一种多源时空大数据深度融合的空气污染预测方法
1.本发明涉及一种空气污染预测方法,尤其涉及一种多源时空大数据深度融 合的空气污染预测方法。
背景技术:
2.研究表明空气污染对身体健康产生有害的影响,短期会导致哮喘、肺炎 等,长期对呼吸系统及循环系统产生有害影响,同肺癌、心血管疾病紧密相 关,也会对孕妇及儿童发育产生不利影响。在经济及科技不断发展的今天,如 何监测并有效地减少空气污染是当前重要的环境问题。当前,虽然许多地区都 设置有空气污染监测站点,用于监测空气污染水平;但空气污染监测站点整体 设置数量有限,有限的监测数据对于区域及人口时空分异大的实际情况是远远 不够的,如何根据有限的监测数据准确地反演空气污染物地面时空分布情况, 对于空气污染的监控是必要且重要的。
3.根据测量数据反演未抽样地点的空气污染浓度,最简单的就是线性回归模 型及空间插值如kriging即克里格方法,但是这不能很好地建模空气污染物浓度 同协变量之间的复杂关系,所以非线性时空建模是反演空气污染浓度时空变化 的主要方法。交通作为空气污染主要的排放来源之一,也逐渐被提取用于空气 污染浓度的时空变化的建模之中。近年以来,遥感技术也逐渐用于提取重要的 空气污染协变量,如从modis(moderate
‑
resolution imaging spectroradiometer) 卫星传感器提取气溶胶光学深度系数(aerosol optical depth,简称aod),可以从 aod反演pm
10
(fine particulate matter with aerodynamic diameter smaller than 10 μm)及pm
2.5
(fine particulate matter with aerodynamic diameter smaller than 2.5μm) 浓度。而从ozone monitoring instrument(omi)传感器aura提取的o3(ozone)及no2(nitrogen dioxide),可用于反演地面空气污染物o3及no2的时空变化情况。 但卫星数据最大的问题是由于云覆盖、地面的高反射率及传感器本身的缺陷, 会导致有大量的缺失值产生,从而严重影响卫星产品的应用。
4.为解决卫星数据的缺失问题,现有技术设计了基于概化累加模型 (generalized additive model,简称gam)的缺值插补的非线性方法,采用基于 geos 5
‑
fp的气象数据、土地利用、cmaq(community multiscale airquality)模拟数据等插补完整中国长三角地区的卫星气溶胶数据maiac (multi
‑
angle implementation ofatmospheric correction)aod,然后用于估算 地面pm
2.5
的浓度;也有采用了类似的变量,通过普通的前馈神经网络进行缺值 插补。其他的一些方法还包括了采用均值、最近邻或其他粗分辨率如cmaq的 模拟aod代替缺失值。虽然现有技术已采用了非线性方法插补缺失值,比简单 的替代方法要好,但是他们的缺值插补方法是基于粗分辨率的气象数据(分辨 率25km x 25km),同反演的地面空气污染浓度的分辨率(1x1km2)差距过大, 这时导致估计结果偏差原因之一。
5.由于影响空气污染的高分辨率的重要气象参数(空气温度、相对湿度、风 速及气压等)缺乏,将会导致在缺乏高分辨率气象参数情况下采用卫星与/或 其他模拟的气象变量反演地面空气污染物浓度的估计偏差。现有技术提出了融 合多源遥感信息与气候环境
的综合性气象环境评估方法,其方法基于较粗的卫 星分辨率,且只是反演了季节性的空气污染浓度分布并进行评估,缺乏高时间 分辨率的结果。现有技术还提出了一种大气颗粒物星地综合定量遥感融合的反 演方法,该方法没有对卫星气溶胶的缺失进行有效的处理,会导致相当多的时 空点由于卫星数据的缺乏无法进行反演;而反演采用的气象等参数分辨率也较 粗。对于采用多源遥感数据融合,基于geos
‑
fp(goddard earth observingsystem
‑
forward processing)系列数反演pm
2.5
污染物,同样其用于反演的地面分 辨率较粗,难以反映地面的在细尺度下的变化情况。以及现有的深度森林算法 估计城市模型估算,这种方法会受到基于树学习模型的输入离散数据的限制, 在样本数较少时会导致表面建模不连续性。虽然目前已有采用深度学习的cnn 等进行空气污染的地表参数重构,但由于空气污染同影响因素的复杂非线性关 系,难以采用卷积网取得理想的结果,且过深的网络会导致梯度消失问题,影 响最后的估计结果。现有技术还提出基于空气质量数据与图像实现多源异构的 融合的pm
2.5
预测模型,该方法需要采集照片估算pm
2.5
的浓度,评估结果受到环 境散射光线的影响,估计精度有限。
技术实现要素:
6.为了解决上述技术所存在的不足之处,本发明提供了一种多源时空大数据 深度融合的空气污染预测方法。
7.为了解决以上技术问题,本发明采用的技术方案是:一种多源时空大数据 深度融合的空气污染预测方法,包括以下步骤:
8.步骤一、采集多源大数据;
9.步骤二、对步骤一采集到的数据进行预处理;
10.步骤三、高时空分辨率气象数据的插补,反演地面统一坐标的地面气象参 数;
11.步骤四、气溶胶参数、no2遥感参数缺失反演及升尺度;
12.步骤五、交通变量、土地利用变量、社会经济及poi变量、时空变异变量 的提取;
13.步骤六、将各类时空大数据的协变量数据进行时空融合,形成统一尺度及 空间坐标的数据集;
14.步骤七、反演空气污染浓度地表参数;
15.步骤八、精度验证及评估;
16.步骤九、验证达标与否;如若达标,进入步骤十一;如若不达标,进入步 骤十;
