基于主亲和性表示的档案跨模态数据特征融合方法
本发明属于跨模态检索领域,具体的涉及基于主亲和性表示的档案跨模态数据特征融合方法。
背景技术:
档案是指国家机构、社会组织以及个人在社会活动中形成的,具有保存价值和意义的各种文字、图表、声像等不同形式的文件材料。我国拥有着悠久的历史,类似“档案”一词的词意,最早可追溯到距今约4000年的夏朝。档案学已发展成为一门独立的学科,而档案检索又是档案管理的重中之重,从1998年到2007年这10年期间档案检索的相关研究论文共计557篇。随着互联网技术的飞速发展,我们已经逐步进入数据化、信息化时代。档案已不满足仅仅以纸质的形式存在,电子档案应运而生。早在上世纪四、五十年代,美国的资料情报工作人员就预见电子计算机在现代档案信息管理领域的巨大前景,并于1954年研发出世界上第一个资料情报检索系统。日新月异的信息技术带动了传统档案领域的发展,档案的信息量也呈指数式增长,这就对档案检索提出了更高的要求。面对海量的多媒体档案数据,如何挖掘这些数据之间的关联性并完成跨模态数据的检索引起学术界的广泛关注。
我国档案检索学科萌芽于20世纪30年代左右,1985年邓绍兴教授的论著《档案检索》标志着我国档案检索学科的形成。从上世纪30年代至今档案检索大致可以分为以下4个阶段:
(1)人工检索阶段。该阶段为档案检索的萌芽时期,虽然档案检索还没有作为一门系统性的学科独立存在并且也没有档案检索相关的论文与论著诞生,但是其相关研究已经开始。殷钟麒于1949年提出:档案管理应当汇案编制,分门别类以便于长期参考。
(2)计算机化检索阶段。随着电子计算机在我国的逐步普及加速了档案工作自动化的进程。档案自动检索系统将著录项如主题词、题名等作为索引使用“pc-xt”级微型计算机完成在数据库中自动检索。1987年蔡新华提出使用档案/主题词矩阵实现倒排文档检索,大大提高了档案检索效率。
(3)网络化检索阶段。随着互联网时代的来临,档案检索进入网络化检索阶段。这一时期大量基于web的档案检索系统应运而生。
(4)智能化检索阶段。“信息化”的发展趋势就是逐步迈向“智能化”。21世纪以来,人工智能技术的高速发展,促使着传统档案学的智能化演变。张倩在中阐述了现阶段档案检索面临的技术问题,总结了语义搜索、基于内容特征的多模态检索等8种搜索引擎的智能检索研究方向,并提出可以依托这些智能检索引擎而实现智能化的档案信息检索。
在国际上档案检索也有着悠久的历史,比较著名的是1284年那不勒斯王国安茹王朝编制的档案目录。近现代,布拉赫曼提出了编目理论:对档案进行整理编目以便于档案检索。其中比较著名的有谢伦伯格提出的按来源和主题编制的两类检索工具与格雷斯提出的按内部管理、内部参考、对外发表编制的三类检索工具。随着计算机的问世,欧美国家档案工作者将重心转移到自动化的档案检索工具上,美国海军军械试验站图书馆于1954年研发出世界上第一个资料情报检索系统。其后,美国于80年代中期先后研发出marcon系统、蔡斯·曼哈顿计算机检索系统、omss系统等档案自动化检索系统。近代,跨模态检索的潮流也引发了档案检索的变革。如pinho等人提出将可以跨模态检索应用于医学档案的数据检索。
跨模态检索旨在融合各种模态的异构数据通过信息互补从而达到检索准确率的最大化。不同模态数据呈现底层上特征异构、高层上语义相关的特点。所以,跨模态检索的难点就是如何将这些特征异构的数据进行统一表示,挖掘潜在的语义关联,解决不同模态数据语义鸿沟的问题。综上所述,跨模态检索的核心就是跨模态表征融合。跨模态表征融合算法主要包括以下:
共享子空间法:共享子空间法是跨模态检索中最常使用的一种方法,通过将多模态数据映射到共享的潜在子空间,从而获得语义相近但底层异构数据的互补信息实现跨模态检索。2010年,rasiwasia提出将基于线性变换的典型相关分析(cca)应用于跨模态检索领域,引起了学术界的广泛关注。akaho等在此基础上提出将支持向量机中的核函数引入cca,提出了kcca算法很好的解决了跨模态数据非线性相关的问题。andrew等提出可以将深度学习与cca算法相结合的dcca算法,进一步提升检索的准确率。区别于传统的共享子空间法使用向量空间表示数据,zhang等提出了一种用矩阵空间来表征不同特征空间的多阶判别结构子空间学习算法(mdssl)。通过使用多阶统计量表征各模态数据来丰富特征信息,然后分别对多阶统计量使用一个统一的集成距离度量框架,从而解决异构数据协方差矩阵黎曼流形在欧氏空间上不统一的问题。
针对上述问题,本文在设计面向档案数据的跨模态检索算法时,将会结合档案检索的领域独特性,并对现有的跨模态检索算法加以改进,从而最终实现高效、准确地跨模态检索任务。
技术实现要素:
发明目的:为克服上述现有技术的不足,本发明的目的在于提供基于主亲和性表示的档案跨模态数据特征融合方法。
技术方案:为实现上述发明目的,本发明采用如下技术方案:
基于主亲和性表示的档案跨模态数据特征融合方法,基于档案文本图像特征表示模块和档案文本图像表征融合模块,具体包括以下步骤:
(1)档案文本图像特征表示模块,选取档案文本、图像数据作为原始数据,通过特征提取与表示实现原始数据的向量化表示;在预处理阶段将结合档案数据的进行改进,通过多特征融合互信息的算法对文本语料的特征词筛选,并使用深度学习模型实现图文数据的特征表示;
(2)档案文本图像表征融合模块,通过跨模态表示学习实现跨模态数据的统一表示,提出一种基于混合核函数的主亲和性表示算法,使用高斯核函数与多项式核函数相结合的混合核函数实现主亲和度计算,采用多元逻辑回归完成与标签的语义映射,实现跨模态数据的统一表示。
进一步地,所述的步骤(1)中,实现图文数据的特征表示包括以下步骤:
(11)通过pkuseg分词工具并构建档案词典,实现中文文本分词任务;使用哈工大停用词表去除与主题无关的停用词,并构建同义词词典实现同义词替换;
(12)对分词后的平衡因子、词性、集中度、词频、互信息的特征进行统计计算,使用nbpcfmi算法实现短文本语料的特征词筛选;并使用bert-as-service搭建bert词嵌入服务实现词串的向量表达。
进一步地,所述的步骤(1)中,多特征融合互信息的算法对文本语料的特征词筛选包括以下步骤:
(11)采用多特征融合的互信息算法,即bpcfmi算法,针对特定主题,筛选出词串中对主题贡献度较高的特征词;通过组合融合平衡因子bp、词频f、集中度c、互信息mi、词性pos与位置l特征实现非特征词过滤;bpcfmi算法公式如下:
其中,mi(t,ci)表示总共有多少既包含特征项t又属于ci类的文档概率,fi(t)表示在类别ci中包含词组t的文档数,
(12)针对档案文本语料多为题名,位置信息一致的特征,提出一种多特征融合互信息算法,即nbpcfmi算法,nbpcfmi算法实现短文本语料的特征词筛选的公式如下:
其中,mi(t,ci)表示总共有多少既包含特征项t又属于ci类的文档概率,fi(t)表示在类别ci中包含词组t的文档数,
进一步地,所述的步骤(2)具体为:
(21)利用基于混合核函数的主亲和性表示算法,计算每种模态数据与自身样本簇的主亲和度;先通过核函数计算样本数据与聚类中心点的亲和度,实现异构数据的统一表示,再通过par学习到模态内部的相关性,从而保留元数据的特征信息;
(22)利用多元逻辑回归学习主亲和性表示到语义标签的映射关系,以实现跨模态数据的统一表示。
进一步地,所述的步骤(21)中,基于混合核函数的主亲和性表示算法包括以下步骤:
(211)通过核函数计算样本数据与聚类中心点的亲和度,实现了异构数据的统一表示;通过模态内部的相关性,保留元数据的特征信息;
(212)主亲和性表示par的定义如下:假设原始数据集x={x1,x2,…,xn}∈rd×n聚类成k簇,其中心点分别为{c1,c2,…,ck},则样本xi的主亲和性表示如下式所示:
par(xi)=[k(xi,c1),k(xi,c2),…,k(xi,ck)]
其中k(xi,xj)为核函数,1≤i≤n,1≤j≤n;
(213)针对高斯核函数过拟合问题,提出基于高斯核与多项式核的混合核函数的主亲和性表示算法,其定义如下:
其中,kgaussian、kpolynomial分别表示高斯核和多项式核函数,σ表示高斯核的带宽,d表示多项式的次数,1≤i≤n,1≤j≤n;t为转置。
有益效果:与现有技术相比,本发明的档案文本图像表征融合模块,通过跨模态表示学习实现跨模态数据的统一表示。提出一种基于混合核函数的主亲和性表示hkpar算法,针对单一核函数无法兼顾全局和局部特征的学习问题,提出使用高斯核函数与多项式核函数相结合的混合核函数实现主亲和度计算,采用多元逻辑回归完成与标签的语义映射,实现跨模态数据的统一表示。
附图说明
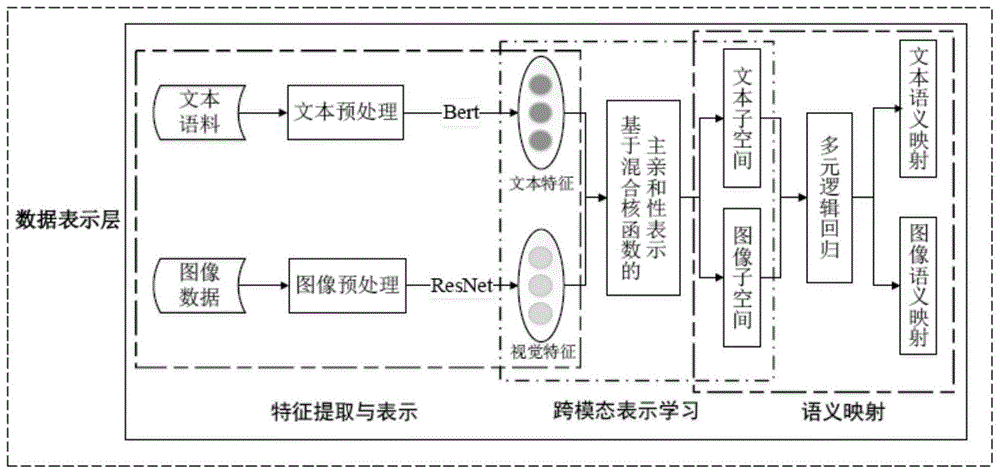
图1是本发明所述系统的框架示意图;
图2是本发明的档案图像文本构建流程图;
图3是本发明的档案图像文本特征融合流程图。
具体实施例方式
为了详细的说明本发明所公开的技术方案,下面结合说明书附图及具体实施做进一步的阐述。
基于主亲和性表示的档案跨模态数据特征融合方法,包括以下步骤:
(1)档案文本图像特征表示模块,选取档案文本、图像数据作为原始数据,通过特征提取与表示实现原始数据的向量化表示。在预处理阶段将结合档案数据的独特性进行改进,并提出一种全新的多特征融合互信息的nbpcfmi算法实现文本语料的特征词筛选,使用深度学习模型实现图文数据的特征表示。
(2)档案文本图像表征融合模块,通过跨模态表示学习实现跨模态数据的统一表示。提出一种基于混合核函数的主亲和性表示hkpar算法,针对单一核函数无法兼顾全局和局部特征的学习问题,提出使用高斯核函数与多项式核函数相结合的混合核函数实现主亲和度计算,采用多元逻辑回归完成与标签的语义映射,实现跨模态数据的统一表示。
步骤(1)档案文本图像特征表示包括以下步骤:
(11)通过pkuseg分词工具并构建档案词典,实现中文文本分词任务。使用哈工大停用词表去除与主题无关的停用词,并构建同义词词典实现同义词替换。
(12)对分词后的平衡因子、词性、集中度、词频、互信息等特征进行统计计算,使用nbpcfmi算法实现短文本语料的特征词筛选。并使用bert-as-service搭建bert词嵌入服务实现词串的向量表达。
步骤(12)中nbpcfmi算法实现短文本语料的特征词筛选包括以下步骤:
(121)采用多特征融合的互信息算法(bpcfmi算法),筛选词串中对主题贡献度较高的特征词。
(122)通过融合平衡因子(balanceparameter,bp)、词频(frequency,f)、集中度(concentration,c)、互信息(mutualinformation,mi)、词性(pos)与位置(location,l)等特征实现非特征词过滤。
(123)由于使用的档案文本语料多为题名,因此位置信息一致,结合档案文本语料的独特性在原算法的基础上提出一种全新的多特征融合互信息算法(nbpcfmi算法),其公式如下:
其中,fi(t)表示在类别ci中包含词组t的文档数,
步骤(2)包括以下步骤:
(21)利用基于混合核函数的主亲和性表示算法,计算每种模态数据与自身样本簇的主亲和度。
(22)利用多元逻辑回归学习主亲和性表示到语义标签的映射关系,以实现跨模态数据的统一表示。
步骤(21)中基于混合核函数的主亲和性表示算法包括以下步骤:
(211)主亲和性表示(par)核心思路是通过核函数计算样本数据与聚类中心点的亲和度,实现了异构数据的统一表示。相较于更关注于不同模态之间关联的传统共享子空间学习方法,基于主亲和度的表征融合算法则通过par学习到模态内部的相关性,从而更好地保留元数据的特征信息。
