基于HADOOP的小文件存储方法及其装置与流程
本申请涉及一种基于hadoop的小文件存储方法及其装置,属于文件存储技术领域。
背景技术:
hadoop分布式文件系统(hdfs)属于在通用硬件(commodityhardware)上运行的分布式文件系统。它和现有的分布式文件系统有很多共同点。hdfs具有高度容错性,能提供高吞吐量的数据访问。同时hdfs放宽了一部分posix约束,以实现流式读取文件系统数据的目的。
hadoop分布式文件系统的基本存储单元是数据块(block),当设置一个数据块容量为128mb时,如果上传文件大小小于该值时,由于hdfs系统现有存储模式,导致该文件依然会占用一个block的命名空间(namenodemetadata),但物理存储上则不会占用128mb的全部空间。
当需要存储大量小文件时,整个文件系统可存储文件数量受限于namenode的内存大小,导致hdfs系统无法高效存储大量字节数小于10mb的小文件。
技术实现要素:
本申请提供了一种基于hadoop的小文件存储方法及其装置,用于解决现有hdfs系统中每个数据块仅能存储一个文件,该文件会同时占据该数据块命名空间导致无法大量有效存储小文件的技术问题。
本申请提供了一种基于hadoop的小文件存储方法,包括以下步骤:
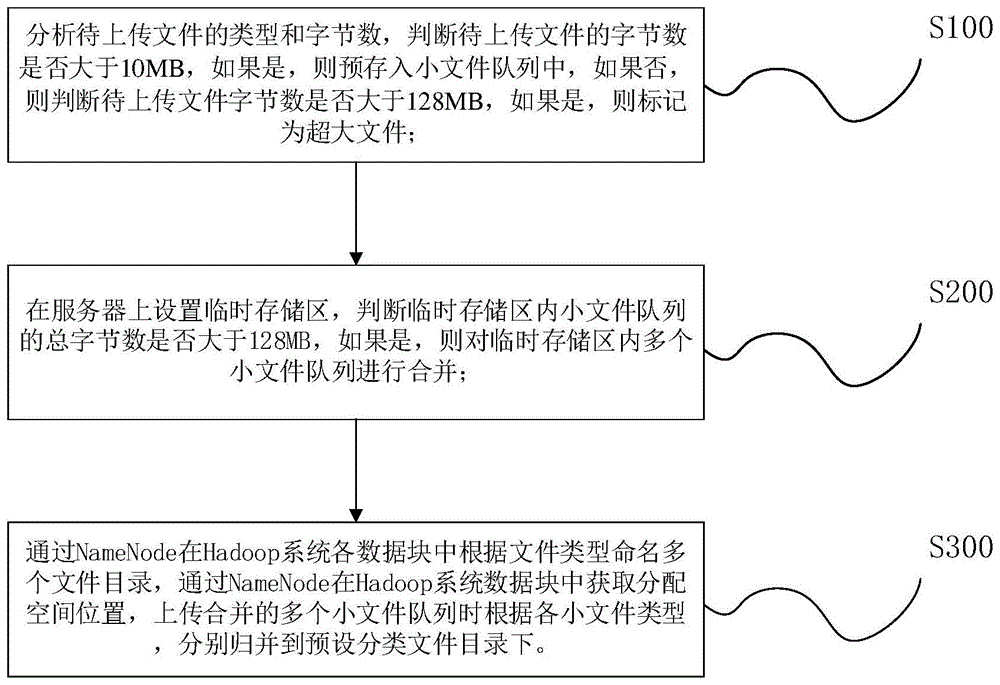
步骤s100:分析待上传文件的类型和字节数,判断待上传文件的字节数是否大于10mb,如果是,则预存入小文件队列中,如果否,则判断待上传文件字节数是否大于128mb,如果是,则标记为超大文件;
步骤s200:在服务器上设置临时存储区,判断临时存储区内小文件队列的总字节数是否大于128mb,如果是,则对临时存储区内多个小文件队列进行合并;
步骤s300:通过namenode在hadoop系统各数据块中根据文件类型命名多个文件目录,通过namenode在hadoop系统数据块中获取分配空间位置,上传合并的多个小文件队列时根据各小文件类型,分别归并到预设分类文件目录下。
优选的,还包括:步骤s400:用户读取小文件时,通过文件类型经过namenode获得小文件存储位置,并进行小文件读取。
优选的,步骤s400中用户读取小文件步骤包括:用户输入文件信息后,对小文件中包含信息进行搜索,输出结果按包含用户输入信息量由多到少进行依序排列检索文件,并将包含用户输入信息最多的检索文件排列在文件队列前端,对所得多个检索文件进行预加载,输出小文件检索队列。
优选的,步骤s100中包括:对小文件队列中的小文件分别进行序列化处理后,得到小文件队列。
优选的,步骤s200中包括:如果判断临时存储区内小文件队列的总字节数是否大于128mb时所得结果为否,则判断临时存储区内各小文件队列存储时间是否达到存储时限,如果是,则对对临时存储区内多个小文件队列进行合并。
优选的,步骤s100中包括:对判断为非小文件的文件按照hadoop的常规方式存储到对应文件分类数据块中。
本申请的另一方面还提供了一种如上述的方法所用装置,包括:
文件处理器,用于分析待上传文件的类型和字节数,判断待上传文件的字节数是否大于10mb,如果是,则预存入小文件队列中,如果否,则判断待上传文件字节数是否大于128mb,如果是,则标记为超大文件;
合并机,用于在服务器上设置临时存储区,判断临时存储区内小文件队列的总字节数是否大于128mb,如果是,则对临时存储区内多个小文件队列进行合并;
文件读取模块,用于通过namenode在hadoop系统各数据块中根据文件类型命名多个文件目录,通过namenode在hadoop系统数据块中获取分配空间位置,上传合并的多个小文件队列时根据各小文件类型,分别归并到预设分类文件目录下。
优选的,包括:文件检索模块,文件检索模块用于用户输入文件信息后,对小文件中包含信息进行搜索,输出结果按包含用户输入信息量由多到少进行依序排列检索文件,并将包含用户输入信息最多的检索文件排列在文件队列前端,对所得多个检索文件进行预加载,输出小文件检索队列。
优选的,文件处理器包括:序列化模块,序列化模块,用于对小文件队列中的小文件分别进行序列化处理后,得到小文件队列。
