基于YOLOv4改进算法的目标检测方法、装置及系统
本发明属于目标检测领域,具体涉及一种基于yolov4改进算法的目标检测方法、装置及系统。
背景技术:
伴随我国汽车保有量的逐年增加,道路拥堵成为不可避免的问题。为了解决这一问题,智能交通系统(intelligenttransportationsystem,its)应运而生。its由道路、车辆、行人三部分组成,通过对道路上车辆和行人的实时信息监测来缓解道路交通负担。其中视觉智能交通系统是构成its的重要部分,它通过采集到的路况信息,利用相关视觉算法,实现车辆和行人检测。
车辆和行人检测方法主要有两类,基于传统机器学习的检测方式和基于深度学习的目标检测方式。其中,基于传统方法的目标检测方式有基于图像特征和几何特征等这类方法。基于图像特征方法的常见特征有呈现图像灰度值的变化的haar特征,有计算局部图像区域的梯度直方图的hog特征等;基于几何特征方法的常见特征有目标物体的形状特征、对称性特征、车底阴影特征等。但是,通过人工选择的单个或几种特征,并不能很好的描述目标物体,在车辆种类的不同、行人形态的差异以及外部环境因素等复杂场景下会导致物体检测的不准确性。
基于深度学习的目标检测的特征提取是将图像经过训练的更深,更复杂的网络模型进而从中提取特征,提取的特征优于传统上使用人工设计方法提取的特征。主要包括两大类,一类是two_stage检测算法,其步骤是首先确定目标区域,然后对区域进行分类,它对目标物体的检测分为两步,代表算法有fastr-cnn和fasterr-cnn,这类算法的优点是检测精度较高,但检测速度慢,不适合实时检测;另一类是one_stage检测算法,通过单次检测就能检测出物体的类别概率和位置坐标,代表算法有yolo和ssd,这类算法的检测精度会有所下降,但换来的是检测速度的提高,可以满足实时性要求,真正运用到无人驾驶领域,可以很好地改善传统方法带来的训练时间长,检测速度慢的问题。
在工程应用中,基于单阶段检测的yolo算法被广泛应用,虽然能很好的解决检测速度慢这一缺点,但其检测准确性,尤其对小目标的检测精度还有待提高。
技术实现要素:
针对上述问题,本发明提出一种基于yolov4改进算法的目标检测方法、装置及系统,能够大大提高对小目标的检测精度。
为了实现上述技术目的,达到上述技术效果,本发明通过以下技术方案实现:
第一方面,本发明提供轮一种基于yolov4改进算法的目标检测方法,包括:
获取yolov4-fcspx网络结构,所述yolov4-fcspx网络结构是通过对yolov4网络结构中cspx的残差结构进行浅层到深层的融合构造而成的;
获取含目标物体的图片集,所述图片集分为训练子集和测试子集;
对训练子集中图片分别进行目标物体标注,获得对应的标注框;
对所有标注框进行聚类,获得k个先验框;
将所有先验框和所述图片集中的原始图片输入至yolov4-fcspx网络结构,生成特征图,得到特征图对应先验框的位置信息、类别信息和物体置信度;
基于设定的物体置信度阈值,以及特征图对应先验框的位置信息、类别信息和物体置信度,获得一定数量的候选框;
对所有候选框进行非极大值抑制,得到预测框;
基于各预测框与对应的标注框的损失值对yolov4-fcspx网络结构的权值进行更新,直到损失值小于设定阈值,获得训练好的yolov4-fcspx网络结构;
将测试子集中的图片输入至训练好的yolov4-fcspx网络结构,获得目标物体的大小、位置及类别,完成目标检测。
