一种注意力机制下的协同学习文字识别方法与流程
本发明涉及计算机视觉和机器学习领域,具体涉及一种注意力机制下的协同学习文字识别方法。
背景技术:
近些年,自然场景图像中的文字区域检测由于兼顾挑战性和和实用性一直是计算机视觉研究领域和工程应用领域的热门研究方向。一般来说,把从自然场景图像中提取文字信息定义为两个子任务:一是自然场景中的文本定位任务,二是自然场景文本识别任务。因此自然场景文本检测往往有如下两种框架,如图一是任务分离式框架,先进行文本区域定位,将检测出的文本框从原图中抠出作为文字识别模型的输入,得到该区域的文本信息。两种任务模型互不干涉。另一种是将两种任务整合到一个模型中进行端到端的优化。
分离式框架自然场景中文本区域定位,受到深度卷积在通用目标领域检测一阶检测算法和二阶检测算法的影响,当前主流的有两种方案:一种是anchor-based方法,另一种是regionproposal方法。由于自然场景文字识别因采集设备因素,光照,扭曲等问题和文档识别有很大不同。分离式框架中文字识别方案,基于卷积网络和时间序列模型成为了主流,主要衍生出两个方向:一是基于ctc转录的预测模型,另一种是基于注意力机制的sequence-to-sequence预测模型。
端到端的文字识别系统产生是受通用物体检测算法的启发,该方法将单词视为一种特殊的对象,将字符视为对象的一部分。通过对单个字符的检测和字符之间的空间关系建模来搜索最可能的识别结果。最近的端到端方案提出具有非常相似的整体架构,包括检测分支和识别分支。分别采用east和yolov2作为检测分支,并有一个类似的文本识别分支,对文本提议映射特征区域通过双线性采样映射到固定高度张量,然后通过基于ctc的转录为字符串。其中一方案基于注意力的识别分支中引入了显著性信息作为显性监督。
卷积网络的学习依赖大量的训练数据驱动,不同于印刷体文本图像可以采用多种方式生成逼真数据,自然场景下的文本数据集的标注需要耗费大量的人力物力。其中文本的精确位置标注作为标注最为耗时的一部分,其标注数据的数量和质量直接影响模型最后的性能表现。现有ocr模型方案主要针对完整及精确的标注数据。弱监督目标检测最近受到了很多关注,因为它只需要更简单的标注方式,如点标注,线标注或者图像级标注。其中图像级别的标注是指针对图像中含有的文本进行标注,而不需要具体的框画出字符的位置从而节省了大量的标注成本。作为强监督学习的替代方案,弱监督检测可从富媒体中以标签检索等方式快速获取大量的图像级注释数据。然而,弱信息标签通常是以模型精度为代价的,因此仅用弱标签训练出的ocr模型很能将其应用到真正的实际生活中。因此能否通过大量弱标注图像数据提升强监督学习模型的性能成为该领域的一个值得探究的研究方向,而将弱监督学习器和强监督学习器这两个相似的任务协同训练,使得大量的弱监督标签数据能够更好地提升强监督框架的准确度是一个行之有效的方法。
技术实现要素:
为解决上述背景技术中存在的问题,本发明目的是提出一种基于深度学习注意力机制下协同学习的文本识别方法。该实例包含一种基于注意力机制的上采样特征金字塔网络,和一种弱监督文本检测器和强监督文本检测器协同学习的框架。
实现本发明的技术思路是,构建协同监督数据集,利用协同监督数据集训练一个强文本检测网络和一个弱文本检测网络,构建协同框架保持感知一致性。把协同监督数据集输入到卷积网络提取特征,得到特征输入基于注意力机制的上采样网络,构建特征金字塔。构建强监督检测器与弱监督检测器,把特征金字塔分别输入到一个强文本检测网络分支和一个弱文本检测网络分支分别得到字符定位结果,构建协同框架保持两个子网络分支对于字符的定位结果的一致性。使得大量弱监督数据能够训练提升整体文字识别网络性能。
本发明的技术方案包含以下步骤:
步骤s1,构建协同监督图像数据集,并划分为训练集与测试集,所述数据集中包含全标注数据集与弱标注训练集;
步骤s2,构建主干神经网络模型,该模型包括基础特征提取模块、特征金字塔构建模块和特征金字塔融合模块;
