一种基于生成对抗网络和时间卷积网络的唇语识别方法
1.本发明属于人工智能和深度学习领域,具体是一种基于生成对抗网络和时间卷积网络的唇语识别方法。
背景技术:
2.随着科学技术的发展和硬件制造水平的提升,计算机所能处理的信息量也在成指数级增长,这使得以深度学习为基础的人工智能技术进入快速发展阶段,人工智能技术已经越来越广的应用到了人们的日常生活中,潜移默化地改变着人们的生产生活方式,成为人类社会中不可缺少的重要技术之一。人工智能技术的应用场景涵盖生产生活的各个方面,包括语音识别、智能医疗、机器视觉、智能问答系统、无人驾驶等。人工智能技术在这些领域取得的成功以及积累的经验更加推进了社会对于这一新兴技术的关注,加速人工智能技术的发展。
3.唇语识别是人工智能技术的一个重要应用领域,在社会生产生活的诸多领域具有举足轻重的地位,有非常广的应用前景,例如:
4.1.基于唇部特征的活体检测:在一些需要身份验证的场景中往往需要确定对象的真实生理特征,对象需要完成转动头部、眨眼、读出一段话等一系列指定动作来完成验证对象是否为真实的活体人体。使用人脸关键点检测技术以及唇语识别等方式可以有效规避照片、视频、换脸、面部遮挡等常见的逃避检测的方式,从而帮助用户免受欺诈行为的危害,保障使用者的权益。
5.2.辅助听障人士交流:听障人士包括先天性遗传或后天人为因素造成的听力受损的残疾人,他们无法听到或无法发出声音,在生活中与他人交流十分不便。通过使用搭载唇语识别技术的交流辅助装置,满足听障人士的交流需求。
6.目前的唇语识别模型按识别等级分为字母级、单词级和句子级三类模型,他们大多都采用序列到序列(sequence2sequence,seq2seq)模型进行序列建模识别,并使用连续时序分类(connectionist temporal classification,ctc)算法作为衡量预测结果准确性的标准。seq2seq模型的作用是将连续的唇部特征序列作为输入,通过编码器(encoder)和解码器(decoder)将输入的特征序列进行时序编码解码。唇语识别任务的一大难点是唇部图像的上下文联系较强,但seq2seq模型往往采用的是顺序上下文联系的机制,因此并不能很好地处理唇部变化序列中的上下文关系。
7.之后出现了基于注意力机制(attention)的改进版序列模型,在机器翻译、智能问答系统等具有短句上下文依赖的应用场景中取得了令人满意的结果。但是唇语识别任务处理的是较长的连续图像序列,上下文联系更加紧密,时间维度的跨度更大,而attention机制在唇语识别任务中的精度仍然有待提升。唇语识别任务的另一大难点是唇部特征往往受角度、光照、说话人身份影响,特征提取面临很大的不确定性。大部分识别模型都采用了基于残差网络(residual network,resnet)的特征提取器,这种特征提取器在实验室条件下的效果较好,但直接在实际环境中应用却表现不佳。
技术实现要素:
8.针对现有技术的不足,本发明拟解决的技术问题是,提供一种基于生成对抗网络和时间卷积网络的唇语识别方法。
9.本发明解决所述技术问题的技术方案是,提供一种基于生成对抗网络和时间卷积网络的唇语识别方法,其特征在于,该方法包括以下步骤:
10.s1、制作原始数据;所述原始数据包括识别网络原始数据和密集多角度唇部变化原始数据;
11.s2、分别对原始数据的每帧或每张图像用人脸标注算法标注人脸特征点,得到两个特征点位置数组;
12.s3、根据特征点位置数组中的原始数据特征点矩阵和平均人脸特征点矩阵,对原始数据的每帧或每张图像中的人脸分别进行人脸对齐,得到对齐后原始数据;
13.s4、人脸对齐完成后,从s2得到的人脸特征点中选取唇部特征点,再根据唇部特征点计算得到对齐后原始数据的每帧或每张图像中各自的唇部特征点的中心的坐标;再根据唇部特征点的中心的坐标将对齐后原始数据的每帧或每张图像中的唇部区域切分为固定尺寸的唇部图像,进而分别得到密集多角度唇部变化数据集和识别网络数据集;
