一种基于深度学习的胸片检测方法与流程
1.本发明属于图像处理技术领域,具体涉及一种基于深度学习的胸片检测方法。
背景技术:
2.目前x光胸片是占全世界所有x光诊断图像的40%,但由于拥有诊断资格的医疗人员的缺乏,x光胸片常出现积压状况,病人并且无法第一时间得到诊断,导致错过最佳治疗时间,对于x光胸片的诊断主要依赖医师人工诊断,由于人力有限,诊断时间通常较长,无法让病人得到最快的治疗。
3.存在问题或缺陷的原因:目前的x光胸片智能识别技术多依赖人工特征选择,而此类特征选取较为困难,由于算法设计人员对于医学图像了解有限,而专业医师对于计算机识别算法理解同样不足,导致人工特征工程常常无法包含所有有效特征,导致识别效果较差。
技术实现要素:
4.针对上述胸片识别处理技术模型识别效果较差等问题,本发明提供了一种基于深度学习的胸片检测方法。
5.为了解决上述技术问题,本发明采用的技术方案为:
6.一种基于深度学习的胸片检测方法,包括下列步骤:
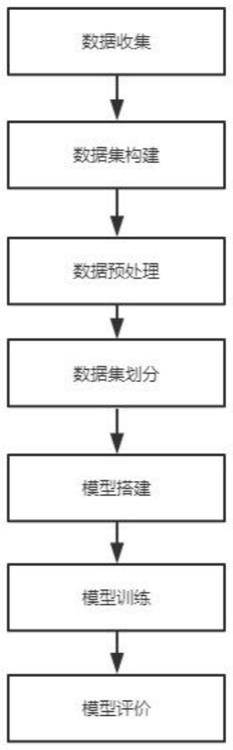
7.s100、数据采集:对肺浑浊、骨折、气胸、胸腔积液与正常x光胸片五种图像进行收集,并由专业医师进行标注;
8.s200、数据预处理:对数据进行裁剪与缩放并进行归一化处理,将标签转换为one
‑
hot形式,构建可供深度学习网络进行训练与识别的标准数据集;
9.s300、数据集划分:使用k折交叉验证的方法将数据集划分为5个数据集;
10.s400、模型构建:构建x光胸片识别深度网络模型,模型由cnn层、x
‑
d层、全卷积层与全连接层4部分构成,前三层网络对特征进行不同感受野与不同方式的特征提取,由全连接层输出分类结果;
11.s500、模型训练与评价:指定训练参数,使用k折交叉方法对模型进行训练,根据模型识别效果,选取最优参数模型,当模型损失值无下降则停止训练,保存模型并评价。
12.所述s100数据采集中,从医疗机构获取病灶x光图像数据,由专业医师对数据进行标注,数据集共包含病灶x光图像共1600张,4类疾病x光图像各400张,600张正常胸部x光图像,肺浑浊、骨折、气胸、胸腔积液与正常x光图像的标签分别为1
‑
5类。
13.所述s200数据预处理中,将数据全部缩放为600*600大小的图像,归一化处理方式为对所有像素点除以255,将所有数据归一化到[0,1]的范围内,one
‑
hot标签分别为肺浑浊[1,0,0,0,0]、骨折[0,1,0,0,0]、气胸[0,0,1,0,0]、胸腔积液[0,0,0,1,0]、正常[0,0,0,0,1]。
[0014]
所述s300数据集划分中,对数据集采用k折交叉验证方式进行数据集的划分为训
练集与验证集,取k=5,将全部数据平均分为5个数据集,编号为数据集a/b/c/d/e。
[0015]
所述s400模型构建中,基于xception构建模型,并对模型进行改进,模型由4部分构成,分别为cnn层、x
‑
d层、全卷积层、全连接层,cnn层用于缩小feature map,并提升数据维度,挖掘数据特征;x
‑
d层由具有膨胀卷积核的xception网络构成,利用深度可分离卷积对数据特征进行学习,并利用膨胀卷积对不同感受野下的特征进行分析;全卷积层利用全卷积网络对特征进行降维分析;全连接层用于完成分类任务。
[0016]
所述s400模型构建中,cnn层、x
‑
d层、全卷积层、全连接层,cnn层工作方式分别如下:
[0017]
cnn层:进行三次卷积运算,每次卷积运算后进行一次最大池化并使用relu进行激活,第一次卷积的卷积核大小为5*5,步长为2,池化核大小为4*4,步长为2;第二次卷积的卷积核大小为.3*3,步长为2,池化核大小为3*3,步长为1;第三次卷积的卷积核大小为.3*3,步长为1,池化核大小为2*2,步长为1;每次池化完成后进行一次系数为0.3的dropout操作,防止过拟合,三次卷积完成后,对得到的feature map进行一次batch normalization对数据进行处理,防止梯度消失,3次卷积分别将数据维度提升到4维,8维,16维;
[0018]
x
‑
d层:cnn层输出特征提取结果后,x
‑
