基于带离群点去除的车辆轨迹聚类方法
1.本发明属于大数据分析技术领域,进一步涉及一种车辆轨迹聚类方法,可用于城市交通中普通车辆行驶的行为分析和工程车辆相关的施工行为分析,为改善城市交通管理和道路养护提供依据。
背景技术:
2.随着移动定位技术与移动通信系统的蓬勃发展,以及各类移动终端设备的广泛应用衍生了海量的移动对象的位置信息。位置信息中主要包括对象所处位置的经纬度和时间戳等信息,这些海量的数据被终端设备实时采集,并在持续累积的条件下形成了规模庞大高速集中的对象轨迹流信息。实时的对轨迹流数据进行处理分析可以感知移动对象在移动过程中发生的变化,并通过深度的分析揭示隐藏在对象行为模式背后的规律。
3.聚类是轨迹数据分析中经典的数据挖掘技术。聚类的主要目标是将海量的轨迹数据集划分成若干个相似度满足要求的簇用以表征不同的轨迹所代表的相似的移动趋势。然而,聚类算法的有效性受到限制的原因有三个:首先,聚类算法所需的输入参数值通常很难确定;第二,聚类算法对这些参数值是敏感的,即使参数设置稍有不同,也常常会产生非常不同的数据聚类结果;第三,现实世界中的高维数据集往往具有很大的分布偏差。
4.目前,对轨迹聚类算法的改进已经有很多研究。xinzheng niu等人在发表的论文“label
‑
based trajectory clustering in complex road networks”中提出了一种复杂道路网络中基于标号的轨迹聚类方法,该方法研究了复杂网络理论,探讨了复杂网络理论在道路网络轨迹聚类中的应用。具体来说,是将道路网络建模为对偶图,以助于有效地将聚类问题从道路网络中的子轨迹转化为复杂网络中的节点,并在此模型的基础上,设计了一种基于标签的轨迹聚类算法lbtc,用来捕捉和刻画节点间相似度的本质。该方法将网格理论应用于轨迹聚类中虽说可通过网状网络的特性增加轨迹段的可描述性,但该种方法在面对大规模的轨迹数据时,庞大的网状网络构建会成为性能的瓶颈。在amir salarpour等人发表的论文“direction
‑
based similarity measure to trajectory clustering”中提出基于方向的轨迹聚类相似性度量,其根据不同分辨率下的方向变化计算轨迹相似性,并通过轨迹段的角度描述对轨迹的相似性进行分析,以实现旋转和位置不变性,但该方法由于判断的条件单一,因而无法相对准确的描述相似性的概念。he ailin等人发表的论文“movement pattern extraction based on a non
‑
parameter sub
‑
trajectory clustering algorithm”为了使轨迹聚类方法摆脱相关领域先验知识的限制,该方法改进了对轨迹段划分的方式,率先采用了通信领域中的mdl最小描述性原则,并基于该种相对准确的轨迹段描述使用dbscan算法进行后续的轨迹聚类分析。但直接使用mdl原则进行轨迹段划分的时间复杂度较高,难以适应海量轨迹数据的处理,并且仅使用基于密度的聚类算法聚类的准确度较低。
技术实现要素:
5.本发明的目的在于克服上述已有技术的不足,提出一种基于带离群点去除的车辆轨迹聚类方法,以减小时间复杂度,提高聚类的运行效率和准确度。
6.本发明的技术思路是:在轨迹划分时通过使用带角度描述的轨迹划分策略a
‑
mdl算法减小轨迹段划分过程的时间复杂度并提高轨迹段划分的准确度,通过在聚类的过程中采用了带离群因子lof的dbscan算法提高聚类的准确度,通过在轨迹簇分析时设计最大置信长度的扫描策略,使得轨迹聚类结果更加平滑。
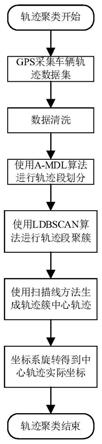
7.根据上述思路,本发明的实现步骤包括有如下:
8.(1)在车联网系统中通过gps采集目标车辆移动的经度x
r
和纬度y
r
这些信息,并存储到云服务器;
9.(2)整理采集的车辆轨迹点的数据,并定义轨迹点格式:p
r
=(x
r
,y
r
);
10.(3)遍历车辆目标的轨迹数据集,去除位置信息中重复位置的数据和采集失败或超出范围的错误数据,实现对车辆轨迹数据的清洗;
