一种基于XGBoost算法的个体出行行为预测方法、系统及终端
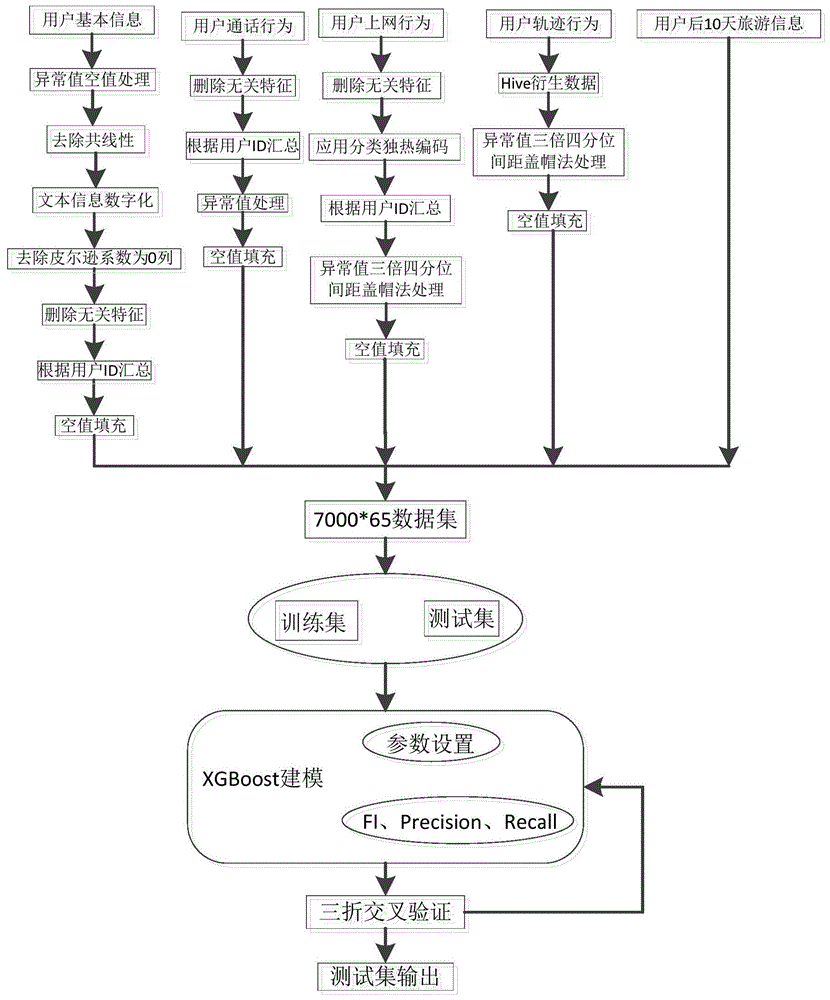
本发明属于大数据模型预测
技术领域:
,具体涉及一种基于xgboost算法的个体出行行为预测方法、系统及终端。
背景技术:
:近年来,随着移动互联网和信息科技的蓬勃发展,数据的重要性日益凸显。在打造数字经济高地的时代进程中,数据流助推技术流、资金流、人才流、物资流,在促进社会生产率提升,推动创新发展方面发挥着重要作用。例如,利用数据可以帮助对个人的行为或需求进行预测,这在商业推广、广告分发中已有广泛应用。理论上说,通过大数据应当也可以对人体的出行行为进行预测,从而为处理一些公共管理事务提供帮助。在新冠肺炎疫情爆发期间,多国政府为了整体的公共利益考量,实施了对部分人群进行出行自由约束的政策。而在人群的出行自由限制被放开之后,人们的出行需求可能会出现补偿性爆发。因此,如何在出行需求爆发前,对人群中个体的出行行为进行预测,从而根据预测结果科学地为社会管理其它各项事务做好提前规划,成为相关的管理部门需要解决的重要问题;这对于降低人群聚集对交通、餐饮、旅游等行业造成冲击,以及预防发生人群超额聚集引发安全事件具有重大意义。但是,目前还没有一种较好的方法可以利用既有数据,实现对个体出行行为决策的准确预测。技术实现要素:针对现有技术中的问题,本发明提供一种基于xgboost算法的个体出行行为预测方法、系统及终端,该方法、系统或终端可以解决现有技术无法准确预测个体出行行为决策的问题。为了达到上述目的,本发明是通过以下技术方案来实现的:一种基于xgboost算法的个体出行行为预测方法,该方法包括如下步骤:s1:获取用于表征用户行为特征的历史数据,历史数据包括用户基本信息、近三个月的用户通话行为数据、近三个月的用户上网行为数据,以及近三个月的用户轨迹行为数据;s2:对获取的历史数据进行预处理得到样本数据集,并使用样本数据集中的部分作为预训练数据集,其余作为预测数据集;其中,所述预训练数据集中包括训练集和测试集;s3:构建基于xgboost算法的个体出行行为的预测模型;所述预测模型的构建方法包括如下步骤:s31:使用cart回归树构造xgboot的分类器;通过不断进行特征分裂来添加树的数量,从而学习新的函数并拟合上一侧预测的残差;s32:将cart树中某棵树中子节点的分数累加获得某个树的分数和,再将所有树的得分累加获得样本的预测值;s33:构造算法模型的目标函数,所述目标函数包括损失函数部分和正则项部分;s34:使用加法训练分布优化目标函数,依次优化cart中的每一棵树,并在最优树的基础上使得目标函数最小,完成损失函数部分的构造;s35:通过对cart树的重新定义,完成对目标函数中正则化项的定义,确定正则项部分的函数;s36:利用前述函数求取cart树中各叶子节点的最佳值,以及当前目标函数的值;s4:设定预测模型的超参数,通过分层三折交叉差分器对预测模型进行超参数调整,并利用预训练数据集对预测模型进行训练,直到所述预测模型达到评价指标的要求;s5:采用预测数据集作为作为输入样本,利用训练好的预测模型对样本输出进行输出,从预测模型的输出中获得关于用户出行行为决策的预测结果。进一步地,步骤s1中获取的历史数据来源是政府的政务开放数据和通信运营商收集的真实用户数据。