视频数据标注方法、系统、获取神经网络深度学习的数据源的方法及计算机可读存储介质与流程
本发明涉及数据标注技术领域,尤其涉及一种视频数据标注方法、系统、获取神经网络深度学习的数据源的方法及计算机可读存储介质。
背景技术:
深度学习(deeplearning)需要大量精细化标注的数据素材用于神经网络训练。目前获取数据的方法主要有三种:人工数据标注、自动数据标注、外包数据标注。人工标注可以得到较高可信度的数据,受限于人力资源以及需要巨大的数据基数,单纯的人工标注注定无法完成如此庞大的数据清洗。目前也有很多比较实用的客户端、web端的数据标记工具,极大的减轻了劳动力,同时也带来一些信息安全的风险。
技术实现要素:
为了克服上述技术缺陷,本发明的目的在于提供一种数据标注效率高、样本数据量大的视频数据标注方法、系统、获取神经网络深度学习的数据源的方法及计算机可读存储介质。
本发明公开了一种视频数据标注方法,包括如下步骤:人工标注目标视频内的部分数据,编写需要关注对象的内容与视频时间对齐的文本;通过计算机编程编写脚本将目标视频按照每秒n帧的速度分裂成图片,以时间戳命名所述图片的名称,根据所述时间戳获取每张图片所处的时间区间;依据所述文本内的内容,通过计算机编程编写脚本为每张图片生成描述性文件,所有图片的所述描述性文件组成所述目标视频的标注源数据;通过训练模型筛选出所述标注源数据中的异常图片,并通过人工审核确定所述异常图片,剔除所述异常图片后形成初始标注数据;剔除所述初始标注数据的重复图片,形成最终标注数据。
优选地,所述人工标注目标视频内的部分数据,编写需要关注对象的内容与视频时间对齐的文本包括:人工浏览目标视频一次性标注部分数据,坐标位置不变,被标记坐标的内容填写默认值,获得所有需要标记对象和分界点帧信息;浏览目标视频、关注需要标记对象的内容变化,并根据视频时间对齐标注该标记对象的内容,以形成需要关注对象的内容与视频时间对齐的txt文本。
优选地,所述通过训练模型筛选出所述标注源数据中的异常图片,并通过人工审核确定所述异常图片,剔除所述异常图片后形成初始标注数据包括:标注源数据的内容形式是文字、数字、实物照,通过训练模型对所述标注源数据进行识别得到识别结果;筛选出识别结果与标注内容不一致的异常图片;通过人工审核确定所述异常图片;剔除所述异常图片后,通过编写python可视化插件将所述标注源数据重新分类形成初始标注数据。
优选地,所述通过训练模型筛选出所述标注源数据中的异常图片,并通过人工审核确定所述异常图片,剔除所述异常图片后形成初始标注数据还包括:标注源数据的内容形式是文字、数字、实物照以外的新内容,则随机取所述标注源数据内的部分数据记为data0,其余部分记为data1;将data0分类训练成第一训练模型,使用所述第一训练模型挑选data1,经人工审核修正后的data1分类训练成第二训练模型,使用所述第二训练模型挑选data0,如此多次迭代形成所述初始标注数据。
优选地,所述剔除所述初始标注数据的重复图片,形成最终标注数据包括:计算所述初始标注数据的图片的phash值,获取不同图片之间的汉明值,从而去掉重复图片,形成最终标注数据。
一种视频数据标注系统,包括数据标注模块、计算机编程模块和数据校准模块;人工通过所述数据标注模块标注目标视频内的部分数据,编写所述标注数据的需要关注对象的内容与视频时间对齐的文本;通过所述计算机编程模块编写脚本将目标视频按照每秒n帧的速度分裂成图片,以时间戳命名所述图片的名称,根据所述时间戳获取每张图片所处的时间区间;依据所述文本内的内容,通过所述计算机编程模块编写脚本为每张图片生成描述性文件,所有所述图片的所述描述性文件组成所述目标视频的标注源数据;所述数据校准模块内储存有训练模型,通过训练模型筛选出所述标注源数据中的异常图片,并通过人工审核确定所述异常图片,剔除所述异常图片后形成初始标注数据;所述数据校准模块还剔除所述初始标注数据的重复图片,形成最终标注数据。