可选地,所述yolov4-fcspx网络结构包括:骨干backbone、颈部neck和头部head三部分;
所述骨干backbone由两部分组成,一部分是卷积conv+批标准化bn+激活函数mish,称为cbm,另一部分是cbm与残差模块resunitn组成的cspx;所述cspx的数量为5,分别记为:csp1、csp2、csp8、csp8、csp4;所述csp8中有8个残差模块,前6个残差模块均与最后一个残差模块进行跳接,进行浅层特征与深层特征的融合,命名为fcsp8;所述csp4中有4个残差模块,前2个残差模块均与最后一个残差模块进行跳接,进行浅层特征与深层特征的融合,命名为fcsp4。
所述颈部neck由两部分组成,一部分是卷积conv+批标准化bn+激活函数leakyrelu,称为cbl,另一部分是空间金字塔池化spp;
所述头部head是由cbl和conv组成。
可选地,所述标注框的获得方法包括:
利用数据标注软件labelme对训练集中图片进行车辆和行人标注,获得对应的标注框,以及目标物体的位置信息和类别信息,所述位置信息包括标注框的中心点坐标值、标注框的高宽值。
可选地,所述图片集中共包含9423帧图像,标签分为两类:车辆和行人;
所述训练子集和测试子集,比例为9:1;
利用数据标注软件labelme对数据集中的训练集进行车辆和行人标注,生成xml文件,利用python脚本voc_label将xml文件格式转换为txt文件格式。
可选地,所述先验框的个数为9,各先验框的宽高尺寸分别为(12,18)、(14,49)、(17,23)、(24,29)、(31,45)、(41,32)、(52,59)、(83,102)、(159,229)。
可选地,所述对所有标注框进行聚类,获得k个先验框,及各先验框的高宽值,具体为:
(1)获取任意标注框的高宽值作为初始聚类中心;
(2)计算标注框的中心与最近的聚类中心的距离d=1-iou,计算时每个标注框的中心点都与聚类中心重合,其中iou为标注框宽高与聚类中心宽高的交并比,把所有的距离加起来得到sum(d);
(3)在选取新的聚类中心时,先取落在sum(d)之间的随机值random,对于未被选中的数据点,若当前的数据点对应的∑d>random,该数据点被选为下一个聚类中心;
(4)重复步骤(1)和步骤(3),直到k个聚类中心(wi,hi)(i=1,2,...,k)被选出来;
(5)计算每个标注框与聚类中心的距离d=1-iou[(xj,yj,wj,hj),(xj,yj,wi,hi)],j∈{1,2,...,n},i∈{1,2,3...k};
(6)将标注框分配给距离最近的聚类中心,计算时每个标注框的中心点都与聚类中心重合;
(7)所有标注框分配完毕后,对每个簇重新计算聚类中心点,计算方式为:
其中,ni是第i个簇的标注框个数;
(8)重复步骤(6)和步骤(7),直到聚类中心的改变量逐渐收敛即可得到k个先验框的宽高尺寸。
可选地,所述将所有先验框和所述图片集中的原始图片输入至yolov4-fcspx网络结构,生成特征图,得到特征图对应先验框的位置信息、类别信息和物体置信度,具体为:
将所有先验框和所述图片集中的原始图片输入至yolov4-fcspx网络结构,生成特征图尺寸为大、中、小三个尺寸,尺寸分别为76×76、38×38和19×19,大特征图对应有76×76个特征点,每个特征点对应有3种尺寸的先验框,则76×76的特征图一共有76×76×3=17328个先验框,那么3个特征图一共有76×76×3+38×38×3+19×19×3=22743个先验框,最终一张原始图片经过yolov4-fcspx网络结构得到22743个先验框的位置信息、物体置信度和类别。