步骤s3,构建一种弱监督文本检测器和强监督文本检测器协同学习的框架,该框架包括强监督检测器网络、弱监督检测器网络、分支任务协同学习模块和协同损失设计;
步骤s4,强弱监督协同学习网络的端到端训练,使用s1构建的图像数据集对步骤s2及s3构建的整体神经网络模型进行自监督训练。
进一步地,上述步骤s1所述数据集中包含带强标注的图片数据及带弱标注的图片数据。全标注数据集内部为带强标注的图片数据。
数据集来源于icdar2013,icdar2015,icdar2017mlt,icdar2017total-text等文本检测标准数据集。其中数据图像总量为5.5k,其中包含大量复杂背景,弯曲文本,模糊难以辨别的文本区域,测试集总共1.5k,而训练集则等比例划分1:3为全标注数据集1k和弱标注训练集3k。
进一步地,上述步骤s2所述主干神经网络模型包括基础特征提取模块、特征金字塔构建模块、特征金字塔融合模块3个组成部分。本发明所设计的主干神经网络架构具体如下:。
基础特征提取模块是vgg-net的前四层卷积,原始输入图片尺寸(h×w×3),从第一层至第四层输出尺寸分别为
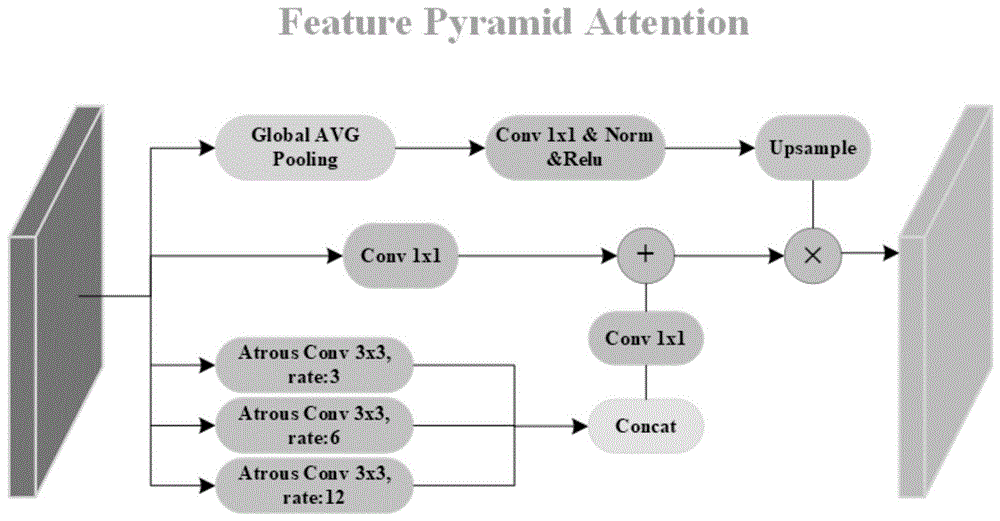
特征金字塔构建模块是attention-basedfeaturepyramidnetwork(fpn-attention)特征金字塔网络。输入基础特征提取模块的输出特征图,进行多尺度上采样,构建了含三种感受野的特征金字塔。具体过程如下:
vgg-net中conv4层的输出特征图
将特征金字塔构建模块输出的三个特征图尺寸为
将特征金字塔融合特征图
同时结合全局池化的注意力分支可以学习更好的高级特征表示。从高级特征生成的全局上下文是通过1×1卷积、normalization及relu实现的。通过上采样后的注意力权重与底层特征
特征融合模块。采用新型特征上采样结构featureattentionup-sample(fau),它能有效地利用高层特征指导监督底层特征融合。利用了fau结构思想构建,将特征金字塔构建模块与基础特征提取模块的特征融合。具体过程如下:
fau结构包含两种注意力机制,分别是channelattention和positionattention。假设low-levelfeaturemap的大小为(h×w×c),high-levelfeaturemap的大小为
融合过程包含前4个基础特征提取模块与一个含特征金字塔层模块特征融合处理,得到步骤2最终的三个不同尺度特征。具体工作流程如下:
将第二层基础特征提取模块输出结果
将第三层基础特征提取模块输出结果
将含特征金字塔层模块输出结果作为一个
针对原始输入图像尺寸为(h×w×3)步骤s2最终的三个不同特征尺寸分别为
进一步地,步骤s3构建一种弱监督文本检测器和强监督文本检测器协同学习的框架,该框架包括强监督检测器网络、弱监督检测器网络、分支任务协同学习模块和协同损失设计,如图4,步骤s2构建的主干神经网络模型的输出,作为步骤s3强监督检测器网络与弱监督检测器网络的输入。本发明所设计的协同框架具体如下:
步骤s3-1,构建强监督检测器网络,主要包含rpn网络模块、预测框分类和回归任务模块与分割支路模块3个部分。详细过程如下:
backbone特征图是步骤s2输出多尺度的特征图
rpn网络模块是输入backbone特征图,通过rpn网络对特征层提取可能包含文字区域的roi特征。该模型中关于anchor尺寸的初始化采用fpn算法的方式。
预测框分类和回归任务模块主要使用fastrcnn模型,rpn网络模块为该模块生成文本提议,把roi特征经过roialign算法输出7×7分辨率图片,将7×7分辨率图片作为fastrcnn的输入,通过全连接卷积实现对预测框回归与分类
分割支路模块包含单独的文本分割(wordsegmentation)和文本识别(characterinstancesegmentation)两个分割支路。