进一步地,步骤s2中,历史数据的预处理过程包括如下步骤:s21:对用户基本信息的表处理:s211:发现数据变量中的异常值,对在网时长一列中小于0的异常值进行空值处理;s212:通过特征变量的热力图发现特征变量之间的共线性,删除数据中共线值超过0.9的所有列;s213:对数据中的文本信息进行数值化处理,终端操作系统类型统一划分为安卓和ios系统,分别用0和1进行表示;s214:根据所有特征变量和目标变量的皮尔逊相关系数,皮尔逊相关系数为0的列删除;并删除与训练无关的终端型号,终端品牌和终端首次使用时间的相关列;s215:根据用户的id来对特征变量信息进行汇总统计,对其中的空值使用平均值或众数进行填充;s22:对用户通话行为的表处理:s221:删除与训练无关的对端号码编号和通话起始时间的相关列;s222:根据用户id对特征变量采用总和或众数进行汇总统计,对归属局和对端号长途区号的列中的异常值进行数字化处理;对缺失值采用众数进行填充;s23:对用户上网行为的表处理:s231:删除与训练无关的应用名称和数据日期的相关列;并对应用分类相关列采用独热编码处理;s232:根据用户id对特征变量中的访问次数和访问流量进行求和汇总,并对应用分类独热编码的所有特征变量使用众数进行汇总统计;s233:对发现的特征变量中的异常值采用三倍四分位间距盖帽法进行处理;s234:对各特征变量中存在的空值采用众数进行填充;s24:对用户轨迹行为的表处理:s241:通过数据仓库工具hive根据用户id和是否省内4a级以上景区两列来标记当前经纬度是否为景区,并基于此衍生出所有用户的总停留时间,景区停留时间和非景区停留的时间三列数据;s242:发现特征变量中的异常值,采用三倍四分间距盖帽法对异常值进行处理s243:对特征变量中存在的空值采用众数进行填充;其中,所述相关数据的预处理方法步骤中,各特征变量的异常值均通过绘制相关变量箱线图的方法来发现。步骤s31中,cart回归树是假设二叉树,其表达式为:r1(j,s)={x|x(j)≤s}andr2(j,s)={x|x(j)>s}上式中,r1(j,s)和r2(j,s)分别表示左棵子树和右棵子树,j表示数据中第j个特征,s表示切分点;决策二叉树中,若树节点是基于数据中第j个特征值进行分裂,当特征值小于s时,样本划分为左棵子树,当特征值大于s时,则划分为右棵子树。进一步地,步骤s32中,某棵树的得分采用如下函数计算:上式中,表示第i个样本的预测值,k表示树的棵树,f表示所有的cart树,f表示某一棵具体的cart树,fk(xi)为样本在某棵树中叶子节点得到的分数。进一步地,步骤s33-s35中,目标函数的表达式为:上式中,l表示树模型经验损失函数,yi表示第i个样本的真实值,ω表示回归树正则化项;其中,上式左边表示损失函数,右边为正则化项;损失函数的函数表达式为:上式中,gi表示第i个叶子节点的一阶偏导,hi第i个叶子节点的二阶偏导;正则化项表达式为:上式中,γ和λ表示权衡因子,ωj表示第j个叶子节点的输出均值,t表示叶子节点的数量。进一步地,步骤s36中,各叶子节点的最佳值采用下式计算:上式中,gj和hj分别表示叶子节点j所包含样本的一阶偏导、二阶偏导累加之和,均为常数;此时的目标函数的值采用下式计算:上式中,t表示叶子节点的数量。进一步地,步骤s4中,预测模型中需要设置的超参数包括迭代模型类别、损失函数类别、学习率、树的深度、l1正则化参数、迭代次数;预测模型的评价指标包括准确率p、召回率r和f1值,三者的计算公式如下:上式中,tp表示的是实际是正样本预测为正样本的样本数,fp表示实际是负样本预测却为正样本的样本数,fn实际是正样本预测成负样本的样本数。