用于卷积神经网络的滤波器裁剪方法及贝类自动分类系统
本发明涉及机器学习领域,尤其涉及用于卷积神经网络的滤波器裁剪方法及贝类自动分类系统。
背景技术:
生物分类学中的分类遵循分类学原理和方法,对生物的各种类群进行界、门、纲、目、科、属、种的等级划分。实际应用中,属于同一科的贝类图片特征具有高相似度且各类样本不均衡,对贝类分类研究提出了更高的要求。目前卷积神经网络(cnn)在物体种类识别方面有广泛的应用,而直接应用到同一科的贝类分类时,由于同科贝类特征相似,以及不同贝类样本分布不平衡和样本分类难度不平衡问题,cnn识别准确率较低,识别效果较差。
技术实现要素:
本发明所要解决的技术问题是:提供一种用于卷积神经网络的滤波器裁剪方法。
为解决上述技术问题,本发明所采用的技术方案是:
一种高相似度同科贝类自动分类方法,包括以下步骤:
s1、计算卷积神经网络的初始过滤器wl,j的重要度h(wl,j),进行排序,其中wl,j为第l卷积层中第j个过滤器的权重;
s2、对重要度h(wl,j)按照大小进行排序;
s3、裁剪掉重要度相对低的s%的过滤器;
s4、计算同一层中各过滤器之间的正交性度量;
s5、根据各过滤器间的正交性度量,选取正交性相对小的r%的相关过滤器,并裁剪掉其中重要度排名较低的过滤器;
s6、重新初始化裁剪后剩余的过滤器。
与现有技术相比,本发明具有如下技术效果:
本方法抑制了特征之间的相关性,更关注正交特征,捕获激活空间中的不同方向,提升分类模型的泛化能力,分类准确度得到提升。
在上述技术方案的基础上,本发明还可以做如下改进。
优选地,所述初始过滤器wl,j的重要程度h(wl,j),首先将wl,j的值离散化,划分至c个不同的容器,计算每个容器的概率pt,所述重要程度h(wl,j)按照如下公式计算:
采用上述进一步方案的有益效果是,这种以输出熵的评价标准衡量过滤器的信息重要性的方法,相比于过滤器范数和参数稀疏度等评价标准,本方法更为准确,且得到的评价指数更有区分性。
优选地,所述步骤s4,计算各过滤器之间的正交性度量,步骤如下:
s4-1、将表征滤波器的多维向量展开为k×k×c的1维向量f;其中k为滤波器的大小,c为滤波器的通道数;
s4-2、将层中所有的jl个f组合为矩阵wl,每个f占据一行;
s4-3、将矩阵wl做归一化处理得到
s4-4、根据
s4-5、根据相关性矩阵计算过滤器间的正交性度量:
其中,δλ表示其他过滤器对第i个过滤器的最小差异性,
采用上述进一步方案的有益效果是能够抑制特征之间的相关性,更关注模型的正交特征,并通过修复准则,重新捕获激活空间中的不同方向,提升模型泛化能力。
优选地,所述卷积神经网络采用的损失函数中包含正则化项l1:
其中,δ是正则化项的权重参数;i是与
优选地,所述卷积神经网络采用的损失函数中包含焦点损失项l2:
其中,通过放大(或减小)一个类别的αi值,控制该类别对总的损失的共享权重大小,模型会更重视(或更不重视)该类别的正确预测。根据一个类别真实标签对应的输出概率p(yi)确定该类别对应的γ,当一个贝类样本是易分类样本时,例如p(yi)=0.9,γ=3,则(1-p(yi))γ就会很小,这时该易分类样本对总的损失的贡献变的更小;当一个贝类样本是难分类样本时,例如p(yi)=0.2,γ=3,则(1-p(yi))γ就会相对很大,这时该难分类样本对总的损失的贡献变的更大。综上,(1-p(yi))γ更加关注于难分类的贝类样本,减少易分类贝类样本的影响。通过放大(小)一个类别的βi值,控制该类别最小差异性对总的损失的影响,模型会更重视(或更不重视)该类别的正确(或不正确)预测。
