一种基于复习机制的机器教学方法及系统
1.本发明涉及人工智能、群体智能和众包等领域,尤其涉及一种基于复习机制的机器教学方法及系统。
背景技术:
2.机器教学(machine teaching)是一个新兴的研究领域,主要研究如何为“学习者”定制一个最优的教学样例集,以达到既定的教学目标。机器教学可以理解为机器学习的逆过程。给定已知训练集x,机器学习解决的是如何让学习者从x中习得最优模型参数θ
*
的问题。而机器教学恰恰相反,机器教学中最优模型参数θ
*
是已知的,而机器教学解决的是在x中寻找一个最小的、且能够让学习者习得模型参数θ
*
的训练集a的问题。与机器学习不同的是,机器教学中的“学习者”既可以是机器算法,也可以是人。当学习者为人类时,教学目标就是使学习者对教学样例达到目标认知状态,即使得学习者在回答同类问题时的错误率降到一个目标值。机器教学有着广泛的应用场景,例如:对抗机器学习中设计一个小训练集对机器学习算法进行攻击;线上教学系统如慕课中给学生选择教学样例;又或者选取教学样例对众包工人进行技能培训等。
3.机器教学研究一般将提供教学样例的一方称为教学者,将接收并学习样例的一方称为学习者。在研究机器教学问题时,需要先明确其教学框架,即教学者是如何向学习者提供学习样例的。然后需要对学习者进行建模,模拟学习者在该教学框架下学习状态的改变过程。在建立学习者模型后,就可以针对性地设计教学算法了。教学算法根据学习者模型的特性,从教学样例集x中挑选教学样例来对学习者进行教学。
4.现有的机器教学框架主要可以分为两类,交互式教学和非交互式教学。交互式教学是在教学过程中与学习者互动,根据学习者反馈给出最合适的教学样例,最后达到理想的教学效果。非交互式教学则是直接选择好一批教学样例,然后交给学习者进行学习,研究目标是找到一个最优的教学样例集a来达到理想的教学效果。
5.交互式教学的主要方法是知识追踪。它是一种广泛用于智能导学系统(intelligent tutoring system)的对人类学习者进行教学的算法。知识追踪算法通过分析学习者的历史答题表现来追踪他们对不同知识的掌握程度,可以将其视为一种学习者模型。而相应的教学算法非常简单,就是根据学习者每个时刻对不同知识的掌握程度,选出最适合学习者的习题来对其进行训练。常见的知识追踪算法有两类,基于贝叶斯方法的知识追踪和基于深度学习方法的知识追踪。贝叶斯知识追踪是一种典型的基于贝叶斯方法的知识追踪模型,该方法使用隐马尔科夫模型对学习者不同知识掌握程度的状态变化进行建模。随着深度学习技术的发展,长短期记忆网络和记忆增强神经网络也被用于建模学习者的知识掌握程度的变化过程。
6.常见的非交互式教学算法有strict教学算法,它用马尔科夫随机过程对学习者的学习过程进行建模,并采用贪婪算法作为教学算法。explain算法在教学框架上进行了改进,通过在展示教学样例时加入对样例的解释来提升教学效果,即在教学样例中增加了额
外信息。由于对教学过程进行了调整,他也在学习者模型中考虑了解释对学习者学习过程的影响。该方法也采用贪婪算法作为教学算法。
7.但现有技术仍存在如下问题。
8.知识追踪方法,尤其是基于深度学习方法的知识追踪,这类方法往往用于较复杂的人类教学任务(如各种学科知识的教学)上,这类任务往往具有大量的学习者练习数据,可以用于训练模型。当缺少学习者历史数据时,这类方法很难训练得到一个精确的学习者模型,从而很难取得好的教学效果。
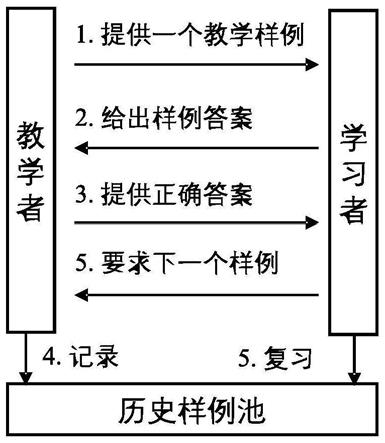
9.对于经典的strict方法和explain方法,虽然它们选取的教学样例集在学习者模型是最优的,但由于学习者与学习者模型存在差异,将其用于对学习者教学时未必是最优的,学习者在学完教学样例后并回答同类问题时往往达不到理论准确率。而这两种方法在对学习者进行教学时,只是机械地将教学样例按既定顺序教给他们。两种方法的机器教学框架如图1所示。
10.在它们的教学框架中,学习者没有选择的自由,只能被动接收样例。当学习者意识到自己的不足时,无法选择自己觉得最重要的教学样例进行学习,这进一步限制了学习者能力的提升。其中学习者的能力具体表现为,学完教学样例后,回答同类问题的准确率。