14.s5、使用密集多角度唇部变化数据集训练gan二阶段转换器和resnet角度分类器;
15.s6、使用训练后resnet角度分类器和训练后gan二阶段转换器来矫正识别网络数据集,将其中发生偏转的唇部图像转正:将识别网络数据集逐帧拆分成若干张待矫正唇部图像,然后输入到训练后resnet角度分类器中进行角度分类,得到每张待矫正唇部图像各自的唇部偏转角度θ;
16.之后根据唇部偏转角度θ确定使用的gan二阶段转换器编号i;
17.然后将唇部偏转角度θ的待矫正唇部图像送入对应编号的训练后gan二阶段转换器中进行唇部矫正,得到矫正后唇部图像;矫正后唇部图像的唇部偏转角度θ为0
°
;再将矫正后唇部图像合并成矫正后唇部图像序列;
18.s7、使用矫正后唇部图像序列训练tcn时间卷积网络;
19.s8、通过训练后tcn时序卷积网络来进行特征识别分类,生成唇语识别结果。
20.与现有技术相比,本发明有益效果在于:
21.(1)本发明是首先通过resnet角度分类器判断唇部偏转角度,之后利用的gan二阶段转换器进行唇部矫正,最后送入tcn中进行特征识别分类生成唇语识别结果的高精度唇语识别方法;该方法克服了传统卷积模型无法解决的唇部特征提取受实际环境中光照强度、光照角度、识别角度、说话人身份等不确定性的影响,使唇语识别的准确性显著提高。
22.(2)本发明采用基于时间和空间双重维度的时间卷积网络(temporal convolutional network,tcn),抛弃了传统序列模型处理时采用的门机制,使用扩张卷积来实现序列模型的建模任务,解决唇语识别面临的困境,使得唇语识别的精度进一步提升。tcn在处理序列模型时具有并行性,并不需要像序列模型一样按顺序处理句子。而且,tcn的感受野灵活,受卷积层数、卷积核大小、扩张系数等影响,可以根据不同任务进行灵活的设置。在tcn模型的训练过程中不易发生序列模型经常出现的因不同时间段上共用参数导致的梯度消失和爆炸问题。最后,tcn因为在训练的时候不像序列模型一样,需要把每步的信息保存在下来,而且tcn在一层里面卷积核是共享的,所以内存使用更低。
23.(3)将大偏移角度的唇部图像通过一步转换成正面的效果是非常不好的,因为转换器不能处理结构变化非常大的信息,因此本发明的gan网络采用两个阶段转换器,将转换过程分为两步,即第一步先将某一范围内的唇部图像转换到某一固定角度,范围为
±
10
°
,再输入到第二阶段转换器再转换时虽然也会跨越最大60
°
的范围,但是输入和输出图像两个分部域内变化都不大,即输入图像大多为转角
±2°
的图像,输出为0
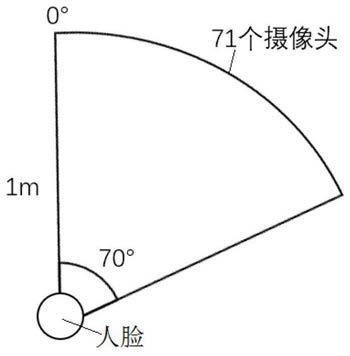
°
图像,所以转正效果有很大的提升。
24.(4)本发明设计了密集多角度唇部变化原始数据,不仅实现了单个摄像机自身图像的连续,而且最大限度地实现了唇部图像在观测范围内的连续,有效解决现有多角度模型无法处理实际环境中连续变化的唇部图像的问题,从而提高唇语识别精度。
附图说明
25.图1是本发明制作密集多角度唇部变化原始数据时的高清摄像头的摆放位置图;
26.图2是本发明的gan二阶段转换器矫正唇部偏转角度的转换过程图;
27.图3是本发明的tcn时间卷积网络的结构图;
28.图4是本发明的密集多角度唇部变化原始数据中的观测角度为35
°
处的摄像头拍摄图;
29.图5是本发明的图4经6号gan二阶段转换器矫正后生成的唇部偏转角度为0
°
的矫正后唇部图像;
30.图6是本发明的密集多角度唇部变化原始数据中的观测角度为0
°
处的摄像头拍摄图。
具体实施方式
31.下面给出本发明的具体实施例。具体实施例仅用于进一步详细说明本发明,不限制本申请权利要求的保护范围。
32.本发明提供了一种基于生成对抗网络和时间卷积网络的唇语识别方法(简称方法),其特征在于,该方法包括以下步骤:
