存储装置的制作方法
1.本发明涉及存储装置,更具体而言,涉及通过无损压缩来缩减存储数据量的存储装置。
背景技术:
2.数据存储是计算机系统的基本功能。大多计算机系统在处理大量数据时会将数据保存在存储装置中。存储装置将数据保存在hdd(hard disk drive)和ssd(solid state drive)等内置存储介质(存储驱动器)中,按照外部的命令进行数据的写入和读取处理。数据保持成本在简单的定义(不考虑运行成本等)下,可计算为存储介质的比特成本(存储介质价格/存储介质容量)与记录数据量的积。
3.近年来,出于削减数据保持成本的目的,通过无损压缩算法缩减存储介质中保存的物理数据量的技术得到了广泛使用。在具有数据量缩减功能的存储装置内,在将数据写入介质之前进行压缩处理,在将数据从介质读取之后进行解压缩处理。不过,数据的压缩和解压缩是负荷较大的处理,所以若利用存储装置内的cpu(central processing unit)执行该处理,基于外部命令而执行的数据的写入和读取的性能将会降低。
4.例如,专利文献1公开了一种装置,在cpu总线上安装了能够利用专用硬件高速进行数据的压缩和解压缩的加速器,将保存在存储器(memory,例如内存)中的数据和总线上输入输出的数据的压缩和解压缩分流至加速器来减小cpu负荷。
5.另一方面,在具有数据量缩减功能的存储装置中,为了更多地削减数据保持成本,需要通过无损压缩实现较高的数据缩减率。作为其方法之一,存在以较大单位对数据进行压缩的方法。例如,若有8个8kb数据,与分别压缩8个数据相比,将8个数据排列构成为1个64kb数据对该1个数据进行压缩,能够提高数据缩减率。这是因为,存储装置使用的无损压缩算法通常是滑动字典法(sliding dictionary method),压缩单位越大则字典查找空间越大,能够发现一致字符串的概率越高。
6.现有技术文献
7.专利文献
8.专利文献1:美国专利申请公开第2017/0147624号
技术实现要素:
9.发明要解决的技术问题
10.增大数据的压缩单位是有缺点的。设想要从压缩成20kb的8个8kb数据(共64kb的数据)中,按照来自外部的命令读取1个8kb数据的情况。存储装置需要从存储介质将20kb数据读取至存储器(memory,例如内存),对其进行解压缩来将64kb数据展开到存储器中,之后提取8kb数据输出到外部。
11.若使用专利文献1所述的连接加速器的方式构成具有数据量缩减功能的存储装置,在将数据的压缩单位增大为64kb等情况下,要在存储器上读写的数据量会变得比要输
出到外部的数据量多很多。
12.对cpu的存储器带宽与存储介质的传输带宽进行比较。二者都因传输技术的逐年进步而实现了高速化,存储装置的数据读取性能也与其相应地得到了提高。但与存储介质的传输带宽相比,cpu的存储器带宽的提升率存在停滞的趋势。即,若增大数据的压缩单位,在存储装置的数据读取过程中,cpu的存储器带宽可能成为瓶颈,妨碍性能提高。
13.解决问题的技术手段
14.本发明的一个方案的存储装置包括:第一存储器;处理装置,其在所述第一存储器中保存数据,并从所述第一存储器中读取数据;和加速器,其包括与所述第一存储器不同的第二存储器,所述加速器将用于保存数据的1个以上的存储驱动器中保存的压缩数据保存在所述第二存储器中,将保存在所述第二存储器中的压缩数据解压缩而生成明文数据,从所述明文数据中提取由所述处理装置指定的数据,将提取出的所述指定的数据发送至所述第一存储器。
15.发明效果
16.采用本发明的一个方案,能够提高通过无损压缩来缩减存储数据量的存储装置的性能。
附图说明
17.图1表示第一实施方式的系统的结构。
18.图2表示第一实施方式的压缩解压缩加速器的内部结构。
19.图3a表示第一实施方式的扩大数据压缩单位的效果。
20.图3b表示第一实施方式的明文数据和压缩数据的结构。
21.图4表示第一实施方式的读取数据的提取例。
22.图5表示比较例的数据读取处理的概要。
23.图6表示第一实施方式的数据读取处理的概要。
24.图7表示第一实施方式的数据读取之一例与现有的传输量的比较。
25.图8表示比较例的数据读取处理的流程图。
26.图9表示第一实施方式的数据读取处理的第一流程图。
27.图10表示第一实施方式的数据读取处理的第二流程图。
28.图11表示第二实施方式的系统的结构。
29.图12表示第三实施方式的系统的结构。
30.图13表示第三实施方式的数据读取处理的概要。
31.图14表示第三实施方式的数据读取处理的流程图。
32.图15表示第三实施方式的数据读取之一例与第一实施方式的传输量的比较。
具体实施方式
33.下面基于附图详细说明本发明的实施方式。以下说明中,对于同一结构原则上标注相同标记省略重复说明。应当注意,以下说明的实施方式只是用于实现本发明的一个示例,并不限定本发明的技术范围。
34.<第一实施方式>
35.(1)系统结构
36.利用图1说明第一实施方式的存储装置100和包括它的系统结构,其中,存储装置100具有使用无损压缩实现的数据量缩减功能。多台主机102经由网络101与存储装置100连接。各主机102为了管理数据而经由网络101对存储装置100进行读请求或写请求(i/o请求)等各种请求。