本发明还包括一种基于xgboost算法的个体出行行为预测系统,该系统采用如前述的基于xgboost算法的个体出行行为预测方法,实现对个体出行行为的结果预测;预测系统包括:数据采集模块,其用于获取用于表征用户近期行为特征的历史数据,历史数据包括用户基本信息、近三个月的用户通话行为数据、近三个月的用户上网行为数据,近三个月的用户轨迹行为数据;采集的历史数据输出到预处理模块中;预处理模块,其用于对数据采集模块获取的历史数据进行预处理,得到所需的样本数据集;样本数据集输出到行为预测模块中;以及预测模块,其用于基于构建的预测模型,采用样本数据集中的预训练数据集对预测模型进行训练,并采用样本数据集中的预测数据集作为输入,获取包含用户出行行为预测结果的输出。本发明还包括一种基于xgboost算法的个体出行行为预测终端,该终端包括存储器、处理器以及存储在所述存储器上并可在处理器上运行的计算机程序,处理器执行如前述的基于xgboost算法的个体出行行为预测方法。本发明提供的一种基于xgboost算法的个体出行行为预测方法、系统及终端,具有如下的有益效果:1、本发明基于xgboost算法构建所需的预测模型,并利用用户真实的信息大数据进行用户未来省内旅游出行预测;用于预测的原始用户数据经过预处理,提取了模型预测所需的关键属性,因此获得的与预测结果的准确率和可靠性较高,同时该预测模型的召回率和f1值均具有较佳的表现。2、本发明中采用预测模型是一种加权回归模型,在应用过程中不需要做特征的归一化,可以自行选择特征,可以适应多种损失函数,因此具有更好的可操作性,可以降低数据处理的工作量和计算负担。3、本发明中的预处理过程中,考虑到了原始数据中的异常值和缺失值的问题,降低该部分数据对预测结果的影响;在属性选取时,考虑到了可通过大数据获取的绝大部分特征变量,同时在预测模型的构建上也进行了优选和改进,并优化了模型的部分参数;上述工作内容均为预测结果的准确性和可靠性提供了保障。附图说明附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:图1为本发明实施例1中基于xgboost算法的个体出行行为预测方法的方法流程图;图2为本发明实施例2的在网时长列的特征量箱线图;图3为本发明实施例2中用户基本信息表的热力图;图4为本发明实施例2的用户上网行为数据表中部分数据的表格;图5为本发明实施例2中用户上网行为数据表中访问次数类的箱线图;图6为本发明实施例2的用户轨迹行为数据表中部分数据的表格;图7为本发明实施例2中用户轨迹行为衍生数据表中部分数据的表格;图8为本发明实施例2的用户轨迹行为数据中总停留时间的箱线图;图9为本发明实施例2中基于xgboost算法的个体出行行为预测方法试验结果中f1值随迭代次数的变化曲线图;图10为本发明实施例3中基于xgboost算法的个体出行行为预测系统的模块示意图;图中标记为:1、数据采集模块;2、预处理模块;3、预测模块。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。实施例1如图1所示,本实施例提供一种基于xgboost算法的个体出行行为预测方法,该方法包括如下步骤:s1:获取用于表征用户行为特征的历史数据,历史数据包括用户基本信息、近三个月的用户通话行为数据、近三个月的用户上网行为数据,以及近三个月的用户轨迹行为数据;获取的历史数据来源是政府的政务开放数据和通信运营商收集的真实用户数据。