一种基于图匹配网络的可对比学习对象生成方法及系统
1.本发明属于知识对比学习领域,具体涉及一种基于图匹配网络的可对比学习对象生成方法及系统。
背景技术:
2.对比是一种基本的人类认知手段,贯穿于感知、分类、解释等各种认知活动中。根据美国心理学家dedre gentner的结构映射理论(structure mapping theory),对比能促进学习对象间的结构对齐。这里,结构对齐不仅要建立不同学习对象在属性上的一一对应关系,而且在属性之间的关系上也需要实现对齐。例如,在物理课程中“无线电波”与“声波”对象可以进行对比学习;两者在“波长λ”、“频率f”、“速度v”三个属性之间的关系上实现了结构对齐,因为都存在v=λf函数关系。
3.学习对象之间的对比能够帮助学习者识别出被对比的学习对象在共同属性上的重要差异,从而促进深层次的联系性学习,并促进学习者思考导致这些异同点的原因,提高学习者学习效率。对比学习能够用于各类课程教学。例如,在“解析几何”课程中,可以将学习对象“双曲线”与“椭圆”进行对比学习;在“数据结构”课程中,可以将学习对象“堆栈”与“队列”进行对比学习。然而,这些课程中可对比学习对象的选取目前主要依赖教师与领域专家,存在人工开销大、时效性不强等局限性,很难满足在线学习环境下对比对象学习的需求。
4.大多数研究表明学习对象之间的对比都能取得较好的教学效果。典型研究工作如:star等人采用工具变量法(instrumental variables estimation)分析发现在代数课堂上,对比学习能降低学生的学习难度,并且强化过程性知识学习。begolli与richland的研究表明,在数学教学中,以并列方式呈现并对比不同的解题方案,要比顺序方式更加有效。straaten等人将对比学习用于历史教学,其核心是以人类社会中的一些持久性问题(如难民问题)为线索,建立过去和现在之间的联系。benjamin等人将对比学习用于地球科学中空间概念“断层”的学习,并研究了视觉相似性对学习效果的影响,实验表明视觉上相似的对比对象更有助于学习者区分断层的相关特征和无关特征。alfieri等对前期对比学习相关文献中的57个实验进行了元分析(meta
‑
analysis),发现对比目的、相关原理的表示等因素与学习效果紧密相关。郭建鹏等研究了一元一次方程类型和解法的对比学习中,多重样例变异性与先前知识之间的相互作用。目前在计算机领域还未见到关于可对比学习对象生成的研究工作,而在认知领域的研究主要依赖教师与领域专家给出可对比学习对象,这将极大的限制了对比学习的作用,无法满足在线教育中快速生成大量可对比学习对选哪个的学习需求。
5.cn201910025419.5
‑
提供一种基于知识图谱的快速知识对比方法及系统,包括构建知识表示单元,将各领域词条拆分解析成知识表示单元;构建知识图谱,包括将知识表示单元保存到图数据库中形成知识图谱,领域词条之间形成多对多的图结构关系;构建需对比的领域概念,包括确定需要进行比较的领域概念,拆分解析成知识表示单元,存入知识图
谱并建立不破坏原图结构的临时提及关系;抽取领域概念的多级拓扑;对比多级拓扑,计算出拓扑节点权重,然后计算出领域概念的带权相似度,得到知识对比结果,而上述方法只是在结构化的知识图谱中进行计算,获取结果,无法对非结构化的文本进行知识点和属性抽取。
技术实现要素:
6.本发明的目的在于提供一种基于图匹配网络的可对比学习对象生成方法及系统,以克服现有技术的不足。
7.为达到上述目的,本发明采用如下技术方案:
8.一种基于图匹配网络的可对比学习对象生成方法,包括以下步骤:
9.s1,通过解析半结构化数据获得两个学习对象间的关系和学习对象的初始属性集合;
10.s2,通过属性的信念传播持续更新初始属性集合中每个属性属于该学习对象的概率值,将初始属性集合中所有属性的概率值进行迭代传播,直到所有概率值处于稳定状态;