优选地,所述卷积神经网络的目标函数为l=l1+l2。
采用上述进一步方案的有益效果是,实现了对不同样本的权重再分配,通过放大(或缩小)一个类别的αi值,控制该类别对总的损失的共享权重大小,模型会更重视或更不重视该类别的正确预测。通过放大(或缩小)一个类别的βi值,控制该类别最小差异性对总的损失的影响,模型会更重视或更不重视该类别的正确或不正确预测。解决了样本分布不平衡,导致不同样本分类难度存在巨大差异,原始交叉熵损失函数无法刻画这种分布特征的问题。
本发明还公开了一种贝类自动分类系统,针对高相似度贝类识别。包括图像采集模块、处理控制模块、置物台和输出模块;
所述置物台用于放置待分类的贝类;
所述图像采集模块用于采集放置在置物台上的贝类的照片;
所述处理控制模块包含有基于神经网络分类模型,对采集的贝类照片进行生物类群的识别,并将识别结果输送给输出模块;
所述输出模块用于输出识别结果;
所述神经网络模型以如上所述的方法进行模型训练。
与现有技术相比,本发明具有如下有益的效果:对过滤器进行重要度排序,裁剪掉不重要的部分,计算过滤器之间的正交性,裁剪掉正交性较低的过滤器中重要性相对较低的过滤器,再对所有过滤器进行初始化,对于高相似度贝类的分类更佳精准。
进一步地,还包括测距模块,所述测距模块用于测量相机到置物台的距离。
采用上述进一步方案的有益效果是,获得了相机与置物台的距离,就可以换算出照片中贝类的大概尺寸。
进一步地,所述处理控制模块根据测距模块测得的相机与贝类距离信息,分析得到贝类尺寸信息,结合图像采集模块获取的贝类图片信息,利用神经网络分类模型,对贝类进行生物类群的识别。
采用上述进一步方案的有益效果是,在分类识别过程中增加了尺寸信息,可以更加准确的识别贝类。
进一步地,所述测距模块包括激光源和激光传感器,所述激光源向置物台发射的激光经置物台反射后进入激光传感器。
采用上述进一步方案的有益效果是,测量精准,速度快,工作稳定,受外界干扰少。
附图说明
图1为本发明的贝类自动分类系统结构示意图;
图2为本发明实施例中计算贝类尺寸的流程图;
图3为本发明的贝类自动分类系统总的工作流程图;
图4为本发明的贝类自动分类系统中对分类模型进行训练的流程图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
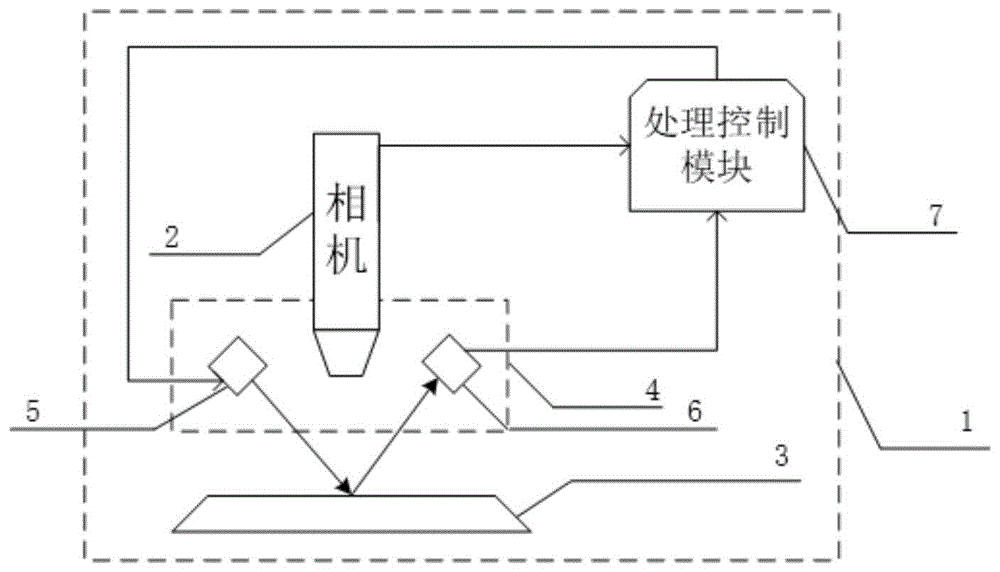
请参照图1所示,一种高相似度同科贝类分类装置整体结构示意图1所示。其中,高相似度同科贝类分类装置1,相机2,液晶板3(对应载物台),测距模块4,激光源5,激光传感器6,处理控制模块7。所述相机采集贝类图片,并传输至所述处理控制模块上。
所述测距模块采集相机与贝类图片之间的距离信息,并传输至处理控制模块储存。
所述液晶板反射激光(测距的激光),并且用于用户放置预识别的贝类。
所述测距模块包含激光源和激光传感器,所述测距模块通过激光源向铝板发射激光,并通过激光传感器对经液晶板反射的激光进行接收从而获取激光源发射激光至激光被激光传感器接收所经过的时间t,结合激光的传播速度v,即可获得激光源及激光传感器所在的相机靠近铝板的一端与铝板之间的距离sb,具体如下公式所示,近似为相机与贝类之间的距离sk。
其中a为相机中心点所在直线与激光源发射激光所在直线的夹角,同时为相机中心点所在直线与激光传感器接收激光所在直线的夹角。
所述处理控制模块基于cnn生成贝类图片的边界框,提取贝类轮廓信息,从而根据贝类轮廓信息和距离信息,得出图片尺寸信息,基本过程如图2所示.