s2:对获取的历史数据进行预处理得到样本数据集,并使用样本数据集中的部分作为预训练数据集,其余作为预测数据集;其中,所述预训练数据集中包括训练集和测试集;历史数据的预处理过程包括如下步骤:s21:对用户基本信息的表处理:s211:发现数据变量中的异常值,对在网时长一列中小于0的异常值进行空值处理;s212:通过特征变量的热力图发现特征变量之间的共线性,删除数据中共线值超过0.9的所有列;s213:对数据中的文本信息进行数值化处理,终端操作系统类型统一划分为安卓和ios系统,分别用0和1进行表示;s214:根据所有特征变量和目标变量的皮尔逊相关系数,皮尔逊相关系数为0的列删除;并删除与训练无关的终端型号,终端品牌和终端首次使用时间的相关列;s215:根据用户的id来对特征变量信息进行汇总统计,对其中的空值使用平均值或众数进行填充;s22:对用户通话行为的表处理:s221:删除与训练无关的对端号码编号和通话起始时间的相关列;s222:根据用户id对特征变量采用总和或众数进行汇总统计,对归属局和对端号长途区号的列中的异常值进行数字化处理;对缺失值采用众数进行填充;s23:对用户上网行为的表处理:s231:删除与训练无关的应用名称和数据日期的相关列;并对应用分类相关列采用独热编码处理;s232:根据用户id对特征变量中的访问次数和访问流量进行求和汇总,并对应用分类独热编码的所有特征变量使用众数进行汇总统计;s233:对发现的特征变量中的异常值采用三倍四分位间距盖帽法进行处理;s234:对各特征变量中存在的空值采用众数进行填充;s24:对用户轨迹行为的表处理:s241:通过数据仓库工具hive根据用户id和是否省内4a级以上景区两列来标记当前经纬度是否为景区,并基于此衍生出所有用户的总停留时间,景区停留时间和非景区停留的时间三列数据;s242:发现特征变量中的异常值,采用三倍四分间距盖帽法对异常值进行处理s243:对特征变量中存在的空值采用众数进行填充;其中,相关数据的预处理方法步骤中,各特征变量的异常值均通过绘制相关变量箱线图的方法来发现。s3:构建基于xgboost算法的个体出行行为的预测模型;xgboost算法是一种基于梯度提升算法以及决策树的改进型学习算法。其原理是使用迭代运算的思想,将大量的弱分类器转化成强分类器,以实现准确的分类效果。xgboost是boosting中的经典方法。boosting算法的宗旨是通过将许多弱分类器集成,构造一个强的分类器,其中,在本实施例中,xgboost使用的是cart回归树。所述预测模型的构建方法包括如下步骤:s31:cart回归树是假设二叉树,可以对特征不断地进行分裂,若树节点是基于数据中第j个特征值进行分裂,当特征值小于s时,则将样本划分为左棵子树,当特征值大于s时,则将样本划分为右棵子树,cart回归树的表达式如下所示:r1(j,s)={x|x(j)≤s}andr2(j,s)={x|xj>s}上式中,r1(j,s)和r2(j,s)分别表示左棵子树和右棵子树,j表示数据中第j个特征,s表示切分点;s32:xgboost算法思想在于不断的添加树,不断地进行特征分裂生长一棵树,通过每一次的添加,可以学习一个新的函数,拟合上一次预测的残差。在训练了k棵树以后,当需要预测某个样本的分数的时候,可以根据该样本的特征,每棵树都会得到一个子节点的分数,最后将每棵树中相应的得分加起来就是该样本的预测值;其中,某一棵树中的分数值由下式确定:上式中,表示第i个样本的预测值,k表示树的棵树,f表示所有的cart树,f表示某一棵具体的cart树,fk(xi)为样本在某棵树中叶子节点得到的分数。s33:通常设置目标函数来确定算法的每个参数是否是最佳的,在本实例中,xgboost目标函数定义为:上式中,l表示树模型经验损失函数,yi表示第i个样本的真实值,ω表示回归树正则化项;式中包含两个部分,左边为损失函数,右边为正则项,损失函数保证了衡量测分数和真实分数的差别。