一种基于感受野感知的无锚点框目标检测方法与流程
1.本发明涉及视频图像处理领域,尤其涉及一种基于感受野感知的无锚点框目标检测方法。
背景技术:
2.目标检测技术在计算机视觉领域中是一项非常具有研究意义的课题,其主要任务是预测物体的位置以及种类。
3.目前,主流的经典检测模型无论是单阶段的检测模型,如ssd,yolo目标检测算法,还是两阶段的检测模型,如faster r
‑
cnn等,都是基于一系列预先设置好超参数的锚点框,通过在不同特征层上设置不同的尺度的锚点框,实现更高的概率出现对于目标物体有良好匹配度的目标框。
4.但是,基于锚点框设置的目标检测方法却有面临着以下挑战:1.锚点框的尺度设计无法完全覆盖所有的目标检测物体,每遇到一个全新的数据集都需要根据数据集的特点重新设置锚点框的数量和纵横比,限制了检测模型的通用性和鲁棒性;2.将锚点框与真实框进行匹配是依赖于iou参数的设置决定的,其阈值往往是依据经验设定;3.根据针对不同尺寸的目标检测物体设置的锚点框的数量,往往会增加冗余计算,计算耗时等等;4.过多设置的锚点框在实际处理中会被标注为负样本,增加了正负样本数量上的不均衡,影响分类器的训练。
技术实现要素:
5.本发明所要解决的技术问题是,提供一种基于感受野感知的无锚点框目标检测方法,其舍弃了传统的锚点框引入,整体结构更简单,无多余分支,检测进度和检测速度更为明显。
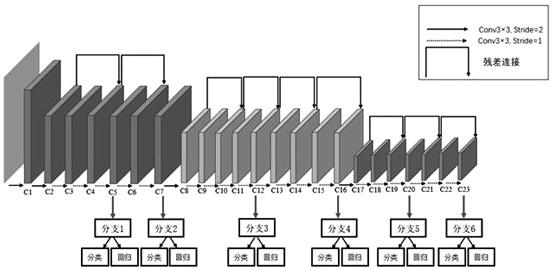
6.为了解决上述技术问题,本发明是通过以下技术方案实现的:一种基于感受野感知的无锚点框目标检测方法,将感受野作为锚点框,具有由23个卷积层构成并且分为三大检测单元的网络;所述三大检测单元分别为小尺度目标检测单元、中等尺度目标检测单元和大尺寸目标检测单元;每一个单元根据感受野大小选择两个分支进行分类与回归操作,共可以获得6个检测分支,每两个分支负责对不同尺度的各自单元目标进行检测;其中,分类分支用于确定所检测的目标是否为所需要的目标,回归分支用于获取目标框的位坐标信息。
7.进一步地,所述网络总体由3
×
3卷积核、1
×
1卷积核、relu激活函数以及残差边连接构成。
8.进一步地,所述感受野的计算公式如下:
[0009][0010]
其中,l
k
‑1为第k
‑
1层对应的感受野大小,f
k
为第k层的卷积核大小;根据上述公式
可以得到所提出的检测框架各个卷积层对应的感受野大小,通过数据增广方法增加光噪声、更改亮度对比度,随机水平翻转,其中以0.5的概率对子图进行随机翻转,通过损失函数根据损失值对负样本排序,以正负样本1:10的比例选取排名靠前的负样本。
[0011]
进一步地,所述损失函数是分类损失和回归损失的加权和。
[0012]
进一步地,所述分类损失采用交叉熵损失,所述交叉熵损失函数公式如下:
[0013][0014]
其中,h为交叉熵的计算值,即损失的计算值;p为真实概率分布,即分类函数的预测概率值;q为非真实概率分布,即分类函数的预测概率值的补集;i为每一个类别的下标。
[0015]
进一步地,所述回归损失采用smooth l1损失函数,其公式如下:
[0016][0017]
回归真实值设定为:
[0018][0019]
其中,rf
x
,rf
y
为感受野的中心坐标,rf
s
为感受野的边长,与为目标框的左上角的坐标,与为目标框的右上角的坐标。
[0020]
与现有技术相比,本发明的有益之处在于:这种基于感受野感知的无锚点框目标检测方法具有以下优势:
[0021]
1.该目标检测模型取消了锚点框设置,避免了以往对锚点框数量、大小、比例的参数设定,减少了模型的计算复杂度,提高了目标检测模型的通用性和鲁棒性;
[0022]
2.该目标检测模型利用不同大小的感受野回归预测目标的位置和种类,感受野小的特征图,像素点映射回输入图像包含的区域小,负责预测小尺寸的目标物体。感受野大的特征图,像素点映射回输入图像包含的区域大,负责预测大尺寸的目标物体,这样,该方法可以很好地预测连续多尺度目标物体;
[0023]
3.该网络模型仅仅由3
×
3,1
×
1卷积核构成,模型是非简单并且模型参数非常小,可以很方便地在嵌入式设备上进行移植应用,适合边缘设备等。
附图说明
[0024]
图1是本发明基于感受野感知的无锚点框目标检测总体框架;
[0025]
图2是检测框架中各个卷积层对应的感受野大小;
[0026]
图3至图5是本发明与其他行人检测方法在caltech数据集评估检测结果对比图。