17.步骤十、对于不合理或不达标预测,调整预测协变量、超参数及限制性条 件循环训练,直至得到合理的模型及预测;
18.步骤十一、结果输出。
19.进一步地,步骤二中,数据预处理包括对数据进行质量控制、时空融合及 格式转换;质量控制是按照有效数据阈值,或者质量标记对数据进行清理,删 除无效数据;时空融合是对多源大数据在时空上进行融合,取得统一的目标时 空分辨率;格式转换是将格式不一致的数据,转换成统一的高分空间栅格数 据。
20.进一步地,步骤三中,采用一体化的插值方法进行高时空分辨率气象数据 的插补,汇总气象数据中的特征协变量,建立目标变量统一且引入注意力层的 全残差深度网络模型;对各特征协变量加权,设计多变量输出层,采用多个目 标变量同时输出,便于模型参
数间共享;在建模过程中,令特征的注意力权重 输入为:c={c
i
},并由此对输入的特征进行加权:
21.满足足
22.其中,x={x
i
}为特征值矢量输入,x
i
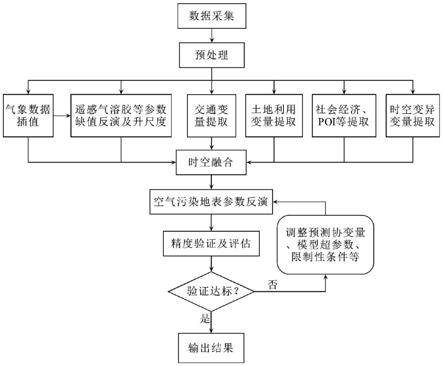
则为第i个特征,c={c
i
}为特征值矢 量的注意力权重,c
i
为第i个特征的注意力权重系数;为被注意力权重 加权之后的特征输出,
°
代表矩阵元素相乘;f为特征的个数;
23.采用softmax层来实现注意力层,以满足式2的限制条件:
[0024][0025]
其中,e
i
为注意力层的第i单元的输入,c
i
为第i个单元的权重输出,exp(
…
) 为取指数函数;j为特征的索引,e
j
为注意力层的j索引的输入,f为特征的个 数;注意力的权重系数通过模型优化自适应求解;
[0026]
多变量输出的损失函数为:
[0027][0028]
其中,n为样本数,代表空气温度的损失,代表相对湿度的损 失,代表空气压强的损失,代表风速的损失;y
t
、y
r
、y
p
及y
w
分 别代表空气温度、相对湿度、压强及风速的正则化后的观察值,而而及分别代表空气温度、相对湿度、压强及风速的估 计值;θ
w,b
为网络模型的需要优化的参数集合,ω(θ
w,b
)则为参数集θ
w,b
的正 则化项,采用弹性网络进行正则化;
[0029]
最后,对目标变量结果进行反正则化,获得同原数据尺度一致的估计值。
[0030]
进一步地,引入全残差深度网络模型为基模型的聚集引导聚集建模,训练 多个基模型,计算各参数的均值及变差,获得更优的地面气象参数反演结果。
[0031]
进一步地,步骤四中,气溶胶参数指的是maiacaod,no2遥感参数指 的是omi
‑
no2,在步骤三生成的高分气象参数基础上,分别建立全残差深度网 络的aod及omi
‑
no2的缺值反演模型;在此缺值反演模型中引入注意力层,提 升重要协变量权重,以输入协变量+缺值需要插补的变量共同作为输出的目标 变量;
[0032]
再分别对maiacaod及omi
‑
no2建立缺值反演及升尺度模型,采用mse 作为目标损失函数:
[0033]
[0034]
其中,n为样本数,l
mse
表示采用均方误差的损失函数,y代表了地面空气 污染监测站点的观察的no2浓度,为地面高分辨率的尺度转换后得到 的地面的omi
‑
no2的代理变量,引入了坡度因子s及截距a,通过其转换成地面no2,使其同地面之间的观察值误差最低,从而优化参数得到高分辨率的尺度 化结果,对于缺失值直接采用尺度转化模型输入协变量即可得到缺失值的估 计。
[0035]
进一步地,步骤五中,交通变量的提取采用最近邻提取或缓冲区分析法; 缓冲区分析法计算缓冲区内主干道的长度,通过敏感性分析,选取最优缓冲距 离作为最后距离:
[0036][0037]
其中,d
*
代表最优缓冲距离,r为相关系数函数,rlen(d
i
)代表以d
i
为缓冲 距离时统计缓冲区内的道路长度,x则为目标点空气污染物的浓度,i为测试的 缓冲距离索引;
[0038]
土地利用变量的提取通过计算一定缓冲区范围内土地利用所占的面积比 例,将此比例作为污染来源的代理变量;作敏感性分析,确定最优的缓冲距 离:
[0039][0040]
其中,d
*
代表最优缓冲距离,r为相关系数函数,lprop(d
i
)代表以d
i
为缓冲 距离时统计缓冲区内的土地利用面积比例,x则为目标点空气污染物的浓度,i 为测试的缓冲距离索引;
[0041]
社会经济指人口密度及gdp,通过空间叠加分析获得样本相应的人口密度 及gdp;poi数据则先选择污染源相关的兴趣点,计算到最近的poi的距离;
[0042]
时空变异变量的提取包括空间变量、时间变量的提取两方面,其中,空间 变量包括高程、坐标及其派生变量,用于捕捉空间变异信息;时间变量包括多 尺度时间信息,包括年
‑
天、月份、星期、及年份。
[0043]
进一步地,步骤七中,基模型采用引入注意力层的全残差深度网络模型, 输入变量包括步骤一至步骤五获得的参数数据,设输入变量个数为d个,注意 力节点也为d个,对关键变量进行加权,输出变量为m个,即需要估计的变量 个数;同时,对输出设定了限制性条件,通过限制性优化方法,取得符合限制 性条件的解;输出的损失函数采用下式:
[0044][0045][0046][0047]
其中,l(θ
w,b
)代表了网络参数集θ
w,b
的损失函数,n为样本数,及 分别
代表no2及pm
2.5
正则化后的观察值,而及分别代 表了针对输入协变量集x的no2及pm
2.5
的网络预测值,及分别代表no2及pm
2.5
的mse的损失函数,ω(θ
w,b
)则为参数集θ
w,b
的正则化项,同理,采用 弹性网络实现正则化;式9及式10定义了no2及pm
2.5
的网络预测值需要满足的 条件,其中,及分别表示no2的取值的最小值与最大值,及 分别表示pm
2.5
的取值的最小值与最大值;
[0048]