11.本发明针对当前的机器教学方法没有利用学习者自身的主观能动性,以致限制了学习者能力提升的问题,旨在提出一种基于复习机制的机器教学方法,发挥学习者的主观能动性,更好地提升学习者在该类任务上的处理能力。具体来说,本发明的目标是使得学习者在学习同等数量的教学样例后,在回答同类问题时取得比传统机器教学方法更低的错误率。
12.本发明主要解决的问题包括:(1)传统的机器教学教学过程中,学习者即使意识到自身的知识短板,也只能按顺序学习给定的教学样例,无法自行选择;(2)当学习者能够自主选择教学样例时,对其学习过程的建模方式需要进行改变;(3)针对改变后的学习者模型,需要设计相应的教学算法来挑选教学样例。
技术实现要素:
13.为此,本发明提出一种基于复习机制的机器教学方法,包括一个引入复习机制的机器教学框架和应用于所述机器教学框架的学习者模型以及应用所述学习者模型设计的教学算法;
14.具体地,所述机器教学框架为由十个步骤组成的与学习者互动的系统:
15.步骤1:对于一个给定的教学样例集x,教学者根据某种教学算法(该框架适用于任何教学算法),从x中用所述教学算法选出最优的教学样例集a并确定a中样例的教学顺序,每个教学样例由题目和答案两部分组成;
16.步骤2:取出教学样例集a中的第一个教学样例,将题目展示给学习者;
17.步骤3:学习者给出第一个样例的答案;
18.步骤4:将第一个教学样例的答案展示给学习者;
19.步骤5:将第一个教学样例加入到历史样例池中;
20.步骤6:取出教学样例集a中的下一个教学样例x,将题目展示给学习者;
21.步骤7:学习者给出教学样例x的答案;
22.步骤8:将教学样例x的答案展示给学习者;
23.步骤9:若x不在历史样例池中,则将教学样例x加入其中;
24.步骤10:学习者选择是否学习下一个教学样例,若选择是,则重复步骤6到步骤10;若选择否,则由学习者从历史样例池中选择一个,并将其题目和答案都展示给学习者,学习者复习该样例,然后重复步骤10。
25.所述学习者模型为系统后台对学习者行为的建模,通过马尔科夫过程方法构建表示学习者认知状态的空间,计算并更新对学习者认知状态的判断,进而将其应用于模拟学习者的学习策略;
26.所述教学算法应用所述学习者模型实现,所述教学算法通过挑选教学样例,使学习者模型得到系统参数计算下的最优认知状态以及对特定问题的真实答案一致的回答,并将选出的教学样例用于对真实学习者的教学。在机器教学框架的步骤1中,根据教学算法确定教学样例集a以及教学顺序,然后将a用于接下来对学习者的教学。教学算法实际上进行了一个教学前的样例筛选,根据学习者模型筛选出了一系列可能有效的教学样例。在完成筛选后,将这些样例按照所述机器教学框架对学习者进行教学。
27.所述学习者模型的马尔科夫过程方法具体为:把学习者对教学样例的一种认知状态称为假设,用h表示,对一个教学样例x,用sgn(h(x))表示学习者对样例x的判断,其中h(x)∈[
‑
1,1],h(x)<0时,sgn(h(x))=
‑
1,h(x)≥0时,sgn(h(x))=1。h是假设空间h中的元素;学习者每学习一个样例后,会从假设空间h中重新选取假设;
[0028]
当学习者接收到教学样例集a及其教学顺序后,根所述机器教学框架自主选择学习新样例还是复习历史样例,定义学习者的实际学习序列为s,s中的元素都属于a且有重复,记s中的第i个元素为s
i
,当学习者接收到教学样例集a后,根所述机器教学框架自主选择学习新样例还是复习历史样例,定义学习者的实际学习序列为s,s中的元素都属于a且有重复,记s中的第i个元素为s
i
,定义影响学习者认知状态的有关的三个因素并对学习者每个时刻的认知状态用分布p
t
(h)表示。三个因素和p
t
(h)的具体形式如下给出:
[0029]
当前样例s
i
的答案是否与学习者当前的判断sgn(h(s
i
))一致。用a(s
i
)=
‑
h(s
i
)y来表示学习者对s
i
的判断h(s
i
)与s
i
的答案y的不一致程度,对a归一化后得到影响因素a:
