一种基于深度学习的船舶作业违章行为实时侦测方法与流程
1.本发明涉及船舶管理技术领域,尤其涉及一种基于深度学习的船舶作业违章行为实时侦测方法。
背景技术:
2.随着社会经济的发展,交通运输事业在迅速发展,运输船舶在数量、吨位和航速上逐年增长,船舶行驶安全也越来越受到重视,每年因为船舶工作人员的违章行为导致的事故时有发生,各大机构和公司都在致力于预防和及时制止违章行为的发生,排除安全隐患。传统的预防方式主要为开船前严格检查和通过摄像头人工监测,人工观看监控方法无法对海量的视频进行有效利用,由于人工疲劳和场景太多,会漏掉许多违规行为,进而带来安全隐患。
3.现有技术中,对于运输船舶各类作业操控人员的违章监控行为缺乏实时的人工智能监测手段,不能实时分辨监测出违章行为的细小细节,以及提供准确有效判决和报警。
技术实现要素:
4.本发明主要解决的技术问题是提供一种基于深度学习的船舶作业违章行为实时侦测方法,解决现有技术中对船舶操控违章行为缺乏人工智能监测以及难以监测小目标的问题。
5.为解决上述技术问题,本发明采用的一个技术方案是提供一种基于深度学习的船舶作业违章行为实时侦测方法,包括:步骤一:采集训练图像数据,对船舶中监控摄像头拍摄的违章图像数据进行采集和处理,构建违章图像数据库;步骤二:训练一级检测模型,从所述违章图像数据库中选取初级训练图像,输入到一级检测模型进行人员特征检测训练,直至所述一级检测模型收敛,则所述一级检测模型被训练为人员特征检测识别模型;步骤三:应用一级检测模型,继续利用初级训练图像,输入到已经训练好的所述一级检测模型中进行检测,根据有效检测出的人员特征,对初级训练图像进行裁剪获得二级训练图像;步骤四:训练二级检测模型,将二级训练图像输入到二级检测模型进行违章特征检测训练,直至所述二级检测模型收敛,则所述二级检测模型被训练为违章特征检测识别模型;步骤五:实时采集数据检测,船舶中监控摄像头实时采集监控图像,输入到已经训练好的人员特征检测识别模型和违章特征检测识别模型进行检测,对应输出人员特征检测结果和违章特征检测结果;步骤六:操控违章行为识别,将所述人员特征检测结果和违章特征检测结果与对应的违章行为进行匹配识别,输出识别判断结果。
6.优选的,在步骤一中,所述违章图像数据处理包括筛选图像、裁剪图像和/或标注图像。
7.优选的,在步骤二中,在初级训练图像输入到一级检测模型之前,对初级训练图像进行尺度缩放处理,得到统一尺寸的统一训练图像,然后将统一训练图像输入到一级检测模型进行训练。
8.优选的,在步骤二中,所述一级检测模型是基于yolov4网络改进的第一yolov4网络改进模型。
9.优选的,在步骤二中,将统一训练图像送入所述第一yolov4网络改进模型的不同输出通道和不同输出尺度的卷积块中,获得对应的池化特征图,将所述池化特征图进行残差连接和多尺度融合,得到最终的三种不同尺度的人员检测特征图输出。
10.优选的,在步骤三中,根据各场景人员检测结果,对人员检测图像进行裁剪,获得包含人员目标的二级训练图像,对所述二级训练图像进行标注,由此构建二级模型训练数据库。
11.优选的,在步骤四中,所述二级检测模型是基于yolov4网络改进的第二yolov4网络改进模型。
12.优选的,在步骤四中,对第二yolov4网络改进模型训练时,对二级训练图像缩放到固定尺寸608*608,送入所述第二yolov4网络改进模型的不同输出通道和不同输出尺度的卷积块中,获得对应的池化特征图,再将所述池化特征图进行残差连接和多尺度融合,得到最终的三种不同尺度的违章检测特征图输出。
13.优选的,在步骤五中,对采集的监控图像缩放到416x416大小,然后输入已经训练好的第一yolov4网络改进模型进行检测,对应输出三种尺度的人员检测特征图;对三种尺度的人员检测特征图,分别预测并回归13*13*3个目标框,输出每个目标框的位置信息、置信度和类别信息;设定置信度阈值,过滤置信度小于置信度阈值的预测框,对保留的目标框进行非极大值抑制,输出最终的人员特征检测结果。
14.优选的,在步骤六中,统计一段时间内所述人员特征检测结果和违章特征检测结果的违章帧数,输出检测占比统计,设定报警阈值,根据占比统计结果,超过阈值时给出报警。