33.s1、制作原始数据;所述原始数据包括识别网络原始数据和密集多角度唇部变化原始数据;
34.优选地,s1中,制作识别网络原始数据是:通过python网络爬虫从网络中获取源视频和字幕文件,使用yolov5人脸检测算法获得源视频中的人脸区域,再将人脸切分出来,并与字幕文件对应,得到识别网络原始数据,数据类型为视频;
35.优选地,为保证充足的样本量,提高网络应对多变的真实环境的能力,本方法的识别网络原始数据采用了多种数据来源,包括室内环境的样本(如广播电视台节目等)和室外环境的样本(如一天中不同时刻的街头采访视频);同时,为保证识别网络原始数据包含的数据样本稳定,在采集了大量数据后通过手动挑选,选出一些不同光照条件、不同唇部角度、多位说话者的共5000条数据,并将这些数据按照训练集:测试集=8:2的比例进行随机取样,训练集用于训练网络,测试集用于对比实验结果。识别网络原始数据中的每个带标签的视频长度为1秒,帧率为25帧/秒,并保存为rgb视频,至此完成了识别网络原始数据的采集。
36.优选地,s1中,制作密集多角度唇部变化原始数据是:为进一步提高唇语识别的准确率,在受试者面前放置高清摄像头,在每个受试者读出指定文字的过程中,摄像头记录不同观测角度α下的受试者唇部变化情况,并在记录过程中改变受试者所处的光照强度和光照角度以模拟真实环境,得到密集多角度唇部变化原始数据;定义人直视前方时的观测角度为0
°
,此时人脸与摄像头的光轴垂直;一般的人脸转角都不会超过70
°
,故观测角度α的范围为
‑
70
°
~70
°
。
37.优选地,在距离受试者唇部正前方1米处、唇部一侧(本实施例为右侧)观测角度α为0
°
~70
°
的范围内设置71个高清摄像头,每个摄像头间距为1
°
,如图1所示;视频录制长度为每个受试者20秒,帧率为25帧/秒,并保存为连续变化的唇部rgb图像;在录制完一侧的视频后,将这些视频水平翻转作为另一侧(观测角度α为
‑
70
°
~0
°
)的视频并保存为连续变化的唇部rgb图像,共得到141个观测角度下的所有图像,每个观测角度有若干张图像。
38.s2、由于识别网络原始数据中人脸的区域非常小,而唇语识别与人物背景无关,所以需要确定人脸在背景中的位置,并将特征提取出来;由于识别网络原始数据数量非常庞大,人工标注费时费力,故本方法分别对原始数据的每帧或每张图像(即识别网络原始数据的每帧以及密集多角度唇部变化原始数据的每张图像)用人脸标注算法(本实施例是dlib开源工具)标注人脸特征点,得到两个特征点位置数组并保存为单独的文件;将两个特征点位置数组与原始数据分开存放,以便后续计算调用;
39.特征点位置数组是原始数据的每帧或每张图像的特征点矩阵组成的序列;使用dlib开源工具进行人脸特征点标注,共得到68个人脸特征点。
40.s3、根据特征点位置数组中的原始数据特征点矩阵和平均人脸特征点矩阵,对原始数据的每帧或每张图像中的人脸分别进行人脸对齐,得到对齐后原始数据:根据已有数据使用dlib工具计算得到平均人脸特征点矩阵;分别从各自的特征点位置数组中选取所有的原始数据特征点矩阵,再使用普氏分析(procrustes analysis)分别计算每个原始数据特征点矩阵与平均人脸特征点矩阵的偏移量,再针对每个偏移量采用梯度下降法分别求得各自的最小偏移量,再根据各个最小偏移量将原始数据的每帧或每张图像中的人脸分别进行平移并旋转对齐,得到对齐后原始数据,进而完成人脸对齐,矫正人脸,减小面部倾斜对唇部特征提取的影响;
41.优选地,s3中,偏移量采用普氏分析计算得到,偏移量的计算过程如式(1)所示:
[0042][0043]
式(1)中,diff表示原始数据特征点矩阵与平均人脸特征点矩阵的差距,r是一个2
×
2的正交矩阵,s是标量,e是二维向量,p
i
表示原始数据特征点矩阵,q
i
表示平均人脸特征点矩阵。
[0044]
