一种基于网状结构与长距离相关性的真实图像去噪方法
1.本发明涉及计算机视觉中的图像去噪领域,特别涉及真实噪声拟合与深度学习网络结构的网状结构与长距离相关性。
背景技术:
2.图像去噪问题是计算机视觉中非常经典的低级视觉处理问题,图像常常会因为我们手机传感器和设备读出电路的原因而产生噪点,破坏原图的清晰度,图像去噪的目的就是将噪声从噪声图像去除来恢复出干净图像。
3.几十年来,传统去噪方法不断深入研究,许多方法,例如全变分(total variation),双边滤波(bilateral filtering),稀疏表示(sparse representaion)或者非局部相似性(nonlocal self
‑
similarity)等等都被提出。其中bm3d和wnnm是比较优秀的算法,bm3d利用通过相似块匹配分组,协同滤波和聚合的思想进行去噪,wnnm是利用加权核范数最小化进行恢复图像。
4.而随着深度学习的发展,尤其是卷积神经网络(convolutional neural networks,cnn)大规模应用于图像处理领域,在图像去噪领域也出现了大量深度学习算法。在2017年,张等人提出的dncnn网络,利用多个卷积层堆叠并利用残差学习的思想,取得了非常不错的效果,在多个测试集psnr高于传统算法。之后越来越多的网络结构的提出,例如u
‑
net,resnet,densenet等,引入图像去噪网络结构设计之中,使得深度学习图像去噪算法的性能不断提升。
5.然而很多深度学习图像去噪算法在进行噪声仿真时仅仅利用高斯白噪声(add white gaussian noise,awgn)来进行成对数据集训练,学习干净图像与噪声图像的映射关系,而高斯白噪声显然与真实成像设备产生的噪声有区别。所以如果仅仅将在高斯白噪声训练的深度学习模型应用到真实图像去噪中效果并不理想。鉴于现在深度学习在图像去噪领域大多还是采用监督学习方法,需要制作成对的真实噪声图像与干净图像,出现了很多制作真实图像去噪的数据集提供训练,例如dnd数据集,sidd数据集等。
6.目前来看深度学习进行图像去噪的上限高于传统方法,但是还要继续提高深度学习网络的性能;另外一点制作的真实数据集相对麻烦导致成对图像较少,这使得需要大量数据来进行驱动学习的深度学习方法有了一定的限制。这两个方面都需要进一步解决。
技术实现要素:
7.为解决现有技术中存在的上述缺陷,本发明的目的在于提供一种基于网状结构与长距离相关性的真实图像去噪方法,该方法网络结构上相比其他算法进一步提升,并且利用到长距离图像像素相关性,使得深度学习网络的真实图像去噪能力进一步提升;另外利用额外的图像生成网络和真实噪声拟合制作更多的真实图像成对数据集,辅助训练。
8.本发明是通过下述技术方案来实现的。
9.一种基于网状结构与长距离相关性的真实图像去噪方法,包括以下步骤:
10.1)利用图像生成网络和真实噪声拟合制作额外的真实噪声数据集:
11.使用异方差高斯噪声来拟合真实噪声中的光子到达统计的噪声和读出电路不精确的噪声;
12.利用图像生成网络将srgb图像转为rawrgb图像,将拟合的真实噪声添加,之后再将图像从rawrgb转为srgb图像,从而制作出额外的真实噪声数据集;
13.2)构建基于网状结构和长距离相关性的真实去噪网络模型;
14.3)联合步骤1)制作的真实噪声数据集与步骤2)的真实去噪网络模型进行训练;
15.4)将智能手机图像去噪数据集的测试集中待去噪图像,输入至训练好的真实图像去噪网络中,得到去噪后的图像。
16.进一步,步骤1)中,制作额外的真实噪声数据集包括:
17.1a)选取智能手机图像去噪数据集,从相机数据中的元数据中提取拍摄图像的两个噪声分量,即光子到达统计的噪声和读出电路不精确的噪声;
18.1b)将两种噪声近似为一个异方差高斯函数,得到均值为μ,方差为σ2的异方差高斯噪声分布;
19.1c)利用图像生成网络的模拟逆isp网络将srgb图像转换为rawrgb图像,利用模拟isp网络将rawrgb图像转换为srgb图像,生成模拟真实噪声的图片;
