基于Transformer模型的INT8离线量化及整数推断方法
本发明涉及自然语言处理技术领域,更具体地说,涉及一种基于transformer模型的自然语言处理神经网络模型的int8(8位整型)离线量化方法及整数推断方法。
背景技术:
随着深度学习算法的出现,人工智能迎来了第三次爆发,而深度学习算法的参数量和计算复杂性的增长对硬件提出了更高的性能要求,设计深度学习领域的专用硬件加速器是解决这一需要的有效办法。如何减少深度神经网络计算的延迟和存储是神经网络算法落地和神经网络加速器设计的重要研究方向。
模型量化是解决上述问题的理想技术方法。一般情况下,自然语言处理模型的训练和推断阶段使用的都是单精度浮点数类型完成,但是浮点数计算会占用大量的计算资源和存储资源,执行速度也很慢。使用低比特的数据格式,计算逻辑相对简单,可以提高计算效率的同时降低功耗和资源消耗。与单精度浮点数计算相比,采用int8运算最多可以节省30倍的计算能耗和116倍的芯片面积。因此,模型量化广泛应用于深度神经网络的压缩和加速。离线量化不需要进行反向传播,直接将训练好的模型进行量化,可以减少深度学习模型的部署时间。
transformer模型作为自然语言处理领域新的通用模型,在各方面表现全面超越lstm等传统神经网络所付出的代价是模型复杂度和网络参数量的倍增,导致对计算能力和功耗的需求的急剧提高,使得它们难以在边缘设备中运行。将现有的卷积神经网络的int8离线量化方法直接使用到transformer模型会带来精度损失。为了减少int8量化带来的精度损失和提高边缘加速器的推断效率,急需一种针对transformer浮点模型进行优化int8离线量化及整数推断方法。
技术实现要素:
为克服现有技术中的缺点与不足,本发明的目的在于提供一种基于transformer模型的int8离线量化及整数推断方法;该方法可减少模型计算所需硬件资源和模型量化带来的误差,为硬件加速器的设计提供数据量化和量化模型推断的技术方案。
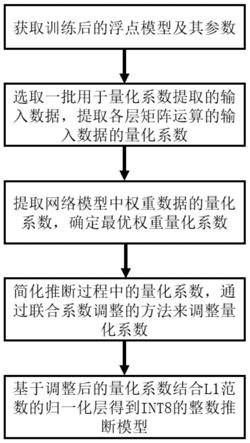
为了达到上述目的,本发明通过下述技术方案予以实现:一种基于transformer模型的int8离线量化及整数推断方法,包括如下步骤:
s1,将原始transformer浮点模型中归一化层的l2范数转换成l1范数;之后对transformer浮点模型进行模型训练,获取训练后的浮点模型及其参数;
s2,通过少量数据进行前向推断,获取浮点模型中各层矩阵运算的输入数据的量化系数,提取为一般浮点数据;
s3,根据训练完的浮点模型,获取浮点模型中各线性层的权重量化系数,提取为一般浮点数据,根据计算均方误差的方法确定各线性层中的最优权重量化系数;
s4,将推断过程中涉及量化操作的量化系数化为2-n的浮点数形式,通过联合系数调整的方法来调整量化系数;
s5,基于调整后的量化系数结合l1范数的归一化层得到int8的整数推断模型。
进一步地,所述步骤s1中,根据以下公式进行归一化层的计算:
其中,x是输入数据,μ表示输入数据所在行的平均值,α和β是浮点模型中的可训练参数,n代表的是行的大小,
进一步地,所述步骤s2包括以下步骤:
s21,选取一批浮点模型输入数据;
s22,采用选取的浮点模型输入数据,使用训练后的浮点模型进行前向推断,获取浮点模型中各层矩阵运算的输入数据的分布;
s23,根据获取的浮点模型中各层矩阵运算的输入数据的分布,采用步骤s2中的计算方法确定输入数据的量化系数,对所求得的量化系数进行平均,得到每一层矩阵运算输入数据的量化系数,提取为一般浮点数据,记为sinput,使每个矩阵运算都有一个量化系数sinput:
其中,n代表浮点模型输入数据的大小,xi代表第i个浮点模型输入数据计算的所求矩阵的输入数据,max表示取矩阵的最大值,abs表示取矩阵的绝对值。
进一步地,所述步骤s3包括以下分步骤:
s31,根据以下公式计算所述各线性层的权重数据和偏置数据的量化系数,提取为一般浮点数据,分别记为sw和sb,使每组权重数据和偏置数据都有一个量化系数:
sw=max(abs(w))/127
sb=sinput*sw
其中,sinput为步骤s2获取的该线性层矩阵运算的输入数据的量化系数,max表示取权重权重最大值,abs表示取权重矩阵绝对值;
s32,根据权重数据的量化系数sw计算量化后的int8类型的权重数据qw:
其中,w是权重数据,round表示通过四舍五入进行浮点数的取整操作,clip表示对数据在所限定范围内进行截断;
s33,根据获取的int8类型的权重数据qw和权重数据的量化系数sw计算量化前后权重数据的均方误差,找到该层权重数据的最佳量化系数sw,使得均方误差最小:
进一步地,在所述步骤s33之后,还包括:
s34,通过步骤s31获取的权重数据的量化系数sw,重新通过步骤s32的计算公式计算新的int8类型的权重数据qw,根据步骤s32和s33迭代求解qw和sw,寻找最佳的量化系数sw。
进一步地,所述步骤s4包括以下分步骤:
s41,提取步骤s2和s3得到的量化系数sinput和sw;
s42,将推断过程中的涉及量化操作的量化系数化为2-n的浮点数形式,通过移位完成数据传递过程中的量化系数传递,确保每一层矩阵运算在整数域进行;
s43,对量化系数进行联合调整,通过对自注意力层和前馈神经网络计算层内部的权重数据进行缩放来完成量化系数的联合调整,以减少将量化系数化为2-n的浮点数形式带来的计算误差。
进一步地,所述自注意力层包括两部分;自注意力层的第一部分包含查询向量的线性层计算、键向量的线性层计算和两个线性层结果的点积计算;为了保持softmax函数的输入数据的原始度,减少将量化系数化为2-n的浮点数形式带来的计算误差,通过对查询向量的线性层计算和键向量的线性层计算进行同等比例但是反向的缩放:
γk`=γwkk+γbk
k`=γk`
其中,q表示查询向量,k表示键向量,q`表示查询向量线性层的输出,k`表示键向量线性层的输出,wq表示查询向量线性层的权重,wk表示键向量线性层的权重,bq表示查询向量线性层的偏置,bk表示键向量线性层的偏置,γ表示缩放系数;缩放系数γ通过公式中的权重和偏置进行调整,缩放系数γ的值决定于量化带来的计算误差最小。
优选地,自注意力层的第二部分包括值向量的线性层计算、softmax计算的结果和值向量的加权求和计算和输出线性层计算;为了保持自注意力层输出的原始度,减少将量化系数化为2-n的浮点数形式带来的计算误差,通过对值向量的线性层计算和输出线性层计算进行同等比例但是反向的缩放:
其中,v表示值向量,v`表示值向量线性层的输出,wv表示值向量线性层的权重,bv表示值向量线性层的偏置,wo表示输出线性层的权重,bo表示输出线性层的偏置,y表示输出线性层的输出,λ表示缩放系数;缩放系数λ通过公式中的权重和偏置进行调整,缩放系数λ的值决定于量化带来的计算误差最小。
优选地,所述前馈神经网络计算层包括两层线性层,线性层中间的relu函数为线性函数,满足性质:
f(αx)=αf(x),α>0
为了保持输出结果的原始度,减少将量化系数化为2-n的浮点数形式带来的计算误差,通过第一层线性层的权重和偏置和第二层线性层的权重进行同等比例但是反向的缩放:
其中,l1表示第一层线性层的输入,l表示第一层线性层的输出,wl1表示第一层线性层的权重,bl1表示值第一层线性层的偏置,wl2表示第二层线性层的权重,bl2表示第二层线性层的偏置,y代表第二层线性层的输出,μ表示缩放系数;缩放系数μ通过公式中的权重和偏置进行调整,缩放系数μ的值决定于量化带来的计算误差最小。
进一步地,所述步骤s5是指:将原始transformer浮点模型中归一化层的l2范数转换成l1范数,以直接代入量化后的整数型输入,计算得到归一化层的浮点数计算结果;将步骤s2和s4得到的量化系数代入到归一化层转换成l1范数后的模型中,将模型中的矩阵运算转化到整数域,得到transformer整数推断模型。
