一种基于语义分析、统计的工单自动处理方法及装置与流程
1.本发明属于工单处理领域,特别涉及一种基于语义分析、统计的工单自动处理方法及装置。
背景技术:
2.当前服务台系统都是接收到用户提交的工单主要渠道,工单数据记录了用户的基本诉求,包括投诉单、故障单、需求单等等。工单处理与客户体验息息相关,对人员的专业素养要求极高,是一项知识密集型的工作,工单的受理、分配需要管理人员根据工单的描述,判断工单提出的意图,把工单分配到适合的运维服务人员,尤其银行系统工单处理人员需要具备丰富的金融知识和很强的分析能力,所有处理难度、复杂度都比较高,所有工单受理是服务台一个重要环节。
3.当前处理银行工单受理一种还是基本以人工为主,依靠专业的人员受理、分配工单,都是靠人工完成工作。另一种是近年出现的人工智能处理系统,但是系统的研发需要专业的人工智能研发人才,才能完成开发实现。对于人工完成的服务台系统,主要缺点是人工投入问题,需要专业的人员人为处理,成本相对较高。对于人工智能处理方式,开发难度较大,需要投入较多的人力、财力。
技术实现要素:
4.针对相关技术中的上述技术问题,本发明提出一种基于语义分析、统计的工单自动处理方法及装置,能够克服现有技术的上述不足。
5.为实现上述技术目的,本发明的技术方案是这样实现的:
6.一种基于语义分析、统计的工单自动处理方法,该方法包括:
7.建立数据模型;
8.依据数据模型,处理工单。
9.进一步的,所述建立数据模型,包括:
10.统计分析旧的工单数据;
11.对所述旧的工单数据的内容进行分词,得到关键词;
12.统计所述关键词在业务结果中的分类方向上出现的次数。
13.进一步的,所述依据数据模型,处理工单,包括:
14.接收新的提交工单;
15.对所述新的提交工单进行分词,得到所有关键词;
16.在所述数据模型中,循环查询所述关键词,得到所述关键词的统计信息;
17.根据查到的统计信息得出、叠加倾向概率,处理新工单。
18.进一步的,所述根据查到的统计信息得出、叠加倾向概率,处理新工单,包括:
19.根据查到的统计信息,得出每个分类方向上的关键词最倾向概率;
20.叠加、统计所述关键词最倾向概率,得出新工单在每个分类上最大的概率倾向;
21.依据所述概率倾向,决定所述新工单处理结果。
22.进一步的,所述决定所述新工单处理结果中,所述处理结果包括:事件、请求和部门。
23.进一步的,所述关键词的分类设定概率计算修正值。
24.另一方面,本发明还提出了一种基于语义分析、统计的工单自动处理装置,该装置包括:
25.建模单元,用于建立数据模型;
26.处理单元,用于依据数据模型,处理工单。
27.进一步的,所述建模单元,包括:
28.第一统计单元,用于统计分析旧的工单数据;
29.第一分词单元,用于对所述旧的工单数据的内容进行分词,得到关键词;
30.第二统计单元,用于统计所述关键词在业务结果中的分类方向上出现的次数。
31.进一步的,所述处理单元,包括:
32.接收单元,用于接收新的提交工单;
33.第二分词单元,用于对所述新的提交工单进行分词,得到所有关键词;
34.查询单元,用于在所述数据模型中,循环查询所述关键词,得到所述关键词的统计信息;
35.第一处理单元,用于根据查到的统计信息得出、叠加倾向概率,处理新工单。
36.进一步的,所述第一处理单元,包括:
37.第一得出单元,用于根据查到的统计信息,得出每个分类方向上的关键词最倾向概率;
38.第二得出单元,用于叠加、统计所述关键词最倾向概率,得出新工单在每个分类上最大的概率倾向;
39.决定单元,用于依据所述概率倾向,决定所述新工单处理结果。
40.本发明的有益效果为:本发明通过使用一个统计概率模型,分析记录以往的工单数据,得到一个数据模型,后续通过这个模型快速分析工单,然后得出工单的意图和分配信息,可以替代人工分配工单,分配的准确率能达到85%
‑
90%,同时没有人工智能方式的复杂程度,更容易开发、维护。
附图说明
41.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
42.图1示出了根据现本发明实施例的一种基于语义分析、统计的工单自动处理方法的流程框图;
43.图2示出了根据现本发明实施例的一种基于语义分析、统计的工单自动处理装置的结构示意图。