可选地,所述损失函数包括位置回归损失、物体置信度损失和类别损失,所述位置回归损失采用ciou_loss计算,物体置信度损失和类别损失均采用交叉熵损失计算。
第二方面,本发明提供了一种基于yolov4改进算法的目标检测装置,包括:
第一获取单元,用于获取yolov4-fcspx网络结构,所述yolov4-fcspx网络结构是通过对yolov4网络结构中cspx的残差结构进行浅层到深层的融合构造而成的;
第二获取单元,用于获取含目标物体的图片集,所述图片集分为训练子集和测试子集;
对训练子集中图片分别进行目标物体标注,获得对应的标注框;
聚类单元,用于对所有标注框进行聚类,获得k个先验框;
生成单元,用于将所有先验框和所述图片集中的原始图片输入至yolov4-fcspx网络结构,生成特征图,得到特征图对应先验框的位置信息、类别信息和物体置信度;
计算单元,用于基于设定的物体置信度阈值,以及特征图对应先验框的位置信息、类别信息和物体置信度,获得一定数量的候选框;
筛选单元,用于对所有候选框进行非极大值抑制,得到预测框;
训练单元,用于基于各预测框与对应的标注框的损失值对yolov4-fcspx网络结构的权值进行更新,直到损失值趋近于很小的值,获得训练好的yolov4-fcspx网络结构;
检测单元,用于将测试子集中的图片输入至训练好的yolov4-fcspx网络结构,获得目标物体的大小、位置及类别,完成目标检测。
第三方面,本发明提供了一种基于yolov4改进算法的目标检测系统,包括:包括存储介质和处理器;
所述存储介质用于存储指令;
所述处理器用于根据所述指令进行操作以执行根据第一方面中任一项所述方法的方法。
与现有技术相比,本发明的有益效果:
由于现有技术在使用yolov4网络结构对车辆和行人进行检测时,对于小目标物体的检测精度不足,因此本发明对yolov4网络结构进行改进,具体为对cspx的残差结构进行浅层到深层的融合,避免了信息在深层网络传递过程中的部分损失和干扰,所以具有提高了对于小目标物体检测的准确性的效果。
附图说明
为了使本发明的内容更容易被清楚地理解,下面根据具体实施例并结合附图,对本发明作进一步详细的说明,其中:
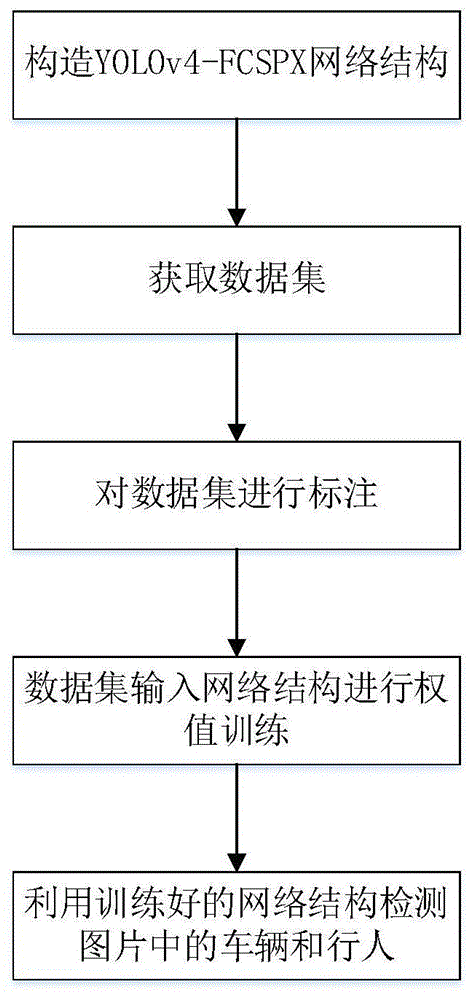
图1为本发明流程图;
图2为本发明基于改进的yolov4算法的车辆和行人检测的网络结构图;
图3为本发明在训练好的网络结构中检测输入图片中包含车辆和行人的检测结果。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明的保护范围。
下面结合附图对本发明的应用原理作详细的描述。
实施例1
参照图1,本发明实施例中提供了一种基于yolov4改进算法的目标检测方法,具体包括以下步骤:
步骤一:获取yolov4-fcspx网络结构,并对yolov4-fcspx网络结构进行参数初始化;
具体地,在本发明实施例的一种具体实施方式中,所述yolov4-fcspx网络结构包括:骨干backbone、颈部neck和头部head三部分;所述骨干backbone由两部分组成,一部分是卷积conv+批标准化bn+激活函数mish,称为cbm,另一部分是cbm与残差模块resunitn组成的cspx;所述cspx的数量为5,分别记为:csp1、csp2、csp8、csp8、csp4;所述csp8中有8个残差模块,前6个残差模块均与最后一个残差模块进行跳接,进行浅层特征与深层特征的融合,命名为fcsp8;所述csp4中有4个残差模块,前2个残差模块均与最后一个残差模块进行跳接,进行浅层特征与深层特征的融合,命名为fcsp4。所述颈部neck由两部分组成,一部分是卷积conv+批标准化bn+激活函数leakyrelu,称为cbl,另一部分是空间金字塔池化spp;所述头部head是由cbl和conv组成,具体参见图2。
