一种基于Kubernetes的集群负载调节方法及存储介质
本发明涉及深度学习领域,特别涉及一种基于kubernetes的集群负载调节方法及存储介质。
背景技术:
深度学习的发展为计算机领域的传统问题带来了新的解决方式,它作为学术界的热点议题、工业界的全新机遇,已经受到高度重视与广泛支持。作为执行算法训练、优化网络模型的基础设施,构建实现数据处理与模型训练的深度学习平台已具有重要意义与研究价值。
传统的进行深度学习训练的方法主要是个人或组织购置硬件设施、在电脑或服务器上配置相应的深度学习环境、在构建完成的环境中直接进行训练工作。这一系列的步骤在经济与经验上都具有较高的门槛,难以面向各行各业进行推广,为大众开展深度学习的研发工作提供了不少障碍。对于高校而言,实验室团队往往已经配备一定规模的服务器集群,但学生需要自己手动开展环境配置工作,不仅入门难度较高,还容易对他人的实验环境造成影响。近年来,各大云服务商逐渐开始研发、推出深度学习平台,它们大多能为用户带来训练上的便捷,但对高校实验室多团队协作开发这一应用场景的适应性较差。
在面对多团队共享gpu资源池这一应用场景下,未能确保不同团队能独占一部分节点,同时不能保证集群的负载均衡,且当一个使用场景或团队较大时,意味着分配给该场景或团队的节点较多,有必要保证场景或团队节点的负载均衡。
技术实现要素:
本发明主要提供一种基于kubernetes的集群负载调节方法及存储介质,能够解决现有技术中在面对多团队共享gpu资源池这一应用场景下,未能确保不同团队能独占一部分节点,同时不能保证集群的负载均衡的问题。
为解决上述技术问题,本发明提供一种基于kubernetes的集群负载调节方法,包括以下内容:
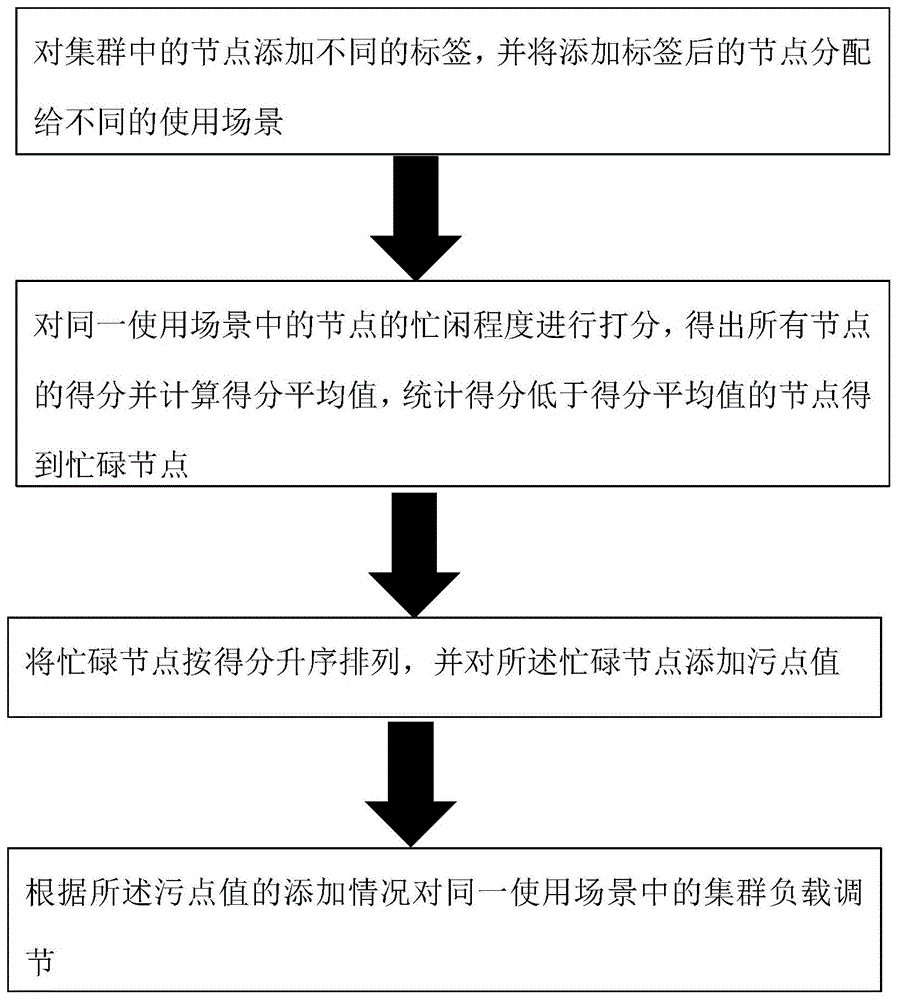
对集群中的节点添加不同的标签,并将添加标签后的节点分配给不同的使用场景;
对同一使用场景中的节点的忙闲程度进行打分,得出所有节点的得分并计算得分平均值,统计得分低于得分平均值的节点得到忙碌节点;
将所述忙碌节点按得分升序排列,并对所述忙碌节点添加污点值;
根据所述污点值的添加情况对同一使用场景中的集群负载进行调节。
优选地,所述对所述忙碌节点添加污点值包括:对排序靠前的忙碌节点添加第一污点值noscheduler,对剩余的忙碌节点添加第二污点值prefernoscheduler。
优选地,所述将添加标签后的节点分配给不同的使用场景包括:当用户指定应用场景、提交训练需求并创建pod时,根据所述pod指定的信息,选择有相应标签的节点进行调度。
优选地,不将所述pod调度到添加了第一污点值noscheduler的忙碌节点上,尽量不将所述pod调度到添加了第二污点值prefernoscheduler的忙碌节点上。
优选地,所述对同一使用场景中的节点的忙闲程度进行打分的计算公式为:
score(pi)=λcpu×ccpu×score(cpui)+λmemory×score(memoryi),其中,ccpu表示第i个节点的cpu核数,score(cpui)表示cpu频率,score(memoryi)表示内存大小,λcpu表示ccpu的权重,λmemory表示score(memoryi)的权重;
所述load(ni)表示总负载,计算公式如下:
load(ni)=λcpu×u(cpui)+λmemory×u(memoryi),其中,u(cpui)表示第i个节点的cpu使用量,为u(memoryi)表示内存使用量。
优选地,根据所述污点值的添加情况对同一使用场景中的集群负载进行调节包括:将所述pod调度到未被添加污点值的节点上,直至集群达到负载均衡。
优选地,根据所述污点值的添加情况对同一使用场景中的集群负载进行调节包括:集群进入新的负载情况后,删除为节点添加的污点值,继续监测负载并调度所述pod。
优选地,所述方法还包括:定期监测集群中每个节点的忙闲程度。
优选地,所述定期监测集群中每个节点的忙闲程度包括:根据使用需求设置节点计分时的权值因子以及计时器监控周期参数,定期检查集群中每个节点的负载情况。