37.存储装置100具有使用无损压缩实现的数据量缩减功能。存储装置100为了提高装置的可靠性而搭载了具有相同功能的2个存储控制器(storage controller,ctl)110,且搭载了内置多个存储驱动器130(也简称为驱动器130)作为保持数据的存储介质的驱动器盒(drive box)111。驱动器盒111包括驱动器130和用于收容驱动器130的壳体。本实施方式记载了存储控制器110为2个的例子,但本实施方式并不限定为该控制器数。例如存储装置中也可以搭载3个以上的存储控制器110。
38.驱动器130例如是hdd(hard disk drive)和ssd(solid state drive)等非易失性存储介质。本实施方式中,驱动器130并不限定于hdd和ssd。
39.存储控制器110在内部搭载有各种组件,包括:进行存储装置的各种控制的处理器(pr)128、存储器控制器(memory controller,mc)129、fe切换器(front end switch)122、dram(dynamic random access memory)125、前端接口121(以后记作fe_i/f121)和后端适配器124(以后记作be_adp124)。
40.cpu120是内置有处理器(pr)128、存储器控制器129、fe切换器122的半导体芯片。be_adp124内置be切换器126和与其连接的加速器123。
41.除dram125外的各组件由fe切换器122相互连接。该相互连接的接口规格例如是pci
‑
express。本实施方式中,存储控制器110内的连接接口不限定于pci
‑
express。
42.dram125是第一存储器,与cpu120的存储器控制器129连接。与dram125连接的处理装置即cpu120在dram125中保存数据并从dram125中读取数据。该连接接口符合的标准例如是ddr4(double data rate 4)。本实施方式中,dram125的连接接口的标准不限定于ddr4。
43.dram125是易失性存储介质,在存储装置100内提供暂时性的存储区域用作数据的高速缓存(cache)和缓冲(buffer)。易失性存储介质和非易失性存储介质都是计算机可读取的非瞬态存储介质。
44.fe_i/f121是用于连接多个主机的接口,各主机能够对存储装置进行各种请求,该接口能够使用fc(fibre channel)和ethernet等协议。本实施方式中,fe_i/f121使用的协议不限定于fc或ethernet。
45.be_adp124是用于连接搭载在存储装置100中的包括多个驱动器130的驱动器盒111的接口。be_adp124是向驱动器盒111写入数据和从驱动器盒111读取数据用的接口。be_adp124使用sas(serial attached scsi)、sata(serial ata)、nvme(nvm express)等协议。本实施方式中,be_adp124使用的协议并不限定于sas、sata、nvme。
46.加速器123是本实施方式的特征性的组件,是存储控制器110能够高速地进行数据的压缩和解压缩的硬件。加速器123是代替存储控制器110的cpu120来高速地执行压缩和解压缩处理的硬件。本实施方式记载了1个存储控制器110上搭载1个加速器123的例子,但本实施方式并不限定于该数量。例如,也可以在1个存储控制器110上搭载2个加速器123。关于加速器123的细节,使用图2在后文中叙述。
47.cpu120和驱动器130经由be切换器126与加速器123连接,进行数据传输和进行控制信息的交换。
48.存储装置100将多个驱动器130合并为一个存储区域进行管理,向主机102提供用于存储数据的区域。此时,为了防止数据因驱动器130的一部分发生故障而消失,进行基于raid(redundant arrays of inexpensive disks)技术的冗余化,实施数据保护。
49.驱动器盒111内置2个驱动器盒切换器(以后记作db_sw131),用于从2个存储控制器110向多个驱动器130分别建立数据传输路径。db_sw131管理多个驱动器130与cpu120之间的数据传输路径。各驱动器130从2个db_sw131分别具有传输路径。其目的在于,即使2个存储控制器110中的某一方发生故障也能够继续数据的读写。另外,本实施方式中db_sw131的数量不限定于2个。
50.(2)加速器结构
51.使用图2说明加速器123的内部结构。加速器123在内部包括dram220和作为数据处理电路的fpga(field programmable gate array)210。
52.dram220是与dram125相同的易失性存储介质,但不同于dram125,其是没有与cpu120连接的第二存储器。dram220在加速器123内提供压缩数据和明文数据(指未压缩的数据)的暂时性的存储区域。本实施方式中,不限定为dram220与dram125是相同的易失性存储介质。
53.fpga210是能够可编程地用硬件实现任意逻辑电路的器件。fpga210在其内部包括压缩处理电路216、解压缩处理电路217、数据完整性处理电路218、i/o接口211、dram接口212、控制电路214、和dmac(direct memory access controller)电路215。
