一种基于特征数据及维度缩放的黑色素瘤分类方法
1.本发明涉及计算机图像识别技术领域,尤其涉及一种基于特征数据及维度缩放的黑色素瘤分类方法。
背景技术:
2.以往经验丰富的医生都是运用皮肤镜的识别方法来进行黑色素瘤的诊断。这样诊断有很大的不足和局限性。从客观的角度看,图像上的毛发干扰和光线的影响等都会严重影响肉眼的判断。从主观的角度看,每个医生都会根据自己的经验进行判断,主观色彩较强。加上对皮肤图像的长时间观测导致的视觉疲劳导致诊断结果的差异性较大,可重复性较差,确诊率较低。
3.随着计算机硬件gpu的普及和计算机视觉领域的高速发展,yasuhiro fujisawa和sae inoue(y.fujisawa,s.inoue,and y.nakamura,“the possibility of deep learning
‑
based,computer
‑
aided skin tumor classifiers,”frontiers med.,vol.6,p.191,aug.2019.)等人将深度学习应用于皮肤镜图像的黑色素瘤分类,发现其中一些基于神经网络的深度学习算法的分类能力已经达到了一个经验丰富的医生的水准,有些甚至优于医生的判断。nasiri,s.,helsper等人(nasiri,s.,helsper,j.,jung,m.et al.depict melanoma deep
‑
class:a deep convolutional neural networks approach to classify skin lesion images.bmc bioinformatics 21,84(2020).https://doi.org/10.1186/s12859
‑
020
‑
3351
‑
y)将在imagenet上预训练好的inception v3模型进行微调,然后通过人工神经网络的密集层来融合手工功能和深度学习功能。这个特征融合模型的诊断准确率达到82.02%。在isbi 2016面向黑色素瘤检测挑战数据集的皮肤病变分析中,vinay b n等人(vinay b n,shah p j,shekar v,et al.detection of melanoma using deep learning techniques[c]//2020international conference on computation,automation and knowledge management(iccakm).ieee,2020:391
‑
394.)采用u
‑
net进行图像分割,然后再用深度残差网络进行分类,准确率达到了88.7%。然而卷积神经网络的深度不断地增加出现了诸如过拟合、数据计算量过大、梯度消失、梯度爆炸等问题。
[0004]
胡海银和王海洋等人提出了一种联合多种深度学习网络模型的模型(专利申请公布号:cn108427963a),其准确率提升不大,但是计算量却增长过多。针对目前黑色素瘤识别网络深度增加和联合学习所导致的计算量过大、准确率提升不大,在训练集上容易出现过拟合等缺点。这里提出了一种将识别对象的年龄和性别等特征数据和多维度缩放网络efficient网络相融合的神经网络efficient
‑
mix来对黑色素瘤进行分类,相较于restnet50本网络的识别准确率提升了5%。
技术实现要素:
[0005]
本发明的目的在于提供一种基于特征数据及维度缩放的黑色素瘤分类方法,旨在解决现有技术中的计算量过大、准确率提升不高,在训练集上容易出现过拟合等问题。
[0006]
为了实现上述目的,本发明提供一种基于特征数据及维度缩放的黑色素瘤分类方法,包括:
[0007]
对图像进行增强处理;
[0008]
将增强处理后的图像进行数据提取,获得目标图像数据;
[0009]
对增强处理后的图像进行数据特征提取,获得特征数据,其中,所述特征数据至少包括:性别数据和年龄数据;
[0010]
将获得的所述目标图像数据和所述特征数据进行数据连接,获得融合后的图像数据;
[0011]
对融合后的图像数据进行分类处理。
[0012]
可选的,所述将增强处理后的图像进行数据提取,获得目标图像数据的步骤:
[0013]
将经过数据增强和预处理的图片调整为384*384,并将图片在imagenet上训练好的efficient网络进行迁移学习,以通过全局平均池化层,计算每个特征图的平均值以避免过拟合;
[0014]
将经过迁移学习的数据作为目标图像数据。
[0015]
一种实现方式中,所述对增强处理后的图像进行数据特征提取,获得特征数据的步骤:
[0016]
将性别数据和年龄数据分别转化成对象并输入至多维度缩放网络全连接层;
[0017]
将获得的特征数据进行归一化处理并用relu层进行激活。
[0018]
可选的,所述将获得的所述目标图像数据和所述特征数据进行连接,获得融合后的图像数据的步骤:
[0019]
通过concatenate函数将所获得的目标图像数据和特征数据进行连接,以获得融合后的图像数据。
[0020]
应用本发明实施例提供的一种基于特征数据及维度缩放的黑色素瘤分类方法,通过将与黑色素瘤发病率影响较大的特征数据和能够缩放调整的efficient网络相融合,使得网络的性能和准确率都有了明显的提升。采用图像预处理、数据增强、添加dropout层等方法对研究过程中出现的问题进行解决和改善,模型的拟合能力和泛化能力都得到了更好的优化,减少了现有技术增加网络深度所带来的计算量过大、过拟合、梯度爆炸和梯度消失的等情况的发生,相较于restnet50本网络的识别准确率提升了5%。
附图说明
[0021]