15.本发明的有益效果是:本发明公开了一种基于深度学习的船舶作业违章行为实时侦测方法。该方法包括步骤先对违章图像数据采集,用于训练一级检测模型和二级检测模型,分别对人员特征检测识别和违章特征检测识别,然后基于这两种模型对船舶中实时监控拍摄的图像进行实时检测,得到人员特征检测结果和违章特征检测结果,再与对应的违章行为进行匹配识别,输出识别判断结果。该方法中使用了改进的yolov4模型,能够对船舶上人员抽烟、玩手机、未穿工作服等细节性违章行为进行智能化实时检测,具有良好的实时性、精确性以及鲁棒性,有效的解决了船舶操控违章行为实时检测问题,同时具有较短的检测时间和和较高的检测精度。
附图说明
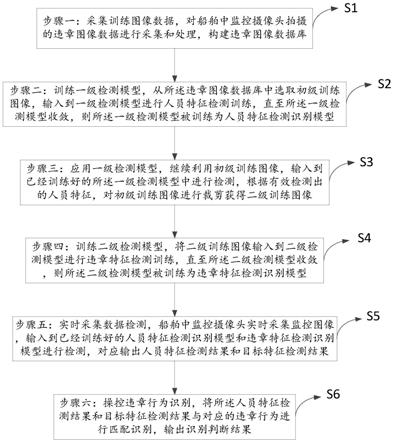
16.图1是根据本发明基于深度学习的船舶作业违章行为实时侦测方法一实施例的流程图;
17.图2是根据本发明基于深度学习的船舶作业违章行为实时侦测方法另一实施例中一级检测模型网络架构图;
18.图3是根据本发明基于深度学习的船舶作业违章行为实时侦测方法另一实施例中二级检测模型网络架构图。
具体实施方式
19.为了便于理解本发明,下面结合附图和具体实施例,对本发明进行更详细的说明。附图中给出了本发明的较佳的实施例。但是,本发明可以以许多不同的形式来实现,并不限于本说明书所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
20.需要说明的是,除非另有定义,本说明书所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是用于限制本发明。本说明书所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
21.图1显示了本发明基于深度学习的船舶作业违章行为实时侦测方法一实施例的流程图。该方法包括步骤有:
22.步骤一s1:采集训练图像数据,对船舶中监控摄像头拍摄的违章图像数据进行采集和处理,构建违章图像数据库;
23.步骤二s2:训练一级检测模型,从所述违章图像数据库中选取初级训练图像,输入到一级检测模型进行人员特征检测训练,直至所述一级检测模型收敛,则所述一级检测模型被训练为人员特征检测识别模型;
24.步骤三s3:应用一级检测模型,继续利用初级训练图像,输入到已经训练好的所述一级检测模型中进行检测,根据有效检测出的人员特征,对初级训练图像进行裁剪获得二级训练图像;
25.步骤四s4:训练二级检测模型,将二级训练图像输入到二级检测模型进行违章特征检测训练,直至所述二级检测模型收敛,则所述二级检测模型被训练为违章特征检测识别模型;
26.步骤五s5:实时采集数据检测,船舶中监控摄像头实时采集监控图像,输入到已经训练好的人员特征检测识别模型和违章特征检测识别模型进行检测,对应输出人员特征检测结果和违章特征检测结果;
27.步骤六s6:操控违章行为识别,将所述人员特征检测结果和违章特征检测结果与对应的违章行为进行匹配识别,输出识别判断结果。
28.优选的,在步骤一s1中,船舶中监控摄像头拍摄的违章图像数据是高清图像数据,例如是像素为1920*1080的高清图像数据,这些高清图像数据包括多种场景和多种违章行为的图像,例如驾驶台场景、甲板场景、船舷场景、机舱场景等,违章行为包括甲板作业不戴安全帽、不穿工作服和不穿工作鞋,船舷临水作业不穿救生衣,值班室人员玩手机,驾驶台人员吸烟、用餐等。
29.优选的,在步骤一s1中,分别采集驾驶室、集控室、机舱、船头甲板在不同时间、不同光照下的图像,采样间隔为10分钟。
30.优选的,在步骤一s1中,对所述违章图像数据处理包括筛选图像,去除因遮挡而显示内容难以识别的图像,以及去除没有检测目标的图像,例如需要对人员进行检测,但是图像中没有人员,则去除这些图像。
31.优选的,在步骤一s1中,对所述违章图像数据处理包括裁剪图像,并且可以是随机裁剪包含检测目标的图像,例如对于一幅1920*1080的高清图像,可以根据检测目标的数
量、大小和位置进行随机裁剪为不同大小的图像,例如图像中有一个人员占据的矩形像素范围为260*50,可以裁剪获得这样的一个包含检测人员的图像。