标签如下:
p={p1,p2...pm}
c={c1=(cc1,cl1),c2=(cc2,cl2),...,cn=(ccn,cln)}
这里的pi是表示文本区域的标注的多边形,ccj和clj分别是字符的类别和位置。rpn网络模块为该模块提供mask输入。首先输入roi特征图的二维尺寸为16×64,然后经过一些卷积层和反卷积层继续提取特征,最后通过卷积核数量为38的卷积层输出38个map,每个map的二维尺寸都是32×128,首先将多边形以最小外接矩形的方式转换为水平矩形。之后为mask分支生成两种类型的目标图分别是用于文本实例分割的全局图(globalwordmap)和字符语义分割的字符图(charactermap)。但是在characterinstancesegmentation分支中,并不是直接回归单个字符的位置,而是通过高斯卷积核对字符图进行卷积生成的字符位置密度图。
步骤s3-2,构建弱监督检测器网络,包含弱监督注意力感知与特征融合两个模块。
把步骤s2得到的金字塔特征图输入rpn算法进行弱监督注意力感知,骤s2输出的金字塔特征图在经过1x1卷积、relu、1x1卷积及sigmoid得到相应的感知权重,步骤s2得到的输出经过3x3卷积提取结果与上述感知权重点乘,点乘后的结果叠加到步骤s2得到的输出经过3x3卷积提取结果上。
特征融合模块是特征图经过弱监督注意力感知后,将三层卷积层的前两层上采样之后和第三层合并为图样大小的特征层,在经过3x3卷积后将其通道数降为36,在经过globalaveragepooling作为聚合及sigmoid输出多标签类别向量。
由于这种设计,上一层卷积隐藏层的每一个通道对应一个相应的字符,起诉至对应着相应的类激活图,将每一个字符的激活图累加得到最终的的文字区域激活图
步骤s3-3,分支任务协同学习,包含对强监督分支网络与弱监督分支网络的分析及实现算法。
强监督分支网络,不直接预测字符图(charactermap),而是预测字符密度图(characterdensitymap)。字符图可以看作是字符中心位置在图中的坐标预测,而字符密度图可以认为是字符中心在图中的在该像素出现的概率图。其次弱监督网络采用了全卷积网络,在最后的卷积特征图含有36通道,经globalaveragepooling直接得到对应每个字符的置信度,因此卷积特征图通道和字符是一一对应的。所以本发明认为弱监督网络的最后一层特征图和强监督网络的字符分割分支回归字符密度图的任务是相同的,应该在训练过程中保持感知一致性。
在弱标签数据训练弱监督分支任务时,强监督分支的字符密度图应该与弱监督分支的字符密度图保持一致,从而产生感知一致性loss协同监督强分支网络,在训练强监督分支任务时,弱监督分支产生的密度图应该与强监督分支产生的字符密度图保持一致,从而通过感知一致loss协同监督弱监督分支网络。
分支任务协同学习实现手段:将经过roialign采样后的特征图预测对应弱监督分支网络的中间层结果,类似roiupsample采样,可以看作是roialign的逆操作,根据对应的roi的精确空间位置恢复特征贴图。
步骤s3-4,构建协同损失网络
为了更好地监督两个分支网络的互补学习过程,模型训练设计了一下两组损失函数:第一组损失是关于强监督子任务分支和弱监督子任务分支损失函数。第二组侧重于检查两个分支网络之间的感知一致性损失。
对于强监督子网络,损失函数分为以下几个部分:1、rpn网络的lrpn;2、fastrcnn的分类和回归lrcnn;3、分割支路的lmask,实验中α1、α2和β都设置为1。其中前两部分损失函数和fastrcnn一致,重点在于分割支路的lmask。
ltotal=lrpn+α1lrcnn+α2lmask
分割支路损失函数lmask所示,主要包含两个部分:1、文本分割的损失函数lglobal,这部分是针对分割支路的mask输出分支;2、文本分割(识别)的损失函数lchar,这部分是针对分割支路输出的38个channel的后36个channel进行计算。