(212)主亲和性表示的定义如下:假设原始数据集x={x1,x2,…,xn}∈rd×n聚类成k簇,其中心点分别为{c1,c2,…,ck},则样本xi的主亲和性表示如下式所示:
par(xi)=[k(xi,c1),k(xi,c2),…,k(xi,ck)]
其中k(xi,xj)为核函数。核函数的选取对于主亲和性表示的结果有较大的影响。
(213)高斯核函数作为一种最广泛使用的核函数具有较高的适用性,然而,高斯核函数是一种局部核,距离相近的数据点对于函数值影响较大,而距离较远的数据点其作用较小。因此,使用高斯核可以较好地提取样本的局部特征,因此其外推能力较差。
(214)高斯核函数由于其学习能力较强,很容易产生过拟合现象,使得模型在测试集上泛化性能较差。相反地,多项式核函数作为一种全局核,其全局推广能力强,而相对的学习能力较弱。针对以上问题,提出一种基于高斯核与多项式核的混合核函数的主亲和性表示算法,其定义如下:
其中,kgaussian、kpolynomial分别表示高斯核和多项式核函数,σ表示高斯核的带宽,d表示多项式的次数。
实施例
本发明所提供的一种基于主亲和性表示的档案跨模态特征融合方法,系统整体架构如图1,本实施实例以河海大学档案馆文本图像数据为例,具体如下:
s1档案文本图像特征表示模块,选取档案文本、图像数据作为原始数据,通过特征提取与表示实现原始数据的向量化表示。在预处理阶段将结合档案数据的独特性进行改进,并提出一种全新的多特征融合互信息的nbpcfmi算法实现文本语料的特征词筛选,使用深度学习模型实现图文数据的特征表示。
s2档案文本图像表征融合模块,通过跨模态表示学习实现跨模态数据的统一表示。提出一种基于混合核函数的主亲和性表示hkpar算法,针对单一核函数无法兼顾全局和局部特征的学习问题,提出使用高斯核函数与多项式核函数相结合的混合核函数实现主亲和度计算,采用多元逻辑回归完成与标签的语义映射,实现跨模态数据的统一表示。
其中,在s1中,构建服务于档案文本图像搜索的数据集包括以下步骤,具体流程图如图2所示:
s101:采用bert和resnet模型分别实现文本数据和图像数据的特征表示。此外,原始的档案数据存在数据质量不一致、结构不完整、极易受到噪声数据影响、类别不平衡等问题。因此,在进行文本、图像特征表示前需要进行数据的预处理工作,从而更好地提取数据的内在语义信息;
s102:在处理中文文本时,首先需要按照语义将文本分词,从而更好地理解文本的语义信息。采用的分词工具是2019年北京大学构建的pkuseg分词工具,为降低停用词对文本分析造成的噪声干扰,通常使用停用词表过滤频繁出现在文本语料中,却不具备实际意义的词语,使用哈工大停用词表实现停用词过滤。除无实际意义的停用词之外,档案文本语料中还包含许多频繁出现却与主题无关的非特征词。因此,我们需要对分词后的词串进行特征选择,过滤文本语料中的非特征词,从而避免特征维度过高导致的维度灾难;
s103:使用的档案文本语料多为题名,其篇幅通常较短、特征稀疏。故本文拟采用多特征融合的互信息算法(bpcfmi算法),筛选词串中对主题贡献度较高的特征词。由于传统的互信息属性会降低高频词的权重而偏袒稀有特征,因而并不适用于词语个数较少的稀疏短文本。通过融合平衡因子(balanceparameter,bp)、词频(frequency,f)、集中度(concentration,c)、互信息(mutualinformation,mi)、词性(pos)与位置(location,l)等特征实现非特征词过滤。由于使用的档案文本语料多为题名,因此位置信息一致,故结合档案文本语料的独特性在原算法的基础上提出一种全新的多特征融合互信息算法(nbpcfmi算法),其公式如下:
其中,fi(t)表示在类别ci中包含词组t的文档数,