[0030][0031]
其中α为人为设定的参数,且α>0。
[0032]
当前样例s
i
与上一个样例s
i
‑1的差异程度。定义两种对学习者的提升最大的情况:两个相邻样例不同类但看起来相似、两个相邻样例同类但看起来不同;用d(s
i
,s
i
‑1)表示两样例间的距离,计算两张图片特征向量的欧式距离或余弦距离并将这个距离归一化得到:
[0033][0034]
其中β为人为设定的参数,β>0,那么给出影响因素b的定义:
[0035][0036]
学习者学习同一个样例的次数:定义负指数型学习曲线l(k)=1
‑
e
‑
γk
,γ>0,来表示学习者在学习同一个样本k次后对它的掌握程度,其中γ为人为设定的参数。于是学习者
第k次学习s
i
后对样例s
i
的掌握程度的提升程度:的掌握程度的提升程度:其中k(s
i
)表示学习者学习样例s
i
的次数,那么影响因素c的定义:
[0037]
c(s
i
)=1
‑
c(s
i
)
[0038]
根据上述三个影响因素,定义学习者学完第t个样例后,从假设空间h中重新选取的假设h所服从的分布:
[0039][0040]
其中归一化因子
[0041][0042]
p0(h)为人为确定的初始分布,η为指定参数。
[0043]
在所述机器教学框架下,在给定教学样例集a以及教学顺序后,学习者最终会选出一个学习序列s
a
,所述模拟学习者的学习策略采用贪婪算法,对于每个时刻t,选择使得e[err
t
]最小的样例来进行学习,定义学习者在时刻t的期望错误率为:
[0044][0045]
其中err(h,h
*
)为假设h与最优假设h
*
的距离:
[0046][0047]
学习者的具体学习策略如下:
[0048]
假设时刻t学习的样例为x,计算学习完x后的分布p
t
(h),然后计算学习x后的期望错误率e[err
t
];
[0049]
对所有的x∈x,计算第t步学习x后的期望错误率,取期望错误率最小的x,作为学习者模型第t步实际选取的样例。
[0050]
在给定教学样例集a以及教学顺序后,学习者最终会选出一个学习序列s
a
,且|s
a
|=η|a|。将学习者学完s
a
后的假设分布p(h|s
a
)定义为:
[0051][0052]
其中s
i
为学习者学习的第i个样例,且
[0053][0054]
相应的期望错误率为:
[0055]
e[err|s
a
]=∑
h∈h
p(h|s
a
)err(h,h
*
)。
[0056]
所述教学算法分为准备过程和筛选教学样例过程,
[0057]
所述准备过程包含三个步骤:
[0058]
步骤1:准备教学样例集x,采用特征提取方法对教学样例的题目部分进行特征提取,其特征向量组成教学样例集x。所述特征提取方法对图片样例采用resnet,对于文本样例采用bert;
[0059]
步骤2:构造假设空间h,随机生成n个线性分类器h,使得对任意h∈h,x∈x,都有h(x)∈[
‑
1,1];
[0060]
步骤3:确定初始分布p0,初始分布需要人为给定,比较简单的做法是,令
[0061]
所述筛选教学样例过程包括四个步骤:
[0062]
首先构造一个函数f(a):
[0063][0064]
其中
[0065][0066]
步骤1:令并确定希望达到的最小期望误差∈;
[0067]
步骤2:若对所有的x∈x,计算f(a∪{x})的值,取令f(a∪{x})的值最大的x,并将x加入a中,其中
[0068]
步骤3:重复步骤2直至结束,最终的集合a即为最终需要的教学样例集,a中元素加入a的先后顺序即为教学顺序,可以将其用于学习者的教学;
[0069]
步骤4:将最终的教学样例集a按照4.1中机器教学框架的流程对学习者进行教学,以降低学习者在回答同类问题时的错误率。
[0070]
本发明所要实现的技术效果在于:
[0071]
本发明针对当前的机器教学方法没有利用学习者自身的主观能动性,以致限制了学习者能力提升的问题,旨在提出一种基于复习机制的机器教学方法,发挥学习者的主观能动性,更好地提升学习者在该类任务上的处理能力。具体来说,本发明的目标是使得学习者在学习同等数量的教学样例后,在回答同类问题时取得比传统机器教学方法更低的错误率。