lmask=lglobal+βlchar
lglobal采用crossentropyloss,n表示输出map的点数量;yn∈[0,1],表示每个像素点的标签;x表示分割支路输出的预测图的第n个像素值;输入概率是通过sigmoid函数s(x)得到的。
lchar不同于masktextspotter,对字符的位置采用了密度图的方式回归,因此采用crossentropyloss衡量期间的损失。其中n带指的是特定通道的像素。
对于弱监督子任务,它输出图像级别上的字符类别预测。鉴于图像级别的监督较弱,以图像级别预测的多标签二元交叉熵损失的形式定义分类损失,其中c带指的是字符的种类:
对于感知一致性损失函数,为了避免训练初始阶段弱监督检测器和强监督检测器糟糕的性能导致误差过大影响网络收敛,采用基于loss的加权样本的方式,其中m是roi的经筛选之后得到的数量,λ是平衡两个损失函数权值,实际实验中设值为2。
其中密度图采用欧氏距离来衡量其差距,其中n指代的像素数量,x是密度估计图对应的激活值,i是对应像素位置:
进一步地,步骤s4,强弱监督协同学习网络的端到端训练,使用s1构建的图像数据集对步骤s2及s3构建的整体神经网络模型进行自监督训练。方法如下:
采用sgd进行优化,优化器的参数设置略有不同,其中强文本检测分支初始学习率设置为0.005,权重衰减为0.0001,动量为0.9。弱文本检测分支初始学习速率设置为0.01,权重衰减为0.0005,动量为0.9.rpn和roihead的训练样本roi的数量设置为256和512,具有1:3的正数与负数的采样比。mask分支的roi训练样本为16。在训练时采用数据增强,包含扭曲,旋转,多尺度训练,文本裁切,遮挡,模糊。对于多尺度训练,输入图像的短边随机调整为三个尺度(600,800,1000)。将batchsize设置为1,在强监督标注数据和弱监督标注数据轮次迭代,在迭代70k时候停止。
在损失函数部分,设置强监督学习器的lmask,lrcnn,lrcnn比例系数为1:1:1,其中lmask中的β设置为2.在感知一致性损失中,λ1和λ2比例设置为1和10。该模型是并行训练的,并在单个gpu上进行评估。
在测试阶段,输入图像的比例取决于不同的数据集。在nms之后,1000个提议被输入fastr-cnn。fastr-cnn和nms分别过滤掉错误和冗余候选框。保留的候选框被输入到掩码分支以生成全局文本实例映射和字符映射。最后,从预测的映射生成文本实例边界框和序列。
本发明的优点:
1、本发明设计了一种适用于协同训练模型的注意力感知主干网络(featurepyramidnetworkwithattention,fpn-attention),该网络使用大量特征注意力模块用于更好的通过大量弱标签数据训练使得强监督模型对于背景误检率显著降低。通过设计featureattentionup-sample(fau)模块改进了传统的反卷积或者双线性插值上采样,使模型在上采样过程中可以避免引入背景噪声。通过featurepyramidattention(fpa)和featureattentionup-sample(fau)堆叠,主干网络在不损失卷积感受野的情况下拥有更高分辨率和更有效的特征图。
2、本发明创新地提出一种基于注意力机制的弱监督检测器和强监督检测器协同学习的框架,将弱监督学习网络和强监督学习网络连接成为一个整体网络,在共享主干网络的同时也通过rpn-attention将强监督任务和弱监督任务更好地结合在一起。通过量化强监督和弱监督学习网络间感知水平上的一致性,实现强监督和弱监督学习网络的协同增强学习并从开源的数据集中构建了严格的对比实验数据集,与其他的工作比较,本发明的训练框架取得了先进性效果。本发明基于深度卷积神经网络,在光学字符检测领域寻求更为有效的混合协同监督框架,使得强监督文字检测模型能通过海量的弱监督数据进一步提升性能。