优选的,包括:存储时限模块,存储时限模块,用于如果判断临时存储区内小文件队列的总字节数是否大于128mb时所得结果为否,则判断临时存储区内各小文件队列存储时间是否达到存储时限,如果是,则对对临时存储区内多个小文件队列进行合并。
本申请能产生的有益效果包括:
1)本申请所提供的基于hadoop的小文件存储方法,通过在一个hdfs文件中按一定的规则放入多个小文件,改善了小文件存储的读写效率慢和空间占用大的问题。
2)本申请所提供的基于hadoop的小文件存储方法,通过对待存入文件字节数进行分类,并对文件类型进行分类后,对于字节数小于10mb的小文件进行临时存储后分类型上次,能减少对服务器的访问次数,减少分别存储小文件对系统资源的占用。
3)本申请所提供的基于hadoop的小文件存储方法,通过namenode在hadoop系统数据块中获取分配空间位置,并根据小文件类型上传合并的多个小文件队列能提高小文件存储准确性,便于用户获取文件时检索效率提高和访问准确率提高。
4)本申请所提供的基于hadoop的小文件存储方法,通过在检索时对小文件中所含用户信息量进行排序,提高用户准确检索得到小文件的准确率,进而减少用户对系统的访问次数,减少大量存储小文件导致的系统资源消耗过大的问题。
附图说明
图1为本申请提供的基于hadoop的小文件存储方法的流程示意图;
图2为本申请提供的基于hadoop的小文件存储装置模块连接示意图。
具体实施方式
下面结合实施例详述本申请,但本申请并不局限于这些实施例。
参见图1,本申请提供的基于hadoop的小文件存储方法,包括以下步骤:
步骤s100:分析待上传文件的类型和字节数,判断待上传文件的字节数是否大于10mb,如果是,则预存入小文件队列中,如果否,则判断待上传文件字节数是否大于128mb,如果是,则标记为超大文件;
采用该步骤能实现对不同字节数的文件进行分类存储,提高文件存储效率和处理效率。
步骤s200:在服务器上设置临时存储区,判断临时存储区内小文件队列的总字节数是否大于128mb,如果是,则对临时存储区内多个小文件队列进行合并;
采用上述步骤进行小文件存储能减少多次存储对系统资源的占用,通过将多个小文件合并后再在系统处于闲时的情况下一次性将文件写入的文件系统中,这样可以使文件的写操作对系统影响最小,使查询数据时间得到节约,达到减少系统写入小文件队列的次数。主要依据有两个,一个是命名节点的目录个数,另一个是上传文件合并时间。临时存储区用于存储多个小文件队列。
步骤s300:通过namenode在hadoop系统各数据块中根据文件类型命名多个文件目录,通过namenode在hadoop系统数据块中获取分配空间位置,上传合并的多个小文件队列时根据各小文件类型,分别归并到预设分类文件目录下。
优选的,还包括:步骤s400:用户读取小文件时,通过文件类型经过namenode获得小文件存储位置,并进行小文件读取。
该方法通过在存储时进行文件特性分类,当读取文件时,通过有效分类查找,更能得到查询效率的提升及准确命中率。
优选的,步骤s400中用户读取小文件步骤包括:用户输入文件信息后,对小文件中包含信息进行搜索,输出结果按包含用户输入信息量由多到少进行依序排列检索文件,并将包含用户输入信息最多的检索文件排列在文件队列前端,对所得多个检索文件进行预加载,输出小文件检索队列;
采用上述步骤进行文件读取,能根据用户输入信息,选取包含较多用户信息的结果,并将所得检索文件按包含用户信息的数量进行排列后,预加载后进行文件输出,系统通过实现预加载,减少用户与名字节点的交互以及名字节点与数据节点的访问,减少文件的访问次数并提供更好的用户体验,同时优化了文件的加载时间。
优选的,步骤s100中包括:对小文件队列中的小文件分别进行序列化处理后,得到小文件队列。
优选的,步骤s200中包括:如果判断临时存储区内小文件队列的总字节数是否大于128mb时所得结果为否,则判断临时存储区内各小文件队列存储时间是否达到存储时限,如果是,则对对临时存储区内多个小文件队列进行合并。