11.s3,根据概率值处于稳定状态的属性所对应的学习对象,利用该学习对象所对应的属性词进行相关性操作得到两个属性词的注意力权重;
12.s4,将包含两个属性词的所有句子的特征表示进行加权作为整个句子特征向量,将句子特征向量采用softmax分类器计算得到关联概率,根据两个属性词的注意力权重以及两个属性词所属句子的关联概率,即可得到两个学习对象对应属性之间的关联图信息,基于关联图信息分别计算两个学习对象间的整体图匹配和局部图匹配,得到候选对比对象结果,采用属性节点权重值与ferilli的结构相似性度量方法计算两个学习对象间的相似度,对比对象结果中两个学习对象间的相似度大于设定阈值的即为最终的可对比学习对象。
13.进一步的,具体的,通过解析半结构化数据wikidata页面的内容部分contenets和目录部分categories,分别获得学习对象间的关系和学习对象的初始属性集合。
14.进一步的,将初始属性集合中所有属性的概率值进行迭代传播,得到学习对象具有属性的概率值p,若p>α,则学习对象具有属性f
i
;阈值α取值范围为0.4
‑
1。
15.进一步的,对于概率值处于稳定状态的属性所对应的学习对象o的任意两个属性词f
i
,f
j
∈f,利用卷积对两个属性词的关联句子s进行词向量输入表示;将关联句子s中每个词分别与属性词对中的两个属性词进行相关性操作,得到两个属性词和关联句子s中每个单词之间的关联相关性的对角矩阵,并通过对角线的softmax得到属性词对中的两个属性词的注意力权重。
16.进一步的,所述相关性操作指将关联句子s中每个词分别与属性词对中的两个属性词进行余弦相似度计算。
17.进一步的,句子的注意力权重通过属性词相似度进一步通过线性网络得到。
18.进一步的,将学习对象的属性图通过多层感知器编码各个属性节点的特征和边的特征e
i,j
;根据得到的编码得到的两个学习对象对应属性之间的关联和编码得到特征经过多层网络传播,得到属性词f
i
的特征表征;将属性词f
i
的特征表征通过池化操作对图结构进行的简化,得到图的整体结构,同时利用多个特征向量进行上采样来得到的各个局部
信息表示。
19.进一步的,将两个学习对象间的整体结构之间进行匹配,将两个学习对象间的局部结构之间进行匹配,得到候选对比对象结果;采用pagerank(pr)计算方法来计算属性节点权重值。
20.进一步的,设f
o
、分别表示学习对象o与o*的属性集,将属性权重与ferilli的结构相似性度量方法相结合,用以下公式度量学习对象o*与o的相似度:
[0021][0022]
上式中,表示o*与o公共属性集中所有属性的权重之和;表示仅属于学习对象o的属性的权重之和;表示仅属于o*的属性的权重之和。
[0023]
一种基于图匹配网络的可对比学习对象生成系统,包括学习对象间属性集合预处理模块、属性间关联模块和可对比对象识别模块;
[0024]
学习对象间属性集合预处理模块用于解析半结构化数据获得两个学习对象间的关系和学习对象的初始属性集合,通过属性的信念传播持续更新初始属性集合中每个属性属于该学习对象的概率值,将初始属性集合中所有属性的概率值进行迭代传播,直到所有概率值处于稳定状态;
[0025]
属性间关联模块用于根据概率值处于稳定状态的属性所对应的学习对象,利用该学习对象所对应的属性词进行相关性操作得到两个属性词的注意力权重,将包含两个属性词的所有句子的特征表示进行加权作为整个句子特征向量,将句子特征向量采用softmax分类器计算得到关联概率,根据两个属性词的注意力权重以及两个属性词所属句子的关联概率,即可得到两个学习对象对应属性之间的关联图信息,基于关联图信息分别计算两个学习对象间的整体图匹配和局部图匹配,得到候选对比对象结果;