附图说明
图1是本发明实例的fpn-attention特征金字塔模型架构图。
图2是本发明实例的fau特征融合模型架构图。
图3是本发明实例的fpa与fau特征交互工作流程图。
图4是本发明实例的文本检测协同学习框架结构示意图。
具体实施方式
为使本发明实施方式的目的、技术方案和和特点说明更加清楚,下面结合本发明的附图,对本发明实施方式中的技术方案进行清晰、完整地描述。显然,所描述的实施方式是本发明实施方法中的一部分,而不是全部。本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施方式,都属于本发明保护的范围。因此,以下对在本发明附图中所提供的消息描述并非旨在限制要求本发明的保护范围,而是仅仅表示本发明的选定实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施方式,都属于本发明保护的范围。
为解决上述背景技术中存在的问题,本发明目的是提出一种基于深度学习注意力机制下协同学习的文本识别方法。该实例包含一种基于注意力机制的上采样特征金字塔网络,和一种弱监督文本检测器和强监督文本检测器协同学习的框架。图1是本发明实例的fpn-attention特征金字塔模型架构图。图2是本发明实例的fau特征融合模型架构图。图3是本发明实例的fpa与fau特征交互工作流程图。图4是本发明实例的文本检测协同学习框架结构示意图。
本发明的技术方案包含以下步骤:
步骤s1,构建协同监督图像数据集,并划分为训练集与测试集,所述数据集中包含全标注数据集与弱标注训练集;
步骤s2,构建主干神经网络模型,该模型包括基础特征提取模块、特征金字塔构建模块和特征金字塔融合模块;
步骤s3,构建一种弱监督文本检测器和强监督文本检测器协同学习的框架,该框架包括强监督检测器网络、弱监督检测器网络、协同损失网络;
步骤s4,强弱监督协同学习网络的端到端训练,使用s1构建的图像数据集对步骤s2及s3构建的整体神经网络模型进行自监督训练。
进一步地,上述步骤s1所述数据集中包含带强标注的图片数据及带弱标注的图片数据。全标注数据集内部为带强标注的图片数据。
数据集来源于icdar2013,icdar2015,icdar2017mlt,icdar2017total-text等文本检测标准数据集。其中数据图像总量为5.5k,其中包含大量复杂背景,弯曲文本,模糊难以辨别的文本区域,测试集总共1.5k,而训练集则等比例划分1:3为全标注数据集1k和弱标注训练集3k。
进一步地,上述步骤s2所述主干神经网络模型包括基础特征提取模块、特征金字塔构建模块、特征金字塔融合模块3个组成部分。本发明所设计的主干神经网络架构具体如下:。
基础特征提取模块是vgg-net的前四层卷积,原始输入图片尺寸(h×w×3),输入到第一层卷积(包含两次卷积:卷积核大小都为3×3,卷积核个数为64,使用relu激活;),然后经过maxpool,得到从第一层输出尺寸分别为
特征金字塔构建模块是attention-basedfeaturepyramidnetwork(fpn-attention)特征金字塔网络,如图1所示。输入基础特征提取模块的输出特征图,进行多尺度上采样,构建了含三种感受野的特征金字塔。具体过程如下:
vgg-net中conv4层的输出特征图
将特征金字塔构建模块输出的三个特征图尺寸为
将特征金字塔融合特征图
同时结合全局池化的注意力分支可以学习更好的高级特征表示。从高级特征生成的全局上下文是通过1×1卷积、normalization及relu实现的。通过上采样后的注意力权重与底层特征
特征融合模块。本发明采用新型特征上采样结构featureattentionup-sample(fau),它能有效地利用高层特征指导监督底层特征融合。利用了fau结构思想构建,将特征金字塔构建模块与基础特征提取模块的特征融合。具体过程如下:
fau结构包含两种注意力机制,分别是channelattention和positionattention。假设low-levelfeauremap的大小为(h×w×c),high-levelfeaturemap的大小为
融合过程包含前4个基础特征提取模块与一个含特征金字塔层模块特征融合处理,得到步骤2最终的三个不同尺度特征,如图3。具体工作流程如下:
将第二层基础特征提取模块输出结果
将第三层基础特征提取模块输出结果
将含特征金字塔层模块输出结果作为一个
针对原始输入图像尺寸为(h×w×3),步骤s2最终的三个不同特征尺寸分别为
进一步地,步骤s3构建一种弱监督文本检测器和强监督文本检测器协同学习的框架,该框架包括强监督检测器网络、弱监督检测器网络、协同损失网络,如图4,步骤s2构建的主干神经网络模型的输出,作为步骤s3强监督检测器网络与弱监督检测器网络的输入。本发明所设计的协同框架具体如下:。
步骤s3-1,构建强监督检测器网络,主要包含rpn网络模块、预测框分类和回归任务模块与分割支路模块3个部分。详细过程如下:
backbone特征图是步骤s2输出多尺度的特征图
rpn网络模块是输入backbone特征图,通过rpn得到roi结果。根据anchor大小在不同阶段分配anchor。为后续的fast-r-cnn分类与回归任务模块生成文本提议和mask分支。
构建强监督检测器网络,主要包含rpn网络模块、预测框分类和回归任务模块与分割支路模块3个部分。详细过程如下:
backbone特征图是步骤s2输出多尺度的特征图,也就是
rpn网络模块是输入backbone特征图,通过rpn网络对特征层提取可能包含文字区域的roi特征。该模型中关于anchor尺寸的初始化采用fpn算法的方式,宽高比例采用0.5、1和2,anchor大小设置为(32×32,64×64,128×128,256×256,512×512),步长设置为2.
预测框分类和回归任务模块主要使用fastrcnn模型,rpn网络模块为该模块生成文本提议,把roi特征经过roialign算法输出7×7分辨率图片得到(7×7×256),将7×7分辨率图片作为fastrcnn的输入,通过全连接卷积实现对预测框回归与分类。将(7×7×256)输入到一个卷积层(卷积核大小为7×7,卷积核个数为1024,使用relu激活),再输入到一个卷积层(卷积核大小为1×1,卷积核个数为1024,使用relu激活)得到预测框分类及回归结果。
分割支路模块包含单独的文本分割(wordsegmentation)和文本识别(characterinstancesegmentation)两个分割支路。
标签如下:
p={p1,p2...pm}
c={c1=(cc1,cl1),c2=(cc2,cl2),...,cn=(ccn,cln)}
这里的pi是表示文本区域的标注的多边形,ccj和clj分别是字符的类别和位置。rpn网络模块为该模块提供mask输入。首先输入roi特征图的二维尺寸为16×64,然后经过4个卷积,1个反卷积提取特征,输出的大小都为(16×64×256),最后通过卷积核数量为38的卷积层输出38个map,每个map的尺寸都是(32×128×256),首先将多边形以最小外接矩形的方式转换为水平矩形。之后为mask分支生成两种类型的目标图分别是用于文本实例分割的全局图(globalwordmap)和字符语义分割的字符图(charactermap)。但是在characterinstancesegmentation分支中,并不是直接回归单个字符的位置,而是通过高斯卷积核对字符图进行卷积生成的字符位置密度图。
密度图的计算方式:假设xi表示字符中心位置坐标,gi代表的是高斯核,则密度图的计算公式
步骤s3-2,构建弱监督检测器网络,包含弱监督注意力感知与特征融合两个模块。