优选的,步骤s100中包括:对判断为非小文件的文件按照hadoop的常规方式存储到对应文件分类数据块中。
实现对不同大小的文件分类存储,充分利用hadoop系统对大文件的高效存储。
在一具体实施例中,该方法包括以下步骤:
1.1文件处理器
文件处理器主要用于分析上传文件的类型和大小。根据文件大小在系统中有处理超大文件和小文件两种处理方式。经过文件判断后,超大文件按照hadoop的常规方式存储到对应的分类中,小文件预存到小文件队列中,等待进行文件序列化。
1.2合并机
合并机主要用于存放需要合并的小文件。序列化文件要减少系统写入文件的次数,在系统处于闲时的情况下一次性将文件写入的文件系统中,这样可以使文件的写操作对系统影响最小,而且使查询节约时间。主要依据有两个,一个是命名节点的目录个数,另一个是上传文件合并时间。在进行文件上传时,在服务器上为文件合并队列设立一个临时的存储区,当文件达到时限时或者一个block大小时进行合并。
1.3文件读取
通过在存储时进行文件特性分类,当读取文件时,通过有效分类查找,更能得到查询效率的提升及准确命中率。文件结果的输出形式满足含有效信息的排列在前端,根据搜索到的相似度最高的文件是含有用户需要信息最多的文件,系统通过实现预加载,减少用户与名字节点的交互以及名字节点与数据节点的访问,减少文件的访问次数并提供更好的用户体验,同时优化了文件的加载时间。
用户存储文件时,首先经过文件处理器的判断,如果是小文件则需要进入到合并机的文件缓存队列等待系统合并,在系统合并时通过namenode获得分配空间的位置并归并到规定好的分类下。用户读取文件时通过文件的类型经过namenode获得文件存储位置。
参见图2,本申请的另一方面还提供了一种如上述方法的装置,包括:
文件处理器10,用于分析待上传文件的类型和字节数,判断待上传文件的字节数是否大于10mb,如果是,则预存入小文件队列中,如果否,则判断待上传文件字节数是否大于128mb,如果是,则标记为超大文件;
合并机20,用于在服务器上设置临时存储区,判断临时存储区内小文件队列的总字节数是否大于128mb,如果是,则对临时存储区内多个小文件队列进行合并;
文件读取模块30,用于通过namenode在hadoop系统各数据块中根据文件类型命名多个文件目录,通过namenode在hadoop系统数据块中获取分配空间位置,上传合并的多个小文件队列时根据各小文件类型,分别归并到预设分类文件目录下。
优选的,包括:文件检索模块,用于用户输入文件信息后,对小文件中包含信息进行搜索,输出结果按包含用户输入信息量由多到少进行依序排列检索文件,并将包含用户输入信息最多的检索文件排列在文件队列前端,对所得多个检索文件进行预加载,输出小文件检索队列。
优选的,文件处理器10包括:序列化模块,用于对小文件队列中的小文件分别进行序列化处理后,得到小文件队列。
优选的,存储时限模块,用于如果判断临时存储区内小文件队列的总字节数是否大于128mb时所得结果为否,则判断临时存储区内各小文件队列存储时间是否达到存储时限,如果是,则对对临时存储区内多个小文件队列进行合并。
优选的,超大文件存储模块,用于对判断为非小文件的文件按照hadoop的常规方式存储到对应文件分类数据块中。
在本说明书中所谈到的“一个实施例”、“另一个实施例”、“实施例”、“优选实施例”等,指的是结合该实施例描述的具体特征、结构或者特点包括在本申请概括性描述的至少一个实施例中。在说明书中多个地方出现同种表述不是一定指的是同一个实施例。进一步来说,结合任一实施例描述一个具体特征、结构或者特点时,所要主张的是结合其他实施例来实现这种特征、结构或者特点也落在本申请的范围内。
尽管这里参照本申请的多个解释性实施例对本申请进行了描述,但是,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本申请公开的原则范围和精神之内。更具体地说,在本申请公开说明书和权利要求的范围内,可以对主题组合布局的组成部件和/或布局进行多种变型和改进。除了对组成部件和/或布局进行的变形和改进外,对于本领域技术人员来说,其他的用途也将是明显的。
- 还没有人留言评论。精彩留言会获得点赞!