[0026]
可对比对象识别采用属性节点权重值与ferilli的结构相似性度量方法计算两个学习对象间的相似度,根据对比对象结果中两个学习对象间的相似度大于设定阈值确定得到最终的可对比学习对象。
[0027]
与现有技术相比,本发明具有以下有益的技术效果:
[0028]
本发明一种基于图匹配网络的可对比学习对象生成方法,通过解析半结构化数据获得两个学习对象间的关系和学习对象的初始属性集合,通过属性的信念传播持续更新初始属性集合中每个属性属于该学习对象的概率值,利用信念传播的方法来挖掘学习对象的属性;将初始属性集合中所有属性的概率值进行迭代传播,直到所有概率值处于稳定状态;根据概率值处于稳定状态的属性所对应的学习对象,利用该学习对象所对应的属性词进行相关性操作得到两个属性词的注意力权重;引入注意力机制来解决远程监督带来的噪声问题,利用双重注意力机制对属性间关联挖掘;通过图神经网络来捕获学习对象属性间关联的整体和局部结构,基于图匹配网络进行学习对象的结构间对齐,将学习对象的属性重要性计算转化为在属性关联上的中心度计算问题,采用属性节点中心度来实现可对比学习对象识别方法,能够实现非结构化的文本进行知识点和属性抽取,提高非结构化的文本学习对象的快速识别,为学习者提供一种可对比的学习对象生成结果。
[0029]
进一步的,利用gmn来分别计算一对学习对象的整体和局部图匹配,将两者的匹配结果用来判断是否作为可对比学习对象的候选结果,实现学习对象间的结构对齐,提高了识别准确度。
[0030]
进一步的,引入双重注意力机制,使模型更注意那些能够体现实体对之间关联的句子,更准确的抽取属性之间关联信息。
附图说明
[0031]
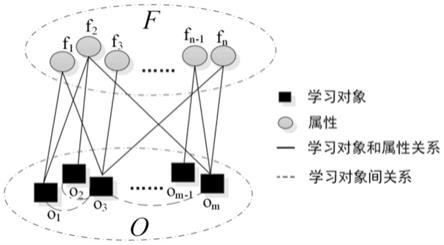
图1为本发明实施例中学习对象
‑
属性结构示意图。
[0032]
图2为本发明实施例中基于图匹配网络的可对比对象识别模型框架图。
具体实施方式
[0033]
下面结合附图对本发明做进一步详细描述:
[0034]
本发明提供一种基于图匹配网络的可对比对象识别方法,以满足在线教育中快速生成可对比对象的需求。
[0035]
如图1所示,一种基于图匹配网络的可对比对象识别方法,包括如下步骤,
[0036]
步骤一,通过解析半结构化数据wikidata页面的内容部分contenets和目录部分categories,分别获得两个学习对象间的关系和两个学习对象的初始属性集合;
[0037]
步骤二,通过属性的信念传播持续更新初始属性集合中每个属性f
i
属于该学习对象的概率值p;即更新初始属性集合;
[0038]
步骤三,将初始属性集合中所有属性的概率值进行迭代传播,直到所有概率值处于稳定状态,即得到学习对象o具有属性f
i
的概率值p,选取合适的阈值α,若p>α,则学习对象o具有属性f
i
;本申请阈值α取值范围为0.4
‑
1。
[0039]
步骤四,对于概率值处于稳定状态的属性所对应的学习对象o的任意两个属性词f
i
,f
j
∈f,利用卷积对属性词对(两个属性词)的关联句子s进行词向量输入表示;
[0040]
步骤五,将关联句子s中每个词分别与属性词对中的两个属性词进行相关性操作,得到两个属性词和关联句子s中每个单词之间的关联相关性的对角矩阵,并通过对角线的softmax得到属性词对中的两个属性词的注意力权重;上述相关性操作指将关联句子s中每个词分别与属性词对中的两个属性词进行余弦相似度计算。
[0041]
步骤六,将包含一个属性词对(两个属性词)的所有句子的特征表示s进行加权作为整个句子特征向量,其中句子的注意力权重通过属性词相似度进一步通过线性网络得到;
[0042]