附图说明
[0072]
图1现有技术两种方法的机器教学框架;
[0073]
图2引入复习机制的机器教学框架;
具体实施方式
[0074]
以下是本发明的优选实施例并结合附图,对本发明的技术方案作进一步的描述,
但本发明并不限于此实施例。
[0075]
本发明提出了一种基于复习机制的机器教学方法,主要分为两个部分,第一部分是通过引入复习机制来充分发挥学习者主观能动性的新机器教学框架;第二部分是对该框架下的学习者模型以及针对该模型设计的教学算法。
[0076]
机器教学框架
[0077]
首先介绍本发明的机器教学框架。本发明的机器教学框架在传统的机器教学框架中引入了复习机制,具体流程分为如下几步:
[0078]
1.对于一个给定的教学样例集x,教学者根据某种教学算法(该框架适用于任何教学算法),从x中选出最优的教学样例集a并确定样例的教学顺序,每个教学样例由题目和答案两部分组成。
[0079]
2.取出教学样例集a中的第一个教学样例,将题目展示给学习者。
[0080]
3.学习者给出第一个样例的答案。
[0081]
4.将第一个教学样例的答案展示给学习者。
[0082]
5.将第一个教学样例加入到历史样例池中。
[0083]
6.取出教学样例集a中的下一个教学样例x,将题目展示给学习者。
[0084]
7.学习者给出教学样例x的答案。
[0085]
8.将教学样例x的答案展示给学习者。
[0086]
9.若x不在历史样例池中,则将教学样例x加入其中。
[0087]
10.学习者选择是否学习下一个教学样例,若选择是,则重复第6到10步。若选择否,则由学习者从历史样例池中选择一个,并将其题目和答案都展示给学习者,学习者复习该样例,然后重复第10步。
[0088]
具体流程如图1所示。
[0089]
该框架中,1至5步为初始化,6到10步为循环步。值得注意的是,该框架第10步理论上可能出现学习者重复执行第10步的死循环,但由于决定是否复习的是学习者而非机器,所以当学习者学会该样例时会自主跳出循环。
[0090]
学习者模型
[0091]
本发明考虑二分类问题,并采用马尔科夫随机过程对学习者进行建模。研究表明,学习者对教学样例的认知随着他接收教学样例而改变。本发明把学习者对教学样例的一种认知状态称为假设,用h表示。对一个教学样例x,用sgn(h(x))表示学习者对样例x的判断,其中h(x)∈[
‑
1,1],h(x)<0时,sgn(h(x))=
‑
1,h(x)≥0时,sgn(h(x))=1。h是假设空间h中的元素。学习者每学习一个样例后,会从假设空间h中重新选取假设。本发明的目标是使学习者学到最优假设h
*
,对任意的x,sgn(h
*
(x))都与x的真实答案一致。
[0092]
当学习者接收到教学样例序列a后,根据4.1中的机器教学框架,学习者能够自主选择学习新样例还是复习历史样例。假设学习者的实际学习序列为s,s中的元素都属于a且有重复,记s中的第i个元素为s
i
。学习者的认知状态与以下三个因素相关,教学算法选取样例的过程实际上可以看做模拟学习者在不同教学样例集下的学习过程以及学习效果,并最终选出效果最好的教学样例集a的过程,因此对学习者学习过程的精确建模是很重要的。在本发明中,学习者每个时刻的认知状态用分布p
t
(h)表示,而认知状态的改变则由a、b和c决定。a、b和c是本发明根据生活经验以及历史文献自行设计的:
[0093]
1.当前样例s
i
的答案是否与学习者当前的判断sgn(h(s
i
))一致。用a(s
i
)=
‑
h(s
i
)y来表示学习者对s
i
的判断h(s
i
)与s
i
的答案y的不一致程度。对a归一化后得到影响因素a:
[0094][0095]
其中α为人为设定的参数,且α>0。
[0096]
2.当前样例s
i
与上一个样例s
i
‑1的差异程度。本发明认为,以下两种情况对学习者的提升最大:两个相邻样例不同类但看起来相似;两个相邻样例同类但看起来不同。这两种情况有助于学习者发现区分教学样例的关键特征。用d(s
i
,s
i