32.优选的,在步骤一s1中,对所述违章图像数据处理包括标注图像,通过标注来说明该违章图像检测目标,例如标注类别为“person”表明是该违章图像中用于检测识别人员特征,例如标注类别为“phone”表明是该违章图像中用于检测识别手机特征。优选的,可以通过矩形框在图像上进行标注,框出目标位置并标注对应的类别。具体的,图像数据的标注方法为:使用pascal voc格式标注违章行为涉及的多类目标,为了标注框位置的精确性,本专利采用浮点型数据格式记录标注框位置信息,包括标注框左上角和右下角的坐标,然后转换成检测模型,如yolov4网络需要的数据格式。优选的,图像标注数据文件格式如下:
33.<object
‑
class><x><y><width><height>
34.其中,object
‑
class是类的索引,后面的4个值都是相对于整张图片的比例值。其中,width和height是矩形框的宽和高相对于原图像宽和高的比例值,x是目标框内中心点的横坐标相对于图像宽的比例值,y是中心点纵坐标相对于图像高的比例值。
35.优选的,在步骤二s2中,所述一级检测模型为第一yolov4网络改进模型,如图2所示,该模型是在yolov4网络模型基础上进行了适应性修改,在darknet53单元10中包括模块input(416,416,3)、模块conv2d_bn_mish(416,416,32),以及以下5个级联的模块:
36.模块resblock_body(208,208,64)
×137.模块resblock_body(104,104,128)
×238.模块resblock_body(52,52,256)
×839.模块resblock_body(26,26,512)
×840.模块resblock_body(13,13,1024)
×441.还进一步级联有模块conv
×
3,以及spp模块12和模块concat+conv
×
3。该spp模块对特征尺度为13x13的特征图进行空间金字塔池化(spp),池化核大小分别为1、4、9。进一步,模块resblock_body(104,104,128)
×
2、模块resblock_body(26,26,512)
×
8和模块concat+conv
×
3对应为三个输出通道分别输出三种池化特征图至panet单元11。然后panet单元11将三种池化特征图进行残差连接和多尺度融合操作。
42.进一步的,在图2中包括第一输出通道由模块resblock_body(104,104,128)
×
2输出第一池化特征图至第一concat+conv
×
5模块110,然后输出到第一yolohead模块111,由第一yolohead模块111生成尺度为104x104的人员检测特征图。
43.第二输出通道由模块resblock_body(26,26,512)
×
8输出第二池化特征图至第二concat+conv
×
5模块113;第三输出通道由模块concat+conv
×
3输出第三池化特征图至第三concat+conv
×
5模块114。
44.其中,模块concat+conv
×
3输出最小特征尺度13x13的第三池化特征图,被第一conv+upsampling上采样模块115上采样之后,通过第二concat+conv
×
5模块113与模块resblock_body(26,26,512)
×
8输出的26x26尺度的第二池化特征图融合;第二concat+conv
×
5模块113输出的特征图被第二conv+upsampling上采样模块116上采样后,与模块resblock_body(104,104,128)
×
2输出的104x104尺度的第一池化特征图,通过第一concat+conv
×
5模块110进行融合。
45.进一步的,特征尺度从大到小进行下采样后与下一级特征图融合,具体是第一
concat+conv
×
5模块110输出的104x104尺度的特征图经过第一downsampling下采样模块118下采样之后,通过第四concat+conv
×
5模块119与第二concat+conv
×
5模块113输出的26x26尺度的特征图融合,第四concat+conv
×
5模块119输出的26x26尺度的特征图又经过第二downsampling下采样模块120下采样之后输入到第三concat+conv
×
5模块114,第一concat+conv
×
5模块110输出的104x104尺度的特征图还经过第三downsampling下采样模块121下采样之后输入到第三concat+conv
×
5模块114,与concat+conv
×