54.本实施方式中,也可以代替fpga210,设置固定地用硬件实现逻辑电路的asic(application specific integrated circuit)。另外,fpga(或asic)210可以由1个半导体芯片构成,也可以由多个半导体芯片相互连接而构成。另外,由各个半导体芯片实现上述逻辑电路中的哪一个也是任意的。
55.dmac215连接fpga210内的压缩处理电路216、解压缩处理电路217、数据完整性处理电路218、i/o接口211、dram接口212、控制电路214。dmac215利用地址或标识符(id)传输组件之间的数据。图2中记载了各组件星形连接的方式,但本实施方式中的连接并不限定于该方式。
56.压缩处理电路216是利用无损压缩算法将明文数据压缩而生成压缩数据的逻辑电路。压缩处理电路216能够比cpu120的处理器128更高速地进行处理。
57.解压缩处理电路217是利用无损压缩算法将压缩数据解压缩而生成明文数据的逻辑电路。解压缩处理电路217能够比cpu120的处理器128更高速地进行处理。
58.数据完整性处理电路218是在要压缩的明文数据中生成包含在校验码(data guarantee code)中的crc(cyclic redundant code),并在解压缩后的明文数据中验证包含在校验码中的crc来确认数据是否损坏的逻辑电路。
59.i/o接口211是与外部连接的逻辑电路。i/o接口211在其与外部之间收发数据和控制信息。i/o接口211在压缩处理时接收明文数据并发送压缩数据。i/o接口211在解压缩处理时接收压缩数据并发送明文数据。
60.控制电路214与i/o接口211连接,通过它从cpu120接收对加速器123的处理请求。
另外,控制电路214控制dmac215,进行加速器123内的组件之间的数据传输和经由i/o接口211的数据传输。
61.控制电路214在从cpu120接收了读请求的情况下,按照请求参数,对驱动器130发出读命令(该动作在图9的流程中不进行,但在图10的流程中进行)。请求参数例如表示从驱动器130读取的对象数据的地址、对象数据内的要提取的部分的内部地址、提取出的部分的传输目标。
62.dmac215将从驱动器130接收的对象数据保存至dram220。控制电路214对压缩处理电路216、解压缩处理电路217、数据完整性处理电路218,分别指示对于对象数据进行上述压缩处理、解压缩处理、校验码处理,并将它们的处理结果传输至dram220。
63.然后,控制电路214按照从cpu120接收的请求参数,提取dram220中的处理结果数据的一部分,通过i/o接口211将其发送至dram125。进而,控制电路214通过执行定期的信息监视和中断处理,来监视fpga210的其他组件是否发生了故障。
64.dram接口212是用于fpga210读写dram220的数据的接口。该接口符合的标准例如是ddr4。本实施方式中,dram220的连接接口的规格不限定于ddr4。
65.dram接口212的通道数是这样设计的,其中,基于存储装置100的读写性能规格,计算压缩数据和明文数据的内部传输吞吐率要求,相应地设计dram接口212的通道数以具有充分的带宽。即,将其设定成,使得dram接口212的带宽在压缩数据和明文数据的传输中不会成为瓶颈。吞吐率要求越高则通道数越多。由于fpga210是可编程的,而cpu120与dram125之间的最大通道数在cpu120的规格中已经固定,因此相比而言设计自由度更高。
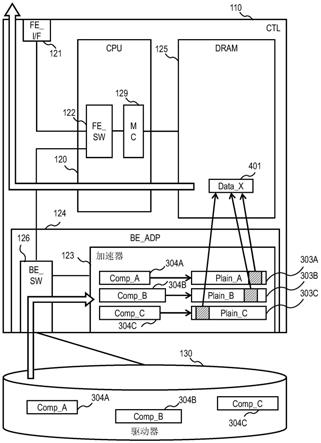
66.(3)压缩单位和数据结构
67.使用图3a和图3b说明扩大压缩单位的效果,以及明文数据和压缩数据的结构。图3a中,8kb明文数据301是存储装置100按照来自外部的读/写请求而在主机102与存储装置100之间传输的数据的最小单位。在将这些8kb明文数据分别地压缩的情况下,平均与8kb明文数据301相比减少例如46%的数据量。
68.另一方面,64kb数据303是由8个上述8kb数据301连接构成的数据。在对该64kb数据303进行压缩的情况下,平均与64kb明文数据303相比减少例如60%的数据量。像这样,已知增大压缩单位能够提高压缩率。本实施方式的存储装置100通过将压缩单位设定为比现有的8kb大的64kb,能够提高数据缩减率,削减数据保持成本。
69.图3b表示明文数据301、压缩数据302(304)的数据结构。明文数据301由主机102要保存到存储装置100中的净数据即载荷311,和与其对应的校验码312构成。校验码312包括载荷311的保存目标地址和crc。存储控制器110使用校验码312检查保存目标地址是否错误、数据内容是否损坏。另外,该保存目标地址是用于识别主机102读和写的地址空间内的位置的地址,不是驱动器130的地址。
70.压缩数据302(304)由明文数据301的压缩结果(或由8个明文数据301排列得到的明文数据303的压缩结果)322、头信息321、校验码323构成。头信息321包括压缩结果322的长度。校验码323包括压缩结果322的保存目标地址和crc。存储控制器110使用校验码323检查保存目标地址是否错误、数据内容是否损坏。另外,该保存目标地址是用于存储控制器110识别由多个驱动器130构成的地址空间内的位置的地址。