步骤七,将句子特征向量采用softmax分类器计算关联概率,根据设定概率阈值β,大于设定概率阈值β即有关联,进而判断输入的属性词之间是否相关联,根据两个属性词的注意力权重以及两个属性词所属句子的关联概率,即可得到两个学习对象对应属性之间的关联图信息;
[0043]
步骤八,对于学习对象的属性图,通过多层感知器(multilayer perceptr on,mlp)编码各个属性节点的特征(即两个学习对象对应属性之间的关联)和边的特征e
i,j
(即编码得到特征);
[0044]
步骤九,根据步骤8得到的编码得到的两个学习对象对应属性之间的关联和编码得到特征经过多层网络传播,得到属性词f
i
的特征表征作为后续的输入;
[0045]
步骤十,属性词f
i
的特征表征通过池化操作对图结构进行的简化,得到图的整体结构,同时利用多个特征向量进行上采样来得到的各个局部信息表示;
[0046]
步骤十一,分别计算两个学习对象间的整体和局部图匹配,将两者的匹配结果用来判断是否作为可对比学习对象的候选结果;(即将两个学习对象间的整体结构之间进行匹配,将两个学习对象间的局部结构之间进行匹配),得到候选对比对象结果;
[0047]
步骤十二,采用pagerank(pr)计算方法来计算属性节点权重值;
[0048]
步骤十三,采用属性节点权重值与ferilli的结构相似性度量方法计算两个学习对象间的相似度,根据得到的两个学习对象间的相似度即可得到最终的可对比学习对象。根据得到的两个学习对象间的相似度,设定相似度阈值,候选对比对象结果中相似度大于设定相似度阈值的前n个即为对比学习对象,n大于0。
[0049]
下面,将参考附图详细描述根据本申请的示例实施例,以使得本发明的这些和/或其它方面和优点将变得更加清楚并更容易理解。显然,所描述的实施例仅是本申请的一部分实施例,而不是本申请的全部实施例,应理解本申请不受这里描述的示例实施例的限制。附图说明如下:
[0050]
表1为可对比对象在物理中应用的示例图
[0051]
表1展示了可对比对象在物理中应用的示例,通过对比“无线电波”与“声波”,有助于学习者掌握两者在“性质”、“介质”、“现象”、“波长”等方面的异同点,并促进学习者思考导致这些异同点的原因,提高学习者学习效率。
[0052]
1.基于信念传播的学习对象属性迭代传播:
[0053]
通过分析发现“相关学习对象具有相似的属性集”这一现象。这里,相关学习对象是指具有上下位与兄弟关系的学习对象。设学习对象x,y的属性集分别为f
x
与f
y
,则x,y的属性相似性定义为s=|f
x
∩f
y
|/|f
x
∪f
y
|。
[0054]
以外部知识源中不完整的“学习对象
‑
属性”关系作为先验知识,提出基于信念传播(belief propagation)的属性概率分布估计算法实现属性挖掘。该算法将学习对象o的属性挖掘问题转化为求解隐马尔科夫随机场联合概率分布问题。其中,隐马尔科夫随机场包含三部分:观测变量(属性全集f={f1,f2,...})、隐含变量(y={y1,y2,...},y
i
表示属性f
i
是学习对象o的属性的概率)以及学习对象间的关系构成的图结构g。求解隐马尔科夫随机场联合概率分布公式为:
[0055][0056]
其中,c表示该图g中所有的最大团(maximal cliques)集合,y*表示最大团c中隐含变量y组成的变量集合,u(y*)表示隐马尔科夫随机场的势函数(potential function)。按照以下三个步骤进行求解。
[0057]
1)初始化:构建如图1所示的“学习对象
‑
属性”图g=(o∪f,e
o
∪e
o
→
f
)。表示学习对象间的关系,可通过解析wikipedia页面中contenets的结构化数据,获得学习对象间的上下位与兄弟关系。表示学习对象和属性的关系,可通过解析
wikipedia页面的目录部分(categories)获得学习对象的初始属性集合,据此得到属性f