s34:模型建立后需要对数据进行训练,通过最小化目标函数找到最佳参数,本实例中使用加法训练分布优化目标函数,其步骤如下:s341:首先优化cart的第一棵树,然后优化第二棵,直到最后优化完k棵树为止,所述优化目标函数如下:上式中,表示第t次迭代后样本i的预测分数,表示前t-1棵树的预测得分,ft(xi)表示第t棵树的函数形式;s342:在优化的最后一步可以得到了一颗最优的cart树ft(xi),该棵树是在ft-1(xi)的基础上使得目标函数最小,即满足下式:上式中,constant为前t-1棵树的复杂度。s343:当考虑到使用的损失函数为mse时,上述表达式变为:而对于一般函数,我们将其泰勒二阶展开,则上式表达式进一步变为:上式中:s344:xgboost的目标是使目标函数最小化,因此将常数项去掉,可得构造的损失函数的表达式为:上式中,gi表示第i个叶子节点的一阶偏导,hi第i个叶子节点的二阶偏导。s35:通过对cart树的重新定义,确定xgboost中正则化项的定义;将cart树定义为如下的表达式:ft(x)=ωq(x),ω∈rt,q:rd→{1,2,…,t}上式中,t表示一棵树中的叶子节点数,由这些值组成了一个t维向量ω,q(x)是ω的一个映射,将样本分到某个叶子节点;ωq(x)表示这棵树对样本的预测值。在上述定义下,xgboost的正则化项定义为:上式中,γ和λ表示权衡因子,ωj表示第j个叶子节点的输出均值,t表示叶子节点的数量;在应用xgboost算法模型时,可以对γ和λ的取值进行人为设定,γ、λ值越大,模型越简单。s35:在新的定义下,目标函数进一步变形为:上式中,表示第i棵树对样本的预测值;对上述表达式进行简化得到:上式中,gj和hj分别表示叶子节点j所包含样本的一阶偏导、二阶偏导累加之和,均为常数,γ和λ表示权衡因子,ωj表示第j个叶子节点的输出均值,t表示叶子节点的数量;当第t棵cart树的结构确定之后,gj和hj都是确定的,因此可以通过下式分别求得各叶子节点的最佳值:上式中,gj和hj分别表示叶子节点j所包含样本的一阶偏导、二阶偏导累加之和,均为常数;以及求取此时目标函数的值:上式中,t表示叶子节点的数量。s4:设定预测模型的超参数,通过分层三折交叉差分器对预测模型进行超参数调整,并利用预训练数据集对预测模型进行训练,直到所述预测模型达到评价指标的要求;预测模型中需要设置的超参数包括迭代模型类别、损失函数类别、学习率、树的深度、l1正则化参数、迭代次数;预测模型的评价指标包括准确率p、召回率r和f1值,三者的计算公式如下:上式中,tp表示的是实际是正样本预测为正样本的样本数,fp表示实际是负样本预测却为正样本的样本数,fn实际是正样本预测成负样本的样本数。s5:采用预测数据集作为输入样本,利用训练好的预测模型对样本输出进行输出,从预测模型的输出中获得关于用户出行行为决策的预测结果。实施例2本实施例提供了一种如实施例的基于xgboost算法的个体出行行为预测方法,并在实施如实施例1的方法的基础上进行仿真试验(在其他实施例中可以不进行仿真实验,也可以采用其他实验方案进行试验以确定相关参数以及对个体出行行为的预测性能)。一、数据来源本实例中,采用安徽运营商用户的实际真实运营数据。提供了供10000用户的数据,其中7000用户的相关数据用于训练,3000用户的相关数据用于预测,自行从7000个用户中划分训练集、测试集。