优选地,所述数据校准模块包括数据训练单元;标注源数据的内容形式是文字、数字、实物照,通过所述数据训练单元获取训练模型对所述标注源数据进行识别得到识别结果;所述数据校准模块筛选出识别结果与标注内容不一致的异常图片;通过人工审核确定所述异常图片;剔除所述异常图片后,通过编写python可视化插件将所述标注源数据重新分类形成所述初始标注数据;标注源数据的内容形式是文字、数字、实物照以外的新内容,则随机取所述标注源数据内的部分数据记为data0,其余部分记为data1;通过所述数据训练单元将data0分类训练成第一训练模型,使用所述第一训练模型挑选data1,经人工审核修正后的data1通过所述数据训练单元分类训练成第二训练模型,使用所述第二训练模型挑选data0,如此多次迭代形成所述初始标注数据。
优选地,所述数据校准模块还包括图像phash值计算单元,通过所述图像phash值计算单元计算所述初始标注数据的图片的phash值,获取不同图片之间的汉明值,从而去掉重复图片,形成最终标注数据。
本发明还公开了一种获取神经网络深度学习的数据源的方法,将上述任一所述的视频数据标注方法所获取的所述最终标注数据作为用于获取神经网络深度学习的数据源。
本发明还公开了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一所述的视频数据标注方法的步骤。
采用了上述技术方案后,与现有技术相比,具有以下有益效果:
1.本发明通过人工标注视频内的少量的核心数据,以这些核心帧的数据为基础,通过分界时刻点的数据标注拓展到整个区间段,以完成整段区间内的数据标记;再针对区间内的递增递减规律,进一步完成动态的被标注对象的信息采集记录,获取所述标注源数据,极大提高了人工标注的速度;
2.对所述标注源数据内的异常图片进行识别和挑选,并通过人工将挑选出的异常图片进行审核确认,剔除异常图片后提高标注数据的可信度;
3.通过模型对标注数据进行反复迭代训练,进一步提高标注数据的可信度;
4.扩大样本数据边际后,由于样本数据量十分大,还通过去除重复图片的过程保证标注数据的精度。
附图说明
图1为本发明提供的视频数据标注方法的流程图;
图2为本发明提供的一优选实施例的xml文件;
图3为本发明提供的一优选实施例的txt文本;
图4为本发明提供的另一优选实施例的流程图。
具体实施方式
以下结合附图与具体实施例进一步阐述本发明的优点。
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
在本公开使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本公开。在本公开和所附权利要求书中所使用的单数形式的“一种”、“”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
应当理解,尽管在本公开可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本公开范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,如在此所使用的词语“如果”可以被解释成为“在……时”或“当……时”或“响应于确定”。
在本发明的描述中,需要理解的是,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
在本发明的描述中,除非另有规定和限定,需要说明的是,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是机械连接或电连接,也可以是两个元件内部的连通,可以是直接相连,也可以通过中间媒介间接相连,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