71.加速器123内的数据完整性处理电路218在进行压缩和解压缩处理时,进行校验码
312和323内的crc的生成和检查。
72.(4)读取数据的提取
73.使用图4说明存储控制器110如何构成主机102的读请求数据的方法。
74.主机102可能会对存储装置100按随机的地址顺序写入8kb明文数据301。该情况下,存储控制器110在dram125中每次按写入顺序保存了8个8kb明文数据301后,用其构成64kb明文数据303。
75.图4所示的例子中,按随机的地址顺序写入24个8kb明文数据301,3个64kb明文数据303a、303b、303c分别由8个8kb明文数据301的组构成。8个8kb明文数据301的组各自的一个8kb明文数据例如由标记301表示。表示8kb明文数据301的矩形内的数字,是用于识别主机102读和写的地址空间内的位置的地址。存储控制器110对3个64kb明文数据个别地进行压缩,并保存在驱动器130中。
76.之后,主机102可能对存储装置100按连续的地址顺序读取8kb明文数据301。图4表示主机102读取由3个8kb明文数据301构成、地址是005、006、007的顺序即连续的24kb明文数据401的例子。
77.图4的例子中,存储控制器110从驱动器130读取由3个64kb明文数据303a、303b、303c分别压缩得到的3个64kb压缩数据304。存储控制器110对3个64kb压缩数据304分别解压缩,还原为3个64kb明文数据303a、303b、303c。存储控制器110从它们中提取地址是005、006、007的3个8kb明文数据301,构成主机102请求的读数据401。
78.如果压缩单位是8kb,则存储控制器110从驱动器130读取3个由8kb明文数据302压缩得到的数据,将其分别解压缩。存储控制器110使用3个8kb明文数据301构成主机102请求的读数据401。
79.即,若扩大了压缩单位,如上所述,在主机102进行的访问是按随机的地址顺序写入之后连续地读取的情况下,存储控制器110需要从驱动器130读取较多的数据进行解压缩。从而,存储控制器110内的数据传输路径的带宽消耗增大,所以可能导致传输带宽成为瓶颈、存储装置100的性能降低。
80.(5)数据读取处理
81.使用图5和图6说明比较例和本实施方式的数据读取处理。图5表示比较例的存储装置中扩大了压缩单位时的数据读取处理。与图1所示的本实施方式的存储装置100相比,追加了与fe切换器122连接的压缩解压缩引擎127。另外,be_adp141与图1所示的be_adp124不同,没有内置加速器。压缩解压缩引擎127与图1所示的加速器123同样地,是高速地进行数据的压缩和解压缩的硬件,按照处理器128的处理指示,以来自dram125的数据为输入进行压缩或解压缩并将结果输出至dram125。
82.图5中,cpu120从驱动器130将3个64kb压缩数据(comp_a(304a)、comp_b(304b)、comp_c(304c))经由be_adp141、fe_sw122、存储器控制器129读取至dram125。接着,cpu120经由存储器控制器129、fe_sw122将3个64kb压缩数据304a、304b、304c从dram125传输至压缩解压缩引擎127,并指示其解压缩。
83.压缩解压缩引擎127对3个64kb压缩数据304a、304b、304c解压缩,生成3个64kb明文数据(plain_a(303a)、plain_b(303b)、plain_c(303c))。压缩解压缩引擎127经由fe_sw122和存储器控制器129将3个64kb明文数据303a、303b、303c传输到dram125。
84.cpu120从中提取3个8kb明文数据,构成主机120请求的读数据(data_x(401))保存在dram125中。cpu120经由存储器控制器129、fe_sw122和fe_i/f121将读数据181回复给主机102。
85.图6表示本实施方式中扩大了压缩单位时的数据读取处理。cpu120从驱动器130将3个64kb压缩数据(comp_a(304a)、comp_b(304b)、comp_c(304c))经由be_adp124的be_sw126读取至加速器123内的dram220。这样,保存在驱动器130中的压缩数据304a、304b、304c被不经由drma125地传输至dram220。
86.接着,加速器123对3个64kb压缩数据304a、304b、304c解压缩,在dram220中保持3个64kb明文数据(plain_a(303a)、plain_b(303b)、plain_c(303c))。加速器123从3个64kb明文数据303a、303b、303c中提取指定的3个8kb明文数据,将它们经由fe_sw122和存储器控制器129传输至dram125。cpu120用3个8kb明文数据构成主机102请求的读数据(data_x(401)),经由fe_sw122和fe_i/f121回复给主机102。
87.(6)数据读取过程的传输量的比较
