一种基于知识图谱的数据审计方法与流程
本发明涉及数据安全领域,涉及一种基于知识图谱技术的数据安全审计模型,对数据进行审计方法。
背景技术:
随着企业的不断发展和信息化建设的不断深入,在各个业务系统都积累了大量的数据,并且数据的增长速度也在不断增加,数据已经成为企业核心资产中至关重要的一部分,保障数据资产的安全性,充分发挥数据资产的价值,成了近些年企业越来越关注的话题。此外,公司经营管理模式的创新对数据资产的利用效率,提出了更高的要求,特别是对大中型企业而言,数据资产的高效管理和利用,所需要考虑的一个重点就是,如何对各业务线的数据进行统一管理和应用,消除或减少数据的重复存储,统一数据标准,提高数据质量。在这种背景下,如何在保证效率与准确性的前提下对全域数据进行实时审计,成为亟需解决的问题之一。
为了增强系统的整体安全性能,安全审计和防火墙、入侵检测等安全工具一起组成了一个多层次的整体安全策略。安全审计与追踪就是对有关操作系统、系统应用或用户活动所产生的一系列的计算机安全事件进行记录和分析的过程。在计算机网络中,管理员采用审计系统来监视系统状态和用户活动,并对日志文件进行分析,及时发现系统中存在或潜在的安全问题,并且在出现系统安全问题后,管理员可以借助安全审计的帮助对大量数据进行有效分析,甚至可以实现犯罪过程的重放。
随着认知智能技术的深入发展,知识图谱俨然成为了大数据时代的一种重要的知识表示形式。在多个垂直领域,以数据分析、智慧搜索、智能推荐、自然人机交互为主的实际应用场景中,皆对知识图谱提出了客观的使用需求。与此同时,知识图谱作为实现机器认知智能的重要基石,同样是现阶段人工智能领域的热门研究课题。
技术实现要素:
针对现有技术的缺陷,本发明提出一种基于知识图谱的数据审计方法,通过对数据库中获取的第一审计数据经过实体关系抽取以及知识推理处理构建知识图谱,数据采集模块从知识图谱中获取安全第二审计数据,数据分析挖掘模块再从其中提取潜在价值的数据,用于数据安全模型的数据挖掘系统中,提高审计的效率和准确性,进一步降低企业维护数据的成本。是通过如下技术方案实现的。
一种基于知识图谱的数据审计方法,包括以下步骤:
从数据库获取的第一审计数据,在所述第一审计数据中经过实体关系抽取及知识推理处理构建知识图谱;
从所述知识图谱中获取第二审计数据,再从其中提取潜在价值的数据,用于构造数据安全模型;
对数据安全模型进行数据分析得到审计规则。
本发明的有益效果是:
基于知识图谱的数据安全审计策略,根据审计规则实现数据安全审计,提高效率与可靠性。
附图说明
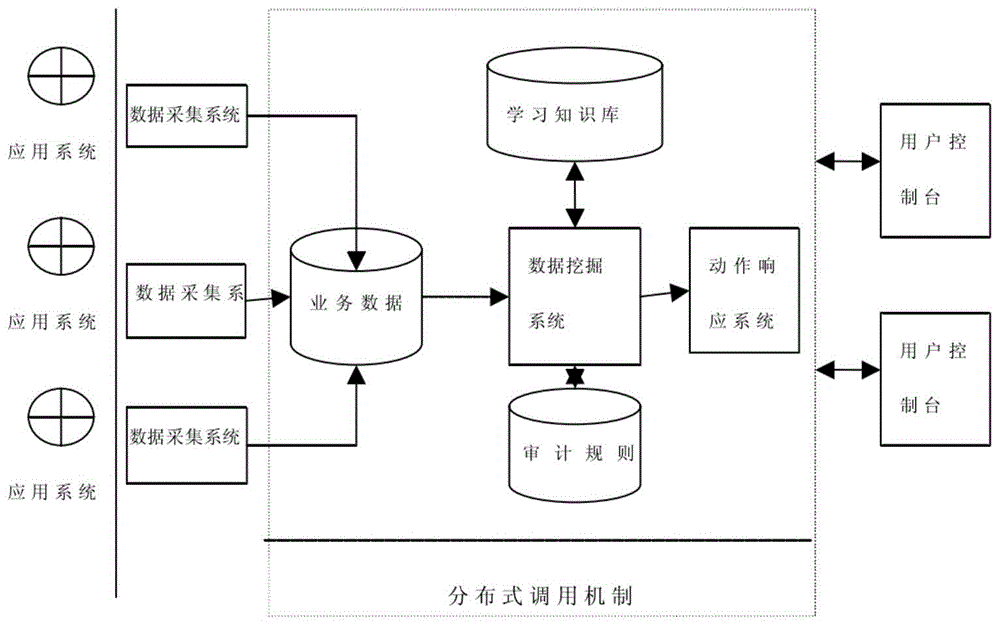
图1是本发明具体实施例的安全审计模型结构示意图。
图2是本发明具体实施例的安全审计模型物理组成框架结构图。
图3是本发明具体实施例的数据采集系统运行过程流程图。
图4是本发明具体实施例的数据挖掘系统框架结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明涉及一种基于知识图谱的数据审计方法,包括以下步骤:
从数据库获取的第一审计数据,在所述第一审计数据中经过实体关系抽取及知识推理处理构建知识图谱;
从所述知识图谱中获取第二审计数据,再从其中提取潜在价值的数据,用于构造数据安全模型;