具体实施方式
[0027]
下面结合附图和具体实施方式对本发明进行详细描述。
[0028]
一种基于感受野感知的无锚点框目标检测方法,如图1所示,将感受野作为锚点框,具有由23个卷积层构成并且分为三大检测单元的网络;所述三大检测单元分别为小尺
度目标检测单元、中等尺度目标检测单元和大尺寸目标检测单元;每一个单元根据感受野大小选择两个分支进行分类与回归操作,共可以获得6个检测分支,每两个分支负责对不同尺度的各自单元目标进行检测;其中,分类分支用于确定所检测的目标是否为所需要的目标,回归分支用于获取目标框的位坐标信息;所述网络总体由3
×
3卷积核、1
×
1卷积核、relu激活函数以及残差边连接构成。
[0029]
所述感受野的计算公式如下:
[0030][0031]
其中,l
k
‑1为第k
‑
1层对应的感受野大小,f
k
为第k层的卷积核大小;根据上述公式可以得到所提出的检测框架各个卷积层对应的感受野大小(参见说明书附图2所示),通过数据增广方法增加光噪声、更改亮度对比度,随机水平翻转,其中以0.5的概率对子图进行随机翻转,通过损失函数根据损失值对负样本排序,以正负样本1:10的比例选取排名靠前的负样本。
[0032]
所述损失函数是分类损失和回归损失的加权和。
[0033]
所述分类损失采用交叉熵损失,所述交叉熵损失函数公式如下:
[0034][0035]
其中,h为交叉熵的计算值,即损失的计算值;p为真实概率分布,即分类函数的预测概率值;q为非真实概率分布,即分类函数的预测概率值的补集;i为每一个类别的下标。
[0036]
所述回归损失采用smooth l1损失函数,其公式如下:
[0037][0038]
回归真实值设定为:
[0039][0040]
其中,rf
x
,rf
y
为感受野的中心坐标,rf
s
为感受野的边长,与为目标框的左上角的坐标,与为目标框的右上角的坐标。
[0041]
具体地,在训练过程中采用了难分类负样本挖掘,对负样本损失值排序后选择最高的几个,保证正负样本1:10。
[0042]
以caltech行人检测数据集为例,对比验证所提出算法的先进性;其中,实验环境配置:ubuntu18.04,gpu型号为gtx2080ti,cudnn版本为8.0.5,cpu型号为intel(r)core(tm)i7
‑
10850k@3.60ghz;最大迭代次数:1,800,000次;训练批次尺寸batch_size:32;学习率:初始学习率为0.001,在迭代至600,000次、1,200,000次的时候学习率衰减10倍;反向传播方法:sgd随机梯度下降算法;动量参数:0.9;分类iou阈值参数:0.5。
[0043]
如图3至5所示,为该发明方法(命名为rfa
‑
lf)与其他行人检测方法在caltech数据集评估检测结果图,对比结果显示该方法方法在“near”、“medium”、“far”即“近”、“中”、“远”三种不同尺度的行人目标评估准则下均表现优异。
[0044]
这种基于感受野感知的无锚点框目标检测方法将感受野充分当做“天然的”锚点框,舍弃了传统的锚点框引入,通过对每个特征层上感受野进行利用,将不同特征层上不同尺度的感受野当做不同尺度的锚点框用以检测不同的物体;浅层的特征层感受野比较小,负责检测小尺寸物体,深层的特征层感受野比较大,负责检测大尺寸物体,这样具有不同大小感受野的特征层可以很好地覆盖连续的不同尺寸的目标,该方法仅仅利用1
×
1以及3
×
3卷积核构成,整体结构简单,无多余分支,相比较传统的ssd以及fasterrcnn方法,在检测进度和检测速度上都有明显的优势;其具体优点如下:
[0045]
1.该目标检测模型取消了锚点框设置,避免了以往对锚点框数量、大小、比例的参数设定,减少了模型的计算复杂度,提高了目标检测模型的通用性和鲁棒性;
[0046]
2.该目标检测模型利用不同大小的感受野回归预测目标的位置和种类,感受野小的特征图,像素点映射回输入图像包含的区域小,负责预测小尺寸的目标物体。感受野大的特征图,像素点映射回输入图像包含的区域大,负责预测大尺寸的目标物体,这样,该方法可以很好地预测连续多尺度目标物体;
[0047]
3.该网络模型仅仅由3
×
3,1
×
1卷积核构成,模型是非简单并且模型参数非常小,可以很方便地在嵌入式设备上进行移植应用,适合边缘设备等。
[0048]
需要强调的是:以上仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1