一种恶劣气候环境下的海洋搜救方法
1.本发明涉及一种恶劣气候环境下的海洋搜救方法,主要用于恶劣气候下海洋环境的人员搜救,属于海上救援领域。
背景技术:
2.随着科学技术的发展、各国经济的增强,我国海洋经济规划的提出和军事海域活动范围的扩大,海洋捕捞、海洋运输、军事巡视等海上海空活动增多,这些活动中难免会出现各种各样的事故,对于事故人员、船只的搜救和定位等应急处理,需要在最短的时间内得到有效救援或控制,在极端的气候环境下救援难度十分巨大,由于无人机/无人船拍摄的图像往往过于模糊,因而还亟需一种有效的图像重构技术,能够用极少量的图片重构照片,从而精确找到待救人员。
技术实现要素:
3.本发明要解决的技术问题是:在恶劣的海洋气候环境下海洋搜救较为困难的问题。
4.为了解决上述问题,本发明的技术方案是提供了一种恶劣气候环境下的海洋搜救方法,其特征在于,包括如下步骤:
5.步骤1、获取海洋图片;
6.步骤2、通过压缩感知技术对图片进行采样后传输;
7.步骤3、将步骤2中的图像通过改进的esrgan神经网络生成技术重构图片,获取图片原有的信息,包括:
8.步骤3.1、初始化深度卷积生成网络,网络权重随机初始化,
9.步骤3.2、确定损失函数,针对损失函数添加正则项来保持图像的光滑性质,并给定迭代次数;
10.在训练过程中使用基于deep image prior的预训练系统缩小所需训练的图片数量;
11.步骤4、使用yolov4目标检测算法对重构的图像进行筛选,从而选定待救人员的精确位置,自动识别落水人员。
12.优选地,所述改进的esrgan神经网络的损失函数为l(w)=argmin(||wx+b
‑
y||2)+λr(w),式中w表示权重,b表示偏置,通过训练模型产生,y表示真实图像,r(w)表示正则化参数,λ表示正则化参数的权重。
13.优选地,所述学习正则化参数r(w)=(w
‑
μ)
t
σ
‑1(w
‑
μ),式中w为权重集,
14.优选地,设改进的esrgan神经网络输入的固定的随机编码向量为z,生成的仿造的图像为f(z),所述基于deep image prior的预训练系统预训练包括:
15.初始化z,用均匀噪声或任何其他随机图像填充z;
16.使用基于梯度的方法求解和优化函数θ是随机初始化的权重,即损失函数的权重w;
17.找到最佳θ,通过将输入的固定的随机编码向量z向前传递到具有参数θ的网络来获得最佳图像。
18.优选地,所述改进的esrgan神经网络为在传统的esrgan神经网络的基础上增加密集连接残差块,密集连接残差块的输出y=x0+[x1,x2,...,x
n
],式中x0表示密集连接残差块的输入,[x1,x2,...,x
n
]表示每一个卷积层输出特征图的串联,n指的是在一个密集连接残差块中卷积层的数目。
[0019]
优选地,对所述密集连接残差块随机丢弃一部分连接形成稀疏连接残差块减少训练时间。
[0020]
优选地,所述步骤1中通过海上无人机或无人船拍摄获取海洋图片。
[0021]
与现有技术相比,本发明的有益效果是:
[0022]
本发明通过无人机/无人船获取海上模糊图像,通过对少数图像采用deep image prior(dip)技术进行预处理,再通过基于改进的esrgan神经网络对图像进行重构,去除受恶劣环境产生的模糊、重影,实现图像的去模糊化,最后通过yolov4目标检测算法识别落水人员。本发明通过图像重构技术重构图像,并利用目标检测技术精确定位待救人员的位置区域,提高救援的效率,具有良好的实用性,能够对恶劣气候下的海洋环境进行图像重构,能最大程度定位落水人员的位置区域,方便后期快速救援。
附图说明
[0023]
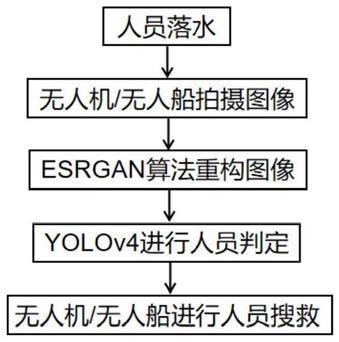
图1为本发明一种恶劣气候环境下的海洋搜救方法总体流程图;
[0024]
图2为基于改进的esrgan神经网络的总体结构图;
[0025]
图3为稀疏连接残差块的结构图;
具体实施方式
[0026]
为使本发明更明显易懂,兹以优选实施例,并配合附图作详细说明如下。
[0027]
如图1所示,本发明一种恶劣气候环境下的海洋搜救方法包括基于改进的esrgan(增强型超分辨率生成对抗网络)神经网络的图像生成技术、基于deep image prior(dip)的预训练系统和基于yolov4目标检测算法。其中基于改进的esrgan神经网络的图像生成技术用于将拍摄的模糊图像转换为清晰图像,在模型训练的过程中使用基于deep image prior(dip)的预训练系统可以大大缩小所需训练的图片数量,期间使用正则化参数来处理过拟合问题,最后可以通过yolov4算法来精确识别落水人员,从而进行搜救。
[0028]
首先通过海上无人机/无人船拍摄海洋图片,通过压缩感知技术对图片进行采样后传输,减少了图片传输的内存大小,其次后台得到的模糊图片通过改进的esrgan神经网络的图像生成技术重构图片,获取图片原有的信息。其中包含了基于deep image prior(dip)的预训练系统,从而避免了大量图片数据集的获取,deep image prior(dip)技术通过捕获由gan神经网络的结构而产生的图像信息,仅需少量图像即可完成网络的预训练。最终可以通过yolov4目标检测算法对重构的图像进行筛选,从而选定待救人员的精确位置。
[0029]