s4、人脸对齐完成后,因为除人脸外其他背景都将增加识别任务的难度,故本方法只保留人脸唇部区域固定大小的图像,从s2得到的人脸特征点中选取唇部特征点,再根据唇部特征点计算得到对齐后原始数据的每帧或每张图像中各自的唇部特征点的中心的坐标;再根据唇部特征点的中心的坐标将对齐后原始数据的每帧或每张图像中的唇部区域切
分为固定尺寸(本实施例是96
×
96像素)的唇部图像,进而分别得到密集多角度唇部变化数据集和识别网络数据集;
[0045]
优选地,s4中,对齐后原始数据的每帧或每张图像中各自的唇部特征点的中心的坐标的计算公式如式(2)所示:
[0046][0047]
式(2)中,x
i
表示第i帧或第i张图像中的唇部特征点的中心的横坐标,y
i
表示第i帧或第i张图像中的唇部特征点的中心的纵坐标;n表示唇部特征点的个数,本实施例中唇部特征点共有20个,故n=20;唇部特征点是从dlib开源工具定义的68个人脸特征点中选取20个与唇部相关的特征,即这20个人脸特征点位于唇部区域,故称之为唇部特征点且数量为20个。
[0048]
s5、使用密集多角度唇部变化数据集训练gan(生成对抗网络generative adversarial networks,其以u
‑
net为生成器,patch
‑
d为判别器)二阶段转换器和resnet角度分类器:实际环境中的唇语识别经常会受光照、角度等因素影响,而本方法设计gan二阶段转换器和resnet角度分类器将解决这一问题,因此需要首先训练gan二阶段转换器和resnet角度分类器;
[0049]
将密集多角度唇部变化数据集分为2α+1类,一类代表一个观测角度,来训练resnet角度分类器,得到一个训练后resnet角度分类器;
[0050]
将密集多角度唇部变化数据集划分为2*k
‑
1个部分,包括k个第一阶段转换集和k
‑
1个第二阶段转换集,再分别对应输入到gan二阶段转换器的第一阶段转换器和第二阶段转换器中进行训练,得到训练后gan二阶段转换器;其中训练后第一阶段转换器个数为k个,训练后第二阶段转换器个数为k
‑
1个;k表示划分区间的个数,本实施例中k=7;
[0051]
每个第一阶段转换集均包括输入和输出;输入为观测角度范围分成的k个角度范围中的一个,输出为该角度范围对应的转换点,其中含有0
°
的角度范围没有转换点;
[0052]
每个第二阶段转换集均包括输入和输出;输入为k
‑
1个转换点中的一个,输出为0
°
观测角度。
[0053]
具体是:将
‑
70
°
~70
°
的观测角度范围分成k个角度范围并分别作为k个第一阶段转换器的输入,将每个角度范围各自对应的k
‑
1个转换点(转换点为该角度范围内的一个固定角度,优选为角度范围的中点角度)分别作为k个第一阶段转换器的输出,来训练第一阶段转换器,其中含有0
°
的角度范围没有转换点;将k
‑
1个转换点分别作为k
‑
1个第二阶段转换器的输入,将0
°
观测角度作为输出,来训练第二阶段转换器;
[0054]
如图2所示,下面的小箭头表示第一阶段转换,上面的大箭头表示第二阶段转换。本实施例中角度范围[
‑
70
°
,
‑
50
°
]属于1号第一阶段转换器,(
‑
50
°
,
‑
30
°
]属于2号第一阶段转换器,(
‑
30
°
,
‑
10
°
]属于3号第一阶段转换器,(
‑
10
°
,10
°
]属于4号第一阶段转换器,(10
°
,30
°
]属于5号第一阶段转换器,(30
°
,50
°
]属于6号第一阶段转换器,(50
°
,70
°
]属于7号第一阶段转换器。1号第二阶段转换器的转换点为
‑
60
°
,2号第二阶段转换器的转换点为
‑
40
°
,3号第二阶段转换器的转换点为
‑
20
°
,5号第二阶段转换器的转换点为20
°
,6号第二阶段转换
器的转换点为40
°
,7号第二阶段转换器的转换点为60
°
。
[0055]
