语义分析模型评价方法与流程
本发明涉及一种语义分析模型评价方法。
背景技术:
随着互联网电商的发达,智能客服被应用的越来越多。好的智能客户能够准确识别用户的意图从而能够进行有针对性的回复。而智能客服的核心在于其中语义识别模型的性能。
现阶段的语义分析模型评估方式比较单一,基本是基于测试集的某一项指标做出评价,比如在测试集上的准确率、精确率或者f1值。所以,语义分析模型即使在现有的测试集上表现优异,但不代表在线上真实场景就会有良好的体感。
技术实现要素:
本发明提供了一种语义分析模型评价方法,采用如下的技术方案:
一种语义分析模型评价方法,包含:
测试语义分析模型的基本功能,具体包含:
检查语义分析模型的模型词表;
通过简易测试集对语义分析模型进行测试判断语义分析模型对简易测试集的分析结果;
对上述测试结果进行打分得到第一得分;
测试语义分析模型的泛化能力,具体包含:
将若干语义分析模型能够准确识别的语料做不影响语句语义的改写处理得到改写语料;
将改写后得到的若干改写语料重新输入到语义分析模型判断其是否能够正确识别;
对上述测试结果进行打分得到第二得分;
测试语义分析模型的反向识别能力,具体包含:
将若干语义分析模型能够准确识别的正向语料做反向改写得到反向语料;
将改写后得到的若干反向语料重新输入到语义分析模型判断其是否能够正确识别;
对上述测试结果进行打分得到第三得分;
综合上述步骤的打分结果得到一个综合得分。
进一步地,检查语义分析模型的模型词表的具体方法为:
将语义分析模型的模型词表和行业关键词库进行比对以判断模型词表是否齐全。
进一步地,行业关键词库通过以下具体方法获得:
获取各行业的对话语料;
将对话语料输入到注意力机制模型以自动识别出其中的关键词;
将所有提取出的关键词组成行业关键词库。
进一步地,通过简易测试集对语义分析模型进行测试判断语义分析模型对简易测试集的分析结果的具体方法为:
获取若干测试语句;
将若干测试语句分别输入到多个简易语义分析模型;
将每个简易语义分析模型均给出高分的测试语句挑选出来组成简易测试集;
将简易测试集输入语义分析模型得到分析结果。
进一步地,将若干语义分析模型能够准确识别的语料做不影响语句语义的改写处理得到改写语料的具体方法为:
获取若干语义分析模型能够准确识别的语料;
通过第一改写模型对这些语料进行添加错别字、添加标点符号、近义词替换和添加不影响语义的单词中的至少一种处理方法得到改写语料。
进一步地,将若干语义分析模型能够准确识别的语料做不影响语句语义的改写处理得到改写语料的具体方法为:
获取若干语义分析模型能够准确识别的语料;
通过翻译模型将这些语料翻译成英文后再翻译回中文得到改写语料。
进一步地,将若干语义分析模型能够准确识别的正向语料做反向改写得到反向语料的具体方法为:
获取若干语义分析模型能够准确识别的正向语料;
通过第二改写模型对这些正向语料进行添加否定词和替换反义词中的一种处理方法得到反向语料。
进一步地,将若干语义分析模型能够准确识别的正向语料做反向改写得到反向语料的具体方法为:
获取若干语义分析模型能够准确识别的正向语料;
通过第三改写模型对这些正向语料进行反向语义改写得到反向语料。
进一步地,综合上述步骤的打分结果得到一个综合得分的具体方法为通过下述公式计算你综合得分:
score=α*sbase+(1-α)[β*sinvar+(1-β)*sdir],