d对输入的特征先进行1*1卷积,之后对每个channel分别进行3*3卷积操作,对3*3卷积的50%卷积核采用膨胀卷积方式,膨胀卷积尺度为1,卷积运算完成后,将所有的输出与cnn层的输出进行concate,得到高维特征,将concate得到的特征进行一次batch normalization;
[0019]
全卷积层:对x
‑
d层输出的feature map进行flatten,之后采用1*1卷积核对数据特征进行全卷积操作,对数据进行降维,经过3层的1*1卷积,将数据降维到1;
[0020]
全连接层:将全卷积层输出的特征进行全连接运算,使用softmax对计算结果进行输出,得到最终分类结果。
[0021]
所述s400模型构建中,网络搭建完毕后使用训练集数据对网络参数进行训练,采用bgd作为优化器,初始学习率为0.02,每100个epoch学习率衰减50%,batch size大小为32,损失函数使用交叉熵损失函数,即j=
‑
[y
·
log(p)+(1
‑
y)
·
log(1
‑
p)],其中y为样本标签,p为预测样本的概率,设定训练500个epoch,连续15个epoch模型损失值无下降则停止训练,保存模型。
[0022]
所述s500模型训练与评价中,取a/b/c/d/e数据集作为验证集,其余四个数据集作为训练集对模型进行训练,得到5个数据模型,对5个模型在验证集上的预测结果进行评价比对,若模型性能相近,则证明模型无过拟合或欠拟合现象,保存模型,完成模型搭建,若5个模型性能差距较大,则重新进行k折交叉验证划分数据集,调整学习率对模型进行再次训练,直到得到最佳模型。
[0023]
所述s500模型训练与评价中,使用训练好的模型对测试集数据进行胸片分类预测,将预测结果与其对应标签进行比对,进行识别效果评价,评价方式为f1
‑
score,f1
‑
score值越高,表示识别效果越好,score值越高,表示识别效果越好,其中,f1为f1
‑
score,a为准确率,r为召回率,tp为正类判定为正类数量,fp为负类判定为正类数量,fn为正类判定为负类数量,tn为负类判定为负类数量。
[0024]
本发明与现有技术相比,具有的有益效果是:
[0025]
本发明通过深度学习的方法,对x光胸片进行智能识别,全过程无需人工对特征进行选取,而是由网络自主学习,避免了主观误差,且识别速度极快,有效解决了x光图片识别速度慢的问题,且基于深度学习在图片识别的优秀性能,本发明模型具有较好的识别效果。
附图说明
[0026]
图1本发明的主要步骤流程图;
[0027]
图2本发明的网络模型图;
具体实施方式
[0028]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0029]
一种基于深度学习的胸片检测方法,如图1所示,包括下列步骤:
[0030]
s100、数据采集:对肺浑浊、骨折、气胸、胸腔积液与正常x光胸片五种图像进行收集,并由专业医师进行标注;
[0031]
s200、数据预处理:对数据进行裁剪与缩放并进行归一化处理,将标签转换为one
‑
hot形式,构建可供深度学习网络进行训练与识别的标准数据集;
[0032]
s300、数据集划分:使用k折交叉验证的方法将数据集划分为5个数据集;
[0033]
s400、模型构建:构建x光胸片识别深度网络模型,模型由cnn层、x
‑
d层、全卷积层与全连接层4部分构成,前三层网络对特征进行不同感受野与不同方式的特征提取,由全连接层输出分类结果;
[0034]
s500、模型训练与评价:指定训练参数,使用k折交叉方法对模型进行训练,根据模型识别效果,选取最优参数模型,当模型损失值无下降则停止训练,保存模型并评价。
[0035]
进一步,步骤s100数据采集中,从医疗机构获取病灶x光图像数据,由专业医师对数据进行标注,数据集共包含病灶x光图像共1600张,4类疾病x光图像各400张,600张正常胸部x光图像,肺浑浊、骨折、气胸、胸腔积液与正常x光图像的标签分别为1
‑
5类。
[0036]
进一步,步骤s200数据预处理中,将数据全部缩放为600*600大小的图像,归一化处理方式为对所有像素点除以255,将所有数据归一化到[0,1]的范围内,one
‑