训练gan二阶段转换器时,例如6号第一阶段转换器使用(30
°
,50
°
]角度范围作为输入,40
°
转换点作为输出,来训练6号第一阶段转换器。但实验过程中发现,由于resnet角度分类器的分类准确率会有
±5°
的误差,为防止出现因分类误差造成的误用临近的第一阶段转换器造成的转换效果较差的现象,可将每个第一阶段转换器的覆盖范围增加10
°
至覆盖范围为30
°
,即可使用角度范围
±5°
作为输入,该角度范围对应的转换点作为输出,来训练第二阶段转换器;例如6号第一阶段转换器会使用(25
°
,55
°
]角度范围作为输入和40
°
转换点作为输出,6号第一阶段转换器会将此江角度范围内的图像转换到40
°
转换点,并由6号第二阶段转换器将40
°
转换点的图像转换为0
°
。考虑到第一阶段转换器转换的误差,可使用转换点
±2°
作为输入,0
°
作为输出,来训练第二阶段转换器;例如6号第二阶段转换器会用到38
‑
42
°
和0
°
的图像。
[0056]
s6、使用训练后resnet角度分类器和训练后gan二阶段转换器来矫正识别网络数据集,将其中发生偏转的唇部图像转正:使用opencv
‑
python库将识别网络数据集逐帧拆分成若干张待矫正唇部图像,然后输入到训练后resnet角度分类器中通过式(3)进行角度分类,得到每张待矫正唇部图像各自的唇部偏转角度θ:
[0057]
θ=classify(image)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0058]
式(3)中,image表示待矫正唇部图像,classify表示训练后resnet角度分类器;
[0059]
之后根据唇部偏转角度θ通过式(4)来确定使用的gan二阶段转换器编号i:
[0060][0061]
式(4)中,i表示gan二阶段转换器编号,1≤i≤k;运算符[]表示取整;
[0062]
然后将唇部偏转角度θ的待矫正唇部图像送入对应编号的训练后gan二阶段转换器中通过式(5)进行唇部矫正,得到矫正后唇部图像;矫正后唇部图像的唇部偏转角度θ为0
°
;再将矫正后唇部图像转化为灰度图后,再合并成矫正后唇部图像序列并存为npz格式文件,此过程耗时3h;
[0063][0064]
式(5)中,out表示输出,具体是矫正后唇部图像;first为第一阶段转换器,second为第二阶段转换器;
[0065]
训练后gan二阶段转换器的矫正过程是:将唇部偏转角度θ的待矫正唇部图像送入对应编号的训练后gan二阶段转换器的第一阶段转换器中,转换为相应编号的第二阶段转换器的转换点,再通过该编号的第二阶段转换器矫正为唇部偏转角度θ为0
°
的矫正后唇部图像。例如,某张待矫正唇部图像经过训练后resnet角度分类器计算得到唇部偏转角度为35
°
,则确定采用6号gan二阶段转换器,则通过6号第一阶段转换器将唇部偏转角度35
°
调整至40
°
的转换点,完成第一阶段转换;转换过程的第二阶段采用第二阶段转换器,将40
°
的转换点输入6号第二阶段转换器将其转换为0
°
的正脸,从而完成唇部图像的二阶段矫正过程,得到矫正后唇部图像。特殊地,当gan二阶段转换器编号i=4时,即角度范围在(
‑
10
°
,10
°
]时,只需要使用4号第一阶段转换器即可将唇部矫正为0
°
。
[0066]
s7、使用矫正后唇部图像序列训练tcn时间卷积网络:导入矫正后唇部图像序列并将其转换成维度为b
×
t
×
h
×
w的张量,其中b为批量大小(batch size),t为帧数,h为高度,w为宽度;再输入至resnet18唇部特征编码器进行编码,编码完成后输出维度为b
×
c
×
