基于改进随机森林的客户信用分类方法
本发明涉及数据分类领域,具体涉及一种基于改进随机森林的客户信用分类方法。
背景技术:
随机森林是一种典型的组合分类器算法,是由多棵决策树组成的,在数据分类问题上是一个非常有用的方法。随机森林具有良好的性能和优点,它克服了数据过拟合的问题,被广泛应用于金融决策、负载预测、图像分类等领域。
随机森林模型的构建主要分为四步:①基于原始训练集生成训练子集;②对随机特征进行选取;③根据训练子集和决策树生成算法生成决策树集合;④生成的每一棵决策树都对测试机进行预测分类,然后对结果进行投票,得出最终的分类结果。
尽管许多学者对随机森林算法进行了广泛研究,并且取得了许多显著的成果。却仍然存在一些不足之处。由于数据集的复杂性,随机森林模型中会包含一些分类精确度差的决策树,而这些决策树会在最后的投票过程中对最终结果产生消极的影响。此外,随机化过程会生成相似度高的决策树,从而影响随机森林模型整体的分类性能,对决策树的多样性,即泛化能力产生消极影响。
技术实现要素:
发明目的:本发明目的是提供一种基于改进随机森林的客户信用分类方法,去除分类精度差和相似度高的决策树,提高客户信用分类随机森林的分类准确性和泛化能力。
技术方案:一种基于改进随机森林的客户信用分类方法,包括如下步骤:
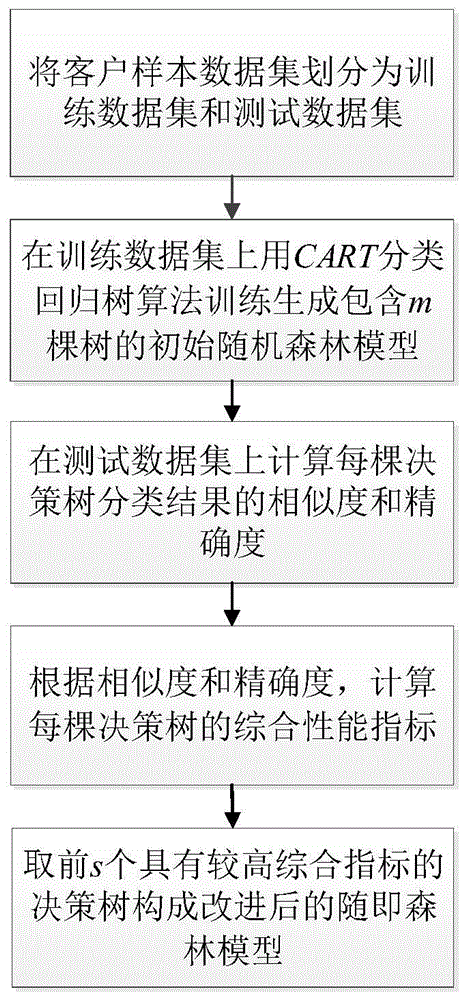
步骤1:将客户样本数据集划分为训练数据集和测试数据集;
步骤2:在训练数据集上用cart分类回归树算法训练生成包含m棵树的初始随机森林模型;
步骤3:将测试数据集输入初始随机森林模型,计算每棵决策树分类结果的相似度和精确度;
步骤4:根据相似度和精确度,计算每棵决策树的综合性能指标;
步骤5:取前s个具有较高综合指标的决策树构成改进后的随机34森林模型。
进一步地,步骤1具体包括:
d为客户样本数据集,di∈d为客户样本数据集中的任一样本,di={特征变量集,li},特征变量集包括借款金额、借款利率、借款期限、初始信用评级、年龄、历史借款总金额、待还本金、历史正常还款期数的用户特征,li为客户信用分类,li∈[1,c],c为信用分类数,表示共有c个不同信用级别;按均匀分布随机地将客户样本数据集d划分为训练数据集和测试数据集。
进一步地,按均匀分布随机地将客户样本数据集d中80%的样本划分为训练数据集f,20%样本划分为测试数据集g。
进一步地,步骤2具体包括:在训练数据集上训练随机森林模型,生成包含m棵树的初始随机森林模型,训练时m的值取100。
进一步地,相似度由kappa统计量确定,计算方法如下:
令
第j棵树的分类期望一致率表达式为:
第j棵决策树的相似度kappa统计量表达式为:
进一步地,精确度的计算方法如下:
精确度根据决策树对样本的预测信用分类和样本标记分类之间的方差来度量,经过归一化处理,得到第j棵决策树对于测试数据集g中所有样本di′∈g的精确度为:
进一步地,步骤4得到的相似度和精确度,计算第j棵树的综合性能指标为:
h(j)=αk(j)+(1-α)r(j)
其中,α为可调参数,α∈[0,1];
进一步地,步骤5具体包括:将决策树按h(j)值从高到低排序,取前s个h(j)值对应的决策树组成改进后的随机森林模型,可用于对客户的信用级别进行分类。
有益效果:与现有技术相比,本发明具有如下显著的优点:
(1)本发明综合考虑了随机森林中决策树的相似度和精确度,提高了客户信用分类的准确性和泛化能力;
(2)定义新的评价决策树综合性能指标,该指标能有效地在相似度和精确度之间进行折中;
(3)本发明不仅适用于客户信用分类,而且很容易拓展应用于其他分类场景中,具有普遍适用的灵活性和应用前景。
附图说明
图1是本发明的方法流程图。
具体实施方式
下面结合附图对本发明的技术方案进行详细说明。
如图1所示,本发明公开了一种基于改进随机森林的客户信用分类方法,包括如下步骤:将客户样本数据集划分为训练数据集和测试数据集;在训练数据集上用cart回归树生成决策树,生成初始随机森林模型;在测试数据集上计算每棵决策树的分类精度和相似度;根据分类精确度和相似度,计算每棵决策树的综合性能指标;取前s个具有较高综合指标的决策树构成改进后的随机森林,用于对客户数据进行信用分类。本发明实现了对传统随机森林模型的改进,有效地提高了客户信用分类随机森林的分类准确性和泛化能力。
具体过程包括以下步骤:
步骤1:设d为客户样本数据集,di∈d为客户样本数据集中的任一样本,di={特征变量集,li}。其中,特征变量集包括借款金额、借款利率、借款期限、初始信用评级、年龄、历史借款总金额、待还本金、历史正常还款期数等用户特征,li为客户信用分类,li∈[1,c],c为信用分类数,表示共有c个不同信用级别;
步骤2:按均匀分布随机地将客户样本数据集d中80%的样本划分为训练数据集f,20%样本划分为测试数据集g。
步骤3:在训练数据集f上训练随机森林模型,生成包含m棵树的初始随机森林模型。训练时m的值可以取100。训练模型时,采用cart分类回归树作为生成决策树的算法;
步骤4:将测试数据集g输入初始随机森林模型,计算每棵决策树分类结果的相似度和精确度;
步骤4.1:相似度由kappa统计量确定,计算方法如下:
令
那么,第j棵决策树的相似度kappa统计量为:
步骤4.2:精确度的计算方法如下:
精确度根据决策树对样本的预测信用分类和样本标记分类之间的方差来度量,经过归一化处理,得到第j棵决策树对于测试数据集g中所有样本di′∈g的精确度为:
步骤5:根据步骤4得到的相似度和精确度,计算第j棵树的综合性能指标为:
h(j)=αk(j)+(1-α)r(j)
其中,α为可调参数,α∈[0,1];
步骤6:将决策树按h(j)值从高到低排序,取前s个h(j)值对应的决策树组成改进后的随机森林模型,可用于对客户的信用级别进行分类。
- 还没有人留言评论。精彩留言会获得点赞!