本发明还提供一种存储介质,其上存储有执行一种基于kubernetes的集群负载调节方法的指令。
本发明的有益效果是:(1)区别于现有技术的情况,本发明对集群中的节点添加不同的标签,并将添加标签后的节点分配给不同的使用场景,在面对多团队共享gpu资源池这一应用场景下,能确保不同团队能独占一部分节点,同时对使用场景中的节点的忙闲程度进行打分,统计得分低于得分平均值的节点得到忙碌节点并添加污点值,对节点的状态进行更精细的划分;根据所述污点值的添加情况进行集群负载调节保证集群的负载均衡;(2)打分的计算公式中加入了cpu与内存的权重因子,提高了打分的灵活度,以便应对不同的使用环境;(3)根据使用需求设置节点计分时的权值因子以及计时器监控周期参数,定期检查集群中每个节点的负载情况,保证集群负载的稳定性。
附图说明
图1是本发明一种基于kubernetes的集群负载调节方法的流程示意图;
图2是本发明提供的带有周期监测的集群负载调节过程示意图。
具体实施方式
为了使本发明的目的、技术方案和有益效果更加清楚和完整,以下实施例结合附图对本发明作进一步地阐述。
实施例1
本发明对节点添加标签的目的是将节点分配给不同的使用场景或是不同团队使用,负载调节是在同一场景或同一团队内部进行调整。当一个使用场景或团队较大时,意味着分配给该场景或团队的节点较多,有必要保证场景或团队节点的负载均衡。
由此,本发明提供一种基于kubernetes的集群负载调节方法,如图1所示,所述方法包括以下内容:
对集群中的节点添加不同的标签,并将添加标签后的节点分配给不同的使用场景;
对同一使用场景中的节点的忙闲程度进行打分,得出所有节点的得分并计算得分平均值,统计得分低于得分平均值的节点得到忙碌节点;
将所述忙碌节点按得分升序排列,并对所述忙碌节点添加污点值;
根据所述污点值的添加情况对同一使用场景中的集群负载进行调节。
该方案的原理是:首先对集群中的节点添加不同的标签,并将添加标签后的节点分配给不同的使用场景,保证不同使用场景能独占一部分节点,避免不同使用场景的资源侵占;针对同一个使用场景,当一个使用场景较大时,意味着分配给该场景的节点较多,有必要保证场景节点的负载均衡,在保证在已打标签的节点内部调度的基础上,对同一使用场景中的节点的忙闲程度进行打分,得出所有节点的得分并计算得分平均值,统计得分低于得分平均值的节点得到忙碌节点并添加污点值,尽可能地将pod调度到未被添加污点值的节点上,直至集群基本达到负载均衡。
其中,为节点添加污点值是为了对节点状态进行更精细的划分。如果为节点添加污点值之后,除非有污点容忍,否则无法调度此节点,污点容忍是指pod如添加污点容忍,则调度时会忽略节点上的污点,正常调度。
进一步地,所述对所述忙碌节点添加污点值包括:对排序靠前的忙碌节点添加第一污点值noscheduler,对剩余的忙碌节点添加第二污点值prefernoscheduler。
进一步地,pod是kubernetes中能够创建和部署的最小单元,是kubernetes集群中的一个应用实例,总是部署在同一个节点node上。pod中包含了一个或多个容器,还包括了存储、网络等各个容器共享的资源。
进一步地,所述将添加标签后的节点分配给不同的使用场景包括:当用户指定应用场景、提交训练需求并创建pod时,根据所述pod指定的信息,选择有相应标签的节点进行调度。
如果为节点添加noschedule,则pod除非有污点容忍,否则无法被调度到此节点;如果为节点添加prefernoschedule,则pod一般不会被调度到此节点,除非集群中没有其它节点可供调度。
进一步地,不将所述pod调度到添加了第一污点值noscheduler的忙碌节点上,尽量不将所述pod调度到添加了第二污点值prefernoscheduler的忙碌节点上。
进一步地,所述对同一使用场景中的节点的忙闲程度进行打分的计算公式为:
score(pi)=λcpu×ccpu×score(cpui)+λmemory×score(memoryi),其中,ccpu表示第i个节点的cpu核数,score(cpui)表示cpu频率,score(memoryi)表示内存大小,λcpu表示ccpu的权重,λmemory表示score(memoryi)的权重;
所述load(ni)表示总负载,计算公式如下:
load(ni)=λcpu×u(cpui)+λmemory×u(memoryi),其中,u(cpui)表示第i个节点的cpu使用量,为u(memoryi)表示内存使用量。
其中,λcpu+λmemory=1,通过计算节点得分平均值,获得得分低于平均值的节点,并将这些节点记录为忙碌节点。
进一步地,根据所述污点值的添加情况对同一使用场景中的集群负载进行调节包括:将所述pod调度到未被添加污点值的节点上,直至集群达到负载均衡。
进一步地,根据所述污点值的添加情况对同一使用场景中的集群负载进行调节包括:集群进入新的负载情况后,删除为节点添加的污点值,继续监测负载并调度所述pod。
该技术方案在面对多团队共享gpu资源池这一应用场景下,能确保不同团队能独占一部分节点,同时对所述集群中的节点的忙闲程度进行打分,统计得分低于得分平均值的节点得到忙碌节点列表;并对所述忙碌节点添加污点值;根据所述污点值的添加情况进行集群负载调节保证集群的负载均衡。
本发明还提供一种存储介质,其上存储有执行一种基于kubernetes的集群负载调节方法的指令。
实施例2
在实施例1的基础上,提供的带有周期监测的集群负载调节方法,进一步地,所述方法还包括:定期监测集群中每个节点的忙闲程度。
进一步地,所述定期监测集群中每个节点的忙闲程度包括:根据使用需求设置节点计分时的权值因子以及计时器监控周期参数,定期检查集群中每个节点的负载情况。
如图2所示,根据实际使用需求,首先对集群中的计算节点添加相应的标签。当用户指定应用场景、提交训练需求、创建pod时,节点标签选择器会根据该pod指定的信息,选择有相应标签的节点进行调度。
其次,根据使用需求设置节点计分时的权值因子以及计时器监控周期等参数。按照计时器设定的周期时间,定期检查集群中每个节点的负载情况。
然后通过使用集群中节点cpu占用率、内存利用率等数据,在调度器的打分阶段进行计算、衡量节点忙闲程度。
进一步地,所述对同一使用场景中的节点的忙闲程度进行打分的计算公式为:
score(pi)=λcpu×ccpu×score(cpui)+λmemory×score(memoryi),其中,ccpu表示第i个节点的cpu核数,score(cpui)表示cpu频率,score(memoryi)表示内存大小,λcpu表示ccpu的权重,λmemory表示score(memoryi)的权重;
所述load(ni)表示总负载,计算公式如下:
load(ni)=λcpu×u(cpui)+λmemory×u(memoryi),其中,u(cpui)表示第i个节点的cpu使用量,为u(memoryi)表示内存使用量。
其中,λcpu+λmemory=1,通过计算节点总得分平均值,若节点得分低于平均值,则该节点记录为忙碌节点,若节点得分不低于平均值,则程序结束。
将忙碌节点列表按得分升序排列,定义一个不超过1的n_sbusy值,所述n_sbusy代表列表中选取的靠前的忙碌节点个数占总节点个数的百分比,n_sbusy的选取根据实际使用情况来选取,为前n_sbusy的忙碌节点添加污点值noscheduler,表示不将pod调度到此节点;为剩余节点添加污点值prefernoscheduler,表示尽量不将pod调度到此节点。
尽可能地将pod调度到未被添加污点值的节点上,直至集群基本达到负载均衡。集群进入新的负载情况后,删除为节点添加的污点值,继续监测负载并调度pod。
该方案根据使用需求设置节点计分时的权值因子以及计时器监控周期参数,定期检查集群中每个节点的负载情况,周期性的调整集群的负载,保证集群负载的均衡,提高系统稳定性。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!