数据文件及其说明:在本实施例中,预测模型中的数据文件包括如下组成:(1).dataplus_public_userinfo_travel.csv说明:该数据包中含有10000用户的基本信息,每个用户每月一行记录,所有用户均有记录。(2).dataplus_public_comm_travel.csv说明:该数据包中含有10000用户的通话数据,每个用户多行记录,可能有用户无记录。(3).dataplus_public_net_travel.csv说明:该数据包中含有10000用户的上网数据,每个用户多行记录,可能有用户无记录。(4).dataplus_travel_train_trail.csv说明:该数据包中含有10000用户的前3个月轨迹信息(含是否出现在景区、景区名称两列),每个用户多行记录,可能有用户无记录。该数据包的数据字典如表1所示:表1:.dataplus_travel_train_trail.csv的数据字典(5).dataplus_travel_train_user.csv说明:该数据包中含有7000用户的后续10天省内旅游信息,每个用户一行记录,所有用户均有记录;该数据包的数据字典如表2所示:表2:.dataplus_travel_train_user.csv的数据字典:user_id用户标识抽样&字段脱敏in_flag省内游出行结果0:无出行;1:有出行二、原始数据的预处理过程2.1用户基本信息表处理原始用户基本信息数据中每条记录包含用户id、客户年龄、归属地市、归属显示等特征,其中,每个用户每个月有一条记录,总共30000行*40列条记录。本实施例中,如图2所示,绘制数据集的箱线图,可以看见其中有些变量存在着异常值,对在网时长一列的小于0的异常值初步进行空值处理。绘制如图3所示的数据集的所有特征变量的热力图,可以看见部分特征变量之间的共线性较高,在处理数据时删除所有共线性值超过0.9的列,只保留其中一列,减少矩阵的维度。对数据集中的文本信息进行数值化处理,把手机终端操作系统一列划分为安卓和ios两大系统,分别用0和1进行表示。根据所有特征变量和目标变量的皮尔逊相关系数,皮尔逊相关系数为0的列删除,与训练无关的终端型号,终端品牌和终端首次使用时间这三列删除。最后根据用户的id来对特征变量信息进行汇总统计,对其中空值使用平均值或众数来填充,处理后得到的是一个7000行*30列完整的dataframe。2.2用户通话行为表处理原始用户通话行为数据中每条记录包含用户id、对端号编码、通话时长等特征,其中每个用户有多条记录,总共3703119行*10列条记录,9879个用户的记录。本实例中,删除与训练无关的对端号码编号和通话起始时间两列,根据用户的id来对特征变量信息采用总和或众数进行汇总统计,其中归属局和对端号长途区号的列中的异常值进行数字化处理,对缺失值采用众数填充,最后我们得到一个7000行*8列的完整dataframe。2.3用户上网行为表处理原始用户上网行为数据如图4所示,每条记录包含用户id、应用名称、应用分类等特征,其中,每个用户有多条记录,总共2246083行*6列条记录,8879个用户的记录。本实施例中,删除与训练无关的应用名称和数据日期两列,对应用分类这一列采用独热编码处理变为23列。根据用户的id来对特征变量访问次数和访问流量两列求和汇总统计,应用分类独热编码的所有特征变量使用众数进行汇总统计。绘制如图5所示的特征数据的箱体图,发现访问次数最高的达到6000000次的异常值,采用三倍四分位间距盖帽法处理。最后,对存在的空值采用众数进行填充,处理后得到一个7000行*26列的完整dataframe。