其中,score为综合得分,sbase为第一得分,sinvar为第二得分,sdir为第三得分,α为第一因子,0≤α≤1,β为第二因子,0≤β≤1。
进一步地,第一因子α为0.55,第二因子β为0.75。
本发明的有益之处在于所提供的语义分析模型评价方法,从多个角度评价语义分析模型的能力,评价的结果更加准确全面。
附图说明
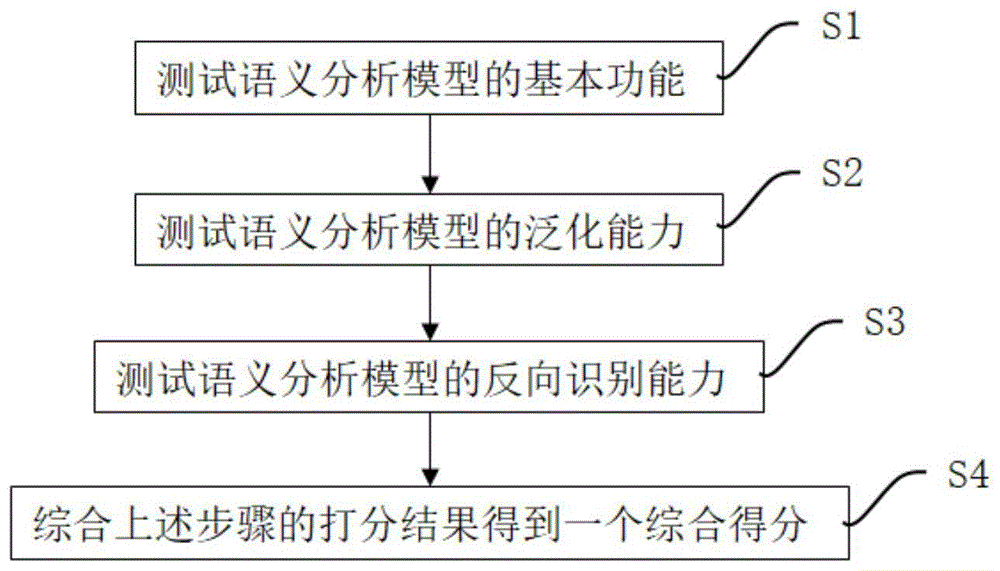
图1是本发明的语义分析模型评价方法的流程图。
具体实施方式
以下结合附图和具体实施例对本发明作具体的介绍。
如图1所述为本发明的一种语义分析模型评价方法,具体包含:s1:测试语义分析模型的基本功能。s2:测试语义分析模型的泛化能力。s3:测试语义分析模型的反向识别能力。s4:综合上述步骤的打分结果得到一个综合得分。通过以上步骤,从多个角度对语义分析模型进行测试,得到的评价结果更加准确全面。以下具体介绍上述步骤。
对于步骤s1:测试语义分析模型的基本功能。
步骤s1主要测试语义分析模型的基本功能,语义分析模型需要在一些比较简单的案例中需要有较好的表现。一般如果语义分析模型在这些案例中表现不佳,对用户体感会有较大影响。
测试语义分析模型的基本功能具体包含:
检查语义分析模型的模型词表。通过简易测试集对语义分析模型进行测试判断语义分析模型对简易测试集的分析结果。对上述测试结果进行打分得到第一得分。
具体而言,检查语义分析模型的模型词表的具体方法为:将语义分析模型的模型词表和行业关键词库进行比对以判断模型词表是否齐全。检查模型词表是否完全覆盖了这些关键词,如果没有全面概括,语义分析模型可能对一些行业关键词缺乏敏感性,从而降低了模型整体效果。
其中,行业关键词库通过以下具体方法获得:
获取各行业的对话语料。从淘宝或京东等电商平台获取到各行业的对话语料。将对话语料输入到注意力机制模型以自动识别出其中的关键词。将所有提取出的关键词组成行业关键词库。
通过简易测试集对语义分析模型进行测试判断语义分析模型对简易测试集的分析结果的具体方法为:
获取若干测试语句。若干测试语句分别输入到多个简易语义分析模型。在本发明中,简易语义分析模型的数量选择为5个。将每个简易语义分析模型均给出高分的测试语句挑选出来组成简易测试集。具体的,在本发明中每个简易语义分析模型均给出0.98分以上的测试语句挑选出来组成简易测试集。这里,简易语义分析模型指本领域的一些简单的语义分析模型。将简易测试集输入语义分析模型得到分析结果。如果模型在这类例句上识别失败,那模型在基本功能测试上表现较差。
对于步骤s2:测试语义分析模型的泛化能力。
测试语义分析模型的泛化能力具体包含:
将若干语义分析模型能够准确识别的语料做不影响语句语义的改写处理得到改写语料。将改写后得到的若干改写语料重新输入到语义分析模型判断其是否能够正确识别。对上述测试结果进行打分得到第二得分。
具体而言,将若干语义分析模型能够准确识别的语料做不影响语句语义的改写处理得到改写语料的具体方法为:获取若干语义分析模型能够准确识别的语料。通过第一改写模型对这些语料进行添加错别字、添加标点符号、近义词替换和添加不影响语义的单词中的至少一种处理方法得到改写语料。例如,例句“这件衣服质量真好”的意图是“买家表示满意”,修改例句为“您好,这件衣服质量真好!”,添加的词语并没有改变原句的主体意思。将修改后的语料重新输入到语义分析模型,看其是否还能够识别出修改后的语料。