所述处理控制模块根据图片信息和尺寸信息,基于cnn并应用本发明所述的过滤器裁剪与修复评价准则、训练策略、混合损失函数,最终对用户所拍摄贝类图片进行分类识别,并将分类结果发送至用户端app,如图3所示。
所述处理控制模块包含基于神经网络的分类模型,所述分类模型的训练过程如图4所示:
1)首先训练整体贝类识别模型mdf,迭代e1次;
2)然后根据上文所提出的过滤器的信息重要性评价准则在贝类识别模型中剪掉相对不重要s%的过滤器f’;
3)在2)的基础上根据层中过滤器间的正交性评价准则剪掉正交性较低的r%个过滤器中重要性相对低的过滤器f”;
4)在剪枝过滤器后的贝类识别模型mdf-f’-f”继续迭代训练e2次;
5)最后对剪枝的过滤器根据正交性度量重新初始化;
6)重复以上模型m次,直至模型收敛为止。
上述步骤中,评价过滤器重要性的准则是基于输出熵,将
其中c是容器的数量,pt是第t个容器的概率。h(wl,j)的数值越小,表示滤波器的信息越少。则第l层具有的总信息为:
公式(1)和(2)中的值越小,意味着滤波器的信息越少,即信息越不重要。
层中过滤器间的正交性评价准则。
卷积核大小为k×k的滤波器是k×k×c的多维向量,其中c是通道数。将滤波器向量展开为k×k×c的1维向量,并用f表示。设jl是第l层中滤波器的数量,其中l∈l。令wl为行数是jl的矩阵,一行为一个过滤器展开的向量。归一化权重为:
根据
公式(4)中,pl矩阵第i行数据表示其他过滤器跟第i个过滤器的相关性,对第i行数据求和所得值越小,表示第i个过滤器与其他过滤器的相关性越小。
根据相关性矩阵计算过滤器间的正交性度量:
其中,δλ表示其他过滤器对第i个过滤器的最小差异性。
根据公式(5)可知,该f所对应行的求和最小,表示正交性越大。
综上所述,为解决一些贝类特征非常相似以致难以区分问题,本发明对过滤器的处理步骤如下:
①首先利用公式(1)对过滤器按信息重要性程度从大到小排序;
②裁剪掉重要性较低的s%的过滤器;
③然后根据层中过滤器间的正交性度量,将正交性度量较低的r%的过滤器中,重要性排名较低的过滤器裁剪掉;
④最后根据同样的评价准则重新初始化裁剪掉的过滤器,也就是过滤器修复。
训练过程中必然少不了损失函数的参与
首先,依据本发明所述的过滤器正交性度量,让模型学习到相互正交的特征,本发明提出一种包含正则化项的损失函数l1:
其次,由于贝类样本分布是不平衡的,导致不同样本分类难度存在巨大差异,采用原始交叉熵损失函数无法刻画这种分布特征,因而分类效果不理想。为了解决这个问题,控制各类别样本之间对总的损失的共享权重以及容易分类和难分类样本的权重,本发明在分类模型中提出一种包含焦点损失的损失函数l2:
具体地,通过放大(减小)一个类别的αi值,控制该类别对总的损失的共享权重大小,模型会更重视(或更不重视)该类别的正确预测。
具体地,根据一个类别真实标签对应的输出概率p(yi)确定该类别对应的γ,当一个贝类样本是易分类样本时,例如p(yi)=0.9,γ=3,则(1-p(yi))γ就会很小,这时该易分类样本对总的损失的贡献变的更小;当一个贝类样本是难分类样本时,例如p(yi)=0.2,γ=3,则(1-p(yi))γ就会相对很大,这时该难分类样本对总的损失的贡献变的更大。综上,(1-p(yi))γ更加关注于难分类的贝类样本,减少易分类贝类样本的影响。
具体地,通过放大(减小)一个类别的βi值,控制该类别最小差异性对总的损失的影响,模型会更重视(或更不重视)该类别的正确或不正确预测。
最后,根据一种包含正则化项的损失函数和一种包含焦点损失的损失函数,本发明提出一种包含正则化项和焦点损失项的混合损失函数,作为模型的多分类目标函数。
l=l1+l2公式(9)
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!