一种基于多模态特征完备表示的短视频分类方法
本发明涉及短视频分类领域,尤其涉及一种基于多模态特征完备表示的短视频分类方法。
背景技术:
近年来,随着智能终端的普及以及社交网络的火热,越来越多的信息采用多媒体内容呈现,高清摄像头、大容量存储和高速网络连接为用户创造了极其便利的拍摄和分享条件,从而创造了海量的多媒体数据。
短视频作为一种新型的用户生成内容,凭借其创作门槛低、碎片化内容以及较强的社交属性等独特优势在社交网络中受到了极大的欢迎。尤其是2011年以来,伴随着移动互联网终端的普及和网络的提速以及流量资费的降低,短视频迅速获得了包括各大内容平台、粉丝以及资本等多方的支持与青睐。有数据显示,全球移动视频流量已经占据移动数据总流量的一半以上,且持续高速增长。规模庞大的短视频数据很容易湮没用户需要的信息,使得用户难以找到其所期望的短视频信息内容,所以如何有效处理和利用这些信息变得至关重要。
以深度学习为代表的人工智能技术已经成为当今最流行的技术之一,被广泛运用到计算机视觉等众多领域中。
因此,将其引入到短视频的分类任务中不仅有利于推动计算机视觉以及多媒体领域相关课题的创新,对于用户体验的提升以及工业界的发展也具有很重要的应用价值和现实意义。
技术实现要素:
本发明提供了一种基于多模态特征完备表示的短视频分类方法,解决了短视频多标签分类问题并对结果进行评估,详见下文描述:
一种基于多模态特征完备表示的短视频分类方法,所述方法包括:
对于短视频自身内容信息,提出以视觉模态特征为主,从模态缺失角度构建四个子空间并分别获得潜在的特征表示,对四个子空间的潜在特征表示进一步利用自动编解码网络进行融合以保证学习到更鲁棒且有效的公共潜在表示;
对于标签信息,采用逆协方差估计和图注意网络探究标签间的相关性并更新标签表示,得到与短视频对应的标签向量表示;
对公共潜在表示和标签向量表示提出基于多头注意的多头跨模态融合方案,用于获得短视频的标签预测分数;
模型的整体损失函数由传统的多标签分类损失和自动编解码网络的重建损失组成,用来度量网络输出值与实际值之间的差距,并以此来指导网络找寻模型最优解。
其中,所述两类视觉模态特征潜在表示为:独特的视觉模态潜在表示和不同模态信息互补下的视觉模态潜在表示。
进一步地,所述采用逆协方差估计和图注意网络探究标签间的相关性并更新标签表示,得到与短视频对应的标签向量表示具体为:
引入逆协方差估计,对于给定的标签矩阵v,寻找逆协方差矩阵s-1来表征标签的成对关系,即定义图关系函数来初始化图结构s;
将输入到该网络中的标签矩阵v转换成新的标签矩阵,并输入到图关系函数g(·)中,计算出新的标签矩阵下的图结构s′。
其中,所述基于多头注意的多头跨模态融合方案为:利用短视频视觉特征公共潜在表示查询标签,计算相关性,对齐短视频视觉模态公共潜在表示和标签矩阵。
本发明提供的技术方案的有益效果是:
1、本发明探究了短视频中的多模态表示学习问题,提出一种以视觉模态信息为主、其他模态信息为辅的深度多模态统一表示学习方案,从模态缺失角度构建四个子空间学习模态间信息互补性,获得两类视觉模态特征的潜在表示,又考虑到视觉模态特征信息的一致性,对两类视觉模态特征的潜在表示利用自动编解码网络融合得到视觉模态特征的公共潜在表示。这一过程同时考虑到模态缺失问题和模态信息的互补性及一致性,充分利用了短视频的模态信息;
2、本发明探究了短视频的标签信息空间,从逆协方差估计和图注意网络两个层面考虑,提供了标签相关性学习的一种新思路;
3、本发明针对短视频“时长有限,信息不足”的劣势,建议从短视频的内容信息和标签信息两个角度分别学习视觉模态公共潜在表示和标签表示,并对这两种表示提出基于多头注意的多头跨模态融合策略获得最终标签预测分数。