将二污染物合在一起在一个网络中输出,采用bootstrap重抽样方法,对样 本及特征进行多次重复抽样,得到不同的样本及特征变量集,对这些不同的样 本集合对全残差深度模型结构进行样本数随机化,以获得差异较大的基模型, 将这些样本分别训练这些基模型,最后将训练的模型分别预测,预测结果反正 则化得到no2与pm
2.5
的估计浓度,统计多个模型预测浓度得到估计平均值及其 变差。
[0049]
进一步地,步骤八中,采用独立性验证方法对聚集引导得到的结果进行精 度验证及结果评估。
[0050]
进一步地,步骤九中,验证总体的预测目标是否符合要求,验证各个协变 量对总的预测解释是否合理。
[0051]
进一步地,步骤十一中,对于得到的合理的优化的训练模型及超参数,保 存相应的模型及参数,并将合理的预测结果输出,供下一步的应用使用。
[0052]
本发明公开了一种多源时空大数据深度融合的空气污染预测方法,具有以 下有益效果:1)考虑的时空大数据更全面,影响因子从基本因素扩展到污染 源因素,覆盖的时空范围更广泛,时空分辨率较高,这些大样本及其协变量, 能充分代表研究对象的总体情况,充分考虑了影响空气污染物浓度分布的各要 素;2)不受粗分辨率气象变量对预测的影响,通过采用地面实测气象数据建 立高精度高分辨率的气象地表参数反演模型,更准确拟合高分辨率下地表气象 因子的时空分布,为后续的遥感参数及空气污染物浓度建模奠定基础;3)基 于气象参数反演结果建立高效的遥感气溶胶缺值插补及omi
‑
no2的升尺度模 型,获得全时空覆盖的高分辨率的遥感参数;4)采用最新的融合注意力的全 残差深度学习时空模型,充分输入变量的值范围,采用共享参数输出,高效的 限制性优化学习可使得本专利在高分辨率的气象地表参数估计、卫星参数缺值 插补及空气污染反演建模取得高的精度。
[0053]
综合以上优点,本专利同现有方法相比时空覆盖度大,考虑的影响要素更 全面,使用了新的深度学习建模技术,通过高级的优化技术提高气象数据的栅 格建模及卫星参数的插补,从而使得本发明取得了较高的测试精度、较高的泛 化性,而本发明也通过结果验证及循环的建模机制减少估计偏差,提高实际应 用的效率。
附图说明
[0054]
图1为本发明的流程示意图。
[0055]
图2为本发明引入注意力机制的全残差深度网络的天模型结构图。
[0056]
图3为本发明实施例预测的no2栅格图。
[0057]
图4为本发明实施例预测的pm
2.5
栅格图。
具体实施方式
[0058]
下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0059]
现有的空气污染物浓度时空估算方法,基于协变量采用回归模型估计,但 采用的气象协变量空间分辨率有限,遥感数据存在大量缺失值,导致了时空不 能全覆盖;而捕捉污染物的来源及其时空分布的协变量有限;许多方法对训练 模型采用黑箱模型,缺乏有效性验证及不确定性度量,无对预测结果的纠偏机 制。在此背景下,本发明提出了一种多源时空大数据深度融合的空气污染预测 方法,采集了气象数据、卫星遥感气溶胶数据、同化数据、交通、土地利用等 多源大数据,设计了一体化的高精度高分辨率气象及空气污染的反演全残差深 度学习方法,通过学习
‑
解译
‑
提高循环式的反演方法,获得更为可靠的空气污 染的地表参数的反演结果。
[0060]
如图1所示为本发明的流程示意图,主要包括如下步骤:
[0061]
步骤一、采集多源大数据;
[0062]
采集的多源大数据包括几个方面,如每小时空气污染物(pm
2.5
,pm
10
,so
2 (sulfur dioxide),no2,o3,co(carbon monoxide),aqi(air quality index)数 据;气象测量数据包括:温度、相对湿度、气压、风速;气象再分析数据:行 星边界层高度(planetary boundary layer height,pblh)、云比例、大气臭氧总 量,地表气温、气压、相对湿度和风速,以及26种各种污染来源的merra2 gmi(the modern
‑
era retrospective analysis for research and applications, version 2,the global modeling initiative)同化数据(表1,来源:https://acd
‑ꢀ
ext.gsfc.nasa.gov/projects/geosccm/merra2gmi);交通数据:交通路网;土地 利用:开源的数据;社会经济:poi、gdp(gross domestic product)、人口密 度;其他数据:中国地区1km数字高程模型的高程、x及y坐标、aeronet (aerosol robotic network)aod地面验证数据。
[0063]
表1来自merra2 gmi同化数据拟合的污染物表面栅格相关变量列表
[0064][0065]
步骤二、对步骤一采集到的数据进行预处理;
[0066]
数据预处理主要包括对数据进行质量控制、时空融合及格式转换等;质量 控制是按照有效数据阈值,或者质量标记对数据进行清理,删除无效数据;采 用统计标注,删除一些对建模无意义的孤立点,采用阈值定义:
[0067]
x∈[q1(x)
‑
5*iqr(x),q3(x)+5*iqr(x)]
ꢀꢀ
式1
[0068]
其中,x∈x={x
i
(i=1,...,n)},n为数据总数,q1(x)与q3(x)分别表示对数 据集取第一及第三分位数,而iqr(x)表示对数据集x取四分位间距(interquartilerange)。
[0069]
时空融合是对多源大数据在时空上进行融合,以便取得统一的目标时空分 辨率;具体而言,对空间覆盖率范围及分辨率不一致的,将采取空间分析的系 列操作,包括合并、裁切、重投影、重采样及平均等统一空间坐标及空间分辨 率;对时间分辨率不一样的,采样双线性插值或平均化等统一空间分辨率。