88.使用图7对比较例和本实施方式的数据读取过程中存储装置100内传输的数据的量进行比较。图7的表700以存储装置100响应于主机102的读请求而回复图4所示的3个8kb明文数据的情况为例,表示了经过存储装置100内部的各组件的数据的传输方向和数据量(单位是kb)之一例。
89.列701表示组件名,列702表示传输方向(输入、输出、传输源、或传输目标)。列703表示在图5所示的比较例的数据读取中,将压缩单位设定为8kb的情况下的传输数据量。列704表示在比较例的数据读取中,将压缩单位扩大为64kb的情况下的传输数据量。列705表示在本实施方式的数据读取中,将压缩单位扩大为64kb的情况下的传输数据量。表700中,一部分单元格的数据量由3个值的和表达,各值表示压缩单位的数据(压缩或明文数据)的数据长度(data size)。
90.本例中,假定地址005、006、007的8kb明文数据301因压缩而平均被压缩46%,成为4kb、5kb、4kb的数据。另外,假定分别包含地址005、006、007的8kb数据的64kb明文数据303a、303b、303c因压缩而平均被压缩60%,分别成为20kb、30kb、26kb的数据。
91.对列703所示的比较例的数据流进行说明。3个8kb压缩数据从驱动器130经由be_adp141、fe_sw122和存储器控制器129保存至dram125(行“1”、“8”、“9”)。3个8kb压缩数据经由存储器控制器129、fe_sw122从dram125传输至压缩解压缩引擎127(行“10”、“11”、“12”)。
92.解压缩后的3个8kb明文数据从压缩解压缩引擎127经由fe_sw122和存储器控制器129传输至dram125(行“13”、“14”、“15”)。由3个8kb明文数据形成的读数据从dram125经由存储器控制器129、fe_sw122和fe_i/f121传输至主机102(行“18”、“19”)。
93.接着对列704所示的比较例的数据流进行说明。3个64kb压缩数据从驱动器130经由be_adp141、fe_sw122和存储器控制器129保存至dram125(行“1”、“8”、“9”)。3个64kb压缩数据经由存储器控制器129、fe_sw122从dram125传输至压缩解压缩引擎127(行“10”、“11”、“12”)。
94.解压缩后的3个64kb明文数据从压缩解压缩引擎127经由fe_sw122和存储器控制器129传输至dram125(行“13”、“14”、“15”)。从3个64kb明文数据中提取3个8kb明文数据构成读数据(行“16”、“17”)。形成的读数据从dram125经由存储器控制器129、fe_sw122和fe_
i/f121传输至主机102(行“18”、“19”)。
95.接着,对列705所示的本实施方式的数据流进行说明。3个64kb压缩数据经由be_adp124的be_sw126传输至加速器123内的dram220(行“1”、“2”)。3个64kb压缩数据从dram220传输至加速器123内的fpga210(行“3”、“4”)。
96.接着,解压缩后的3个64kb明文数据从fpga210传输至加速器123内的dram220(行“5”、“6”)。从3个64kb明文数据中提取出3个8kb明文数据,从dram220经由fe_sw122和存储器控制器129传输至dram125(行“7”、“8”、“15”)。使用从dram125传输到cpu120的3个8kb明文数据构成读数据(行“18”),经由fe_sw122和fe_i/f121传输至主机102(行“19”)。
97.表700的倒数第3行表示加速器123内的dram220上输入输出的数据量的合计。倒数第2行表示dram125上输入输出的数据量的合计。可知在比较例中,当压缩单位扩大时如列704所示,dram125上输入输出的数据量从48kb大幅增加至416kb。
98.如列705所示,在本实施方式中,即使压缩单位扩大,dram125上输入输出的数据量也保持为48kb。不过,dram220上输入输出的数据量是368kb。48+368=416,所以在本实施方式的处理中,dram上输入输出的数据量的合计与现有的处理相比不发生变化,但能够抑制在与cpu120连接的dram125上输入输出的数据量的增加。
99.例如,假定为了在要求的时间内向主机102回复3个8kb明文数据301,在cpu120所内置的存储器控制器129的通道数下,需要将数据量抑制为200kb以下。这表示,在输入输出数据量因压缩单位的扩大而增加至416kb时,dram传输成为瓶颈,存储装置100的读性能降低。
100.另一方面,本实施方式如参照图2所说明的那样,加速器123具有供fpga210对dram220进行读写的接口,所以其通道数能够可编程地设计。例如,进行逻辑设计使得加速器123内的fpga210的dram接口212具有cpu120所内置的存储器控制器129的2倍的通道数,则在数据量达到400kb之前不会发生性能降低。
101.因此,即使dram220的输入输出数据量因压缩单位的扩大而达到368kb,dram传输也不会成为瓶颈,存储装置100的读性能不会降低。在使用与fpga不同的硬件例如asic的情况下,也能够与cpu120独立地设计该硬件与dram220之间的通道数,所以能够达到同样的效果。