20.1d)选择flickr2k干净图片并进行裁剪后,输入模拟逆isp网络,得到rawrgb干净图像;将rawrgb干净图像通过模拟isp网络,获得生成的srgb干净图像;再将rawrgb干净图像与异方差高斯函数相加,所获得的rawrgb含噪图像通过模拟isp网络,获得srgb真实噪声图像,即为成对数据集
21.进一步,步骤2)中,构建基于网状结构和长距离相关性的真实去噪网络模型,主要包含长距离相关网状u型组lrnu模块;包括:
22.2a)构建长距离相关网状u型组,包含三层上下采样的u型网络为主体进行多尺度学习;
23.2b)lrnu中的网状结构在保留长距离连接add的基础上,增加了3个3
×
3卷积,从l1,l2,l3三个尺度层进行上采样,使用3
×
3卷积特征融合,在解码端使用1
×
1卷积进行多特征通道归整;
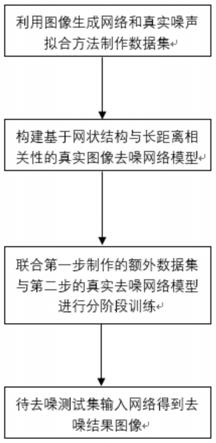
24.2c)lrnu中在l4尺度上结合了两个长距离相关模块lrm,设网络中的特征图大小为h
×
w
×
c,首先将特征图每个通道的特征改变(reshape)为hw
×
c二维,然后将原来每个通道对应像素位置所构成的行看作为一条原特征向量,记为x
i
,通过卷积学习三个转移矩阵w
q
,w
k
,w
v
,并与x
i
相乘得到q
i
,k
i
和v
i
三个特征向量,然后进行相关度计算得到r
i
特征向量;利用多头机制,得到多个r
i
之后,再次通过1
×
1的卷积恢复c个通道数量,最后通过一个残差连接,保证信息流通;
25.2d)整体网络使用两个lrnu模块,并且将两个lrnu的输出通道进行concat,然后加入通道注意力和空间注意力两个模块加权学习图像重点位置,1
×
1卷积恢复通道数,最外层进行残差学习策略。
26.进一步,步骤2a)中,下采样方式使用的为固定3
×
3卷积,卷积核为哈尔小波正变换四个卷积分量值(ll,lh,hl,hh);上采样方式为固定3
×
3反卷积,卷积和为哈尔小波逆变换的四个分量值。
27.进一步,步骤2b)中,l3上采样特征通道c与l2层通道c融合通道2c,然后使用3
×
3卷积特征融合;l2层上采样特征通道c与l1层通道c使用3
×
3卷积特征融合,然后再与上一步l3与l2融合的特征通道c再进行一次使用3
×
3卷积特征融合。
28.进一步,步骤3)联合步骤1)制作的数据集与步骤2)的真实去噪网络模型进行训练,包括:
29.3a)以步骤1)中制作的成对数据集作为预训练,然后采用sidd图像作为微调训练,随机裁剪图像形成一个batch送入去噪网络;
30.3b)在训练步骤2)模型的时候,使用adam优化器,预训练采用的损失函数loss_pre,微调训练采用损失函数loss_finetune,进行分段训练。
31.本发明由于采取以上技术方案,其具有以下有益效果:
32.1.本发明首先根据sidd图像真实噪声中的shot noise和read noise进行噪声拟合,将二者拟合为一个近似符合sidd图像真实噪声分布的异方差高斯分布,然后通过利用图像生成网络制造成对的真实噪声数据集,弥补了现有真实噪声图像数据集量较少的缺点,通过补充数据集在预训练阶段可以更好的收敛并学习基本特征。
33.2.本发明中的真实去噪网络利用网状结构更好的利用了多尺度信息,将底层信息及时传递到上层,避免了长距离连接造成的信息损失。利用长距离相关模块,弥补了卷积核的局部感受野的问题,能够更好地利用长距离像素之间的关系,增强去噪能力。
34.3.预训练阶段使用大量增广数据集,并且以loss_pre损失函数快速进行收敛,微调阶段使用sidd原数据集并以loss_finetune损失函数提高真实去噪结果。两步分段使用不同训练集和不同损失函数进行学习。
附图说明
35.此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,并不构成对本发明的不当限定,在附图中:
36.图1是本方法的整体实施总流程图;
37.图2是图片生成网络处理流程图;
38.图3是针对sidd真实噪声数据集所拟合的shot noise和read noise关系图;
39.图4是基于网状结构与长距离相关性的真实图像去噪网络模型;
40.图5是长距离相关网状u型组(lrnu)示意图;