[0070]
格式转换是将格式不一致的(如文本格式),转换成统一的高分空间栅格 数据。
[0071]
步骤三、高时空分辨率的气象数据的插补,反演地面统一坐标的地面气象 参数;
[0072]
采用地面气象监测点,结合地面坐标、高程、气象同化数据(pblh、各 气象要素)等反演地面统一坐标的地面气象参数。采样一体化的插值方法进行 高分气象数据插补,考虑到气象要素间相互影响,设计了一体化全残差气象要 素集成化反演方法。
[0073]
模型的输入包括了气象同化数据的气温、风速(包括地面、2米及10米的 高东西及南北向风速)、相对湿度、气压、臭氧、pblh,以及地面坐标系列 变量,包括x、y、x2、y2及xy,高程,总计输入16个变量,输出为地面需要反演 的气温、气压、相对湿度及风速4个目标变量,同地面的监测站点的四个变量 相对应。基于全残差深度网络模型,引入了注意力层,对各
特征协变量加权, 提高重要协变量的预测力,设计多变量输出层(4个目标变量同时输出)。由 于气温、气压、相对湿度及风速间相互影响,故采用多目标变量输出便于模型 参数间共享,可减少过拟合。模型结构框架参见图2(d=16,m=4)。注意力 权重的引入主要是为了加权输入特征,提高一些关键特征在预测中的重要性, 是一种自适应优化的建模方法。
[0074]
在建模过程中,令特征的注意力权重输入为:c={c
i
},并由此对输入的特 征进行加权:
[0075]
满足足
[0076]
其中,x={x
i
}为特征值矢量输入,x
i
则为第i个特征,c={c
i
}为特征值矢 量的注意力权重,c
i
为第i个特征的注意力权重系数;为被注意力权重 加权之后的特征输出,
°
代表矩阵元素相乘;f为特征的个数;
[0077]
采用softmax层来实现注意力层,以满足式2的限制条件:
[0078][0079]
其中,e
i
为注意力层的第i单元的输入,c
i
为第i个单元的权重输出,exp(
…
) 为取指数函数;j为特征的索引,e
j
为注意力层的j索引的输入,e
j
与e
i
一样,均 为注意力层的输入,不过j索引表示对所有的e
j
;f为特征的个数;注意力的权 重系数通过模型优化自适应求解;
[0080]
多变量输出的损失函数为:
[0081][0082]
其中,n为样本数,代表空气温度的损失,代表相对湿度的损 失,代表空气压强的损失,代表风速的损失;y
t
、y
r
、y
p
及y
w
分 别代表空气温度、相对湿度、压强及风速的正则化后的观察值,而而及分别代表空气温度、相对湿度、压强及风速的估 计值;θ
w,b
为网络模型的需要优化的参数集合,ω(θ
w,b
)则为参数集θ
w,b
的正 则化项,采用弹性网络进行正则化;
[0083]
最后,对目标变量结果进行反正则化,获得同原数据尺度一致的估计值。
[0084]
同时,本模型通过随机梯度下降法获得最优参数,并通过一个模型估计得 到了4个气象参数的估计值,提高了网络参数的共享,满足测试精度的同时提 高了计算效率。
[0085]
为进一步提高参数估计的精准性,引入全残差深度网络模型为基模型的聚 集引导聚集建模,训练多个(100个)基模型,计算各参数的均值及变差,提 高模型的泛化性及气象参数预测的稳定性,获得更优的地面气象参数反演结 果。
[0086]
步骤四、气溶胶参数、no2遥感参数缺失反演及升尺度;
[0087]
气溶胶参数指的是maiac aod,采用了高分的maiac aod来作为pm
2.5
预测主因子之一;no2遥感参数指的是omi
‑
no2,采用了omi
‑
no2来作为地面 的no2的主因子变量之一。
[0088]
对于maiac aod及omi
‑
no2存在大量的缺失值,缺失值达到50%以上。在 步骤三生成的高分气象参数基础上,加上了气象同化数据的较粗分辨率的协变 量(包括背景aod或no2、pblh、云比例)、坐标(x与y)及其派生变量 (x2,y2及xy)及高程总共9个变量,分别建立全残差深度网络的aod及omi
‑ꢀ
no2的缺值反演模型,采用了类似图2的网络结构;在此缺值反演模型基础上, 同样按照注意力机制引入注意力层,提升重要协变量权重,而在输出变量方 面,以输入协变量+缺值需要插补的变量(即10个输出变量)共同作为输出的 目标变量;之所以加入输入变量也作为输出变量,主要是加强变量间的数共 享,对于采用点缺值建模样本而言样本数足够大,将输入也作为输出一部分同 目标变量一起输出,起到了参数正则化效果,可取得较好的拟合精度。
[0089]
同时,本发明分别对maiac aod及omi
‑
no2建立缺值反演及升尺度模 型;在升尺度方面,直接考虑了升尺度后的omi
‑
no2同地面no2之间的相关 性,采集连续3天的样本合成训练及测试样本,训练全残差的深度网络,以提 高同目标变量代理变量即地面no2间的相关性为损失函数,但相关系数作为损 失函数训练可能不能优化,采用了他们之间mse作为目标损失函数:
[0090][0091]
其中,n为样本数,l
mse
表示采用均方误差(mean square error,即mse) 的损失函数,y代表了地面空气污染监测站点的观察的no2浓度,为地 面高分辨率的尺度转换后得到的地面的omi
‑
no2的代理变量,引入了坡度因子 s及截距a,通过其转换成地面no2,使其同地面之间的观察值误差最低,从而 优化参数得到高分辨率的尺度化结果,对于缺失值直接采用尺度转化模型输入 协变量即可得到缺失值的估计。
[0092]
步骤五、交通变量、土地利用变量、社会经济及poi变量、时空变异变量 的提取;
[0093]