本发明充分利用短视频的各模态信息来学习对多标签分类任务有重大作用的视觉模态表示和标签表示,有利于提高短视频多标签分类任务的准确度。
附图说明
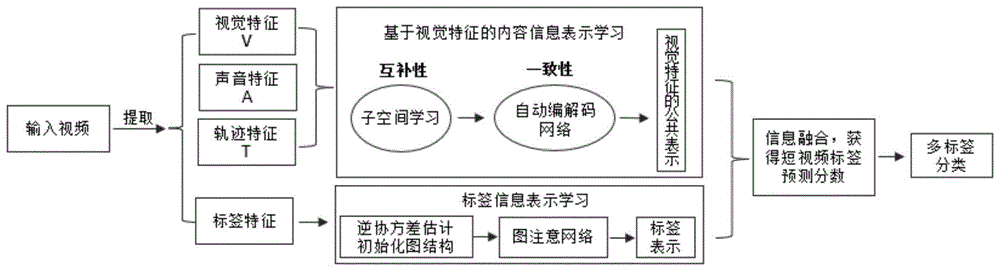
图1为基于多模态特征完备表示的短视频分类方法的整体网络框架图;
图2为子空间学习框架图;
图3为实验结果数据。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
实施例1
本发明实施例提供了一种基于多模态特征完备表示的短视频分类方法,充分利用了短视频的内容信息和标签信息,参见图1,该方法包括以下步骤:
101:对于内容信息,根据经验可知在短视频多标签分类任务中视觉模态的语义特征表示是至关重要的,因此提出基于视觉模态特征的表示学习,以视觉模态特征为主,从模态缺失角度构建四个子空间,学习模态间信息互补性,获得两类视觉模态特征的潜在表示。考虑到视觉模态特征信息的一致性,为得到更为紧凑的视觉模态特征表示,对四个子空间获得的两类视觉模态特征潜在表示利用自动编解码网络融合以学习视觉模态特征的公共潜在表示;
102:对于标签信息,采用一种独特的凸形式(逆协方差估计)和图注意网络探究标签间的相关性并更新标签表示,得到与短视频对应的标签向量表示;
该标签向量表示用来探索适合于短视频数据集的标签表示,与步骤101的视觉模态特征的公共潜在表示一同参与步骤103的多头跨模态融合网络中;
103:对两种信息空间的表示即:步骤101获得的视觉模态特征的公共潜在表示和步骤102获得的标签表示提出基于多头注意的多头跨模态融合方案,用于获得短视频的标签预测分数;
其中,该多头跨模态融合网络的输出可看作输入短视频的标签预测分数,直接用于分类损失函数中。
104:整体损失函数由传统的多标签分类损失和自动编解码网络的重建损失组成,用来度量网络输出值与实际值之间的差距,并以此来指导网络找寻模型最优解。
其中,方案性能用覆盖率、排名损失、平均精度、汉明损失和首标记错误五个评价指标来评估,确保实验结果的客观性。
具体实现时,在步骤101之前,该方法还包括:
输入短视频,分别用经典的深度学习网络提取视觉、声音、轨迹三模态特征。
综上所述,本发明实施例通过利用多模态学习和标签学习相关理论,并结合深度学习网络的优势,获得输入短视频的标签预测分数,分类结果准确、有效。
实施例2
下面结合计算公式、实例对实施例1中的方案进行进一步地介绍,详见下文描述:
201:模型输入一个完整的短视频,分别提取视觉、音频和轨迹三种模态特征;
对于视觉模态,提取关键帧,并对所有视频关键帧运用经典的图像特征提取网络resnet(残差网络),然后做平均(avepooling)操作以获取视觉模态特征xv的整体特征zv:
其中,resnet(·):残差网络,avepooling(·):平均操作,xv:短视频原始视觉特征,βv:待学习的网络参数,
对于音频模态,绘制声音频谱图,对频谱图利用“cnn+lstm(卷积神经网络+长短期记忆网络)”提取声音特征za:
其中,cnn(·):卷积神经网络,lstm(·):长短期记忆网络,xa:短视频原始音频特征,βa:待学习的网络参数,
其中,tdd(·):轨迹深度描述符网络,xt:短视频的原始轨迹信息,βt:待学习的网络参数,
202:基于视觉模态的模态子空间学习;