在后续的描述中,使用用于表示元件的诸如“模块”、“部件”或“单元”的后缀仅为了有利于本发明的说明,其本身并没有特定的意义。因此,“模块”与“部件”可以混合地使用。
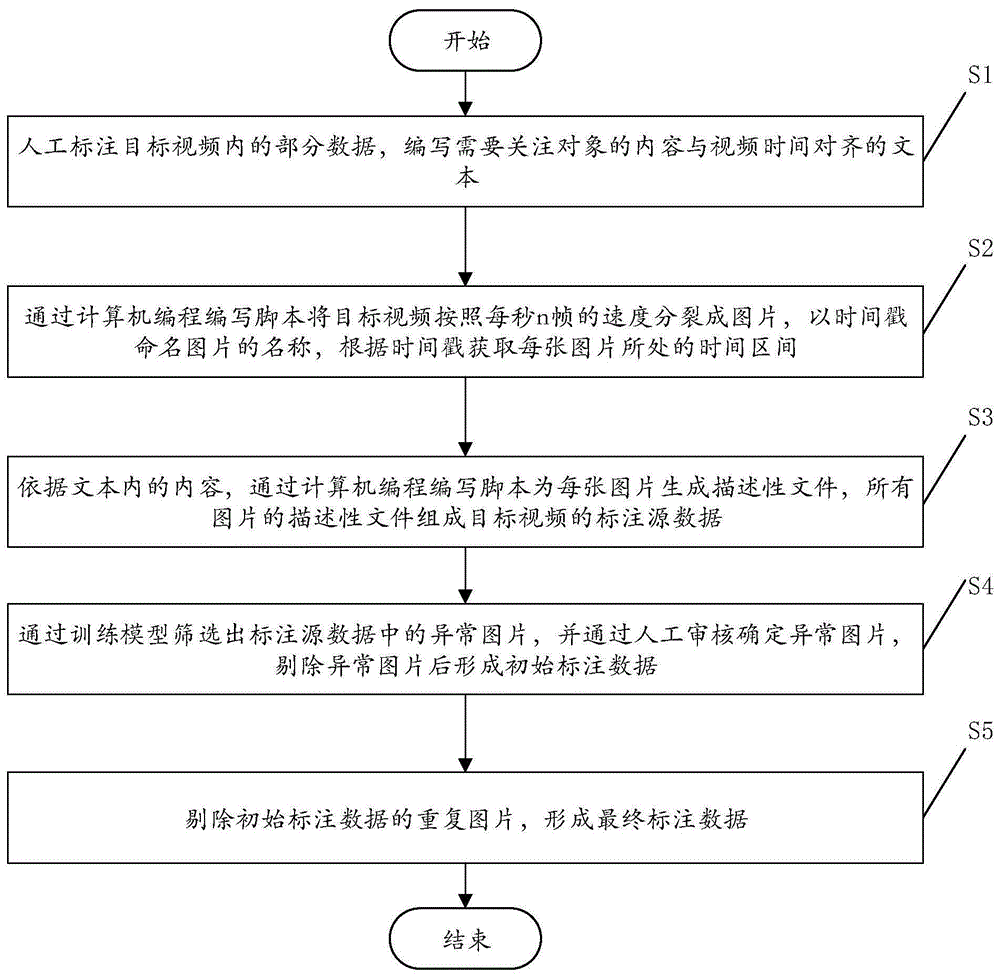
参见附图1,本发明公开了一种视频数据标注方法,包括:
s1、人工标注目标视频内的部分数据,编写需要关注对象的内容与视频时间对齐的文本;
s2、通过计算机编程编写脚本将目标视频按照每秒n帧的速度分裂成图片,以时间戳命名图片的名称,根据时间戳获取每张图片所处的时间区间;
s3、依据文本内的内容,通过计算机编程编写脚本为每张图片生成描述性文件,所有图片的描述性文件组成目标视频的标注源数据;
s4、通过训练模型筛选出标注源数据中的异常图片,并通过人工审核确定异常图片,剔除异常图片后形成初始标注数据;
s5、剔除初始标注数据的重复图片,形成最终标注数据。
本发明通过步骤s1、步骤s2和步骤s3生成标注源数据,即人工标注视频内的少量的核心数据,以这些核心帧的数据为基础,通过分界时刻点的数据标注拓展到整个区间段,以完成整段区间内的数据标记;再针对区间内的递增递减规律,进一步完成动态的被标注对象的信息采集记录,提高了人工数据标注效率的90%,将原本1小时视频的标注工作量从5小时减少到30分钟以内。
较佳地,骤s1具体包括:人工浏览目标视频一次性标注部分数据,坐标位置不变,被标记坐标的内容填写默认值,获得所有需要标记对象和分界点帧信息,;浏览目标视频、关注需要标记对象的内容变化,并根据视频时间对齐标注该标记对象的内容,以形成需要关注对象的内容与视频时间对齐的txt文本,参见附图3。
一优选实施例,需要标记对象和分界点帧信息的xml数据参见附图2,需要关注对象的内容与视频时间对齐的txt文本参见附图3。附图3中的[00:03:11-00:19:54,playing]表示被标注对象label为playing;[00:03:17-00:11:17,time,00-10-08-10]表示被标注对象label为time,而该区间内对应的比赛时间为[00:10-08:10],据此可以标记每一帧图片的比赛时刻。
本发明所采用的计算机编程语言为python,步骤s2具体为,编写python脚本将视频按照2帧/秒分裂成图片,以时间戳命名图片的名称,根据时间戳获取每张图片所处的时间区间,例如图片*_00066.jpeg对应视频第33秒钟。
步骤s3具体为,编写python脚本将步骤s2中生成的图片,依据步骤1中的xml和txt为每张图片生成描述性的xml文件,例如图片*_00066.jpeg对齐文件*_00066.xml,据此获得整部视频的标注源数据rawdata。
较佳地,为了提高标注数据的可信度,需要对所述标注源数据内的异常图片进行识别和挑选,并通过人工将挑选出的异常图片进行审核确认后剔除异常图片,针对两种不同的标注源数据的内容形式,具体包括两种处理方法:
1.标注源数据的内容形式是文字、数字、实物照,通过训练模型对标注源数据进行识别得到识别结果;筛选出识别结果与标注内容不一致的异常图片及其对应的xml文件;为了避免计算机的识别故障,还需通过人工审核确定异常图片后将异常图片剔除,再通过编写python可视化插件将标注源数据重新分类形成初始标注数据。
2.标注源数据的内容形式是文字、数字、实物照以外的新内容,则随机取标注源数据内的部分数据记为data0,其余部分记为data1;将data0分类训练成第一训练模型,使用第一训练模型挑选data1,经人工审核修正后的data1分类训练成第二训练模型,使用第二训练模型挑选data0,如此多次迭代形成初始标注数据。