i
属于学习对象o属性的概率值,实现属性变量f
i
对应隐变量y
i
的概率值初始化,同时对所有信念值m
i
→
j
(y
j
)初始化为1。
[0058]
2)信念传播:旨在通过信念传播更新随机变量的概率,学习对象o的属性f
i
对应隐含变量y
i
传播到属性f
j
对应变量y
j
的信念m
i
→
j
(y
j
)由下式计算:
[0059][0060]
上式η
i
表示属性f
i
在g的邻居节点;ψ(y
i
,y
j
)表示一个二元能量函数,根据“相关学习对象具有相似的属性集”这一现象,属性f
i
、f
j
所属的学习对象之间的上下位与兄弟关系越多,能量函数的值越大。
[0061]
3)信念分配:p(y
i
)的更新依赖于邻居节点的信念传播,公式如下:
[0062][0063]
所有的信念值进行迭代传播,直到信念处于稳定状态,就可得到所有属性对应隐含变量的概率分布。选取合适的阈值α,若p(y
i
)>α,则学习对象o具有属性f
i
;否则不具有属性f
i
。
[0064]
2.基于双重注意力机制的属性间关联挖掘:
[0065]
学习对象的属性间关联挖掘是下一步学习对象间的可对比识别的前提。有监督的属性间关联挖掘算法往往需要大量标注好的数据,而构建训练集十分费时费力。因此采用基于远程监督(distant supervision)的方法来解决属性关联的数据缺失问题,该方法设知识库中所有提到同一对实体的句子,都是在描述这对实体之间的关系或关联。
[0066]
这种自动获取数据方式可以快速构建出大量数据作为关联分类的训练数据,但会带来一定的噪声,因为并不是所有同时出现两个实体的句子,都能很好的反应该实体对之间的关联。为了缓解噪声问题,引入双重注意力机制,使模型更注意那些能够体现实体对之间关联的句子,更准确的抽取属性之间关联信息。该任务可形式化表示为:已知学习对象o的属性集f,对任意两个属性f
i
,f
j
∈f,判断两者间的关联r(f
i
,f
j
)是否存在。主要分为以下三个步骤:
[0067]
1)属性词和句子的输入表示:对于每一个包含属性关联词对的句子s,其第k个词表示为其中为该词的嵌入表示,和分别为两个目标属性词在该句子中的位置信息表示,于是整个句子可以表示为s=(ω1,ω2,...)。接着通过卷积操作对句子进行特征提取,得到整个句子的特征表示,则包含该属性词对的所有句子特征表示为:s=(s1,s2,...)。
[0068]
2)注意力机制引入:
[0069]
属性词的attention:将句子s的每个词分别与属性关联词对进行相关性操作,得到两个相关性对角矩阵a
i
和a
j
,该矩阵可以描述属性词实体和每个单词之间的关联强度,其对角线元素值分别为:其中ω
k
表示第k个单词,函数g表示内积操作。用下式将矩阵进行参数化:
[0070][0071][0072]
其中衡量第k个词与属性词f
i
之间的相关性,并将两个属性词的系数简单加权。
[0073]
属性句子的attention:为了将包含一对关联词的所有句子的特征表示s=(s1,s2,...)进行加权作为整个特征向量,假设函数r(f
i
,f
j
)表示属性词f
i
和f
j
之间的关联特征信息,则句子的注意力权重定义为:
[0074]
ω
i
=w tanh(s
i
,r)+b
[0075][0076]
其中w表示权重矩阵,b表示偏置,β=(β1,β2,...)是所有句子的权重向量。加权计算得到所有句子的特征向量:
[0077][0078]
3)关联概率计算:将特征向量送入softmax分类器计算关联概率,进而判断输入的属性词之间是否相关联:
[0079][0080]
其中w
s
和b
s
为权重和向量,p
i,j
为属性f
i
和f
j
之间有关联的概率。