本模型考虑短视频的视觉模态、音频模态和轨迹模态。对一个具体的短视频而言,一般都含有视频画面,即视觉模态特征是存在的,但其它两种模态的缺失情况是不确定的,不同的模态缺失情况共有四种。根据经验,在“短视频多标签分类”任务中视觉模态潜在表示是至关重要的,因此基于视觉模态潜在表示学习构建四个子空间,即分成两大类情况讨论:独特的视觉模态潜在表示和不同模态信息互补下的视觉模态潜在表示,以保证对视觉模态潜在表示做充分的挖掘。(其中,视觉模态特征zv、音频模态特征za、轨迹模态特征zt均是步骤201中所得。)
①独特的视觉模态潜在表示
利用提取的视觉模态特征zv,学习其特有的潜在表示hv:
其中,
②不同模态信息互补下的视觉模态潜在表示
引入归一化指数函数定量分析不同模态信息与视觉模态信息的互补关系,从而将其他模态特征转换成视觉表示空间下的对应特征,并与视觉模态特征相加送入一个特征融合映射器中,得到信息互补后的视觉模态潜在表示。
ⅰ.当只有视觉模态特征zv和音频模态特征za时,首先计算两种模态特征的关联矩阵ua:
其中,
然后,计算模态之间的相关性得分矩阵
其中,softmax(·):归一化指数函数(下文同),dv:视觉模态特征zv的维度,da:音频模态特征za的维度,
利用相关性得分矩阵
其中,
最后,将原始视觉模态特征zv和视觉表示空间下的音频模态特征
其中,θa:待学习的特征融合映射器参数,
ⅱ.当只有视觉模态特征zv和轨迹模态特征zt时,采用与ⅰ相同策略得到轨迹模态信息补充后的视觉模态潜在表示。
其中,ut:视觉模态特征zv和轨迹模态特征zt的关联矩阵,
其中,
其中,
其中,φt:特征融合映射器,θt:待学习的特征融合映射器参数,
ⅲ.当视觉模态特征zv、音频模态特征za、轨迹模态特征zt都存在时,考虑用音频信息和轨迹信息联合补充视觉信息。
首先获取音频模态和轨迹模态的联合信息表示zat:
其中,concat(·):特征向量级联函数,
其中,uat:三种模态间的关联矩阵,
其中,
其中,
其中,φat:特征融合映射器,θat:待学习的特征融合映射器参数,
203:自动编解码网络学习视觉模态潜在表示的一致性;
子空间学习到的视觉模态潜在表示应该是相似的,理论上它们都表征同一视觉内容。采用自动编解码网络,使步骤202中学习到的两类视觉模态潜在表示尽可能地投影到一个公共空间中。该方案有两个优点,一方面在一定程度上防止了数据的过拟合,对数据进行降维,得到更为紧凑的视觉模态潜在表示;另一方面,加强了四个子空间之间的有效联系,使子空间学习变得更有意义。步骤202中得到两类视觉模态潜在表示:独特的视觉模态潜在表示hv和模态互补下的视觉模态潜在表示
由此得到重建损失函数
其中,gae(·):编码网络,gdg(·):退化网络,wae:编码网络的待学习参数,wdg:退化网络的待学习参数,
204:学习短视频的标签信息空间;
多标签分类任务的关键问题之一是探索标签关系。构建图注意网络来探索标签相关性和计算标签矩阵。为此,首先引入图的概念。对标签集合y={y1,y2,…,yc},其中c表示标签类别数量,考虑图g(v,e),其中v表示标签节点的集合,e∈|v|×|v|表示标签关系的邻接矩阵。具体来说,对于任意标签节点vi,其邻域节点被定义为ρi(j)={j|vj∈v}u{vi},原始标签矩阵是v=[v1,v2,…,vc],其中
(1)建立初始图结构
由于标签之间的初始关系是未知的,所以引入逆协方差估计,对于给定的标签矩阵v,寻找逆协方差矩阵s-1来表征标签的成对关系,即定义图关系函数:g(v)=tr(vs-1vt)(19)
s.t.s≥0;tr(s)=1
来初始化图结构s。模型的解是使g(v)取得最小值的s。计算s的解析解表达式是:
其中,tr(·):矩阵的迹,vt:标签矩阵的转置。
(2)图注意学习