102.表700的倒数第1行表示经由fe_sw122在dram125上输入输出的数据量的合计。比较例在以8kb单位压缩时是74kb,在以64kb单位压缩时增加至368kb。本实施方式的数据量是48kb,与比较例相比能够减少因压缩单位增大导致的数据量增加。
103.由于能够抑制cpu120内的fe_sw122的带宽消耗,所以能够减小fe_sw122的传输带宽成为存储装置100的读性能瓶颈的风险。上述例子中,使用由三个压缩数据解压缩得到的明文数据构成读数据,但要读取的压缩数据数是根据主机102的读请求而决定的。如上所述,在需要对多个压缩数据分别解压缩、提取部分数据来形成读数据的情况下,本实施方式相对于比较例能够发挥更大的效果。
104.(7)数据读取处理的流程图
105.使用图8、图9、图10表示比较例和本实施方式的数据读取处理的流程图。图8是比较例的数据读取处理的流程图。按cpu120、压缩解压缩引擎127、驱动器130进行的处理划分为3列。
106.首先,cpu120对驱动器130发出压缩数据的读命令(801)。驱动器130将按照读命令而读取的压缩数据传输至与cpu120连接的dram125(图8中是ctl的dram)(802)。cpu120将压缩数据保持在dram125中(803)。
107.接着,cpu120对压缩解压缩引擎127发送压缩数据,请求其解压缩(804)。压缩解压缩引擎127按照解压缩请求对压缩数据进行解压缩(805)。解压缩结果即明文数据被传输至dram125。
108.cpu120从明文数据中提取由主机102请求读的数据部分(806)使用这些数据部分形成读数据(807)。最后,cpu120对主机102回复读数据(808)。
109.图9和图10分别是本实施方式的数据读取处理的流程图。各图都按cpu120、加速器123、驱动器130进行的处理划分为3列。
110.此处,作为从cpu120发出读取指示的方法表示了2种例子。图9是对驱动器130和加速器123个别地发出指示的例子。图10是一次性对加速器123发出指示的例子。
111.图9中,首先,cpu120对驱动器130发出压缩数据的读命令(901)。读命令包括驱动器130的读取开始地址和读取长度以及表示数据传输目标的参数。
112.驱动器130将按照步骤901的请求参数而读取的64kb压缩数据304a、340b、304c传输至指定的加速器123内的dram220(图9中是加速器的dram)(902)。加速器123将64kb压缩数据304保持在dram220中(903)。驱动器130向cpu120通知传输完成。
113.接着,接收到传输完成的通知的cpu120对加速器123请求明文数据部分(904)。该请求包括64kb明文数据303a~303c各自之中为了回复主机102的读请求所需要的数据部分的开始地址(第二地址)和长度、以及传输目标。
114.加速器123响应于上述请求,对64kb压缩数据304a、304b、304c解压缩(905)。然后,按照步骤904的请求参数,从解压缩结果的64kb明文数据303a、303b、303c中分别提取部分数据(906)。加速器123将提取出的数据部分传输至与cpu120连接的dram125(图9中是ctl的dram)(907)。
115.cpu120使用这些数据部分形成读数据401(908)。最后,cpu120对主机102回复读数据401(909)。如上所述,cpu120对驱动器130指示其将压缩数据发送至dram220,加速器123从cpu120接收包括要提取的数据的地址的请求,从明文数据中提取指定的数据。通过上述流程,能够减少加速器123的处理,能够减小其电路结构。
116.另一方面,在图10所示的流程中,首先,cpu120对加速器123请求明文数据部分(1001)。该请求的参数包括驱动器130的读取开始地址(第一地址)和读取长度、64kb明文数据303之中为了回复主机102的读请求所需要的数据部分的开始地址(第二地址)和长度、以及数据部分的传输目标。
117.加速器123按照步骤1001的请求参数,对驱动器130发出压缩数据的读命令(1002)。读命令与参照图9说明的例子相同。驱动器130将按照读命令而读取的64kb压缩数据304a、304b、304c传输至加速器123内的dram220(图10中是加速器的dram)(1003)。加速器123将64kb压缩数据304a、304b、304c保持在dram220中(1004)。
118.接着,加速器123对64kb压缩数据304a、304b、304c进行解压缩(1005)。然后,加速器123按照步骤1001的请求参数,从解压缩结果的64kb明文数据303a、303b、303c中提取为了回复主机102的读请求所需要的数据部分(1006)。加速器123将提取出的数据部分传输至
与cpu120连接的dram125(图10中是ctl的dram)(1007)。
119.cpu120使用这些数据部分形成读数据401(1008)。最后,cpu120对主机102回复读数据401(1009)。如上所述,加速器123从cpu120接收包括保存在驱动器130中的压缩数据的开始地址、和要从明文数据中提取的数据的开始地址的请求。加速器123指定压缩数据的开始地址,指示驱动器130将压缩数据发送至drma220,并按照指定的开始地址从明文数据中提取数据。通过上述流程,能够减少cpu120的处理,提高存储装置的性能。