经过上述两种的数据识别,提高标注数据的可信度。
较佳地,为了获得更大样本量,需要不断增加标注数据,而得到源源不断的可信度较高的rawdata。由于rawdata是根据视频分帧得到的,没有区分差异性,随着样本数量的不断增多,因此需要去重复。计算初始标注数据的图片的phash值,获取不同图片之间的汉明值,从而去掉重复图片,形成最终标注数据。
本发明还公开了一种视频数据标注系统,包括:
数据标注模块,用于对视频进行数据标注;
计算机编程模块,优选实施例选择python进行计算机编程;
数据校准模块,用于对rawdata进行纠偏和去重复,提高数据的可信度。
具体的,人工通过数据标注模块标注目标视频内的部分数据,编写标注数据的需要关注对象的内容与视频时间对齐的文本,再通过计算机编程模块编写脚本将目标视频按照每秒n帧的速度分裂成图片,以时间戳命名图片的名称,根据时间戳获取每张图片所处的时间区间;依据文本内的内容,通过计算机编程模块编写脚本为每张图片生成描述性文件,所有图片的描述性文件组成目标视频的标注源数据。
数据校准模块内储存有训练模型,通过训练模型筛选出标注源数据中的异常图片,并通过人工审核确定异常图片,剔除异常图片后形成初始标注数据;数据校准模块还剔除初始标注数据的重复图片,形成最终标注数据。
具体地,数据校准模块包括数据训练单元。
当标注源数据的内容形式是文字、数字、实物照时,通过数据训练单元获取训练模型对标注源数据进行识别得到识别结果,数据校准模块筛选出识别结果与标注内容不一致的异常图片,通过人工审核确定异常图片后将异常图片剔除,再通过编写python可视化插件将标注源数据重新分类形成初始标注数据。一种优选实施例的数据训练单元为通过第三方的公共接口导入的外部程序。
当标注源数据的内容形式是文字、数字、实物照以外的新内容,或者因安全风险不宜使用第三方公共接口时,则随机取标注源数据内的部分数据记为data0,其余部分记为data1;通过数据训练单元将data0分类训练成第一训练模型,使用第一训练模型挑选data1,经人工审核修正后的data1通过数据训练单元分类训练成第二训练模型,使用第二训练模型挑选data0,如此多次迭代形成初始标注数据。
较佳地,数据校准模块还包括图像phash值计算单元,通过图像phash值计算单元计算初始标注数据的图片的phash值,获取不同图片之间的汉明值,从而去掉重复图片,形成最终标注数据。
本发明还公开了本发明还公开了一种获取神经网络深度学习的数据源的方法,将上述任一的视频数据标注方法所获取的最终标注数据作为用于获取神经网络深度学习的数据源,可克服现有技术的人工标注数据效率低、样本数据量少等问题。
参见附图4,本发明提供一种用于获取神经网络深度学习的训练数据的优选实施例,step1为通过人工标注的信息分裂出所有的数据集,记为sourcedata;step2为裁剪出需要参与训练的数据,记为rawdata;step3为初步筛选rawdata;step4为可视化插件人工审核被模型识别出异常的图片,修正后重新回归至rawdata;step5为去重复,得到最终的参与训练的数据,记为traindata。
本发明还公开了本发明还公开了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述任一的视频数据标注方法的步骤。
应当注意的是,本发明的实施例有较佳的实施性,且并非对本发明作任何形式的限制,任何熟悉该领域的技术人员可能利用上述揭示的技术内容变更或修饰为等同的有效实施例,但凡未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何修改或等同变化及修饰,均仍属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!