t的特征向量,其中c为通道数(本实施例设置为512),再作为输入,输入到tcn时间卷积网络中进行训练,得到预测结果;再使用ce loss(cross entropy loss)作为损失函数,根据预测结果和标签label的标注值计算tcn时间卷积网络的损失值loss;当损失值loss不再下降或者达到指定迭代次数时,训练结束,得到训练后tcn时间卷积网络;若loss仍然下降且未达到指定迭代次数时,由输出层至输入层逐层反向计算各层神经元输出误差,然后根据梯度下降法调节tcn时间卷积网络的各个权重值和偏置值,直到loss不再下降或达到指定迭代次数,使tcn时间卷积网络达到最优,训练结束,得到训练后tcn时间卷积网络;
[0067]
优选地,tcn时间卷积网络结构如图3所示,包括顺序执行的输入层(第一层)、第一隐含层(第二层)、第二隐含层(第三层)、输出层(第四层)、上采样层和softmax层;b
×
c
×
t的特征向量输入输入层中,之后经过扩张系数为1的扩张卷积的第一隐藏层,再经过扩张系数为2的扩张卷积的第二隐藏层,再经过扩张系数为4的扩张卷积的输出层,再经上采样层恢复为原始尺寸后,再通过softmax层的逻辑回归得到预测结果;在输入层和第一隐藏层、第一隐藏层和第二隐藏层以及第二层隐藏层和输出层之间加入跨层连接;
[0068]
优选地,扩张卷积的计算过程如式(6)所示:
[0069][0070]
式(6)中,f(s)表示对tcn时间卷积网络的相应层s进行扩张卷积操作,d表示扩张系数,ind表示卷积块编号,filt表示过滤器大小;
[0071]
优选地,跨层连接的计算过程如式(7)所示:
[0072]
o=activation(base+f(base))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0073]
式(7)中,o表示跨层连接后的输出,activation表示激活函数,f表示对base扩张卷积,base表示底层输入(即输入层和两层隐藏层输入);
[0074]
优选地,softmax层的计算过程如式(8)所示:
[0075][0076]
式(8)中,s
r
表示预测结果;r表示上采样层的第r个输出值,g表示上采样层的所有输出值;
[0077]
优选地,ce loss的计算过程如式(9)所示:
[0078][0079]
式(9)中,loss表示损失值;p(label)表示标签label的标注值,q(label)表示标签label的预测概率;
[0080]
s8、通过训练后tcn时序卷积网络来进行特征识别分类,生成唇语识别结果。
[0081]
通过实验表明,gan二阶段转换器的二阶段算法优势十分明显。本方法使用结构相似性(structural similarity,ssim)指标来衡量图片的转换质量。实验结果表明,二阶段转换比一阶段转换的ssim指数提升了7%,达到89%的结构相似性,进一步提升了唇语识别的精度。由图5和图6可以看出,经第二阶段转换器将图4转换成的人脸正面图像(如图5所示)与真实图像(如图6所示)的差距非常小。
[0082]
下面以两个具体的实验例对本方法的正确率做进一步描述。
[0083]
本实验例中,当预测的结果分类与标签的分类一致时才算预测结果正确。原始数据经筛选后共有400个单词。本实验设置了多个对比实验,每个对比实验中均使用resnet18唇部特征编码器进行编码,测试结果如表1所示:
[0084]
表1
[0085]
网络结构图像处理方式测试精度tcngan二阶段转换器95.6%tcn使用原图92.9%lstmgan二阶段转换器94.9%lstm使用原图91.7%
[0086]
可以看到,相比于仅使用唇部居中方法(即表1中的使用原图)预处理图像的算法,本发明采用的gan二阶段转换器对于不同的识别网络(即tcn和lstm)具有明显的精度提升,同时tcn较lstm(长短期记忆网络)也有精度提升。
[0087]
本发明未述及之处适用于现有技术。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1