41.图6是长距离模块(lrm)处理流程图;
42.图7(a)、图7(b)是本算法在sidd测试集上的去噪前后图对比效果;
具体实施方式
43.下面将结合附图以及具体实施例来详细说明本发明,在此本发明的示意性实施例以及说明用来解释本发明,但并不作为对本发明的限定。
44.本发明的整体流程图如图1所示,实施步骤如下:
45.步骤1,利用图像生成网络和真实噪声拟合制作额外的真实噪声数据集
46.使用异方差高斯噪声来拟合真实噪声中的光子到达统计的噪声和读出电路不精
确的噪声;利用图像生成网络将srgb图像转为rawrgb图像,将拟合的真实噪声添加,之后再将图像从rawrgb转为srgb图像,从而制作出额外的真实噪声数据集。具体包括:
47.1a)选取智能手机图像去噪数据集(smartphone image denoising dataset,sidd)作为基础训练数据集,并且从sidd提供的rawrgb数据中的metadata中提取两个噪声分量,光子到达统计的噪声(shot noise)和读出电路不精确的噪声(read noise),如图3中的圆圈点所示,其中圆圈越大说明噪声在这个点的图像越多。
48.1b)将两种噪声近似为一个异方差高斯函数,噪声为均值为像素强度,方差为像素强度的函数,设噪声强度为n,像素强度为x,则拟合的均值为μ,方差为σ2的异方差高斯噪声分布为:
49.n~n(μ=x,σ2=λ
read
+λ
shot
x)
50.其中,λ
read
为受读出电路不精确噪声影响因子,由相机传感器的数字增益和读出方差决定,λ
shot
为受光子到达统计的噪声影响因子,由相机传感器的模拟增益和数字增益决定;
51.log(λ
read
)的采样为均匀分布,如下:
52.log(λ
shot
)~u(a,b)
53.其中,a、b分别为根据sidd数据集提取的噪声分量拟合常数;
54.a=log(0.0002),b=log(0.022)
55.其中log(λ
read
)的采样服从均值为μ,方差为σ2的以log(λ
shot
)为条件的高斯分布,如下:
56.log(λ
read
)|log(λ
shot
)~n(μ=mlog(λ
shot
)+n,σ=c)
57.其中,m、n、c分别为根据sidd数据集提取的噪声分量拟合常数;m=1.85,n=1.2,c=0.3。
58.具体拟合线如图3中的斜线所示。
59.1c)利用图像生成网络生成模拟真实噪声的图片。如图2所示,该网络主体分为两个网络,第一个网络是将srgb图像转换为rawrgb图像,称为模拟逆isp(image processing pipeline)网络;第二个网络是将rawrgb图像转换为srgb图像,称为模拟isp网络。
60.1d)选择flickr2k干净图片并进行裁剪后,记为i
rgb_clean
,输入模拟逆isp网络,得到rawrgb干净图像然后将第一次直接通过模拟isp网络,获得生成的srgb干净图像第二次将加上1b)中拟合的异方差高斯噪声,所获得rawrgb含噪图像再通过模拟isp网络,获得srgb真实噪声图像构建的成对数据集即为
61.步骤2,构建基于网状结构与长距离相关性的真实图像去噪网络模型,整体结构如图4所示。具体包括:
62.2a)构建长距离相关网状u型组(long range nested ugroup,lrnu),结构如图5所示,该模块包含三层上下采样的u型网络为主体进行多尺度学习,其中下采样方式使用的为固定3
×
3卷积,卷积核为哈尔(haar)小波正变换四个卷积分量值(ll,lh,hl,hh);上采样方式为固定3
×
3反卷积,卷积和为哈尔小波逆变换的四个分量值。
63.2b)lrnu中的网状结构在保留长距离连接(add)的基础上,图5中lrnu包含四个尺度l1,l2,l3,l4,在l1,l2,l3这三个尺度中的长距离连接的基础上增加了3个3
×
3卷积,从l1,l2,l3三个尺度层进行上采样,l3上采样特征(通道c)与l2层(通道c)concat融合(通道2c)然后使用3
×
3卷积特征融合,同理,l2层上采样特征(通道c)与l1层(通道c)使用3
×
