参数组合 param
k,l
(k=1,
…
,k;l=1,
…
,l),其中l代表基分类器参数的个数,及在组合策略中各个基分类器的权重 weightk。这三部分分别对应了ciel方法中重要的三个部分。
[0077]
图3为优化过程的流程图,重要的部分进行了加粗标记。整个优化过程可以分为五个步骤:第一步是处理数据中的缺失值和数据的归一化;第二步是对pso算法的参数ω、c1和c2进行初始化,并随机生成初始种群;第三步则是将待优化参数k、param
k,l
和weightk传递进入ciel模型,从而计算出对应的适应度函数值;第四步则是更新粒子的位置和速度;第五步将使用随机初始化策略来提升pso算法的全局搜索能力。整个优化过程将会迭代执行直到达到最大迭代次数。
[0078]
(四)模型的性能评价
[0079]
(1)所用数据集
[0080]
为了检验本发明的有效性,共收集了12个二元分类数据集及12个多类分类数据集。24个数据集的描述如表2所示。
[0081]
表2数据集的描述
[0082][0083]
[0084]
(2)在二元分类问题上的性能
[0085]
为了检验本发明所提出方法的有用性,我们对比了相关文献中的实验结果,结果如表3所示。通过对比可以发现,本发明提出的ciel方法在多个二元分类数据集都取得了优于其它方法的表现,这证明ciel 方法能够有效地解决二元分类问题。
[0086]
表3 ciel方法与其它方法在二元分类问题上的性能对比
[0087][0088][0089]
(3)在多类分类问题上的性能
[0090]
为了更好地展示本发明在分类问题上广泛的适应性,除了在二元分类数据集上进行了验证之外,我们将ciel方法与其它方法在多类分类问题上的性能进行了对比,结果如表4所示。从表4给出的结果来看,本发明提出的ciel方法要优于其它文献中所提出的方法。
[0091]
表4 ciel方法与其它方法在多类分类问题上的性能对比
[0092][0093]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1