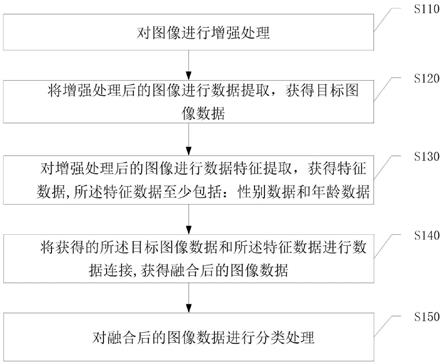
图1是本发明实施例一种基于特征数据及维度缩放的黑色素瘤分类方法的流程示意图。
[0022]
图2是本发明实施例efficient
‑
mix网络结构示意图。
具体实施方式
[0023]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。
[0024]
如图1本发明提供一种基于特征数据及维度缩放的黑色素瘤分类方法,包括:
[0025]
s110,对图像进行增强处理;
[0026]
需要说明的是,深度学习是基于庞大的数据量和合理分布且准确的数据标签来实现准确识别分类的。因此深度学习需要大量的数据进行训练,然而作为医学数据的黑色素瘤的数据量有限,因此数据增强显得十分重要。通过数据增强来增加训练数据的数据量和多样性,可以提高模型的泛化能力、避免过拟合。数据增强主要是对图像实现旋转、裁剪、缩放、拉伸、对比度增强,亮度增强等操作。数据增强技术通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模。随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力。
[0027]
可多维度缩放调整的efficient网络在缩放时平衡网络所有维度可以达到更好的精度和效率。使用一个复合系数来统一缩放网络宽度、深度和分辨率,如公式所示。
[0028][0029]
其中是一个特定的系数,用于控制资源的使用量,α,β,γ决定了资源的具体分配,α,β,γ分别代表着网络深度depth,网络宽度width,图像分辨率resolution的比重。
[0030]
相比深度较深的vgg
‑
16网络,采用多维度缩放的efficient网络能够平衡好网络深度、网络宽度和分辨率之间的关系,有效避免了网络层数增加所导致的过拟合、梯度爆炸、梯度消失、计算量较大等问题。
[0031]
s120,将增强处理后的图像进行数据提取,获得目标图像数据;
[0032]
可以理解的是,在模型结构中,首先将经过数据增强和预处理的黑色素瘤图片大小调整为384*384,随后将图片输入至已经在imagenet上训练好的efficient网络并在数据提取层进行迁移学习,获得图像数据。再经过一层全局平均池化层,计算每个特征图的平均值以避免过拟合。
[0033]
s130,对增强处理后的图像进行数据特征提取,获得特征数据,其中,所述特征数据至少包括:性别数据和年龄数据;
[0034]
需要说明的是,本发明将与黑色素瘤有着强关联的特征数据即性别和年龄都转化成对象,输入数据全连接层进行数据特征提取,然后将提取到的特征数据进行归一化处理并用relu层进行激活。经实验表明,当性别和年龄输出的尺寸调到50的时候,性别和年龄的影响过小,导致融合后网络的效果不佳;当尺寸调到500时,性别和年龄占据比重过大,图像的决策因素过低,导致准确率出现下降。而当尺寸大小调整至100左右的时候,模型效果最好。
[0035]
s140,将获得的所述目标图像数据和所述特征数据进行数据连接,获得融合后的图像数据;
[0036]
可以理解的是,在融合网络中,十分关键的一步就是用concatenate函数将经过处理的图像数据和特征数据在融合连接层进行连接,通过这一步,本发明efficient
‑
mix网络
模型就同时融合了特征信息和图像信息。使得模型和数据之间联系地更加紧密,能够更加准确地预测黑色素瘤,这比只根据图像信息来进行判断的efficient网络,识别的准确率得到了有效地提升,提升了约1%。
[0037]
s150,对融合后的图像数据进行分类处理。
[0038]
需要说明的是,efficient
‑
mix网络模型使用relu作为激活函数的全连接层、数据归一化处理的bn层、防止过拟合的丢弃层,最后添加一个激活函数为sigmoid的分类层,对融合后的图像数据进行分类,从而快速而又准确的区分出正常黑痣和黑色素瘤。efficient
‑
mix网络结构如图2所示。
[0039]
由于siim黑色素瘤的类别分布极其不均衡,本文的损失函数采用focal loss。相比传统的二分类的损失函数,focal loss不仅通过比重系数来解决正负样本的分布不均的问题,还用调制因子来平衡易分类样本和易错分样本的比例。传统的二分类交叉熵损失如公式所示。
[0040][0041]
其中,p表示经过激活函数预测样本为1的概率,值在0
‑
1之间。y表示样本对应的真实类别值。对正样本而言,输出的概率值越大损失越小,相对地,输出的概率值越小负样本的损失越小。解决类别不均衡的一种常用方法是给不同类别不同的比重因子,对正类样本采用权重因子α∈[0,1],负类样本的权重则为1
‑
α,用α
t
来统称正负样本的权重因子,同样的,使用p
t
表示正负样本的预测概率,可以得出ce loss,如下公式所示。
[0042]
ce(p
t
)=
‑
α
t
log(p
t
)
[0043][0044][0045]
α能够平衡正例和反例的比例,但难以区分易分类样本和易错分样本的比例。focal loss将调制因子(1
‑
p
t
)
γ
加入到ce loss中,可以得出focal loss,如下式所示,其中γ是调制系数。focal loss对于难以区分的样本,在大量预测概率较小的样本时,表现的效果更好。
[0046]
fl(p
t
)=
‑
(1
‑
p
t
)
γ
log(p
t
)
[0047]
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1