120.<第二实施方式>
121.使用图11说明第二实施方式的存储装置100和包括它的系统结构。主要说明与图1所示的第一实施方式的差异。
122.第二实施方式中,加速器145不是搭载在存储控制器110内而是搭载在驱动器盒111内。在图11的结构例中,一个驱动器盒111中搭载了2个加速器145以实现冗余化。存储控制器110代替be_adp124搭载了be_sw126。加速器不与be_sw126连接。
123.驱动器盒111内的2个db_sw131分别与各驱动器130连接,并且与1个加速器145连接。即使例如1个be_sw126发生故障,也能够维持运转。第二实施方式的加速器145进行与第一实施方式的加速器123相同的动作。
124.第二实施方式在后续增加驱动器盒111(驱动器130)的个数的情况下是有效的。第一实施方式在驱动器盒111的数量较少时,加速器123的性能可能过剩而导致耗费多余的成本。而在驱动器盒111的数量增多时,存在加速器123性能不足的可能性。在第二实施方式中,由于加速器145的数量随驱动器盒111(驱动器130)的数量相应地增加,所以能够抑制多余的成本,并且降低加速器性能不足的风险。
125.<第三实施方式>
126.使用图12说明第三实施方式的存储装置100和包括它的系统结构。主要说明与图1所示的第一实施方式的差异。
127.第三实施方式中,加速器146不是与存储控制器110内的be_sw126连接,而是与fe_sw122连接。加速器146与上述第一实施方式中的加速器123和第二实施方式中的加速器145不同,不具有从驱动器130直接读取数据的功能。但是,加速器146内部结构与图2所示的加速器123相同。另外,加速器146也可以与be_sw126连接。
128.第三实施方式不需要用加速器146实施对驱动器130的访问控制,所以与第一和第二实施方式相比,在未搭载加速器的现有存储装置上后续安装加速器的情况下,或者将图5的比较例所示的存储装置的压缩解压缩引擎127置换为加速器的情况下是有效的。这是因为,对驱动器130的访问控制与现有技术同样地由cpu120实施,所以能够减少需要由加速器146实现的功能,并且由于加速器146不需要直接访问驱动器130,所以加速器146的搭载部位的选项较多。
129.(1)第三实施方式中的数据读取处理
130.使用图13说明第三实施方式的数据读取处理。图13表示第三实施方式中扩大了压缩单位时的数据读取处理。cpu120从驱动器130将3个64kb压缩数据(comp_a(304a)、comp_b(304b)、comp_c(304c))经由be_adp141、fe_sw122和存储器控制器129读取至dram125。接着,cpu120经由存储器控制器129、fe_sw122将3个64kb压缩数据304a、304b、304c从dram125传输至加速器146,指示其解压缩。这样,保存在驱动器130中的压缩数据304a、304b、304c被
经由drma125传输至dram220。
131.接着,加速器146对3个64kb压缩数据304a、304b、304c解压缩,在dram220中保持3个64kb明文数据plain_a(303a)、plain_b(303b)、plain_c(303c)。加速器146从3个64kb明文数据303a、303b、303c中提取指定的3个8kb明文数据,经由fe_sw122和存储器控制器129传输至dram125。cpu120用3个8kb明文数据构成主机102请求的读数据data_x(401),经由fe_sw122和fe_i/f121回复给主机102。
132.(2)包括第三实施方式在内的数据读取过程的传输量的比较
133.使用图14对第三实施方式的数据读取过程中存储装置100内传输的数据的量进行比较。图14的表1400以存储装置100响应于主机102的读请求而回复图13所示的3个8kb明文数据的情况为例,表示了经过存储装置100内部的各组件的数据的传输方向和数据量(单位是kb)之一例。
134.列1401表示组件名,列1402表示传输方向(输入、输出、传输源、或传输目标)。列1403相当于图7所示的列704,表示在比较例的数据读取中,将压缩单位扩大为64kb的情况下的传输数据量。列1404相当于图7所示的列705,表示在第一实施方式的数据读取中,将压缩单位扩大为64kb的情况下的传输数据量。列1405表示在第三实施方式的数据读取中,将压缩单位扩大为64kb的情况下的传输数据量。表1400中,一部分单元格的数据量由3个值的和表达,各值表示压缩单位的数据(压缩或明文数据)的数据长度。另外,图14所示的数据长度的估算是在与图7相同的条件下实施的,省略重复内容的说明。
135.参照图13和图14说明列1405表示的第三实施方式的数据流。3个64kb压缩数据304a、304b、304c从驱动器130经由be_adp141、fe_sw122和存储器控制器129保存至dram125(行“1”、“a”、“b”)。3个64kb压缩数据304a、304b、304c经由存储器控制器129、fe_sw122从dram125传输至加速器146(行“c”、“d”、“2”)。3个64kb压缩数据304a、304b、304c从dram220传输至加速器123内的fpga210(行“3”、“4”)。