对数据安全模型进行数据分析得到审计规则。
在本发明的实施例中,数据安全审计模型是一个分布式的审计模型,模型的物理组成框架如图1-2所示,在系统框架的结构上可以划分为三个独立的物理组成部分:数据采集系统,控制服务器,用户控制台。
数据采集系统:分布在要监控的各个节点上,负责采集数据和过滤数据以及最终的数据上传,同时还要能调度各个数据采集器工作。
控制服务器:控制服务器可运行在同一主机,也可运行在不同的主机。一般运行的主机是由内部安全控制部门管理的服务器。它提供了数据挖掘系统运行的环境和一些通讯管理功能,负责管理业务数据库的审计数据。
用户控制台:提供用户管理的一个图形化界面,用户可以进行规则管理配置和查看审计结果等。
数据采集系统和控制服务器,用户控制台之间的通信是通过socket通讯代理来实现的。
数据分析是指根据审计规则对数据采集系统采集的数据进行实时或离线的关联分析,来判断目前的数据是符合规则的应用行为信息还是异常的应用行为信息,同时生成相关的审计报告信息。其中的数据分析和规则挖掘是由数据挖掘系统进行的。
审计规则是判断信息系统安全与否的依据,是违规违法事件的判断依据。它主要来自于相应的信息安全策略和领域用户的定制,同时它也可以通过数据挖掘系统的运行过程中进行规则挖掘,把挖掘出一些能反映用户行为的规则扩充到学习知识库中,作为系统规则匹配的依据。
在数据采集系统设计中由于需要进行数据多样化的采集,数据采集系统运行过程如附图3所示,采集到的数据我们分为两类:一类是网络数据;另外一类是主机数据,对于网络数据我们可以在一个局域网的网关处放上采集器,对于主机型的数据我们需要在每个主机上安置采集器。
本发明实施例提出的一种规则增强的三元组抽取算法,采用关联规则的aprioritid的改进算法aprioritid-opt算法进行关联规则挖掘,包括以下步骤。
在有向图g上执行随机游走算法,获得与每个实体相关的路径序列per,例如
从pεγ中获得与vi和vj相关的路径集合。接着遍历上述集合中的每一条路径pl,在以vi开头的路径中,如果存在有与vj之间的最短依存路径dshort_path(vi,vj),则将(vi,vj)放入候选集合。
在上述中的有向图g,通过对图中顶点结构的迭代计算对顶点的重要性进行排序。采用如下公式:
其中n(i)为顶点v的邻居顶点集合。
实体间距离计算:
由上述两个公式得到关系强度度量公式:
对于数据安全审计系统来说,采用的“用户→操作对象→操作类型”模式,所有挖掘的数据都是三项集,aprioritid算法本身对三项集挖掘时不能减少扫描事务数量,很多小于最小支持度的事务的项集被加入到
首先,由原始数据库d直接构造c1,每项i由项集{i}代替(每个事务所包含的潜在频繁1-项集),然后计数得到频繁1-项集l1。
由apriori-gen(l1)生成候选2-项集c2。
接下来就是由
循环事务t.tid中包含的候选集,对于候选集c.count小于最小支持度的,从
若apriori-gen(lk)的返回值为空,算法停止,否则,重复步骤2、3直到满足终止条件为止。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!