一种OpenStack环境下动态调整超配比的方法与流程
本发明涉及云计算技术领域,尤其涉及一种openstack环境下动态调整超配比的方法。
背景技术:
近年来,云计算和大数据等新技术协同推进,在得到广泛应用的同时,也带来了资源无法充分使用的问题。openstack作为云计算领域的业界标准,在私有云、公有云等场景完成众多的商业落地,随之带来的资源调度问题也在慢慢突显。openstack中计算节点实现了cpu/内存等资源的超配,如cpu配置1:2的超配比,1个核可对外提供2个核的调度,这样使得物理资源得到充分的利用。但云上很多业务是有时效性,当负载变化时,固定配置超配比的计算节点需要视变化动态调整,使更多的业务能调度到此节点,保证资源的充分利用,减少单位成本。
现有的openstack环境中,计算节点的cpu、内存的超配比是静态固定的,无法根据业务负载情况进行调整,会出现监控到负载整体较轻但新业务资源无法分配的情况
技术实现要素:
为了解决以上技术问题,本发明提供了一种openstack环境下动态调整超配比的方法,持续监控业务负载情况,对历史数据进行分析并确定未来趋势走向,进而动态调高计算节点的超配比,通过热迁移的方式集中负载轻的业务到这些节点,使得其他节点能调度和运行新的业务。
本发明的技术方案是:
一种openstack环境下动态调整超配比的方法,
通过对虚拟机的资源历史使用情况进行统计和分析,预判业务负载运行轨迹,对云环境中的虚拟机进行分类,从时间和空间两个维度进行预演,根据预演结果计算超配比,对候选节点进行超配比热生效,最后智能化将低负载的虚拟机集中到计算节点。
进一步的,
使用一种以上方式获取资源使用率,包括
1)使用qemu-guest-agent通过socket和宿主机传递虚拟机的cpu、内存使用率;
2)增加telegraf的input实现对接qemu-guest-agent的输出。
在每个计算节点容器化部署监控软件代理,此代理使用telegraf软件采集宿主机的cpu使用率和内存使用率;为每个虚拟机虚拟qemu-guest-agent的socket设备,通过此设备与虚拟机内部安装的qemu-guest-agent进行交互,获取虚拟机的cpu使用率和内存使用率。
采集周期为15s,监控代理把数据进行序列化,发送到服务端。
进一步的,
基于watcher组件实现策略管理,包括
1)watcher组件容器化,使用helm部署在kubernetes上;
2)增加算法插件,从prometheus获取监控指标进行趋势分析,提出低负载时间可容忍周期,当超过此周期,移入可迁移队列。
watcher服务提供策略管理功能,包括策略的增删改查,每个策略包含一个特定业务场景此插件从prometheus获取监控指标,通过监控指标判断2个条件:
1)待变更配置的计算节点:采用得分机制,对cpu使用率和内存使用率正向打分,选在得分低的节点作为候选者,候选者的数量视环境规模和业务负载优先级部署时进行配置;
2)待迁移的虚拟机:同样采用得分机制,对cpu使用率和内存使用率正向打分,选在得分低的节点作为候选者,如持续时间超出可容忍周期则放置到迁移队列;
得分低指依据cpu使用率和内存使用率正向打分,采用10分制,对候选节点进行从小到大排序,选择1~5个节点;
判断好后,则在指定时间进行策略预演和执行,预演是对待迁移的虚拟机模拟完成迁移后,计算节点变更的配置是否能满足此次策略执行,如不满足则会缩小范围,减少待迁移的虚拟机,直到预演成功,最后使用nova的热迁移功能完成策略。
进一步的,
热更改nova配置,包括
1)nova的配置项存储在kubernetes的secrets;
2)调用kubernetes的api完成secrets的修改,nova-compute服务实时获取配置更改并生效,无需重启。
使用helm按照静态超配比配置部署openstack的nova组件,nova-compute服务采用kubernetes的pod的方式运行,配置项使用kubernetes的secrets进行存储;调用kubernetes的api获取当前运行secrets,对其进行修改,动态调整超配比。
本发明的有益效果是