2.4用户轨迹行为表处理原始用户轨迹行为数据如图6所示,每条记录包含用户id、进入时间、离开时间等特征,其中每个用户有多条记录,总共68332348行*7列条记录,9933个用户的记录。考虑到轨迹行为数据集过大,通过数据仓库工具hive根据用户id和是否省内4a级以上景区(poi_tag=1)两列来标记为当前经纬度是否为景区。如图7所示,可衍生出所有用户的总停留时间,景区停留时间和非景区停留的时间。绘制数据中特征变量的箱线图,如图8所示,在箱线图中发现存在总停留时间最高的达到26490441.0分钟的异常值,已经远超过三个月的时间,采用三倍四分位间距盖帽法对其进行处理。最后对存在的空值采用众数进行填充,处理后得到一个7000行*4列的完整dataframe。三、模型参数确定为使实验结果更具有普遍性,本实施例将数据集划分为20%测试集和80%训练集。通过对xgboost算法使用分层三折交叉差分器进行超参数调整,使得模型更加稳定,具体参数设置如表3所示:表3:xgboost模型的超参数设置超参数类型取值迭代模型gbtree损失函数binary:logistic学习率0.01树的深度9l1正则化参数0.1迭代次数1100四、预测试验的结果对比在本实例中,采用xgboost、bdt、lr和gbdt+lr融合四种预测模型进行预测结果的对照试验,经过训练后各模型的评价指标参数如下表2所示:表2本实施例与其它算法模型评价指标的对比模型种类准确率p召回率rf1值xgboost0.88090.94290.9108lr0.55150.80020.6530gbdt0.83780.92390.8787gbdt+lr0.83940.92480.8800分析上述测试结果发现:本实施例提供的基于用户真实的信息大数据进行用户未来省内旅游出行预测模型,相对于对照组中选取gbdt、lr和gbdt+lr融合的三种模型而言,实验结果中各个评价指标包括准确率,召回率和f1值都优于其他模型。因此可以认为本实施例提供的预测方法确实解决了现有技术中预测个人出行行为的问题,同时该方法得出的预测结论还具有较高的准确性和可靠性。绘制本实施例中预测模型的f1值随迭代次数增加的变化曲线,所述曲线如图9所示,分析曲线可以发现,随着迭代次数的增加,xgboost模型f1值越来越好,在迭代次数为1100附近达到最大。实施例3如图10所示,本实施例提供一种基于xgboost算法的个体出行行为预测系统,该系统采用如实施例1的基于xgboost算法的个体出行行为预测方法,实现对个体出行行为的结果预测;该预测系统包括:数据采集模块,其用于获取用于表征用户近期行为特征的历史数据,历史数据包括用户基本信息、近三个月的用户通话行为数据、近三个月的用户上网行为数据,近三个月的用户轨迹行为数据;采集的历史数据输出到预处理模块中;预处理模块,其用于对数据采集模块获取的历史数据进行预处理,得到所需的样本数据集;样本数据集输出到行为预测模块中;以及预测模块,其用于基于构建的预测模型,采用样本数据集中的训练数据集对预测模型进行训练,并采用样本数据集中的预测数据集作为输入,获取包含用户出行行为预测结果的输出。实施例4本实施例提供一种基于xgboost算法的个体出行行为预测终端,该终端包括存储器、处理器以及存储在所述存储器上并可在处理器上运行的计算机程序,处理器执行如实施例1的基于xgboost算法的个体出行行为预测方法。以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1