除了softmax激活函数的计算外,可完成整个模型的整数推断过程,包含所有矩阵的乘法、加法和归一化操作。
与现有技术相比,本发明具有如下优点与有益效果:
(1)本发明提供了一种可以用于transformer模型的整数推断方法,得到的整数推断模型中所有矩阵运算和归一化操作都在整数域进行,且量化后的模型精度损失小,可降低硬件资源消耗和提高模型的推断速度,有效降低对于计算平台的算力和存储要求,为加速器设计提供了模型部署方案;
(2)本发明将量化系数化为2-n的浮点数形式,通过移位操作完成数据传递过程中的量化计算,完成量化推理中的量化和去量化过程,降低硬件计算成本,提高运算速度;
(3)本发明通过计算均方误差和基于transformer模型的量化系数联合调整等操作,对量化系数进行微调,使量化后的模型保持极小的精度损失,满足实际应用需求。
附图说明
图1是本发明的基于transformer模型的int8离线量化及整数推断方法的流程图;
图2是本发明中自注意力层整数推断方法;
图3是本发明中前馈神经网络计算层整数推断方法。
具体实施方式
下面结合附图与具体实施方式对本发明作进一步详细的描述。
实施例一:
如图1所示,本实施例的一种基于transformer模型的int8离线量化及整数推断方法,包括如下步骤:
s1,将原始transformer浮点模型中归一化层的l2范数转换成l1范数;之后对transformer浮点模型进行模型训练,获取训练后的浮点模型及其参数。
根据以下公式进行归一化层的计算:
其中,x是输入数据,μ表示输入数据所在行的平均值,α和β是浮点模型中的可训练参数,n代表的是行的大小,
s2,通过少量数据进行前向推断,获取浮点模型中各层矩阵运算的输入数据的量化系数,提取为一般浮点数据。
所述步骤s2包括以下步骤:
s21,选取一批浮点模型输入数据;
s22,采用选取的浮点模型输入数据,使用训练后的浮点模型进行前向推断,获取浮点模型中各层矩阵运算的输入数据的分布;
s23,根据获取的浮点模型中各层矩阵运算的输入数据的分布,对所求得的量化系数进行平均,得到每一层矩阵运算输入数据的量化系数,提取为一般浮点数据,记为sinput,使每个矩阵运算都有一个量化系数sinput:
其中,n代表浮点模型输入数据的大小,xi代表第i个浮点模型输入数据计算的所求矩阵的输入数据,max表示取矩阵的最大值,abs表示取矩阵的绝对值。
s3,根据训练完的浮点模型,获取浮点模型中各线性层的权重量化系数,提取为一般浮点数据,根据计算均方误差的方法确定各线性层中的最优权重量化系数;
所述步骤s3包括以下步骤:
s31,根据以下公式计算所述各线性层的权重数据和偏置数据的量化系数,提取为一般浮点数据,分别记为sw和sb,使每组权重数据和偏置数据都有一个量化系数:
sw=max(abs(w))/127
sb=sinput*sw
其中,sinput为步骤s2获取的该线性层矩阵运算的输入数据的量化系数,max表示取权重权重最大值,abs表示取权重矩阵绝对值;
s32,根据步骤s31中确定的权重数据的量化系数sw计算量化后的int8类型的权重数据,记为qw:
其中,w是权重数据,sw为该权重数据的量化系数,round表示通过四舍五入进行浮点数的取整操作,clip表示对数据在所限定范围内进行截断;
s33,根据步骤s32中获取的int8类型的权重数据qw和权重数据的量化系数sw计算量化前后权重数据的均方误差,找到该层权重数据的最佳量化系数sw,使得均方误差最小:
优选方案是:在所述步骤s33之后,还包括:
s34,通过步骤s31获取的权重数据的量化系数sw,重新通过步骤s32的计算公式计算新的int8类型的权重数据qw;根据步骤s32和s33迭代求解qw和sw,寻找最佳的量化系数sw。