改变静态配置超配比的方式,结合实际业务负载情况,对负载进行趋势分析,一方面对低负载的计算节点实行超配比的热更改,另一方面对低负载虚拟机进行热迁移到变更的计算节点。使用此发明后,可以使得迁移出低负载虚拟机的节点能承载新业务,同时根据负载能进行实时迁移调整,使得计算节点的资源能充分利用,避免浪费。
附图说明
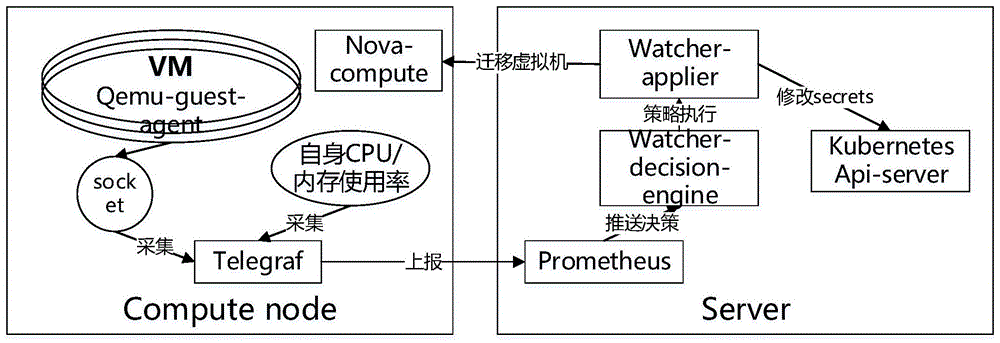
图1是本发明的工作框图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提出一种openstack环境下动态调整超配比的方法,涉及到openstack、telegraf、prometheus等多种开源技术,此处对这些技术做简单的解释。
openstack:一整套开源软件项目的集合,提供部署云的操作平台和工具集,旨在为用户提供虚拟计算、存储和网络服务。其中nova组件为计算服务,负责虚拟机的管理功能,watcher组件为资源优化服务,负责云资源的整合和动态调度;
telegraf:用golang写的开源数据收集agent,基于插件驱动,本身提供的输入和输出插件非常丰富;
prometheus:新一代的云原生监控系统,适合记录纯数字的时间序列,具备多维数据模型查询、灵活的查询语句等特点。
本发明在openstack已有实现的基础上进行创新性改进,包括趋势分析、配置变更与策略管理等模块:
趋势分析:在每个计算节点容器化部署监控软件代理,此代理使用telegraf软件采集宿主机的cpu使用率和内存使用率。为每个虚拟机虚拟qemu-guest-agent的socket设备,通过此设备与虚拟机内部安装的qemu-guest-agent进行交互,获取虚拟机的cpu使用率和内存使用率。采集周期为15s,监控代理把数据进行序列化,发送到服务端。服务端设定低负载时间可容忍周期,分析每个虚拟机的负载指标(cpu使用率),如持续低水平运行超过可容忍周期,则把这些虚拟机加入到待迁移队列,准备执行。
配置变更:使用helm按照静态超配比(如1:6)配置部署openstack的nova组件,nova-compute服务采用kubernetes的pod的方式运行,配置项使用kubernetes的secrets进行存储,因配置项中有敏感信息。调用kubernetes的api获取当前运行secrets,对其进行修改,动态调整超配比,如调整到1:16,本发明采用配置热生效的方式无需重启nova-compute的服务pod。
策略管理:基于openstack的watcher组件进行改造,新开发算法插件,此插件串联起趋势分析和配置变更。改造后的watcher服务提供策略管理功能,包括策略的增删改查,每个策略包含一个特定业务场景,如仅对某几台计算节点执行,执行成功率多大,失败如何回滚等,默认全局进行调整。此插件从prometheus获取监控指标,通过监控指标判断2个条件:
1)待变更配置的计算节点:采用得分机制,对cpu使用率和内存使用率正向打分,选在得分低的节点作为候选者,候选者的数量视环境规模和业务负载优先级部署时进行配置;
2)待迁移的虚拟机:同样采用得分机制,对cpu使用率和内存使用率正向打分,选在得分低的节点作为候选者,如持续时间超出可容忍周期则放置到迁移队列。
判断好后,则在指定时间(避开业务峰值时期)进行策略预演和执行,预演是对待迁移的虚拟机模拟完成迁移后,计算节点变更的配置是否能满足此次策略执行,如不满足则会缩小范围,减少待迁移的虚拟机,直到预演成功,最后使用nova的热迁移功能完成策略。
框图说明:
server侧:包含openstack的watcher组件、prometheus、kubernetes的api-server,watcher组件包括watcher-decision-engine和watcher-applier服务,全容器化,使用helm部署在kubernetes集群上;
computenode侧:包括openstacknova组件的nova-compute服务、telegraf,全容器化,使用helm部署在kubernetes集群上。
以上所述仅为本发明的较佳实施例,仅用于说明本发明的技术方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所做的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!