3卷积特征融合,然后再与上一步l3与l2融合的特征(通道c)再进行一次使用3
×
3卷积特征融合。最后在解码端使用1
×
1卷积进行多特征通道归整。
64.2c)lrnu中在l4尺度上结合了两个长距离相关模块(long range module,lrm),如图6左上,设网络中的特征图大小为h
×
w
×
c,首先将特征图每个通道的特征改变(reshape)为hw
×
c二维。如图6右上,然后将原来每个通道对应像素位置所构成的行看作为一条特征向量,记为x
i
,通过卷积学习三个转移矩阵w
q
,w
k
,w
v
,并与x
i
相乘得到q
i
,k
i
和v
i
三个特征向量,然后进行相关度计算得到r
i
特征向量,即:
65.r
i
=softmax(q
i
*k
j
)*v
j
66.式中,softmax代表逻辑回归函数,r
i
,q
i
,k
j
,v
j
为2c)中描述的特征向量。
67.如图6下方,同时,利用多头机制,得到多个r
i
之后,再次通过1
×
1的卷积恢复c个通道数量,最后通过一个残差连接,保证信息流通。
68.2d)如图4,整体网络使用两个lrnu模块,并且将两个lrnu的输出通道进行concat,然后加入通道注意力和空间注意力两个模块加权学习图像重点位置,1
×
1卷积恢复通道数,最外层进行残差学习策略。
69.步骤3,联合步骤1制作的数据集与步骤2的真实去噪网络模型进行训练
70.具体包括:
71.3a)以步骤1中制作的成对数据集作为预训练,然后采用sidd图像作为微调(fintune)训练,裁剪图像为512
×
512大小,并且在最终输入网络之前再使用随机函数选点裁剪送入一个batch的256
×
256大小的图像。
72.3b)在训练2)模型的时候,使用adam优化器,预训练采用的损失函数loss_pre表示为:
[0073][0074]
其中net为步骤2中构建的去噪网络,n为图像个数,为成对数据集中的噪声图像,为成对数据集中的干净图像。
[0075]
微调训练的时候使用的损失函数loss_finetune表示为:
[0076][0077]
其中,net为步骤2中构建的去噪网络,n为图像个数,i
rgb_noisy_sidd
为智能手机图像去噪数据集sidd中的噪声图像,i
rgb_clean_sidd
为智能手机图像去噪数据集sidd中的干净图像。
[0078]
使用上述两种损失函数进行分段训练,最终得到去噪后的图像。
[0079]
步骤4,将智能手机图像去噪数据集的sidd测试集中待去噪的图像输入训练好的图像去噪网络中,得到去噪后的图像。
[0080]
噪声图像与去噪后的图像对比如图7(a)和图7(b)所示,可以看出本方法模型去除了绝大部分的真实噪声,恢复了较多的图像细节。
[0081]
下面通过对比实验,验证本方法的真实图像去噪效果。
[0082]
a、对比实验方案:
[0083]
本方法与传统图像去噪算法比如bm3d,wnnm等,深度学习去噪算法dncnn,cbdnet,ridnet等在sidd测试集中进行对比,比较psnr与ssim。
[0084]
b、实验条件:
[0085]
测试集为sidd标准测试集,其中为1280张图像,然后用不同算法进行去噪对比,求出平均psnr和ssim来评估恢复效果。
[0086]
c、实验结果分析:
[0087]
实验对比psnr结果如表1所示,bm3d和wnnm传统算法在真实噪声图像上表现不好,类似dncnn这种在高斯噪声训练的深度学习模型也无法泛化到真实噪声图像,cbdnet由于估计了噪声分布,所以结果相比dncnn会高出不少,但仍旧表现一般,ridnet针对真实噪声图像进行了学习,但是依旧不如本方法。可见本方法通过对真实噪声的拟合与网络结构的改变,取得了不错的真实图像去噪效果。
[0088]
表1实验对比psnr结果
[0089][0090]
本发明并不局限于上述实施例,在本发明公开的技术方案的基础上,本领域的技术人员根据所公开的技术内容,不需要创造性的劳动就可以对其中的一些技术特征作出一些替换和变形,这些替换和变形均在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1