作为另一种改写方式,将若干语义分析模型能够准确识别的语料做不影响语句语义的改写处理得到改写语料的具体方法为:
获取若干语义分析模型能够准确识别的语料。通过翻译模型将这些语料翻译成英文后再翻译回中文得到改写语料。
例如,例句“这件衣服质量真好”的意图是“买家表示满意”,中文到英文翻译模型将该例句翻译为“thisclothinghasgoodquality”,然后英文到中文的翻译模型将这句英文结果翻译为“这件衣服有好的质量”,经过两轮翻译后的句子还是表达原先的意思,但是表达方法不一样。如果语义分析模型还能够识别为“买家表示满意”,那么模型在泛化性能测试上表现较好。
对于步骤s3:测试语义分析模型的反向识别能力。
测试语义分析模型的反向识别能力具体包含:
将若干语义分析模型能够准确识别的正向语料做反向改写得到反向语料。将改写后得到的若干反向语料重新输入到语义分析模型判断其是否能够正确识别。对上述测试结果进行打分得到第三得分。
将若干语义分析模型能够准确识别的正向语料做反向改写得到反向语料的具体方法为:
获取若干语义分析模型能够准确识别的正向语料。通过第二改写模型对这些正向语料进行添加否定词和替换反义词中的一种处理方法得到反向语料。
可以理解的是,正向和方向没有语义上的区分,作为一对相对性的意图,其中一个作为正向,则另一个则作为反向。具体的,首先要找出有相对性的意图标签对,比如“买家表示不满”和“买家表示满意”。然后,从模型可以正确识别为其中一类,如“买家表示满意”意图中采样一些例句,此时,“买家表示满意”则表示正向。然后添加否定词或者替换反义词,比如“这件衣服质量真好”改写成“这件衣服质量真差”或者“这件衣服质量真不好”。然后用语义模型对改写后的例句做测试,如果改写的例句预测为“买家表示不满”,那么模型在反向测试上表现较好。
作为另一种可选实施方式,将若干语义分析模型能够准确识别的正向语料做反向改写得到反向语料的具体方法还可以为:
获取若干语义分析模型能够准确识别的正向语料。通过第三改写模型对这些正向语料进行反向语义改写得到反向语料。
例如,通过改写模型将“这件衣服质量真好”改写成“这衣服质量不好”。然后用语义模型对改写后的例句做测试,如果改写的例句预测为“买家表示不满”,那么模型在反向测试上表现较好。
对于步骤s4:综合上述步骤的打分结果得到一个综合得分。
综合上述步骤的打分结果得到一个综合得分的具体方法为通过下述公式计算你综合得分:
score=α*sbase+(1-α)[β*sinvar+(1-β)*sdir],
其中,score为综合得分,sbase为第一得分,sinvar为第二得分,sdir为第三得分,α为第一因子,0≤α≤1,β为第二因子,0≤β≤1。
进一步地,第一因子α为0.55,第二因子β为0.75。
通过得到的综合得分,能够准确评估语义分析模型的功能。
基本功能满分的语义分析模型已经可以大致达到合格线,但缺少泛化能力的模型是不合格的,所以基本功能测试通过且有一定泛化能力模型才是达标的模型。同时,模型反向测试是比较难的测试,这项测试反映的模型问题是具有普遍性且较难解决的,所以第三项测试所占比例是比较低的。各类型测试的权重可以根据情况做一定的调整。
以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,上述实施例不以任何形式限制本发明,凡采用等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!