如图2所示,通过改进的esrgan神经网络的图像生成技术重构图片包括以下步骤:首先初始化深度卷积生成(解码)网络f,网络权重随机初始化。此网络主要是通过输入为固定的随机编码向量z,生成出一个仿造的图像f(z)。
[0030]
其次是选择合适的损失函数。例如对于降噪问题可关注整体的均方差(mse),对于填充问题就应该只关心不需要填充的位置的mse。由于在图像复原过程中,图像上的一点点噪声可能就会对复原的结果产生非常大的影响,因为很多复原算法都会放大噪声。这时候可以针对损失函数添加正则项r(w)来保持图像的光滑性质。理论上,如网络f足够大,训练时间足够久,可实现输出与原图x非常接近的图像,甚至一致(若不添加正则项)。但是这样会对原图的噪声部分进行学习,所以最后需要给定迭代次数使其在训练到一半的时候退出来防止噪声学习。
[0031]
神经网络的损失函数,假设神经元的输入图像为x,经过线性变换:f(x)=wx+b,其中f(x)为输出的图像,需要找到合适的权重w和偏置b使得输出尽可能拟合真实图像y。权重w和偏置b通过学习得到,w初始化为n*n的单位矩阵,b初始化为n*1的0向量,n取决于图片的尺寸。
[0032]
此外,可以设置一个函数定量地衡量任意一个w的好坏,将w作为输入,得分作为输出,得到损失函数l(w)=l(f(x,w),y),损失函数的值最小生成的图片才能逼近真实的图片,但是这样得出的结果往往会学习到当前图片过多的细节,使得模型只对当前图像的重构有效,对于其他图像往往效果就很差,需要引入正则化参数来鼓励模型以某种方式选择更简单的w。于是最终的损失函数为l(w)=argmin(l(f(x,w),y))+λr(w),r(w)即为正则化参数,而λ为权重。正则化参数可以有效避免图像重构过程中产生的过拟合问题,使网络框架能够适应大部分其他图像。
[0033]
本实施例中,esrgan神经网络的损失函数为
[0034]
l(w)=argmin(||wx+b
‑
y||2)+λr(w),
[0035]
式中w表示权重,b表示偏置,通过训练模型产生,y表示真实图像,r(w)表示正则化参数,λ表示正则化参数的权重。学习正则化可以表示为r(w)=(w
‑
μ)
t
σ
‑1(w
‑
μ),式中w为权重集,使用(μ,σ)来惩罚l2范数而不规范图层输出本身,实现了对模型空间的限制,从而在一定程度上避免了过拟合。限制解空间范围,缩小解空间,来控制模型复杂度,降低结构化风险。
[0036]
改进的esrgan神经网络在传统的esrgan神经网络的基础之上加入了密集残差模块,相比之前更有利于捕捉图片的细节。密集连接残差块(densely connected residual block,drblock)的输出计算如下:y=x0+[x1,x2,...,x
n
],式中x0表示drblock的输入,[x1,x2,...,x
n
]表示每一个3
×
3卷积层输出特征图的串联,n指的是在一个drblock中3
×
3卷积层的数目。
[0037]
如图3所示,本发明对密集连接残差块随机丢弃一部分连接形成了稀疏连接残差块,从而减少了训练时间。
[0038]
deep image prior包括三个步骤:首先初始化z,用均匀噪声或任何其他随机图像填充z。其次使用基于梯度的方法求解和优化函数,即
[0039]
[0040]
θ是随机初始化的权重。最后,找到最佳θ时,可以通过将固定输入z向前传递到具有参数θ的网络来获得最佳图像。θ是随机初始化的权重,即损失函数的权重w。
[0041]
yolov4作为当前最强的实时对象检测模型之一,使用了多种数据增强技术的组合,对于单一图片,除了经典的几何畸变与光照畸变外,还创新地使用了图像遮挡(random erase,cutout,hide and seek,grid mask,mixup)技术,对于多图组合,混合使用了cutmix与mosaic技术。除此之外,还使用了self
‑
adversarial training(sat)来进行数据增强。backbone上使用了cspdarknet,从输入图像中提取丰富的信息特征,解决了其他大型卷积神经网络框架backbone中网络优化的梯度信息重复问题,将梯度的变化从头到尾地集成到特征图中,因此减少了模型的参数量和flops数值,既保证了推理速度和准确率,又减小了模型尺寸。本方法使用yolov4算法对重构的图片进行自动识别,减轻人力监管的疲劳。
[0042]
yolov4相比其他目标检测算法包括更大的网络输入分辨率用于检测小目标、更深的网络层能够覆盖更大面积的感受野、更多的参数可以更好的检测同一图像内不同size的目标,同时还包含一种新的数据增强算法——mosaic法,允许检测上下文之外的目标,增强模型的鲁棒性,通过这种方法,可以丰富图像的上下文信息。由于本方法主要应用于海上救援领域,并且海上人员在图像中的占比可能很小,所以可以通过目标检测算法来进行检测,将一些完全没有人员迹象的图像过滤掉,筛选出可能是人员落水的图片,然后进行搜救。考虑到人眼观察的话对于这些细小的特征可能会出现视觉疲劳和误判,所以本方法加上这一目标检测算法尤为重要。该算法的最终目的是能够根据图片的画面细节,比如救生衣的颜色、形状、落水人员肢体形状等细微特征特征来判定是否为落水人员,使得搜救人员可以有针对性的实施救援,避免错误的搜救方向导致错失最佳救援时机。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1