3模块输出的13x13特征尺度的池化特征图进行融合。这样通过第一yolo head模块111、第二yolo head模块112和第三yolo head模块123分别得到三种尺度为104x104、26x26、13x13的人员检测特征图输出。
46.优选的,在步骤二s2中,相对于原有yolov4网络模型,本发明的第一yolov4网络改进模型修改了特征图的残差连接,将预测使用的特征尺度由原始的13,26,52扩大为13,26,104。
47.其中,特征尺度较小的13尺度特征图感受野最大,提取的语义信息最为丰富,在较大的anchor框下,能够准确的预测较大的目标,比如驾驶舱和机舱的工作人员。
48.而对于特征尺度较大的104尺度特征图,相比52尺度的特征图具有更多的细节信息,更有助于定位较小的目标,例如驾驶室工作人员手里的香烟、手机等。因此,经过改进的残差连接,融合后的三种特征图不仅能准确的定位大目标,也能精准的检测小目标。
49.进一步优选的,在步骤二s2中,在初级训练图像输入到一级检测模型之前,对初级训练图像进行尺度缩放处理,得到统一尺寸的统一训练图像,然后将统一训练图像输入到一级检测模型进行训练。例如对1920*1080的高清图像缩小为416*416的图像,以及对于裁剪后的小图像进行放大而得到416*416的图像。
50.优选的,如上所述,在步骤二s2中,将统一训练图像送入所述第一yolov4网络改进模型的不同输出通道和不同输出尺度的卷积块中,获得对应的池化特征图输出。进一步优选的,将上述得到的池化特征图进行残差连接和多尺度融合,得到最终的三种不同尺度的人员检测特征图输出。
51.进一步优选的,根据设置的anchor大小,在上述三种不同尺度的人员检测特征图进行网格分割,分别预测分割n*n*3个目标框,以及每个目标框的位置信息、置信度和类别信息,再根据输入的初级训练图像对应的矩形框的标注信息,进行误差计算和反向传播。
52.优选的,将人员检测特征图分割成n*n个网格取决于所述第一yolov4网络改进模型最后输出的人员检测特征图的最小尺寸。优选的,最后输出的人员检测特征图最小尺寸为13*13,因此需要将人员检测特征图分割成13*13的网格,即n=13。
53.优选的,在步骤二s2中,第一yolov4网络改进模型在训练时,对初级训练图像可以随机缩放到固定尺寸,缩放后的尺寸范围从320*320到608*608,步长为32,即包括320*320、352*352、384*384、416*416、
……
、608*608,那么图像也会对应随机分割成n*n个网格,n的范围是10到19,这里优选为输入图像尺寸为416*416,n=13。
54.优选的,在步骤二s2中,第一yolov4网络改进模型采用了anchor boxes机制,模型中使用9个anchor框,例如设定的9个anchor框对应的宽高值为{(24,55),(21,74),(32,87),(22,132),(38,107),(32,153),(41,190),(50,164),(56,211)}。根据最终三种人员检测特征图的感受野大小变化,每种人员检测特征图分配三个不同大小的anchor框,并且
69.模块resblock_body(19,19,1024)
×470.还进一步级联有模块conv
×
3,以及spp模块22和模块concat+conv
×
3。该spp模块对特征尺度为19x19的特征图进行空间金字塔池化(spp),池化核大小分别为5、9、13。其中,模块resblock_body(152,152,128)
×
2、模块resblock_body(38,38,512)
×
8和模块concat+conv
×
3分别输出特征图至panet单元21。然后panet单元21将三种池化特征图进行残差连接和多尺度融合操作。
71.进一步的,在图3中包括第一输出通道由模块resblock_body(152,152,128)
×
2输出第一池化特征图至第一concat+conv
×
5模块210,然后输出到第一yolohead模块211,由第一yolohead模块211生成尺度为152x152的违章检测特征图。
72.第二输出通道由模块resblock_body(38,38,512)
×
8输出第二池化特征图至第二concat+conv
×
5模块213;第三输出通道由模块concat+conv
×
3输出第三池化特征图至第三concat+conv