具体实施方式
44.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地说明,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
45.如图1所示,一种基于语义分析、统计的工单自动处理方法,该方法包括:
46.建立数据模型;
47.依据数据模型,处理工单。
48.在本发明的一些实施例中,所述建立数据模型,包括:
49.统计分析旧的工单数据;
50.对所述旧的工单数据的内容进行分词,得到关键词;
51.统计所述关键词在业务结果中的分类方向上出现的次数。
52.在本发明的一些实施例中,所述依据数据模型,处理工单,包括:
53.接收新的提交工单;
54.对所述新的提交工单进行分词,得到所有关键词;
55.在所述数据模型中,循环查询所述关键词,得到所述关键词的统计信息;
56.根据查到的统计信息得出、叠加倾向概率,处理新工单。
57.在本发明的一些实施例中,所述根据查到的统计信息得出、叠加倾向概率,处理新工单,包括:
58.根据查到的统计信息,得出每个分类方向上的关键词最倾向概率;
59.叠加、统计所述关键词最倾向概率,得出新工单在每个分类上最大的概率倾向;
60.依据所述概率倾向,决定所述新工单处理结果。
61.在本发明的一些实施例中,所述决定所述新工单处理结果中,所述处理结果包括:事件、请求和部门。
62.在本发明的一些实施例中,所述关键词的分类设定概率计算修正值。
63.另一方面,如图2所示,本发明还提出了一种基于语义分析、统计的工单自动处理装置,该装置包括:
64.建模单元,用于建立数据模型;
65.处理单元,用于依据数据模型,处理工单。
66.在本发明的一些实施例中,所述建模单元,包括:
67.第一统计单元,用于统计分析旧的工单数据;
68.第一分词单元,用于对所述旧的工单数据的内容进行分词,得到关键词;
69.第二统计单元,用于统计所述关键词在业务结果中的分类方向上出现的次数。
70.进一步的,所述处理单元,包括:
71.接收单元,用于接收新的提交工单;
72.第二分词单元,用于对所述新的提交工单进行分词,得到所有关键词;
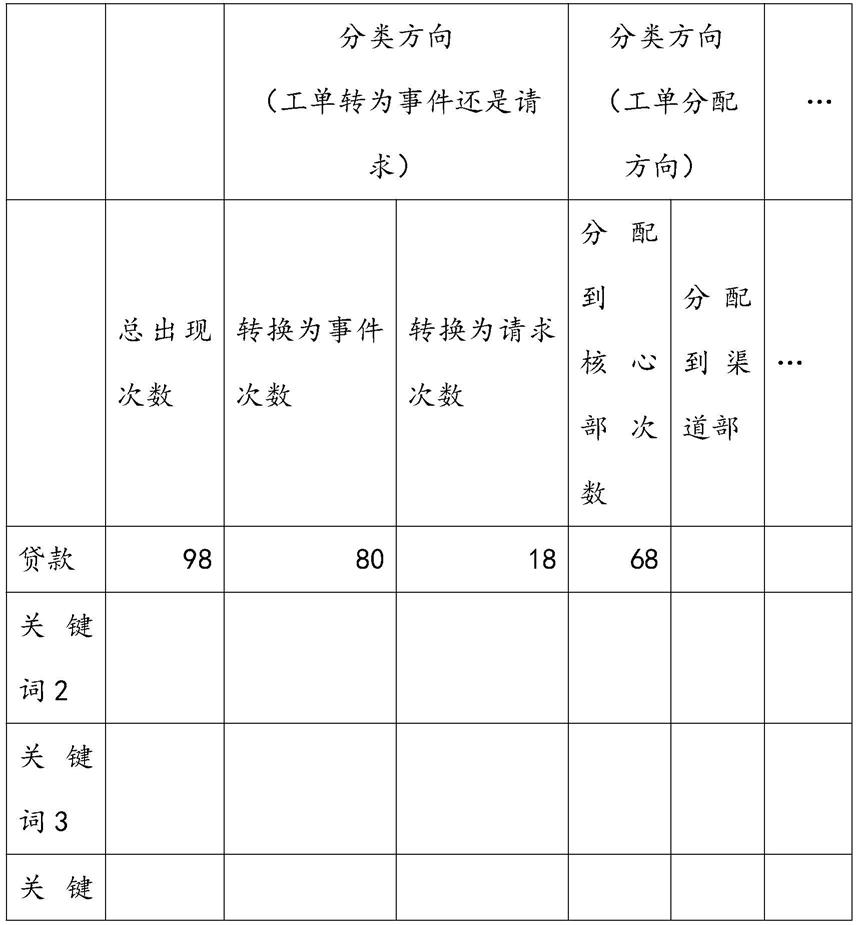
73.查询单元,用于在所述数据模型中,循环查询所述关键词,得到所述关键词的统计信息;
74.第一处理单元,用于根据查到的统计信息得出、叠加倾向概率,处理新工单。
75.在本发明的一些实施例中,所述第一处理单元,包括:
76.第一得出单元,用于根据查到的统计信息,得出每个分类方向上的关键词最倾向概率;
77.第二得出单元,用于叠加、统计所述关键词最倾向概率,得出新工单在每个分类上最大的概率倾向;
78.决定单元,用于依据所述概率倾向,决定所述新工单处理结果。
79.在本发明的一些实施例中,建立数据模型:统计分析以往的工单数据,通过对工单内容进行分词,得到主要的关键词,保存关键词的出现后续产生的业务结果进行统计,例如:关键词“贷款”,在统计以往工单出现,这个关键词出现了多少次,有多少次落到预先定义的分类上,数据模型如下:
80.[0081][0082]
在本发明的一些实施例中,处理新工单:接收到新提交的工单,先进行分词,到的所有的关键词,循环每个关键词到数据库的模型数据中查询,得到这些关键词的历史统计信息(没查到的忽略),然后根据查到信息得出每个分类方向的最倾向概率,最后把每个关键词的分类倾向概率进行叠加统计,得出这个工单在各个分类上最大的概率倾向,决定这个工地应该转为事件还是请求,应该分配到哪个部门。
[0083]
为了更准确,我为每个关键词的分类设定一个概率计算修正值,保证一些重要的关键词能在概率计算起到更大作用,使一些影响小的关键词计算倾向概率变低。
[0084]
本发明通过使用一个统计概率模型,分析记录以往的工单数据,得到一个数据模型,后续通过这个模型快速分析工单,然后得出工单的意图和分配信息,可以替代人工分配工单,分配的准确率能达到85%
‑
90%,同时没有人工智能方式的复杂程度,更容易开发、维护。
[0085]
尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1