词性特征也是一种重要的筛选特征词手段。通常情况下,分词后的词串中名词、动词、形容词和副词的占比是最高的,其中名词相较于其他词性在主题的表达中所占的比重最高。通过对分词后的河海大学档案文本语料进行统计计算,得到各词性的特征词分布;
由于档案数据的时间跨度较大,同一实体在不同时期的名称可能会发生改变。针对此问题,需要手动构建档案领域的同义词词典实现数据增强。通过以上步骤,实现了档案语料的预处理工作。接着,我们需要将词串用特征向量进行表示,采用bert模型实现词嵌入。第一步,模型预训练。该步骤主要由两个无监督模型构成:其一,遮蔽语言模型。在训练深度双向语言模型时,随机遮挡句子中的部分词例,然后预测被随机遮挡的词例。但是,该模型在使用时存在一定的缺陷,若被遮挡词例在后文中从未出现,模型就会从未学习过该词例。针对该问题,提出对于被随机遮挡的词例,其中10%的token使用一个随机词代替,另外10%的词例保持不变,剩余的词例使用遮挡。通过对传统mlm模型的修改,解决了若该词例在后文中从未出现,在下游任务中无法学习的问题。其二,nsp模型。该模型训练一个二元(isnext/notnext)预测任务,用来判断文档中两个语句是否相连。预训练过程使用transformer编码器对输入数据双向编码,并通过联合每一层的上下文对数据进行深度双向表示。本文所使用的是google提供的中文语料预训练模型:bert-basechinese模型。第二步,模型微调。transformer编码器的多头自注意力机制使bert模型已经实现了下游任务的建模任务,因此只需要依据下游任务输入输出的不同对模型进行微调
s104:图像数据是以像素为基本组成单位的一种非结构化数据。图像数据质量的高低将直接影响特征表示的好坏,进而决定跨模态检索的准确率。因此,我们在对图像数据进行特征表示之前,首先需要进行数据的预处理工作。
s105:图像数据在采集、压缩和传输的过程中容易受到成像设备与外部环境的影响产生噪声数据。依据噪声和信号的关系,图像噪声可划分为以下三类:加性噪声、乘性噪声与量化噪声。噪声数据将直接降低数字图像的数据质量,进而影响特征表示。因此在图嵌入之前需要进行降噪处理。采用的是中值滤波算法,基本思想是对于数字图像中的噪声点使用其近邻点灰度值的中值来替换,从而消除图像中孤立的噪声数据。令f(x,y)表示噪声点的灰度值,滤波窗口为a的中值滤波器定义为:
几何变换通过对图像数据进行旋转、伸缩、镜像、平移等操作,从而方便图像特征的提取,其实质是在不改变像素数值的前提下,实现图像平面的像素空间重组。几何变换由两部分组成:其一,空间变换运算,通过齐次坐标变换实现输入图像到输出图像的映射。其二,灰度插值算法,由于空间变换运算可能使灰度值落在非整数域中,或出现原始图像与映射图像像素点不重合的现象。因此,需要通过灰度插值算法,得到输出图像的灰度值。具体流程如下:假设图像数据在水平与垂直方向的缩放比例分别为ratiox和ratioy,源图像缩放前后的像素点坐标分别为(x0,y0),(x1,y1),则图像缩放的空间变换运算如下所示:
比例系数大于1时,源图像被放大,映射图像中的一些像素点在源图像中可能并不存在;而当比例系数小于1时,源图像被缩小,映射图像中的一些像素点会落在非整数域中。此时需要通过灰度插值算法,从源图像中寻找近似点或通过计算求值并赋值给映射图像的像素点。
图像缩小的实质就是在尽量保证特征不丢失的前提下,从原始数据进行筛选。其中常用的方法是等间隔取值算法。图像放大相较于前者需要对多出的空值进行预测,因此其信息处理的难度更大。图像放大的灰度插值算法主要包含:最近邻插值算法和双线性插值算法。其中,双线性插值相较于前者插值结果连续,视觉上也更加平滑。双线性插值算法通过对源图像中四个邻近像素点的灰度值加权计算,从而实现水平、垂直方向上的像素插值。
档案的形成是一个长远的过程,早期的照片档案由于保存不当可能出现模糊、不清晰的情况。因此,在对照片档案特征表示之前需要先进行图像增强,通过增强图像数据中重要信息。例如,通过增加局部对比度、灰度变换等方式,以达到图像质量的改善以及丰富信息量的目的。