‑1)表示两样例间的距离。具体算法为计算两张图片特征向量的欧式距离。将这个距离归一化得到:
[0097][0098]
其中β为人为设定的参数,β>0。然后就可以给出影响因素b的定义:
[0099][0100]
3.学习者学习同一个样例的次数。引入复习机制后,会出现学习者重复学习某一样例的情况。工业工程学中的大量研究表明,学习者的学习过程是符合负指数型学习曲线的规律,即学习者重复执行同一任务时,其对该任务的熟练程度会逐渐增长,且增长过程符合负指数函数。用负指数型学习曲线l(k)=1
‑
e
‑
γk
(γ为人为设定的参数,γ>0)来表示学习者在学习同一个样本k次后对它的掌握程度。于是可以计算学习者第k次学习s
i
后对样例s
i
的掌握程度的提升程度:其中k(s
i
)表示学习者学习样例s
i
的次数。综上可以给出影响因素c的定义:
[0101]
c(s
i
)=1
‑
c(s
i
)
[0102]
综合以上的影响因素,学习者学完第t个样例后,将从假设空间h中重新选取假设h,且h服从如下分布:
[0103][0104]
其中归一化因子
[0105][0106]
p0(h)为初始分布,需要人为确定,比如令n为假设空间h的大小。η需要人为指定。
[0107]
然后定义学习者在时刻t的期望错误率为:
[0108]
[0109]
其中err(h,h
*
)为假设h与最优假设h
*
的距离,具体表达式如下:
[0110][0111]
除了学习者认知状态的更新方式,还需要对学习者选择样例的策略进行建模。
[0112]
学习者选择样例的策略:由于在图1的机器教学框架下,学习者能够选择复习或学习新样例,所以还需要模拟学习者的选择策略。本发明采用贪婪算法来模拟学习者的选择策略,即每个时刻t,选择使得e[err
t
]最小的样例来进行学习。学习者的具体策略如下:
[0113]
1.假设时刻t学习的样例为x,计算学习完x后的分布p
t
(h),然后计算学习x后的期望错误率e[err
t
]。
[0114]
2.对所有的x∈x,计算第t步学习x后的期望错误率,取期望错误率最小的x,作为学习者模型第t步实际选取的样例。
[0115]
为了介绍最终的教学算法,需要定义一些新的符号。根据学习者的选择策略,在给定样例集a后,学习者最终会选出一个学习序列s
a
,且|s
a
|=η|a|。将学习者学完s
a
后的假设分布p(h|s
a
)定义为:
[0116][0117]
其中
[0118][0119]
相应的期望错误率为:
[0120][0121]
教学算法
[0122]
在对学习者的学习过程进行建模后,可以据此设计相应的教学算法。首先需要构造一个函数f(a),令:
[0123][0124]
其中
[0125][0126]
在给出f(a)后,就可以根据贪婪算法来筛选教学样例。首先进行如下准备工作:
[0127]
1.准备样例集x。采用特征提取方法对教学样例的题目部分进行特征提取,其特征向量组成样例集x。特征提取方法并不固定,例如对图片样例可以采用resnet,对于文本样例可以采用bert。
[0128]
2.构造假设空间h。假设空间h需要人为构造,且构造方法不唯一。比较简单的方法是随机生成n个线性分类器h,使得对任意h∈h,x∈x,都有h(x)∈[
‑
1,1]。
[0129]
3.确定初始分布p0。初始分布需要人为给定,比较简单的做法是,令。初始分布需要人为给定,比较简单的做法是,令
[0130]
然后可以根据以下步骤筛选教学样例:
[0131]
1.令并确定希望达到的最小期望误差∈。
[0132]
2.若对所有的x∈x,计算f(a∪{x})的值,取令f(a∪{x})的值最大的x,并将x加入a中。其中
[0133]
3.重复第2步直至结束,最终的集合a即为最终需要的教学样例集,a中元素加入a的先后顺序即为教学顺序,可以将其用于学习者的教学。
[0134]
4.将最终的教学样例集a按照图1中机器教学框架的流程对学习者进行教学,以降低学习者在回答同类问题时的错误率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1