×
5模块214。
73.其中,模块concat+conv
×
3输出最小特征尺度19x19的第三池化特征图,被第一conv+upsampling上采样模块215上采样之后,通过第二concat+conv
×
5模块213与模块resblock_body(38,38,512)
×
8输出的38x38尺度的第二池化特征图融合;第二concat+conv
×
5模块213输出的特征图被第二conv+upsampling上采样模块216上采样后,与模块resblock_body(152,152,128)
×
2输出的152x152尺度的第一池化特征图,通过第一concat+conv
×
5模块210进行融合。
74.进一步的,特征尺度从大到小进行下采样后与下一级特征图融合,具体是第一concat+conv
×
5模块210输出的152x152尺度的特征图经过第一downsampling下采样模块217下采样之后,通过第四concat+conv
×
5模块218与第二concat+conv
×
5模块213输出的38x38尺度的特征图融合,第四concat+conv
×
5模块218输出的38x38尺度的特征图又经过第二downsampling下采样模块219下采样之后输入到第三concat+conv
×
5模块214,第一concat+conv
×
5模块210输出的152x152尺度的特征图还经过第三downsampling下采样模块220下采样之后输入到第三concat+conv
×
5模块214,与concat+conv
×
3模块输出的19x19特征尺度的池化特征图进行融合。这样通过第一yolo head模块211、第二yolo head模块212和第三yolo head模块221分别得到三种尺度为152x152、38x38、19x19的违章检测特征图输出。
75.优选的,在步骤四s4中,对于第二yolov4网络改进模型进行训练时,设置迭代次数为30000次,初始学习率为0.01,每隔10000次,衰减学习率为原始的1/10。
76.优选的,在步骤四s4中,第二yolov4网络改进模型在训练时,对二级训练图像缩放到固定尺寸608*608,送入所述第二yolov4网络改进模型的不同输出通道数和不同输出尺度的卷积块中,获得对应的池化特征图。进一步优选的,将上述得到的池化特征图进行残差连接和多尺度融合,得到最终的三种不同尺度的违章检测特征图输出。具体的网络连接方式如前所述,这里不再赘述。
77.进一步优选的,根据设置的anchor大小,在上述三种不同尺度的违章检测特征图进行网格分割,分别预测分割n*n*3个目标框,以及每个目标框的位置信息、置信度和类别信息,再根据输入的二级训练图像对应的矩形框标注信息,进行误差计算和反向传播。
78.优选的,将违章检测特征图分割成n*n个网格取决于所述第二yolov4网络改进模
型最后输出的违章检测特征图的尺寸。优选的,最后输出的违章检测特征图最小尺寸为19*19,因此需要将违章检测特征图分割成19*19的网格,即n=19。
79.优选的,在步骤四s4中,第二yolov4网络改进模型进行训练时,当达到最大迭代次数或者损失值不再降低时结束训练,获得该第二yolov4网络改进模型检测二级训练图像的最终的模型配置文件和权重参数。
80.优选的,在步骤五s5中,对采集的监控图像缩放到416x416大小作为一级检测图像,然后输入已经训练好的第一yolov4网络改进模型进行检测,对应输出三种尺度的人员检测特征图。
81.进一步的,在步骤五s5中,对三种尺度的人员检测特征图,分别预测并回归13*13*3个目标框,输出每个目标框的位置信息、置信度和类别信息。
82.进一步的,在步骤五s5中,设定置信度阈值,过滤置信度较低的预测框,对保留的目标框进行非极大值抑制,输出最终的人员特征检测结果,从而实现目标的精确定位和识别。
83.优选的,设定置信度阈值β,当置信度低于β时,目标框被过滤掉,在保留的目标框中,选取置信度最高的框做为基准框,将剩余框分别与基准框求交集和并集,去除剩余框中交并比nms大于第二阈值的框,以去掉同个目标的多个预测框。优选的,为了降低误检率,我们将置信度阈值β设定为0.85,交并比nms对应的第二阈值设定为0.35,当交并比大于0.35时,认定该框与基准框是预测的同一个目标并去除。