交通变量提取:地面空气污染物如no2同交通紧密相关,需要提取交通相 关的变量。由于具体交通流量信息很难获取,本发明基于主要交通干道,包括 各级高速公路、主要道路提取2个关键的交通要素:到最近交通主干道的距 离、一定缓冲距离范围内道路的长度。对前者,采用最近邻提取;而对于后 者,采用缓冲区分析方法,计算缓冲区内交通主干道的长度。通过敏感性分 析,即计算一系列的距离缓冲区内道路长度同现有污染物no2浓度间的相关 性,选取最优缓冲距离作为最后距离:
[0094][0095]
其中,d
*
代表最优缓冲距离,r为相关系数函数,rlen(d
i
)代表以d
i
为缓冲 距离时统计缓冲区内的道路长度,x则为目标点空气污染物的浓度,i为测试的 缓冲距离索引。
[0096]
土地利用变量提取:土地利用也提供了主要的排放源信息。本发明将污染 来源相关的数据划分为一类,通过计算一定缓冲区范围内土地利用所占的面积 比例,将此比例作为污染来源的代理变量;同交通变量提取类似,作敏感性分 析,确定最优的缓冲距离:
[0097][0098]
其中,d
*
代表最优缓冲距离,r为相关系数函数,lprop(d
i
)代表以d
i
为缓冲 距离时统计缓冲区内的土地利用面积比例,x则为目标点空气污染物的浓度,i 为测试的缓冲距离索引。
[0099]
社会经济及poi提取:此处的社会经济指人口密度及gdp,通过空间叠加 分析获得样本相应的人口密度及gdp,通常更高的gdp意味着更高的排放源; poi数据则先选择污染源相关的兴趣点,计算到最近的poi的距离。
[0100]
时空变异变量提取:包括空间变量、时间变量的提取两大方面,其中,空 间变量包括高程、坐标及其派生变量,即x、y、x2、y2及xy,用于捕捉空间变异 信息;时间变量包括多尺度时间信息,包括年
‑
天、月份、星期、及年份,
ꢀ“
年
‑
天”捕捉天尺度的时间变化,“月份”捕捉粗尺度季节性变化,“星 期”用于捕捉是否周末信息,“年份”用于捕捉年纪变化。
[0101]
步骤六、将各类时空大数据的协变量数据进行时空融合,形成统一尺度及 空间坐标的数据集;
[0102]
如数据在粗细尺度不一致需采用线性插值或非线性的升尺度方法统一尺 度,对于空间变量(如坐标),需要衍生到各个时间点;对于多尺度时间变量 (如年天),也需要衍生到各个空间点;最后形成统一的数据集。
[0103]
步骤七、反演空气污染浓度地表参数;
[0104]
输入变量包括步骤一至步骤五获得的参数数据,包括气象反演参数4个 (温度、气压、相对湿度及风速),卫星参数2个(aod及omi
‑
no2),气象 同化参数30个(pblh、背景气溶胶、背景o3、背景no2、及其他如表1所列的 26个污染源数据),交通变量2个,土地利用变量1个,社会经济变量2个,poi 变量1个,空间变量6个,多尺度时间变量4个,总计达到52个变量。变异模型 的结构如图2所示(d=52,m=2),基模型采用包括注意力层的全残差深度网 络模型,输入变量个数d=52个,注意力节点也为52个,对关键变量进行加权, 输出变量为m个,即需要估计的变量个数;例如:估计pm
2.5
及no2,则m=2。 此处同时对输出设定了限制性条件,通过限制性优化方法,尽量取得符合限制 性条件的解。输出的损失函数可以采用下式:
[0105][0106][0107][0108]
其中,l(θ
w,b
)代表了网络参数集θ
w,b
的损失函数,n为样本数,及 分别代表no2及pm
2.5
正则化后的观察值,而及分别代 表了针对输入协变量
集x的no2及pm
2.5
的网络预测值,及分别代表no2及pm
2.5
的mse的损失函数,ω(θ
w,b
)则为参数集θ
w,b
的正则化项,同理,采用 弹性网络实现正则化;式9及式10定义了no2及pm
2.5
的网络预测值需要满足的 条件,即需要分别落在在区间及之内,其中及分别表示no2的取值的最小值与最大值,及分别表示pm
2.5
的 取值的最小值与最大值;
[0109]
将二污染物合在一起在一个网络中输出,主要考虑pm
2.5
与no2关系密切, 派生出no2的交通污染也是pm
2.5
的来源之一,将二者同时作为一个模型输出, 有助于网络参数共享,减少过拟合,提高泛化性。
[0110]
对于加入的限制性条件,采用投影梯度下降进行求解,虽不能保证全局最 优解(深度模型不是一个凸模型),但局部最优解也基本满足要求。
[0111]
为进一步提高反演稳定性,采用bootstrap重抽样方法,对样本及52个特征 进行多次(100次)重复抽样,得到100个不同的样本及特征变量集,对这些不 同的样本集合对全残差深度模型结构进行样本数随机化,以获得差异较大的基 模型,将这些样本分别训练这些基模型,最后将训练的模型分别预测,将多个 模型预测结果计算平均及变差,将结果反正则化得到no2与pm
2.5
的估计浓度。
[0112]
步骤八、精度验证及评估;
[0113]
采用独立性验证方法对聚集引导得到的结果进行精度验证及结果评估。主 是对训练完成的模型对独立性样本计算r2及rmse,获得精度评价标准。采用 shap(shapley additive explanations)方法对模型解译,计算各变量对预测贡 献。
[0114]
步骤九、验证达标与否;
[0115]
验证总体的预测目标是否符合要求,验证各个协变量对总的预测解释是否 合理。如模型解译表明交通路线促进污染物的下降说明是不合常理的,需要调 整模型进行重新建模训练,进入步骤十,否则保存模型,进入到步骤十一。
[0116]
步骤十、对于不合理或不达标预测,调整预测协变量、超参数及限制性条 件循环训练,直至得到合理的模型及预测;
[0117]
检查预测协变量提取是否有问题,是否真正反应两变量间关系,对模型训 练的超参数进行调整,包括学习率、训练的小批次样本大小(mini batchsize)、网络的深度及节点数,采用启发式优化搜索方法,获取最优超参数进 入第七步进行下一步,循环直至得到合理的模型及预测。
[0118]