11.(4)对清洗后的车辆轨迹数据集中的轨迹逐个使用引入角度描述的最小描述长度a
‑
mdl进行轨迹段划分,生成新的车辆轨迹段数据集:
12.(4a)选取车辆轨迹数据集中的一条轨迹,并将其表示为t={p1p2p3…
p
i
…
p
n
}其中p
i
表示轨迹第i点,n为轨迹中轨迹点的个数;
13.(4b)定义每个轨迹段角度为:其中i、j为满足j>i的任意正整数,θ
k
表示两条轨迹段的夹角,k从k=i开始递增至k=j;
14.(4c)设定角度阈值a
max
,从轨迹的首个轨迹段开始对每个轨迹段进行角度判断:
15.若a的值大于a
max
,则直接排除假设描述的可行性,向后扩充一个轨迹点重新进行判断,直到a的值小于角度阈值a
max
;
16.若a的值小于角度阈值a
max
,则执行(4d);
17.(4d)计算轨迹段p
i
p
j
的最小描述性原则mdl的成本:
18.若轨迹段p
i
p
j
包含其它轨迹点,则将其mdl成本计算为mdl
cost
=s+h;
19.若轨迹段p
i
p
j
不包含其它轨迹点,则将其mdl成本计算为mdl
np
‑
cost
=s;
20.其中,s为轨迹段p
i
p
j
的假设描述长度,h为假设描述s下轨迹段p
i
p
j
的描述长度;
21.(4e)对每个轨迹段p
i
p
j
进行轨迹段划分判断:
22.若mdl
cost
<mdl
np
‑
cost
,则当前轨迹段满足划分条件假设描述s就是最佳轨迹段假设d,向后扩充一个轨迹点,若扩充至轨迹t的最后一个轨迹点p
n
,则完成轨迹段划分,即生成的新轨迹段数据集,执行(5),否则,返回(4c);
23.若mdl
cost
≥mdl
np
‑
cost
则回退一个轨迹点,返回(4c);
24.(5)使用带lof离群因子的dbscan算法,按照密度可达性原则将轨迹段划分生成的新轨迹段数据集分为不同的轨迹簇;
25.(6)设轨迹簇中心轨迹的任意子轨迹段最大置信长度为z表示,在z的限制下对多个轨迹簇进行扫描,得到每个轨迹簇的中心轨迹;
26.(7)对扫描得到的中心轨迹进行坐标系旋转,计算每个轨迹簇中心轨迹的实际坐标,这些中心轨迹为轨迹聚类的最终结果。
27.本发明与现有技术相比具有以下优点:
28.第一,本发明由于使用了a
‑
mdl算法改进轨迹段划分的过程,提高了轨迹段划分的效率。
29.第二,本发明由于使用带lof离群因子的dbscan算法将轨迹段数据集分为不同的轨迹簇,消除了离群样本的影响,提高了聚类的质量。
30.第三,本发明由于在轨迹簇扫描时设置了中心轨迹的任意子轨迹段最大置信长度z,使得中心轨迹更加平滑。
附图说明
31.图1为本发明的实现总流程图;
32.图2为本发明中gps采集车辆位置信息的车辆网系统框架图;
33.图3为本发明中轨迹数据清洗子流程图;
34.图4为本发明中定义轨迹段之间的间距示意图;
35.图5为本发明中轨迹段扫描的示意图;
36.图6为本发明中旋转坐标系的示意图。
具体实施方式
37.下面结合附图对本发明的实施例作进一步的详细描述。
38.参照图1,本发明的实现步骤如下:
39.步骤1,采集车辆轨迹数据集。
40.本实例的轨迹聚类是基于车联网系统下车辆轨迹数据的采集进行。
41.所述车联网系统,如图2所示,其包括车载终端、云端服务器、前端网页这三大部分。其中车载终端主要负责采集车辆设备的相关参数、车辆位置、运行时间、传感器数据等信息并通过4g移动网络实现数据上传;云端服务器主要对存储在服务器中的车辆相关信息进行分析;前端网页用于进行可视化信息显示,将云端分析数据的结果通过网页向用户进行展示,直观的展现车辆运行情况、位置信息等统计分析结果为车辆行为分析提供依据。
42.基于上述系统,本实例预先设定采集频率,车载的终端通过gps信号,每隔一段时间获取车辆目标的经度x和纬度y信息,并由4g网络传输至云端服务器存储,随着轨迹数据的积累在云端服务器形成车辆轨迹数据集。
43.步骤2,轨迹点数据整理。