[0081]
3.基于图匹配网络的可对比学习对象识别:
[0082]
前面两部分得到的学习对象间属性及其关联构成的图结构作为输入,通过对象间结构对齐和相似度计算,识别出可对比学习对象。主要内容包括:
[0083]
1)学习对象的结构对齐:
[0084]
对比是学习对象间的结构对齐过程,不仅要建立不同对象在属性上的对应关系,而且在属性之间的关联上也需要实现对齐。因此,需要实现学习对象的结构对齐,以生成候选的可对比学习对象集合。
[0085]
相比于传统图嵌入网络,图匹配网络(graph matching network,gmn)模型并不是单独计算每个图的图表征,而是通过对比两个图的结构来计算图表征。采用gmn网络进行结构对齐,如图2所示:
[0086]
i)图结构特征表示:拟采用图神经网络(graphneural network,gnn)来表征学习对象的图结构。将一对学习对象的属性图作为输入,对于每个属性图,首先通过多层感知器(multilayer perceptron,mlp)来编码各个属性节点的特征和边的特征e
i,j
,经过多层网络传播,得到f
i
的特征表征作为后续的输入。
[0087]
ii)整体和局部结构分离:学习对象的整体图结构表示该学习对象属性簇之间的关联,整体结构对齐程度可以反映学习对象之间的结构相似性。而属性簇内可以展示属性之间的关联信息,对属性簇进行结构对齐可以有效解决属性命名冲突问题。依据以上分析,一个学习对象的属性图可以定义为g={g
′
,g*},其中g
′
表示通过池化操作(如求平均、最大
值)对图结构进行简化,称为图的整体结构;是同时利用多个特征向量进行上采样来得到的各个局部信息表示。
[0088]
iii)结构对齐:利用gmn来分别计算一对学习对象的整体和局部图匹配,将两者的匹配结果用来判断是否作为可对比学习对象的候选结果,来实现学习对象间的结构对齐。
[0089]
2)学习对象的相似度计算
[0090]
在通过图结构对齐获取候选可对比学习对象的基础上,采用图分析方法来获取属性权重差异,实现学习对象的相似度计算,主要包括两个步骤:
[0091]
i)属性节点的权值计算。对比不仅要建立不同对象在属性上的一一对应关系,而且在属性之间的关联上也需要实现对齐,并且涉及关联对齐的属性在对比中更重要。这里采用图分析的中心度分析方法计算权重。设学习对象的属性图g
f
由属性f={f
i
},i=1,
…
,l及之间的关联组成。对于每一个属性节点f
i
,可采用pagerank(pr)算法(一种特征向量中心度,eigen centrality)。节点f
i
的pr计算步骤如下:首先设置收敛值ξ和可调参数η,初始化每个属性节点的pr值为通过下式进行迭代计算:
[0092][0093]
其中,i(v
i
)表示指向属性v
i
的所有属性集合,|o(v
j
)|是属性节点v
j
的中心度。计算收敛条件||pr
t+1
‑
pr
t
||<ξ,满足收敛条件之后得到最终的pagerank值pr={pr1,...,pr
n
}。最后利用softmax函数来计算每个属性的权值,形式如下:
[0094][0095]
ii)学习对象间相似度计算:设f
o
、分别表示学习对象o与o*的属性集。我们将属性权重与ferilli的结构相似性度量方法相结合,提出以下公式用于度量学习对象o*与o的相似度。
[0096][0097]
上式中,表示o*与o公共属性集中所有属性的权重之和;表示仅属于学习对象o的属性的权重之和;表示仅属于o*的属性的权重之和。
[0098]
通过以上三个方面,实现可对比学习对象的识别,最后通过设置相似度阈值或对象数阈值来确定最终的可对比学习对象。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1