步骤十一、结果输出。
[0119]
对于得到的合理的优化的训练模型及超参数,保存相应的模型及参数,便 于以后的空气污染物地表浓度的反演及应用;并将合理的预测结果输出,供下 一步的应用使用。
[0120]
由此,对于本发明所公开的一种多源时空大数据深度融合的空气污染预测 方法,具有以下技术优势:
[0121]
1)涵盖了大的研究区域及多年的时段,采集了多种时空大数据。同其他 同类方法比较,本专利空间及时间覆盖范围宽,样本采集充足,能充分体现建 模总体的时空变化;采集的要素全面,包括气象测量、气象及空气污染同化数 据、卫星遥感气溶胶、高程、交通、土
地利用、poi、社会经济及坐标等多达 52个变量,尤其是采集了nasa的多达26种污染源栅格背景同化数据。宽泛的 时空覆盖度及充足的预测因子,可以充分捕捉空气污染物的来源及时空分布, 大幅减少预测时的偏差。
[0122]
2)高精度高分辨率气象地面参数反演,作为影响空气污染时空分布的关 键参数,现有方法通常使用了较粗分辨率的背景气象参数,没有经过地面测量 数据的矫正,空间分辨率过于粗糙,难以反映高空间分辨率如1km下的气象参 数的尺度变化,本发明采集了地面实测气象资料,用气象再分析背景数据、坐 标、高程等数据进行反演,获得了高精度高时空分辨率的气象数据,极大地提 高了空气污染时空建模的效果。
[0123]
3)卫星气溶胶等数据的缺值插补,针对卫星气溶胶等参数大量的缺失 值,许多现有方法无法直接处理卫星缺失值,采用最近的值或均值替代,有的 方法采用了插补的非线性回归,但精度有限。本发明依托高精度高分辨率的气 象数据,加上背景同化数据、坐标及高程等,实现了高精度的全残差深度网络 缺值反演模型,取得了高精度的反演结果。对于粗尺度缺失的关键变量,采用 地面代理变量优化,取得了升尺度的较好的结果。同现有方法相比,本发明插 补完成了可靠的卫星气溶胶等数据,在空气污染地表参数反演时无需担心缺失 值,可实现时空全覆盖的估计。
[0124]
4)在空气污染物浓度地表参数反演的建模方法进行了改进,同现有非线 性方法相比,在全残差深度模型基础上,加入了注意力层提高重要影响因子的 权重,采用了多变量输出方式使得变量之间实现参数共享,减少模型训练过程 的过拟合,加入限制性条件,通过限制优化方法求得更符合预期的解。因此本 发明采用的的全残差方法有效解决了深度网络导致的梯度消失问题,加入注意 力层加强重要因子的权重,多变量输出及限制性优化提高计算效率同时取得更 为合理的解。此方法也高效地用到气象参数重构及遥感参数缺值反演之中去。
[0125]
5)注重对预测结果的解译及有效性验证,采用了可解释的机器学习技术 提取各影响因子对预测的贡献,对于不合理的预测进行干预,通过模型的回调 及再训练,消除预测结果中的偏差,更全面地获得预测的预测结果。同现有 的方法相比,本发明可以分析结果偏差的原由,通过循环纠偏过程,提高模型 应用的有效性。
[0126]
【实施例】
[0127]
下面结合具体的实施例,对本发明所公开的多源时空大数据深度融合的空 气污染预测方法做进一步详细的介绍。
[0128]
本实施例以覆盖中国大陆地区的空间范围,时间覆盖2015
‑
2018年4年,目 标空间分辨率为1x1km2,为时间分辨率为天,以此时空大数据地表参数反演中 国大陆局部地区的时空污染地表浓度。
[0129]
步骤一、数据采集:采集覆盖中国大陆地区的高时空分辨率时空大数据集 (区域:中国大陆;时间:2015
‑
2018年;空间分辨率1x1km;时间分辨率: 天)。具体包括:
[0130]
地面测量数据:环境监测站点的空气污染数据从数据共享网站 https://quotsoft.net/air/下载得到;从中国气象数据网下载覆盖中国大陆地区的气 象参数(包括温度、相对湿度、气压、风速)测量值;
[0131]
气溶胶及omi
‑
no2数据:从modis land team网站获取了maiac aod的 气溶胶光学深度数据(空间分辨率:1x1km,时间分辨率:天);从 https://aeronet.gsfc.nasa.gov网站
获得aeronet aod数据集,用于验证maiac aod缺值反演精度;从earth observing system,aura网站获得了omi
‑
no2数据 (空间分辨率:0.25
°
lonx0.25
°
lat,时间分辨率:天);
[0132]
气象参数同化背景数据:从全球土地数据同化系统(global land data assimilation system,gldas)获得了粗分辨率的气象同化的数据(温度、相 对湿度、风速;空间分辨率:0.25
°
lon x0.25
°
lat;时间分辨率:3小时);从戈 达德地球观测系统
‑
前向处理(goddard earth observing system
‑
forward processing,geos
‑
fp)获得臭氧及pblh数据(空间分辨率:0.25
°
lon x0.25
°
lat;时间分辨率:3小时);从merra2 gmi同化数据源获得了26种污 染来源的栅格数据(表1;空间分辨率:0.625
°
(经度)x 0.5
°
(维度);时间 分辨率:3小时);
[0133]
高程数据来自资源环境数据云平台的500m空间分辨率的dem数据,其数 据源自对航天飞机雷达地形测绘任务(shuttle radar topography mission, srtm)重采样获得;
[0134]
交通、土地利用及poi,来自于openstreet网站;
[0135]
gdp(gross domestic product)及人口密度:gdp来自于资源环境科学与 数据中心;人口密度来自于国家地球系统科学数据中心。
[0136]