hot标签分别为肺浑浊[1,0,0,0,0]、骨折[0,1,0,0,0]、气胸[0,0,1,0,0]、胸腔积液[0,0,0,1,0]、正常[0,0,0,0,1]。
[0037]
进一步,步骤s300数据集划分中,对数据集采用k折交叉验证方式进行数据集的划分为训练集与验证集,取k=5,将全部数据平均分为5个数据集,编号为数据集a/b/c/d/e。
[0038]
进一步,步骤s400模型构建中,如图2所示,基于xception构建模型,并对模型进行改进,模型由4部分构成,分别为cnn层、x
‑
d层、全卷积层、全连接层,cnn层用于缩小feature map,并提升数据维度,挖掘数据特征;x
‑
d层由具有膨胀卷积核的xception网络构成,利用深度可分离卷积对数据特征进行学习,并利用膨胀卷积对不同感受野下的特征进行分析;全卷积层利用全卷积网络对特征进行降维分析;全连接层用于完成分类任务。
[0039]
进一步,步骤s400模型构建中,cnn层、x
‑
d层、全卷积层、全连接层,cnn层工作方式
分别如下:
[0040]
cnn层:进行三次卷积运算,每次卷积运算后进行一次最大池化并使用relu进行激活,第一次卷积的卷积核大小为5*5,步长为2,池化核大小为4*4,步长为2;第二次卷积的卷积核大小为.3*3,步长为2,池化核大小为3*3,步长为1;第三次卷积的卷积核大小为.3*3,步长为1,池化核大小为2*2,步长为1;每次池化完成后进行一次系数为0.3的dropout操作,防止过拟合,三次卷积完成后,对得到的feature map进行一次batch normalization对数据进行处理,防止梯度消失,3次卷积分别将数据维度提升到4维,8维,16维;
[0041]
x
‑
d层:cnn层输出特征提取结果后,x
‑
d对输入的特征先进行1*1卷积,之后对每个channel分别进行3*3卷积操作,对3*3卷积的50%卷积核采用膨胀卷积方式,膨胀卷积尺度为1,卷积运算完成后,将所有的输出与cnn层的输出进行concate,得到高维特征,将concate得到的特征进行一次batch normalization;
[0042]
全卷积层:对x
‑
d层输出的feature map进行flatten,之后采用1*1卷积核对数据特征进行全卷积操作,对数据进行降维,经过3层的1*1卷积,将数据降维到1;
[0043]
全连接层:将全卷积层输出的特征进行全连接运算,使用softmax对计算结果进行输出,得到最终分类结果。
[0044]
进一步,步骤s400模型构建中,网络搭建完毕后使用训练集数据对网络参数进行训练,采用bgd作为优化器,初始学习率为0.02,每100个epoch学习率衰减50%,batchsize大小为32,损失函数使用交叉熵损失函数,即j=
‑
[y
·
log(p)+(1
‑
y)
·
log(1
‑
p)],其中y为样本标签,p为预测样本的概率,设定训练500个epoch,连续15个epoch模型损失值无下降则停止训练,保存模型。
[0045]
进一步,步骤s500模型训练与评价中,取a/b/c/d/e数据集作为验证集,其余四个数据集作为训练集对模型进行训练,得到5个数据模型,对5个模型在验证集上的预测结果进行评价比对,若模型性能相近,则证明模型无过拟合或欠拟合现象,保存模型,完成模型搭建,若5个模型性能差距较大,则重新进行k折交叉验证划分数据集,调整学习率对模型进行再次训练,直到得到最佳模型。
[0046]
进一步,步骤s500模型训练与评价中,使用训练好的模型对测试集数据进行胸片分类预测,将预测结果与其对应标签进行比对,进行识别效果评价,评价方式为f1
‑
score,f1
‑
score值越高,表示识别效果越好,score值越高,表示识别效果越好,其中,f1为f1
‑
score,a为准确率,r为召回率,tp为正类判定为正类数量,fp为负类判定为正类数量,fn为正类判定为负类数量,tn为负类判定为负类数量。
[0047]
上面仅对本发明的较佳实施例作了详细说明,但是本发明并不限于上述实施例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化,各种变化均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1