把步骤s2得到的金字塔特征图输入rpn算法进行弱监督注意力感知,骤s2输出的金字塔特征图在经过1x1卷积、relu、1x1卷积及sigmoid得到相应的感知权重,步骤s2得到的输出经过3x3卷积提取结果与上述感知权重点乘,点乘后的结果叠加到步骤s2得到的输出经过3x3卷积提取结果上。
特征融合模块是特征图经过弱监督注意力感知后,将三层卷积层的前两层上采样之后和第三层合并为图样大小的特征层,在经过3x3卷积后将其通道数降为36,在经过globalaveragepooling作为聚合及sigmoid输出多标签类别向量。
由于这种设计,上一层卷积隐藏层的每一个通道对应一个相应的字符,起诉至对应着相应的类激活图,将每一个字符的激活图累加得到最终的的文字区域激活图
步骤s3-4,分支任务协同学习,包含对强监督分支网络与弱监督分支网络的分析及实现算法。
强监督分支网络,不直接预测字符图(charactermap),而是预测字符密度图(characterdensitymap)。字符图可以看作是字符中心位置在图中的坐标预测,而字符密度图可以认为是字符中心在图中的在该像素出现的概率图。其次弱监督网络采用了全卷积网络,在最后的卷积特征图含有36通道,经globalaveragepooling直接得到对应每个字符的置信度,因此卷积特征图通道和字符是一一对应的。所以弱监督网络的最后一层特征图和强监督网络的字符分割分支回归字符密度图的任务是相同的,应该在训练过程中保持感知一致性。
在弱标签数据训练弱监督分支任务时,强监督分支的字符密度图应该与弱监督分支的字符密度图保持一致,从而产生感知一致性loss协同监督强分支网络,在训练强监督分支任务时,弱监督分支产生的密度图应该与强监督分支产生的字符密度图保持一致,从而通过感知一致loss协同监督弱监督分支网络。
分支任务协同学习实现手段:将经过roialign采样后的特征图预测对应弱监督分支网络的中间层结果,类似roiupsample采样,可以看作是roialign的逆操作,根据对应的roi的精确空间位置恢复特征贴图。
步骤s3-4,构建协同损失网络
为了更好地监督两个分支网络的互补学习过程,为模型训练设计了一下两组损失函数:第一组损失是关于强监督子任务分支和弱监督子任务分支损失函数。第二组侧重于检查两个分支网络之间的感知一致性损失。
对于强监督子网络,损失函数分为以下几个部分:1、rpn网络的lrpn;2、fastrcnn的分类和回归lrcnn;3、分割支路的lmask,实验中α1、α2和β都设置为1。其中前两部分损失函数和fastrcnn一致,重点在于分割支路的lmask。
ltotal=lrpn+α1lrcnn+α2lmask
分割支路损失函数lmask所示,主要包含两个部分:1、文本分割的损失函数lglobal,这部分是针对分割支路的mask输出分支;2、文本分割(识别)的损失函数lchar,这部分是针对分割支路输出的38个channel的后36个channel进行计算。
lmask=lglobal+βlchar
lglobal采用crossentropyloss,n表示输出map的点数量;yn∈[0,1],表示每个像素点的标签;x表示分割支路输出的预测图的第n个像素值;输入概率是通过sigmoid函数s(x)得到的。
lchar不同于masktextspotter,对字符的位置采用了密度图的方式回归,因此采用crossentropyloss衡量期间的损失。其中n带指的是特定通道的像素。
对于弱监督子任务,它输出图像级别上的字符类别预测。鉴于图像级别的监督较弱,以图像级别预测的多标签二元交叉熵损失的形式定义分类损失,其中c带指的是字符的种类:
对于感知一致性损失函数,为了避免训练初始阶段弱监督检测器和强监督检测器糟糕的性能导致误差过大影响网络收敛,采用基于loss的加权样本的方式,其中m是roi的经筛选之后得到的数量,λ是平衡两个损失函数权值,实际实验中设值为2。
其中密度图采用欧氏距离来衡量其差距,其中n指代的像素数量,x是密度估计图对应的激活值,i是对应像素位置:
进一步地,步骤s4,强弱监督协同学习网络的端到端训练,使用s1构建的图像数据集对步骤s2及s3构建的整体神经网络模型进行自监督训练。方法如下:
采用sgd进行优化,优化器的参数设置略有不同,其中强文本检测分支初始学习率设置为0.005,权重衰减为0.0001,动量为0.9。弱文本检测分支初始学习速率设置为0.01,权重衰减为0.0005,动量为0.9.rpn和roihead的训练样本roi的数量设置为256和512,具有1:3的正数与负数的采样比。mask分支的roi训练样本为16。在训练时采用了数据增强,包含扭曲,旋转,多尺度训练,文本裁切,遮挡,模糊。对于多尺度训练,输入图像的短边随机调整为三个尺度(600,800,1000)。将batchsize设置为1,在强监督标注数据和弱监督标注数据轮次迭代,在迭代70k时候停止。
在损失函数部分,设置强监督学习器的lmask,lrcnn,lrcnn比例系数为1:1:1,其中lmask中的β设置为2.在感知一致性损失中,λ1和λ2比例设置为1和10。该模型是并行训练的,并在单个gpu上进行评估。
在测试阶段,输入图像的比例取决于不同的数据集。在nms之后,1000个提议被输入fastr-cnn。fastr-cnn和nms分别过滤掉错误和冗余候选框。保留的候选框被输入到掩码分支以生成全局文本实例映射和字符映射。最后,从预测的映射生成文本实例边界框和序列。
训练方式比对实验:
由于本发明中的模型采用协同监督的方式,其中强标注样本1k,弱标注样本3k。但是本发明中的模型也可以只进行强监督或只进行弱监督训练。为此,首先划定数据集范围,并注明标识,如下所示:
(1):1k具有完全标注样本
(2):1k+3k具有完全标注的样本
(3):3k具有图像级标注的样本
(4):3k+1k具有图像级标注的样本
(5):1k完全标注和3k弱标注的训练样本
为了探究训练方式对模型的影响,模型自身的训练方式比较。模型训练方式总计有三种方式:
(1)第一种是全强监督训练方式,这种情况训练数据为完全标注样本,同时生成图像级弱标注用于监督弱监督分支网络,最后评估强监督子网络的检测效果。
(2)第二种是全弱监督训练方式,这种情况训练数据为图像级标注样本,强监督网络仅通过感知一致性约束学习,最后评估强监督子网络的检测效果。
(3)第三种是协同监督训练方式,通过部分完全标注样本和大量图像级标注样本,训练协同框架,最后评估强监督子网络的检测效果。
对比结果见下表:
本发明优点:
1.本发明设计了一种适用于协同训练模型的注意力感知主干网络(featurepyramidnetworkwithattention,fpn-attention),该网络使用大量特征注意力模块用于更好的通过大量弱标签数据训练使得强监督模型对于背景误检率显著降低。通过设计featureattentionup-sample(fau)模块改进了传统的反卷积或者双线性插值上采样,使模型在上采样过程中可以避免引入背景噪声。通过featurepyramidattention(fpa)和featureattentionup-sample(fau)堆叠,主干网络在不损失卷积感受野的情况下拥有更高分辨率和更有效的特征图。
2.本发明创新地提出一种基于注意力机制的弱监督检测器和强监督检测器协同学习的框架,将弱监督学习网络和强监督学习网络连接成为一个整体网络,在共享主干网络的同时也通过rpn-attention将强监督任务和弱监督任务更好地结合在一起。通过量化强监督和弱监督学习网络间感知水平上的一致性,实现强监督和弱监督学习网络的协同增强学习并从开源的数据集中构建了严格的对比实验数据集,与其他的工作比较,本发明的训练框架取得了先进性效果。本发明基于深度卷积神经网络,在光学字符检测领域寻求更为有效的混合协同监督框架,使得强监督文字检测模型能通过海量的弱监督数据进一步提升性能。
- 还没有人留言评论。精彩留言会获得点赞!