136.接着,解压缩后的3个64kb明文数据303a、303b、303c从fpga210传输至加速器123内的dram220(行“5”、“6”)。从3个64kb明文数据303a、303b、303c中提取出3个8kb明文数据,从dram220经由fe_sw122和存储器控制器129传输至dram125(行“7”、“8”、“15”)。使用从dram125传输到cpu120的3个8kb明文数据构成读数据401(行“18”),经由fe_sw122和fe_i/f121传输至主机102(行“19”)。
137.表1400的倒数第3行表示加速器146内的dram220上输入输出的数据量的合计。倒数第2行表示dram125上输入输出的数据量的合计。对列1404所示的第一实施方式与列1405所示的第三实施方式进行比较可知,dram220上的输入输出数据量相等。另一方面,关于dram125上的输入输出数据量,第三实施方式要多出152kb。但是,与列1403所示的比较例相比,第三实施方式能够将dram125上的输入输出数据量缩减为一半以下(从416kb到200kb)。
138.表1400的倒数第1行表示经由cpu120内的fe_sw122在dram125上输入输出的数据量的合计。对列1404所示的第一实施方式与列1405所示的第三实施方式进行比较可知,第三实施方式的输入输出数据量比第一实施方式的输入输出数据量多152kb。但是,与列1403所示的比较例相比,第三实施方式能够将输入输出数据量缩减为大致一半(从368kb到200kb)。
139.通过以上所述,第三实施方式虽然相对于第一和第二实施方式效果较差,但能够
减少dram125和cpu120内的fe_sw122的带宽消耗。因此,在它们的带宽成为存储装置100的读性能的瓶颈的情况下,通过采用第三实施方式,能够提高存储装置100的读性能。
140.(3)第三实施方式的数据读取处理的流程图
141.使用图15表示第三实施方式的数据读取处理的流程图。按cpu120、加速器146、驱动器130进行的处理划分为3列。
142.首先,cpu120对驱动器130发出压缩数据的读命令(1501)。驱动器130将按照读命令而读取的压缩数据传输至与cpu120连接的dram125(图15中是ctl的dram)(1502)。cpu120将压缩数据保持在dram125中(1503)。
143.接着,cpu120对加速器146发送压缩数据,并请求明文数据部分(1504)。该请求包括64kb明文数据303a~303c各自之中为了回复主机102的读请求所需要的数据部分的开始地址(第二地址)和长度、以及传输目标。
144.加速器146响应于上述请求,对64kb压缩数据304a、304b、304c解压缩(1505)。然后,按照步骤1504的请求参数,从解压缩结果的64kb明文数据303a、303b、303c中分别提取部分数据(1506)。加速器146将提取出的数据部分传输至与cpu120连接的dram125(图15中是ctl的dram)(1507)。
145.cpu120使用这些数据部分形成读数据401(1508)。最后,cpu120对主机102回复读数据401(1509)。如上所述,加速器146从cpu120接收包括压缩数据、和要从明文数据提取的数据的开始地址的请求。加速器146从cpu120的dram125读取压缩数据,对数据解压缩,并按照指定的开始地址从明文数据中提取数据。通过上述流程,能够减少cpu120的处理,提高存储装置的性能。
146.本发明并不限定于具有图1、图11或图12所示的组件作为存储控制器110内的组件的存储装置100。例如,也可以是在存储控制器110或驱动器盒111内搭载了对数据进行加密的加速器的存储装置100。
147.本发明不限定于上述实施方式,包括各种变形例。例如,上述实施方式为了使本发明易于理解而进行了详细说明,但并不限定于必须具备所说明的全部结构。能够将某个实施方式的结构的一部分置换为其他实施方式的结构,也能够在某个实施方式的结构上添加其他实施方式的结构。另外,对于各实施方式的结构的一部分,能够追加、删除、置换其他结构。
148.上述各结构、功能、处理部等,例如可以通过集成电路设计等而由硬件实现其一部分或全部。上述各结构、功能等,也可以通过处理器解释、执行实现各功能的程序而由软件实现。实现各功能的程序、表、文件等信息,能够保存在存储器、硬盘、ssd(solid state drive)等记录装置、或者ic卡、sd卡等记录介质中。
149.另外,控制线和信息线表示了说明上必要的部分,并不一定表示了产品上全部的控制线和信息线。实际上也可以认为几乎全部结构都相互连接。
150.附图标记说明
151.100
……
存储装置,110
……
存储控制器,120
……
cpu,122
……
fe_sw,123
……
加速器,125、220
……
dram,130
……
驱动器
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1