44.根据轨迹数据的特征,将通过gps信号采集到的经纬度数据进行格式整理,遍历每条轨迹的数据信息,将轨迹中每一个轨迹点的格式定义为点p=(x,y)。
45.步骤3,对轨迹数据集进行清洗。
46.在gps采集车辆位置信息时,车辆目标长时间停留在某个位置时会导致采集到大量重复的数据点,此外,由于gps信号的不稳定性,采集中时常会记录到一些错误信息或空信息。这些重复或错误的位置信息会影响轨迹聚类分析,所以轨迹聚类前需要进行数据清洗。
47.如图3所示,本实例进行轨迹数据清洗的实现如下:
48.3.1)遍历轨迹数据集中的轨迹点,判断当前轨迹点的经纬度信息是否与相邻的下
一个轨迹点重复:
49.若重复,则删除当前轨迹点,对下一个轨迹点重新进行判断,直到所有轨迹点判断完毕,得到数据清洗后的轨迹数据集,执行步骤4;
50.若不重复,则直接执行3.2);
51.3.2)判断当前轨迹点的经纬度信息是否符合轨迹点的格式:
52.若不符合,则删除当前轨迹点,对下一个轨迹点执行3.1);
53.若符合,则直接对下一个轨迹点执行3.1)。
54.步骤4,对数据清洗后的轨迹数据集进行轨迹段划分。
55.轨迹数据是通过gps设备对车辆目标的位置进行均匀持续的采点形成的一组轨迹点数据集,如何通过采集的轨迹点描述聚类分析可用的轨迹段是轨迹聚类中十分重要的一个步骤。轨迹段划分不仅要保证划分出的轨迹段能尽可能表征车辆目标原有的移动趋势,还需要使用尽量少的轨迹点生成轨迹段以减少海量数据时处理的时间。常用的轨迹段划分算法有两种:一种是douglas
‑
peucker压缩算法,该方法使用距离阈值的限制对轨迹段进行划分,其直接通过距离限制进行划分,划分结果无法很好的表征原轨迹的趋势;另一种是使用mdl最小长度描述性原则对轨迹段进行划分,该算法时间复杂度较高。本实例在mdl算法的基础上扩展了角度描述提出了a
‑
mdl算法,通过角度阈值的判断降低了轨迹段划分的时间复杂度。a
‑
mdl算法遍历轨迹数据集中的每一条轨迹进行轨迹段划分,步骤如下:
56.4.1)选取车辆轨迹数据集中的一条轨迹t,并将其表示为:
57.t={p1p2p3…
p
i
…
p
n
}
58.其中,p
i
表示轨迹第i点,n为轨迹中轨迹点的个数;
59.4.2)为了降低算法的时间复杂度,本实例在轨迹段划分时定义了任意一个轨迹段p
i
p
j
的角度为:其中i、j为满足j>i的任意正整数,θ
k
表示两条轨迹段的夹角,k从k=i开始递增至k=j;
60.4.3)根据轨迹聚类使用时不同的实际场景,设定轨迹段角度的阈值a
max
,本实例基于车辆轨迹聚类的场景,将角度阈值a
max
设定为30
°
;
61.4.4)从轨迹段角度入手,判断轨迹段是否符合轨迹划分要求,即从轨迹的首个轨迹段开始对每个轨迹段进行角度判断:
62.若a的值大于a
max
,则判定当前轨迹段不符合轨迹段划分的要求,向后扩充一个轨迹点重新进行判断,直到a的值小于角度阈值a
max
;
63.若a的值小于角度阈值a
max
,则执行4.5);
64.4.5)完成角度判断后使用mdl原则进行下一步轨迹段划分,mdl原则的原理是找到数据总描述长度最小的模型最为最佳假设,实现如下:
65.4.5.1)寻找轨迹段p
i
p
j
最佳假设需要计算p
i
p
j
的mdl成本,为了计算mdl成本,本实例参照图4,首先对轨迹t中任意两条轨迹段p
i
p
j
和p
b
p
m
的垂直距离d
⊥
和角度距离d
θ
分别定义为:
66.[0067][0068]
其中,b、m为任意正整数,且m>b;l
⊥
i
为端点p
i
与轨迹段p
b
p
m
之间的垂直距离;l
⊥
j
为端点p
j
与轨迹段p
b
p
m
之间的垂直距离;l(p
i
p
j
)表示两个轨迹点p
i
与p
j
之间的距离;θ为轨迹段p
i
p
j
与轨迹段p
b
p
m
之间的夹角;
[0069]
4.5.2)依据轨迹段间的垂直距离d
⊥
和角度距离d
θ
,设轨迹段p
i
p
j
的假设描述长度s和假设描述s下轨迹段p
i
p
j
的描述长度h分别为:
[0070]
s=log2(l(p
i
p
j
)),