s4,将推断过程中涉及量化操作的量化系数化为2-n的浮点数形式,通过联合系数调整的方法来调整量化系数。
所述步骤s4包括以下步骤:
s41,提取步骤s2和s3得到的量化系数sinput和sw,选择最优的量化系数用于模型计算中的浮点数据量化;
s42,将推断过程中的涉及量化和去量化操作的量化系数化为2-n的浮点数形式,通过移位完成数据传递过程中的量化系数传递,确保每一层矩阵运算在整数域进行;
s43,对量化系数进行联合调整,为了减少将量化系数化为2-n的浮点数形式带来的计算误差,通过对自注意力层和前馈神经网络计算层内部的权重数据进行缩放来完成量化系数的联合调整。
自注意力层包括两部分,自注意力层的第一部分包含查询向量的线性层计算、键向量的线性层计算和两个线性层结果的点积计算。为了保持softmax函数的输入数据的原始度,减少将量化系数化为2-n的浮点数形式带来的计算误差,通过对查询向量的线性层计算和键向量的线性层计算进行同等比例但是反向的缩放:
γk`=γwkk+γbk
k`=γk`
其中,q表示查询向量,k表示键向量,q`表示查询向量线性层的输出,k`表示键向量线性层的输出,wq表示查询向量线性层的权重,wk表示键向量线性层的权重,bq表示查询向量线性层的偏置,bk表示键向量线性层的偏置,γ表示缩放系数。缩放系数γ通过公式中的权重和偏置进行调整,缩放系数γ的值决定于量化带来的计算误差最小。
自注意力层的第二部分包括值向量的线性层计算、softmax计算的结果和值向量的加权求和计算和输出线性层计算。为了保持自注意力层输出的原始度,减少将量化系数化为2-n的浮点数形式带来的计算误差,通过对值向量的线性层计算和输出线性层计算进行同等比例但是反向的缩放:
其中,v表示值向量,v`表示值向量线性层的输出,wv表示值向量线性层的权重,bv表示值向量线性层的偏置,wo表示输出线性层的权重,bo表示输出线性层的偏置,y表示输出线性层的输出,λ表示缩放系数。缩放系数λ通过公式中的权重和偏置进行调整,缩放系数λ的值决定于量化带来的计算误差最小。
前馈神经网络计算层包括两层线性层,线性层中间的relu函数为线性函数,满足性质:
f(αx)=αf(x),α>0
为了保持输出结果的原始度,减少将量化系数化为2-n的浮点数形式带来的计算误差,通过第一层线性层的权重和偏置和第二层线性层的权重进行同等比例但是反向的缩放:
其中,l1表示第一层线性层的输入,l表示第一层线性层的输出,wl1表示第一层线性层的权重,bl1表示值第一层线性层的偏置,wl2表示第二层线性层的权重,bl2表示第二层线性层的偏置,y代表第二层线性层的输出,μ表示缩放系数。缩放系数μ通过公式中的权重和偏置进行调整,缩放系数μ的值决定于量化带来的计算误差最小。
s5,将原始transformer浮点模型中归一化层的l2范数转换成l1范数;将步骤s2和s4得到的量化系数代入到归一化层转换成l1范数后的模型中,将模型中的矩阵运算转化到整数域,得到transformer整数推断模型。
实施例二
本实施例的一种基于transformer模型的int8离线量化及整数推断方法,在步骤s43中,自注意力层整数推断方法是:如图2所示,输入量化得到的int8类型的查询向量q、键向量k和值向量v,与量化后的权重数据进行线性层计算和注意力计算,通过移位操作完成矩阵运算间的量化操作,将计算的整数结果与查询向量进行残差连接输入到l1范数的归一化层进行输出。
前馈神经网络计算层整数推断方法是:如图3所示,直接将量化后的输入数据和第一层线性层的量化后的权重数据进行线性层计算,通过移位得到int8类型计算结果,经过relu函数计算,输入到第二层线性层与量化后的权重数据进行线性层计算,与输入数据进行残差连接输入到l1范数的归一化层进行输出。
本实施例的其余步骤与实施例一相同。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!