深度学习模型对样本数据集的大小要求较高,样本数量不足可能会导致模型泛化程度低,准确率不高。档案照片数据同样也存在样本空间较低,数据集容量较小等问题,因此在训练前需要通过图像数据增强扩充数据集,以提升模型鲁棒性。常用的数据增强方法包括:①基于几何变换的数据增强。通过平移、旋转、镜像等方法扩充数据集。②通过随机调整亮度和对比度的数据增强。③基于生成对抗网络和遗传算法的数据增强。
s106:需要对非结构化的图像数据进行特征表示。本文拟采用深度残差网络模型(residualnetwork,resnet)实现图像的特征表示。resnet模型[35]是何恺明等于2015年提出的一种基于卷积神经网络的极深网络结构。随着cnn模型的网络深度不断增加,由于梯度消失和梯度爆炸,模型的准确率呈现“退化”趋势:随着网络深度的不断增加,准确率首先会逐渐提升,之后趋于饱和,最后甚至呈现下降趋势。针对以上问题,提出使用一种全新的深度残差学习框架以解决深度学习的退化问题,具体实现如下:基于highwaynetwork的思想,在网络层中增加快捷连接(shortcutconnection),利用残差块保留原始的输入信息并直接传输到后面的网络层中。
其中,在s2中,构建档案文本图像数据集表征融合包括以下步骤,具体流程图如图3所示:
s201:主亲和性表示(par)核心思路是通过核函数计算样本数据与聚类中心点的亲和度,实现了异构数据的统一表示。相较于更关注于不同模态之间关联的传统共享子空间学习方法,基于主亲和度的表征融合算法则通过par学习到模态内部的相关性,从而更好地保留元数据的特征信息。主亲和性表示的定义如下:假设原始数据集x={x1,x2,…,xn}∈rd×n聚类成k簇,其中心点分别为{c1,c2,…,ck},则样本xi的主亲和性表示如下式所示:
par(xi)=[k(xi,c1),k(xi,c2),…,k(xi,ck)]
其中k(xi,xj)为核函数。显然,核函数的选取对于主亲和性表示的结果有较大的影响。高斯核函数作为一种最广泛使用的核函数具有较高的适用性,然而,高斯核函数是一种局部核,距离相近的数据点对于函数值影响较大,而距离较远的数据点其作用较小。因此,使用高斯核可以较好地提取样本的局部特征,因此其外推能力较差。同时,高斯核函数由于其学习能力较强,很容易产生过拟合现象,使得模型在测试集上泛化性能较差。相反地,多项式核函数作为一种全局核,其全局推广能力强,而相对的学习能力较弱。针对以上问题,提出一种基于高斯核与多项式核的混合核函数的主亲和性表示算法,其定义如下:
其中,kgaussian、kpolynomial分别表示高斯核和多项式核函数,σ表示高斯核的带宽,d表示多项式的次数;
s202:二元逻辑回归(logisticregression)是一种常见的分类学习方法,通过sigmoid函数作为激活函数将输入数据x的概率映射到0到1之间,从而获得样本在各个类别的近似概率预测,并通过数值优化算法求得最优解[71]:
通常情况下,使用极大似然估计法拟合非线性模型,求解最优参数对(β0,β1):
将二元逻辑回归推广到多元分类问题,假设预测变量x是一个k元预测变量x={x1,x2,…,xk},则其逻辑函数(logisticfunction)满足以下公式[72]:
类似于二元逻辑回归,可以使用极大似然估计求解最优参数组(β0,β1,…,βk)。然而使用最优参数解可能会导致模型的泛化能力较差。为避免以上问题,本文拟引入l2范数作为正则项,并通过对偶函数求解,从而避免模型的过拟合。l2正则化的多元逻辑回归方程表示为:
其中,c是正则化系数,n是训练样本集的大小。通过基于组合核函数的主亲和性表示与l2正则化的多元逻辑回归,实现了跨模态数据的统一语义表示。
- 还没有人留言评论。精彩留言会获得点赞!