坐标数据x,y,x2,y2,xy根据生成的目标坐标网格中心点直接提取,目标 网格采用1954北京坐标系,空间分辨率为1x1km2。
[0137]
步骤二、数据预处理:先对采集的数据进行预处理,包括删除无效的测量 数据,如根据maiac aod提供的质量控制标记确定无效的像素值,根据阈值 定义删除极值点;之后,进行时空融合,通过合并、裁切、重投影、重采样及 平均等多种操作统一各类来源数据的空间坐标及空间分辨率。
[0138]
步骤三、高精度高分辨率的气象栅格数据的反演。根据采集得到的主要气 象测量数据及气象同化数据,总共汇总得到16个协变量,建立气温、气压、相 对湿度及风速多变量输出的统一的引入了注意力层的深度残差回归网络,训练 100个基模型,最后得到预测输出。
[0139]
表2报告各个气象要素的测试精度(r2及rmse),高精度的测试结果 (r2≥0.81)表明一体化的全残差深度网络取得了较好的反演效果。全残差深度 模型均采用了基于tensorflow的keras建立模型,基于python语言实现。而训练 模型采用的节点数依次是[16,96,64,32,16,8,16,32,64,96,16,4],其中包括16 个输入,4个目标变量的输出(包括温度、相对湿度、风速、气压),选取的 训练超参数:批学习样本大小为1024,初始的学习率为0.1,采用了adam的梯 度下降法优化方法。
[0140]
表2高分辨率的气象参数反演的测试精度
[0141][0142]
步骤四、气溶胶参数、no2遥感参数缺失反演及升尺度;气溶胶maiacaod虽然提供了同目标坐标一致的空间分辨率,即1x1km2,但包含大量的缺失 值。采用了气象同化数据
(背景aod、pblh、云比例)、坐标及其派生变 量、高程共9个输入变量,建立引入注意力机制的全残差深度网络的天模型 (图2),反演maiac aod同这些输入参数间的关系,最后得到缺值插补的天 模型,采用训练得到的天模型,完成缺值插补的功能,总计每天一个模型,总 结从2015
‑
2018年建立了1461个模型,平均的r2为0.90,最小的为测试r2为 0.76。对于omi
‑
no2,有大量的缺失值且分辨率较粗,如前所述,采用地面实 测的空气污染物no2作为矫正变量,以提高二者间相关性为目标,建立引入注 意力机制的全残差深度网络升尺度模型,采用可靠的空间点得到训练及测试样 本,训练模型,将训练后的模型进行升尺度,同时进行缺值插补,得到与目标 尺度一致的插补完成的omi
‑
no2地面代理变量值,同理建立了1461个升尺度模 型,获得平均的r2为0.88,最小的r2为0.74,表明本升尺度方法取得了理想的 效果,同时提高了omi
‑
no2地面代理变量同预测目标即地面no2之间的相关关 系。训练的网络模型采用的节点数依次是[9,128,64,32,16,8,16,32,64,128, 15,10],其中包括9个输入,10个输出中包括原9个输入加1个目标变量 (maiac aod或omi
‑
no2),选取的训练超参数:批学习样本大小为1024, 初始的学习率为0.1,采用了adam的梯度下降法优化方法。
[0143]
步骤五、交通变量的提取,用于提取的道路包括国道及主高速公路,其他 次要的道路未包括在内。提取最近的距离采用基于kd树实现最近邻的快速检 索,采用python的scipy包的ckdtree实现快速的交通变量的最近邻提取并计算 最近邻的距离。统计一定缓冲距离内的国道或高速公路的道路长度,采用了r 统计软件的包rgeos的gbuffer函数及raster包的intersect联合实现一定距离缓冲区 国道及主干道路的长度。采用1公里到10公里(间隔1公里)的敏感性分析,得 到当缓冲区距离取10公里时取得道路长度同地面no2最大的相关系数0.51,因 此取10公里作为最佳的缓冲区距离。
[0144]
步骤六、土地利用变量的提取,选取了居民地、工业用地、商业用地及垃 圾处理场4类用地,计算一定缓冲范围内这些用地面积占总面积的比例。采用 了类似步骤五中提取交通距离类似的函数,敏感性分析表明10km的缓冲距离可 取得这些土地利用同地面no2最大的相关性0.47。
[0145]
步骤七、社会经济及poi提取,社会经济即gdp及人口密度直接是1公里栅 格数据,只需要作简单坐标统一后叠加到协变量数据集中。而对poi,提取了 污水处理厂、垃圾处理厂、废旧玻璃处理厂及废纸处理场等的poi,采用 ckdtree计算目标点到poi的最短距离作为poi的协变量。
[0146]
步骤八、时空变异变量提取,提取坐标数据,取每个栅格点的中心点的坐 标即x与y,以及其派生变量(x2,y2及xy),根据坐标提取高程数据;对时间变 量提取年
‑
天、月份、星期及年份4个多尺度时间变量信息。
[0147]
步骤九、空气污染物浓度地表参数反演,由以上九个步骤获得时空一致的 数据集,建立注意力机制的全残差深度时空网络,如图2所示,其中输入变量 包括反演的高分气象参数4个、卫星变量2个、气象同化参数30个、交通变量2 个、土地利用变量1个、社会经济2个、poi变量1个、空间变量6个、多尺度时 间变量4个,总计52个输入变量,输出包括取log对数的pm
2.5
及no2,所有数据 均经过standard scalar正则化处理,预测结果最后反正则化及取指数还原原数据 尺度得到预测结果。训练的网络模型采用14层,包括1个输入层、5个编码层、 1个特征表征层(中间层)、6个解码层及1个输出层,节点数从输入到输出依 次是[52,256,128,64,32,16,8,16,32,64,128,256,52,2],其中包括52个输入,2个输出(地面的
no2及pm
2.5
),选取的训练超参数:批学习样本大小为 1024,初始的学习率为0.1。对预测目标no2及pm
2.5
进行了限制,即:0≤no2≤300μg/m3及0≤pm
2.