[0071][0072]
4.5.3)依据s和h的值,对轨迹段p
i
p
j
的mdl成本进行计算:
[0073]
若轨迹段p
i
p
j
中包含其它轨迹点则称为分段轨迹,将其mdl成本计算为mdl
cost
=s+h;
[0074]
若轨迹段p
i
p
j
中不包含其它轨迹点则称为不分段轨迹,将其mdl成本计算为mdl
np
‑
cost
=s;
[0075]
4.6)轨迹段划分的目的是寻找最佳假设,根据计算得到的mdl成本判断假设描述长度s是否为最佳假设:
[0076]
如果mdl
cost
<mdl
np
‑
cost
,则假设描述s就是最佳假设,向后扩充一个轨迹点,并根据扩充轨迹点的次序判断轨迹段划分是否完成:
[0077]
若扩充的轨迹点为轨迹t的最后一个轨迹点p
n
,则完成轨迹段划分,即生成的新轨迹数据集,执行步骤5;否则,返回4.4);
[0078]
如果mdl
cost
≥mdl
np
‑
cost
,则假设描述s下轨迹段p
i
p
j
的描述长度h不是最小值,表明当前轨迹段不满足轨迹段划分条件,需回退一个轨迹点后,返回4.4);
[0079]
步骤5,使用带lof因子的dbscan算法对新轨迹数据集聚簇。
[0080]
轨迹段的聚簇是轨迹聚类中的关键步骤,通过不同轨迹间存在的相似性对轨迹数据集进行分析,将相似度符合要求的轨迹的集合作为一个轨迹簇。
[0081]
现有的轨迹聚簇过程常用两种算法进行:第一种是k
‑
means算法,该算法是一种仅依靠轨迹对象间距离关系进行相似度判断的算法,距离越近则相似度越高,但该算法由于仅依靠距离聚簇使得聚簇的结果始终为圆形区域,与轨迹形状多变的特性不符导致聚簇结果存在偏差;第二种是dbscan算法,该算法是一种基于密度的判断轨迹对象间相似度的方法,并将判断不同轨迹对象间是否密度可达作为轨迹对象是否属于同一个轨迹簇的依据,聚簇的结果为任意的形状,改善了k
‑
means算法聚簇结果为圆形区域的缺点。
[0082]
本实例针对现实采集的轨迹数据存在较大分布偏差的特性,将一种带离群因子lof的dbscan算法应用于轨迹聚簇的过程。在轨迹聚簇的过程中引入了lof离群因子用来表征轨迹对象的离群度,在轨迹对象的离群因子lof不大于限制时,通过寻找局部密度可达的轨迹生成轨迹簇,具体实现如下:
[0083]
5.1)定义如下概念,以在基于dbscan算法进行轨迹聚簇的过程中引入轨迹段t的离群因子lof:
[0084]
5.1.1)参照图4,定义轨迹段p
i
p
j
和p
b
p
m
间的距dist(p
i
p
j
,p
b
p
m
)=d
⊥
+d
θ
+d
||
,其中d
||
=min(l
||1
,l
||2
),其中,l
||1
表示p
i
向p
b
p
m
做垂线的垂点与p
b
的距离;l
||2
分别表示表示p
j
向p
b
p
m
做垂线的垂点与p
m
的距离;
[0085]
5.1.2)给定任意正整数s,定义轨迹段t的s阶距离为dist
st
,该dist
st
的值是轨迹段t和核心轨迹段之间的距离;
[0086]
5.1.3)定义n
s(t)
为轨迹段t的s阶邻域,邻域中任意一条轨迹段t'与轨迹段t的距离小于或等于dist
st
;
[0087]
5.1.4)将在轨迹段t的e阶领域内,最少有e个非t的轨迹段t'满足dist(o,t')<dist(t,o),并且lof(t)<lofub,的轨迹段定义为轨迹段t为核心轨迹段,其中e为限制邻域阶数的常数,lofub为离群因子阈值;
[0088]
5.1.5)定义邻域阶数为s时,相对可达距离dist
‑
reach
to
为轨迹段t相对核心轨迹段o的可达距离,dist
‑
reach
to
=max{dist
so
,dist(o,t)};
[0089]
5.1.6)定义邻域阶数为s时轨迹段t局部可达密度lrd
s
(t)为:
[0090][0091]
5.1.7)定义邻域阶数为s时轨迹段t的局部离群因子lof
s
(t)表示为
[0092][0093]
5.1.8)若轨迹段t'在轨迹段t的s阶邻域范围内,且满足:
[0094][0095]
则定义这两个轨迹段t和t'的局部密度可达,其中pct为用于限制波动范围的常数;
[0096]
5.2)根据轨迹聚类的聚类质量设置轨迹聚簇的三个核心参数:邻域阶数的限制e、密度限制pct、离群因子阈值lofub,本实例在车辆轨迹的实际场景中根据聚类结果的对比设置e=28;pct=0.5、lofub=3;
[0097]
5.3)遍历轨迹数据集,根据5.1.4)定义将所有满足核心轨迹段条件的轨迹段标记为核心轨迹段;
[0098]
5.4)从轨迹数据集中随机选取一个核心轨迹段;
[0099]
5.5)遍历轨迹段数据集,根据5.1.8)定义找出所有与当前核心轨迹段局部密度可达的轨迹段,形成轨迹簇;
[0100]
5.6)在未聚簇的轨迹段中随机选取核心轨迹段:
[0101]
若未聚簇的轨迹段中不存在核心轨迹段,则轨迹段聚簇结束,执行步骤6;
[0102]
若未聚簇的轨迹段中存在核心轨迹段,则返回5.5);
[0103]
步骤6,使用扫描线法生成每个轨迹簇的中心轨迹。
[0104]
每一个轨迹簇中包含多个轨迹段,对轨迹簇分析得到中心轨迹是进行轨迹聚类的最终目的,中心轨迹表征了车辆目标的行为特点,可用于后续的异常检测、热点分析这些过
程。因此,在一个轨迹簇中分析出一条能充分代表该簇运动特征的轨迹是十分必要的。扫描线法是轨迹簇分析的一种常用算法,通过定义一个垂直于轨迹簇轴线方向的扫描线对轨迹簇进行扫描,根据扫描线穿过轨迹段数量的变化分析得到轨迹簇中心轨迹。
[0105]
参照图5,本实例采用扫描线的方法生成轨迹簇的中心轨迹,并设置了中心轨迹子轨迹段最大置信长度z,使得生成的中心轨迹更加平滑,具体实现如下:
[0106]
6.1)根据轨迹聚类结果的平滑度设置轨迹簇扫描的两个核心参数:中心轨迹子轨迹段最大置信长度z和扫描线所需要穿过的最小的轨迹段个数m,本实例在车辆轨迹的实际场景中根据聚类结果的对比设置z=45、m=3;
[0107]
6.2)定义一条垂直于轨迹簇轴线的线段为扫描线;
[0108]
6.3)扫描线沿轴线方向移动进行扫描:
[0109]
若扫描线穿过轨迹簇轴线终点,则结束轨迹簇扫描,执行步骤7;
[0110]
否则,执行6.4);
[0111]
6.4)当扫描线穿过的轨迹段实际个数大于等于预设个数m时,使用扫描线与所有穿过的轨迹段交点,计算中心轨迹点的平均坐标(x',y'):
[0112]
参照图6,计算平均坐标是根据扫描线与三条不同的轨迹段的交点(x',y1')、(x',y'2)、(x',y'3)计算中心轨迹点为:并保存当前扫描线的位置;
[0113]
6.5)在扫描线间距不超过中心轨迹的任意子轨迹段最大置信长度z的条件下,继续移动扫描线,直到扫描线穿过的轨迹段个数小于m时,计算得到中心轨迹点的平均坐标后,返回6.3)。
[0114]
步骤7,对轨迹簇中心轨迹进行坐标系旋转。
[0115]
由于轨迹簇的方向是任意的,计算中心轨迹的轨迹点时使用的是以轨迹簇轴线方向为横轴建立的平面直角坐标系,因此,为了得到中心轨迹在原平面直角坐标系xy下的实际坐标,需要对中心轨迹的坐标点进行坐标系旋转。
[0116]
参照图6,本步骤的具体实现如下:
[0117]
7.1)定义轨迹簇轴线方向与坐标系x轴的夹角为φ;
[0118]
7.2)设以轨迹簇轴线方向为横轴建立的平面直角坐标系下,中心轨迹中任意一个轨迹点p
e
的横纵坐标值为x'、y',根据坐标系旋转的对应关系计算点p
e
实际坐标x、y的值:
[0119]
7.3)计算所有中心轨迹的轨迹点的实际坐标,轨迹聚类的最终结果为每个轨迹簇中心轨迹点构成的中心轨迹。
[0120]
以上描述仅是本发明的一个具体实例,并未构成对本发明的任何限制,显然对于本领域的专业人员来说,在了解了本发明的内容和原理后,都可能在不背离本发明原理、结构的情况下,进行形式和细节上的各种修改和改变,但是这些基于本发明思想的修正和改变仍在本发明的权利要求保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1