为学习标签节点表示,提出一种独特的图注意学习网络,包括节点特征学习和节点关系学习两步:
第一步,节点特征学习。考虑将输入到该网络中的标签矩阵v转换成新的标签矩阵
其中,m(·):应用在每个标签节点上的特征映射函数,vj:第j个标签节点表示,sij:标签i和标签j的关系得分,v′i:标签i的新特征,v'c:标签c的新特征,
第二步,节点关系学习。将第一步学习到的新的标签矩阵v'输入到图关系函数g(·)中,计算出新的标签矩阵下的图结构s′:
其中,v′t:新的标签矩阵的转置。注意:v′、s′是后一层图注意学习层(式-21)的输入。这样,模型共建立2到3个图注意学习层,最后获取结构化标签矩阵
205:为获得短视频的标签预测分数,对步骤203得到的视觉模态公共潜在表示h和步骤204得到的结构化标签矩阵p提出基于多头注意的信息融合方案。
多头注意允许模型在不同的位置联合处理来自不同表示子空间的信息。首先计算本任务中的查询矩阵q、键矩阵k和值矩阵v。
分析短视频多标签分类任务的特点,一个短视频可能包含多个标签,即短视频的视觉特征表示与标签表示的关系是多重耦合的,显式地研究这种耦合关系有利于分类任务。因此提出一个多头跨模态融合层,利用短视频视觉特征公共表示查询标签,计算它们的相关性,对齐短视频视觉模态公共表示和标签矩阵。
首先,考虑标签表示和视觉特征表示的相关性。计算视觉模态公共潜在表示h与第i类标签向量pi的关系得分βi:
受多头注意机制的启发,提出一个多头跨模态融合层计算视觉特征表示对应的标签表示。对于第e个注意头,计算视觉特征表示在标签空间的加权投影he:
其中,
其中,
其中,
206:采用传统的多标签分类损失来衡量预测标签分数与真实标签信息之间的差距:
其中,log(·):对数函数,y:短视频的真实标签信息,
所以,模型的整体损失函数
其中,λ是平衡分类损失
整个训练和测试过程中,模型的性能用覆盖率coverage、排名损失rankingloss、平均精度map、汉明损失hammingloss和首标记错误one-error五个评价指标来评估,其中:(1)覆盖率coverage用来计算平均需要多大程度的标签以覆盖实例的所有正确标签,它与召回率最佳水平的精确性有松散的联系,其值越小,性能越好;(2)排名损失rankingloss计算实例的倒序标签对的平均分数,其值越小,性能越好;(3)map表示m个类别准确度的平均值,其值越大,性能越好;(4)汉明损失hammingloss衡量标签被错分的次数,其值越小,性能越好;(5)首标记错误one-error计算预测概率值最大的标签不在真实标签集中的次数,其值越小,性能越好。(实验结果见图3)
综上所述,本发明针对短视频“时间有限,信息不足”的劣势,从内容信息和标签信息两个角度分别学习视觉模态公共潜在表示和标签表示,最后融合这两个信息空间的表示获得标签预测分数,整个过程充分利用了短视频的各模态信息。首先,探究短视频中的多模态表示学习问题,提出一种以视觉模态信息为主、其他模态信息为辅的深度多模态统一表示学习方案,具体来说,从模态缺失角度构建四个子空间学习模态间信息互补性,进一步考虑到视觉模态特征信息的一致性,利用自动编解码网络学习视觉模态的公共潜在表示;然后,探究短视频的标签信息,从逆协方差估计和图注意网络两个层面考虑,提供了标签相关性学习的一种新思路;最后对两种信息空间的表示提出基于多头注意的多头跨模态信息融合方案获得最终标签预测分数。
本发明实施例对各器件的型号除做特殊说明的以外,其他器件的型号不做限制,只要能完成上述功能的器件均可。
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!