≤2000μg/m3,带限制性条件的优化采用了投影梯度 下降法,采用了基于tensorflow的软件包tensorflow constrained optimization (tfco)来实现。
[0148]
步骤十一、精度验证及评估。初步的训练得到测试精度r2:0.84(no2)及 0.89(pm
2.5
);测试rmse:8.3μg/m3(no2)及22.34μg/m3(pm
2.5
)。同时采用 shap计算模型各个协变量贡献,计算得到贡献最大的前10个协变量包括 maiac aod及omi
‑
no2、3个来自merra2 gmi变量(co、no2及pm
2.5
)、 交通道路长度、到poi最短距离、风速、坐标,这表明了包括污染源的 merre2 gmi的变量的主要贡献。
[0149]
步骤十二、验证达标与否。总体上如步骤十一报告的no2及pm
2.5
的r2及 rmse基本达到要求。该方法用于预测京津塘地区2015年地面的no2及pm
2.5
, 地面预测结果查看发现北部地区有6个点的no2浓度的预测结果偏高,与其周边 预测结果差距较大,表明这些点预测存在偏差,转入步骤十三。
[0150]
步骤十三、对于不合理或不达标的预测,调整预测协变量,超参数及限制 性条件循环训练。问题检查表明北部地区这6个点交通的协变量提取错误,对 此进行修正。返回步骤十重新训练。
[0151]
步骤十四、训练得到模型精度几乎一样,异常点较少,对总的训练精度影 响不大。但修正后的结果更符合要求,最终将预测结果的栅格估计表面输出。 图3展示了2015年12月30日预测的no2栅格图;图4展示了2015年12月30日预测 的pm
2.5
栅格图。
[0152]
通过本实施例可知,本发明针对当前空气污染时空反演方法的主要缺点, 提出了相应的解决办法,具体有:
[0153]
1)用于建模的数据大部分基于局部区域或时段,样本时空覆盖度不足。 过小的采样域会对总体估计值造成偏差。对此本专利数据的准备覆盖了中国大 陆地区,取多年的天数据,所以本专利具有更为宽泛的时空覆盖度,用于建模 的数据样本更为全面,更能体现总体的分布情况。
[0154]
2)缺乏高分辨率的气象协变量数据。气象协变量数据是影响空气污染的 关键变量,但全国范围内缺乏可靠的高分辨率栅格气象数据,现有的研究大部 分采用了分辨率较粗的气象同化数据,难以反映在精细尺度上要素的变异情 况,这严重影响空气污染反演效果。本专利结合国家气象局地面实测数据,对 气象变量进行高分辨率及高精度的反演,获得了可靠的结果。
[0155]
3)现有的方法采用了ctm等及卫星气溶胶数据等提取空气污染的分布, 但是空气污染源于多种不同的来源,现有的大部分方法难以全面的包括各种污 染来源数据,是导致估计有偏的原因之一。本专利考虑得更全面,除了常规的 气溶胶aod数据,也包括了最新的merra2 gmi的多达26种污染源的同化数 据,提取了地面交通、土地利用及poi(point of interest)的多个潜在污染来源 的协变量数据,从而使得本专利的影响要素考虑更为全面。
[0156]
4)现有的方法许多没有处理卫星遥感气溶胶及omi no2数据大量缺失 值,或者由于气象粗分辨率协变量及建模方法的原因反演缺失值的精度有限。 为此本专利提出了基于全残差深度学习的方法将缺失的气溶胶及omi no2缺失 数据插补完整,使得研究区域内
无缺失值,从而使得本专利的评估范围更为宽 泛,不受到卫星数据缺失值的影响。
[0157]
5)现有的方法采用了gam、传统的多层感知机及克里格等,这些传统方 法学习能力有限,虽然有的也采用了深层cnn(convolutional neural network)、lstm(long short
‑
term memory)及支持向量机等,但支持向量机 需要复杂的特征提取,效率较低,而cnn本身受到深层网络导致梯度消失的影 响等。本专利在建模方法上采用了最新的融入了注意力机制的全残差深度网络 模型,大幅提高学习测试精度,而连续变量的输入保全输入信息,在实际中提 高了其泛化性,是本专利成果实施的基础模型。
[0158]
6)现有方法大部分对结果大部分采用测试的精度,缺乏对实际结果的有 效性验证及解译,对此本专利采用有效解译方法,解译每个预测变量对结果的 贡献,并建立了回调循环机制,通过多次的调整训练获得更可信结果。
[0159]
上述实施方式并非是对本发明的限制,本发明也并不仅限于上述举例,本 技术领域的技术人员在本发明的技术方案范围内所做出的变化、改型、添加或 替换,也均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1