84.优选的,在步骤五s5中,根据人员特征检测结果,对包含人员目标的监控图像进行裁剪,得到包含人员目标的二级检测图像,将二级检测图像缩放到608x608大小,然后送入已经训练好的第二yolov4网络改进模型中进行检测,输出违章特征检测结果,以实现香烟、手机、工作服等小目标的精确定位和识别。
85.这里,将裁剪后二级检测图像缩放到608x608之后送入训练好的第二yolov4网络改进模型,可以使得二级检测图像被放大之后,小目标像素占比显著提升,背景像素点减少,通过预先聚类anchor框在三种尺度特征图上进行预测,能准确检测出香烟和手机等小目标。
86.优选的,在第二yolov4网络改进模型进行检测中,包括将二级检测图像送入第二yolov4网络改进模型具有不同输出通道数和输出尺度的卷积块中,获得对应的池化特征图。进一步优选的,将上述得到的池化特征图进行残差连接和多尺度融合,得到最终的三种不同尺度的目标检测特征图输出。
87.进一步的,在步骤五s5中,对三种尺度的违章检测特征图,分别预测并回归19*19*3个目标框,输出每个目标框的位置信息、置信度和类别信息。进一步的,在步骤五s5中,设定置信度阈值,过滤置信度较低的预测框,对保留的目标框进行非极大值抑制,输出最终的违章特征检测结果,从而实现目标的精确定位和识别。具体实现方法参照前述内容,这里不再赘述。
88.步骤六s6:操控违章行为识别,将所述人员特征检测结果和目标特征检测结果与对应的违章行为进行匹配识别,输出识别判断结果。
89.优选的,在步骤六s6中,统计一段时间内所述人员特征检测结果和违章特征检测结果的违章帧数,输出检测占比统计,设定报警阈值,根据占比统计结果,超过阈值时给出
报警。
90.优选的,在步骤六s6中,每个监控摄像头取帧间隔为25,也就是每25帧图像中取出1帧作为检测帧用于检测,以实现多路摄像头并行检测。考虑到需要对多个摄像头并行检测,若每一帧都检测则性能会降低,当船舶工作人员进行某一个动作时,比如玩手机和抽烟,在2秒之内,动作变化幅度小,一秒大约包含25帧,因此我们每个摄像头取帧的间隔为25帧中取1帧,这样既能实现多路摄像头并行检测,也不会漏掉包含违章行为的图像。
91.根据一级检测模型的输出结果,我们可以计算在规定帧数内检测到人员目标的占比,从而去判断是否出现违章行为,例如:船舶航行时,驾驶室只有一人值班、规定时间内无人对机舱进行巡检等;根据二级检测模型的输出结果,我们可以根据检测到香烟、手机目标在规定帧数中的占比,去判断驾驶室值班人员是否玩手机和抽烟。该步骤可以输出各违章行为对应每50个检测帧中检测出目标的帧数占比。
92.优选的,为了提高检测的精度,降低因为遮挡或光线变化给检测带来的负面影响,将报警阈值设定为0.5,即该场景中,50个检测帧内,有25个检测帧都检测出违章目标,如香烟,那么就给出出现抽烟违章行为的警报。根据人员特征检测结果和违章特征检测结果,计算各违章行为对应每50个检测帧中检测出违章的帧数占比。
93.优选的,通过一级检测模型检测出人员特征,例如检测出在驾驶室中的值班人员,又通过二级检测模型检测出香烟或手机,根据这两个模型的检测结果可以判定人员在驾驶室违规抽烟或玩手机的结果,然后与违章规定不能在驾驶室抽烟或玩手机,确定出现了违章行为进而可以报警。
94.本发明对既定船舶工作人员违章行为检测的准确率能够达到0.863,对于不同船只、不同场景的适应性较广,对于由于光线变化、摄像机角度不规范等原因产生的低质量图像同样具有较好的效果,适用于多场景、多目标的违章行为检测。
95.由此可见,本发明公开了一种基于深度学习的船舶作业违章行为实时侦测方法。该方法包括步骤先对违章图像数据采集,用于训练一级检测模型和二级检测模型,分别对人员特征检测识别和违章特征检测识别,然后基于这两种模型对船舶中实时监控拍摄的图像进行实时检测,得到人员特征检测结果和违章特征检测结果,再与对应的违章行为进行匹配识别,输出识别判断结果。该方法中使用了改进的yolov4模型,能够对船舶上人员抽烟、玩手机、未穿工作服等细节性违章行为进行智能化实时检测,具有良好的实时性、精确性以及鲁棒性,有效的解决了船舶操控违章行为实时检测问题,同时具有较短的检测时间和和较高的检测精度。
96.以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1