基于语义理解的文字组织编码算法的制作方法
1.本发明涉及计算机自然语言处理技术领域,特别涉及一种基于语义理解的文字组织编码算法。
背景技术:
2.目前对于计算机与人工智能的融合,已在多领域进行应用,最为广泛的即nlp(natural language processing,自然语言处理,是研究人与计算机交互的语言问题的一门学科),而现有技术对于传统文本分类的处理大致分为文本预处理、文本特征提取和分类模型构建等,在对文本处理时通常通过大数据来统计,按照概率值进行分词,或者通过提前设置好的词典来分词。但该处理方式还存在以下不足之处:1.容易引起维度灾难问题,语料库太大,字典的大小为每个词的维度,高维度导致计算困难,若每个文档包含的词语数少于词典的总词语数,则又导致文档稀疏;2.仅仅考虑词语出现的次数,没有考虑句子词语之间的顺序信息,即语义信息未考虑。
技术实现要素:
3.本发明要解决的技术问题是:提供一种将文本的语义信息具体化、数据化,变为计算机可以存储的数据信息的基于语义理解的文字组织编码算法,以克服已有技术所存在的上述不足。
4.本发明采取的技术方案是:一种基于语义理解的文字组织编码算法,包括以下步骤:(一)拆分文本(1)将文本拆分成段落;(2)将段落拆分成整句;(3)将整句拆分成子句;(4)将子句拆分成单个字符;(二)编码转换将单个字符转换成对应的unicode编码,每个字符均用16位二进制数来表示;(三)组织编码(1)将相邻字符的unicode编码两两组合;(2)寻找有经验的组合,优先进行组织、存储;(3)再与剩下的编码一起继续进行两两组合,重复寻找两两组合有经验的优先进行组织;(4)持续组织,最终得到一个可能有经验的知识编码,用于系统保存或者关联其它有用编码信息。
5.其进一步的技术方案是:所述步骤(二)具体包括以下步骤:
(1)将单个字符里的数字部分进行数字转码,即将数字保存到id1,系统标识符
‑
数字保存到id0;(2)将单个字符里的非数字部分进行非数字转码,其中窄字符(ascii)转换为宽字符(unicode),获取对应的unicode编码,文字则直接转成unicode编码。
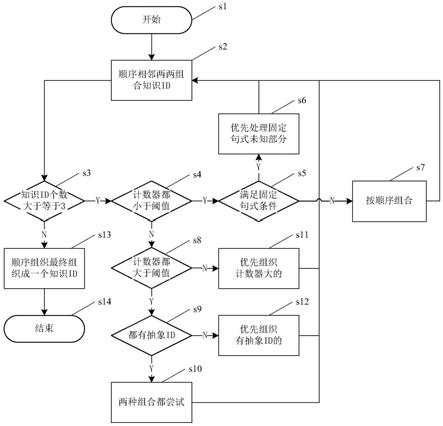
6.进一步:所述步骤(三)具体包括以下步骤:s1.组织开始;s2.将相邻字符的unicode编码按顺序两两组合成知识id;s3.判断知识id个数是否大于等于3,若是,进入步骤s4,若否,进入步骤s13;s4.判断计数器是否都小于阈值,若是,进入步骤s5,若否,进入步骤s8;s5.判断知识id是否满足固定句式条件,若是,进入步骤s6,若否,进入步骤s7;s6.优先处理固定句式未知部分,返回步骤s2;s7.按顺序进行组合、存储,返回步骤s2;s8.判断计数器是否都大于阈值,若是,进入步骤s9,若否,进入步骤s11;s9.判断知识id是否都有抽象id,即是否有经验,若是,进入步骤s10,若否,进入步骤s12;s10.有抽象id的两种组合都尝试进行组织、存储,返回步骤s2;s11.优先组织计数器大的知识id,返回步骤s2;s12.优先组织有抽象id的知识id,返回步骤s2;s13.按顺序依次进行组织,最终组织成一个知识id;s14.组织结束。
7.由于采用上述技术方案,本发明之基于语义理解的文字组织编码算法具有如下有益效果:本发明通过将文本逐步拆分成单个字符,转换成unicode编码,后再对每个字符进行两两组合,寻找有经验的组合优先进行组织,直到把所有的知识组织起来,得到一个有经验的可以表达更多意思的知识编码,用于语义理解系统里对语句的分析、理解,如此将文字数据化的方式,不仅传递方便而且还可以通过id查询到所有相关信息,更方便系统识别。
8.下面结合附图和实施例对本发明之基于语义理解的文字组织编码算法的技术特征作进一步的说明。
附图说明
9.图1:本发明之组织编码算法流程图。
10.文中英文及缩略语说明:ascii:美国信息交换标准代码;unicode:为了解决传统的字符编码方案(ascii)的局限而产生的代码,unicode如一本很厚的字典,记录着世界上所有字符对应的一个数字。
具体实施方式
80003两个编码,则直接组织成80005,在语义系统里 80005 便代表字符串“语义理解系统”;当文本出现都没有词性和抽象时,会尝试运用猜实体名词方法,把组织后不能组织的部分“语、义、理解系统”和曾经根据经验生成的猜分类句式“事物、理解、系统”对比出“语、义”和“事物”应该为同一类,就可以优先组织“语、义”。
15.所述步骤(二)具体包括以下步骤:(1)字符转编码分为两种转码:数字转码与非数字转码,将单个字符里的数字部分进行数字转码,即将数字保存到id1,系统标识符
‑
数字保存到id0;(2)将单个字符里的非数字部分进行非数字转码,其中窄字符(ascii)转换为宽字符(unicode),获取对应的unicode编码,文字则直接转成unicode编码。
16.如图1所示,所述步骤(三)具体包括以下步骤:s1.组织开始;s2.将相邻字符的unicode编码按顺序两两组合成知识id;s3.判断知识id个数是否大于等于3,若是,进入步骤s4,若否,进入步骤s13;s4.判断计数器是否都小于阈值,若是,进入步骤s5,若否,进入步骤s8;s5.判断知识id是否满足固定句式条件,若是,进入步骤s6,若否,进入步骤s7;s6.优先处理固定句式未知部分,返回步骤s2;s7.按顺序进行组合、存储,返回步骤s2;s8.判断计数器是否都大于阈值,若是,进入步骤s9,若否,进入步骤s11;s9.判断知识id是否都有抽象id,即是否有经验,若是,进入步骤s10,若否,进入步骤s12;s10.有抽象id的两种组合都尝试进行组织、存储,返回步骤s2;s11.优先组织计数器大的知识id,返回步骤s2;s12.优先组织有抽象id的知识id,返回步骤s2;s13.按顺序依次进行组织,最终组织成一个知识id;s14.组织结束。
17.以上实施例仅为本发明的较佳实施例,本发明的方法并不限于上述实施例列举的形式,凡在本发明的精神和原则之内所作的任何修改、等同替换等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1