步骤二:获取含目标物体的图片集,所述图片集分为训练子集和测试子集;
具体地,在本发明实施例的一种具体实施方式中,所述步骤二具体为:
在本发明实施例中设置目标物体为车辆和行人,图像集采用开源的self-driving-car数据集,共包含9423帧图像,超过65000个标签,标签分为两类:车辆和行人;所述图像集被分为训练子集和测试子集这两部分,所述训练子集和验证子集的比例为9:1。
步骤三、对训练子集中图片分别进行目标物体标注,获得对应的标注框;
具体地,在本发明实施例的一种具体实施方式中,所述步骤三具体为:
利用数据标注软件labelme对训练子集进行车辆和行人标注,可以得到目标物体的位置信息和类别信息,其中位置信息包括标注框的中心点坐标值,标注框的高宽值;即:利用数据标注软件labelme对数据集中的训练集进行车辆和行人标注,生成xml文件,利用python脚本voc_label将xml文件格式转换为txt文件格式。
标注框的数据为(c,x,y,w,h),其中c代表标注框内目标物体的类别,x、y分别代表标注框中心点的x、y坐标值,w、h分别代表标注框的宽、高值。
步骤四:对所有标注框进行聚类,获得k个先验框;
具体地,在本发明实施例的一种具体实施方式中,所述步骤四具体为:
(1)获取任意标注框的高宽值作为初始聚类中心;
(2)计算标注框的中心与最近的聚类中心的距离d=1-iou,计算时每个标注框的中心点都与聚类中心重合,其中iou为标注框宽高与聚类中心宽高的交并比,把所有的距离加起来得到sum(d);
(3)在选取新的聚类中心时,先取落在sum(d)之间的随机值random,对于未被选中的数据点,若当前的数据点对应的∑d>random,该数据点被选为下一个聚类中心;
(4)重复步骤(1)和步骤(3),直到k个聚类中心(wi,hi)(i=1,2,...,k)被选出来;
(5)计算每个标注框与聚类中心的距离d=1-iou[(xj,yj,wj,hj),(xj,yj,wi,hi)],j∈{1,2,...,n},i∈{1,2,3...k};
(6)将标注框分配给距离最近的聚类中心,计算时每个标注框的中心点都与聚类中心重合;
(7)所有标注框分配完毕后,对每个簇重新计算聚类中心点,计算方式为:
其中,ni是第i个簇的标注框个数;
(8)重复步骤(6)和步骤(7),直到聚类中心的改变量逐渐收敛,最终得到9个先验框的宽、高数值,分别为(12,18),(14,49),(17,23),(24,29),(31,45),(41,32),(52,59),(83,102),(159,229)。
步骤五、将所有先验框和所述图片集中的原始图片输入至yolov4-fcspx网络结构,生成特征图,得到特征图对应先验框的位置信息、类别信息和物体置信度;
在本发明实施例的一种具体实施方式中,所述步骤五具体为:
将所有先验框和所述图片集中的原始图片输入至yolov4-fcspx网络结构,生成特征图尺寸为大、中、小三个尺寸,尺寸分别为76×76、38×38和19×19,大特征图对应有76×76个特征点,每个特征点对应有3种尺寸的先验框,则76×76的特征图一共有76×76×3=17328个先验框,那么3个特征图一共有76×76×3+38×38×3+19×19×3=22743个先验框,最终一张原始图片经过yolov4-fcspx网络结构得到22743个先验框的位置信息、物体置信度和类别。
步骤六、基于设定的物体置信度阈值,以及特征图对应先验框的位置信息、类别信息和物体置信度,获得一定数量的候选框,即根据特征图对应先验框的置信度大于设定的物体置信度阈值,获得一定数量的候选框;
步骤七、对所有候选框进行非极大值抑制,得到预测框;
步骤八、基于各预测框与对应的标注框的损失值对yolov4-fcspx网络结构的权值进行更新,直到损失值趋近于很小的值,获得训练好的yolov4-fcspx网络结构;
损失函数包括位置回归损失、物体置信度损失和类别损失,其中位置回归损失采用ciou_loss计算,物体置信度损失和类别损失均采用交叉熵损失计算。
步骤九、将测试子集中的图片输入至训练好的yolov4-fcspx网络结构,获得目标物体的大小、位置及类别,完成目标检测。
本实施例中,输入图像尺寸为608×608,对应的三个检测尺寸为76×76、38×38和19×19,每个检测尺寸的一个网格对应有三个先验框,预测目标物体种类为2种:车辆和行人,输出维度为3×(5+2)=21。仿真实验显卡选用的为nvidiageforcertx2080ti,显存为11g,内存为32g。使用编程环境为python3.6,使用的深度学习框架为pytorch。
为了验证本发明的有效性,在self-driving-car测试集上进行了验证,实验的结果如图3所示,能够识别出尺寸大小差别较大的目标物体,对小目标车辆和行人的检测有了明显的提升。
实施例2
基于与实施例1相同的发明构思,本发明实施例中提供了一种基于yolov4改进算法的目标检测装置,包括:
第一获取单元,用于获取yolov4-fcspx网络结构,所述yolov4-fcspx网络结构是通过对yolov4网络结构中cspx的残差结构进行浅层到深层的融合构造而成的;
第二获取单元,用于获取含目标物体的图片集,所述图片集分为训练子集和测试子集;
对训练子集中图片分别进行目标物体标注,获得对应的标注框;
聚类单元,用于对所有标注框进行聚类,获得k个先验框,及各先验框的高宽值;
生成单元,用于将所有先验框和所述图片集中的原始图片输入至yolov4-fcspx网络结构,生成特征图,得到特征图对应先验框的位置信息、类别信息和物体置信度;
计算单元,用于基于设定的物体置信度阈值,以及特征图对应先验框的物体置信度,获得一定数量的候选框;
筛选单元,用于对所有候选框进行非极大值抑制,得到预测框;
训练单元,用于基于各预测框与对应的标注框的损失值对yolov4-fcspx网络结构的权值进行更新,直到损失值趋近于很小的值,获得训练好的yolov4-fcspx网络结构;
检测单元,用于将测试子集中的图片输入至训练好的yolov4-fcspx网络结构,获得目标物体的大小、位置及类别,完成目标检测。
其余部分均与实施例1相同。
实施例3
基于与实施例1相同的发明构思,本发明实施例中提供了一种基于yolov4改进算法的目标检测系统,包括:包括存储介质和处理器;
所述存储介质用于存储指令;
所述处理器用于根据所述指令进行操作以执行根据实施例1中任一项所述方法的方法。
其余部分均与实施例1相同。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!